目录
[(2)初始向量加位置编码 得到词向量](#(2)初始向量加位置编码 得到词向量)
[(5)Q 乘 K 再缩放,算出注意力分数](#(5)Q 乘 K 再缩放,算出注意力分数)
[(6)softmax 归一化,得到词之间的关联权重](#(6)softmax 归一化,得到词之间的关联权重)
[(7)权重乘 V 再求和,算出自注意力向量Z](#(7)权重乘 V 再求和,算出自注意力向量Z)
[2.多头自注意力机制Multi-Head Attention](#2.多头自注意力机制Multi-Head Attention)
[(9)512 维向量拆成 8 个 64 维的小向量](#(9)512 维向量拆成 8 个 64 维的小向量)
[(10)每组小向量算自注意力,拼回 512 维 Z 向量](#(10)每组小向量算自注意力,拼回 512 维 Z 向量)
[🔹 第一步:左侧 Encoder 输入层](#🔹 第一步:左侧 Encoder 输入层)
[🔹 第二步:左侧 Encoder Block(共 N=6 层,每层结构相同)](#🔹 第二步:左侧 Encoder Block(共 N=6 层,每层结构相同))
[🔹 第三步:右侧 Decoder 输入层](#🔹 第三步:右侧 Decoder 输入层)
[🔹 第四步:右侧 Decoder Block(共 N=6 层,每层结构相同)](#🔹 第四步:右侧 Decoder Block(共 N=6 层,每层结构相同))
[🔹 第五步:右侧输出层](#🔹 第五步:右侧输出层)
[(1)单词 Embedding](#(1)单词 Embedding)
[(2)位置 Embedding(正弦余弦位置编码)](#(2)位置 Embedding(正弦余弦位置编码))
[举例说明(以 d=4、pos=1 为例)](#举例说明(以 d=4、pos=1 为例))
[2.Q, K, V 的计算](#2.Q, K, V 的计算)
[3.Self-Attention 的输出](#3.Self-Attention 的输出)
[4.Multi-Head Attention](#4.Multi-Head Attention)
[(1)输入层:Q、K、V 向量](#(1)输入层:Q、K、V 向量)
(3)核心计算:缩放点积注意力(自注意力计算Self-Attention)
[(1)Add & Norm 残差、归一化](#(1)Add & Norm 残差、归一化)
[(2)Feed Forward](#(2)Feed Forward)
一.transformer整体框架
1.自注意力计算
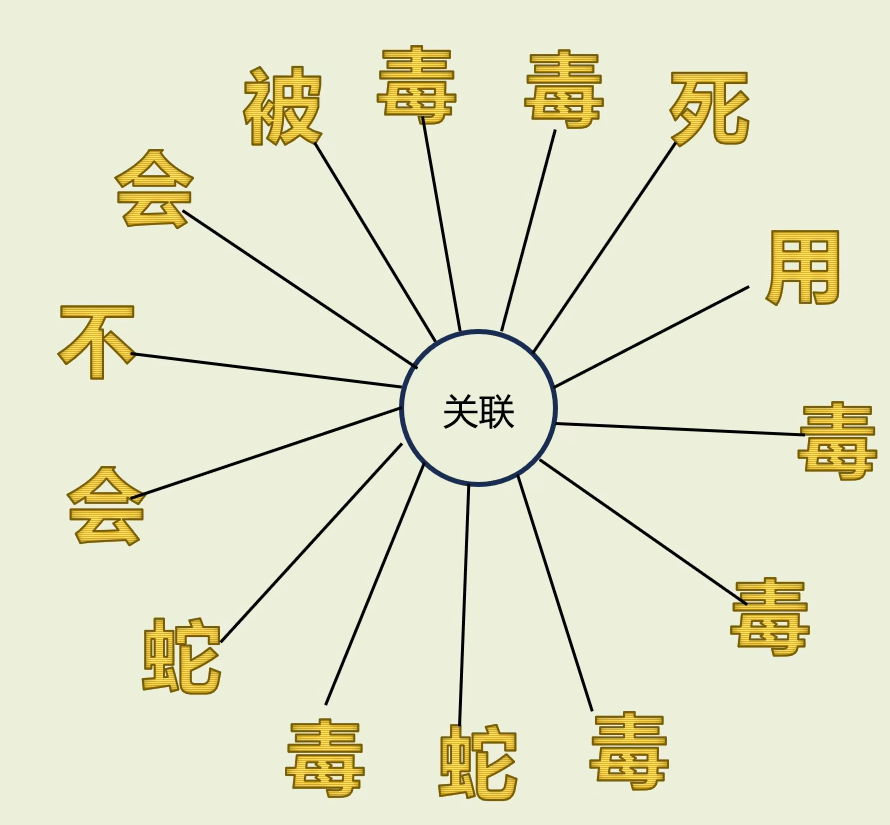
(1)翻译要找联系
"用毒毒毒蛇毒蛇会不会被毒毒死",若想翻译这句话,就要找到这句话每个词之间的联系

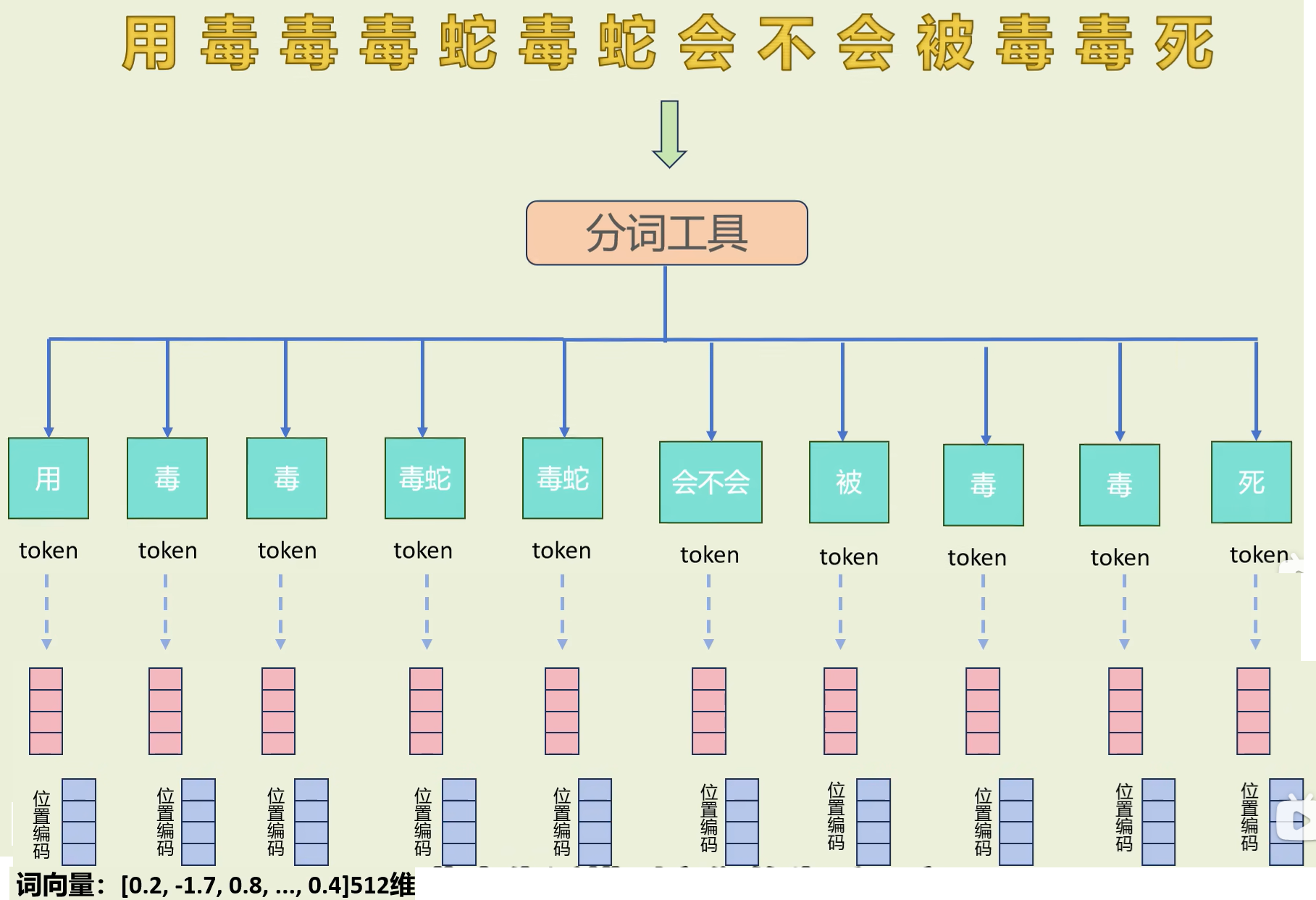
(2)初始向量加位置编码 得到词向量
这个句子首先会被分词工具分成若干个词,每个词对应一个512维的向量,这个512维向量还需加法加上一个512维位置编码,得到一个新的512维词向量,共10组512维新的词向量
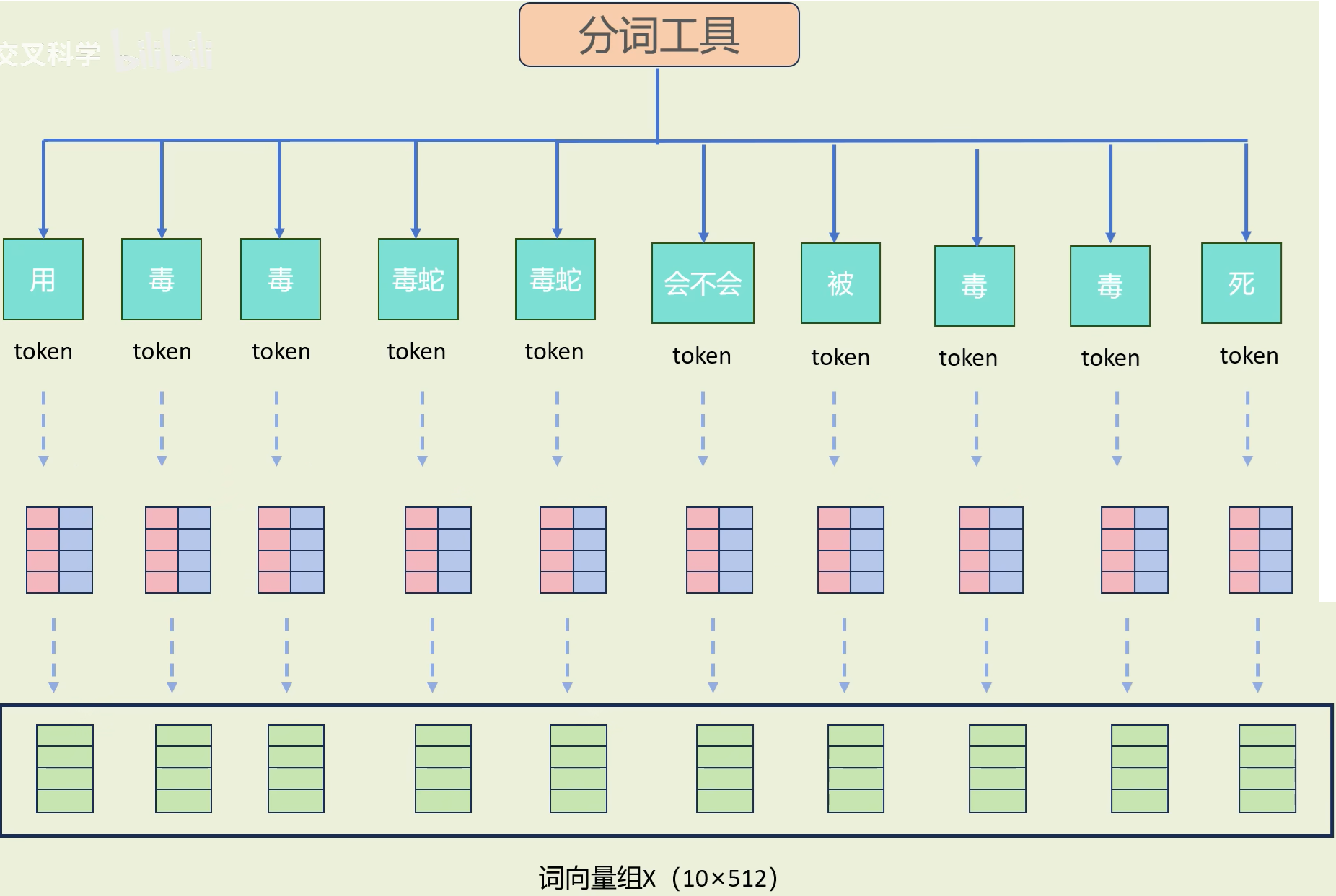
(3)得词向量
得到10组新的512维新的词向量
(4)得q、k、v
用三个权重矩阵分别与每个词向量相乘,每个词向量得到q、k、v三个向量
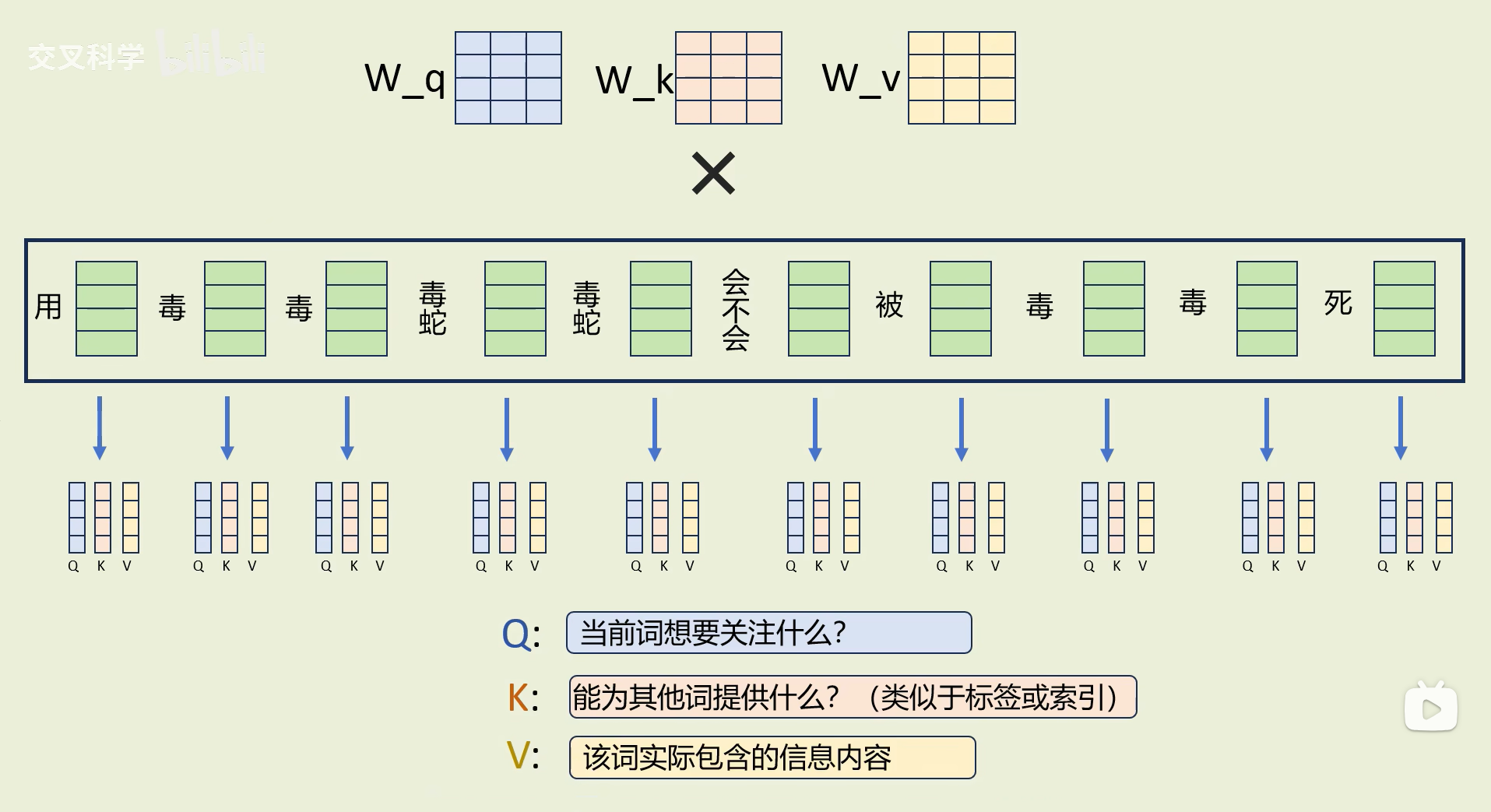
Q(查询向量):当前词想要关注什么?
K(键向量):该词能为其他词提供什么信息?(可看做标签或索引)
V:该词实际包含的信息内容
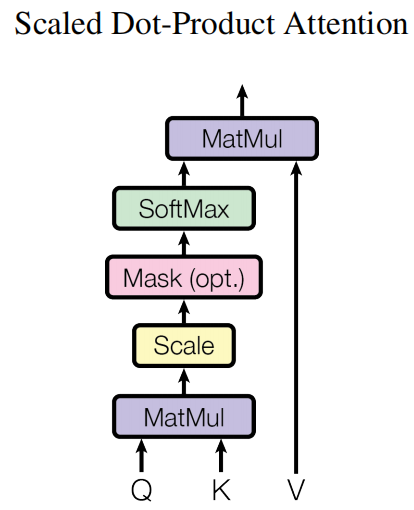
下面是Scaled Dot-Product Attention缩放点积注意力机制
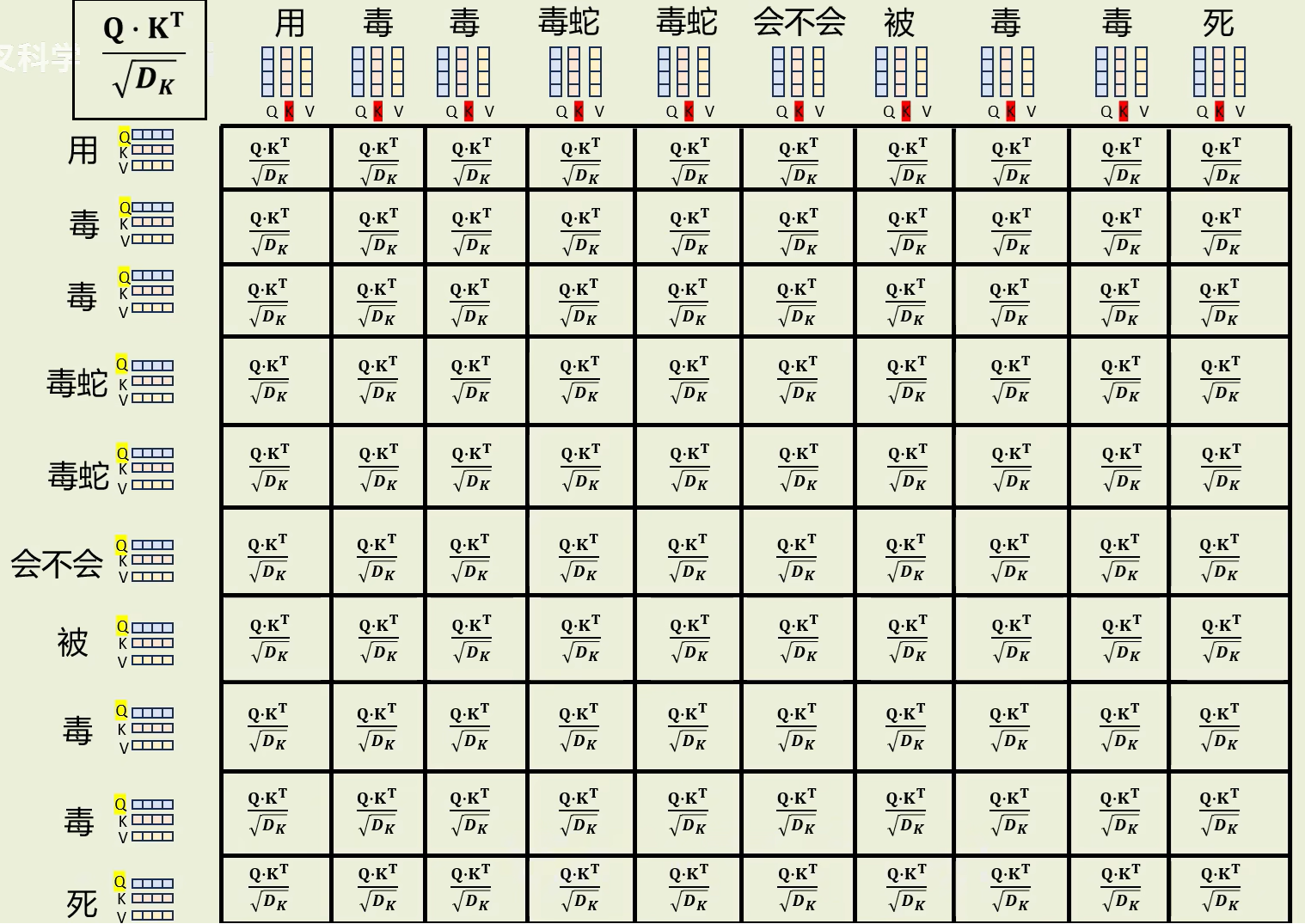
(5)Q 乘 K 再缩放,算出注意力分数
++MatMul++(Q × Kᵀ):将 Q 与 K 的转置矩阵进行矩阵乘法。
++Scale++ (缩放):将矩阵中的每个元素除以 √Dₖ(Dₖ 是 K 向量的维度)
用每个词的Q乘每个词的K,防止梯度爆炸除上,得到注意力分数
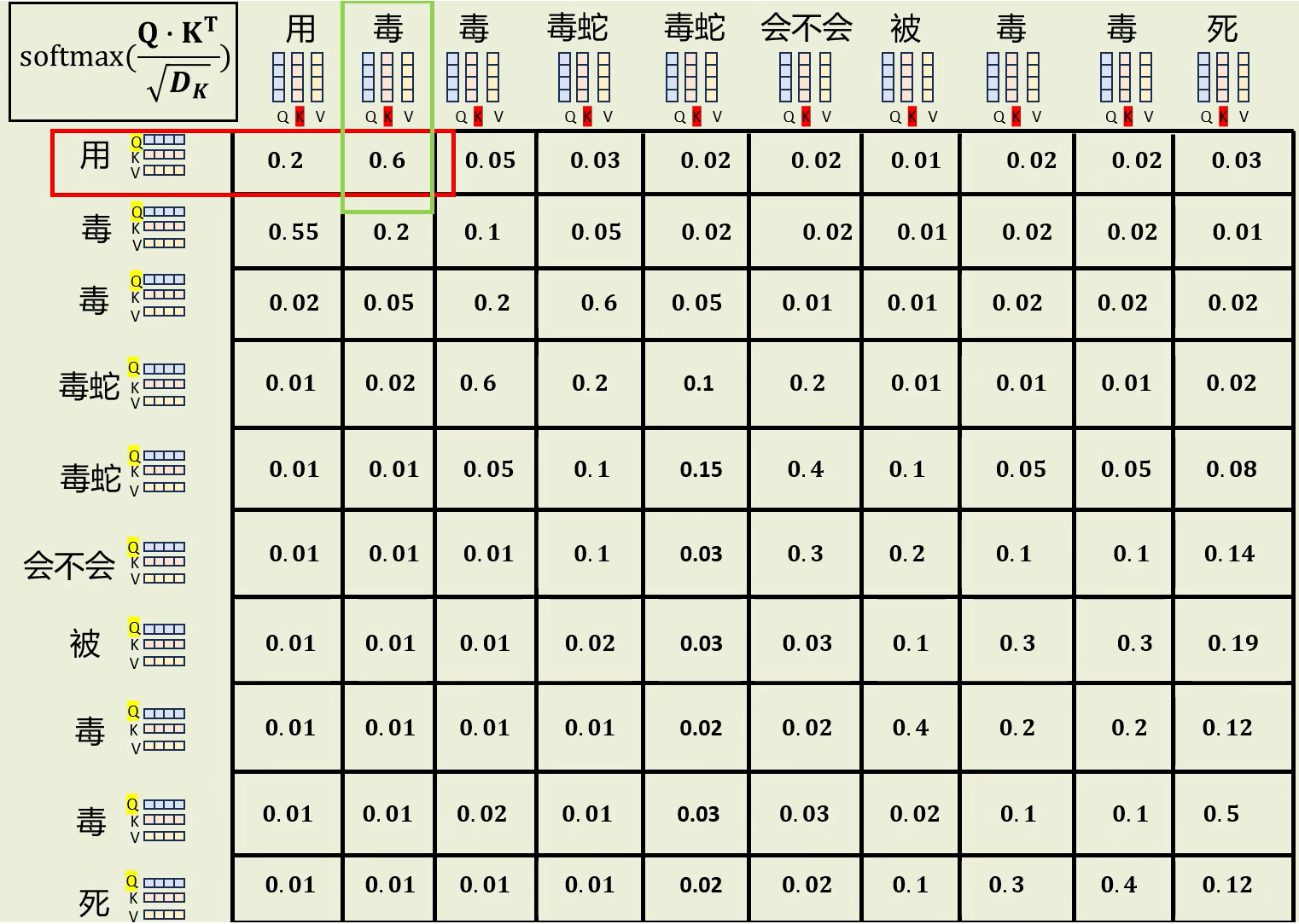
(6)++softmax++ 归一化,得到词之间的关联权重
加上softmax把注意力分数保持在0-1之间,得到注意力权重,这代表每个词的关联程度,例如"用"字和第一个"毒"字权重更高,和其他"毒"字权重较低
(7)权重乘 V 再求和,算出自注意力向量Z
++MatMul++(与 V 相乘):将注意力权重矩阵与 V 进行矩阵乘法。
将注意力权重和每个词的V向量相乘,再加权求和得到新的V向量,假设叫向量Z,这就经过了一次自注意力计算得到了一个向量Z

2.多头自注意力机制Multi-Head Attention
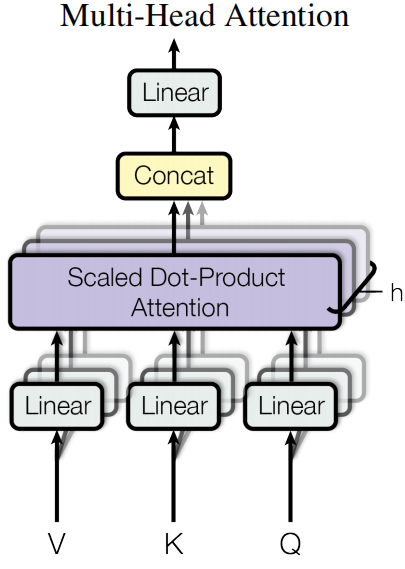
Multi-Head Attention
(8)引出多头机制
一次自注意力计算得到一个向量Z,太少不够用
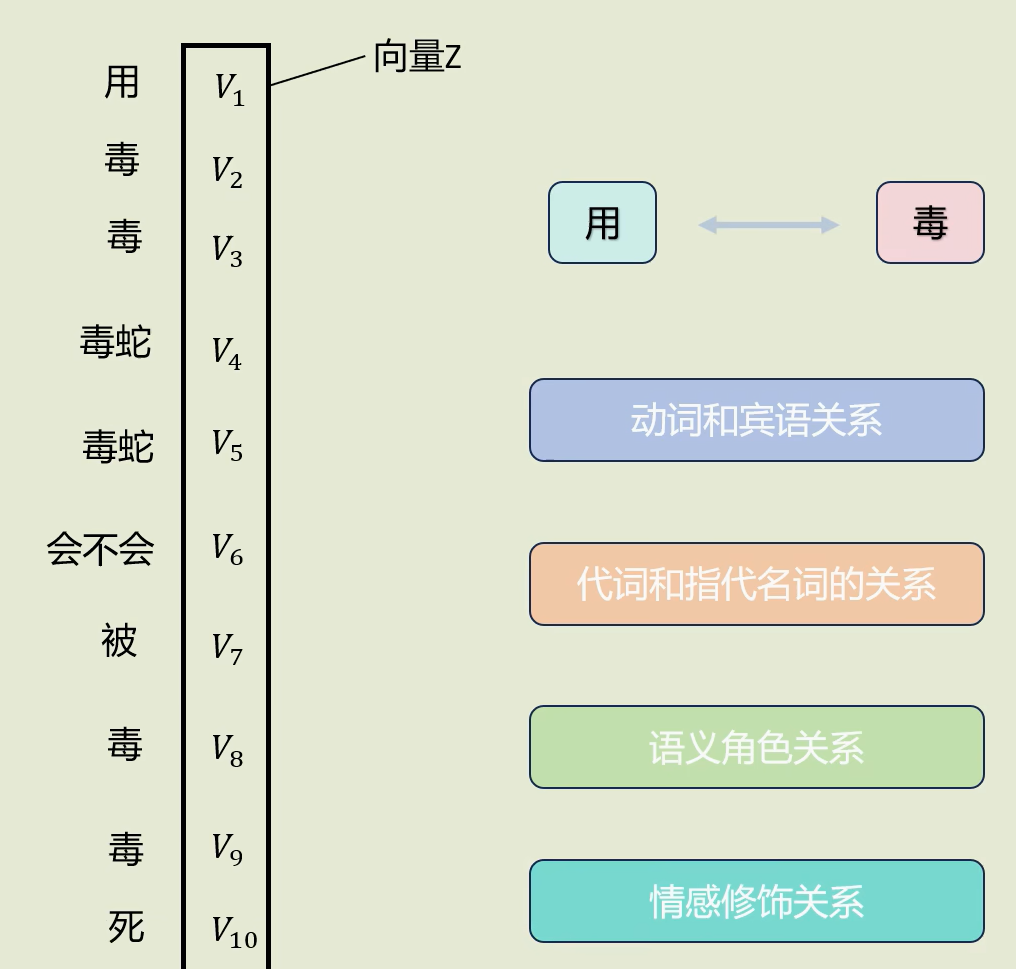
(9)512 维向量拆成 8 个 64 维的小向量
一次自注意力计算太少,那么下面是最开始的初始512维向量+512维位置编码得到的10组512维词向量,直接将10组512维词向量每个向量分成8个64维的向量
(10)每组小向量算自注意力,拼回 512 维 Z 向量
对应Multi-Head Attention图中的Linear
每组8个64维词向量分别进行之前的步骤,即:计算q、k、v,再跑一遍自注意力计算,每个64维词向量计算后各自得到一个64维的向量Z,然后再将这8个64维的向量Z拼接起来重新得到1个512维向量Z,10组的每一组都拼接,最终得到10×512的向量Z(我们叫它 上下文特征矩阵)

那么这个10×512的向量Z包含了8次独立的自注意力计算,这就叫做一层"多头自注意力机制"
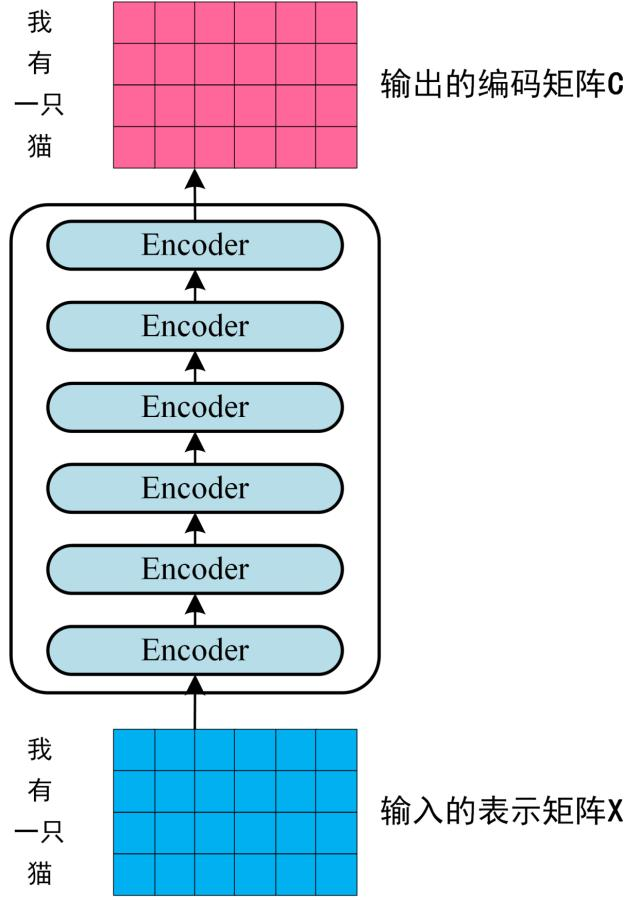
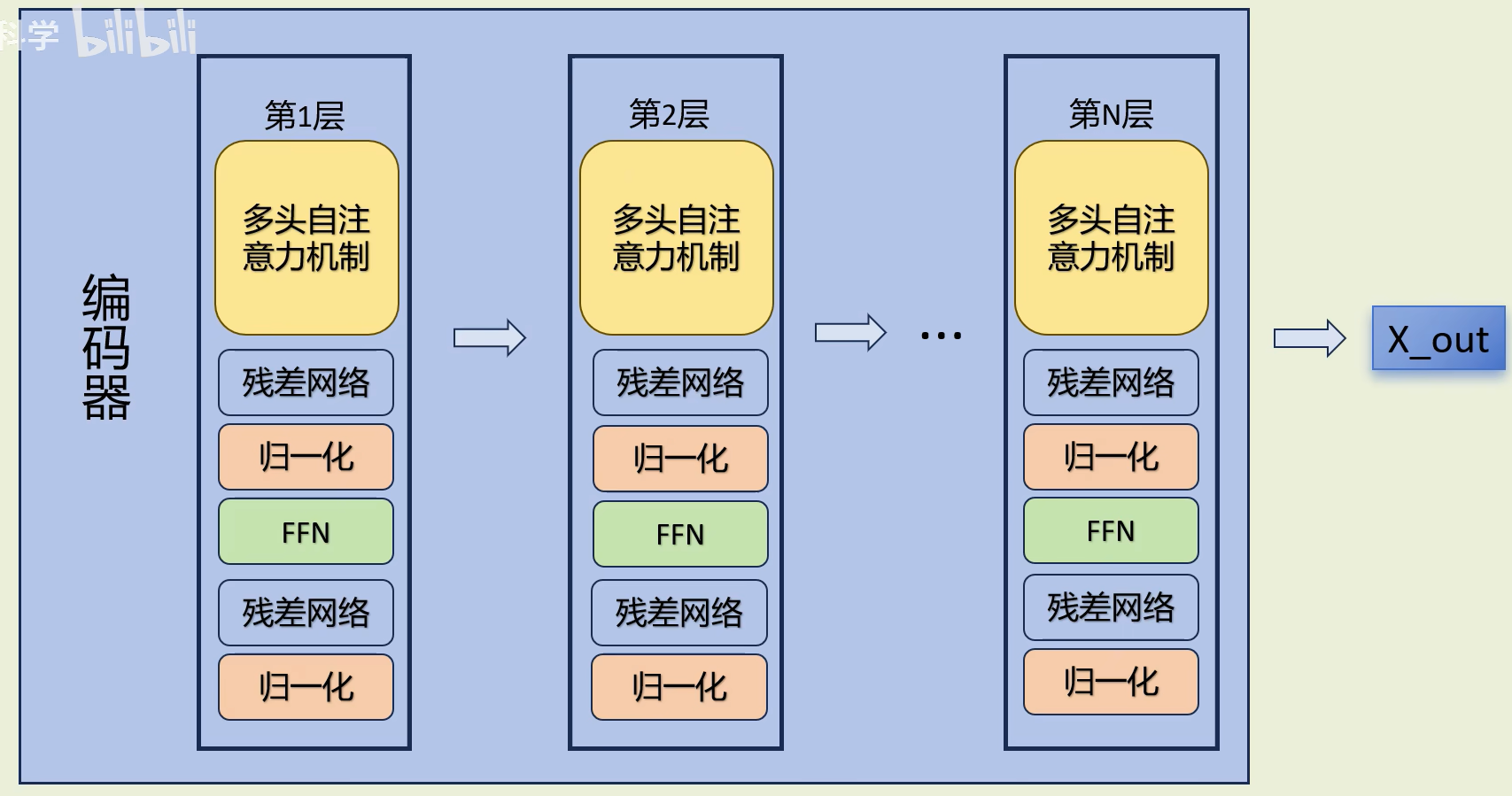
3.编码器
上述的"多头自注意力机制"需要n层,并且在每次"多头自注意力机制"后又依次进行 残差网络--->归一化--->FFN(relu激活)--->再一次残差网络--->再一次归一化,最终得到向量X_out。
这就形成了编码器,主要用途是负责理解输入的语言。
二.transformer架构图流程讲解
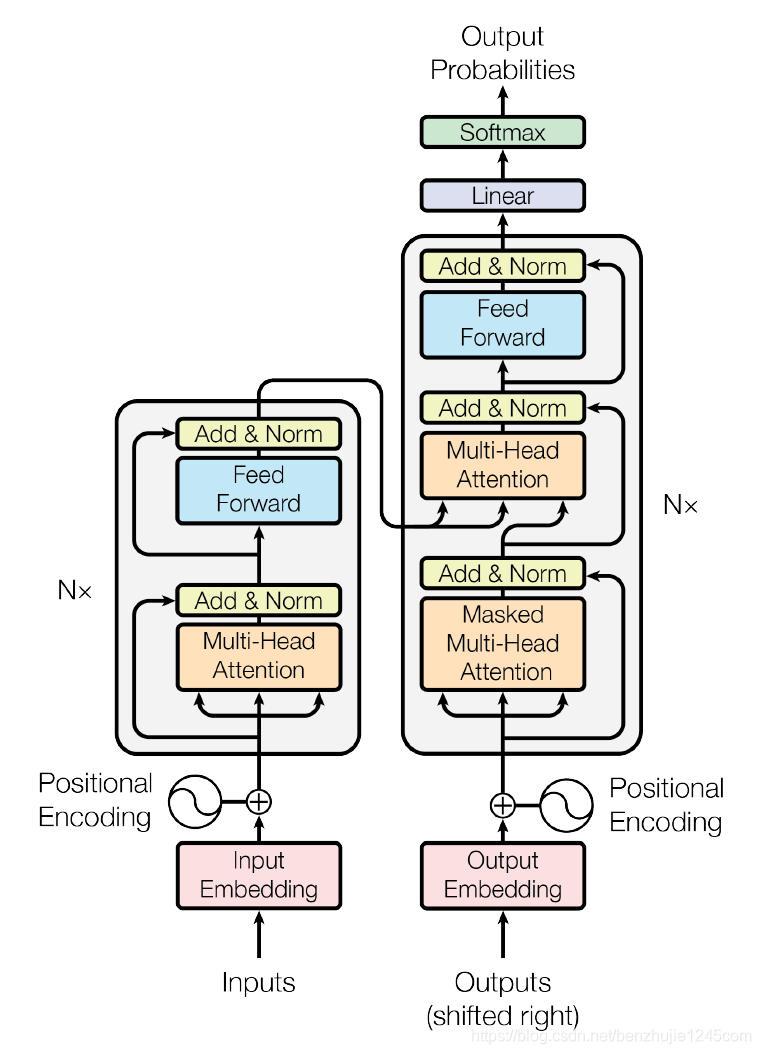
🔹 第一步:左侧 Encoder 输入层
对应图中模块 :Inputs(输入原始句子) → Input Embedding(生成词向量) → Positional Encoding(加入位置编码,并执行 ⊕(加法) )
🔹 第二步:左侧 Encoder Block(共 N=6 层,每层结构相同)
对应图中模块 :Multi-Head Attention(多头自注意力层 <下面的三个箭头说明需要3个向量q、k、v>) → Add & Norm (残差连接<侧边箭头> + 层归一化) → Feed Forward(两层全连接层 ) → Add & Norm→最终输出一个 10 × 512 的矩阵(向量Z)(我们叫它 上下文特征矩阵 )【N 层堆叠:这个 Block 会重复 N=6 次,每一层的输出都是下一层的输入。 】
🔹 第三步:右侧 Decoder 输入层
对应图中模块 :Outputs (shifted right) → Output Embedding (生成词向量) → ⊕ → Positional Encoding(位置编码)
- 输入已生成的英文词
- 翻译是自回归生成的,初始输入是
<START>标记;后续输入是已经生成的词(比如已生成Will,下一个输入就是<START> Will)。 - 图中
shifted right表示输入是 "右移一位" 的输出序列,防止模型偷看未来的词。
- 翻译是自回归生成的,初始输入是
🔹 第四步:右侧 Decoder Block(共 N=6 层,每层结构相同)
对应图中模块 :Masked Multi-Head Attention(掩码多头自注意力) → Add & Norm (残差、归一化) → Multi-Head Attention → Add & Norm (残差、归一化) → Feed Forward → Add & Norm 最后N 层堆叠( 第 1 层输出 → 第 2 层输入 → ... → 第 6 层输出 → 送入输出层。)
我们以第 1 层为例:
-
Masked Multi-Head Attention(掩码多头自注意力)
- 输入:Decoder 输入层的
3 × 512矩阵。 - 计算:和 Encoder 的多头自注意力类似,但会加入一个上三角掩码,让第 i 个词只能关注前 i-1 个词(比如生成第 3 个词时,只能看前 2 个词),防止 "偷看" 未来的词。
- 输出:
3 × 512的掩码注意力矩阵。
- 输入:Decoder 输入层的
-
Multi-Head Attention(交叉注意力)
- 输入:
- Q:来自上一步的
3 × 512归一化矩阵(Decoder 侧的输出)。 - K、V:来自 Encoder 最终输出的
10 × 512上下文特征矩阵(Encoder 侧的全局信息)。
- Q:来自上一步的
- 计算:让当前生成的英文词关注输入中文句子里的对应词(比如生成
poison时,会关注中文里的 "毒")。 - 输出:
3 × 512的交叉注意力矩阵。 - 线的含义:Encoder 最终输出 → 作为 K/V 送入该层;Decoder 上一步输出 → 作为 Q 送入该层 → 计算交叉注意力 → 输出矩阵。
- 输入:
🔹 第五步:右侧输出层
对应图中模块 :Linear(全连接) → Softmax → Output Probabilities
-
Linear 层(全连接)
- 把 Decoder 输出的 512 维向量映射到整个英文词汇表的大小(比如 3 万词)。
- 输出:
3 × 30000的矩阵(每个词对应词汇表中所有词的得分)。
-
Softmax 层
- 对每个词的得分做归一化,得到每个词的概率(0~1 之间,和为 1)。
- 输出:
3 × 30000的概率矩阵。
-
生成最终词
- 选择概率最大的词作为当前生成的输出(比如选择
Will)。 - 这个词会被送回 Decoder 输入层,重复整个流程,直到生成
<END>标记,翻译完成。 - 最终输出:完整的英文句子,比如
Will a poisonous snake be poisoned if you poison it with poison?。
- 选择概率最大的词作为当前生成的输出(比如选择
三.transformer流程详细讲解
1.正弦余弦位置编码
之前所说的最开始每个词对应的初始521维向量和512维位置编码就是:Transformer 中单词的输入表示 x 由单词 Embedding 和位置 Embedding (Positional Encoding)相加得到。
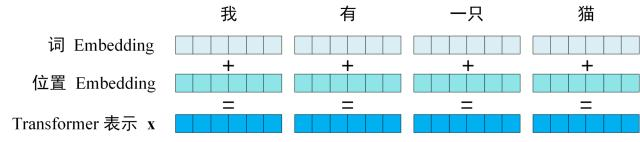
(1)单词 Embedding
单词的 Embedding 有很多种方式可以获取,例如可以采用 Word2Vec、Glove 等算法预训练得到,也可以在 Transformer 中训练得到。
(2)位置 Embedding(正弦余弦位置编码)
位置 Embedding 用 PE 表示,PE 的维度与单词 Embedding 是一样的。PE 可以通过训练得到,也可以使用某种公式计算得到。在 Transformer 中采用了后者,计算公式如下:
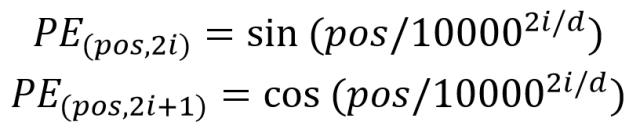
这个公式是Transformer 模型中 "位置编码(Positional Encoding,简称 PE)" 的计算方式,作用是给句子中的每个单词添加 "位置信息"------ 因为 Transformer 本身没有循环 / 卷积结构,无法自动感知单词的顺序,所以需要用这个公式生成位置向量,和词 Embedding 相加,让模型知道单词的先后顺序。
每个参数的解释
- PE(pos, 2i) / PE(pos, 2i+1) :表示 "位置为
pos的单词,在位置编码向量的第2i(偶数位)/2i+1(奇数位)维度上的取值",假设词Embedding维度是6,位置编码的维度与词Embedding维度相同,则i应该取0、1、2 ,这样2i/2i+1就涵盖了0、1、2、3、4、5这6个维度。 - pos:单词在句子中的位置序号(比如句子 "我有一只猫" 中,"我" 的 pos=0,"有" 的 pos=1,依此类推)。
- d:位置编码的维度(必须和词 Embedding 的维度相同,这样才能相加),比如常用的 d=512、d=768。
- i :维度的索引(从 0 开始),用来区分偶数 / 奇数维度,满足
2i ≤ d、2i+1 ≤ d。
举例说明(以 d=4、pos=1 为例)
++假设位置编码维度d=4++ ,要计算位置 pos=1的单词的位置编码向量:
- 当
i=0时:- 偶数维度(2i=0):
PE(1, 0) = sin(1 / 10000^(2×0/4)) = sin(1/10000^0) = sin(1) ≈ 0.8415 - 奇数维度(2i+1=1):
PE(1, 1) = cos(1 / 10000^(2×0/4)) = cos(1) ≈ 0.5403
- 偶数维度(2i=0):
- 当
i=1时:- 偶数维度(2i=2):
PE(1, 2) = sin(1 / 10000^(2×1/4)) = sin(1/10000^0.5) = sin(1/100) ≈ 0.0099998 - 奇数维度(2i+1=3):
PE(1, 3) = cos(1 / 10000^(2×1/4)) = cos(1/100) ≈ 0.99995
- 偶数维度(2i=2):
最终 pos=1 的位置编码向量是:[0.8415, 0.5403, 0.0099998, 0.99995],之后会和这个位置的词 Embedding(维度也是 4)相加,作为 Transformer 的输入。
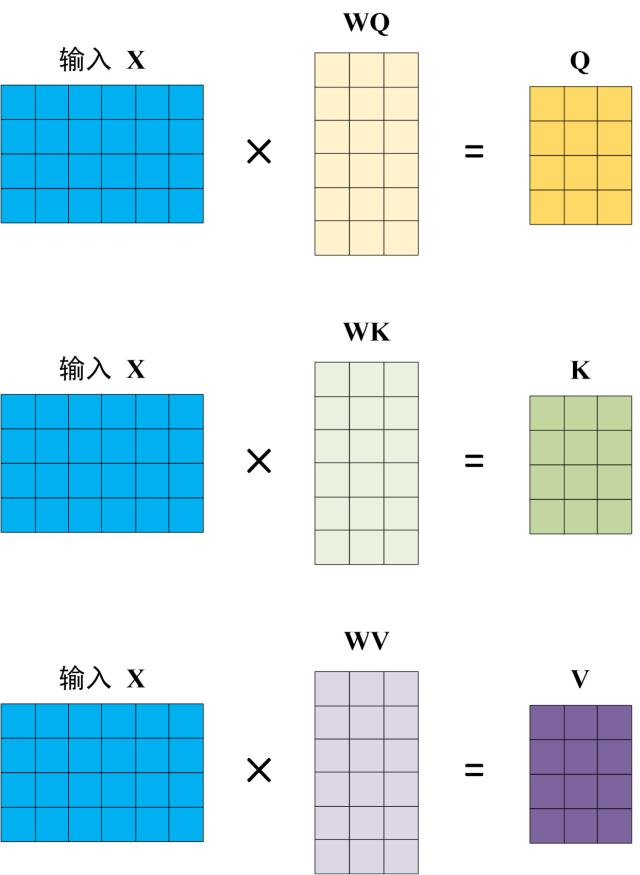
2.Q, K, V 的计算
Self-Attention 的输入用矩阵X进行表示,则可以使用线性变阵矩阵WQ,WK,WV 计算得到Q,K,V 。计算如下图所示,注意 X, Q, K, V 的每一行都表示一个单词。
3.Self-Attention 的输出
得到矩阵 Q, K, V之后就可以计算出 Self-Attention 的输出了,计算的公式如下:

Self-Attention 的输出
公式中计算矩阵Q 和K 每一行向量的内积,为了防止内积过大,因此除以的平方根。Q 乘以K 的转置后,得到的矩阵行列数都为 n,n 为句子单词数,这个矩阵可以表示单词之间的 attention 强度。下图为Q 乘以
,1234 表示的是句子中的单词。
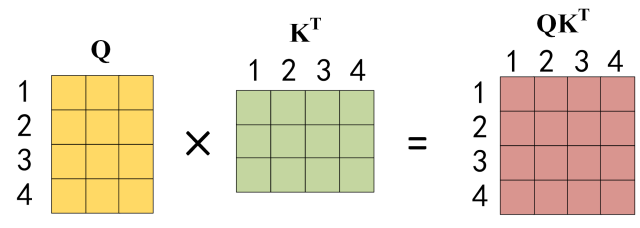
Q乘以K的转置的计算
得到之后,使用 Softmax 计算每一个单词对于其他单词的 attention 系数,++公式中的 Softmax 是对矩阵的每一行进行 Softmax,即每一行的和都变为 1++.
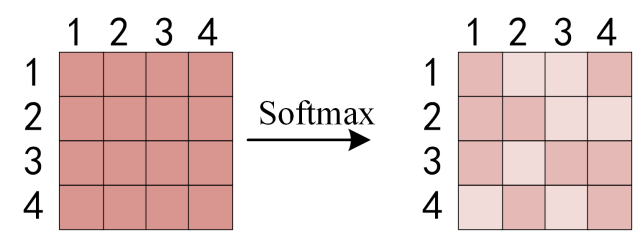
对矩阵的每一行进行 Softmax
得到 Softmax 矩阵之后可以和V( 该词实际包含的信息内容**)** 相乘,得到最终的输出Z。
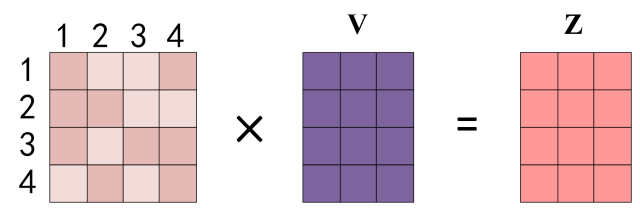
Self-Attention 输出
上图中 Softmax 矩阵的第 1 行表示单词 1 与其他所有单词的 attention 系数,最终单词 1 的输出Z1等于所有单词 i 的值 Vi 根据 attention 系数的比例加在一起得到,如下图所示:
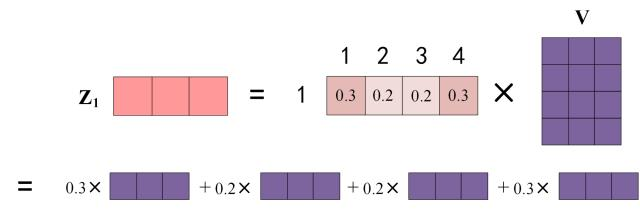
Zi 的计算方法
4.Multi-Head Attention
在上一步,我们已经知道怎么通过 Self-Attention 计算得到输出矩阵 Z,而 Multi-Head Attention 是由多个 Self-Attention 组合形成的,下图是论文中 Multi-Head Attention 的结构图。
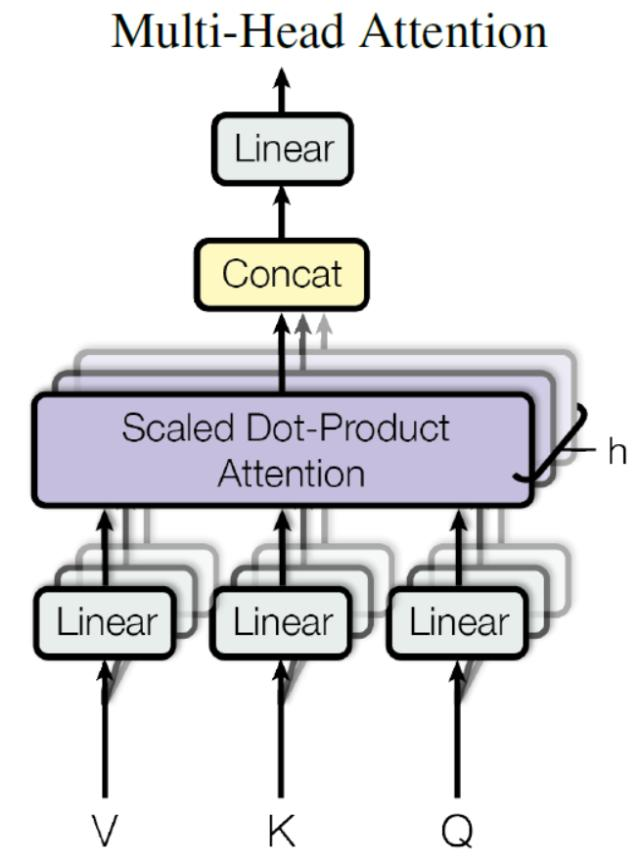
(1)输入层:Q、K、V 向量
- 最下面的三个输入分别是 Q(查询向量) 、K(键向量) 、V(值向量)。
- 它们通常来自同一个输入序列(比如 "用毒毒毒蛇毒蛇会不会被毒毒死" 处理后的词向量),经过不同的线性变换得到。
- ++每个
Linear层的作用就是把原始输入映射到适合计算注意力的维度++。
(2)拆分多头:并行计算注意力Self-Attention
- 这一步图里没有画出来,但逻辑上,++我们会把 Q、K、V 各自拆成 h 组(比如 h=8)。++
- ++每组的维度是
d_model/h(比如 512/8=64),这样就能同时跑 h 个独立的注意力计算。++ - 图里那层叠的灰色框,就代表这 h 个并行的 "缩放点积注意力"(Scaled Dot-Product Attention),++也就是自注意力计算Self-Attention++。
(3)核心计算:缩放点积注意力(++自注意力计算Self-Attention++)
- 每一组 Q、K、V 都会进入一个 Scaled Dot-Product Attention 模块。
- 它会先计算 Q 和 K 的点积得到注意力分数,再除以
防止梯度爆炸,最后通过 softmax 得到注意力权重。
- 用这个权重去加权求和 V,就得到了这一组的注意力输出。
- 因为有 h 组,所以会得到 h 个这样的输出向量。
(4)拼接输出:Concat
- 把 h 个并行计算得到的注意力输出向量 ** 拼接(Concat)** 在一起,就得到一个维度和原始输入一致的大向量(比如 8×64=512)。
(5)最终线性变换:Linear
- 拼接后的向量再经过最后一个
Linear层做一次线性变换,得到多头注意力的最终输出。 - 这一步的作用是让模型可以学习如何更好地融合这 h 组注意力的信息。
5.编码器Encoder
(1)Add & Norm 残差、归一化
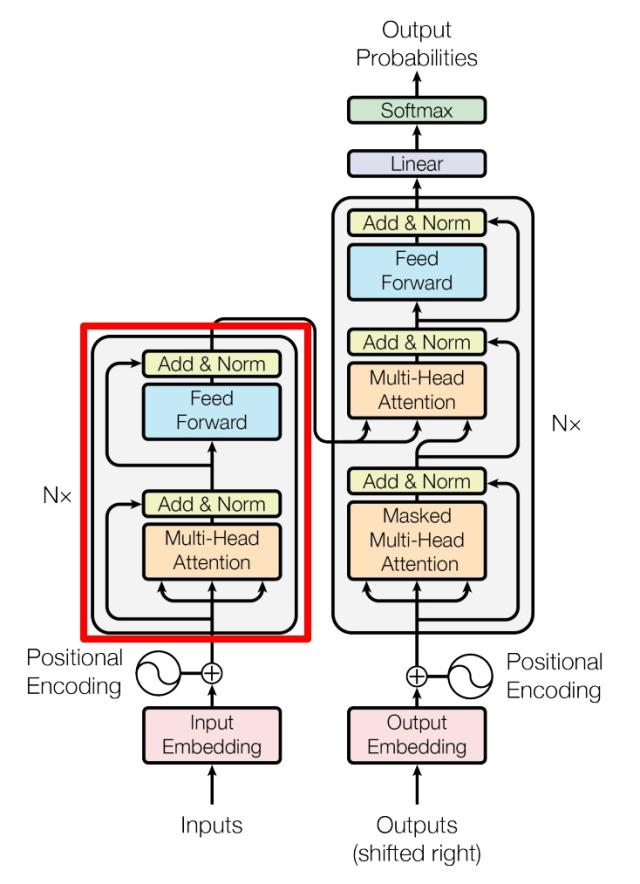
上图红色部分是 Transformer 的 Encoder block 结构,可以看到是由 Multi-Head Attention,Add & Norm, Feed Forward, Add & Norm组成的。刚刚已经了解了 Multi-Head Attention 的计算过程,现在了解一下 Add & Norm 和 Feed Forward 部分。
Add & Norm 层由 Add 和 Norm 两部分组成,其计算公式如下:

Add &amp;amp;amp;amp; Norm 公式
其中 X 表示 Multi-Head Attention 或者 Feed Forward 的输入,MultiHeadAttention(X ) 和 FeedForward(X ) 表示输出 (输出与输入 X维度是一样的,所以可以相加)。
++Add 指 X +MultiHeadAttention(X),是一种残差连接++,通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分,在 ResNet 中经常用到:

残差连接
++Norm指 Layer Normalization++ ,通常用于 RNN 结构,++Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛++。
(2)Feed Forward
++Feed Forward 层比较简单,是一个两层的全连接层,第一层的激活函数为 Relu,第二层不使用激活函数++,对应的公式如下:
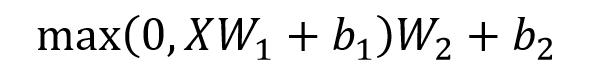
Feed Forward
X 是输入,Feed Forward 最终得到的输出矩阵的维度与X一致。
(3)组成了Encoder
通过上面描述的++Multi-Head Attention, Feed Forward, Add & Norm 就可以构造出一个 Encoder block++,Encoder block 接收输入矩阵 ,并输出一个矩阵 。通过多个 Encoder block 叠加就可以组成 Encoder。
++第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就是编码信息矩阵 C++,这一矩阵后续会用到 Decoder 中。