并不是全部题目
全部中等和困难,有空了做做在更新
1题
这个三方库直接过 curl_cffi
2题
AST 字面量还原 然后把代码展开 把几个三元运算的环境检测替换成真就可以
javascript
const parser = require('@babel/parser');
const traverse = require('@babel/traverse').default;
const generate = require('@babel/generator').default;
/**
* AST 反混淆主函数
* @param {string} code - 混淆的 JS 代码
* @returns {string} - 反混淆后的代码
*/
function deobfuscate(code) {
const ast = parser.parse(code, {
sourceType: 'script', // 或 'module'
allowReturnOutsideFunction: true,
// 根据需要启用插件,如 jsx、typescript、dynamicImport 等
plugins: []
});
traverse(ast, {
// === 在这里添加你的反混淆规则 ===
// 示例1: 解码 \x 十六进制字符串
StringLiteral(path) {
const raw = path.node.value;
let decoded = raw;
try {
decoded = raw.replace(/\\x([0-9a-fA-F]{2})/g, (_, hex) =>
String.fromCharCode(parseInt(hex, 16))
);
} catch (e) { /* ignore */ }
if (decoded !== raw) {
path.node.value = decoded;
}
},
// 示例2: 常量折叠(仅限纯字面量表达式)
BinaryExpression(path) {
const { operator, left, right } = path.node;
// 仅处理数字字面量的简单运算
if (
left.type === 'NumericLiteral' &&
right.type === 'NumericLiteral'
) {
let result;
switch (operator) {
case '+': result = left.value + right.value; break;
case '-': result = left.value - right.value; break;
case '*': result = left.value * right.value; break;
case '/': result = left.value / right.value; break;
default: return;
}
path.replaceWith({
type: 'NumericLiteral',
value: result
});
}
},
// 示例3: 清理 MemberExpression 中的逗号表达式:obj["", "key"] → obj.key
MemberExpression(path) {
if (path.node.computed && path.node.property.type === 'SequenceExpression') {
const exprs = path.node.property.expressions;
if (exprs.length > 0) {
const last = exprs[exprs.length - 1];
if (last.type === 'StringLiteral') {
path.node.property = last;
path.node.computed = false; // 转为 .property 形式
}
}
}
},
// 示例4: 删除无副作用的表达式(谨慎使用!)
ExpressionStatement(path) {
const { expression } = path.node;
// 例如:删除孤立的字符串字面量或数字(通常无意义)
if (
expression.type === 'StringLiteral' ||
expression.type === 'NumericLiteral'
) {
path.remove(); // 删除整行
}
}
// TODO: 添加你的其他规则,如:
// - 删除 debugger
// - 内联简单变量
// - 简化逻辑表达式
// - 控制流还原(高级)
});
return generate(ast, {
concise: true,
quotes: 'single',
retainLines: false
}).code;
}
// === 导出供外部使用 ===
// module.exports = deobfuscate;
const code = `function(){}......`;
const fs = require('fs');
// 假设 result 是你 console.log 输出的字符串
const result = deobfuscate(code);
// 写入
fs.writeFileSync('output.js', result.trim() + '\n');3题
下载 wasm 和 wasm_anti 文件 下方代码调用
javascript
import {promises as fs} from 'fs';
import {fileURLToPath} from 'url';
import {dirname, join} from 'path';
import init, {encrypt_simple, aes_encrypt, get_timestamp} from './wasm_anti.js';
async function main(verifyString) {
const __filename = fileURLToPath(import.meta.url);
const __dirname = dirname(__filename);
const wasmPath = join(__dirname, 'wasm_anti_bg.wasm');
const wasmBuffer = await fs.readFile(wasmPath);
const wasmUint8Array = new Uint8Array(wasmBuffer);
await init(wasmUint8Array);
const timestamp = Math.floor(get_timestamp() / 1000).toString();
const encrypted = encrypt_simple(verifyString, timestamp);
// 输出 JSON 格式,方便 Python 解析
console.log(JSON.stringify({ encrypted, timestamp }));
}
// 从命令行参数获取 verifyString
const verifyString = process.argv[2];
if (!verifyString) {
console.error('Usage: node hash.js <verifyString>');
process.exit(1);
}
main(verifyString).catch(err => {
console.error(err);
process.exit(1);
});5题
找到代码生成点 下方红框代码可以删除 最后补上字符串数字即可
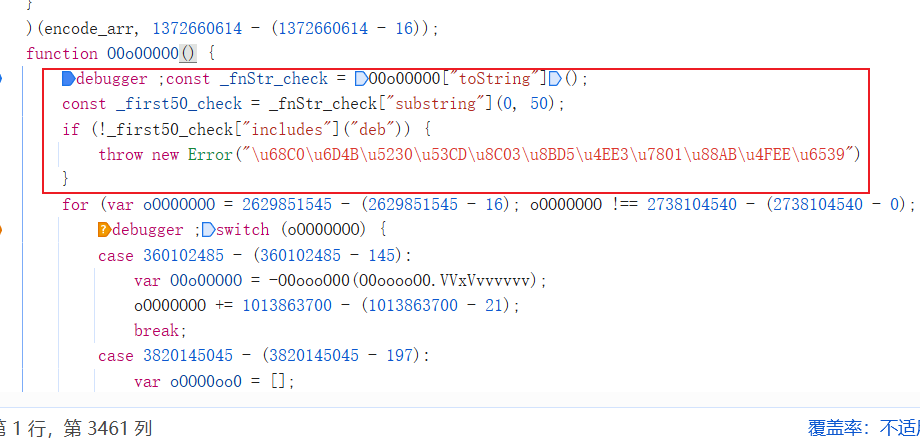
7题
解析css代码
python
import re
def solve_render_numbers(data_list):
results = []
# 假设一个标准字符的逻辑宽度,只要是正数即可,用于模拟文档流排位
CHAR_WIDTH = 15
for item in data_list:
html = item['display_html']
# 1. 解析 CSS 变量
var_map = {}
css_vars = re.findall(r'(--[\w-]+):\s*calc\((.*?)\);', html)
def safe_eval(expr, v_map):
# 转换 CSS 函数为 Python 可执行函数
temp = expr.replace('px', '').replace('min', 'min').replace('max', 'max')
# 替换嵌套的变量
for k, v in v_map.items():
temp = temp.replace(f'var({k})', str(v))
try:
# 这里的 eval 处理简单的数学运算和 min/max
val = eval(temp, {"min": min, "max": max})
return val[0] if isinstance(val, (tuple, list)) else val
except:
return 0
# 迭代解析变量依赖
for _ in range(len(css_vars)):
for name, expr in css_vars:
if name not in var_map:
var_map[name] = safe_eval(expr, var_map)
# 2. 提取 body 中的所有数字(包含 span 和 纯文本)
body = html.split('</style>')[-1] if '</style>' in html else html
# 匹配 <span...>数字</span> 或 纯数字
# pattern 考虑了 left 和 right 两种位移方向
pattern = re.compile(r'(<span[^>]*?style="[^"]*?(left|right):var\((--[\w-]+)\)[^>]*?>(.*?)</span>)|(\d)')
elements = []
current_doc_index = 0
# 针对 HTML 逐个扫描,确保原始顺序
# 因为正则对混合文本(如 "2<span>1</span>")处理较弱,这里先简单拆分
import xml.etree.ElementTree as ET
try:
# 补齐标签使其成为合法 XML 片段
wrapped = f"<root>{body}</root>"
# 使用更稳健的正则来逐个标记解析
# 这里简化处理:按字符顺序扫描并计算坐标
tokens = re.finditer(r'<span.*?>(.*?)</span>|(\d)', body)
for match in tokens:
full_span = match.group(0)
char = match.group(1) or match.group(2)
offset = 0
if full_span.startswith('<span'):
# 识别位移量
var_match = re.search(r'(left|right):var\((--[\w-]+)\)', full_span)
if var_match:
direction = var_match.group(1)
var_name = var_match.group(2)
val = var_map.get(var_name, 0)
offset = val if direction == 'left' else -val
# 最终坐标 = 原始占位 + 位移
final_x = (current_doc_index * CHAR_WIDTH) + offset
elements.append((final_x, char))
current_doc_index += 1
except Exception as e:
# 如果解析出错(如 HTML 极其不规范),退回到纯文本提取
results.append(re.sub(r'<[^>]+>', '', html))
continue
# 2. 排序并组合
elements.sort(key=lambda x: x[0])
results.append(int("".join([e[1] for e in elements])))
print(results)8题
读取 字体 转xml 获取上标 英文译中 取值
python
# 引入请求woff表
font2 = TTFont("./AntiSpiderFont.woff2")
# 转
font2.saveXML("font2.xml")
# 获取请求表中的上标
orders = font2.getGlyphOrder()[1:]
# 英译
Comparison = {
'zero': '0',
'one': '1',
'two': '2',
'three': '2',
'four': '4',
'five': '5',
'six': '6',
'seven': '7',
'eight': '8',
'nine': '9'
}
dic = {}
for i, a in enumerate(orders):
dic[Comparison[a]] = str(i)11题
识别图片即可
12题
下载gif 截取每一帧 返回最小的一帧
python
def extract_smallest_frame(self, gif_bytes: bytes) -> bytes:
"""从 GIF 字节中提取体积最小的一帧,返回 PNG 字节"""
with BytesIO(gif_bytes) as gif_buffer:
with Image.open(gif_buffer) as im:
min_size = float('inf')
best_png_bytes = None
for i in range(im.n_frames):
im.seek(i)
frame = im.convert('RGBA')
png_buffer = BytesIO()
frame.save(png_buffer, format='PNG')
size = png_buffer.tell()
if size < min_size:
min_size = size
best_png_bytes = png_buffer.getvalue()
png_buffer.close()
return best_png_bytes13题
识别提交即可
14题
识别提交 处理下缩放即可
python
print("缺口横坐标 x =", round(x * 400 / 840))15题
识别提交 处理下缩放即可
python
print("缺口横坐标 x =", round(x * 400 / 840))21题
关键字搜索直接定位
python
def spiderdemo_hash(e, t, n):
"""
还原 JavaScript 的 hash_challenge 函数
"""
# 构造字符串 s = `${e}_${t}_${n}`
s = f"{e}_{t}_{n}"
# 1. HMAC-SHA256
hmac_key = "spiderdemo_hmac_secret_2025".encode('utf-8')
hmac_hash = hmac.new(hmac_key, s.encode('utf-8'), hashlib.sha256).hexdigest()
# 2. MD5
md5_salt = "spiderdemo_md5_salt_2025"
md5_hash = hashlib.md5((s + md5_salt).encode('utf-8')).hexdigest()
# 2. SHA256 (需要变量 o)
sha256_hash = hashlib.sha256((s + 'spiderdemo_sha_salt_2025').encode('utf-8')).hexdigest()
# 4. SHA3-256 (需要变量 o)
sha3_256_hash = hashlib.sha3_256((s + 'spiderdemo_sha_salt_2025').encode('utf-8')).hexdigest()
return {
'hmac': hmac_hash,
'md5': md5_hash,
'sha256': sha256_hash,
'sha3_256': sha3_256_hash
}22题
关键字搜索直接定位
python
import time
import requests
from Crypto.Cipher import DES
from Crypto.Util.Padding import pad
from Crypto.Cipher import AES
from Crypto.Util import Counter
import base64
def des_encrypt(e):
# 密钥 "6f726c64" 转为字节
key = "6f726c64".encode('utf-8')
# IV "01234567" 转为字节
iv = "01234567".encode('utf-8')
# 创建DES cipher对象,CBC模式
cipher = DES.new(key, DES.MODE_CBC, iv)
# PKCS7填充并加密
padded_data = pad(e.encode('utf-8'), DES.block_size)
encrypted = cipher.encrypt(padded_data)
# 返回Base64字符串(与CryptoJS.toString()一致)
import base64
return base64.b64encode(encrypted).decode('utf-8')
def aes_encrypt_ofb(e):
key = "12345678901234567890123456789012".encode('utf-8')
iv = "abcdefghijklmnop".encode('utf-8')
# 创建AES cipher对象,OFB模式
cipher = AES.new(key, AES.MODE_OFB, iv=iv)
# 无填充直接加密(NoPadding)
# 注意:数据长度必须是16字节的倍数
data = e.encode('utf-8')
# 如果数据不是16字节倍数,需要手动处理
# 这里按照原JS代码直接加密(JS的NoPadding也不会自动填充)
encrypted = cipher.encrypt(data)
# 返回Base64字符串(与CryptoJS.toString()一致)
return base64.b64encode(encrypted).decode('utf-8')
def aes_encrypt_ctr(e):
key = "1234567890123456".encode('utf-8')
iv = "abcdefghijklmnop".encode('utf-8')
# 使用 Counter 模拟 CryptoJS 的 CTR 行为
# iv 作为初始计数器值
ctr = Counter.new(128, initial_value=int.from_bytes(iv, 'big'))
cipher = AES.new(key, AES.MODE_CTR, counter=ctr)
data = e.encode('utf-8')
encrypted = cipher.encrypt(data)
return base64.b64encode(encrypted).decode('utf-8')23题
关键字搜索直接定位
python
const forge = require('node-forge');
const crypto = require('crypto');
function u(e) {
const publicKeyPem = `-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQC1vKwZUIv7pgpJUXXPpDlD4+VE
on3a0ANOrNmqAESrcGfkmYzDCo2JeuYezhBGjBNjwVmSct/Y3BBOCRGT2bvtCJGd
S12RMvHbFcdbwS/Adh48+rhLiMNYXLm+7pI3e2k6TlScxKa7EeeZpVtew/Cv5z6o
l0llNPp6BdqAlOa8DwIDAQAB
-----END PUBLIC KEY-----`;
const publicKey = forge.pki.publicKeyFromPem(publicKeyPem);
// JSEncrypt 默认使用 PKCS#1 v1.5 填充(不是 OAEP),且加密前会 UTF-8 编码
const encrypted = publicKey.encrypt(e, 'RSAES-PKCS1-V1_5', {
md: null, // 不使用 OAEP 的 hash
mgf: null
});
// 返回 Base64 编码结果,与 JSEncrypt 行为一致
return forge.util.encode64(encrypted);
}
function signWithPrivateKey(data) {
// 你的私钥(注意:保留完整 PEM 格式)
const privateKey = `-----BEGIN RSA PRIVATE KEY-----
MIICXAIBAAKBgQC1vKwZUIv7pgpJUXXPpDlD4+VEon3a0ANOrNmqAESrcGfkmYzD
Co2JeuYezhBGjBNjwVmSct/Y3BBOCRGT2bvtCJGdS12RMvHbFcdbwS/Adh48+rhL
iMNYXLm+7pI3e2k6TlScxKa7EeeZpVtew/Cv5z6ol0llNPp6BdqAlOa8DwIDAQAB
AoGAS0GaWI9AsFAFEXBgoz/jkMf14DKTgEFEJVexeNLMnNuawhCNuBSOIMCaO2Zk
WfpWaygdUeYs6M3UGKRruXhf92g/BRmJK5FzR0kWW4qw6WwlYob3TPc3c9MFOjmp
VtWQ0VSeEPrnBNoQRccKl0dGBnToHGuV+KEuKx8oWZc/JM0CQQDH/cvlx0BKz2zN
6PM8FidAvc+Wgon8YW81KJgC7iJIrK9FOpctOE3L1pdF7guOQNVGRqN4HCIgLfHE
cqxWJKJtAkEA6KIkwHe/Q23uWH5GP8DHtVkLVfohTumYkpb0rk05EYQ0dsWSNzWH
XDH/kD6ayNq+fscnS8g+59onzvfhJ0bq6wJBAKNFkDEHenWY4js481sauvEgBVnb
OMvSv/emLHQ39cVfNbhPHRzN2rWPe/CbZtO8GmJFSS/FyBZ9a+P1uryZLAECQAaw
ApZ12s25b0yj9KkIhbU05hqGokZ+eKBeLpKELcvPHSL88wMbStTfqxUed5ymjStf
1kVbcFOB9fsBLTvP0hkCQFCON0l1VjFli+vqfN0lypgIqCf85V6FZFN19creGCCd
76pX/X2FIBbUSDN1z48SM5I/RKdCkTx7FY+509q2Mek=
-----END RSA PRIVATE KEY-----`;
const signer = crypto.createSign('SHA256');
signer.update(data); // 默认是 'utf8' 编码
signer.end();
const signature = signer.sign({
key: privateKey,
padding: crypto.constants.RSA_PKCS1_PADDING // JSEncrypt 默认使用 PKCS#1 v1.5
}, 'base64'); // 返回 Base64 字符串,与 JSEncrypt 一致
return signature;
}
function hmacSHA256(data, secret) {
return crypto
.createHmac('sha256', secret)
.update(data, 'utf8') // 明确指定输入编码(通常为 utf8)
.digest('hex'); // CryptoJS.HmacSHA256(...).toString() 默认输出 hex
}
function X(s) {
return [u(s), signWithPrivateKey(s),u(s+'_param'),hmacSHA256(s,'dsa_secret_key_2025')]
}
var str = "2_fsymmetry_challenge_1771051703027"
console.log(X(str));33题
x-caesar-token 也就他难看点
_encrypted_type 这个直接window hook就出了
解混后代码
javascript
const CryptoJS = require('crypto-js');
window = globalThis
window._caesar_encrypt_fn = function(text, shift=7) {
window._encrypt_text = text;
window._encrypt_shift = shift;
window._encrypt_result = [];
for (let i = 0; i < text.length; i++) {
window._char = text[i];
if (/[a-z]/.test(window._char)) {
window._shifted = ((window._char.charCodeAt(0) - 97 + shift) % 26 + 26) % 26 + 97;
window._encrypt_result.push(String.fromCharCode(window._shifted));
} else if (/[A-Z]/.test(window._char)) {
window._shifted = ((window._char.charCodeAt(0) - 65 + shift) % 26 + 26) % 26 + 65;
window._encrypt_result.push(String.fromCharCode(window._shifted));
} else if (/[0-9]/.test(window._char)) {
window._shifted = ((parseInt(window._char) + shift) % 10 + 10) % 10;
window._encrypt_result.push(window._shifted.toString());
} else {
window._encrypt_result.push(window._char);
}
}
return window._encrypt_result.join('');
}
;
window._caesar_decrypt_fn = function(text, shift=7) {
window._decrypt_text = text;
window._decrypt_shift = shift;
return window._caesar_encrypt_fn(text, -shift);
}
;
function caesarDecrypt(text, shift) {
return window._caesar_decrypt_fn(text, shift);
}
function getDynamicShift(pageNum) {
const _caesar_key = 'spiderdemo_caesar_2025';
const _text_to_hash = `${_caesar_key}_${pageNum}`;
const _md5_hash = CryptoJS.MD5(_text_to_hash).toString();
const _hex_prefix = _md5_hash.substring(0, 2);
const _shift_value = parseInt(_hex_prefix, 16) % 25 + 1;
return _shift_value;
}
function lin(index,data){
const shift = getDynamicShift(index)
return data.map(encryptedNum => {
const decrypted = caesarDecrypt(encryptedNum.toString(), shift);
return parseInt(decrypted);
})
}
// 上面 lin 为响应解密
// 下面 cheng 为 t值加密
function caesarEncrypt(text, shift) {
return window._caesar_encrypt_fn(text, shift);
}
function cheng(page,ts){
let _token_data = `${page}_jsfuck_challenge_${ts}`
return caesarEncrypt(_token_data,getDynamicShift(page))
}