1. 多模态的定义与边界
1.1 单模态到多模态的概念与演进
多模态技术的发展是人工智能从"单一信息认知"向"类人多维度协同认知"的核心演进过程,本节将从核心概念界定 、模态与数据类型 、关键边界厘清 、技术演进脉络四个维度,系统梳理单模态到多模态的发展逻辑,形成完整的知识框架。
1.1.1 核心概念:单模态、模态与多模态
1.1.1.1 模态(Modality)的本质定义
模态 是信息的来源或存在形式,是机器感知和理解世界的"信息维度"。在人工智能领域,任何具备独立表征形式的信息载体,都可被定义为一种模态。
核心特征与关键区分:
- 基础模态类型:文本/语义、音频/语音、图像、视觉、传感器数据等;
- 重要误区澄清:视觉 ≠ 视频 ,在多模态语境中,视频是复合模态载体,其本质为「视觉帧(静态视觉)+ 音频(时序声学)+ 可选文本字幕」的多模态组合。

1.1.1.2 单模态(Single-modality)
单模态指系统仅能处理、理解一种 模态的信息,是人工智能发展早期的主流形态。其核心特点是"信息维度单一、处理逻辑简单",但存在认知局限------无法利用不同模态的互补信息完成复杂任务。
典型示例:纯文本分类模型、单帧图像识别算法、孤立的语音识别系统。
1.1.1.3 多模态与多模态机器学习(MMML)
多模态 :指两种及以上不同模态信息的组合与协同,核心是实现不同模态间的"关联、对齐、融合"。
多模态机器学习(MMML, MultiModal Machine Learning) :是实现多模态认知的技术核心,指利用机器学习方法,对两种及以上异质模态信息进行表征、融合与推理的技术体系。
核心基础:图像-语义对是多模态研究的核心起点,图像承载静态视觉语义,音频承载时序声学语义,二者结合构成最基础的跨模态语义理解场景。
1.1.2 模态分类与多模态数据类型
1.1.2.1 常见模态的分类与示例
根据信息的感知与表征方式,主流模态可分为四大类,覆盖从"人工符号"到"物理感知"的全场景:
| 模态类别 | 核心特征 | 典型示例 |
|---|---|---|
| 文本模态 | 离散符号表征,承载抽象语义 | 自然语言文字、编程语言代码、数据表格 |
| 语音模态 | 时序声学信号,承载语音语义与情感 | ASR(自动语音识别)、声纹识别、TTS(文本转语音) |
| 视觉模态 | 像素/帧序列表征,承载空间与视觉语义 | 静态图像、动态视频帧 |
| 传感器模态 | 物理量测信号,承载环境与运动信息 | LiDAR(激光雷达)、IMU(惯性测量单元)、可穿戴设备传感数据 |
1.1.2.2 从单模态数据到多模态数据的结构演进
单模态数据是"单一载体的信息单元",多模态数据则是不同模态载体的结构化组合,按关联方式可分为三大核心类型,决定了多模态模型的处理逻辑:
| 多模态数据类型 | 核心定义 | 数据结构特征 | 典型应用场景 |
|---|---|---|---|
| 成对数据(Paired Data) | 两种模态"一对一"刚性绑定 | 模态数=2,存在明确的语义对应关系 | 图像-文本标注对、音频-文本转录对、视频-字幕对 |
| 成组数据(Grouped Data) | 三种及以上模态"协同关联" | 模态数≥3,无严格一对一绑定,为场景化组合 | 新闻报道(文本+图像+视频+音频)、电商商品(图像+文本+演示视频) |
| 序列数据(Sequential Data) | 至少一种模态随时间同步演进 | 含时序特征,模态数≥1,时间维度为核心约束 | 自动驾驶多传感器时序数据、可穿戴设备健康监测数据 |
1.1.3 关键边界:多模态与AIGC的关系厘清
多模态与AIGC(人工智能生成内容)是包含与被包含的关系,而非等同关系,这是理解多模态边界的核心要点。
1.1.3.1 常见误区纠正
❌ 错误认知:"多模态=多输入单输出,AIGC=单输入单输出";
✅ 正确结论:二者的输入输出形式无固定限制,核心差异在于任务目标 。
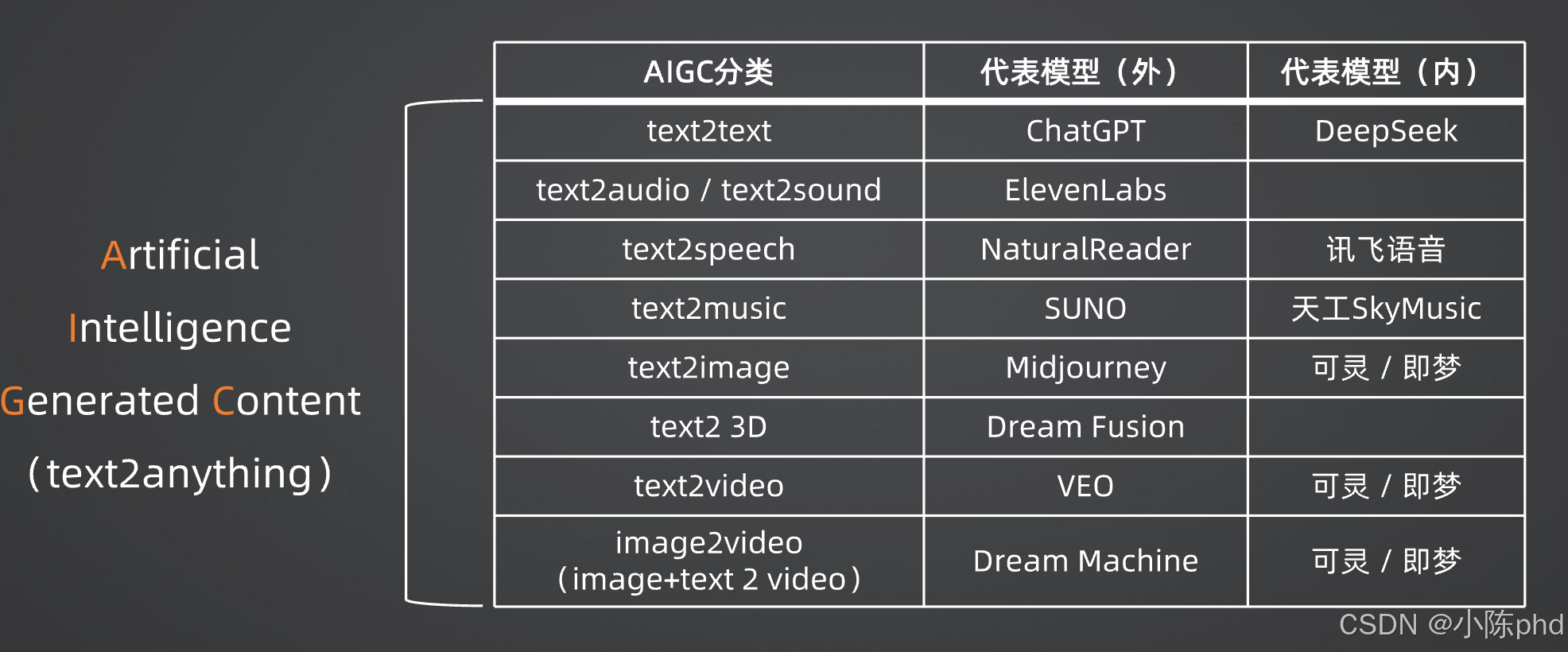
1.1.3.2 核心关系与任务范畴
- 从属关系:AIGC ⊂ 多模态任务-生成类,AIGC是多模态技术在"内容生成"场景的具体应用;
- 多模态任务的完整范畴:远超AIGC,涵盖四大核心类型,覆盖"理解、生成、检索、控制"全链路:
| 多模态任务类型 | 核心目标 | 典型场景 |
|---|---|---|
| 生成类 | 从一种/多种模态生成目标模态内容 | 文本生成图像、音频生成视频、多模态内容创作(AIGC核心场景) |
| 理解类 | 解析多模态信息的语义与关联 | 图像描述、视觉问答(VQA)、语音情感识别、医学影像多模态诊断 |
| 检索类 | 跨模态匹配相似语义信息 | 以文搜图、以图搜文、以音频搜视频、影视多模态推荐 |
| 推理与控制类 | 基于多模态信息完成决策与控制 | 游戏AI、自动驾驶多传感器融合控制、人形机器人动作规划 |

1.1.4 技术演进脉络:从萌芽到体系化
多模态技术的发展,受数据、算法、算力三大核心要素驱动,经历了四个关键阶段,实现了从"浅层交互"到"深度语义融合"的范式革命。
1.1.4.1 1970s:多模态探索的萌芽期(语音-视觉执行闭环)
这是人类首次系统性突破单模态局限,开启多模态交互探索的起点。
- 核心事件:1971年,美国DARPA启动为期5年(1971-1976)的SUR(Speech Understanding Research)计划,目标是开发具备1000词汇量的语音理解系统,核心愿景为"说一句话让机器在屏幕上执行命令"。
- 核心成果:卡内基梅隆大学(CMU)研发的Harpy系统,可识别约1000个词汇(相当于3岁儿童词汇量),实现了「语音(听觉模态)→ 文本(文本模态)→ 屏幕命令执行(视觉模态)」的早期跨模态闭环。
- 参与主体:CMU、IBM、斯坦福研究所等顶尖机构,奠定了多模态"跨模态映射"的核心逻辑。
1.1.4.2 1980s-1990s:人机交互探索期(瓶颈凸显)
此阶段聚焦多模态人机交互场景,但受限于技术条件,未能实现实质性突破。
- 关键探索:1985年MIT媒体实验室成立,探索全息影像、虚拟现实等电子介入式人机交互技术,尝试融合视觉、音频模态打造沉浸式交互体验。
- 核心瓶颈("三缺"):
- 数据稀缺:无大规模成对的语音-图像、图像-文本数据集;
- 算法局限:依赖手工特征工程与传统统计方法,无法捕捉"跨模态语义关联";
- 算力不足:计算机处理单一模态(语音/图像)已达性能上限,无法支撑多模态并行处理。
1.1.4.3 2000s:统计学习尝试期(对齐难题凸显)
传统统计机器学习的普及,让多模态技术进入"浅层应用"阶段,但核心瓶颈------跨模态语义对齐仍未解决。
- 技术进展:HMM、SVM等统计学习算法流行,实现了"文字搜图"等简易多模态检索任务。
- 核心痛点:
- 模态表征异构性:文本是离散符号、语音是连续波形、图像是像素矩阵,缺乏统一的表征空间;
- 跨模态语义鸿沟:如"图片中的小猫"与"文本中的kitten"语义等价,但技术上无法实现精准对齐;
- 行业共识:研究者明确"模态对齐"是多模态技术的核心,但受限于算法与算力,无法突破。
1.1.4.4 2010s及之后:深度学习驱动的体系化成熟期(范式革命)
深度学习的出现成为多模态技术的"转折点",彻底解决了"表征统一"与"语义对齐"的核心难题,推动多模态学习走向体系化。
- 核心技术突破:
- 文本建模:从RNN到Transformer,解决了长距离依赖与上下文语义建模问题;
- 视觉建模:从CNN到ViT(视觉Transformer),实现了从"局部卷积特征"到"全局自注意力特征"的升级;
- 表征统一:Embedding向量化技术,构建了统一语义空间,让不同模态的信息可在同一空间中对齐、融合与推理。
- 体系化发展:多模态学习形成五大核心研究方向,构建了完整的技术体系:
① 多模态表示学习(Multimodal Representation);
② 模态转化(Translation);
③ 对齐(Alignment);
④ 多模态融合(Multimodal Fusion);
⑤ 协同学习(Co-learning)。
从单模态到多模态的演进,本质是人工智能认知能力的三次升级:
- 从"单一信息维度处理"到"多信息维度协同";
- 从"手工规则驱动"到"数据与算法联合驱动";
- 从"浅层交互执行"到"深度语义理解与生成"。
这一演进过程,是人工智能向"类人智能"迈进的核心路径,而"模态对齐"与"统一语义空间",则是贯穿始终的核心技术主线。