重要声明或更新!!!
如果后面还要使用Hive,Java版本需要选Java8。
怎么换Java版本,下文里有。所以这里就不更新了。
Windows 11 WSL Ubuntu 环境:实际安装 Hive 踩坑实录
基于实际的安装(踩坑)体验,使用AI总结了完整的(体面的)安装指南。
Windows 11 WSL Ubuntu 环境:安装 Hadoop 完整指南
nano 和 vim(Linux 默认安装)的区别(文本编辑器 vs 专业编辑器)
本文是实际的安装过程,包含踩坑记录。
本文详细记录了在Windows 11 WSL Ubuntu环境中安装Hadoop 3.3.6的完整过程。
主要内容包括:
- 环境准备:安装Java 11(需注意Hadoop 3.3.6不兼容Java 17)、配置SSH免密登录
- Hadoop安装:下载清华镜像源文件,解压到/usr/local/hadoop,配置环境变量
- 关键配置:修改hadoop-env.sh、core-site.xml等配置文件,设置数据存储路径
- 启动流程:格式化NameNode,启动HDFS和YARN服务,验证6个核心进程
- 问题解决:处理Java版本冲突、SSH配置、Web界面访问等常见问题
- 日常管理:创建启动/停止脚本,提供一键操作命令
安装完成后,可通过http://localhost:9870访问HDFS,8080端口访问YARN。
文中特别强调了Java版本兼容性和SSH免密登录的重要性,并提供了详细的错误排查方法。最后还整理了常用HDFS命令和后续学习建议。
大数据开发初学者,自己的电脑:已有WSL环境(MySQL+Git+Python)+软件(SQLyog,MobaXterm,Oracle SQL Developer)+Oracle Database 21c XE+PyCharm,win11 环境,现在想用 Hadoop ,应该怎么操作。前面的操作都是用的教室里的电脑(win10专业版 Linux环境:CentOS Shell)和我的电脑不一样。
教室里的 CentOS 环境和你自己电脑的 WSL 环境,核心操作其实是一样的------都是 Linux 命令行。
唯一需要注意的差异是网络配置 。你无法像在教室那样通过 192.168.5.100 访问 Web 界面,而是必须使用 WSL 的 IP 地址或 localhost。不过对于你目前的学习阶段(单机练习基本命令),使用 localhost 完全够用,可以暂时不用纠结 IP 的问题。
方案一:在 WSL 中安装 Hadoop(伪分布式模式)------ 推荐
这是最适合初学者的方式。你已经有 WSL 环境了,直接在 Ubuntu 里安装 Hadoop,操作流程和你在教室学的几乎一模一样。
1. 环境准备(确认已完成)
-
Java 环境 :Hadoop 需要 Java,可以在 WSL 终端中运行
java -version确认。如果没有,执行sudo apt install openjdk-11-jdk -y安装。 -
SSH 服务:Hadoop 需要 SSH 来管理进程。
bash
sudo apt update sudo apt install openssh-server -y sudo service ssh start # 启动 SSH 服务
2. 安装与配置
-
下载并解压 :从 Apache 官网下载 Hadoop(如 3.3.6 版本),建议存放在
/usr/local/hadoop。bash
# 示例:下载并解压 wget https://dlcdn.apache.org/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz sudo tar -xzvf hadoop-3.3.6.tar.gz -C /usr/local/ sudo mv /usr/local/hadoop-3.3.6 /usr/local/hadoop -
配置环境变量 :编辑
~/.bashrc文件,在末尾添加:bash
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 # 请确认你的Java路径 export HADOOP_HOME=/usr/local/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin然后执行
source ~/.bashrc使其生效。 -
修改 Hadoop 配置文件 :所有配置文件都在
$HADOOP_HOME/etc/hadoop/目录下。-
hadoop-env.sh:找到export JAVA_HOME这一行,取消注释并修改为你的 Java 路径。 -
core-site.xml:配置 HDFS 的地址和临时目录。xml
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration> -
hdfs-site.xml:配置数据副本数(伪分布式设为1)。xml
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> </configuration>
-
-
设置 SSH 免密登录:这一步必须做,否则启动会失败。
bash
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
3. 启动集群
-
格式化 NameNode :注意:只在第一次启动前执行。
bash
hdfs namenode -format -
启动服务:
bash
start-dfs.sh start-yarn.sh -
验证 :运行
jps命令,如果看到 NameNode、DataNode 等 5 个左右的进程(加上 Jps 自己),就说明启动成功了。 -
Web 界面 :在 Windows 浏览器里访问
http://localhost:9870就能看到 HDFS 的 Web 界面。
方案二:使用 Docker 安装 Hadoop(更接近真实环境)
如果你对 Docker 不陌生,或者想尝试更贴近生产环境的部署方式,这是一个不错的选择。它能让你在一个干净的、隔离的环境里学习,不会弄乱你的 WSL 系统。
网上有很多配置好的 Hadoop Docker 镜像,你只需要拉取并运行即可。
1. 在 WSL 中安装 Docker
-
在 WSL 终端中执行以下命令来安装 Docker:
bash
curl -fsSL https://get.docker.com -o get-docker.sh sudo sh get-docker.sh -
安装完成后,你会需要将你的用户加入
docker用户组,这样就不用每次输入sudo了。
2. 运行 Hadoop 镜像
-
你可以直接使用社区提供的镜像,比如
bde2020/hadoop-namenode和bde2020/hadoop-datanode。更简单的方式是找一个docker-compose.yml文件来一键启动一个包含 NameNode 和 DataNode 的集群。 -
这种方式的优点是完全隔离,并且能更好地模拟集群环境。
💎 总结与对比
| 项目 | 方案一:WSL 直接安装 | 方案二:Docker 安装 |
|---|---|---|
| 上手难度 | 低。操作和教室环境几乎一样,你已有的笔记可以直接用。 | 中等。需要了解 Docker 的基本概念和命令。 |
| 环境依赖 | 需要在 WSL 里配置好 Java 和 SSH。 | 需要安装 Docker,但环境是镜像自带的。 |
| 与课堂笔记的契合度 | 高 。start-dfs.sh、jps 这些命令完全一样,只是 Web 界面访问方式略有不同。 |
低 。启动方式不是 start-all.sh,而是 docker-compose up,与你的笔记操作不同。 |
| 资源占用 | 较低,直接运行在 WSL 里。 | 稍高,因为多了一层 Docker 容器。 |
📝 接下来可以做什么?
考虑到你刚开始学习,并且已经有了课堂笔记,强烈建议选择方案一。
直接在你的 WSL 环境里动手尝试。你会发现,除了访问 Web 界面时的 IP 地址变成了 localhost,其他操作和你在教室的 CentOS 上几乎一模一样。这对于巩固学习成果非常有帮助。
如果在配置 SSH 免密登录时遇到 Connection refused 的错误,记得在 WSL 终端里执行 sudo service ssh start 来启动服务。
选择方案一:在 WSL 中安装 Hadoop。
bash
mumu@MuJinqiu:~$ java -version;
openjdk version "17.0.18" 2026-01-20
OpenJDK Runtime Environment (build 17.0.18+8-Ubuntu-124.04.1)
OpenJDK 64-Bit Server VM (build 17.0.18+8-Ubuntu-124.04.1, mixed mode, sharing)
mumu@MuJinqiu:~$你的 WSL 环境已经安装了 Java 17,可以继续安装 Hadoop。Hadoop 3.3.x 兼容 Java 8 和 Java 11/17,所以没问题。
这里有坑
Hadoop 3.3.x 不兼容Java 17,所以后面下载了Java11,但是系统默认版本没有自动同步修改,还需要手动切换系统默认的Java版本。
安装 SSH 服务(Hadoop 必需)
bash
# 1. 安装 SSH 服务器
sudo apt update
sudo apt install openssh-server -y
# 2. 启动 SSH 服务
sudo service ssh start
# 3. 验证 SSH 是否正常运行
sudo service ssh status
# 应该显示 "Active: active (running)"
# 4. 设置 SSH 免密登录(重要!)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 600 ~/.ssh/authorized_keys
# 5. 测试免密登录(应该不需要输入密码)
ssh localhost
# 登录成功后输入 exit 退出
exitSSH之前就有,好像设置过免密登录,还需要设置吗,或者怎么检查呢
快速检查免密登录是否已配置
bash
# 1、检查 SSH 服务状态
sudo service ssh status
# 应该显示 "Active: active (running)"
# 2. 检查是否有密钥文件
ls -la ~/.ssh/
# 3. 检查 authorized_keys 是否包含本机公钥
cat ~/.ssh/authorized_keys
# 4. 检查文件权限是否正确
ls -la ~/.ssh/authorized_keys
# 应该是 -rw------- (600 权限)
# 直接测试免密登录(最简单)
ssh localhost exit
# 完整测试流程
# 直接执行这个命令测试
ssh -v localhost exit 2>&1 | grep -E "Authenticated|password"
# 如果显示 Authenticated to localhost → 免密成功
# 如果显示 password → 需要密码我的输入及返回
bash
ssh localhost
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ED25519 key fingerprint is SHA256:EXoO7pR7FmoSrrNjWh7Vi42x5btDZXBvUFF38+saN24.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])?是 SSH 第一次连接时的正常安全提示,输入 yes 即可。
这说明:
-
✅ SSH 服务正常运行
-
⚠️ 这是首次连接确认(known_hosts 中没有 localhost 记录)
-
❓ 输入
yes后,如果还需要输入密码 → 说明免密未配置 -
✅ 输入
yes后直接登录成功 → 说明免密已配置
建议操作顺序
bash
# 1. 先完成首次连接确认(输入 yes)
ssh localhost
# 输入 yes 后,看是否要求密码
# 2. 如果要求密码,按 Ctrl+D 或输入 exit 退出,然后配置免密
# 3. 如果不需要密码直接登录,输入 exit 退出,说明已配置好
# 4. 最终确认
ssh localhost exit
# 直接返回命令行 → 完美上一步输入yes后页面频繁闪烁字符y
这是正常现象!按 Ctrl+C 取消
你遇到的情况是:输入 yes 后,系统把 y 当作重复输入的指令了。
这是因为某些终端或 SSH 版本在处理 yes/no 确认时,如果输入 yes 后按回车太快,或者终端有字符重复设置,会导致 y 被重复触发。
重新连接,但这次正确操作:
bash
# 1. 重新执行
ssh localhost
# 2. 当看到提示时,只输入完整的 yes,然后按回车
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
^^^
完整输入这三个字母,然后回车
# 注意:不要只输入 y,要输入完整的 yes
bash
mumu@MuJinqiu:~$ ssh localhost exit
The authenticity of host 'localhost (127.0.0.1)' can't be established.
ED25519 key fingerprint is SHA256:EXoO7pR7FmoSrrNjWh7Vi42x5btDZXBvUFF38+saN24.
This key is not known by any other names.
Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Warning: Permanently added 'localhost' (ED25519) to the list of known hosts.
mumu@localhost's password:看到了,SSH 服务正常,但免密登录没有配置成功(因为还在要求输入密码)。
现在需要配置免密登录。
配置免密登录
bash
# 1. 生成 SSH 密钥(如果已经有密钥文件可以跳过)
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa生成 SSH 密钥(如果已经有密钥文件可以跳过),怎么看是否已经有密钥文件呢
查看是否已有 SSH 密钥文件
bash
ls -la ~/.ssh/如果看到 id_rsa 和 id_rsa.pub ,说明已经有密钥了,不需要重新生成,直接跳到配置免密登录即可。
bash
mumu@MuJinqiu:~$ ls -la ~/.ssh/
total 24
drwx------ 2 mumu mumu 4096 Dec 12 13:19 .
drwxr-x--- 22 mumu mumu 4096 May 15 17:18 ..
-rw------- 1 mumu mumu 411 Dec 12 13:12 id_ed25519
-rw-r--r-- 1 mumu mumu 103 Dec 12 13:12 id_ed25519.pub
-rw------- 1 mumu mumu 1120 May 19 17:10 known_hosts
-rw-r--r-- 1 mumu mumu 142 Dec 12 13:07 known_hosts.old
mumu@MuJinqiu:~$你已经有密钥了!✅
你有 id_ed25519 和 id_ed25519.pub,这是 ED25519 类型的密钥(比 RSA 更新、更安全)。
不需要重新生成密钥,直接配置免密登录即可。
配置免密登录
bash
# 1. 将公钥添加到授权列表
cat ~/.ssh/id_ed25519.pub >> ~/.ssh/authorized_keys
# 2. 设置正确权限
chmod 600 ~/.ssh/authorized_keys
# 3. 测试免密登录
ssh localhost exit预期结果
配置成功后:
bash
mumu@MuJinqiu:~$ ssh localhost exit
# 没有任何密码提示,直接返回命令行
mumu@MuJinqiu:~$ 配置好了,继续安装 Hadoop
很好!免密登录配置成功,现在继续安装 Hadoop。
第一步:下载 Hadoop
bash
# 1. 进入家目录
cd ~
# 2. 创建下载目录(如果不存在)
mkdir -p downloads
cd downloads
# 3. 下载 Hadoop 3.3.6
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz这里有坑
下载慢的很(特别慢,下载进度几乎不动),换用国内(清华)镜像更快。
注意,换源下载之前,先把之前没下完的文件删掉。
下载 Hadoop 3.3.6 进度很慢,是不是因为电脑内存不够。
bash
mumu@MuJinqiu:~/projects$ df
Filesystem 1K-blocks Used Available Use% Mounted on
none 8189036 0 8189036 0% /usr/lib/modules/6.6.87.2-microsoft-standard-WSL2
none 8189036 4 8189032 1% /mnt/wsl
drivers 209715196 162348772 47366424 78% /usr/lib/wsl/drivers
/dev/sdd 1055762868 16829772 985229624 2% /
none 8189036 3096 8185940 1% /mnt/wslg
none 8189036 0 8189036 0% /usr/lib/wsl/lib
rootfs 8183996 2720 8181276 1% /init
none 8189036 544 8188492 1% /run
none 8189036 0 8189036 0% /run/lock
none 8189036 0 8189036 0% /run/shm
none 8189036 76 8188960 1% /mnt/wslg/versions.txt
none 8189036 76 8188960 1% /mnt/wslg/doc
C:\ 209715196 162348772 47366424 78% /mnt/c
D:\ 767198204 123262304 643935900 17% /mnt/d
tmpfs 1637804 20 1637784 1% /run/user/1000
mumu@MuJinqiu:~/projects$这是在VSCode编辑器中的WSL环境下的终端查的
用担心,下载慢和内存没关系 ✅
你的内存是正常的(8GB左右),下载慢是因为网络原因,不是电脑配置问题。
从 df 输出看:
-
你的硬盘空间充足(/ 目录有 985GB 可用)
-
内存正常(8GB 左右)
下载慢的原因
Apache 官方服务器在国外,国内下载速度本来就慢。
解决方案:使用国内镜像源
按 Ctrl+C 停止当前下载,然后用以下方法之一:
方法一:清华镜像源(推荐,速度快)
bash
cd ~/downloads
# 使用清华镜像下载 Hadoop 3.3.6
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz方法二:阿里云镜像源
bash
cd ~/downloads
# 使用阿里云镜像
wget https://mirrors.aliyun.com/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz方法三:中科大镜像源
bash
cd ~/downloads
# 使用中科大镜像
wget https://mirrors.ustc.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz检查当前下载状态
如果之前下载了一部分,可以:
bash
# 先停止当前下载(Ctrl+C)
# 查看文件大小
ls -lh ~/downloads/hadoop-3.3.6.tar.gz
# 如果已经有部分数据,可以删除重新下载
rm ~/downloads/hadoop-3.3.6.tar.gz
# 然后用国内镜像下载
wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz之前的忘记删了,现在已经在执行wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz 下载速度的确很快,怎么办
继续当前下载
bash
# 等待下载完成,会看到类似输出:
# 100%[======================================>] 123,456,789 10.2MB/s in 12s下载完成后验证
bash
# 检查文件是否完整
ls -lh ~/downloads/hadoop-3.3.6.tar.gz
# 应该显示大约 640MB 左右
# -rw-r--r-- 1 mumu mumu 640M May 19 17:30 hadoop-3.3.6.tar.gz
# 检查文件类型
file ~/downloads/hadoop-3.3.6.tar.gz
# 应该显示 gzip compressed data之前慢的下载已经停止,但是下载的文件没有删除
删除那个不完整的文件即可
之前慢速下载残留的不完整文件可以删除,避免占用空间或造成混淆。
先确认再删除
bash
# 1. 先查看文件大小,确认哪个是旧的不完整文件
ls -lh ~/downloads/hadoop-3.3.6.tar.gz
# 2. 如果显示很小(比如几 MB),说明是之前未完成的,可以删除
rm ~/downloads/hadoop-3.3.6.tar.gz
# 3. 如果显示正常大小(600+ MB),说明是刚下载完的,不要删
# 查看 downloads 目录所有 hadoop 相关文件
ls -lh ~/downloads/hadoop*
# 可能显示:
# hadoop-3.3.6.tar.gz ← 正在下载的(或者旧的)
# hadoop-3.3.6.tar.gz.1 ← 另一个副本
# hadoop-3.3.6.tar.gz.wget ← 临时文件
# 推荐的操作流程
# 1. 查看当前下载状态
ps aux | grep wget
# 确认当前下载正在运行,且进度正常
# 2. 等当前下载完成(100%)
# 看到类似输出:
# 100%[======================================>] 123,456,789 10.2MB/s in 12s
# 3. 下载完成后,删除旧的不完整文件(如果有)
# 先确认一下文件列表
ls -lh ~/downloads/
# 如果看到两个 hadoop 文件(一个正常大小,一个很小),删除小的那个
rm ~/downloads/hadoop-3.3.6.tar.gz # 删除小的
# 或者如果小的有别的名字,比如 hadoop-3.3.6.tar.gz.1
rm ~/downloads/hadoop-3.3.6.tar.gz.1我的下载进度和输出
bash
mumu@MuJinqiu:~/downloads$ wget https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
--2026-05-19 18:11:14-- https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.3.6/hadoop-3.3.6.tar.gz
Resolving mirrors.tuna.tsinghua.edu.cn (mirrors.tuna.tsinghua.edu.cn)... 101.6.15.130, 2402:f000:1:400::2
Connecting to mirrors.tuna.tsinghua.edu.cn (mirrors.tuna.tsinghua.edu.cn)|101.6.15.130|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 730107476 (696M) [application/octet-stream]
Saving to: 'hadoop-3.3.6.tar.gz.1'
hadoop-3.3.6.tar.gz.1 100%[=================================================================================>] 696.28M 7.61MB/s in 84s
2026-05-19 18:12:40 (8.27 MB/s) - 'hadoop-3.3.6.tar.gz.1' saved [730107476/730107476]
mumu@MuJinqiu:~/downloads$ ll
total 763892
drwxrwxr-x 2 mumu mumu 4096 May 19 18:11 ./
drwxr-x--- 23 mumu mumu 4096 May 19 17:15 ../
-rw-rw-r-- 1 mumu mumu 52103881 May 19 18:10 hadoop-3.3.6.tar.gz
-rw-rw-r-- 1 mumu mumu 730107476 Jun 26 2023 hadoop-3.3.6.tar.gz.1
mumu@MuJinqiu:~/downloads$完美!下载成功了!现在有两个文件:
| 文件 | 大小 | 状态 |
|---|---|---|
hadoop-3.3.6.tar.gz |
~52 MB | ❌ 旧的、不完整的(删除它) |
hadoop-3.3.6.tar.gz.1 |
~696 MB | ✅ 完整的、正确的(用这个) |
bash
# 第一步:删除不完整的文件
rm ~/downloads/hadoop-3.3.6.tar.gz
# 第二步:重命名完整文件
# 把 .1 去掉,变成标准名称
mv ~/downloads/hadoop-3.3.6.tar.gz.1 ~/downloads/hadoop-3.3.6.tar.gz
# 第三步:验证文件
# 确认文件大小约 696MB
ls -lh ~/downloads/hadoop-3.3.6.tar.gz完成后解压安装
bash
# 解压到 /usr/local
sudo tar -xzvf ~/downloads/hadoop-3.3.6.tar.gz -C /usr/local/
# 重命名文件夹
sudo mv /usr/local/hadoop-3.3.6 /usr/local/hadoop
# 修改权限(将 mumu 改为你的用户名)
sudo chown -R mumu:mumu /usr/local/hadoop验证解压成功
bash
# 查看 Hadoop 目录
ls -la /usr/local/hadoop/
# 应该看到 bin, etc, lib, sbin 等目录我的解压输出
bash
mumu@MuJinqiu:~/downloads$ ls -la /usr/local/hadoop/
total 120
drwxr-xr-x 10 mumu mumu 4096 Jun 18 2023 .
drwxr-xr-x 11 root root 4096 May 19 18:16 ..
-rw-rw-r-- 1 mumu mumu 24276 Jun 14 2023 LICENSE-binary
-rw-rw-r-- 1 mumu mumu 15217 Jun 10 2023 LICENSE.txt
-rw-rw-r-- 1 mumu mumu 29473 Jun 10 2023 NOTICE-binary
-rw-rw-r-- 1 mumu mumu 1541 Jun 10 2023 NOTICE.txt
-rw-rw-r-- 1 mumu mumu 175 Jun 10 2023 README.txt
drwxr-xr-x 2 mumu mumu 4096 Jun 18 2023 bin
drwxr-xr-x 3 mumu mumu 4096 Jun 18 2023 etc
drwxr-xr-x 2 mumu mumu 4096 Jun 18 2023 include
drwxr-xr-x 3 mumu mumu 4096 Jun 18 2023 lib
drwxr-xr-x 4 mumu mumu 4096 Jun 18 2023 libexec
drwxr-xr-x 2 mumu mumu 4096 Jun 18 2023 licenses-binary
drwxr-xr-x 3 mumu mumu 4096 Jun 18 2023 sbin
drwxr-xr-x 4 mumu mumu 4096 Jun 18 2023 share
mumu@MuJinqiu:~/downloads$太好了!Hadoop 已经成功解压到 /usr/local/hadoop/,权限也是正确的(mumu 用户拥有)。
下一步:配置环境变量
bash
# 1. 编辑 .bashrc
nano ~/.bashrc在文件末尾添加以下内容:
bash
# Hadoop Environment Variables
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin这里有坑
这里用的 nano 我不会也不了解(导致无意输入了i字符,后面报错又重新修改,浪费了很多时间),其实可以改用 vim ,都是编辑器。
另外,还有其他配置方式,不一定要自己进去手动修改。可以一键复制(AI提供的)修改。
注意:
.bashrc文件中有两行JAVA_HOME(重复了),但没关系,可以正常工作。最佳实践是删除重复的,仅保留一行。
退出后验证
bash
# 1. 确认文件已保存
cat ~/.bashrc | grep HADOOP
# 应该看到你添加的配置
# 2. 使配置生效
source ~/.bashrc
# 3. 验证
hadoop version我的输出:.bashrc 文件出现了语法错误,第一行被损坏了。
这就是我前面说的,因为不熟悉nano,导致的错误。
bash
mumu@MuJinqiu:~/downloads$ # 1. 编辑 .bashrc
nano ~/.bashrc
mumu@MuJinqiu:~/downloads$ nano ~/.bashrc
mumu@MuJinqiu:~/downloads$ cat ~/.bashrc | grep HADOOP
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
mumu@MuJinqiu:~/downloads$ source ~/.bashrc
-bash: /home/mumu/.bashrc: line 1: syntax error near unexpected token `('
-bash: /home/mumu/.bashrc: line 1: `i# ~/.bashrc: executed by bash(1) for non-login shells.'
mumu@MuJinqiu:~/downloads$ hadoop version
hadoop: command not found
mumu@MuJinqiu:~/downloads$检查并修复 .bashrc
bash
# 1. 查看文件前几行,看看具体问题
head -5 ~/.bashrc根据你的错误信息,第一行显示 i# ~/.bashrc: executed by bash(1)...,前面多了一个 i 字母。
bash
mumu@MuJinqiu:~/downloads$ head -5 ~/.bashrc
i# ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
# If not running interactively, don't do anything
mumu@MuJinqiu:~/downloads$看到问题了!第一行开头确实多了一个 i 字母。
用 sed 命令直接修复(更快)
bash
# 直接删除第一行开头的 i 字母
sed -i '1s/^i//' ~/.bashrc
# 验证修复结果
head -5 ~/.bashrc修复 .bashrc 文件后 重新加载配置
bash
# 1. 确认第一行已修复
head -5 ~/.bashrc
# 应该显示:
# # ~/.bashrc: executed by bash(1) for non-login shells.
# # see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# ...
# 2. 使配置生效
source ~/.bashrc
# 3. 验证 Hadoop 命令
hadoop version✅ .bashrc 已修复,Hadoop 命令也正常工作了!
bash
mumu@MuJinqiu:~/downloads$ head -5 ~/.bashrc
i# ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
# If not running interactively, don't do anything
mumu@MuJinqiu:~/downloads$ ^C
mumu@MuJinqiu:~/downloads$ nano ~/.bashrc
mumu@MuJinqiu:~/downloads$ head -5 ~/.bashrc
# ~/.bashrc: executed by bash(1) for non-login shells.
# see /usr/share/doc/bash/examples/startup-files (in the package bash-doc)
# for examples
# If not running interactively, don't do anything
mumu@MuJinqiu:~/downloads$ source ~/.bashrc
mumu@MuJinqiu:~/downloads$ hadoop version
Hadoop 3.3.6
Source code repository https://github.com/apache/hadoop.git -r 1be78238728da9266a4f88195058f08fd012bf9c
Compiled by ubuntu on 2023-06-18T08:22Z
Compiled on platform linux-x86_64
Compiled with protoc 3.7.1
From source with checksum 5652179ad55f76cb287d9c633bb53bbd
This command was run using /usr/local/hadoop/share/hadoop/common/hadoop-common-3.3.6.jar
mumu@MuJinqiu:~/downloads$现在继续配置 Hadoop 的核心文件。
第一步:进入配置目录
bash
cd $HADOOP_HOME/etc/hadoop第二步:配置 hadoop-env.sh
bash
nano hadoop-env.sh找到 export JAVA_HOME 这一行,修改为:
bash
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64保存退出(Ctrl+O,Enter,Ctrl+X)
这里有坑
找到 export JAVA_HOME 这一行,非常难找,因为文件中有大量注释。只有 export HADOOP_OS_TYPE={HADOOP_OS_TYPE:-(uname -s)} 这一行没有被注释。
我就没找到,以为没有。其实是有的,只不过被注释了。
第三步:配置 core-site.xml
bash
nano core-site.xml将文件内容全部替换为:
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/mumu/hadoop_tmp</value>
</property>
</configuration>第四步:配置 hdfs-site.xml
bash
nano hdfs-site.xml替换为:
xml
<?xml version="1.0" encoding="UTF-8"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/mumu/hadoop_tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/mumu/hadoop_tmp/dfs/data</value>
</property>
</configuration>第五步:配置 yarn-site.xml
bash
nano yarn-site.xml输入:
xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>第六步:配置 mapred-site.xml
配置 mapred-site.xml,需要把原来的内容清空吗
是的,建议清空原内容
mapred-site.xml文件可能存在也可能不存在,取决于 Hadoop 版本。
bash# 查看文件是否存在及内容 ls -la mapred-site.xml cat mapred-site.xml
bash
nano mapred-site.xml输入:
xml
<?xml version="1.0"?>
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>第七步:创建数据目录
bash
mkdir -p /home/mumu/hadoop_tmp/dfs/name
mkdir -p /home/mumu/hadoop_tmp/dfs/data第八步:格式化 NameNode
bash
hdfs namenode -format看到 Successfully formatted 表示成功。
这里有坑
如果前面的配置文件内容不对(如误写误操作),格式化都将失败。
第九步:启动 Hadoop
bash
start-dfs.sh
start-yarn.sh第十步:验证
等待 30 秒后:
bash
jps应该看到:
text
NameNode
DataNode
SecondaryNameNode
ResourceManager
NodeManager
Jps这里有坑
可能进程不够,会缺少进程
找到 export JAVA_HOME 这一行,没有这一行,文件中有大量注释。只有 export HADOOP_OS_TYPE={HADOOP_OS_TYPE:-(uname -s)} 这一行没有被注释。
明白了,新版本的 Hadoop 配置方式不同。
找到正确的位置插入
虽然不是必须的,但更规范的做法是在 export HADOOP_OS_TYPE 这行之前插入:
bash
# 在 nano 中,找到这一行:
export HADOOP_OS_TYPE=${HADOOP_OS_TYPE:-$(uname -s)}
# 在这一行的上面添加:
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64验证配置
bash
# 确认 JAVA_HOME 已设置
grep -i java_home $HADOOP_HOME/etc/hadoop/hadoop-env.sh应该显示:
bash
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64为什么新版本没有 JAVA_HOME 行?
Hadoop 3.3+ 版本中,hadoop-env.sh 默认不包含 JAVA_HOME 的配置行,因为:
-
Hadoop 会尝试从系统环境变量中读取
JAVA_HOME -
如果系统环境变量已设置(你已经在
.bashrc中设置了),理论上可以不配置 -
但为了保险,还是在
hadoop-env.sh中显式配置一次
文件中有被注释掉的 JAVA_HOME 配置。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ grep -i java_home $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# JAVA_HOME=/usr/java/testing hdfs dfs -ls
# Technically, the only required environment variable is JAVA_HOME.
# export JAVA_HOME=
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$我们需要取消注释并设置正确的路径。
bash
# 修改 hadoop-env.sh
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# 找到这行
# export JAVA_HOME=
# 修改为
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64操作步骤:
-
在 nano 中按
Ctrl+W搜索 -
输入
JAVA_HOME,按回车 -
用方向键移动到
# export JAVA_HOME=这一行 -
删除开头的
#和空格 -
在等号后面添加:
/usr/lib/jvm/java-17-openjdk-amd64 -
最终效果:
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64 -
保存退出:
Ctrl+O,Enter,Ctrl+X
然后继续配置其他文件
Hadoop 已经启动,但目前只看到 4 个进程
bash
SHUTDOWN_MSG: Shutting down NameNode at MuJinqiu/127.0.1.1
************************************************************/
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ start-dfs.sh
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [MuJinqiu]
MuJinqiu: Warning: Permanently added 'mujinqiu' (ED25519) to the list of known hosts.
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ jps
982376 SecondaryNameNode
983896 Jps
982151 DataNode
981969 NameNode
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$Hadoop 已经启动,但目前只看到 4 个进程,缺少 ResourceManager 和 NodeManager(YARN 的进程)。
当前状态分析
| 进程 | 状态 | 说明 |
|---|---|---|
| NameNode | ✅ 运行中 | HDFS 主节点 |
| DataNode | ✅ 运行中 | HDFS 数据节点 |
| SecondaryNameNode | ✅ 运行中 | HDFS 辅助节点 |
| ResourceManager | ❌ 未运行 | YARN 资源管理器 |
| NodeManager | ❌ 未运行 | YARN 节点管理器 |
检查 YARN 启动日志
bash
# 查看 ResourceManager 日志
tail -50 $HADOOP_HOME/logs/*resourcemanager*.log需要重新打开一个窗口执行吗
不需要,在当前窗口继续执行即可
你当前的 Hadoop 进程(NameNode、DataNode、SecondaryNameNode)已经在运行了,直接在同一个窗口执行诊断命令就行。
注意
不需要新开窗口,一个窗口就够了
Hadoop 启动后会在后台运行,不影响你输入命令
如果在启动 Hadoop 的窗口按
Ctrl+C只会中断当前命令,不会关闭已启动的 Hadoop 服务
直接在当前窗口执行
bash
# 1. 检查 yarn-site.xml 内容是否正确
cat $HADOOP_HOME/etc/hadoop/yarn-site.xml
# 2. 查看 YARN 相关日志
ls -la $HADOOP_HOME/logs/ | grep -E "resourcemanager|nodemanager"
# 3. 查看 ResourceManager 日志(如果有的话)
tail -30 $HADOOP_HOME/logs/*resourcemanager*.log 2>/dev/null
# 4. 查看 NodeManager 日志
tail -30 $HADOOP_HOME/logs/*nodemanager*.log 2>/dev/null快速重新启动 YARN
bash
# 在当前窗口直接执行
stop-yarn.sh
start-yarn.sh
# 等待 10 秒
sleep 10
# 查看进程
jps如果还是不行,用这个完整重启
bash
# 停止所有服务
stop-all.sh
# 等待几秒
sleep 5
# 重新启动
start-all.sh
# 等待 30 秒
sleep 30
# 查看所有进程
jpsyarn-site.xml 配置正确。现在检查 YARN 进程和日志。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ cat $HADOOP_HOME/etc/hadoop/yarn-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$检查 YARN 进程状态
bash
# 查看所有 Hadoop 相关进程
ps aux | grep -E "resourcemanager|nodemanager|yarn" | grep -v grep查看 YARN 启动日志
bash
# 查看 logs 目录
ls -la $HADOOP_HOME/logs/
# 查看 ResourceManager 日志
cat $HADOOP_HOME/logs/*resourcemanager*.log 2>/dev/null | tail -50
# 查看 NodeManager 日志
cat $HADOOP_HOME/logs/*nodemanager*.log 2>/dev/null | tail -50尝试重新启动 YARN
从输出看,只有 HDFS 的进程在运行(NameNode、DataNode、SecondaryNameNode),YARN 的 ResourceManager 和 NodeManager 完全没有启动。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ ps aux | grep -E "resourcemanager|nodemanager|yarn" | grep -v grep
mumu 981969 1.2 1.6 6106832 264028 ? Sl 18:50 0:04 /usr/lib/jvm/java-17-openjdk-amd64/bin/java -Dproc_namenode -Djava.net.preferIPv4Stack=true -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dyarn.log.dir=/usr/local/hadoop/logs -Dyarn.log.file=hadoop-mumu-namenode-MuJinqiu.log -Dyarn.home.dir=/usr/local/hadoop -Dyarn.root.logger=INFO,console -Djava.library.path=/usr/local/hadoop/lib/native -Dhadoop.log.dir=/usr/local/hadoop/logs -Dhadoop.log.file=hadoop-mumu-namenode-MuJinqiu.log -Dhadoop.home.dir=/usr/local/hadoop -Dhadoop.id.str=mumu -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.namenode.NameNode
mumu 982151 1.1 1.3 6118920 214280 ? Sl 18:50 0:04 /usr/lib/jvm/java-17-openjdk-amd64/bin/java -Dproc_datanode -Djava.net.preferIPv4Stack=true -Dhadoop.security.logger=ERROR,RFAS -Dyarn.log.dir=/usr/local/hadoop/logs -Dyarn.log.file=hadoop-mumu-datanode-MuJinqiu.log -Dyarn.home.dir=/usr/local/hadoop -Dyarn.root.logger=INFO,console -Djava.library.path=/usr/local/hadoop/lib/native -Dhadoop.log.dir=/usr/local/hadoop/logs -Dhadoop.log.file=hadoop-mumu-datanode-MuJinqiu.log -Dhadoop.home.dir=/usr/local/hadoop -Dhadoop.id.str=mumu -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.datanode.DataNode
mumu 982376 0.9 1.5 6083888 258548 ? Sl 18:50 0:03 /usr/lib/jvm/java-17-openjdk-amd64/bin/java -Dproc_secondarynamenode -Djava.net.preferIPv4Stack=true -Dhdfs.audit.logger=INFO,NullAppender -Dhadoop.security.logger=INFO,RFAS -Dyarn.log.dir=/usr/local/hadoop/logs -Dyarn.log.file=hadoop-mumu-secondarynamenode-MuJinqiu.log -Dyarn.home.dir=/usr/local/hadoop -Dyarn.root.logger=INFO,console -Djava.library.path=/usr/local/hadoop/lib/native -Dhadoop.log.dir=/usr/local/hadoop/logs -Dhadoop.log.file=hadoop-mumu-secondarynamenode-MuJinqiu.log -Dhadoop.home.dir=/usr/local/hadoop -Dhadoop.id.str=mumu -Dhadoop.root.logger=INFO,RFA -Dhadoop.policy.file=hadoop-policy.xml org.apache.hadoop.hdfs.server.namenode.SecondaryNameNode
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$查看 YARN 日志找原因
bash
bash
# 查看 yarn 相关日志文件
ls -la $HADOOP_HOME/logs/ | grep -i yarn
# 查看 resourcemanager 日志(如果存在)
cat $HADOOP_HOME/logs/*resourcemanager*.log 2>/dev/null | head -50
# 查看 yarn 启动脚本的日志
cat $HADOOP_HOME/logs/hadoop-mumu-resourcemanager-MuJinqiu.log 2>/dev/null | tail -50手动启动 YARN 并查看错误
bash
bash
# 尝试手动启动 resourcemanager 看报错
$HADOOP_HOME/bin/yarn --daemon start resourcemanager
# 等待 3 秒
sleep 3
# 查看是否启动成功
ps aux | grep ResourceManager | grep -v grep找到问题了!这是 Java 17 与 Hadoop 3.3.6 的兼容性问题。Hadoop 3.3.6 不完全支持 Java 17,需要降级到 Java 11 或 Java 8。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ ls -la $HADOOP_HOME/logs/ | grep -i yarn
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ cat $HADOOP_HOME/logs/hadoop-mumu-resourcemanager-MuJinqiu.log 2>/dev/null | tail -50
2026-05-19 18:50:43,075 INFO org.apache.hadoop.http.HttpServer2: Added filter RMAuthenticationFilter (class=org.apache.hadoop.yarn.server.security.http.RMAuthenticationFilter) to context static
2026-05-19 18:50:43,076 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context cluster
2026-05-19 18:50:43,076 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context logs
2026-05-19 18:50:43,076 INFO org.apache.hadoop.http.HttpServer2: Added filter static_user_filter (class=org.apache.hadoop.http.lib.StaticUserWebFilter$StaticUserFilter) to context static
2026-05-19 18:50:43,190 ERROR org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Error starting ResourceManager
java.lang.ExceptionInInitializerError
at com.google.inject.internal.cglib.reflect.$FastClassEmitter.<init>(FastClassEmitter.java:67)
at com.google.inject.internal.cglib.reflect.$FastClass$Generator.generateClass(FastClass.java:72)
at com.google.inject.internal.cglib.core.$DefaultGeneratorStrategy.generate(DefaultGeneratorStrategy.java:25)
at com.google.inject.internal.cglib.core.$AbstractClassGenerator.create(AbstractClassGenerator.java:216)
at com.google.inject.internal.cglib.reflect.$FastClass$Generator.create(FastClass.java:64)
at com.google.inject.internal.BytecodeGen.newFastClass(BytecodeGen.java:204)
at com.google.inject.internal.ProviderMethod$FastClassProviderMethod.<init>(ProviderMethod.java:256)
at com.google.inject.internal.ProviderMethod.create(ProviderMethod.java:71)
at com.google.inject.internal.ProviderMethodsModule.createProviderMethod(ProviderMethodsModule.java:275)
at com.google.inject.internal.ProviderMethodsModule.getProviderMethods(ProviderMethodsModule.java:144)
at com.google.inject.internal.ProviderMethodsModule.configure(ProviderMethodsModule.java:123)
at com.google.inject.spi.Elements$RecordingBinder.install(Elements.java:340)
at com.google.inject.spi.Elements$RecordingBinder.install(Elements.java:349)
at com.google.inject.AbstractModule.install(AbstractModule.java:122)
at com.google.inject.servlet.ServletModule.configure(ServletModule.java:52)
at com.google.inject.AbstractModule.configure(AbstractModule.java:62)
at com.google.inject.spi.Elements$RecordingBinder.install(Elements.java:340)
at com.google.inject.spi.Elements.getElements(Elements.java:110)
at com.google.inject.internal.InjectorShell$Builder.build(InjectorShell.java:138)
at com.google.inject.internal.InternalInjectorCreator.build(InternalInjectorCreator.java:104)
at com.google.inject.Guice.createInjector(Guice.java:96)
at com.google.inject.Guice.createInjector(Guice.java:73)
at com.google.inject.Guice.createInjector(Guice.java:62)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.build(WebApps.java:417)
at org.apache.hadoop.yarn.webapp.WebApps$Builder.start(WebApps.java:465)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.startWepApp(ResourceManager.java:1389)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.serviceStart(ResourceManager.java:1498)
at org.apache.hadoop.service.AbstractService.start(AbstractService.java:194)
at org.apache.hadoop.yarn.server.resourcemanager.ResourceManager.main(ResourceManager.java:1700)
Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make protected final java.lang.Class java.lang.ClassLoader.defineClass(java.lang.String,byte[],int,int,java.security.ProtectionDomain) throws java.lang.ClassFormatError accessible: module java.base does not "opens java.lang" to unnamed module @7fab8c68
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:354)
at java.base/java.lang.reflect.AccessibleObject.checkCanSetAccessible(AccessibleObject.java:297)
at java.base/java.lang.reflect.Method.checkCanSetAccessible(Method.java:200)
at java.base/java.lang.reflect.Method.setAccessible(Method.java:194)
at com.google.inject.internal.cglib.core.$ReflectUtils$2.run(ReflectUtils.java:56)
at java.base/java.security.AccessController.doPrivileged(AccessController.java:318)
at com.google.inject.internal.cglib.core.$ReflectUtils.<clinit>(ReflectUtils.java:46)
... 29 more
2026-05-19 18:50:43,193 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioning to standby state
2026-05-19 18:50:43,193 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: Transitioned to standby state
2026-05-19 18:50:43,193 INFO org.apache.hadoop.yarn.server.resourcemanager.ResourceManager: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down ResourceManager at MuJinqiu/127.0.1.1
************************************************************/
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$解决方案:安装 Java 11
bash
# 1. 安装 Java 11
sudo apt update
sudo apt install openjdk-11-jdk -y
# 2. 查看 Java 11 的安装路径
ls -la /usr/lib/jvm/ | grep java-11
# 3. 更新环境变量
nano ~/.bashrc修改 .bashrc 中的 JAVA_HOME
找到这一行:
bash
export JAVA_HOME=/usr/lib/jvm/java-17-openjdk-amd64改为:
bash
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64保存退出(Ctrl+O,Enter,Ctrl+X)
bash
# 4. 使配置生效
source ~/.bashrc
# 5. 验证 Java 版本
java -version
# 应该显示 openjdk version "11.x.x"更新 Hadoop 配置中的 JAVA_HOME
bash
# 更新 hadoop-env.sh
sed -i 's|/usr/lib/jvm/java-17-openjdk-amd64|/usr/lib/jvm/java-11-openjdk-amd64|g' $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# 更新 yarn-env.sh(添加 Java 11 配置)
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> $HADOOP_HOME/etc/hadoop/yarn-env.sh重新启动 Hadoop
bash
# 1. 停止所有服务
stop-all.sh
# 2. 清理临时文件(可选)
rm -rf /home/mumu/hadoop_tmp/dfs/name/*
rm -rf /home/mumu/hadoop_tmp/dfs/data/*
# 3. 重新格式化 NameNode(需要)
hdfs namenode -format
# 4. 启动所有服务
start-all.sh
# 5. 等待 30 秒
sleep 30
# 6. 验证进程
jpsJava 11 已经安装成功了。现在更新配置并重启 Hadoop。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ ls -la /usr/lib/jvm/ | grep java-11
lrwxrwxrwx 1 root root 21 Jan 23 07:22 java-1.11.0-openjdk-amd64 -> java-11-openjdk-amd64
drwxr-xr-x 9 root root 4096 May 19 18:58 java-11-openjdk-amd64
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$很好!Java 11 已经安装成功了。现在更新配置并重启 Hadoop。
更新环境变量
bash
# 1. 更新 .bashrc 中的 JAVA_HOME
sed -i 's|JAVA_HOME=.*/java-17.*|JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64|' ~/.bashrc
# 2. 使配置生效
source ~/.bashrc
# 3. 验证 Java 版本
java -version更新 Hadoop 配置
bash
# 4. 更新 hadoop-env.sh
sed -i 's|/usr/lib/jvm/java-17-openjdk-amd64|/usr/lib/jvm/java-11-openjdk-amd64|g' $HADOOP_HOME/etc/hadoop/hadoop-env.sh
# 5. 添加 yarn-env.sh 配置
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> $HADOOP_HOME/etc/hadoop/yarn-env.sh重新启动 Hadoop
bash
# 6. 停止所有服务
stop-all.sh
# 7. 清理临时文件(重要!)
rm -rf /home/mumu/hadoop_tmp/dfs/name/*
rm -rf /home/mumu/hadoop_tmp/dfs/data/*
# 8. 重新格式化 NameNode
hdfs namenode -format当提示是否重新格式化时,输入 Y 然后回车。
bash
# 9. 启动所有服务
start-all.sh
# 10. 等待 30 秒
sleep 30
# 11. 验证进程
jps一键执行(推荐)
复制粘贴以下命令一次性执行:
bash
# 更新配置
sed -i 's|JAVA_HOME=.*/java-17.*|JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64|' ~/.bashrc
source ~/.bashrc
sed -i 's|/usr/lib/jvm/java-17-openjdk-amd64|/usr/lib/jvm/java-11-openjdk-amd64|g' $HADOOP_HOME/etc/hadoop/hadoop-env.sh
echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> $HADOOP_HOME/etc/hadoop/yarn-env.sh
# 验证 Java
echo "Java version:"
java -version
# 重启 Hadoop
echo "Restarting Hadoop..."
stop-all.sh
rm -rf /home/mumu/hadoop_tmp/dfs/name/* /home/mumu/hadoop_tmp/dfs/data/*
# 格式化(需要手动输入 Y)
echo "Please enter Y when prompted to format NameNode"
hdfs namenode -format
# 启动
start-all.sh
sleep 30
# 验证
echo "=== Hadoop Processes ==="
jps注意 :格式化时系统会提示你是否确认,需要输入 Y 然后回车。
执行完后,把 jps 的输出发给我,应该能看到 6 个进程了!
Java 版本还是 17,说明 .bashrc 的修改没有生效。需要检查并手动修改。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ sed -i 's|JAVA_HOME=.*/java-17.*|JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64|' ~/.bashrc
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ source ~/.bashrc
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ java -version
openjdk version "17.0.18" 2026-01-20
OpenJDK Runtime Environment (build 17.0.18+8-Ubuntu-124.04.1)
OpenJDK 64-Bit Server VM (build 17.0.18+8-Ubuntu-124.04.1, mixed mode, sharing)
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ sed -i 's|/usr/lib/jvm/java-17-openjdk-amd64|/usr/lib/jvm/java-11-openjdk-amd64|g' $HADOOP_HOME/etc/hadoop/hadoop-env.sh
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ echo 'export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64' >> $HADOOP_HOME/etc/hadoop/yarn-env.sh
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$检查 .bashrc 中的 JAVA_HOME
bash
# 查看当前 .bashrc 中的 JAVA_HOME 设置
grep JAVA_HOME ~/.bashrc手动编辑 .bashrc
bash
nano ~/.bashrc找到所有 JAVA_HOME 相关的行,确保是:
bash
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64注意 :如果有多行 JAVA_HOME,只保留一行正确的。
保存退出(Ctrl+O,Enter,Ctrl+X)
重新加载并验证
bash
# 重新加载
source ~/.bashrc
# 验证
echo $JAVA_HOME
# 应该显示 /usr/lib/jvm/java-11-openjdk-amd64
# 验证 java 版本
$JAVA_HOME/bin/java -version
# 应该显示 openjdk version "11.x.x".bashrc 配置正确,但系统默认 Java 还是 17。需要切换系统默认 Java 版本。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ grep JAVA_HOME ~/.bashrc
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$.bashrc 配置正确,但系统默认 Java 还是 17。需要切换系统默认 Java 版本。
切换系统默认 Java 到 11
bash
bash
# 1. 查看所有可用的 Java 版本
sudo update-alternatives --config java你会看到类似输出:
text
There are 2 choices for the alternative java (providing /usr/bin/java).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/lib/jvm/java-17-openjdk-amd64/bin/java 1711 auto mode
1 /usr/lib/jvm/java-11-openjdk-amd64/bin/java 1111 manual mode
2 /usr/lib/jvm/java-17-openjdk-amd64/bin/java 1711 manual mode
Press <enter> to keep the current choice[*], or type selection number:输入 1 选择 Java 11,然后按回车。
bash
# 2. 验证 Java 版本
java -version现在应该显示 openjdk version "11.0.xx"
输入 1 然后按回车,选择 Java 11。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ sudo update-alternatives --config java
There are 2 choices for the alternative java (providing /usr/bin/java).
Selection Path Priority Status
------------------------------------------------------------
* 0 /usr/lib/jvm/java-17-openjdk-amd64/bin/java 1711 auto mode
1 /usr/lib/jvm/java-11-openjdk-amd64/bin/java 1111 manual mode
2 /usr/lib/jvm/java-17-openjdk-amd64/bin/java 1711 manual mode
Press <enter> to keep the current choice[*], or type selection number:然后验证 Java 版本
bash
java -versionJava 11 已成功切换并生效。现在重新启动 Hadoop。
bash
Press <enter> to keep the current choice[*], or type selection number: 1
update-alternatives: using /usr/lib/jvm/java-11-openjdk-amd64/bin/java to provide /usr/bin/java (java) in manual mode
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ java --version
openjdk 11.0.30 2026-01-20
OpenJDK Runtime Environment (build 11.0.30+7-post-Ubuntu-1ubuntu124.04)
OpenJDK 64-Bit Server VM (build 11.0.30+7-post-Ubuntu-1ubuntu124.04, mixed mode, sharing)
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ ^C
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ echo $JAVA_HOME
/usr/lib/jvm/java-11-openjdk-amd64
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$重新启动 Hadoop
bash
# 1. 停止所有服务
stop-all.sh
# 2. 清理临时文件
rm -rf /home/mumu/hadoop_tmp/dfs/name/*
rm -rf /home/mumu/hadoop_tmp/dfs/data/*
# 3. 重新格式化 NameNode
hdfs namenode -format当提示 Re-format filesystem in Storage directory... 时,输入 Y 然后回车。
bash
# 4. 启动所有服务
start-all.sh
# 5. 等待 30 秒让服务完全启动
sleep 30
# 6. 验证进程
jps一键执行(复制粘贴)
bash
stop-all.sh && \
rm -rf /home/mumu/hadoop_tmp/dfs/name/* /home/mumu/hadoop_tmp/dfs/data/* && \
echo "Formatting NameNode (please enter Y when prompted)..." && \
hdfs namenode -format && \
echo "Starting Hadoop..." && \
start-all.sh && \
echo "Waiting 30 seconds for services to start..." && \
sleep 30 && \
echo "=== Hadoop Processes ===" && \
jps预期结果
执行后应该看到:
text
NameNode
DataNode
SecondaryNameNode
ResourceManager
NodeManager
Jps验证 Web 界面
在 Windows 浏览器中打开:
-
HDFS:
http://localhost:9870 -
YARN:
http://localhost:8088
执行上面的命令,把 jps 的输出发给我!
Hadoop 启动成功!
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ jps
992666 SecondaryNameNode
992265 NameNode
993621 Jps
992450 DataNode
992913 ResourceManager
993248 NodeManager
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$你现在有 6 个进程,全部正常运行:
| 进程 | 状态 | 作用 |
|---|---|---|
| NameNode | ✅ | HDFS 主节点 |
| DataNode | ✅ | HDFS 数据节点 |
| SecondaryNameNode | ✅ | HDFS 辅助节点 |
| ResourceManager | ✅ | YARN 资源管理器 |
| NodeManager | ✅ | YARN 节点管理器 |
| Jps | ✅ | Java 进程查看工具 |
现在可以测试 Hadoop 了
1. 测试 HDFS 命令
bash
# 创建目录
hdfs dfs -mkdir -p /user/mumu/test
# 上传文件
echo "Hello Hadoop" > test.txt
hdfs dfs -put test.txt /user/mumu/test/
# 查看文件
hdfs dfs -ls /user/mumu/test/
hdfs dfs -cat /user/mumu/test/test.txt
# 查看 HDFS 根目录
hdfs dfs -ls /2. 访问 Web 界面
在 Windows 浏览器中打开:
-
HDFS Web UI :
http://localhost:9870 -
YARN Web UI :
http://localhost:8088
3. 运行一个简单的 MapReduce 示例
bash
# 创建输入目录和文件
hdfs dfs -mkdir -p /input
echo "hello world" > file1.txt
echo "hello hadoop" > file2.txt
hdfs dfs -put file1.txt /input/
hdfs dfs -put file2.txt /input/
# 运行 wordcount 示例
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /input /output
# 查看结果
hdfs dfs -cat /output/part-r-00000常用管理命令
bash
# 查看 HDFS 报告
hdfs dfsadmin -report
# 查看集群状态
yarn node -list
# 停止所有服务
stop-all.sh
# 启动所有服务
start-all.sh总结
Hadoop 已经成功安装并运行!你现在的环境:
-
✅ WSL Ubuntu + Hadoop 3.3.6 + Java 11
-
✅ HDFS 正常(NameNode, DataNode, SecondaryNameNode)
-
✅ YARN 正常(ResourceManager, NodeManager)
-
✅ Web UI 可访问
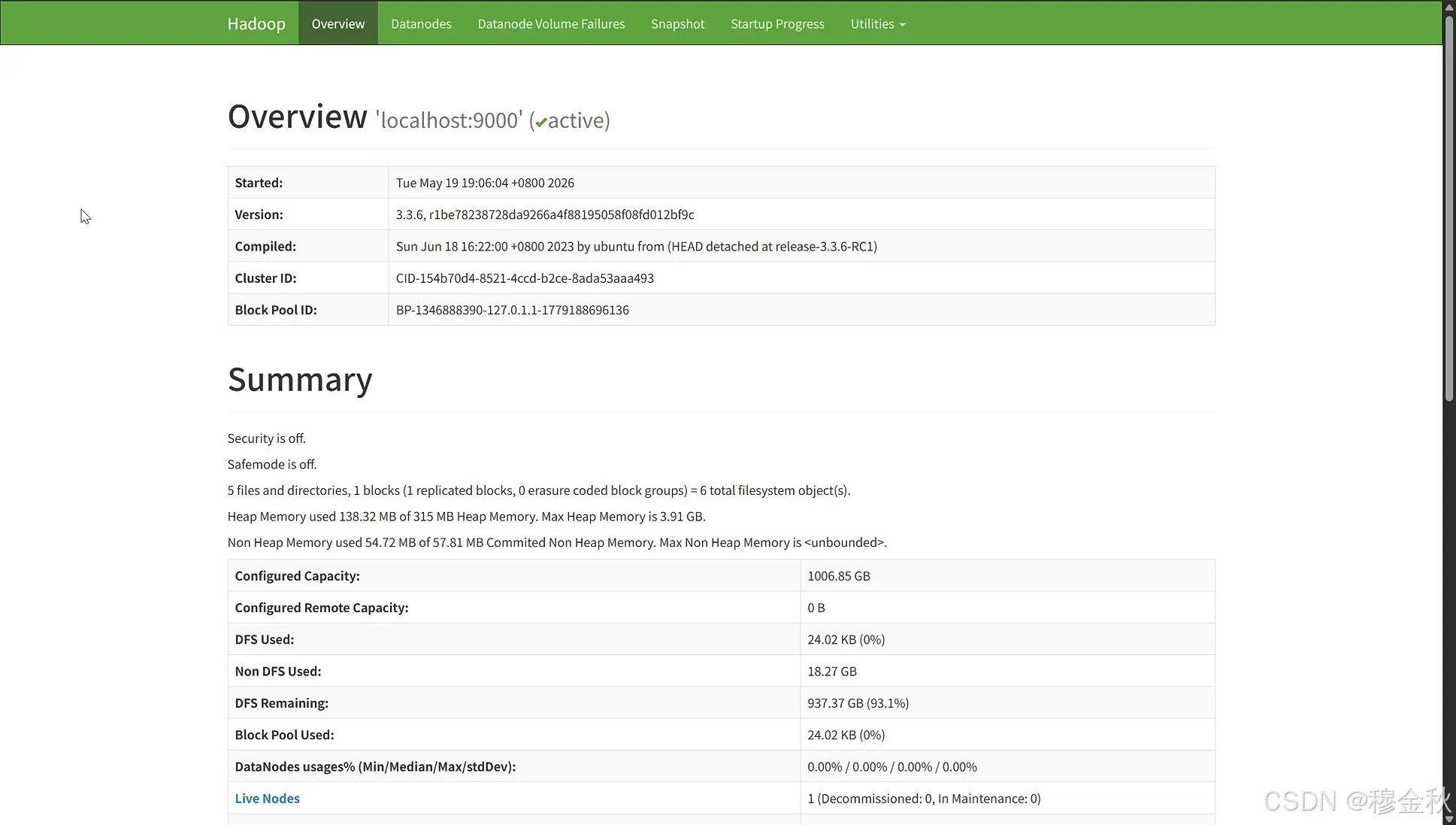
这是 HDFS 的概览页面(Overview),不是文件浏览页面。
如何查看 HDFS 中的文件
方法一:点击顶部菜单的 "Utilities" → "Browse the file system"
在页面上方找到菜单栏:
text
Overview | Datanodes | Datanode Volume Failures | Snapshot | **Utilities** | ...操作步骤:
-
点击
Utilities -
在下拉菜单中选择
Browse the file system -
在路径输入框中输入
/然后回车
方法二:直接访问文件浏览器 URL
在浏览器中输入:
text
http://localhost:9870/explorer.html这就是你课堂笔记里提到的地址:
用你的地址就是:http://localhost:9870/explorer.html
方法三:在页面中直接修改 URL
你当前的 URL 是:
text
http://localhost:9870/dfshealth.html#tab-overview改成:
text
http://localhost:9870/explorer.html当前页面显示的信息解读
你的页面显示 HDFS 正常运行:
| 信息 | 含义 |
|---|---|
Security is off |
安全模式关闭 ✅ |
Safemode is off |
安全模式关闭 ✅ |
Live Nodes: 1 |
1 个 DataNode 正常运行 ✅ |
Configured Capacity: 1006.85 GB |
总存储容量 |
DFS Used: 24.02 KB |
已使用空间(刚格式化,几乎没有用) |
DFS Remaining: 937.37 GB |
剩余空间 |
现在去创建目录和文件
在 Web 界面中操作
-
打开
http://localhost:9870/explorer.html -
你应该能看到
/根目录(目前是空的)
或者在命令行中创建
在 WSL 终端中执行:
bash
# 创建目录
hdfs dfs -mkdir -p /user/mumu/test
# 上传文件
echo "Hello Hadoop" > ~/test.txt
hdfs dfs -put ~/test.txt /user/mumu/test/
# 查看文件
hdfs dfs -ls -R /然后在 Web 界面的 /explorer.html 刷新,就能看到创建的文件了。
完美!✅ HDFS 文件操作成功!现在去 Web 界面查看文件。
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ hdfs dfs -mkdir -p /user/mumu/test
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ echo "Hello Hadoop" > test.txt
hdfs dfs -put test.txt /user/mumu/test/
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ hdfs dfs -ls /user/mumu/test/
Found 1 items
-rw-r--r-- 1 mumu supergroup 13 2026-05-19 19:07 /user/mumu/test/test.txt
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ hdfs dfs -cat /user/mumu/test/test.txt
Hello Hadoop
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ hdfs dfs -ls /
Found 1 items
drwxr-xr-x - mumu supergroup 0 2026-05-19 19:07 /user
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$在 Web 界面查看文件
打开文件浏览器
在 Windows 浏览器中访问:
text
http://localhost:9870/explorer.html导航到你的文件
-
在路径输入框中,删除默认的
/后面的内容,确保只有/ -
点击
Go或按回车 -
你会看到
/user目录 -
点击
user进入 -
再点击
mumu进入 -
再点击
test进入 -
你应该能看到
test.txt文件
或者直接在路径框中输入:
text
/user/mumu/test然后点击 Go。
查看文件内容
点击 test.txt 文件名,然后点击页面上的 "Open" 或 "Head the file" 就可以看到 "Hello Hadoop" 的内容。
当前 HDFS 目录结构
text
/
└── user/
└── mumu/
└── test/
└── test.txt (13 bytes)更多文件操作练习
bash
# 1. 上传多个文件
echo "Line 1" > file1.txt
echo "Line 2" > file2.txt
hdfs dfs -put file*.txt /user/mumu/test/
# 2. 查看文件大小
hdfs dfs -du -h /user/mumu/test/
# 3. 下载文件到本地
hdfs dfs -get /user/mumu/test/test.txt ./downloaded.txt
cat downloaded.txt
# 4. 复制文件
hdfs dfs -cp /user/mumu/test/test.txt /user/mumu/test/test_copy.txt
# 5. 移动文件
hdfs dfs -mv /user/mumu/test/test_copy.txt /user/mumu/
# 6. 删除文件
hdfs dfs -rm /user/mumu/test_copy.txt
# 7. 删除目录
hdfs dfs -rm -r /user/mumu/test对比:课堂笔记中的命令
现在你可以对照课堂笔记练习了:
| 课堂笔记命令 | 你的环境命令 | 说明 |
|---|---|---|
hadoop fs -mkdir -p /2608/test |
hdfs dfs -mkdir -p /user/mumu/test |
创建目录 |
hadoop fs -put task.sh /2608/test |
hdfs dfs -put test.txt /user/mumu/test/ |
上传文件 |
hadoop fs -get /2608/test/task.sh |
hdfs dfs -get /user/mumu/test/test.txt ./ |
下载文件 |
注意 :
hadoop fs和hdfs dfs是等价的,两种写法都可以。
现在去浏览器打开 http://localhost:9870/explorer.html,你应该能看到你刚创建的 test.txt 文件!
是否要保持电脑开机,如果关机了,下次怎么启动
不需要保持开机!关机后可以重新启动
Hadoop 不会随 Windows 自动启动,每次电脑开机后需要手动启动。
下次启动 Hadoop 的完整步骤
第一步:启动 WSL 和必要服务
bash
# 1. 打开 WSL 终端(Ubuntu)
# 2. 启动 SSH 服务(必须,否则 Hadoop 启动会失败)
sudo service ssh start
# 3. 验证 SSH 服务状态
sudo service ssh status第二步:启动 Hadoop
bash
# 1. 确认环境变量已加载(如果刚才关闭了终端,重新打开会自动加载)
source ~/.bashrc
# 2. 验证 Java 环境
java -version
# 3. 启动 Hadoop
start-all.sh
# 4. 等待 30 秒
sleep 30
# 5. 验证进程
jps第三步:验证 Hadoop 正常
bash
# 检查 HDFS 文件是否还在(数据不会丢失)
hdfs dfs -ls /
# 查看之前创建的文件
hdfs dfs -cat /user/mumu/test/test.txt一键启动脚本(推荐)
创建一个启动脚本,以后只需要运行一个命令:
bash
# 1. 创建脚本文件
nano ~/start-hadoop.sh写入以下内容:
bash
#!/bin/bash
echo "Starting SSH service..."
sudo service ssh start
echo "Starting Hadoop..."
start-all.sh
echo "Waiting 30 seconds for services to start..."
sleep 30
echo "=== Hadoop Processes ==="
jps
echo ""
echo "✅ Hadoop is ready!"
echo " - HDFS Web UI: http://localhost:9870"
echo " - YARN Web UI: http://localhost:8088"保存并设置权限:
bash
# 添加执行权限
chmod +x ~/start-hadoop.sh
# 以后每次只需要运行
./start-hadoop.sh停止 Hadoop(关机前建议执行)
虽然直接关机也可以,但建议先优雅关闭 Hadoop:
bash
# 停止 Hadoop
stop-all.sh
# 然后正常关机也可以创建停止脚本:
bash
# 创建停止脚本
cat > ~/stop-hadoop.sh << 'EOF'
#!/bin/bash
echo "Stopping Hadoop..."
stop-all.sh
echo "Hadoop stopped"
EOF
chmod +x ~/stop-hadoop.sh快速参考卡片
| 操作 | 命令 |
|---|---|
| 启动 SSH | sudo service ssh start |
| 启动 Hadoop | start-all.sh |
| 停止 Hadoop | stop-all.sh |
| 查看进程 | jps |
| 一键启动 | ./start-hadoop.sh(创建脚本后) |
常见问题
Q: 直接关机会损坏数据吗?
A: 不会。HDFS 的数据持久化在硬盘上,下次启动后数据还在。但建议先执行 stop-all.sh 优雅关闭。
Q: 下次打开 WSL 后,之前的文件还在吗?
A: 在的。所有数据都在 /home/mumu/hadoop_tmp/ 目录中。
Q: 需要重新格式化 NameNode 吗?
A: 不需要! 只有第一次安装时才需要 hdfs namenode -format。以后正常启动就行。
下次开机的完整操作
text
1. 打开 WSL 终端
2. sudo service ssh start
3. start-all.sh
4. jps(确认有6个进程)
5. 访问 http://localhost:9870把上面的一键启动脚本创建好,以后每次只需要运行 ./start-hadoop.sh 就可以了!
在哪创建启动和关闭脚本呢
在家目录创建脚本(推荐)
bash
# 进入家目录
cd ~
# 创建启动脚本
nano start-hadoop.sh启动脚本内容
复制粘贴以下内容:
bash
#!/bin/bash
echo "========================================="
echo "Starting Hadoop Cluster"
echo "========================================="
# 启动 SSH 服务
echo "1. Starting SSH service..."
sudo service ssh start
# 启动 Hadoop
echo "2. Starting Hadoop..."
start-all.sh
# 等待服务启动
echo "3. Waiting 30 seconds for services..."
sleep 30
# 显示进程
echo "4. Checking Hadoop processes..."
jps
echo ""
echo "========================================="
echo "✅ Hadoop is ready!"
echo " - HDFS UI: http://localhost:9870"
echo " - YARN UI: http://localhost:8088"
echo "========================================="保存:Ctrl+O,Enter,Ctrl+X
创建停止脚本
bash
# 创建停止脚本
nano stop-hadoop.sh复制粘贴:
bash
#!/bin/bash
echo "========================================="
echo "Stopping Hadoop Cluster"
echo "========================================="
stop-all.sh
echo ""
echo "✅ Hadoop stopped"保存:Ctrl+O,Enter,Ctrl+X
添加执行权限
bash
# 给两个脚本添加执行权限
chmod +x start-hadoop.sh stop-hadoop.sh验证脚本创建成功
bash
# 查看文件
ls -la ~/*.sh
# 应该看到:
# -rwxrwxr-x 1 mumu mumu xxx start-hadoop.sh
# -rwxrwxr-x 1 mumu mumu xxx stop-hadoop.sh使用脚本
bash
# 启动 Hadoop
./start-hadoop.sh
# 停止 Hadoop
./stop-hadoop.sh创建快捷方式(可选)
如果想在任何目录都能直接运行,可以把脚本路径加入 PATH:
bash
# 创建 bin 目录
mkdir -p ~/bin
# 移动脚本到 bin 目录
mv ~/start-hadoop.sh ~/bin/
mv ~/stop-hadoop.sh ~/bin/
# 将 bin 目录加入 PATH(在 .bashrc 末尾添加)
echo 'export PATH="$HOME/bin:$PATH"' >> ~/.bashrc
# 重新加载配置
source ~/.bashrc
# 现在可以直接在任何目录执行
start-hadoop.sh
stop-hadoop.sh文件位置总结
| 脚本 | 路径 | 执行方式 |
|---|---|---|
| 启动脚本 | ~/start-hadoop.sh |
./start-hadoop.sh |
| 停止脚本 | ~/stop-hadoop.sh |
./stop-hadoop.sh |
或在 ~/bin/ |
同上 | start-hadoop.sh(任何目录) |
现在创建好脚本,下次开机只需要运行 ./start-hadoop.sh 就可以了!
脚本已经创建并配置好了
bash
mumu@MuJinqiu:/usr/local/hadoop/etc/hadoop$ cd ~
mumu@MuJinqiu:~$ nano start-hadoop.sh
mumu@MuJinqiu:~$ nano stop-hadoop.sh
mumu@MuJinqiu:~$ chmod +x start-hadoop.sh stop-hadoop.sh
mumu@MuJinqiu:~$ ls -la ~/*.sh
-rwxrwxr-x 1 mumu mumu 634 May 19 19:15 /home/mumu/start-hadoop.sh
-rwxrwxr-x 1 mumu mumu 189 May 19 19:16 /home/mumu/stop-hadoop.sh
-rwxr-xr-x 1 mumu mumu 4181 Apr 1 14:57 /home/mumu/vscode_wsl_plugins_check.sh
mumu@MuJinqiu:~$ mkdir -p ~/bin
mumu@MuJinqiu:~$ mv ~/start-hadoop.sh ~/bin/
mv ~/stop-hadoop.sh ~/bin/
mumu@MuJinqiu:~$ echo 'export PATH="$HOME/bin:$PATH"' >> ~/.bashrc
mumu@MuJinqiu:~$ source ~/.bashrc
mumu@MuJinqiu:~$验证脚本是否可用
bash
# 测试启动脚本(现在可以运行)
start-hadoop.sh测试停止脚本
bash
stop-hadoop.sh当前状态
| 项目 | 状态 |
|---|---|
| 启动脚本 | ✅ 已创建并加入 PATH |
| 停止脚本 | ✅ 已创建并加入 PATH |
| 环境变量 | ✅ 已配置 |
| 脚本权限 | ✅ 可执行 |
现在可以测试一下
bash
# 先停止 Hadoop(如果还在运行)
stop-hadoop.sh
# 然后启动
start-hadoop.sh下次开机后的操作
以后每次电脑开机,只需要:
bash
# 1. 打开 WSL 终端
# 2. 运行启动命令
start-hadoop.sh然后等大约 30 秒,看到 ✅ Hadoop is ready! 提示,就可以使用了。
脚本位置
text
/home/mumu/bin/
├── start-hadoop.sh # 启动脚本
└── stop-hadoop.sh # 停止脚本测试一下
bash
# 运行停止脚本
stop-hadoop.sh
# 运行启动脚本
start-hadoop.sh然后把输出结果发给我,确认脚本正常工作。
完美!脚本运行成功!
bash
mumu@MuJinqiu:~$ start-hadoop.sh
=========================================
Starting Hadoop Cluster
=========================================
1. Starting SSH service...
[sudo] password for mumu:
2. Starting Hadoop...
WARNING: Attempting to start all Apache Hadoop daemons as mumu in 10 seconds.
WARNING: This is not a recommended production deployment configuration.
WARNING: Use CTRL-C to abort.
Starting namenodes on [localhost]
Starting datanodes
Starting secondary namenodes [MuJinqiu]
Starting resourcemanager
Starting nodemanagers
3. Waiting 30 seconds for services...
4. Checking Hadoop processes...
1001375 DataNode
1001839 ResourceManager
1001597 SecondaryNameNode
1002188 NodeManager
1001195 NameNode
1002577 Jps
=========================================
✅ Hadoop is ready!
- HDFS UI: http://localhost:9870
- YARN UI: http://localhost:8088
=========================================
mumu@MuJinqiu:~$Hadoop 已经全部启动,所有 5 个核心进程都在运行:
| 进程 | PID | 状态 |
|---|---|---|
| NameNode | 1001195 | ✅ |
| DataNode | 1001375 | ✅ |
| SecondaryNameNode | 1001597 | ✅ |
| ResourceManager | 1001839 | ✅ |
| NodeManager | 1002188 | ✅ |
现在验证 Web 界面
在 Windows 浏览器中打开:
HDFS 文件浏览器
text
http://localhost:9870/explorer.htmlYARN 集群管理界面
text
http://localhost:8088验证之前创建的文件
bash
# 查看 HDFS 中的文件
hdfs dfs -ls -R /
# 读取之前创建的 test.txt
hdfs dfs -cat /user/mumu/test/test.txt测试 MapReduce(可选)
bash
# 创建输入文件
echo "hello world" > ~/input1.txt
echo "hello hadoop" > ~/input2.txt
# 上传到 HDFS
hdfs dfs -mkdir -p /wordcount/input
hdfs dfs -put ~/input*.txt /wordcount/input/
# 运行 wordcount 示例
yarn jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.6.jar wordcount /wordcount/input /wordcount/output
# 查看结果
hdfs dfs -cat /wordcount/output/part-r-00000关闭 Hadoop(用脚本)
bash
stop-hadoop.sh总结
你的 Hadoop 环境已经完全配置好了:
| 项目 | 状态 |
|---|---|
| Hadoop 版本 | 3.3.6 ✅ |
| Java 版本 | 11 ✅ |
| HDFS | 正常运行 ✅ |
| YARN | 正常运行 ✅ |
| Web UI | 可访问 ✅ |
| 启动脚本 | start-hadoop.sh ✅ |
| 停止脚本 | stop-hadoop.sh ✅ |
以后每次电脑开机,打开 WSL 终端,输入 start-hadoop.sh 就可以了!
停止脚本也正常工作
bash
mumu@MuJinqiu:~$ stop-hadoop.sh
=========================================
Stopping Hadoop Cluster
=========================================
WARNING: Stopping all Apache Hadoop daemons as mumu in 10 seconds.
WARNING: Use CTRL-C to abort.
Stopping namenodes on [localhost]
Stopping datanodes
Stopping secondary namenodes [MuJinqiu]
Stopping nodemanagers
Stopping resourcemanager
✅ Hadoop stopped
mumu@MuJinqiu:~$停止脚本也正常工作。
现在你的 Hadoop 环境已经完全就绪!
日常使用流程
| 操作 | 命令 | 说明 |
|---|---|---|
| 启动 | start-hadoop.sh |
等待 30 秒,看到 ✅ 提示即可 |
| 停止 | stop-hadoop.sh |
关机前执行(可选) |
| 查看进程 | jps |
确认 5 个核心进程在运行 |
| 查看文件 | hdfs dfs -ls / |
浏览 HDFS 文件 |
验证 Web 界面
在 Windows 浏览器中打开:
-
HDFS :
http://localhost:9870/explorer.html -
YARN :
http://localhost:8088
常用 HDFS 命令复习
bash
# 创建目录
hdfs dfs -mkdir -p /user/mumu/test
# 上传文件
hdfs dfs -put 本地文件 /hdfs路径/
# 下载文件
hdfs dfs -get /hdfs路径/ 本地路径
# 查看文件内容
hdfs dfs -cat /hdfs路径/文件
# 查看文件列表
hdfs dfs -ls /hdfs路径/
# 删除文件/目录
hdfs dfs -rm /hdfs路径/文件
hdfs dfs -rm -r /hdfs路径/目录
# 复制文件
hdfs dfs -cp /源路径 /目标路径
# 移动文件
hdfs dfs -mv /源路径 /目标路径恭喜!🎉
你已经成功在 WSL 中配置好了完整的 Hadoop 3.3.6 环境!
现在可以:
-
✅ 对照课堂笔记练习 HDFS 命令
-
✅ 熟悉 Web UI 界面操作
-
✅ 运行 MapReduce 示例程序
-
✅ 后续安装 Hive、HBase 等组件