之前探索了基于Saliency Map对LLM进行可解释性分析
https://blog.csdn.net/liliang199/article/details/156951048
这里进一步探索似然比方法,以及基于似然比方法的黑盒显著性图生成框架。
该方法的核心在于绕过反向传播,通过前向推理和随机采样来估计梯度。
所述内容参考和修改自网络资料。
1 似然比方法
似然比方法的核心:在不进行反向传播的情况下,仅仅通过前向推理和随机采样来估计梯度,从而生成显著性图。下面这张图直观地梳理了它的工作原理。
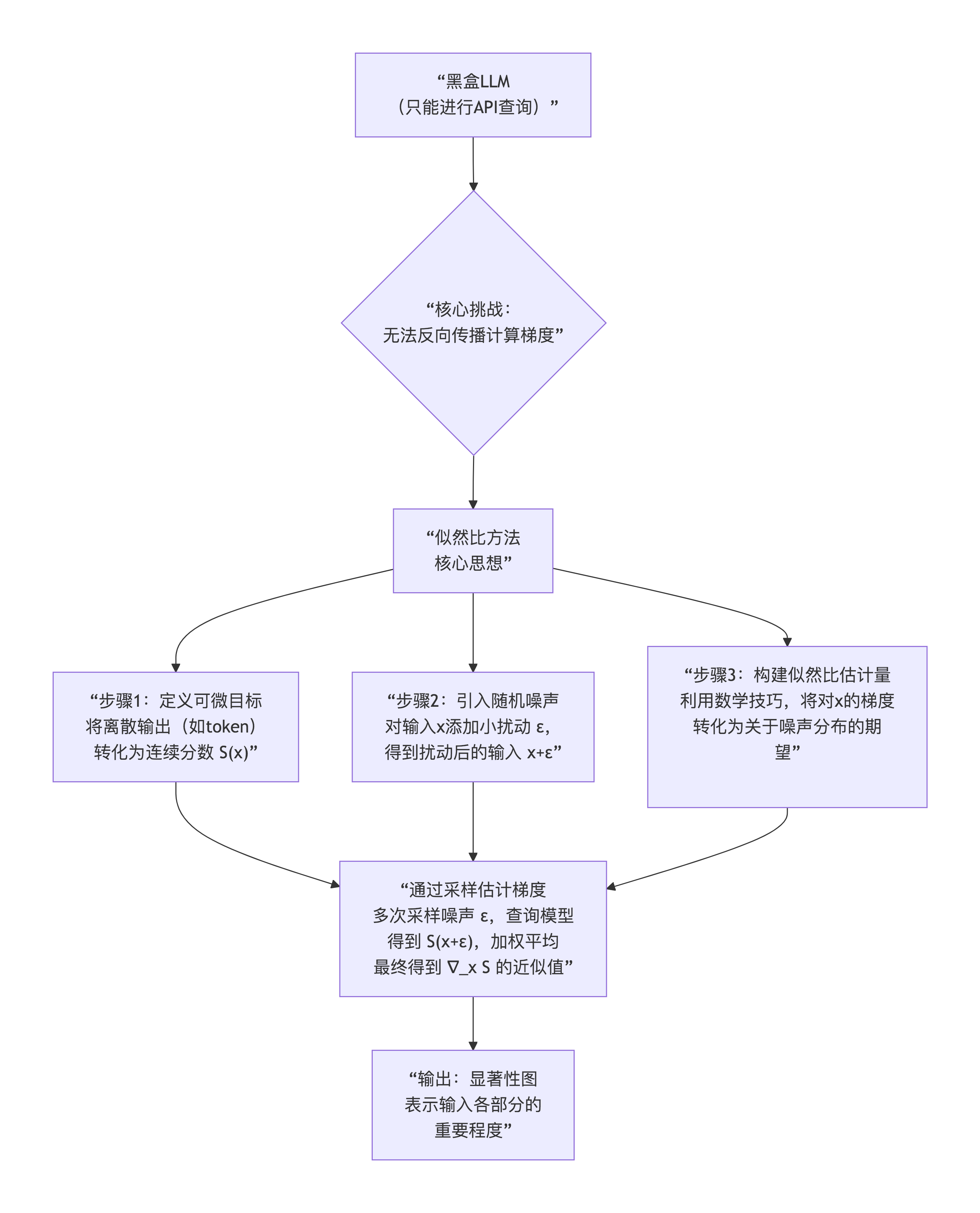
2 计算与推导
这里探索的目标是计算模型输出对输入
的梯度
。
传统方法需要已知模型内部结构并应用链式法则。
在黑盒场景下,只有一个能够通过API查询的函数,其内部网络和实现结构未知。
似然比方法通过一个巧妙的积分变换,将梯度估计问题转化为一个可以通过采样解决的期望问题。
2.1 引入随机性
目标是估计梯度是。这里人为地给输入
引入一个已知的概率分布。
例如,假设有一个服从标准正态分布的随机噪声。
那么,扰动后的输入的分布可以表示为
,其中
。
此时,模型在扰动输入上的输出的期望可以写成:
2.2 恒等变换-似然比
虽然目标很难直接得到,但也许可以估计
。
如果噪声的尺度很小,那么这两个量是近似相等的。
关键在于,对期望的梯度可以巧妙地移到概率密度函数上:
由于积分区域与无关,可以将梯度算子移入积分内部:
现在,利用对数导数的技巧,得到:
这个形式其实可以变成了一个期望:
这里,就是似然比(Likelihood Ratio)。
因为我们选择的是已知的简单分布(如正态分布),它的对数梯度
是可以直接解析求出的。
例如,对于,我们可以推导出
。
2.3 蒙特卡洛采样估计
现在,梯度估计转化为了一个期望。我们可以通过蒙特卡洛方法来近似这个期望:
这就是似然比梯度估计器的核心计算过程。
3 学习和探索
在似然比梯度估计器的计算过程中,可能需要注意以下一些方面。
1)无偏估计
这个估计器是无偏的,意味着当采样次数N足够大时,它的期望值就等于真实的梯度值。
2)方差问题
这个方法可能存在估计方差很大的问题。直观上,随机的噪声可能会导致的值产生剧烈波动。为了获得稳定的梯度,通常需要大量的采样,这会带来巨大的计算开销。
3)目标定义
对于LLM,不能是一个离散的token,必须是一个连续函数。
可以将其定义为目标token的对数概率,在大部分闭源LLM的API,比如OpenAI的GPT,都可以输出这个概率。
也可以是一些启发式的语义得分,例如通过计算模型回答与某个关键词的语义相似度。
总而言之,似然比方法通过对黑盒函数的输入引入随机性,并利用对已知概率密度的求导,成功地将一个不可导的黑盒函数梯度估计问题,转化为一个可采样的期望估计问题。
这为打开LLM黑盒提供了一扇新的窗户,但如何降低其高方差,仍是该领域研究的重点。
reference
Forward Learning for Gradient-based Black-box Saliency Map Generation
https://ar5iv.labs.arxiv.org/html/2403.15603
基于Saliency Map对LLM进行可解释性分析