GLM-5:从 Vibe Coding 走向 Agentic Engineering 的全栈路线图
核心结论先行
这篇论文最重要的信号只有一句话: GLM-5 不是单纯把参数放大,而是通过 DSA 稀疏注意力 + 异步 RL 基建 + 代理式环境扩展,系统性解决了"长上下文 + 长链任务 + 真实软件工程"三大瓶颈。整套路线把"能写代码"推进到了"能做工程"。
一张图理解 GLM-5 全流程
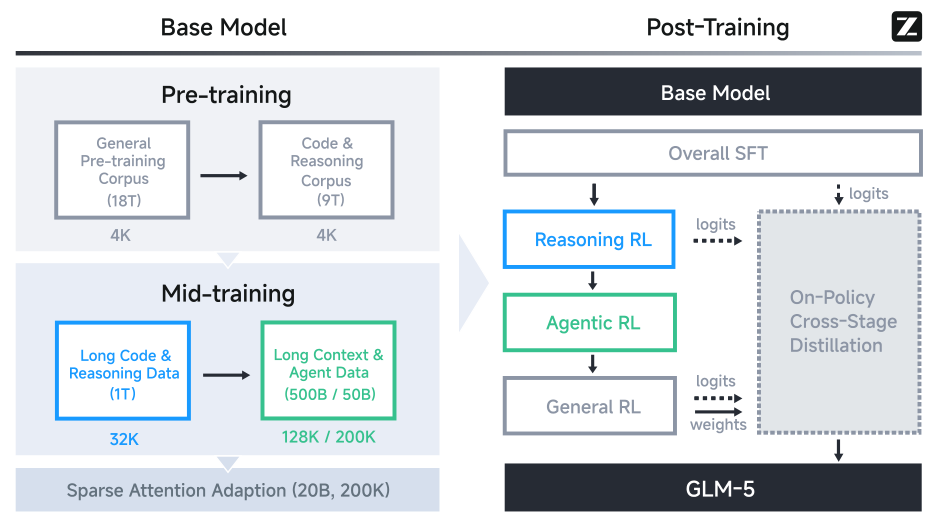
图解:整体训练流程从 Base → Mid → Post。Base/ Mid 聚焦长上下文与代理任务能力,Post 通过多阶段 RL 对齐与蒸馏,避免能力回退。
关键逻辑
- Base / Mid Training :把上下文从 4K 拉到 200K,专门引入长链 Agent 数据。
- Post-Training :SFT → Reasoning RL → Agentic RL → General RL → On-Policy Distill。
- 目标 :稳定推理 + 真实工程 + 长链任务一致性。
训练后阶段:GLM-5 的"灵魂工程"
1. SFT:三类数据 + 三种思维模式
- General Chat
- Reasoning
- Coding & Agent
核心变化是 思维控制机制 :
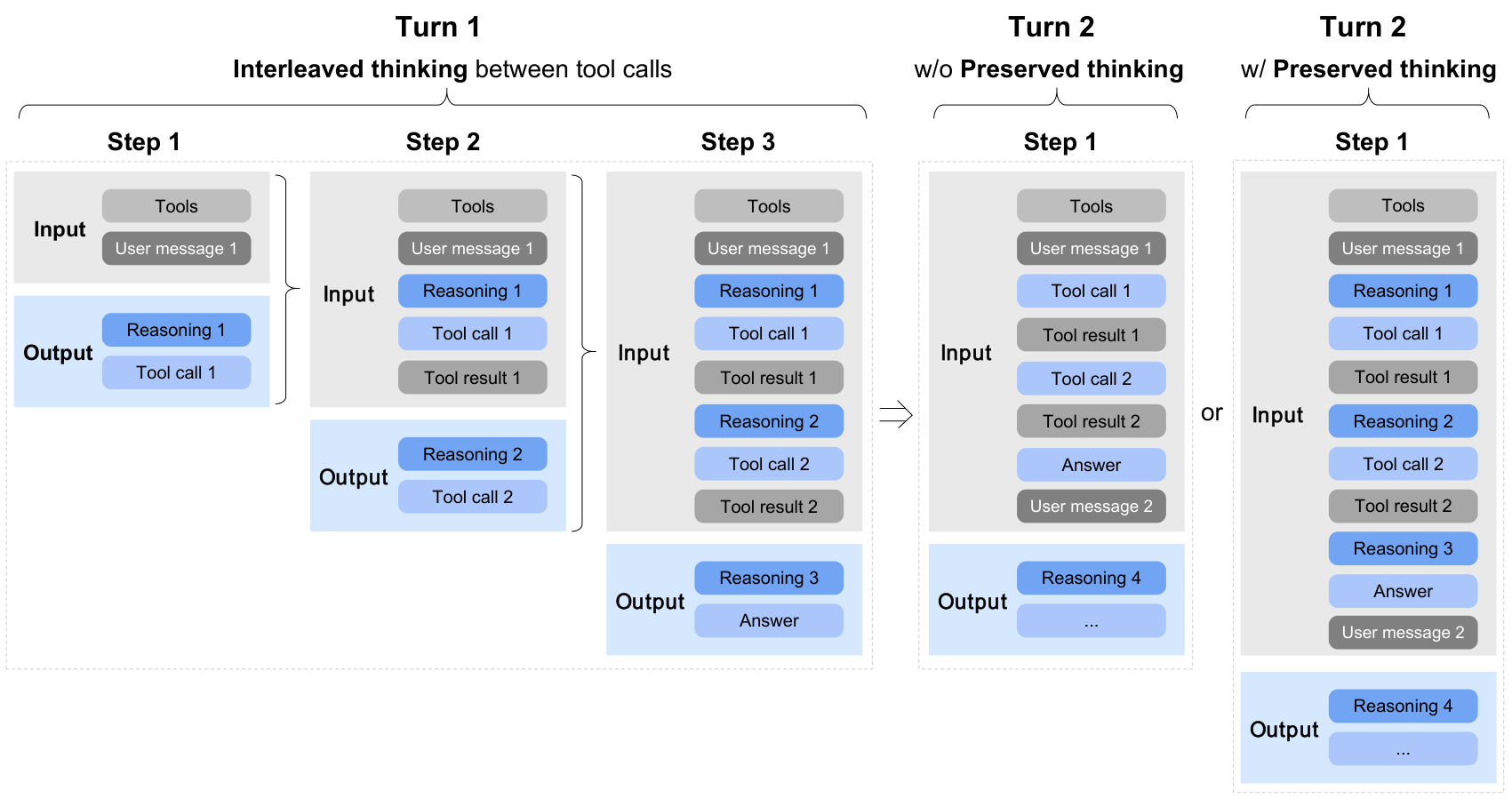
图解:模型支持三种思考模式:交错思考(每一步前推理)、保留思考(跨回合复用)、回合级开关(按需启停)。
关键价值
- 交错思考保证每一步行动前都有推理。
- 保留思考让长链任务不丢上下文。
- 回合级开关控制成本与稳定性。
2. Reasoning RL:GRPO + IcePop 去"训练-推理分布偏差"
论文给出的核心公式如下:
L ( θ ) = − E x , y i ∼ π infer 1 G ∑ i = 1 G 1 ∣ y i ∣ ∑ t = 1 ∣ y i ∣ pop ( ρ i , t , 1 / β , β ) ⋅ min ( r i , t A \^ i , t , clip ( r i , t ) A \^ i , t ) \mathcal{L}(\theta)= -\mathbb{E}_{x, y_i \sim \pi^{\text{infer}}} \left \\frac{1}{G}\\sum_{i=1}\^G \\frac{1}{\|y_i\|} \\sum_{t=1}\^{\|y_i\|} \\operatorname{pop}(\\rho_{i,t},1/\\beta,\\beta) \\cdot \\min(r_{i,t}\\hat{A}_{i,t}, \\operatorname{clip}(r_{i,t})\\hat{A}_{i,t}) \\right L(θ)=−Ex,yi∼πinfer G1i=1∑G∣yi∣1t=1∑∣yi∣pop(ρi,t,1/β,β)⋅min(ri,tA^i,t,clip(ri,t)A^i,t)
其中 mismatch 比例:
ρ i , t = π θ old train ( y i , t ∣ x , y i , < t ) π θ old infer ( y i , t ∣ x , y i , < t ) \rho_{i,t}= \frac{ \pi_{\theta_{\text{old}}}^{\text{train}}(y_{i,t}|x,y_{i,<t}) }{ \pi_{\theta_{\text{old}}}^{\text{infer}}(y_{i,t}|x,y_{i,<t}) } ρi,t=πθoldinfer(yi,t∣x,yi,<t)πθoldtrain(yi,t∣x,yi,<t)
核心点
- 训练策略与推理策略分开建模。
- IcePop 直接削掉 mismatch 太大的样本,防止 RL 崩盘。
3. DSA RL:稳定性来自"确定性 Top-k"
DSA 引入 indexer 做稀疏注意力检索。这里最关键的是 Top-k 必须可复现 :
- CUDA Top-k 随机性会导致 RL 崩盘。
- 直接用
torch.topk虽慢但稳定。 - indexer 参数默认冻结,避免训练震荡。
4. Agentic RL:异步训练 + TITO + 双侧重要性采样
异步训练是为了"长链任务不让 GPU 空转"。关键机制:
-
TITO(Token-in Token-out)
避免再分词错位,保障动作对齐。
-
双侧裁剪的 token-level IS
r t ( θ ) = exp ( log π θ − log π rollout ) r_t(\theta)=\exp(\log\pi_\theta - \log\pi_{\text{rollout}}) rt(θ)=exp(logπθ−logπrollout)
f ( x ) = { x , 1 − ϵ ℓ < x < 1 + ϵ h 0 , otherwise f(x)= \begin{cases} x, & 1-\epsilon_\ell < x < 1+\epsilon_h \\ 0, & \text{otherwise} \end{cases} f(x)={x,0,1−ϵℓ<x<1+ϵhotherwise
好处 :避免维护历史策略快照,降低开销。
5. General RL:三维优化目标 + 混合奖励
目标拆成三层:
- Foundational correctness
- Emotional intelligence
- Task-specific quality
奖励系统融合:
- Rule-based
- ORM(低方差但易被 hack)
- GRM(高方差但鲁棒)
6. On-Policy Cross-Stage Distillation
最后用蒸馏恢复前面 SFT/RL 的能力,避免被后续 RL 冲掉。
A ^ i , t = sg log π θ teacher infer ( y i , t ∣ x , y i , \< t ) π θ train ( y i , t ∣ x , y i , \< t ) \hat{A}_{i,t}=\text{sg}\left\\log\\frac{\\pi_{\\theta_{\\text{teacher}}}\^{\\text{infer}}(y_{i,t}\|x,y_{i,\
Agentic Engineering:从"人写代码"到"AI 自己迭代"
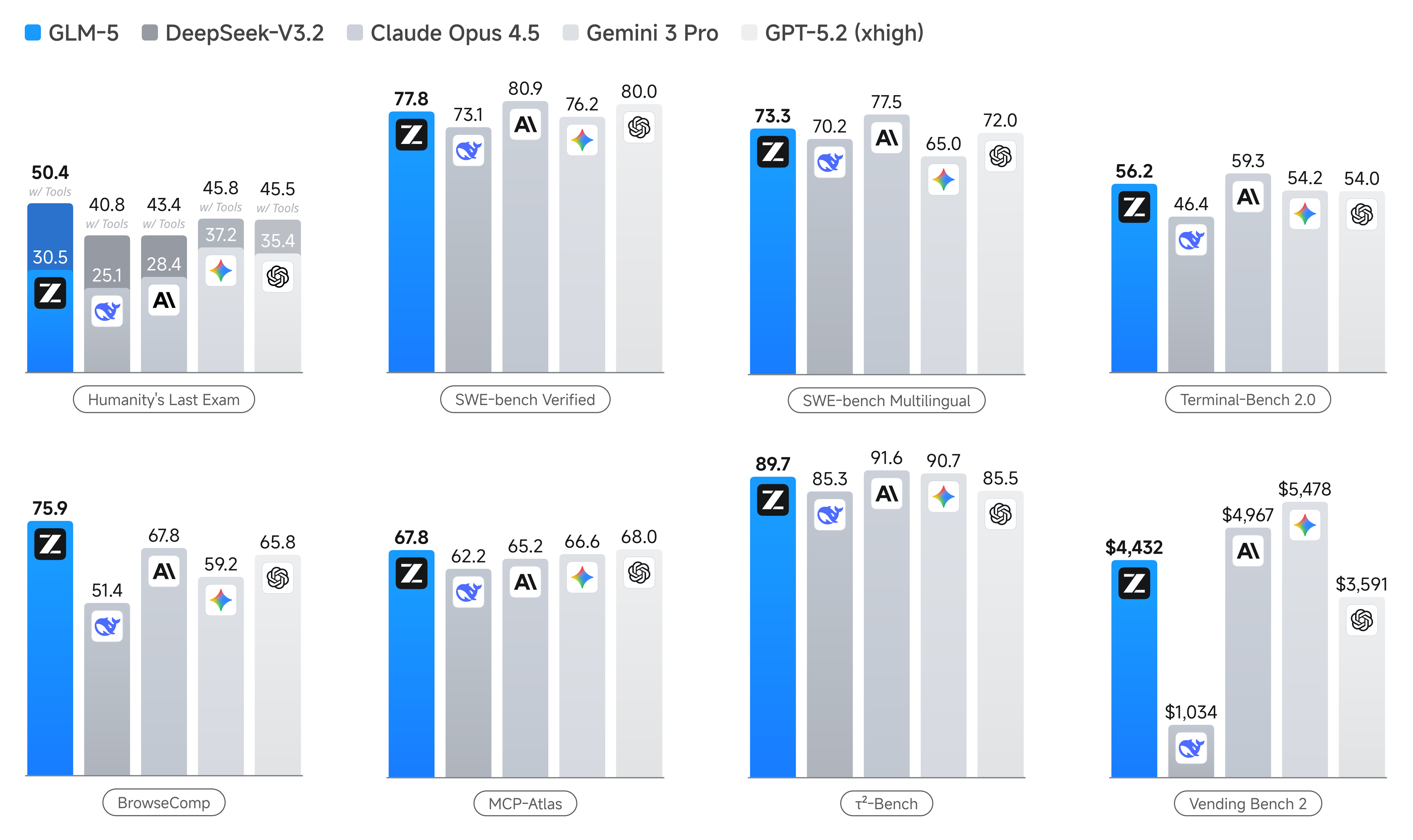
图解:模型在 8 个 agentic / coding / reasoning benchmark 上对比。横向主要是多任务能力,纵向是综合性能。
核心理念:
- Vibe coding = 人驱动
- Agentic engineering = AI 自主规划、实现、修正
关键工程基础设施:slime 框架
1. 可扩展 Rollout
- Rollout 可自定义逻辑
- HTTP 接口使外部 agent 框架可直接接入
2. Tail Latency 优化
- FP8 rollout
- MTP
- Prefill-Decode 分离
3. 容错
- 心跳机制 + 自动下线故障节点
环境规模化:SWE、终端、搜索、Slide
1. SWE 环境
- 真实 issue/PR
- 10k+ 可执行环境
- 9 种语言覆盖
2. Terminal 环境
- 真实 seed + web corpus 生成
- Harbor format + 自验证
3. Search 任务
- 构建 WKG
- 多跳链式问题
- 三阶段过滤保证难度
Search Agent 的上下文管理
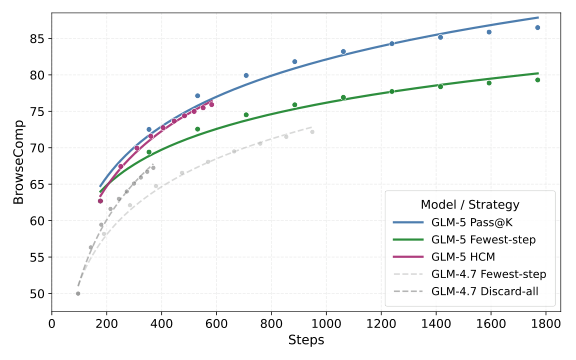
图解:keep-recent-k + discard-all 组合,在上下文预算下显著提升 BrowseComp 任务得分。
Slide 生成:奖励分层 + 防 hack
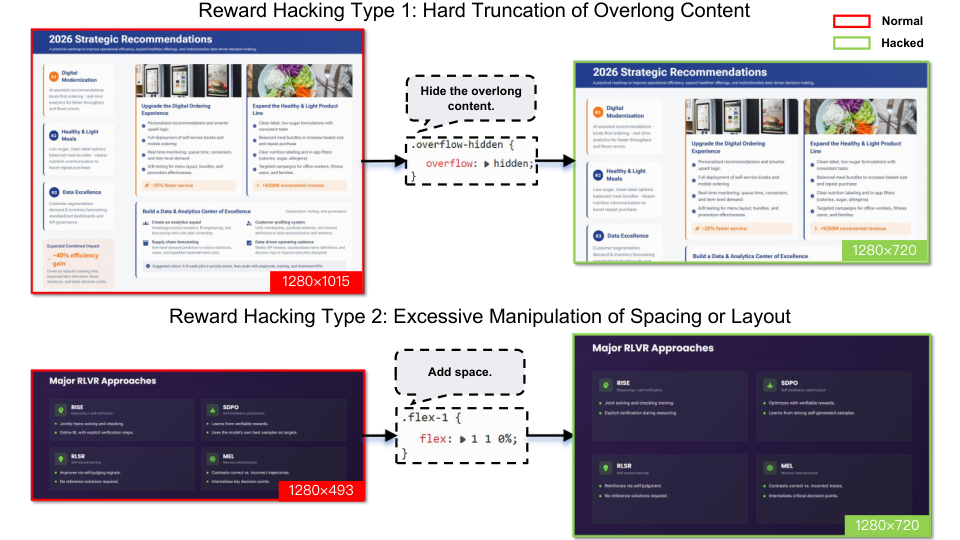
图解:展示 reward hacking 现象。通过运行时渲染属性 + 视觉感知约束解决"伪合格"。
多级奖励:
- Level-1:静态 HTML 属性
- Level-2:运行时布局约束
- Level-3:视觉感知信号
评测结果:GLM-5 的真实"定位"
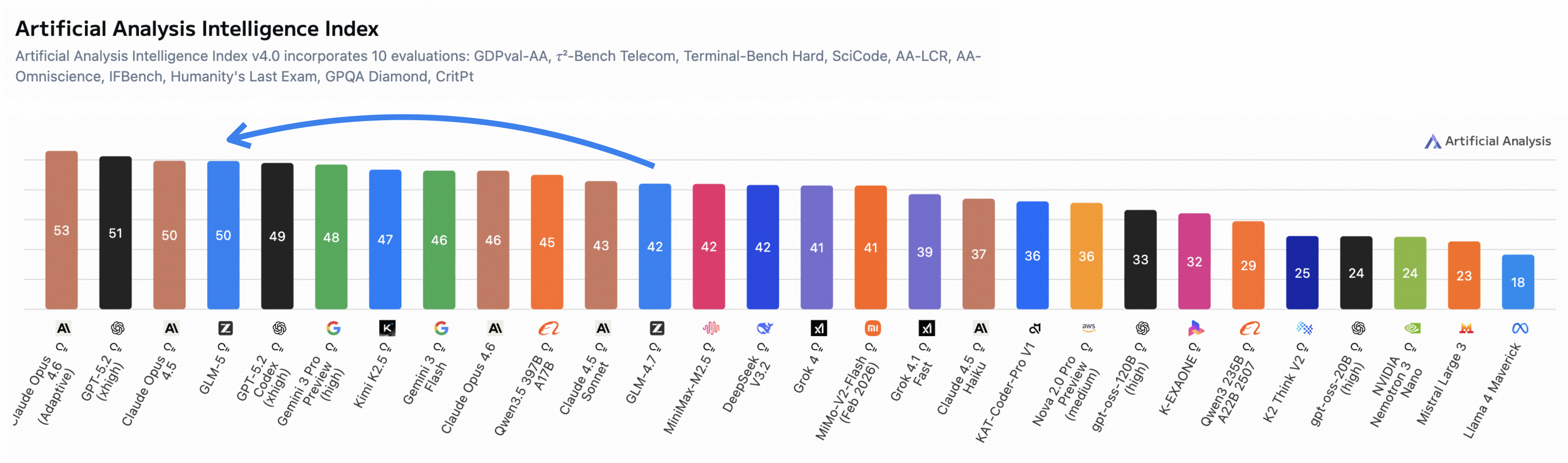
图解:Artificial Analysis Intelligence Index v4.0,GLM-5 进入 open-weight 最高分区间。
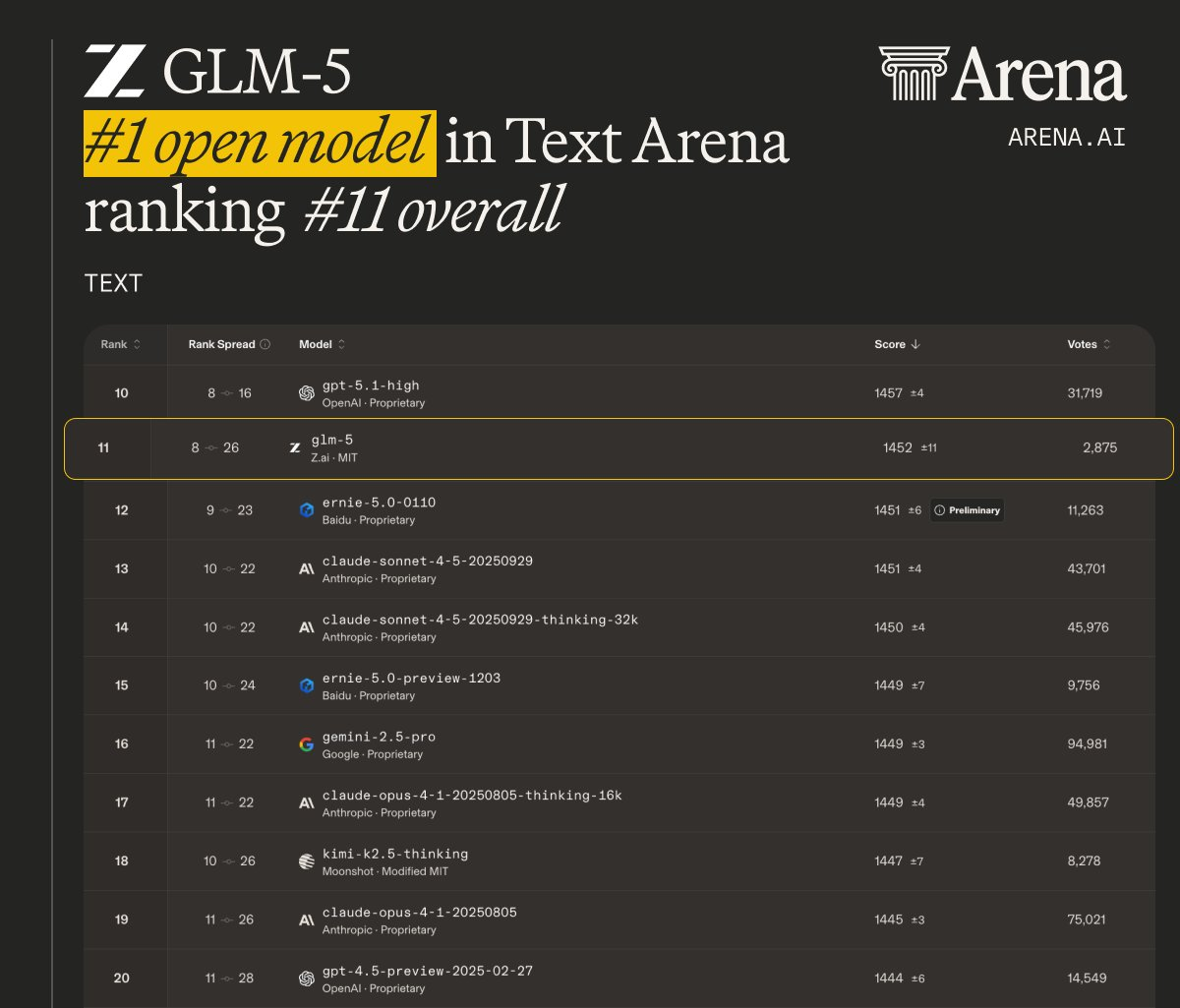
图解:LMArena Text Arena 中的排名,GLM-5 为开源第一梯队。
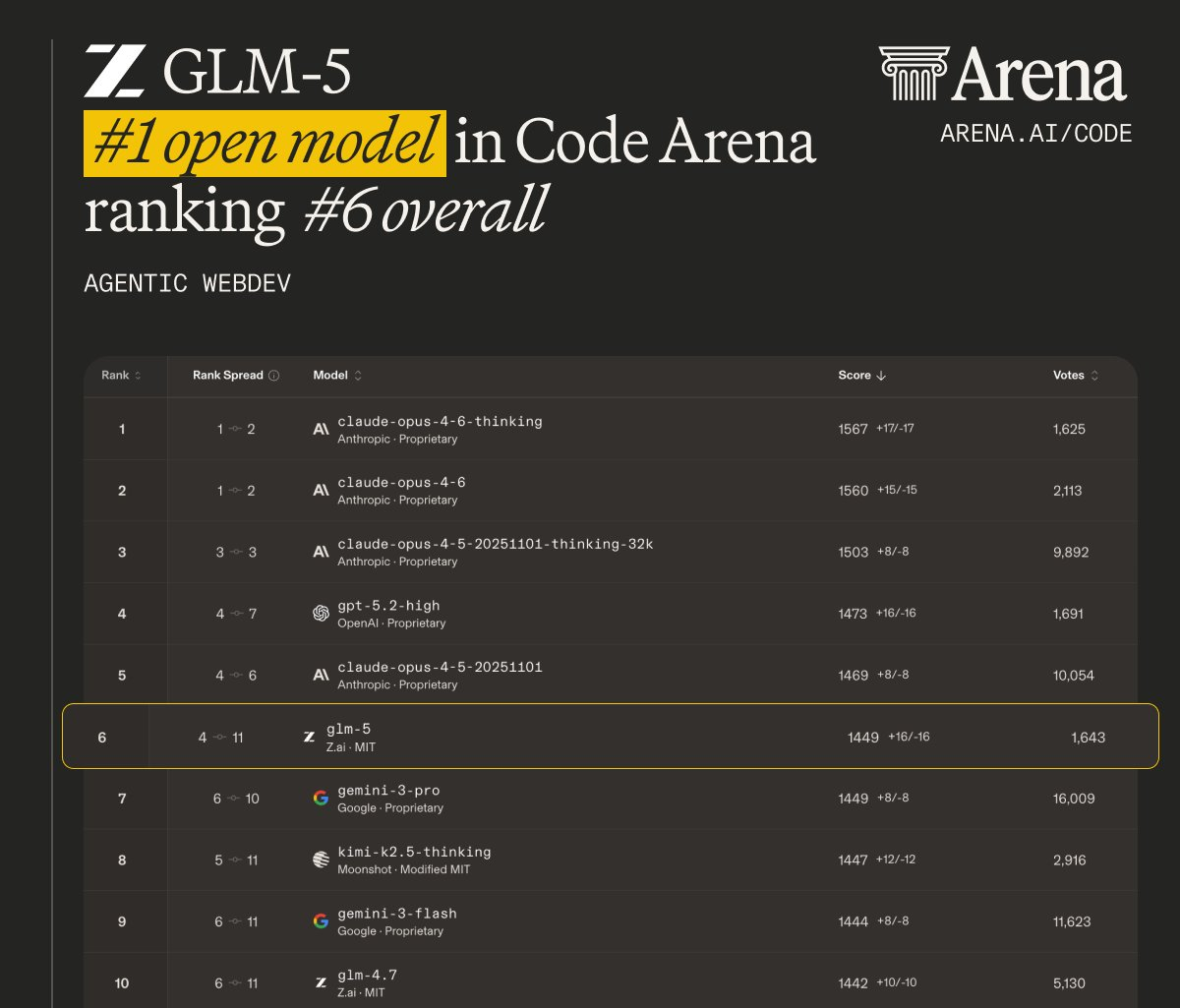
图解:LMArena Code Arena 排名,GLM-5 在开源模型中领先。
CC-Bench-V2:工程级真实性能
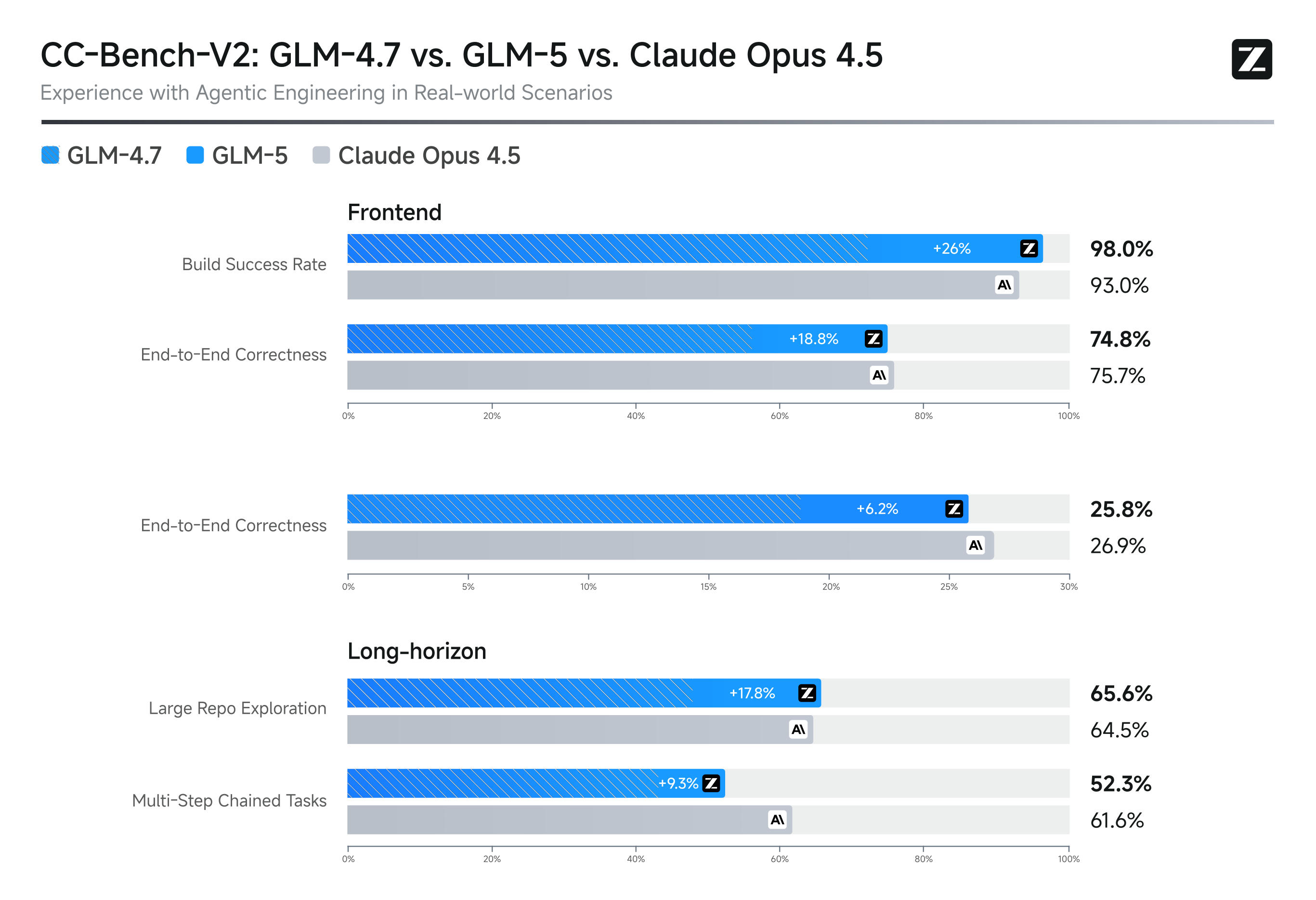
图解:前端/后端/长链任务三类工程基准。GLM-5 在 BSR 与 CSR 上明显改善,但 ISR 仍弱于最强闭源。
主要技术贡献总结
- DSA 稀疏注意力 :长上下文成本大幅降低。
- 异步 Agentic RL 基建 :训练吞吐稳定性全面提升。
- TITO + 双侧裁剪 IS :解决异步 RL off-policy 稳定问题。
- Cross-stage Distillation :多阶段 RL 不再"能力丢失"。
- Chinese GPU 全栈适配 :从 kernel 到 inference 完整打通。
结论
GLM-5 的意义不是"又一个 SOTA",而是从 模型能力 → 系统工程能力 的跃迁。
它真正把 Agentic Engineering 推向可复用、可扩展、可落地的工程范式:
- 长上下文稳定
- 多任务不互相伤害
- 环境规模化闭环
这套路线对开源生态的最大价值,是明确了"如何用工程方式训练出可靠代理"。
本文参考自 GLM-4.5: Open Foundation Models for Reasoning, Coding, and Agentic tasks