SLUB分配器
linux 内核的 slab 分配器有三种不同的实现,它们分别是 slab、slub和 slob。每种实现都有不同的设计侧重点,以适应不同的系统需求。本文基于 4.14.7 版本分析下其实现,内核代码里面很多地方都用 slab 来统一称呼,本文也保持一致。
| 分配器 | 典型场景 | 现状 |
|---|---|---|
| SLAB | 早期的高性能服务器 | 已弃用(Linux 6.5 开始) |
| SLUB | 通用(桌面、服务器、现代嵌入式) | 绝对主流/默认 |
| SLOB | 极小内存嵌入式(<32MB) | 已移除(自 Linux 6.4) |
slab 分配器基于伙伴系统来实现,用来解决伙伴系统存在的一些问题。比如内存碎片、性能开销等。
1. 概述
slab cache 是一个管理器,用来管理特定的对象,比如进程描述符 task struct、文件节点 inode 等,
所有的 slab cache 通过全局链表管理起来。
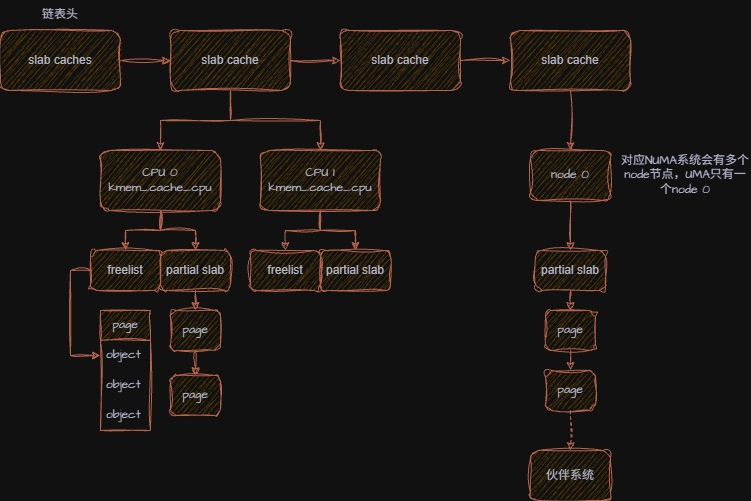
根据 slab 中对象的分配情况,slab 分为了3种:
- partial slab:有已分配对象,又有空闲对象的页面。
- full slab:对象都被分配出去的页面,slab cache 不会对其跟踪,当需要释放对象时,内核根据对象地址找到 page 结构,然后将其挂回到 partial slab 中。
- empty slab:对象都没被分配出去,基本上大部分都还给了伙伴系统,少部分挂载到 partial slab 的末尾,作为缓冲。
2. 结构体定义
2.1 slab cache
slab cache 为每个 cpu 设置了一个本地缓存cpu_slab,只有绑定的 cpu 才能访问他,用于无锁的快速分配和释放对象;为了防止频繁的向伙伴系统申请和释放页面,设置了一个成员min_partial,当node 节点的 partial slab 页面数量 < min_partial 时,即使是一个 empty slab,也会把它留在 partial 链表中,反之则将其归还给伙伴系统。
其他变量含义见注释。
c
/* include/linux/slub_def.h */
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab; /* cpu本地缓存 */
unsigned long flags; /* 标志位,用于设置对象的一些特性,比如对齐、填充等 */
unsigned long min_partial; /* node节点partial slab数量现职 */
int size; /* 实际分配大小 */
int object_size; /* 用户申请的原始对象大小 */
/* 空闲指针(freelist pointer)在对象内的偏移量
* 在对象没有分配前,内核会复用对象的内存当作指针指向下一个空闲对象
*/
int offset;
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* per-cpu partial链表中所有slab可供分配的空闲对象数量
* 多的将会放入node->partial供其他cpu使用
*/
int cpu_partial; /* */
#endif
/* 高位为申请页面的阶数、低位为该slab容纳的对象总数 */
struct kmem_cache_order_objects oo; /* 正常情况配置 */
struct kmem_cache_order_objects max; /* 最大尝试配置 */
struct kmem_cache_order_objects min; /* 最小保底配置 */
gfp_t allocflags; /* 向伙伴系统申请内存时的分配标识 */
int refcount; /* 当计数为0时,可以释放内存到伙伴系统 */
void (*ctor)(void *); /* 构造函数,用于创建slab池中的对象 */
int inuse; /* Offset to metadata */
int align; /* Alignment */
int reserved; /* Reserved bytes at the end of slabs */
int red_left_pad; /* Left redzone padding size */
const char *name; /* 名称,会在/proc/slabinfo下面展示 */
struct list_head list; /* 链接系统中所有类型的slab caches */
struct kmem_cache_node *node[MAX_NUMNODES]; /* 指向内存结点对对应的partial cache */
};2.2 kmem_cache_cpu
cpu 本地缓存使用kmem_cache_cpu 结构体来表示,变量含义见注释。
c
/* include/linux/slub_def.h */
struct kmem_cache_cpu {
void **freelist; /* 指向cpu本地缓存中的第一个空闲对象 */
unsigned long tid; /* 确保申请的cpu和cpu本地缓存是一致的 */
struct page *page; /* 使用page表示slab */
#ifdef CONFIG_SLUB_CPU_PARTIAL
/* cpu本地缓存的备用slab
* 当cpu本地缓存无空闲对象时,内核会从partial列表中查找空闲对象
*/
struct page *partial;
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS]; /* 记录一些状态信息 */
#endif
};2.3 page
当前版本内核代码,slab 使用struct page来表示,变量含义见注释。
c
/* include/linux/mm_types.h */
struct page {
union {
void *s_mem; /* 指向slab页中第一个对象的起始虚拟地址 */
};
union {
void *freelist; /* 指向slab页中的第一个空闲对象 */
};
union {
/*
* counters相当于是 _refcount (32bit) + SLUB metadata (32bit)
* 让cpu用一条原子指令操作这些关键字段
*/
unsigned long counters;
struct {
union {
struct {
unsigned inuse:16; /* slab已分配对象的数量 */
unsigned objects:15; /* slab包含的对象总数 */
unsigned frozen:1; /* slab冻结标志,为1表示在cpu本地缓存中 */
};
};
};
atomic_t _refcount; /* slab对应物理页面的引用计数 */
};
union {
/* 当slab位于node->partial时,用于挂入链表 */
struct list_head lru;
/* slab位于cpu partial list时使用 */
struct {
struct page *next; /* 指向partial链表的下一个slab */
int pages; /* 当前slab开始,链表后面还剩多少个slab */
int pobjects; /* 当前slab开始,链表后面所有slab中空闲对象的总数 */
};
};
union {
struct kmem_cache *slab_cache; /* 指向该slab所属的slab cache */
};
}2.4 kmem_cache_node
为了支持 NUMA 架构(UMA 架构就一个node 0),减少跨内存节点的访问延迟和锁竞争,每个 slab 缓存会为系中的每个内存节点维护一个 kmem_cache_node结构。
c
struct kmem_cache_node {
spinlock_t list_lock;
#ifdef CONFIG_SLUB
unsigned long nr_partial; /* 记录partial链表中的slab数量 */
struct list_head partial; /* partial slab的链表头 */
#endif
};3. slab cache创建
cache 创建的入口函数是kmem_cache_create,流程如下。
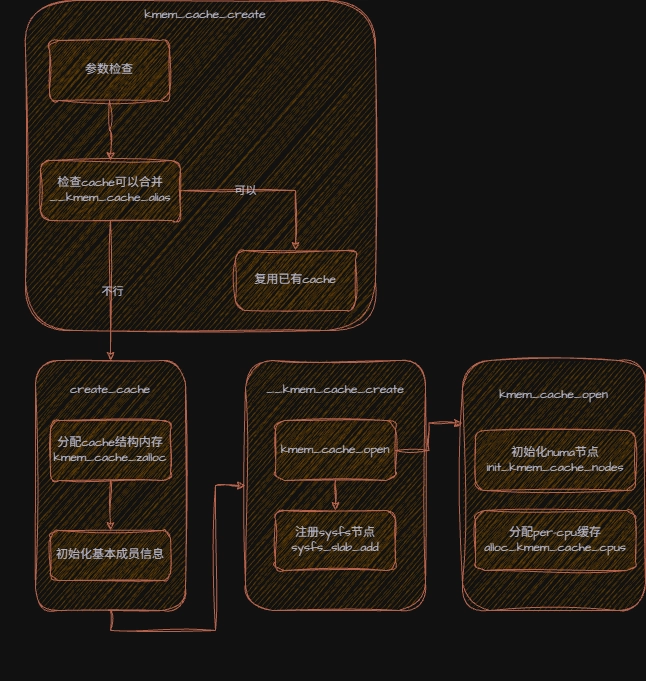
3.1 init_kmem_cache_nodes
init_kmem_cache_nodes函数用于为指定 slab cache 在各个内存结点上面分配并初始化管理结构。static struct kmem_cache *kmem_cache_node是一个全局变量,专门管理 kmem_cache_node 对象的 slab cache 。它和struct kmem_cache_node区别就是全局变量它是一个管理员,而结构体是被管理的对象。
c
static int init_kmem_cache_nodes(struct kmem_cache *s)
{
int node;
/* 遍历内存结点 */
for_each_node_state(node, N_NORMAL_MEMORY) {
struct kmem_cache_node *n;
if (slab_state == DOWN) {
/* 系统处于早期启动阶段,使用早期分配函数 */
early_kmem_cache_node_alloc(node);
continue;
}
/* 正常分配:从专用缓存中分配 */
n = kmem_cache_alloc_node(kmem_cache_node,
GFP_KERNEL, node);
if (!n) {
free_kmem_cache_nodes(s);
return 0;
}
/* 初始化刚分配的kmem_cache_node结构 */
init_kmem_cache_node(n);
/* 将分配好的结点管理结构挂载到kmem_cache的node数组 */
s->node[node] = n;
}
return 1;
}对于 NUMA 系统来说会有多个节点,而 UMA 只有一个节点 node 0 。
3.2 alloc_kmem_cache_cpus
alloc_kmem_cache_cpus是为指定 cache 分配并初始化一个 cpu 本地缓存。
c
static inline int alloc_kmem_cache_cpus(struct kmem_cache *s)
{
BUILD_BUG_ON(PERCPU_DYNAMIC_EARLY_SIZE <
KMALLOC_SHIFT_HIGH * sizeof(struct kmem_cache_cpu));
/* 分配per-cpu内存 */
s->cpu_slab = __alloc_percpu(sizeof(struct kmem_cache_cpu),
2 * sizeof(void *));
if (!s->cpu_slab)
return 0;
/* 初始化分配的结构 */
init_kmem_cache_cpus(s);
return 1;
}4. slab 内存分配
内存分配的入口函数是kmem_cache_alloc,函数执行路径为kmem_cache_alloc->slab_alloc→slab_alloc_node ,从最后一个函数开始分析。
4.1 slab_alloc_node
slab_alloc_node会决定当前执行快速分配路径还是慢速分配路径。它判断cpu_slab→freelist,如果不为空,代表 cpu 本地缓存还有空闲对象。 除了有空闲对象以外,cpu_slab 要和请求分配的节点保持一致,比如当前 cpu_slab 属于node 0,那么请求的内存节点也是node 0,这样才可以走快速路径,实现无锁快速分配。对于 UMA 架构来说,只有一个 node 0 。
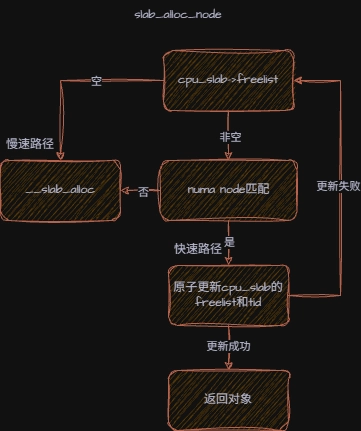
c
static __always_inline void *slab_alloc_node(struct kmem_cache *s,
gfp_t gfpflags, int node, unsigned long addr)
{
void *object;
struct kmem_cache_cpu *c;
struct page *page;
unsigned long tid;
/* 分配前的检查和准备工作 */
s = slab_pre_alloc_hook(s, gfpflags);
if (!s)
return NULL;
redo:
/*
* 获取cpu_slab指针和任务ID
* 由于内核抢占,tid和c可能不属于同一个cpu,则重新获取
*/
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
barrier();
/*
* 快速路径:从cpu的本地缓存获取对象
* 获取空闲链表的第一个object对象
* 获取缓存对应的物理页page
*/
object = c->freelist;
page = c->page;
if (unlikely(!object || !node_match(page, node))) {
/* 如果没有空闲对象或者
* 当前cpu缓存的页面所在的numa节点和请求的node不一致
* 则进入慢速路径
*/
object = __slab_alloc(s, gfpflags, node, addr, c);
stat(s, ALLOC_SLOWPATH);
} else {
/* 获取下一个对象 */
void *next_object = get_freepointer_safe(s, object);
/* 让freelist指向下一个空闲对象 */
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
object, tid,
next_object, next_tid(tid)))) {
note_cmpxchg_failure("slab_alloc", s, tid);
goto redo;
}
/* 预取下一个对象到cpu高速缓存 */
prefetch_freepointer(s, next_object);
stat(s, ALLOC_FASTPATH);
}
/* 如果设置了ZERO标志,则将内存清0 */
if (unlikely(gfpflags & __GFP_ZERO) && object)
memset(object, 0, s->object_size);
/* 解除毒化 标记内存可访问 */
slab_post_alloc_hook(s, gfpflags, 1, &object);
return object;
}4.2 ___slab_alloc
当 cpu 本地缓存无空闲对象,或者和申请的内存节点不匹配时,就会进入到慢速路径,调用函数__slab_alloc ,函数会将中断关闭然后调用___slab_alloc。
函数首先检查cpu_slab→page是否为空,如果freelist 为空,page 不为空,说明虽然缓存链表空了,但是这个页面本身可能还有未被提取到 freelist 的空闲对象,比如在page→freelist中。关于这两个 freelist ,可以看作是同一个池子的两本账单:
cpu_slab→freelist:本地账单,记录的是当前 cpu 可无锁直接拿走的对象。cpu_slab→page→freelist:共享账单,记录的是该 slab 被当前 cpu 占用占用期间,其他 cpu 异步释放回来的对象。
如果 page 也为空,代表 cpu 本地资源已耗尽,需要跳转到new_slab处寻找新的 slab 。在new_slab中,依次完成以下几件事:
- 检查当前 cpu 是否有备用的 partial slab。如果有,则取出一个作为新的
cpu_slab→page,跳回到redo重新尝试分配。 - 如果 cpu 本地没有,就去查全局node节点的 partial 链表,需要加锁。
- 如果 node partial 链表也是空,则需要向伙伴系统申请了。
在redo流程中,如果用户明确要求在特定结点分配内存,而当前 cpu 缓存的 slab 不在该节点中,则会去寻找或分配符合要求的内存,避免远程内存访问带来的性能开销。
redo会重新检查下c→freelist是否是空,虽然__slab_alloc调用___slab_alloc 时关闭了中断,但是在读到c->freelist == NULL到关中断这个时间窗口内可能出现释放操作。
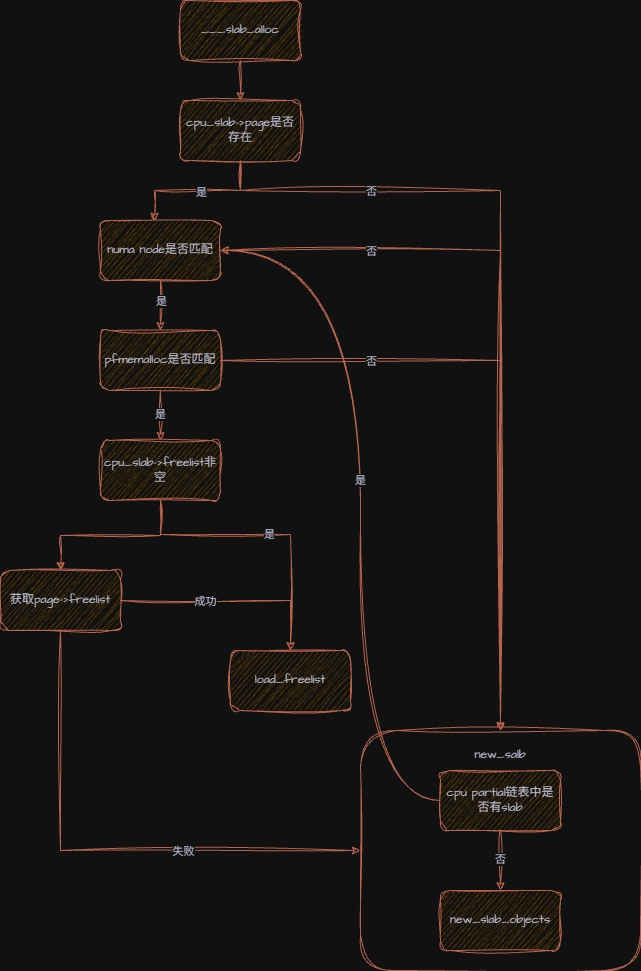
c
static void *___slab_alloc(struct kmem_cache *s, gfp_t gfpflags, int node,
unsigned long addr, struct kmem_cache_cpu *c)
{
void *freelist;
struct page *page;
/* 检查c->page是否为空 */
page = c->page;
if (!page)
goto new_slab;
redo:
/* 检查当前slab和node节点是否匹配 */
if (unlikely(!node_match(page, node))) {
int searchnode = node; /* searchnode为用户请求的节点 */
/* 当numa节点没有内存时,将目标节点修正为最近的有内存结点 */
if (node != NUMA_NO_NODE && !node_present_pages(node))
searchnode = node_to_mem_node(node);
/* 二次确认 */
if (unlikely(!node_match(page, searchnode))) {
stat(s, ALLOC_NODE_MISMATCH);
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}
}
/* 检查当前页面是否是紧急预留内存,并且当前分配请求是否允许
* 使用这种内存,如果不匹配,则寻找新的新的slab
*/
if (unlikely(!pfmemalloc_match(page, gfpflags))) {
deactivate_slab(s, page, c->freelist, c);
goto new_slab;
}
/* 再次检查,其他进程可能释放了一些对象到slab中 */
freelist = c->freelist;
if (freelist)
goto load_freelist;
/* 尝试获取page->freelist */
freelist = get_freelist(s, page);
if (!freelist) {
c->page = NULL;
stat(s, DEACTIVATE_BYPASS);
goto new_slab;
}
stat(s, ALLOC_REFILL);
load_freelist:
/* 这是成功路径 */
VM_BUG_ON(!c->page->frozen);
/* 更新c->freelist指向下一个对象 */
c->freelist = get_freepointer(s, freelist);
/* 更新task id */
c->tid = next_tid(c->tid);
return freelist;
/* 寻找新的slab */
new_slab:
/* 慢速路径:获取c->partial */
if (slub_percpu_partial(c)) {
/* 更新当前的活动slab */
page = c->page = slub_percpu_partial(c);
/* 更新链表头指向下一个partial slab */
slub_set_percpu_partial(c, page);
stat(s, CPU_PARTIAL_ALLOC);
goto redo;
}
/* 走到这里,代表c->partial链表也没有空闲对象了,需要向node节点或者伙伴系统申请 */
freelist = new_slab_objects(s, gfpflags, node, &c);
if (unlikely(!freelist)) {
slab_out_of_memory(s, gfpflags, node);
return NULL;
}
page = c->page;
if (likely(!kmem_cache_debug(s) && pfmemalloc_match(page, gfpflags)))
goto load_freelist;
/* Only entered in the debug case */
if (kmem_cache_debug(s) &&
!alloc_debug_processing(s, page, freelist, addr))
goto new_slab; /* Slab failed checks. Next slab needed */
deactivate_slab(s, page, get_freepointer(s, freelist), c);
return freelist;
}4.3 new_slab_objects
当已经无法从cpu本地缓存中获取到对象的时候,就需要调用 new_slab_objects了。
c
static inline void *new_slab_objects(struct kmem_cache *s, gfp_t flags,
int node, struct kmem_cache_cpu **pc)
{
void *freelist;
struct kmem_cache_cpu *c = *pc;
struct page *page;
/* 从指定node节点的kmem_cache_node->partial获取 */
freelist = get_partial(s, flags, node, c);
if (freelist)
return freelist;
/* 向伙伴系统申请slab */
page = new_slab(s, flags, node);
if (page) {
/* 获取slab cache的本地cpu缓存 */
c = raw_cpu_ptr(s->cpu_slab);
/* 将旧的slab缓存于cpu本地缓存解绑 */
if (c->page)
flush_slab(s, c);
/*
* 将新申请到的slab和cpu本地缓存绑定
* page->freelist赋值给kmem_cache_cpu->freelist
*/
freelist = page->freelist;
/* 绑定后需要将page->freelist置空 */
page->freelist = NULL;
stat(s, ALLOC_SLAB);
/* 将新申请到slab赋值给kmem_cache_cpu->page */
c->page = page;
*pc = c;
} else
freelist = NULL;
return freelist;
}5. slab内存释放
slab 释放流程入口函数是kmem_cache_free,函数执行路径为kmem_cache_free->slab_free→do_slab_free。
5.1 do_slab_free
释放流程也分为快速路径和慢速路径,do_slab_free首先会检查释放对象的 slab 是否在被当前 cpu 使用。如果是,则可以走快速路径直接释放,释放的对象会插入到 freelist 的头部。否则走慢速路径调用__slab_free。
c
static __always_inline void do_slab_free(struct kmem_cache *s,
struct page *page, void *head, void *tail,
int cnt, unsigned long addr)
{
void *tail_obj = tail ? : head;
struct kmem_cache_cpu *c;
unsigned long tid;
redo:
/* 获取当前cpu的本地缓存指针c和任务id */
do {
tid = this_cpu_read(s->cpu_slab->tid);
c = raw_cpu_ptr(s->cpu_slab);
} while (IS_ENABLED(CONFIG_PREEMPT) &&
unlikely(tid != READ_ONCE(c->tid)));
/* 内存屏障 */
barrier();
/* 检查要释放对象的page是否被当前cpu正在使用 */
if (likely(page == c->page)) {
/* 快速路径,无锁释放 */
/* 将要释放的对象放到c->freelist的头部 */
set_freepointer(s, tail_obj, c->freelist);
/* 更新freelist和tid */
if (unlikely(!this_cpu_cmpxchg_double(
s->cpu_slab->freelist, s->cpu_slab->tid,
c->freelist, tid,
head, next_tid(tid)))) {
note_cmpxchg_failure("slab_free", s, tid);
goto redo;
}
stat(s, FREE_FASTPATH);
} else
/* 慢速路径 */
__slab_free(s, page, head, tail_obj, cnt, addr);
}5.2 __slab_free
当释放的对象不属于当前 cpu 使用的 slab 时,就会进到__slab_free,进行慢速路径释放。函数入参head 为待释放对象链表的第一个对象,tail为待释放对象链表的最后一个对象。
c
static void __slab_free(struct kmem_cache *s, struct page *page,
void *head, void *tail, int cnt,
unsigned long addr)
{
void *prior;
int was_frozen;
struct page new;
unsigned long counters;
struct kmem_cache_node *n = NULL;
unsigned long uninitialized_var(flags);
stat(s, FREE_SLOWPATH);
if (kmem_cache_debug(s) &&
!free_debug_processing(s, page, head, tail, cnt, addr))
return;
do {
if (unlikely(n)) {
spin_unlock_irqrestore(&n->list_lock, flags);
n = NULL;
}
prior = page->freelist; /* 获取当前的空闲链表头 */
counters = page->counters; /* 获取当前的计数器状态 */
set_freepointer(s, tail, prior); /* 将待释放对象链表的末尾指向旧的freelist */
/* 准备新的页面状态 */
new.counters = counters;
was_frozen = new.frozen;
new.inuse -= cnt; /* 减少在用对象计数 */
/* 判断释放需要node锁或者改变页面状态
* 条件:(slab变空了 or slab 之前是满的) and(slab当前不是冻结状态)
*/
if ((!new.inuse || !prior) && !was_frozen) {
/* 优化分支:如果支持cpu partial且slab之前是满的(!prior) */
if (kmem_cache_has_cpu_partial(s) && !prior) {
/*
* 关键优化:
* slab之前不在任何列表上(因为它是满的),现在有了空闲对象。
* 我们不急着把它放回node的partial列表,而是将其"冻结"(frozen=1)。
* 这样可以避免获取node锁,稍后将其放入cpu partial列表。
*/
new.frozen = 1;
} else {
/* 需要从链表中移除或移动,必须获取Node锁 */
n = get_node(s, page_to_nid(page));
/*
* 推测性地获取list_lock。
* 如果后面的cmpxchg失败,我们会释放锁并重试。
*/
spin_lock_irqsave(&n->list_lock, flags);
}
}
} while (!cmpxchg_double_slab(s, page,
prior, counters,
head, new.counters,
"__slab_free"));
/* 成功通过原子操作更新了状态,且没有触碰node锁 */
if (likely(!n)) {
/*
* 如果我们在上面的循环中将页面状态设置为了frozen (new.frozen = 1),
* 且它之前不是frozen (!was_frozen),说明我们刚刚把一个满的Slab
* 转化为了一个本地缓存的slab。
*/
if (new.frozen && !was_frozen) {
/* 将页面放入当前cpu的partial列表中,供后续快速分配使用 */
put_cpu_partial(s, page, 1);
stat(s, CPU_PARTIAL_FREE);
}
/*
* 如果was_frozen为真,说明页面本来就是冻结的(属于当前cpu),
* 我们只是简单地归还了对象并更新了计数,不需要任何列表操作。
*/
if (was_frozen)
stat(s, FREE_FROZEN);
return;
}
/* 如果代码执行到这里,说明n不为空,我们持有Node的list_lock。这意味着需要对Node的Partial或Full列表进行操作。 */
/* 如果对象全部释放(!new.inuse)且Node的Partial列表数量已达标 */
if (unlikely(!new.inuse && n->nr_partial >= s->min_partial))
goto slab_empty;
/*
* slab中还有对象。如果它之前不在Partial列表中(即之前是满的),
* 现在需要将其加入到Node的Partial列表尾部。
*/
if (!kmem_cache_has_cpu_partial(s) && unlikely(!prior)) {
if (kmem_cache_debug(s))
remove_full(s, n, page); /* 调试模式下从full列表移除 */
add_partial(n, page, DEACTIVATE_TO_TAIL); /* 加入partial链表 */
stat(s, FREE_ADD_PARTIAL);
}
spin_unlock_irqrestore(&n->list_lock, flags);
return;
/* 实际销毁逻辑 */
slab_empty:
if (prior) {
/*
* 如果prior不为空,说明Slab之前在Partial列表中。
* 现在它空了,需要将其从Partial列表中移除。
*/
remove_partial(n, page);
stat(s, FREE_REMOVE_PARTIAL);
} else {
/* prior 为空说明之前是满的,从full列表(仅调试模式维护)移除 */
remove_full(s, n, page);
}
spin_unlock_irqrestore(&n->list_lock, flags);
stat(s, FREE_SLAB);
/* 将物理页归还给页分配器(伙伴系统) */
discard_slab(s, page);
}