大模型分类
大语言模型(LLM)
这类大模型专注于自然语言处理(NLP),旨在处理语言、文章、对话等自然语言文本。它们通常基于深度学习架构(如Transformer模型)经过大规模文本数据集训练而成,能够捕捉语言的复杂性,包括语法、语义、语境以及蕴含的文化和社会知识。语言大模型典型应用包括文本生成、问答系统、文本分类、机器翻译、对话系统等。示例包括:1.GPT系列(OpenAI):如GPT-3、GPT-3.5.GPT-4等
Bard(Google):谷歌推出的大型语言模型用于提供信息丰富的、有创意的文本输出。通义千问(阿里云):阿里云自主研发的超大规模的语言模型 。
多模态模型
多模态大模型能够同时处理和理解来自不同感知通道
(如文本、图像、音频、视频等)的数据,并在这些模态之间建立关联和交互。它们能够整合不同类型的输入信息,进行跨模态推理、生成和理解任务。多模态大模型的应用涵盖视觉问答、图像描述生成、跨模态检索、
多媒体内容理解等领域。
Tokenization
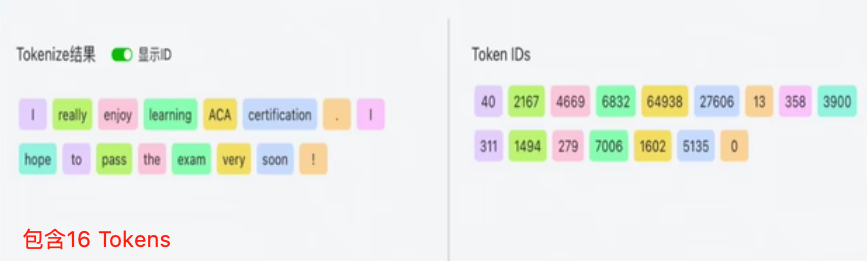
分词化(Tokenization)是自然语言处理(NLP)中的重要概念,它是将段落和句子分割成更小的分词(token)的过程。举一个实际的例子,以下是一个英文句子:
I want to study ACA.
为了让机器理解这个句子,对字符串执行分词化,将其分解为独立的单元。使用分词
化,我们会得到这样的结果:
'I' ,'want' ,'to' ,'study' ,'ACA' ,'.'
将一个句子分解成更小的、独立的部分可以帮助计算机理解句子的各个部分,以及它们在上下文中的作用,这对于进行大量上下文的分析尤其重要。分词化有不同的粒度分类:
- -词粒度(Word-Level Tokenization)分词化,如上文中例子所示,适用于大多数西方语言,如英语。
- -字符粒度(Character-Level)分词化是中文最直接的分词方法,它是以单个汉字为单位进行分词化。
- -子词粒度(Subword-Level)分词化,它将单词分解成更小的单位,比如词根、词缀等。这种方法对于处理新词(比如专有名词、网络用语等)特别有效,因为即使是新词,它的组成部分(子词)很可能已经存在于词表中了。
每一个token都会通过预先设置好的词表,映射为一个tokenid,这是token 的"身份证"一句话最终会被表示为一个元素为token id的列表,供计算机进行下一步处理。
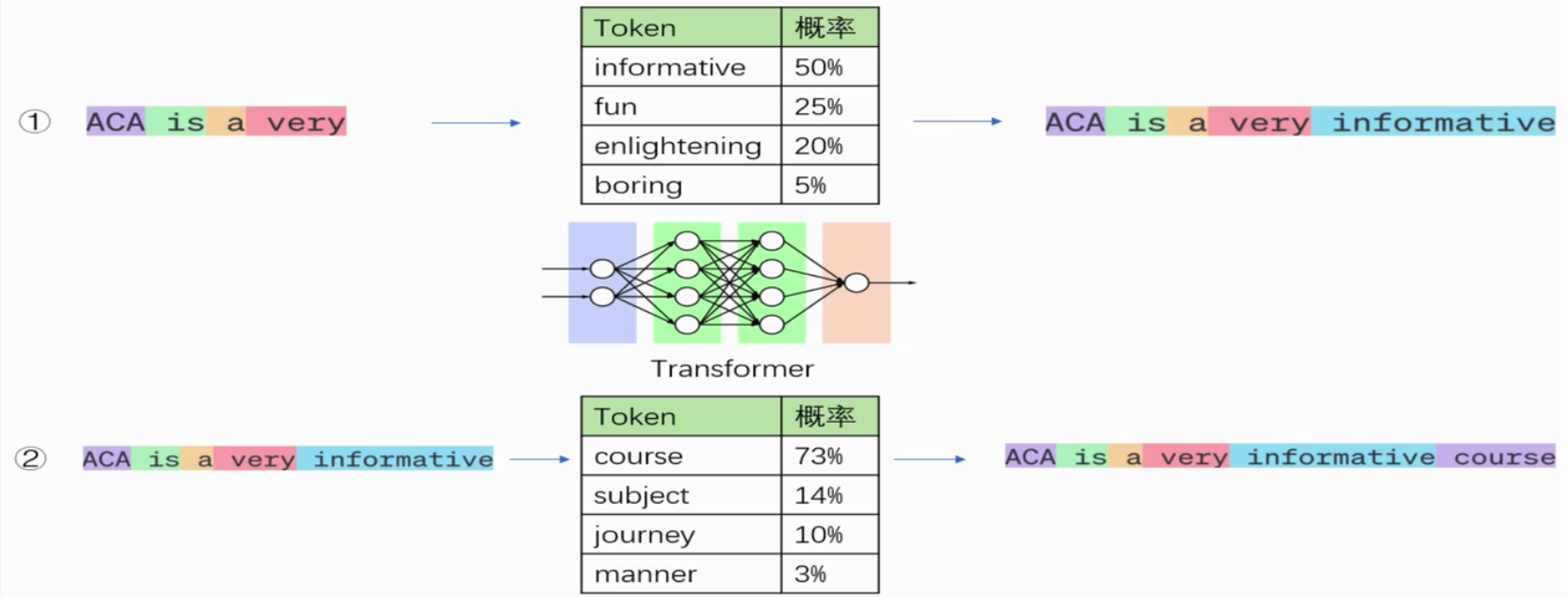
大语言模型生成文本的过程
大语言模型的工作概括来说是根据给定的文本预测下一个token。对我们来说,看似像在对大模型提问,但实际上是给了大模型一串提示文本,让它可以对后续的文本进行推理。大模型的推理过程不是一步到位的,当大模型进行推理时,它会基于现有的token,根据概率最大原则预测出下一个最有可能的token,然后将该预测的token加入到输入序列中,并将更新后的输入序列继续输入大模型预测下一个token,这个过程叫做自回归。直到输出特殊token(如<EOS>,end ofsentence,专门用来控制推理何时结束)或输出长度达到阈值。
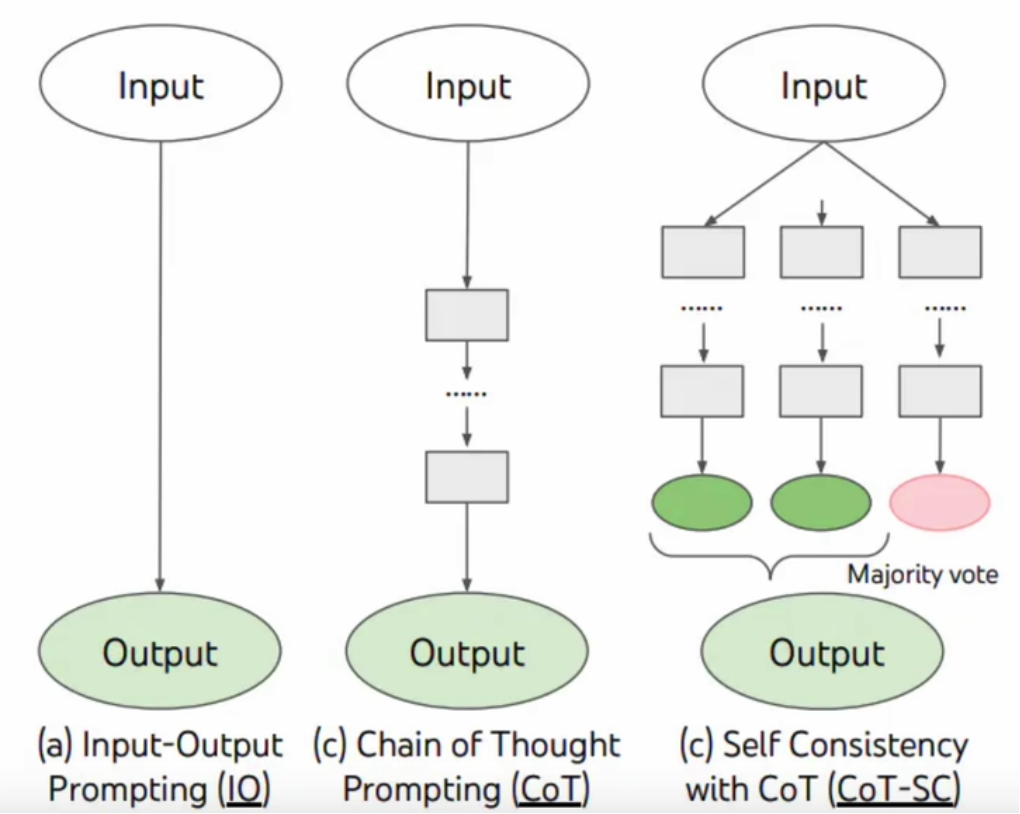
思维链(Chain of Thoughts,CoT)
思维链已经是一种比较标准的提示技术,能显著提升LLM完成复杂任务的效果。当我们对LLM这样要求「think stepbystep」,会发现LLM 会把问题分解成多个步骤,一步-
步思考和解决,能使得输出的结果更加准确。这是一种线性的思维方式。
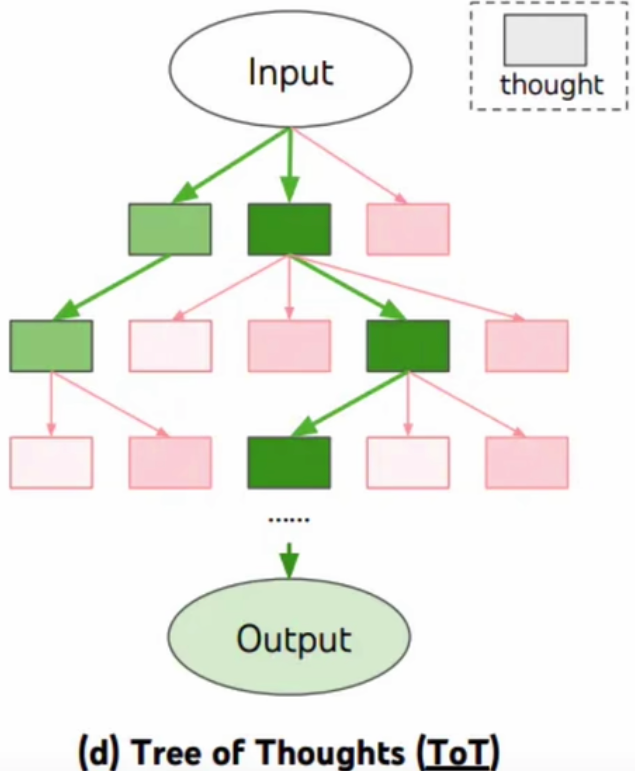
思维树(Tree of Thoughts,ToT)
对 CoT的进一步扩展,在思维链的每一步,推理出多个分支,拓扑展开成一棵思维树。使用启发式方法评估每个推理分支对问题解决的贡献。选择搜索算法,使用广度优先搜索
(BFS)或深度优先搜索(DFS等算法来探索思维树,并进行前瞻和回溯。
ReaAct
思考->行动->观察->再思考... 得到最终答案
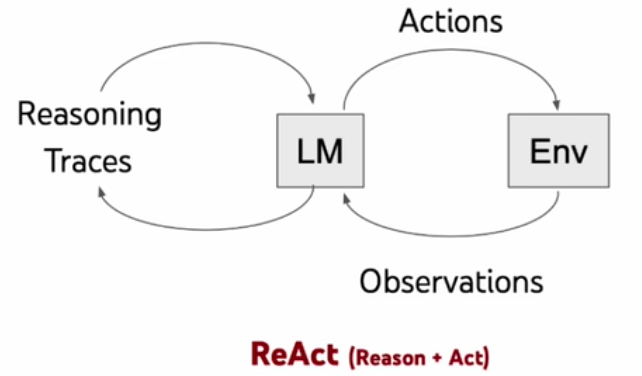
- 仅推理(Reasoning Ony):LLM仅仅基于已有的知识进行推理,生成答案回答这个问题。很显然,如果LLM 本身不具备这些知识,可能会出现幻觉,胡乱回答一通。
- 仅行动(Acting Only):大模型不加以推理,仅使用工具(比如搜索引擎)搜索这个问题,得出来的将会是海量的资料,不能直接回到这个问题,
- 推理+行动(Reasoning and Acting):LLM首先会基于已有的知识,并审视拥有的工具。当发现已有的知识不足以回答这个问题,则会调用工具,比如:搜索工具、生成报告等,然后得到新的信息,基于新的信息重复进行推理和行动,直到完成这个任务。
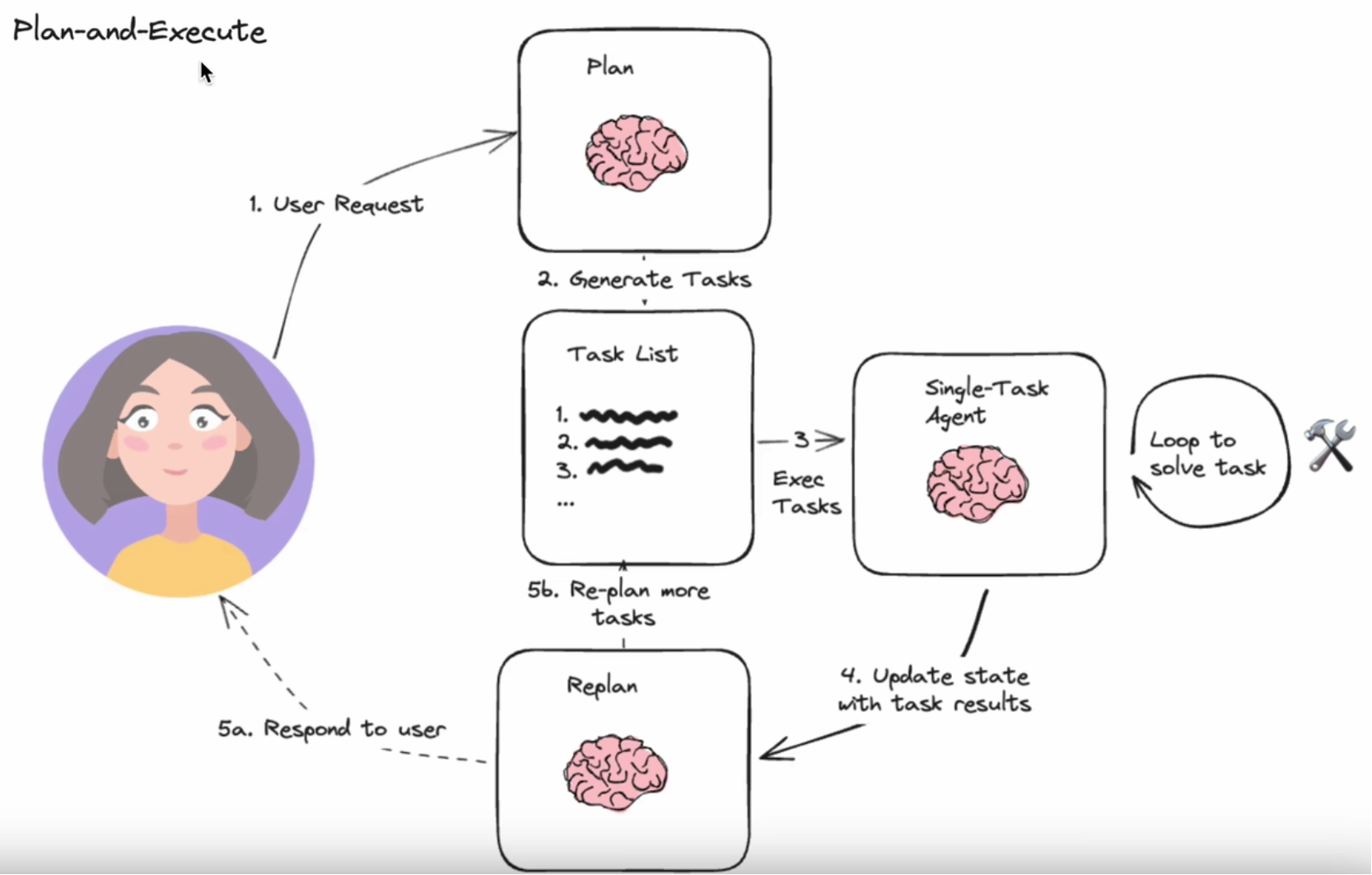
Plan-and-Execute
计划与执行(Plan-and-Execute)框架侧重于先规划一系列的行动,然后执行。这个框架可以使大模型能够先综合考虑任务的多个方面、然后按照计划进行行动。应用在比较复
杂的项目管理中或者需要多步决策的场景下会比较合适。
Self-AsK
自问自答(Self-AsK)框架这个允许大模型对自己提出问题并回答,来增强对问题的理解以提高回答质量,这个框架在需要深入分析或者提供创造性解决方案下可以比较适合,例如创意写作。
大模型训练
大模型的训练整体上分为三个阶段:
预训练、SFT(监督微调)以及RLHF(基于人类反馈的强化学习)