文章目录
- 一、本专栏学习目标
- 二、深度学习是什么
- 三、神经网络的输入输出常见数据形式
-
- [1. 输入分类](#1. 输入分类)
- [2. 输出分类](#2. 输出分类)
- 3.实战判断:输入输出形式对应练习
- 四、如何开始深度学习
-
- 1.只需三步
- [2. 步骤详解:从"找函数"到"优化模型"](#2. 步骤详解:从“找函数”到“优化模型”)
-
- 第一步:定义一个函数(模型)
- [第二步:定义损失函数(Loss Function)](#第二步:定义损失函数(Loss Function))
- 第三步:优化模型(Optimization)
-
- [1. 梯度(Gradient)](#1. 梯度(Gradient))
- [2. 超参数(Hyperparameter)](#2. 超参数(Hyperparameter))
- [3. 梯度下降的具体步骤](#3. 梯度下降的具体步骤)
- 总结
- 五、从单神经元到复杂神经网络:张量视角的参数运算
-
- [1. 回顾:单神经元的标量运算](#1. 回顾:单神经元的标量运算)
- [2. 第一步过渡:多特征输入 → 向量与矩阵运算](#2. 第一步过渡:多特征输入 → 向量与矩阵运算)
-
- [2.1 单神经元的向量运算](#2.1 单神经元的向量运算)
- [2.2 多样本并行 → 矩阵运算](#2.2 多样本并行 → 矩阵运算)
- [3. 核心升级:复杂数据与张量运算(适配CNN核心输入)](#3. 核心升级:复杂数据与张量运算(适配CNN核心输入))
-
- [3.1 张量的维度定义与核心匹配规则](#3.1 张量的维度定义与核心匹配规则)
- [3.2 张量的核心运算法则(以卷积运算为例)](#3.2 张量的核心运算法则(以卷积运算为例))
- [3.3 张量运算的本质:多层神经网络的堆叠基础](#3.3 张量运算的本质:多层神经网络的堆叠基础)
- 总结:从"黑盒子"到可理解的深度学习
一、本专栏学习目标
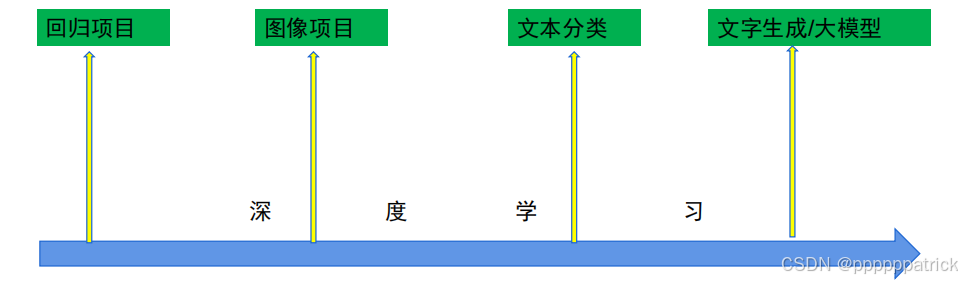
同时这也是最经典的深度学习路线。
二、深度学习是什么
深度学习是人工智能的核心分支,本质是"让计算机像人一样学会'学习'"------不用手动编写复杂规则,而是通过模拟人类大脑的神经网络结构,让计算机从海量数据中自动捕捉规律、提炼特征,最终实现"识别、判断、预测"等功能。比如我们常见的图像识别、语音翻译,背后核心都是深度学习在发挥作用。对于入门者来说,不用纠结复杂的底层数学推导,先从核心概念、基础操作入手,就能逐步理解其原理,这也是本专栏的核心初衷。
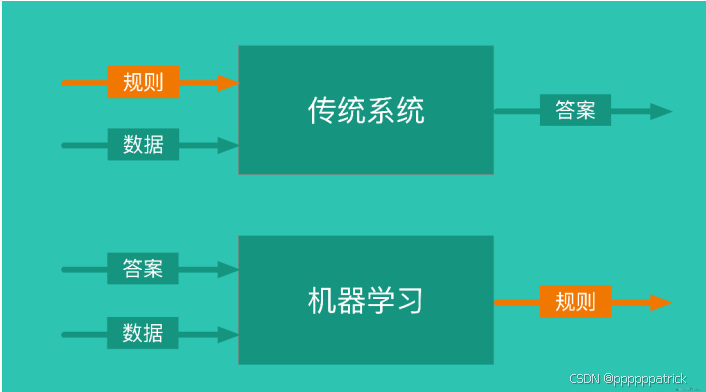
这张图很准确地描述了传统系统与机器学习之间的区别。简单来说,机器学习本身是一个黑盒子,我们不知道他具体里面都干了些什么,但是他总能从我们给的输入数据中找出数据之间的特征,生成一套规则,供我们使用。我们把中间这个"黑盒子"称为"神经网络"。
三、神经网络的输入输出常见数据形式
1. 输入分类
我们通常把一个神经网络的输入分为以下三个形式:
- 向量:最基础的输入形式,本质是"一串数字组成的列表",比如输入一个样本的特征(如一张图片的灰度值压缩后、一个用户的3个行为特征),用1维数组表示,适合简单的分类/回归任务。
- 矩阵/张量:深度学习中最常用的形式,矩阵是2维(行×列),张量是多维(可理解为"多个矩阵叠加")。比如我们之后要练习的4×4特征图就是矩阵,3×4×4特征图(3个通道)就是3维张量;日常的彩色图片(高×宽×3通道)、视频(帧×高×宽×3通道),都是张量形式,也是CNN的核心输入,我们写代码的时候只要涉及模型部分,大多都要将矩阵转换为张量进行运算
- 序列:按"时间/顺序"排列的数据,比如文本(每个字按顺序组成的序列)、语音信号(按时间顺序的音频特征)、时序数据(每天的温度数据),输入后神经网络会捕捉序列中的顺序规律,适配NLP、语音识别等任务。
2. 输出分类
- 回归任务(类比"填空题"):输出是"一个具体的数值",核心是"预测连续的、可量化的结果",没有固定的选项,只要预测的数值越接近真实值,模型效果越好。
实例:根据房屋的面积、户型、楼层(输入向量/矩阵),预测房屋的价格(输出具体数值,如85.6万);根据患者的体检数据(输入向量),预测患者的血糖值(输出具体数值,如5.8mmol/L);根据历史温度数据(输入序列),预测明天的气温(输出具体数值,如25℃)。
关键提醒:回归任务的输出是"连续值",这是它和分类任务的核心区别。 - 分类任务(类比"选择题"):输出是"一个固定的类别/标签",核心是"将输入数据划分到提前定义好的类别中",就像做选择题时,从选项中选出一个正确答案。分类任务又分为"二分类"和"多分类"。
实例1(二分类):根据一张图片(输入张量),判断图片中是"猫"还是"狗"(输出标签:猫/狗);根据用户行为特征(输入向量),判断用户是"潜在客户"还是"非潜在客户"(输出标签:是/否)。
实例2(多分类):根据一张图片(输入张量),判断图片中的动物是"猫、狗、鸡、鸭"中的哪一种(输出标签:猫/狗/鸡/鸭);根据文本序列(输入序列),判断文本的情感是"积极、消极、中性"中的哪一种(输出标签:积极/消极/中性)。
关键提醒:分类任务的输出是"离散的类别",提前定义好所有可能的选项,模型只需从中选择一个最可能的答案。 - 生成任务(类比"简答题"):输出是"一段新的数据",核心是"根据输入的规律,生成符合逻辑、贴合场景的新内容",没有固定的答案,只要生成的内容合理、连贯即可。生成任务是深度学习中较灵活的类型,后续进阶学习中会接触更多,本章先掌握基础定义和实例。
实例:输入一段文本"深度学习入门"(输入序列),生成一段关于深度学习入门的简短介绍(输出新的文本序列);输入一张人脸轮廓图(输入张量),生成一张完整的人脸图片(输出新的张量);输入一段语音片段(输入序列),生成一段模仿该语气的语音(输出新的序列)。
关键提醒:生成任务的核心是"创造新内容",而不是"选择/预测",它需要模型学习输入数据的分布规律,再基于规律生成新的数据,比如我们常见的AI写文案、AI画画,都属于生成任务。
3.实战判断:输入输出形式对应练习
为了帮大家更好地理解输入输出形式的对应关系,我们来看一些深度学习中的常见任务。这里我们用数字来表示不同的数据形式:
- 1 = 向量
- 2 = 矩阵/张量(如图像)
- 3 = 序列(如文本、语音)
| 任务 | 输入 | 输出 | 任务类型 |
|---|---|---|---|
| 根据种子的大小、重量等属性预测发芽概率 | 1 | 1 | 回归任务(预测连续值) |
| 根据视频生成字幕 | 3 | 3 | 生成任务(序列到序列) |
| 自动填充代码 | 3 | 3 | 生成任务(序列到序列) |
| 判断图片中人物是谁 | 2 | 2 | 分类任务(图像→类别) |
| 根据内容判断两部动漫是否为同一部 | 3 | 2 | 分类任务(文本→二分类) |
| 判断动漫声优是否为同一个人 | 3 | 2 | 分类任务(语音→二分类) |
| 判断淘宝商品的配图和文字标题是否一致 | 3 | 2 | 分类任务(图文→二分类) |
| 圈出图片中的羊,并且识别为羊 | 2 | 1+2 | 检测+分类任务(图像→位置+类别) |
| 根据车摄像头看到的画面,把人、路、车的轮廓准确画出来 | 2 | 3 | 生成任务(图像→序列/轮廓) |
| CHATGPT | 3 | 3() | 生成任务(序列到序列) |
四、如何开始深度学习
1.只需三步
其实真正开始深度学习只有三个步骤,就好像是把大象放进冰箱需要几步一样:

在我们后续的学习中,我们会知道,这三个部分都是已经有很多库函数帮我们写好了的,我们直接调用就行,但是我们会在本专栏中模拟一些比较经典的模型。其实真正我们在深度学习中,只需要把要输入的数据整理好,交给我们的模型就行了。但是在此之前,我们需要了解这些原理。
2. 步骤详解:从"找函数"到"优化模型"
深度学习的核心,就是找到一个合适的函数(模型),让它能根据输入数据,输出我们想要的结果。这个过程可以拆解为三个关键步骤:定义模型、计算损失、优化参数。下面我们用最基础的线性模型,一步步拆解这个过程。
第一步:定义一个函数(模型)
我们的目标是从数据中找到规律。比如,我们有一组数据点 (x, y),它们大致符合 y = 2x + 1 的规律,但带有一些噪声。我们的任务就是找到一个函数 ŷ = wx + b,让它尽可能地拟合这些数据。
- 模型(Model) :我们定义的函数,这里是线性模型
ŷ = wx + b。 - 参数(Parameters) :函数中的未知量,即权重
w和偏置b。我们的目标就是找到最优的w和b。 - 数据(Data) :
- 特征(Feature, x) :输入数据,如
1, 2, 3...。 - 标签(Label, y) :我们期望的输出,如
3.1, 5.1, 6.9...。
- 特征(Feature, x) :输入数据,如
第二步:定义损失函数(Loss Function)
有了模型,我们怎么知道当前的 w 和 b 好不好呢?这就需要一个"裁判"------损失函数(Loss Function) 。它的作用是衡量模型预测值 ŷ 和真实标签 y 之间的差距。
- 损失(Loss):差距越大,损失越大,说明模型表现越差。
- 常见损失函数 :
- MAE(Mean Absolute Error,均绝对误差) :
L(w, b) = |ŷ - y| = |wx + b - y| - MSE(Mean Squared Error,均方误差) :
L(w, b) = (ŷ - y)²
- MAE(Mean Absolute Error,均绝对误差) :
- 总损失 :对于所有数据点,我们计算平均损失:
L = (1/N) * Σ l,其中l是单个数据点的损失。
第三步:优化模型(Optimization)
优化的目标是找到一组参数 (w*, b*),使得总损失 L 最小。这个过程就是优化(Optimization) ,最常用的方法是梯度下降(Gradient Descent)。
1. 梯度(Gradient)
梯度是微积分中的一个概念,你可以把它理解为"方向"和"速率"。
- 直观理解:想象你站在一座山上,梯度就是指向最陡峭下坡的方向。沿着这个方向走,你能最快地到达山脚(损失最小的地方)。
- 数学表达 :对于损失函数
L(w, b),梯度就是它对各个参数的偏导数,即∂L/∂w和∂L/∂b。∂L/∂w告诉我们,当w变化时,损失L会如何变化。- 如果
∂L/∂w是正数,说明增大w会让损失变大,我们应该减小w。 - 如果
∂L/∂w是负数,说明增大w会让损失变小,我们应该增大w。
- 梯度大小:梯度的绝对值越大,说明这个方向越陡峭,我们应该迈的步子就越大。
2. 超参数(Hyperparameter)
超参数是我们在开始训练之前,手动设置的参数,它不是模型自己学习出来的。最核心的超参数就是学习率(Learning Rate, η)。
- 学习率(η) :它决定了我们每次更新参数时,迈的步子有多大。
- 学习率太大:步子迈得太大,可能会直接跨过最低点,甚至导致损失越来越大,模型无法收敛。
- 学习率太小:步子太小,虽然稳定,但训练速度会非常慢,需要很多次迭代才能找到最低点。
- 所以,选择一个合适的学习率是训练深度学习模型的关键技巧之一。
3. 梯度下降的具体步骤
- 初始化 :随机选择一组初始参数
w⁰, b⁰。 - 计算梯度 :计算损失函数对当前参数的梯度,即
∂L/∂w和∂L/∂b。 注:在实际开发中,如使用 PyTorch 框架,这个复杂的求导过程会被自动完成,我们无需手动计算。 - 更新参数 :根据梯度和学习率,更新参数:
w¹ ← w⁰ - η * (∂L/∂w|w=w⁰,b=b⁰)b¹ ← b⁰ - η * (∂L/∂b|w=w⁰,b=b⁰)
- 迭代:重复步骤2和3,直到损失函数收敛到一个最小值,此时我们就得到了优化后的模型。
总结
深度学习的"三步法"本质上就是:
- 定义模型:我要找一个什么样的函数?
- 定义损失:我怎么判断这个函数好不好?
- 优化参数:我怎么让这个函数变得更好?
而梯度和超参数,就是让第三步"优化"得以实现的核心工具。梯度告诉我们"往哪走",超参数(学习率)告诉我们"走多快"。
五、从单神经元到复杂神经网络:张量视角的参数运算
在第四步中,我们用单神经元、标量参数(单个w和b)理解了深度学习的核心逻辑,但真实场景中,输入往往是矩阵/张量(如图像、多特征样本),模型也不是单个神经元,而是多层堆叠的复杂神经网络。
这一节我们将从单神经元过渡到多层神经网络 ,并核心讲解张量视角下的w和b运算规则------这是后续CNN、全连接网络实操的数学基础,也是"张量为何是深度学习核心输入"的关键答案。
1. 回顾:单神经元的标量运算
先回顾最基础的单神经元线性计算,公式为:
y ^ = w ⋅ x + b \hat{y} = w \cdot x + b y^=w⋅x+b
- 这里的
w(权重)、x(输入)、b(偏置)、hat{y}(预测值)都是标量(单个数字); - 单个神经元只能处理单个特征输入,无法应对多特征、多样本、多通道的复杂数据(如3×4×4的图像张量)。
而深度学习的核心,就是将标量运算升级为张量运算,让神经网络能并行处理海量复杂数据,同时通过多层神经元堆叠,拟合更复杂的规律。
2. 第一步过渡:多特征输入 → 向量与矩阵运算
首先,我们从"单个特征输入"升级为"多个特征输入",比如输入一个样本的3个特征(如种子的大小、重量、湿度),此时输入不再是标量x,而是向量 x = x 1 , x 2 , x 3 T \boldsymbol{x} = x_1, x_2, x_3^T x=x1,x2,x3T
2.1 单神经元的向量运算
对应地,权重也不再是标量w,而是权重向量 w = w 1 , w 2 , w 3 T \boldsymbol{w} = w_1, w_2, w_3^T w=w1,w2,w3T,偏置仍为标量b(单个神经元只有一个偏置)。此时单神经元的计算升级为向量点积 :
r = w ⋅ x + b = w 1 x 1 + w 2 x 2 + w 3 x 3 + b r = \boldsymbol{w} \cdot \boldsymbol{x} + b = w_1x_1 + w_2x_2 + w_3x_3 + b r=w⋅x+b=w1x1+w2x2+w3x3+b
y ^ = σ ( r ) ( σ 为激活函数 ) \hat{y} = \sigma(r) \quad (\sigma为激活函数) y^=σ(r)(σ为激活函数)
2.2 多样本并行 → 矩阵运算
实际训练时,我们不会逐一样本计算,而是一次性输入批量样本 (如10个种子样本),此时输入变成矩阵 X ∈ R N × F \boldsymbol{X} \in \mathbb{R}^{N \times F} X∈RN×F
- N N N:批量样本数(如10);
- F F F:单个样本的特征数(如3)。
权重也升级为权重矩阵 W ∈ R F × N n e u r o n \boldsymbol{W} \in \mathbb{R}^{F \times N_{neuron}} W∈RF×Nneuron
- F F F:输入特征数(与输入矩阵的列数一致);
- N n e u r o n N_{neuron} Nneuron:当前层的神经元数量(如隐藏层有5个神经元)。
偏置升级为偏置向量 b ∈ R 1 × N n e u r o n \boldsymbol{b} \in \mathbb{R}^{1 \times N_{neuron}} b∈R1×Nneuron(每个神经元对应一个偏置)。
此时,一层神经元的线性计算 变成矩阵乘法 ,公式为:
R = X ⋅ W + b \boldsymbol{R} = \boldsymbol{X} \cdot \boldsymbol{W} + \boldsymbol{b} R=X⋅W+b
- 输出: R ∈ R N × N n e u r o n \boldsymbol{R} \in \mathbb{R}^{N \times N_{neuron}} R∈RN×Nneuron每行代表一个样本,每列代表一个神经元的线性输出。
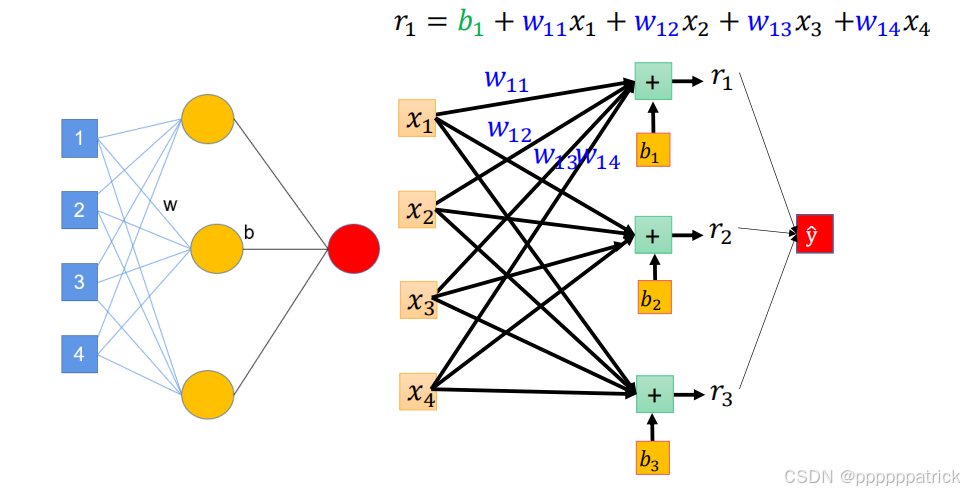
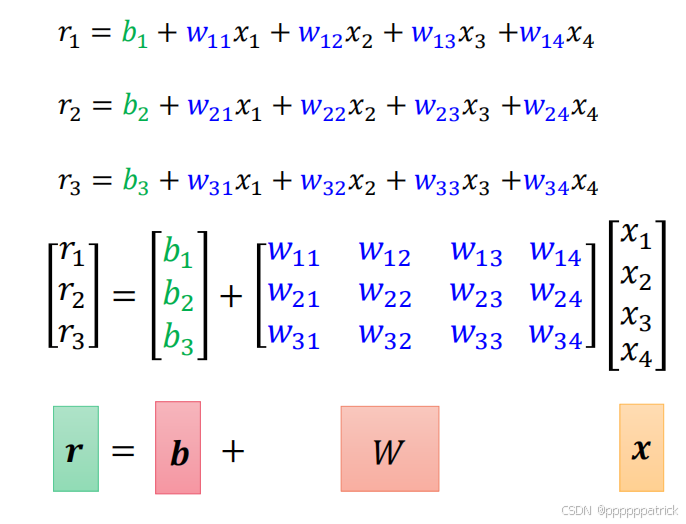
这就是"批量计算"的核心------用矩阵运算替代循环,大幅提升计算效率,也是深度学习框架(如PyTorch)的底层逻辑。
3. 核心升级:复杂数据与张量运算(适配CNN核心输入)
当输入从"多特征样本"升级为"图像/视频张量"(如3×4×4的彩色特征图、224×224×3的图片),标量、向量、矩阵已经无法满足计算需求,我们需要张量运算。
3.1 张量的维度定义与核心匹配规则
在深度学习中,我们约定图像类张量的维度格式 为: ( N , C , H , W ) (N, C, H, W) (N,C,H,W)(批量数×通道数×高度×宽度),比如:
- 单张彩色图片: (1, 3, 4, 4) (1个样本、3个通道、4×4尺寸);
- 批量16张彩色图片:(16, 3, 224, 224) 。
对应地,卷积层的权重不再是矩阵,而是4维权重张量 W ∈ R C o u t , C i n , K , K \boldsymbol{W} \in \mathbb{R}^{C_{out}, C_{in}, K, K} W∈RCout,Cin,K,K
- C o u t C_{out} Cout:输出通道数(卷积核数量,对应下一层的通道数);
- C i n C_{in} Cin:输入通道数(必须与输入张量的通道数一致,核心匹配规则);
- K × K K \times K K×K:卷积核的空间尺寸(如3×3、5×5)。
偏置为1维偏置张量 b ∈ R C o u t \boldsymbol{b} \in \mathbb{R}^{C_{out}} b∈RCout(每个输出通道对应一个偏置)。
3.2 张量的核心运算法则(以卷积运算为例)
张量运算的核心是"维度匹配,对应运算",以CNN中最核心的卷积张量运算为例,输入张量 X ∈ R N , C i n , H , W \boldsymbol{X} \in \mathbb{R}^{N, C_{in}, H, W} X∈RN,Cin,H,W与权重张量 W ∈ R C o u t , C i n , K , K \boldsymbol{W} \in \mathbb{R}^{C_{out}, C_{in}, K, K} W∈RCout,Cin,K,K的运算规则为:
- 通道匹配:权重张量的C_{in} 必须与输入张量的C_{in} 完全一致,确保每个卷积核能"遍历"输入的所有通道;
- 空间卷积:每个卷积核(C_{in} \times K \times K)在输入张量的每个样本、每个通道上,按空间维度(H, W )滑动卷积,计算局部加权和;
- 通道聚合 :单个卷积核对输入的所有通道卷积后,结果求和,得到该卷积核对应的单通道特征图;
- 批量并行 :上述运算在所有样本上同时进行,最终输出张量 R ∈ R N , C o u t , H ′ , W ′ \boldsymbol{R} \in \mathbb{R}^{N, C_{out}, H', W'} R∈RN,Cout,H′,W′(H', W' 为卷积后的空间尺寸);
- 偏置广播 :偏置张量 b 会自动广播到输出张量的所有样本、所有空间位置,完成 R+b 的运算。
关于卷积部分,之后我们会有详解,现在看不懂没有关系,主要是要知道矩阵为什么要升级成"张量"
简单来说,就是矩阵只能表示二维的数据,而"张量"可以表示更高维度数据
3.3 张量运算的本质:多层神经网络的堆叠基础
复杂神经网络(如多层隐藏层结构),本质是多层张量运算的堆叠:
- 输入层:接收张量输入(如(N, 3, 224, 224) 的图片);
- 隐藏层1:卷积/全连接张量运算 → 输出新张量;
- 激活函数:对张量的每个元素逐元素运算(不改变维度);
- 隐藏层2:基于上一层输出张量,继续张量运算;
- 输出层:最终张量运算,得到任务对应的输出(如分类的类别概率张量)。
其实之后我们要写的模拟神经网络的重要步骤就是这样,一路上一次调用隐藏层和激活函数即可
关键总结 :从单神经元到复杂神经网络,本质是参数从标量升级为张量,运算从标量乘法升级为张量运算------而"维度匹配"是所有张量运算的第一准则,也是后续我们手算卷积、代码调试的核心依据。
总结:从"黑盒子"到可理解的深度学习
本文作为本专栏的开篇第0章,我们完成了从概念认知 到核心逻辑的完整入门:
-
深度学习是什么?
它是人工智能的核心分支,通过模拟人类大脑的神经网络结构,让计算机从海量数据中自动捕捉规律、提炼特征,最终实现识别、判断、预测等功能。我们不必纠结复杂的数学推导,而是从"定义模型→定义损失→优化参数"的三步法,理解其核心运转逻辑。
-
输入输出的本质是什么?
神经网络的输入分为向量、矩阵/张量、序列三类,输出则对应回归(连续值)、分类(离散类别)、生成(新内容)三大任务。通过实战练习,我们能清晰看到:数据形式决定了输入,任务目标决定了输出。
-
从单神经元到复杂网络,核心是"张量运算"
我们从最基础的单神经元标量运算出发,逐步升级到多特征向量运算、多样本矩阵运算,最终过渡到适配图像等复杂数据的张量运算。这一过程的本质是:参数从标量升级为张量,运算从标量乘法升级为张量运算,而"维度匹配"是所有运算的第一准则。
-
下一步:激活函数的"非线性魔法"
线性的张量运算只能拟合简单规律,而激活函数的核心作用,就是为神经网络注入"非线性",让它拥有拟合任意复杂函数的能力。下一章,我们将深入解析sigmoid、ReLU等经典激活函数,揭开深度学习"万能近似"的秘密。