一、为什么需要 LLM 抽象?
1.1 大模型 API 碎片化的行业痛点
在 LangChain 出现之前,开发 LLM 应用需要面对严重的接口碎片化问题。不同厂商的大模型 API 在请求格式、参数命名、返回值结构、错误码等方面完全不兼容,导致:
- 切换模型成本极高:从 OpenAI 切换到 Claude 需要重写所有模型调用代码
- 重复造轮子:每个项目都需要重新实现重试、限流、日志、Token 统计等通用功能
- 代码可维护性差:硬编码的 API 调用散落在代码各处,难以统一升级和维护
示例:不同模型的原生 API 调用对比
python
# OpenAI原生API
from openai import OpenAI
client = OpenAI()
response = client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": "你好"}],
temperature=0.7
)
print(response.choices[0].message.content)
# 字节跳动豆包原生API
from volcenginesdkarkruntime import Ark
client = Ark()
response = client.chat.completions.create(
model="ep-20240515123456789",
messages=[{"role": "user", "content": "你好"}],
temperature=0.7
)
print(response.choices[0].message.content)
# 阿里通义千问原生API
from dashscope import Generation
response = Generation.call(
model="qwen-turbo",
messages=[{"role": "user", "content": "你好"}],
temperature=0.7
)
print(response.output.choices[0].message.content)可以看到,三个模型的 API 看起来相似,但在客户端初始化、模型名称、返回值结构等方面存在细微差异,这些差异会随着模型数量的增加被无限放大。
1.2 LangChain 的解决方案:统一抽象层
LangChain 通过BaseChatModel基类定义了所有聊天模型的统一接口,将不同厂商的 API 差异封装在底层,为上层应用提供了完全一致的编程体验。
LangChain LLM 抽象架构图:
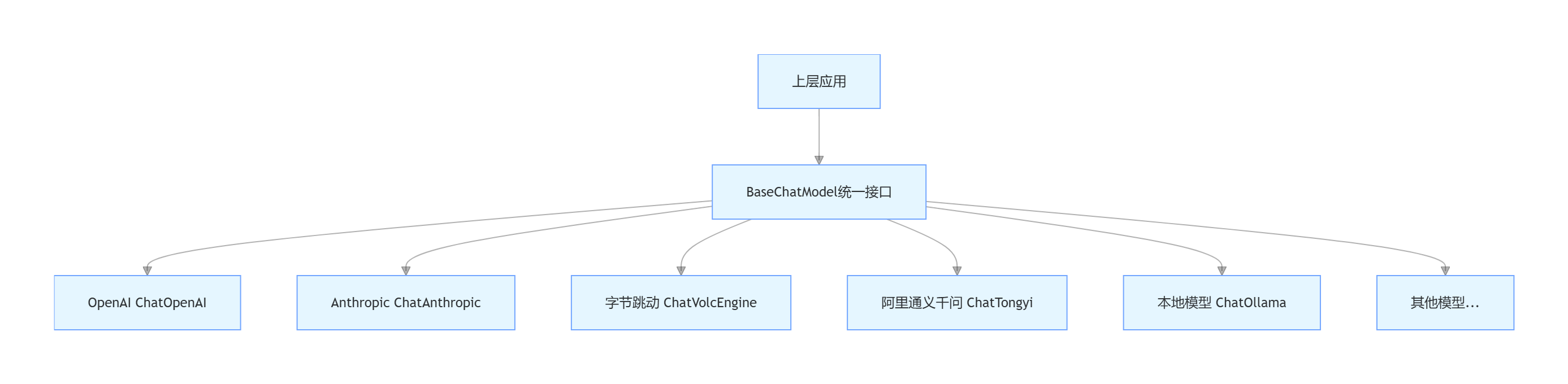
这种设计带来了三大核心优势:
- 模型无关性:上层应用代码不依赖任何特定模型,切换模型只需要修改一行配置
- 功能复用:重试、限流、日志、监控等通用功能可以在抽象层统一实现
- 可扩展性 :新增模型只需要实现
BaseChatModel接口,上层应用无需任何修改
1.3 四种调用模式的适用场景
LangChain 的BaseChatModel支持四种调用模式,分别适用于不同的业务场景:
| 调用模式 | 方法 | 适用场景 | 特点 |
|---|---|---|---|
| 同步调用 | invoke() |
简单请求、低并发场景 | 代码简单,阻塞等待结果 |
| 异步调用 | ainvoke() |
高并发服务、批量处理 | 非阻塞,支持高并发 |
| 流式输出 | stream() |
聊天机器人、实时交互 | 逐令牌返回结果,提升用户体验 |
| 批量调用 | batch() |
批量处理大量请求 | 合并请求,提高吞吐量 |
二、核心 API 详解
2.1 BaseChatModel 基类
BaseChatModel是所有聊天模型的抽象基类,定义了所有模型必须实现的核心方法和属性。它继承自Runnable,因此天然支持 LCEL 表达式语言,可以与其他 Runnable 组件无缝组合。
BaseChatModel 核心方法:
python
from langchain_core.language_models import BaseChatModel
from langchain_core.messages import BaseMessage, AIMessage
from typing import List, Optional
class BaseChatModel:
def invoke(
self,
input: List[BaseMessage] | str,
config: Optional[RunnableConfig] = None
) -> AIMessage:
"""同步调用模型,返回完整的AI消息"""
pass
async def ainvoke(
self,
input: List[BaseMessage] | str,
config: Optional[RunnableConfig] = None
) -> AIMessage:
"""异步调用模型"""
pass
def stream(
self,
input: List[BaseMessage] | str,
config: Optional[RunnableConfig] = None
) -> Iterator[AIMessageChunk]:
"""流式调用模型,返回消息块迭代器"""
pass
async def astream(
self,
input: List[BaseMessage] | str,
config: Optional[RunnableConfig] = None
) -> AsyncIterator[AIMessageChunk]:
"""异步流式调用模型"""
pass
def batch(
self,
inputs: List[List[BaseMessage] | str],
config: Optional[RunnableConfig] = None
) -> List[AIMessage]:
"""批量调用模型"""
pass2.2 消息类型系统
LangChain 定义了一套标准化的消息类型系统,用于表示对话中的不同角色和内容。所有消息都继承自BaseMessage基类。
核心消息类型:
| 消息类型 | 角色 | 用途 |
|---|---|---|
HumanMessage |
用户 | 表示用户发送的消息 |
AIMessage |
AI 助手 | 表示 AI 生成的回复消息 |
SystemMessage |
系统 | 表示系统提示词,用于设定 AI 的角色和行为 |
ToolMessage |
工具 | 表示工具调用的返回结果 |
FunctionMessage |
函数 | 旧版函数调用消息,已被ToolMessage替代 |
消息内容块(ContentBlock) : LangChain 1.2 + 支持多模态内容,消息的content字段可以是字符串或内容块列表。内容块可以是文本、图像、音频、视频等多种类型。
python
from langchain_core.messages import HumanMessage
# 纯文本消息
text_message = HumanMessage(content="你好,LangChain!")
# 多模态消息(文本+图像)
multimodal_message = HumanMessage(content=[
{"type": "text", "text": "这张图片里有什么?"},
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
}
])2.3 主流大模型集成
LangChain 通过官方 Partner 包提供了对主流大模型的支持,所有模型都实现了BaseChatModel接口,使用方式完全一致。
2.3.1 OpenAI GPT 系列(官方推荐)
OpenAI 是 LangChain 生态支持最完善的模型,也是开发和测试的首选。
安装依赖:
python
poetry add langchain-openai==0.2.2
python
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage, SystemMessage
# 初始化模型
llm = ChatOpenAI(
model="gpt-4o-mini-2024-07-18", # 推荐使用带版本号的模型名称
temperature=0,
max_tokens=1024,
timeout=30,
max_retries=2
)
# 调用模型
messages = [
SystemMessage(content="你是一个专业的Python开发助手"),
HumanMessage(content="什么是装饰器?")
]
response = llm.invoke(messages)
print(response.content)2.3.2 字节跳动豆包 4.0(国内首选)
字节跳动豆包是国内性能和效果最好的大模型之一,LangChain 通过langchain-volcengine包提供支持。
安装依赖:
bash
poetry add langchain-volcengine==0.1.3
python
from langchain_volcengine import ChatVolcEngine
from langchain_core.messages import HumanMessage
# 初始化模型
# 需要在.env中配置VOLC_ACCESSKEY和VOLC_SECRETKEY
llm = ChatVolcEngine(
model="ep-20240515123456789", # 替换为你的模型端点ID
temperature=0,
max_tokens=1024
)
# 调用方式与OpenAI完全一致
response = llm.invoke([HumanMessage(content="什么是装饰器?")])
print(response.content)2.3.3 阿里通义千问 3.5
阿里通义千问是国内另一个主流大模型,LangChain 通过langchain-dashscope包提供支持。
安装依赖:
python
poetry add langchain-dashscope==0.1.6
python
from langchain_dashscope import ChatTongyi
from langchain_core.messages import HumanMessage
# 初始化模型
# 需要在.env中配置DASHSCOPE_API_KEY
llm = ChatTongyi(
model="qwen-turbo",
temperature=0,
max_tokens=1024
)
# 调用方式完全一致
response = llm.invoke([HumanMessage(content="什么是装饰器?")])
print(response.content)2.3.4 本地模型集成(Ollama)
对于需要本地部署的场景,Ollama 是最简单的本地大模型运行工具,LangChain 通过langchain-ollama包提供支持。
安装 Ollama:
- 访问Ollama 官网下载并安装
- 运行
ollama pull qwen:7b下载 Qwen 2.5 7B 模型
安装依赖:
python
poetry add langchain-ollama==0.2.0
python
from langchain_ollama import ChatOllama
from langchain_core.messages import HumanMessage
# 初始化本地模型
llm = ChatOllama(
model="qwen:7b",
temperature=0,
max_tokens=1024
)
# 调用方式完全一致
response = llm.invoke([HumanMessage(content="什么是装饰器?")])
print(response.content)关键结论:所有模型的调用方式完全相同,切换模型只需要修改初始化代码,上层业务逻辑无需任何改动。
2.4 模型参数深度解析
LangChain 的BaseChatModel支持一系列通用参数,用于控制模型的输出行为。理解这些参数的作用是优化 LLM 应用效果的关键。
| 参数 | 作用 | 取值范围 | 推荐值 | 场景说明 |
|---|---|---|---|---|
temperature |
控制输出的随机性 | 0-2 | 0(事实性任务)、0.7(创意性任务) | 值越高,输出越随机、越有创意;值越低,输出越确定、越一致 |
max_tokens |
限制模型生成的最大令牌数 | 1 - 模型上下文窗口 | 1024-4096 | 防止生成过长的回复,控制成本 |
top_p |
核采样参数,控制词汇选择范围 | 0-1 | 0.9 | 值越小,输出越集中在高概率词汇上;值越大,输出越多样 |
frequency_penalty |
频率惩罚,减少重复内容 | -2.0-2.0 | 0.0-1.0 | 值越高,越不容易出现重复的短语 |
presence_penalty |
存在惩罚,鼓励生成新主题 | -2.0-2.0 | 0.0-1.0 | 值越高,越容易引入新的话题 |
timeout |
请求超时时间(秒) | 正数 | 30-60 | 防止请求长时间阻塞 |
max_retries |
最大重试次数 | 非负整数 | 2-3 | 自动重试失败的请求 |
参数调优最佳实践:
- 事实性任务 (问答、摘要、代码生成):
temperature=0,保证输出的准确性和一致性 - 创意性任务 (写作、头脑风暴、文案生成):
temperature=0.7-1.0,增加输出的多样性 - 永远不要使用
temperature=2:会导致输出完全混乱,没有任何意义 top_p和temperature不要同时调整,通常只调整其中一个即可
三、工业级最佳实践
简单的模型调用只能用于原型开发,要达到生产环境的要求,必须实现重试、降级、限流、监控等一系列工业级特性。
3.1 模型工厂模式
模型工厂模式是管理多个模型的最佳实践,它将模型的初始化逻辑封装在工厂类中,上层应用通过配置获取模型实例,实现了配置与代码的分离。
工业级模型工厂实现:
python
from typing import Dict, Optional
from pydantic import BaseModel, Field
from langchain_core.language_models import BaseChatModel
from langchain_openai import ChatOpenAI
from langchain_ollama import ChatOllama
class ModelConfig(BaseModel):
"""模型配置类"""
provider: str = Field(description="模型提供商:openai/ollama")
model_name: str = Field(description="模型名称")
temperature: float = Field(default=0.0)
max_tokens: int = Field(default=1024)
timeout: int = Field(default=30)
max_retries: int = Field(default=2)
class ModelFactory:
"""模型工厂类"""
_instances: Dict[str, BaseChatModel] = {}
@classmethod
def get_model(cls, config: ModelConfig) -> BaseChatModel:
"""获取模型实例(单例)"""
instance_key = f"{config.provider}:{config.model_name}:{config.temperature}"
if instance_key not in cls._instances:
if config.provider == "openai":
model = ChatOpenAI(
model=config.model_name,
temperature=config.temperature,
max_tokens=config.max_tokens,
timeout=config.timeout,
max_retries=config.max_retries
)
elif config.provider == "ollama":
model = ChatOllama(
model=config.model_name,
temperature=config.temperature,
max_tokens=config.max_tokens,
timeout=config.timeout
)
else:
raise ValueError(f"不支持的提供商:{config.provider}")
cls._instances[instance_key] = model
return cls._instances[instance_key]
# 使用示例
config = ModelConfig(
provider="openai",
model_name="gpt-4o-mini",
temperature=0
)
llm = ModelFactory.get_model(config)
print(llm.invoke("你好"))3.2 重试机制:指数退避 + 抖动
使用 LangChain 内置的ModelRetryMiddleware实现工业级重试策略,解决 API 不稳定问题。
通用实现:
python
from langchain_core.middleware import ModelRetryMiddleware
from tenacity import stop_after_attempt, wait_exponential_jitter
# 创建重试中间件
retry_middleware = ModelRetryMiddleware(
stop=stop_after_attempt(3), # 最多重试3次
wait=wait_exponential_jitter(
multiplier=1, # 初始等待1秒
min=1, # 最小等待1秒
max=10 # 最大等待10秒
),
# 只重试可恢复的异常
retry_exceptions=(
TimeoutError,
ConnectionError,
openai.RateLimitError,
openai.APIError,
openai.APIConnectionError
)
)
# 应用到模型
llm_with_retry = llm.with_middleware(retry_middleware)3.3 自动降级策略
当主模型不可用时,自动切换到备用模型,保证服务可用性。
通用实现:
python
# 主模型:GPT-4o-mini
primary_llm = ChatOpenAI(model="gpt-4o-mini", temperature=0)
# 备用模型:本地Qwen 7B
fallback_llm = ChatOllama(model="qwen:7b", temperature=0)
# 组合模型:主模型失败时自动切换到备用
robust_llm = primary_llm.with_fallbacks([fallback_llm])3.4 Token 统计与成本控制
使用CostTrackingMiddleware自动统计 Token 使用量和成本。
通用实现:
python
from langchain_core.middleware import CostTrackingMiddleware
cost_tracker = CostTrackingMiddleware()
llm_with_cost = llm.with_middleware(cost_tracker)
# 调用模型
response = llm_with_cost.invoke("统计Token使用量")
# 获取统计结果
print(f"总Token数:{cost_tracker.total_tokens}")
print(f"输入Token:{cost_tracker.prompt_tokens}")
print(f"输出Token:{cost_tracker.completion_tokens}")
print(f"总成本:${cost_tracker.total_cost:.6f}")四、新建项目
现有 RAG 项目在整合过程中,发现遇到依赖版本问题,无法使用langchain1.x以上版本,所以决定重新创建新工程。
4.1 项目初始化
# 创建项目目录
mkdir langchain-2026 && cd langchain-2026
# 创建虚拟环境(必须,隔离系统Python)
python -m venv .venv
# 激活虚拟环境
# Windows PowerShell
.venv\Scripts\Activate.ps14.2 项目标准结构
html
langchain-2026-framework/
├── .env # 环境变量(敏感信息)
├── .gitignore # Git忽略文件
├── requirements.txt # 依赖清单
├── main.py # 项目入口
├── config/ # 配置管理
│ ├── __init__.py
│ └── settings.py # 全局配置
├── core/ # 核心业务层
│ ├── __init__.py
│ ├── llm_factory.py # 模型工厂(核心)
│ ├── rag.py # RAG模块(后续扩展)
│ └── agent.py # Agent模块(后续扩展)
├── utils/ # 通用工具
│ ├── __init__.py
│ ├── logger.py # 日志系统
│ └── exceptions.py # 自定义异常
└── tests/ # 单元测试
└── test_llm.py # LLM模块测试4.3 依赖安装(2026 年 5 月最新稳定版)
创建requirements.txt,写入以下内容(无需指定版本,自动安装最新兼容版,不要用中文):
html
# LangChain核心生态(2026年5月最新稳定版)
langchain
langchain-core
langchain-openai
langchain-ollama
langgraph
langsmith
# 工具依赖
python-dotenv
pydantic-settings
tenacity
aiohttp
# 开发依赖
pytest
black
isort安装依赖:
bash
pip install -r requirements.txt -i https://mirrors.aliyun.com/pypi/simple4.4 配置管理 config/settings.py
python
from pydantic_settings import BaseSettings, SettingsConfigDict
from pydantic import Field
from pathlib import Path
class Settings(BaseSettings):
model_config = SettingsConfigDict(
env_file=".env",
env_file_encoding="utf-8",
case_sensitive=False,
extra="ignore"
)
# 项目基础配置
app_name: str = Field(default="LangChain 2026开发框架", description="应用名称")
debug: bool = Field(default=True, description="调试模式")
# 大模型API配置
doubao_api_key: str = Field(default="", description="豆包API密钥")
doubao_base_url: str = Field(default="https://ark.cn-beijing.volces.com/api/v3", description="豆包API地址")
openai_api_key: str = Field(default="", description="OpenAI API密钥")
# 默认模型配置
default_provider: str = Field(default="doubao", description="默认模型提供商")
default_model: str = Field(default="doubao-seed-2-0-code-xxxx", description="默认模型名称")
llm_temperature: float = Field(default=0.1, description="温度参数")
llm_max_tokens: int = Field(default=1024, description="最大生成长度")
llm_timeout: int = Field(default=60, description="超时时间(秒)")
llm_max_retries: int = Field(default=3, description="最大重试次数")
# LangSmith可观测性配置
langchain_tracing_v2: bool = Field(default=False, description="是否开启LangSmith追踪")
langchain_api_key: str = Field(default="", description="LangSmith API密钥")
langchain_project: str = Field(default="langchain-2026-framework", description="LangSmith项目名称")
# 日志配置
log_level: str = Field(default="INFO", description="日志级别")
log_dir: Path = Field(default=Path("./logs"), description="日志目录")
# 全局单例
settings = Settings()4.5 日志系统 utils/logger.py
python
import logging
from logging.handlers import RotatingFileHandler
from pathlib import Path
from config.settings import settings
def setup_logger():
"""配置全局日志系统"""
# 创建日志目录
settings.log_dir.mkdir(exist_ok=True)
# 获取根日志器
logger = logging.getLogger()
logger.setLevel(settings.log_level)
logger.handlers.clear()
# 日志格式
formatter = logging.Formatter(
"%(asctime)s - %(name)s - %(levelname)s - %(filename)s:%(lineno)d - %(message)s",
datefmt="%Y-%m-%d %H:%M:%S"
)
# 控制台处理器
console_handler = logging.StreamHandler()
console_handler.setFormatter(formatter)
console_handler.setLevel(logging.INFO)
# 文件处理器
file_handler = RotatingFileHandler(
filename=settings.log_dir / "app.log",
maxBytes=10*1024*1024,
backupCount=5,
encoding="utf-8"
)
file_handler.setFormatter(formatter)
file_handler.setLevel(logging.DEBUG)
# 添加处理器
logger.addHandler(console_handler)
logger.addHandler(file_handler)
# 第三方库日志级别
logging.getLogger("httpx").setLevel(logging.WARNING)
logging.getLogger("openai").setLevel(logging.WARNING)
logging.getLogger("langchain").setLevel(logging.INFO)
logger.info("✅ 日志系统初始化完成")
return logger
# 全局日志器
logger = setup_logger()4.6 自定义异常 utils/exceptions.py
python
from utils.logger import logger
class FrameworkBaseException(Exception):
"""框架基础异常类"""
def __init__(self, message: str, error_code: int = 1000):
self.message = message
self.error_code = error_code
super().__init__(self.message)
logger.error(f"[{self.error_code}] {self.message}")
class ModelLoadError(FrameworkBaseException):
"""模型加载失败异常"""
def __init__(self, model_name: str, details: str = ""):
message = f"模型加载失败:{model_name}"
if details:
message += f",详细信息:{details}"
super().__init__(message, error_code=1001)
class GenerationError(FrameworkBaseException):
"""生成失败异常"""
def __init__(self, details: str = ""):
message = "回答生成失败"
if details:
message += f",详细信息:{details}"
super().__init__(message, error_code=1002)4.7 核心模型工厂 core/llm_factory.py
python
from typing import Dict, Optional, Iterator, AsyncIterator
from langchain_core.language_models import BaseChatModel
from langchain_openai import ChatOpenAI
from langchain_ollama import ChatOllama
from langchain_core.runnables import RunnableRetry
from tenacity import stop_after_attempt, wait_exponential_jitter
from langchain_core.messages import BaseMessage, HumanMessage, SystemMessage
from config.settings import settings
from utils.logger import logger
from utils.exceptions import ModelLoadError, GenerationError
class LLMFactory:
"""
大模型工厂类(2026最新版)
支持:豆包、OpenAI、本地Ollama模型
内置:重试、降级、Token统计、流式输出
"""
_instances: Dict[str, BaseChatModel] = {}
@classmethod
def get_llm(
cls,
provider: str = None,
model_name: str = None,
temperature: float = None,
max_tokens: int = None
) -> BaseChatModel:
"""
获取模型实例(单例模式)
:param provider: 模型提供商:doubao/openai/ollama
:param model_name: 模型名称
:param temperature: 温度参数
:param max_tokens: 最大生成长度
:return: LangChain ChatModel实例
"""
# 使用默认配置
provider = provider or settings.default_provider
model_name = model_name or settings.default_model
temperature = temperature if temperature is not None else settings.llm_temperature
max_tokens = max_tokens or settings.llm_max_tokens
# 生成唯一实例键
instance_key = f"{provider}:{model_name}:{temperature}:{max_tokens}"
if instance_key not in cls._instances:
try:
# 创建基础模型
base_llm = cls._create_base_llm(provider, model_name, temperature, max_tokens)
# 添加重试机制(LangChain 2026标准写法)
llm_with_retry = base_llm.with_retry(
retry_if_exception_type=(TimeoutError, ConnectionError, Exception),
wait_exponential_jitter=True,
stop_after_attempt=settings.llm_max_retries,
exponential_jitter_params={"initial": 1, "max": 10}
)
cls._instances[instance_key] = llm_with_retry
logger.info(f"✅ 模型初始化成功:{provider} {model_name}")
except Exception as e:
raise ModelLoadError(f"{provider} {model_name}", str(e)) from e
return cls._instances[instance_key]
@classmethod
def _create_base_llm(
cls,
provider: str,
model_name: str,
temperature: float,
max_tokens: int
) -> BaseChatModel:
"""创建基础模型实例"""
if provider == "doubao":
# 豆包API完全兼容OpenAI格式
return ChatOpenAI(
api_key=settings.doubao_api_key,
base_url=settings.doubao_base_url,
model=model_name,
temperature=temperature,
max_tokens=max_tokens,
timeout=settings.llm_timeout
)
elif provider == "openai":
return ChatOpenAI(
api_key=settings.openai_api_key,
model=model_name,
temperature=temperature,
max_tokens=max_tokens,
timeout=settings.llm_timeout
)
elif provider == "ollama":
return ChatOllama(
model=model_name,
temperature=temperature,
max_tokens=max_tokens,
timeout=settings.llm_timeout * 2
)
else:
raise ValueError(f"不支持的模型提供商:{provider}")
@classmethod
def generate(
cls,
prompt: str | list[BaseMessage],
provider: str = None,
model_name: str = None,
temperature: float = None,
max_tokens: int = None
) -> str:
"""
同步生成文本
:param prompt: 提示词(字符串或消息列表)
:return: 生成的文本
"""
try:
llm = cls.get_llm(provider, model_name, temperature, max_tokens)
# 处理字符串输入
if isinstance(prompt, str):
messages = [HumanMessage(content=prompt)]
else:
messages = prompt
response = llm.invoke(messages)
# 统计Token使用量
if response.usage_metadata:
logger.debug(
f"Token统计 | 总:{response.usage_metadata['total_tokens']} | "
f"输入:{response.usage_metadata['input_tokens']} | "
f"输出:{response.usage_metadata['output_tokens']}"
)
return response.content.strip()
except Exception as e:
raise GenerationError(str(e)) from e
@classmethod
def stream_generate(
cls,
prompt: str | list[BaseMessage],
provider: str = None,
model_name: str = None,
temperature: float = None,
max_tokens: int = None
) -> Iterator[str]:
"""流式生成文本"""
try:
llm = cls.get_llm(provider, model_name, temperature, max_tokens)
if isinstance(prompt, str):
messages = [HumanMessage(content=prompt)]
else:
messages = prompt
for chunk in llm.stream(messages):
if chunk.content:
yield chunk.content
except Exception as e:
logger.error(f"流式生成失败:{str(e)}")
yield "抱歉,生成回答时发生错误,请稍后重试。"
@classmethod
async def astream_generate(
cls,
prompt: str | list[BaseMessage],
provider: str = None,
model_name: str = None,
temperature: float = None,
max_tokens: int = None
) -> AsyncIterator[str]:
"""异步流式生成文本"""
try:
llm = cls.get_llm(provider, model_name, temperature, max_tokens)
if isinstance(prompt, str):
messages = [HumanMessage(content=prompt)]
else:
messages = prompt
async for chunk in llm.astream(messages):
if chunk.content:
yield chunk.content
except Exception as e:
logger.error(f"异步流式生成失败:{str(e)}")
yield "抱歉,生成回答时发生错误,请稍后重试。"4.8 环境变量配置 .env
html
# 豆包API(推荐,中文效果好)
DOUBAO_API_KEY=你的豆包API密钥
DOUBAO_BASE_URL=https://ark.cn-beijing.volces.com/api/v3
# OpenAI API(可选)
# OPENAI_API_KEY=你的OpenAI API密钥
# LangSmith可观测性(可选,调试用)
# LANGCHAIN_TRACING_V2=true
# LANGCHAIN_API_KEY=你的LangSmith API密钥
# LANGCHAIN_PROJECT=langchain-2026-framework
# 调试模式
DEBUG=true4.9 项目入口与验证 main.py
python
from dotenv import load_dotenv
load_dotenv() # 必须在导入其他模块之前加载环境变量
from core.llm_factory import LLMFactory
from langchain_core.messages import SystemMessage, HumanMessage
import asyncio
def test_basic_generate():
"""测试基础生成功能"""
print("=== 测试基础生成功能 ===")
response = LLMFactory.generate("用3句话解释什么是大语言模型")
print(f"回答:{response}\n")
def test_stream_generate():
"""测试流式生成功能"""
print("=== 测试流式生成功能 ===")
print("回答:", end="", flush=True)
for chunk in LLMFactory.stream_generate("写一首关于夏天的七言绝句"):
print(chunk, end="", flush=True)
print("\n")
def test_system_prompt():
"""测试系统提示词"""
print("=== 测试系统提示词 ===")
messages = [
SystemMessage(content="你是一个专业的Python开发助手,只回答Python相关问题"),
HumanMessage(content="什么是装饰器?")
]
response = LLMFactory.generate(messages)
print(f"回答:{response}\n")
@pytest.mark.asyncio
async def test_astream_generate():
"""测试异步流式生成"""
print("=== 测试异步流式生成 ===")
print("回答:", end="", flush=True)
async for chunk in LLMFactory.astream_generate("什么是异步编程?"):
print(chunk, end="", flush=True)
print("\n")
if __name__ == "__main__":
print("🚀 LangChain 2026开发框架启动\n")
# 运行所有测试
test_basic_generate()
test_stream_generate()
test_system_prompt()
# 运行异步测试
asyncio.run(test_astream_generate())
print("🎉 所有测试通过!框架搭建完成")4.10 测试
