最近看吴军老师的数学通识,对π的计算产生了兴趣,就自己来尝试下。
首先是选择语言。由于这个尝试只是关注结果,并不考虑锻炼什么语言开发能力,就选比较容易入手的python吧。
计算方法
计算方法,采用的是比较易于理解的方法,就是积分法。对四分之一圆的曲线下的面积进行积分,具体计算方法,就是将该区域面积,分成多段,每段当做矩形面积进行计算,最后进行累加。
示意图如下:
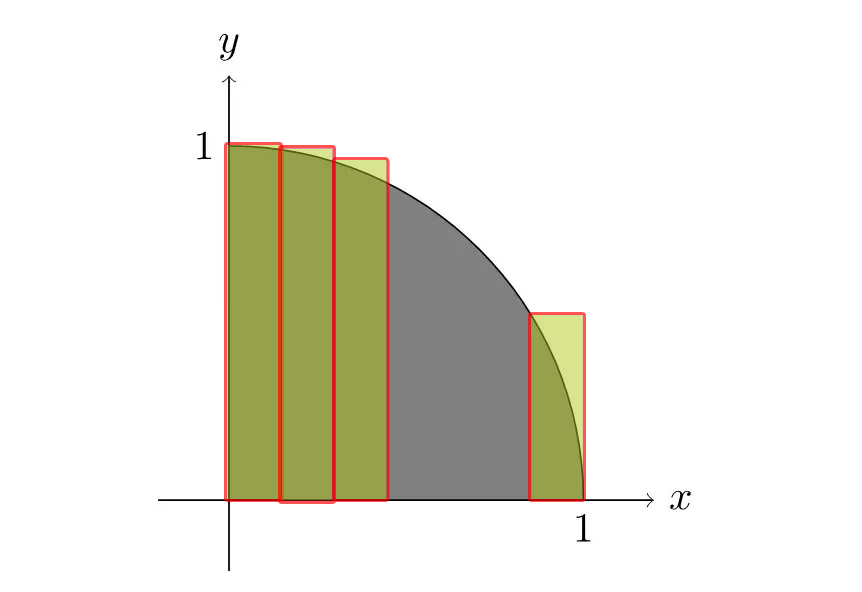
这种计算方法,是将该区域面积分的段数越多,计算结果就越精细,也就是越接近真实四分之一圆的面积,这里为了方便,指定圆的半径为1,则四分之一圆的面积就是π/4。
具体计算方法说明如下:
假设将1/4圆按x轴方向分为n段,则每段的长度就是
dx=1/n
其高度,按圆的曲线公式来计算:
x^2+y^2=1
其中:
x=k/n,k整数,其取值范围为0,n-1
推理得y的表达式:
y=sqrt(1-(k/n)^2)
累加各矩形面积,就得到总面积:
S = ∑ydx
第一次实现(矩形面积累加)
下面是对应的实现代码,如下:
import math
def integralMethod(num):
sum=0.0
for i in range(num):
k=math.sqrt(1-math.pow(i/num,2))/num
sum+=k
return (sum*4)
for j in [1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000, 1000000000]:
num=j
print("num=", num)
pi = integralMethod(num)
print('pi=',pi)运行结果如下:
num= 1
pi= 4.0
num= 10
pi= 3.304518326248318
num= 100
pi= 3.160417031779047
num= 1000
pi= 3.143555466911029
num= 10000
pi= 3.141791477611317
num= 100000
pi= 3.1416126164019564
num= 1000000
pi= 3.1415946524138207
num= 10000000
pi= 3.1415928535523587
num= 100000000
pi= 3.1415926735892157
num= 1000000000
pi= 3.1415926555896565可以看出,随着循环次数的增加,π的计算精度也在增加。
实际在等待计算结果的时候,到后面循环次数很大的情况,耗时挺长的。所以,就考虑加一个时间记录,用于分析运行的耗时:
加上时间记录后的代码如下:
import time
for j in [1, 10, 100, 1000, 10000, 100000, 1000000, 10000000, 100000000, 1000000000]:
num=j
start = time.time()
pi = integralMethod(num)
print("num=", num,', use time={:.2f}'.format(time.time() - start))
print('pi=',pi)运行结果:
num= 1 , use time=0.00
pi= 4.0
num= 10 , use time=0.00
pi= 3.304518326248318
num= 100 , use time=0.00
pi= 3.160417031779047
num= 1000 , use time=0.00
pi= 3.143555466911029
num= 10000 , use time=0.00
pi= 3.141791477611317
num= 100000 , use time=0.04
pi= 3.1416126164019564
num= 1000000 , use time=0.42
pi= 3.1415946524138207
num= 10000000 , use time=4.16
pi= 3.1415928535523587
num= 100000000 , use time=41.62
pi= 3.1415926735892157
num= 1000000000 , use time=417.95
pi= 3.1415926555896565看耗时情况,基本上是线性增加的,就是循环次数增加到10倍,耗时也是大约变为原来的10倍。
分割为10亿段,精度可以达到小数点后8位。
完善积分法(三角形近似)
使用矩形来做近似,与实际形状差异较大,这里优化一下,采用一个矩形减去一个三角形来做近似。
实际计算是用当前矩形加下一个矩形的面积,然后求平均。
代码如下:
# 使用近似的矩形面积累加:分为n份,分别计算矩形面积,以及顶部三角形面积,累加
def integralMethod2(num):
global printed
if not printed: #控制函数名只打印一次
print(sys._getframe().f_code.co_name)
printed = True
sum=0.0
for i in range(num):
if(i==0):
y1 = math.sqrt(1 - math.pow(i / num, 2))
y2 = math.sqrt(1 - math.pow((i+1) / num, 2))
sum += (y1 + y2) / num / 2
y1 = y2
return sum * 4这里,为了在结果信息中比较容易区分各计算函数,将函数名打印了一次。
下面,是执行情况:
integralMethod2
num= 1 , use time=0.00
pi= 2.0
num= 10 , use time=0.00
pi= 3.104518326248318
num= 100 , use time=0.00
pi= 3.140417031779045
num= 1000 , use time=0.00
pi= 3.141555466911024
num= 10000 , use time=0.01
pi= 3.141591477611326
num= 100000 , use time=0.06
pi= 3.141592616401964
num= 1000000 , use time=0.53
pi= 3.1415926524138587
num= 10000000 , use time=5.27
pi= 3.1415926535533543
num= 100000000 , use time=52.63
pi= 3.141592653589112 效果很明显,对比同为循环1亿次的情况,由7位精度提升到12位了。
再次完善积分法(四分之一圆的左半部分)
考虑到四分之一圆的斜率变化,靠右的部分,斜率值较大,也就是倾斜度较大,也就是说,可能带来较大的误差。
所以,仅使用左边一半来进行积分,看看效果如何
说明:
这里积分的结果,要预先计算出来:
左侧部分面积:可以分为2部分,一个是30度的扇形,一个是下面部分的三角形。
见下面示意图:
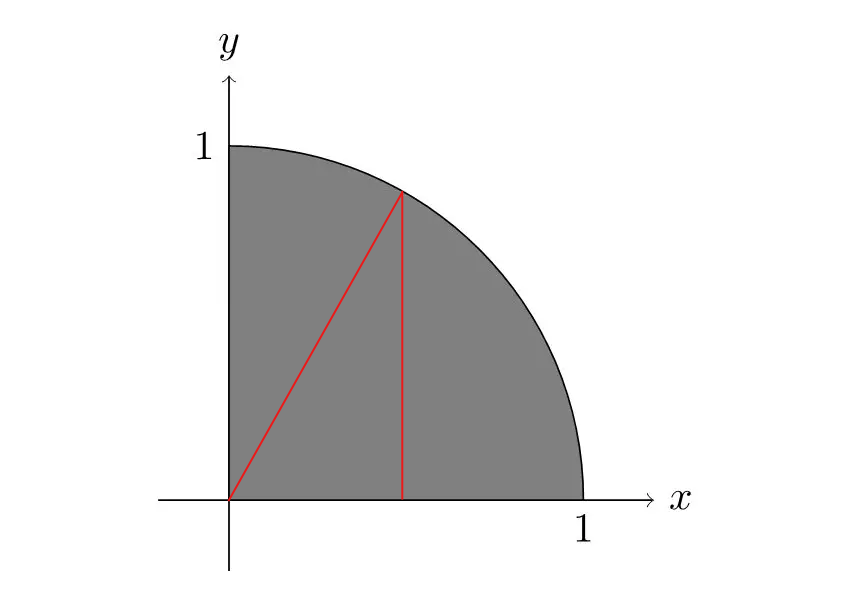
分别计算面积,相加即可:
扇形面积:π*(π/6)/(2π)=π/12
三角形面积:1/2*(1/2*sqrt(3)/2)=sqrt(3)/8
积分的结果 = π/12 + sqrt(3)/8
反推,就可以得到π值了:
π = 12 * (积分的结果 - sqrt(3)/8)
代码:
# 使用近似的矩形面积累加:分为n份,分别计算矩形面积,以及顶部三角形面积,累加,四分之一圆的一半
def integralMethod3(num):
global printed
if not printed: #控制函数名只打印一次
print(sys._getframe().f_code.co_name)
printed = True
sum=0.0
for i in range(num):
if (i >= num / 2):
break
if(i==0):
y1 = math.sqrt(1 - math.pow(i / num, 2))
y2 = math.sqrt(1 - math.pow((i+1) / num, 2))
sum += (y1 + y2) / num / 2
y1 = y2
ret = sum - math.sqrt(3) / 8
return (ret*12)结果:
integralMethod3
num= 1 , use time=0.00
pi= 3.401923788646684
num= 10 , use time=0.00
pi= 3.135824240470953
num= 100 , use time=0.00
pi= 3.1415349190760318
num= 1000 , use time=0.00
pi= 3.1415920762395677
num= 10000 , use time=0.00
pi= 3.14159264781628
num= 100000 , use time=0.03
pi= 3.141592653532077
num= 1000000 , use time=0.30
pi= 3.1415926535891936
num= 10000000 , use time=3.03
pi= 3.141592653589922
num= 100000000 , use time=30.43
pi= 3.14159265359089效果也很明显,分割为百万次就达到了12位精度。对比上一次的程序,是1亿次。
但是,更多的分割,反而下降了!
为什么?
是计算数据的精度达到了上限吗?
第三次优化(高精度数据)
就是采用高精度数据来进行计算。这里使用的是Decimal。
代码变化如下:
getcontext().prec = 20 #设置精度位数
# 积分,四分之一圆的一半,高精度:
def integralMethod4(num):
print(sys._getframe().f_code.co_name)
sum=Decimal(0.0)
for i in range(num):
if (i >= num / 2):
break
if(i==0):
y1 = (Decimal(1 - Decimal(Decimal(i) / num) ** 2) ** Decimal(0.5))
y2 = (Decimal(1 - Decimal(Decimal(i+1) / num) ** 2) ** Decimal(0.5))
sum += (y1 + y2) / num / 2
y1 = y2
ret = sum - Decimal(3)**Decimal(0.5) / 8
return (ret*12)另外,每次数精度达到小数点后几位,也有点麻烦。特别是,如果精度达到几十几百位的话,数起来就更麻烦了。
所以,添加了一个有效位的比较函数:
当然,要先准备一个π值来进行比较。我是上网找了一个,用了前10000位,存放在一个文件中,文件名为 pi-10000.txt 。
下面是读取文件,并与输入参数进行比较:
def read_file(file_name) :
file = open(file_name, 'r')
str = file.read()
file.close()
return str
# 读取文件 pi-10000.txt ,并将其内容存放到一个字符串中
pi_str = read_file("pi-10000.txt")
# 比较两个字符串,前n个字符相等
def strCompare(str1, str2):
n = 0
min_length = min(len(str1), len(str2))
for i in range(min_length):
if str1[i] == str2[i]:
n += 1
else:
break
print("the same is: ", n-2)
return n调用处:
strCompare(pi_str, str(count_pi))结果如下:
2026-02-20 17:29:54 prec= 20
integralMethod3
num= 1 , use time=0.00
count_pi= 3.4019237886466840597
the same is: 0
num= 10 , use time=0.00
count_pi= 3.1358242404709530611
the same is: 1
num= 100 , use time=0.00
count_pi= 3.1415349190760310802
the same is: 4
num= 1000 , use time=0.03
count_pi= 3.1415920762395753683
the same is: 6
num= 10000 , use time=0.27
count_pi= 3.1415926478162905500
the same is: 7
num= 100000 , use time=2.71
count_pi= 3.1415926535320582074
the same is: 10
num= 1000000 , use time=27.09
count_pi= 3.1415926535892159119
the same is: 12
num= 10000000 , use time=271.86
count_pi= 3.1415926535897874587
the same is: 13
num= 100000000 , use time=2725.36
count_pi= 3.1415926535897933398
the same is: 15使用高精度数据Decimal后,分割一亿次,精度达到15位了。
当然,耗时也是明显增加,达到了2725s,大概45分钟。
而之前使用math库时,才半分钟。
第四次优化(15度角)
看这个优化方法有效,那么,是不是可以继续优化呢?
例如,对15度角对应曲线下面积进行积分。
按说,这样的曲线,其倾斜角更小,则积分结果就会更接近真实面积了。
先进行理论计算:
也是将面积分为2部分,一个是15度的扇形,一个是下面部分的三角形。
分别计算面积,相加即可:
扇形面积:π*(π/12)/(2π)=π/24
三角形面积:1/2*(sin15*cos15)=1/4*(sin30)=1/8=0.125
积分的结果 = π/24 + 0.125
反推,就得到π值:
π = 24 * (积分的结果 - 0.125)
代码如下:
#积分法:对15度角对应曲线下面积进行积分。
def integralMethod4(num):
print(sys._getframe().f_code.co_name)
x = (Decimal(3.0)**Decimal(0.5)-1)/(Decimal(2.0)**Decimal(0.5))/Decimal(2)
sum=Decimal(0.0)
num_max = num * x
print('num_max=',num_max)
y1 = Decimal(1.0)
for i in range(num):
if (i >= num_max):
break
y2 = (Decimal(1 - Decimal(Decimal(i+1) / num) ** 2) ** Decimal(0.5))
sum += Decimal(y1 + y2) / Decimal(num) / 2
y1 = y2
ret = Decimal(sum - Decimal(0.125))
return (ret*24)然而,结果却很不理想:
num= 10000000 , use time=104.41
count_pi= 3.1415939262352099219
the same is: 5
num= 100000000 , use time=1038.09
count_pi= 3.1415927671242334836
the same is: 6对比一亿次分割时才6位精度,而30度角积分时其精度已经达到了15位。
为什么反而下降了呢?与预期严重不符!
想了一阵也没有想出来原因,就增加了打印信息,通过查看最后一个截止值:
num_max= 2588190.4510252076234有了思路:可能是这个数不是整数,其余数部分带来了误差!
再次调整代码,将尾部部分补齐:
#积分法:对15度角对应曲线下面积进行积分。--最后一部分,使用余数
def integralMethod5(num):
global printed
if not printed: #控制函数名只打印一次
print(sys._getframe().f_code.co_name)
printed = True
x = (Decimal(3.0)**Decimal(0.5)-1)/(Decimal(2.0)**Decimal(0.5))/Decimal(2)
sum=Decimal(0.0)
num_max = num * x
print('num_max=',num_max)
y1 = Decimal(1.0)
y2 = Decimal(1.0)
for i in range(num):
if (i >= num_max):
break
y1 = y2
y2 = (Decimal(1 - Decimal(Decimal(i+1) / num) ** 2) ** Decimal(0.5))
sum += Decimal(y1 + y2) / Decimal(num) / 2
sum -= (i - num_max) * Decimal(y1 + y2) / Decimal(num) / 2 #减去最后一次计算中的多余部分
ret = Decimal(sum - Decimal(0.125))
return (ret*24)结果:
num= 100000 , use time=1.02
count_pi= 3.1415926535084319161
the same is: 10
num_max= 258819.04510252076234
num= 1000000 , use time=10.17
count_pi= 3.1415926535891189114
the same is: 12
num_max= 2588190.4510252076234
num= 10000000 , use time=101.88
count_pi= 3.1415926535897797992
the same is: 13
num= 100000000 , use time=1018.37
count_pi= 3.1415926535897931756
the same is: 15单纯从数据精度来看,与30度角的也没有明显差别。
但是,耗时时间却有明显下降!
同是千万次分割,耗时从271秒下降到102秒了,而且精度没有下降。
实际,这是循环次数的减少,因为做积分的范围减小了,就是用来累加的面积变少了,耗时相应减少。
如果要继续运行,当然是耗时少的算法能更容易计算到更多分割次数去。
毕竟,按分割1亿次的耗时来看,等待17分钟总要比等待45分钟好一点。
总结
综上:
1,使用积分法来估算π值,分割越精细,精度越高;而且,分割越精细,计算耗时越长,基本上呈线性关系;
2,在同样分割精细度上,相比较直接使用矩形进行累加,使用矩形面积减去三角形面积计算的π值的精度要更高;
3,使用四分之一圆的左半部分(30度角对应区域)计算,要比整个四分之一圆(90度角对应区域)的效果好;
4,使用math库,精度达到12位之后,就反而下降了,可能与math库以及浮点数的精度有关;使用Decimal库,精度能继续提升,但是耗时会明显增加。
5,使用15度角对应区域计算,相比于30度角的,精度上没有明显变化,但是耗时要大幅度减少,约为原耗时的1/3;
6,以上优化方法都使用了,分割一亿次,精度最高达到15位,仍然比较有限。
后续,再考虑其他计算方法,看精度效果。