其他篇章【Linux专栏】
其他篇章 【C语言专栏】
上期回顾【Linux 】网络基础1

文章目录
- [1. 理解源IP地址和目的IP地址](#1. 理解源IP地址和目的IP地址)
- [2. 认识端口](#2. 认识端口)
-
- 2.1端口号范围划分
- [2.2 理解 "端⼝号" 和 "进程ID"](#2.2 理解 "端⼝号" 和 "进程ID")
- [2.3 源端口号与目的端口号](#2.3 源端口号与目的端口号)
- [2.4 理解Socket](#2.4 理解Socket)
- [2. 传输层的典型代表](#2. 传输层的典型代表)
-
- [2.1 TCP协议(传输层协议)](#2.1 TCP协议(传输层协议))
- [2.2 UDP协议(传输层协议)](#2.2 UDP协议(传输层协议))
-
- [UDP 的优缺点](#UDP 的优缺点)
- [3. 网络字节序](#3. 网络字节序)
-
- [3.1 认识大小端(按照字节为单位)](#3.1 认识大小端(按照字节为单位))
- [3.2 网络字节序采用"大端方式"存储](#3.2 网络字节序采用“大端方式”存储)
- 3.3网络字节序与主机字节序之间的转换
- [4. socket 编程接口](#4. socket 编程接口)
-
- [4.1 socket 常见API](#4.1 socket 常见API)
- [4.2 sockaddr 结构](#4.2 sockaddr 结构)
1. 理解源IP地址和目的IP地址
IP 在网络中,⽤来标识主机的唯⼀性
注意:
数据传输到主机是⽬的吗?答案:不是的,数据传输到主机不是目的,而是手段;毕竟聊天是人在聊,下载是人在下载,浏览网页是人在浏览;
进程是人在系统中的代表(即人在系统中就相当于进程),只要把数据给进程,人就相当于拿到了数据!
上网在技术的角度,只有两种行为(IO)
1.从远端服务器,获取数据2.本地数据上传到远端服务器IO:输入/输出
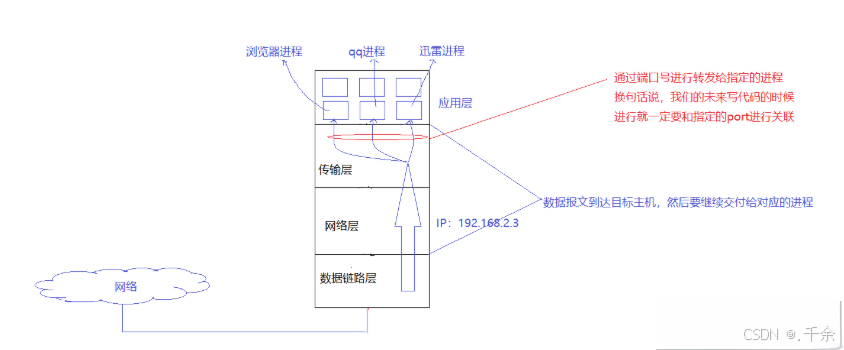
2. 认识端口
端⼝号( port )是传输层协议的内容
- 端口号,可以用来标识系统中唯一的一个网络进程
- IP表示全国内唯一的主机
- port表示该主机内唯一的进程
IP+ Port = 全国唯一的进程
- 端⼝号是⼀个 2 字节 16 位的整数,范围是0 ~ 65535(
1字节=8个bit)- 端⼝号⽤来标识⼀个进程, 告诉操作系统, 当前的这个数据要交给哪⼀个进程来处理;
- IP地址 + 端⼝号能够标识⽹络上的某⼀台主机的某⼀个进程;
⼀个端⼝号只能被⼀个进程占⽤.
2.1端口号范围划分
- 0 - 1023 : 知名端⼝号, HTTP, FTP, SSH 等这些⼴为使⽤的应⽤层协议, 他们的端⼝号都是固定的(比如120、110、119等电话,他们的服务都是一 一对应的)
- 1024 - 65535 : 操作系统动态分配的端⼝号. 客⼾端程序的端⼝号, 就是由操作系统从这个范围分配的
2.2 理解 "端⼝号" 和 "进程ID"
1. 端口号和进程 IP 都能用来唯一标识一台主机上的某个进程,但在网络通信中,并不能用进程 ID 来替代端口号
原因:
- 作用范围不同
PID 只在你的电脑内部有效,另一台电脑根本不知道你的 PID 是什么。而端口是网络通信的全球通用规则,服务必须绑定一个众所周知的固定端口(比如 Web 服务默认用 80 或 443),其他设备才能找到它。- 生命周期不同
PID 在进程重启后会改变。如果一个服务把 PID 作为网络入口,那它每次重启,客户端都要重新获取新的 PID,这在现实中不可行(比如我们都有身份证,但是在不同的场景就不好管理,比如我们在学校、工作中要是都用身份证,当我们换了一个学校,工作地方,我们登记的信息是不是就都要改变了,所以我们在学校就用学号代表我们的身份,工作中就是用工号,这样每次我们需要变更环境时,我们都能有新的信息代表,而不用更改原来的)。而端口绑定的是服务类型,程序重启只要还是这个服务,就应继续使用同一个端口。- 一对多的矛盾
一个进程可以监听多个端口(就像一个人开多家店),同时多个不同进程也可以绑定到同一个端口(但同一时间只有一个能成功)。反过来,一个端口也只能被一个进程使用。PID 和端口之间是灵活的 多对多关系,无法简单替代。
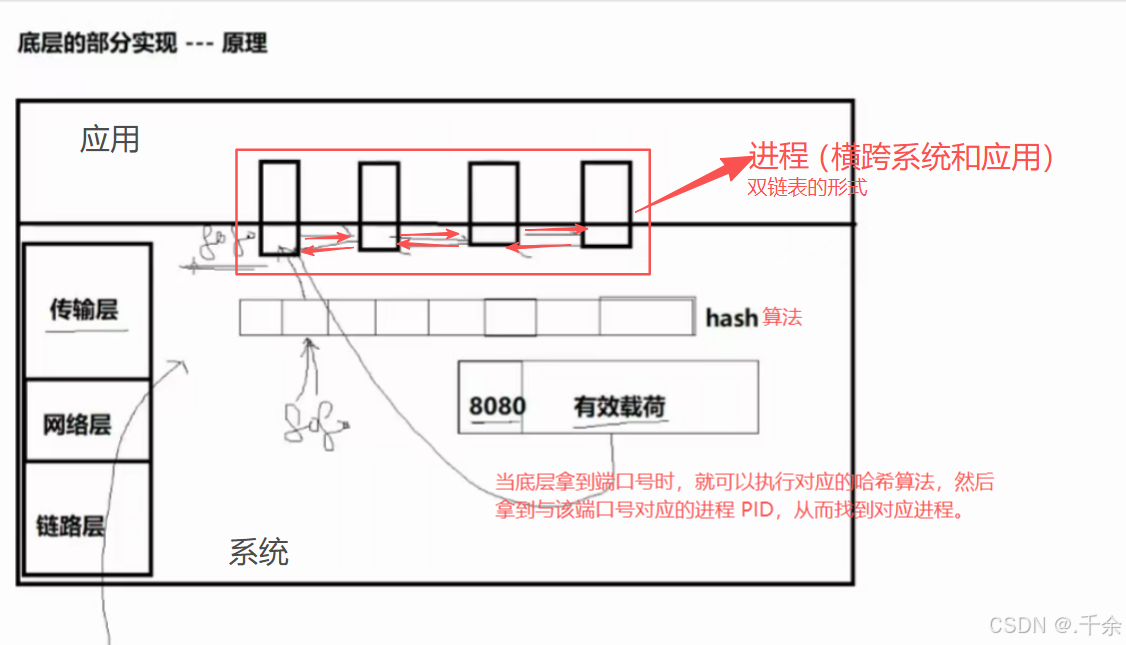
2. 如何通过端口号 port 找到对应的进程
- 在底层中,采用哈希的方式建立了端口号和进程 PID 之间的映射关系。
底层拿到一个端口号 -> 执行hash算法得到与之对应的PID -> 找到对应的进程
2.3 源端口号与目的端口号
传输层协议( TCP 和 UDP )的数据段中有两个端⼝号, 分别叫做源端⼝号和⽬的端⼝号:
- 源端口号:标识
发送端发起通信的进程; - 目的端口号:标识
接收端要交付的目标进程
2.4 理解Socket
ip+port 叫做套接字 socket
-
IP 地址⽤来标识互联⽹中唯⼀的⼀台主机, port ⽤来标识该主机上唯⼀的⼀个⽹络进程
-
IP+Port 就能表⽰互联⽹中唯⼀的⼀个进程
-
通信的时候,本质是两个互联⽹进程代表⼈来进⾏通信,{srcIp,srcPort,dstIp,dstPort}这样的4元组就能标识互联⽹中唯⼆的两个进程
-
网络通信的本质,也是进程间通信
socket
n.
(电源)插座;(电器上的)插⼝,插孔,管座;槽;窝;托座;⾅;孔⽳
vt.
把...装⼊插座;给...配插座
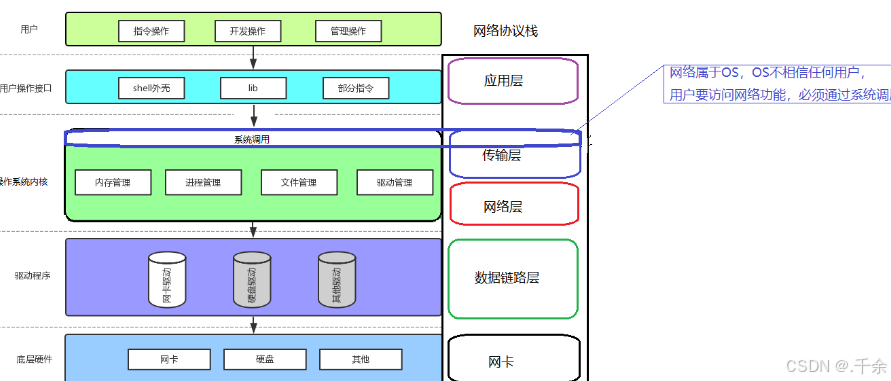
2. 传输层的典型代表
- 网络协议栈贯穿整个网络体系结构,在应用层中,操作系统层和驱动层各自占有一部分网络协议。
- 传输层写在操作系统中,当使用系统提供的接口实现网络通信时,必须要面对的就是传输层的协议,传输层最典型的协议是 TCP 和 UDP 。
2.1 TCP协议(传输层协议)
TCP(Transmission Control Protocol,传输控制协议)是互联网核心的传输层协议,主要解决一个 问题:如何在不可靠的网络上,建立可靠的逻辑连接。
它最关键的三个特性是:
- 有连接:通信前必须通过"三次握手"建立连接。就像打电话,得先拨号、对方接听、建立通路,才能通话。
- 可靠传输:具备确认和重传机制。发送的每个数据包都要求对方回复"收到了",否则就重发。它能保证数据完整、有序、不重复地到达。
- 流量与拥塞控制(面向字节流):发送方会根据接收方的处理能力和网络拥堵程度,自动调整速度,避免丢包。
对比 UDP:TCP 是可靠的、有连接的、速度较慢、有流量控制。而 UDP 不可靠、无连接、速度快,像寄快递,不管收没收到,常用于视频通话、直播等允许偶尔卡顿的场景。
2.2 UDP协议(传输层协议)
UDP(User Datagram Protocol,用户数据报协议)是 TCP 的"简单快速"兄弟。它与 TCP 同属传输层,但核心逻辑截然不同:它不建立连接,不保证可靠,也不做流量控制,主打一个"尽力而为"。
核心特性:
1. 无连接:发送数据前不需要像 TCP 那样"三次握手"。直接发,不管对方在不在、收不收得到。就像写信投递,不确认对方是否在家。
2. 不可靠传输:不保证送达,数据可能丢失、重复、乱序。也没有确认和重传机制。对方收没收到?UDP 协议本身完全不关心。
3. 面向数据报:这是 UDP 与 TCP"面向字节流"的最大区别。UDP 保留应用层发来的消息边界。应用程序每次 send 一个数据报,对方 recv 就能原封不动地读到整个数据报(前提是接收缓冲区够大)。不会发生 TCP 那样的"粘包"问题。
UDP 的优缺点
- 优点: 速度快、开销极小。UDP 的头部只有 8 个字节 (TCP 是 20 字节),且没有连接建立、确认、拥塞控制等步骤。因此实时性极高。
- 缺点: 不稳定、有大小限制。单个 UDP 数据报最大 64KB(通常建议不超过 1.5KB 以免分片)。超出后,IP 层会自动分片,一旦一个分片丢失,整个数据报就废了。
问题1:有连接和无连接怎么理解?
- 连接:
就好比我们打电话的时候,会先"喂",即确保连接了之后我们的沟通才是有效的- 无连接:
就好比我们发送邮件,要么不发,要么发,当我选择发,我不关心你收没收到,我发了就行
3. 网络字节序
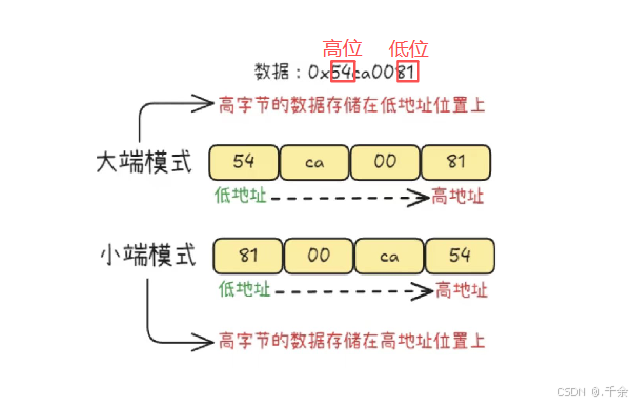
3.1 认识大小端(按照字节为单位)
- 大端模式:数据的
高位字节处的内容存放在内存的低地址处,而数据的低位字节处的内容存放在内存的高地址处。 - 小端模式:数据的
高位字节处的内容存放在内存的高地址处,而数据的低位字节处的内容存放在内存的低地址处。
3.2 网络字节序采用"大端方式"存储
- 发送主机通常将发送缓冲区中的数据按内存地址
从低到⾼的顺序发出; - 接收主机把从⽹络上接到的字节依次保存在接收缓冲区中,也是按内存地址
从低到⾼的顺序保存; - 因此,⽹络数据流的地址应这样规定:先发出的数据是低地址,后发出的数据是⾼地址
- TCP/IP协议规定,
⽹络数据流应采⽤⼤端字节序,即低地址⾼字节. - 不管这台主机是⼤端机还是⼩端机, 都会按照这个TCP/IP规定的⽹络字节序来发送/接收数据;
- 如果当前发送主机是⼩端, 就需要先将数据转成⼤端; 否则就忽略, 直接发送即可
3.3网络字节序与主机字节序之间的转换

h表⽰host,n表⽰network,l表⽰32位⻓整数,s表⽰16位短整数。- 例如 htonl 表⽰将 32 位的⻓整数从主机字节序转换为⽹络字节序,例如将IP地址转换后准备发送。
- 如果主机是小端字节序, 这些函数将参数做相应的⼤⼩端转换然后返回;
- 如果主机是大端字节序, 这些函数不做转换,将参数原封不动地返回。
!!! 所有发送到网络上的数据,都必须是大端的!
4. socket 编程接口
4.1 socket 常见API
(1)创建socket文件描述符(TCP/UDP,客户端+服务器)
int socket (int domain,int type,int protocol);(2)绑定端(TCP/UDP,服务器)
int bind(int socket,const struct sockaddr *address, socklen_t address_len);(3)开始监听socket(TCP,服务器)
int listen(int socket, int backlog);(4)接收请求(TCP,服务器)
int accept(int socket, struct sockaddr* address, socklen_t* address_len);(5)建立连接(TCP,客户端)
int connect(int sockfd, const struct sockaddr *addr, socklen_t addrlen);4.2 sockaddr 结构
socket API (API->应用程序编程接口)是⼀层抽象的⽹络编程接⼝,适⽤于各种底层⽹络协议,如IPv4、IPv6,以及后⾯要讲的UNIX Domain Socket. 然⽽, 各种⽹络协议的地址格式并不相同.
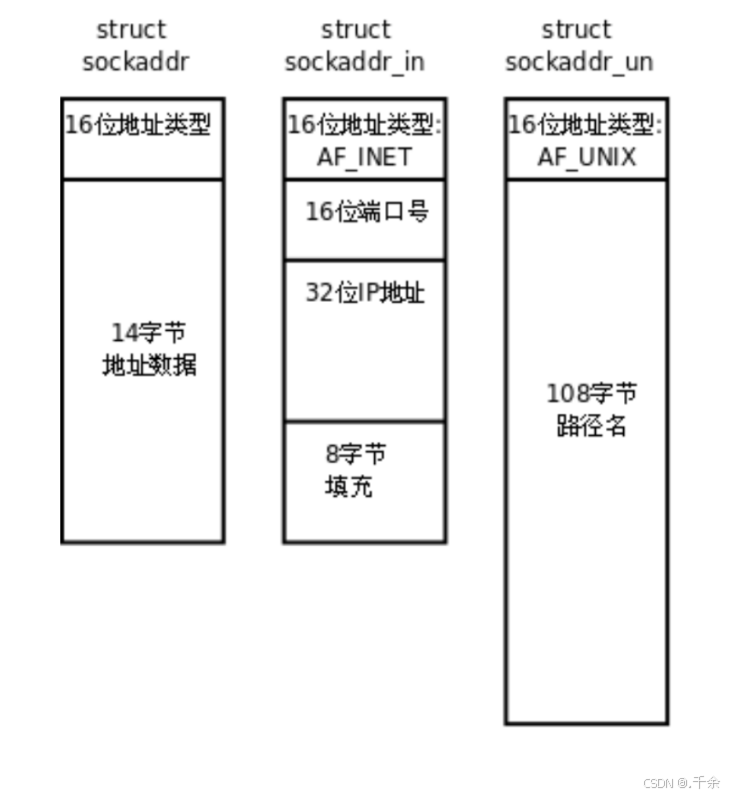
- IPv4和IPv6的地址格式定义在
netinet/in.h中,IPv4地址⽤sockaddr_in结构体表⽰,包括- 16位地址类型,
- 16位端⼝号
- 32位IP地址.
- IPv4、IPv6地址类型分别定义为
常数AF_INET、AF_INET6. 这样,只要取得某种sockaddr结构体的首地址,不需要知道具体是哪种类型的sockaddr结构体,就可以根据地址类型字段确定结构体中的内容. - socket API可以都⽤struct sockaddr 类型表⽰, 在使⽤的时候需要强制转化成sockaddr_in*; 这样的好处是程序的通⽤性, 可以接收IPv4, IPv6, 以及UNIX Domain Socket各种类型的sockaddr结构体指针做为参数
sockaddr 结构
struct sockaddr
{
__SOCKADDR_COMMON (sa_); /* Common data:address famliy and length.
char sa_data[14]; /* Address data. */
};sockaddr_in 结构
struct sockaddr_in
{
__SOCKADDR_COMMON (sin_);
in_port_t sin_port; // 端口号
struct in_addr sin_addr; // IP 地址
/* Pad to size of struct sockaddr. */
unsigned char sin_zero[sizeof (struct sockaddr)
- __SOCKADDR_COMMON_SIZE
- sizeof (in_port_t)
- sizeof (struct in_addr)];
};虽然socket api的接⼝是sockaddr, 但是我们真正在基于IPv4编程时, 使⽤的数据结构是sockaddr_in;这个结构⾥主要有三部分信息: 地址类型, 端⼝号, IP地址.
in_addr结构
typedef uint32_t in_addr_t;
struct int_addr
{
in_addr_t s_addr;
};in_addr⽤来表⽰⼀个IPv4的IP地址. 其实就是⼀个32位的整数;