一、研究背景(Research Background)
1. CT 分割在做什么?
CT(Computed Tomography)是临床中最常用的医学影像之一,用于:
- 器官分割(肝、脾、肾)
- 病灶分割(肿瘤、出血、肺结节)
- 血管结构分割
传统深度学习方法包括:
- U-Net(CNN为主,强调局部结构)
- Transformer-based 方法(强调全局建模)
- CNN-Transformer Hybrid
这些方法的共同问题:
它们都是 task-specific ------ 每个任务单独训练一个模型。
在临床中这非常不现实,因为:
- 不同医院数据不同
- 不同器官/病灶都要重新训练
- 泛化能力弱
2. Foundation Model 的出现
SAM(Segment Anything Model)提出了一种新的 paradigm:
- 一个模型
- 任意图像
- 任意 prompt
- 输出 segmentation
这听起来非常适合医学领域。
但现实是:
SAM 在医学图像上严重退化。
原因(论文明确指出):
- 没有医学数据训练
- 医学图像语义抽象弱
- ViT 的大 patch 导致局部细节丢失
特别是医学图像的特点:
- 低对比度
- 模糊边界
- 小目标
- 复杂结构
ViT 擅长全局语义,但医学更依赖局部细节。
二、问题(Challenge)
论文要解决的问题是:
如何构建一个真正适用于 CT 的 foundation model,并且摆脱人工 prompt 依赖?
这个 challenge 本质上有两个因果冲突:
Challenge 1:ViT 的"全局优势" vs 医学的"局部依赖"
SAM 的 image encoder 是 ViT。
ViT 的优点:
- 全局感受野
- 强泛化能力
但医学图像中:
- 边界极细
- 对比度弱
- 局部纹理决定结构
大 patch tokenization → 局部信息丢失
因果结构:
因为 ViT 依赖大 patch 的 tokenization
→ 局部纹理丢失
→ 小器官/低对比病灶难分割
→ SAM 在医学上退化
Challenge 2:SAM 强依赖高质量 prompt
SAM 是 promptable segmentation。
在医学中:
- 医生必须画点
- 画 box
- 有时还要 mask
这本质上仍是"半自动"。
因果结构:
因为 segmentation 依赖精确人工 prompt
→ 需要医生参与
→ 仍然耗时
→ 无法真正临床落地
Challenge 3:简单 fine-tune 会破坏 foundation 特性
已有方法:
- LoRA
- Adapter
- 微调 encoder
问题:
- 在单一医学数据上训练
- 失去通用性
因果关系:
因为 tuning 数据单一
→ foundation 模型退化为 task-specific 模型
三、Finding(真正的核心洞察)
⚠️ 这里是整篇论文最重要的部分。
Finding 不是技术设计。
Finding 是他们"重新看待问题"的方式。
Finding 1:ViT 不够,不是要替代它,而是"补它"
他们的核心洞察:
医学图像不是不适合 ViT,而是 ViT 缺少局部结构补偿。
换句话说:
不是"换 backbone"
而是:
让 ViT 保持全局能力
同时并行一个 U-shaped CNN
让两者互相交换信息
这是一种 worldview 的改变:
以前的思路是:
- 要么 CNN
- 要么 Transformer
- 或者串联
他们的 insight 是:
不要选择
让两个分支平等并行
再做 cross-branch interaction
这把问题从:
"ViT 不适合医学"
变成:
"ViT + local refinement = 医学 foundation model"
Finding 2:Prompt 不一定来自空间,而可以来自"任务语义"
这是最漂亮的 insight。
SAM 的 prompt 是:
- 点
- box
- mask
他们的 insight:
prompt 本质上是告诉模型"你要找什么"
那为什么一定要用空间信号?
能不能用语义信号?
于是他们提出:
Task-Indicator Prompt
例如:
- "liver"
- "COVID-19"
- "spleen"
他们把 prompt 从"空间约束"变成"语义指令"。
这是一种 paradigm flip:
从"告诉模型在哪里"
→ 变成"告诉模型找什么"
这使得:
- 不需要人工画点
- 不需要额外 detector
- 不需要额外 segmentation model
这是真正的 foundation 思维。
四、方法(Method)
现在讲技术实现。
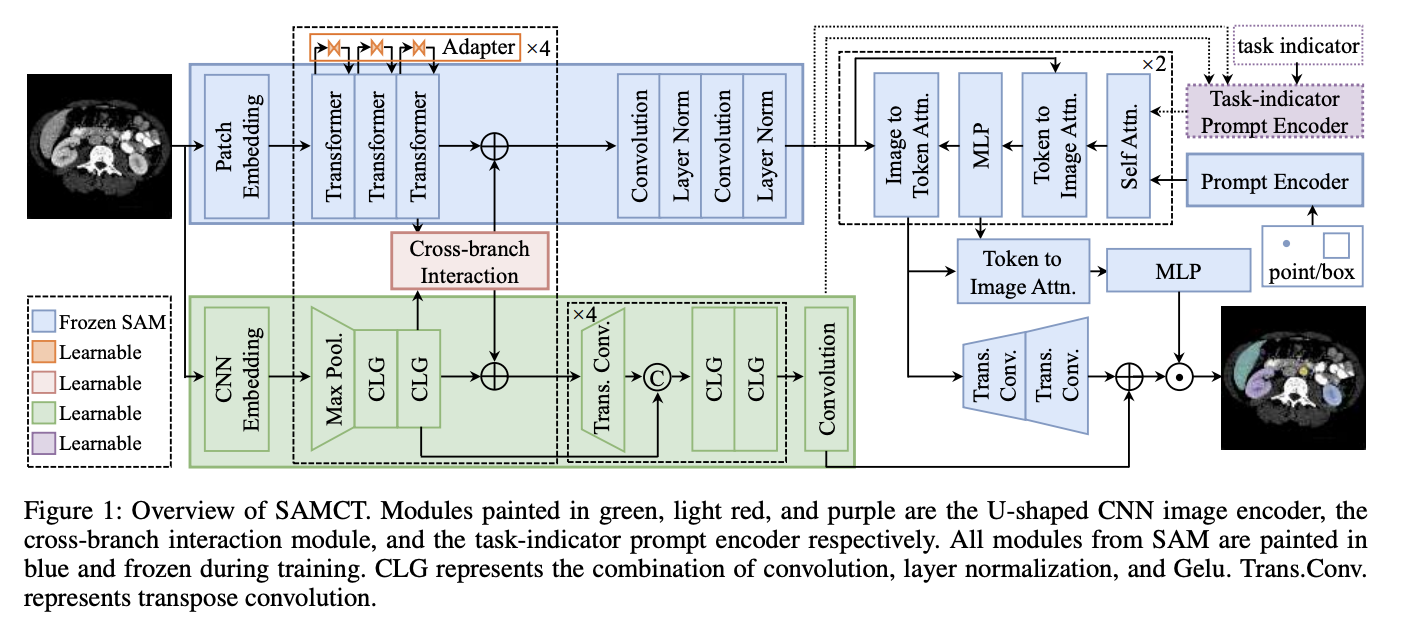
整体结构(page 3 图1)
SAMCT =
- 冻结的 SAM
- U-shaped CNN image encoder
- Cross-branch interaction
- Task-indicator prompt encoder
1️⃣ U-shaped CNN Encoder
输入:
x ∈ R^{3×H×W}
流程:
- CNN embedding
- 4层 encoding
- 4层 decoding
- 多尺度输出:F16, F32, F64, F128, F256
作用:
- 提供高分辨率局部特征
- 补充 ViT 丢失的细节
本质:
用 U-Net 的 inductive bias 补足 ViT 的弱点
2️⃣ Cross-branch Interaction
两种信息流:
CNN → Transformer
机制:
- 把 CNN 局部窗口作为 K/V
- ViT patch 作为 Q
- Cross-attention
作用:
把局部细节注入全局 token
Transformer → CNN
机制:
- 生成 spatial attention
- 对 CNN feature 做 coarse-to-fine reweight
作用:
用全局语义指导局部增强
这是双向知识蒸馏式融合。
3️⃣ Task-Indicator Prompt Encoder
输入:
- 正 indicator
- 负 indicator
- 多尺度特征
- ViT 特征
流程:
-
投影到 task-specific space
-
做 max/avg pooling
-
Cross-attention
-
生成:
- 正点 embedding
- 负点 embedding
- box embedding
关键:
如果没有前景
→ 自动生成 not-a-point embedding
参数量:
仅 1.7M
完全 plug-and-play。
五、实验结果(Conclusion & Findings)
1️⃣ 相比原始 SAM
在 30 datasets 上:
Dice 提升:
- visible datasets:+35% ~ +82%
- invisible datasets:+26% ~ +65%
说明:
- 不是简单 overfit
- 有强泛化能力
2️⃣ 对比医学 SAM 变体
在 16 个 object 上:
SAMCT 平均 Dice = 89.67
超过:
- MedSAM
- SAMed
- MSA
并且:
- visible 最强
- invisible 也最强
这说明:
并行 CNN + cross interaction 真正增强泛化
3️⃣ 对比 task-specific 模型
在 BTCV 上:
task-specific 模型严重退化(Dice 10%~30%)
SAMCT-CT5M:
Dice = 90.91%
这是真正 foundation 能力的体现。
4️⃣ Task-indicator prompt 的发现
对比不同 prompt:
- point 非常敏感
- box 较稳定
- center+box 最好
- task-indicator ≈ 最佳 manual prompt
但:
完全不需要人工
这意味着:
它已经接近 fully-automatic segmentation。
六、关键术语总结
Segment Anything Model (SAM)
通用分割基础模型
可通过点/框 prompt 分割任意对象
Foundation Model(基础模型)
在大规模数据上训练
具有泛化能力
可迁移到多任务
例子:
- GPT
- CLIP
- SAM
Cross-branch Interaction(跨分支交互)
两个 encoder 之间的双向信息流
通过 cross-attention 实现
Task-Indicator Prompt(任务指示 prompt)
用"任务语义"替代"空间点位"
例子:
输入:
task = "liver"
模型自动分割 liver。
Adapter
小型可训练模块
插入冻结大模型中
实现 domain adaptation
七、整篇论文的本质总结
这篇论文真正的贡献不是:
- 加了 CNN
- 加了 attention
真正的贡献是两个 paradigm 转变:
1️⃣ Foundation 不应该被 fine-tune 破坏,而应该被补强
而且补强应该:
- 并行
- 结构互补
- 双向交流
2️⃣ Prompt 不一定是空间约束,可以是语义约束
这实际上打开了:
从 interactive segmentation
→ automatic segmentation foundation model
这是一种范式升级。