地铁上,你戴着 AirPods Pro 打开降噪,车厢轰鸣瞬间消失。与此同时,在某个音频实验室里,工程师正把一段嘈杂的录音拆成人声和背景声两条轨道。这两件事看起来毫无关系------但它们回答的是同一个问题。
一、背景:一副耳机引发的信号处理问题
1.1 你真的理解降噪在做什么吗?
AirPods Pro 的降噪体验太自然了,自然到大多数人从未想过背后发生了什么。
但仔细想一下就会觉得不对劲:它凭什么知道哪些声音该消掉、哪些该保留? 它并不知道你在听什么歌,也不理解播客主持人在说什么,但就是能精准地只压制环境噪声。这背后,是一个非常经典的信号处理问题。
1.2 另一个看似无关的场景
在音频工程的另一个角落,有人在做一件不同的事:拿到一段混合音频,用模型把人声和背景声 拆成两条独立轨道。这叫 Source Separation(声源分离)。
降噪耳机和声源分离,一个是消费电子,一个是音频算法。但把核心逻辑抽象出来,你会发现它们在回答同一个问题:在一段混合信号中,如何定义并处理"非目标成分"?
1.3 为什么值得深入理解
这不只是一个有趣的类比。理解这层关系,能帮你:
- 建立统一的信号处理直觉:降噪、分离、增强,是同一框架的不同实例化
- 做出更好的工程决策:什么场景降噪就够,什么场景必须显式分离
- 看清技术演进方向:为什么现代音频系统越来越倾向"先分离、再处理"
二、基础知识:降噪与分离,到底在做什么
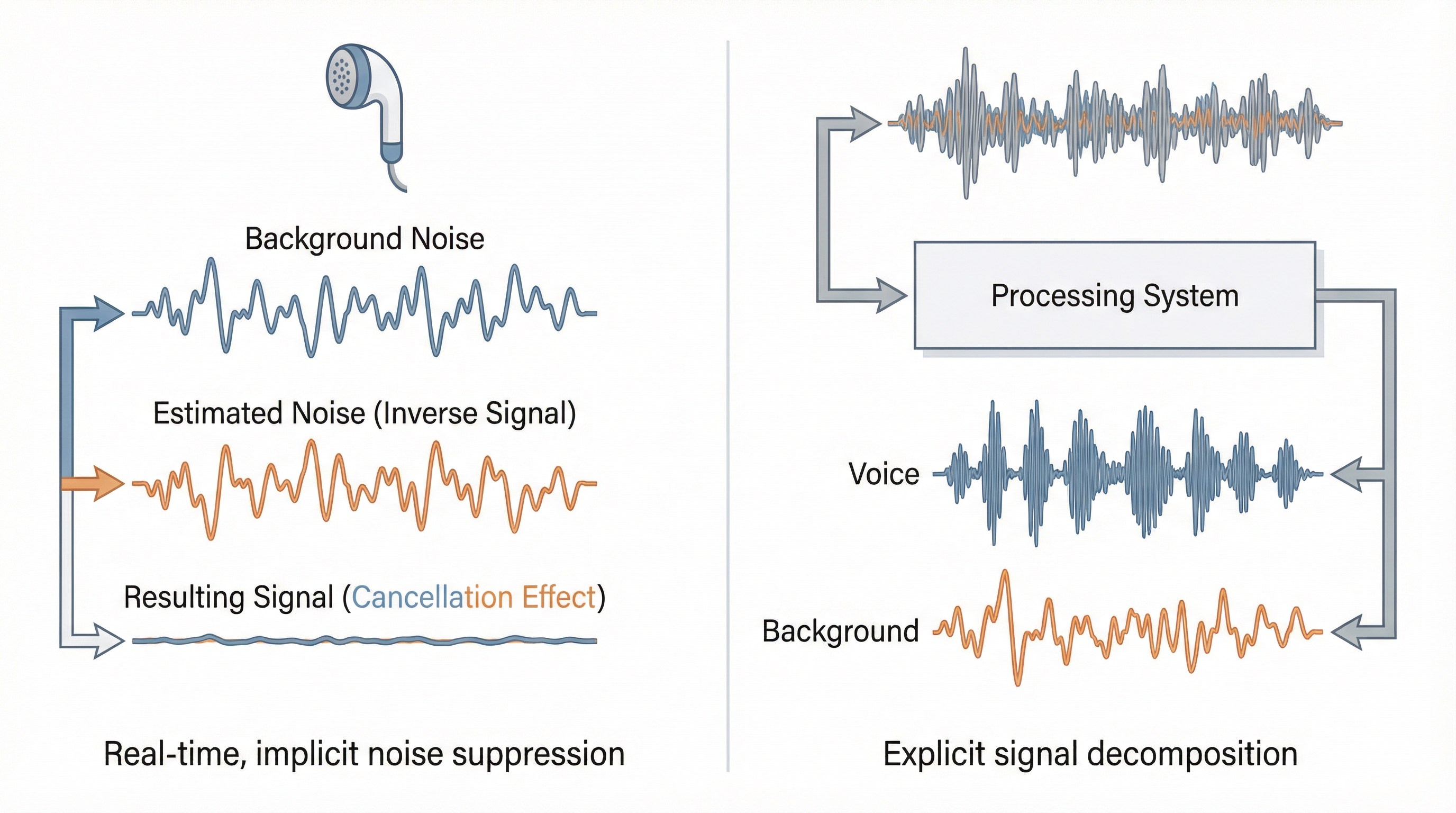
2.1 主动降噪(ANC):我不管世界长什么样,我只要安静
ANC(Active Noise Cancellation)的工程定义比你想的更精确:实时估计环境中的"非目标声音",生成一段反相声波进行抵消。
注意几个关键词:实时 、估计 、反相抵消 。它不理解内容,不区分语义,甚至不知道你在听什么。它只关心一件事:当前有哪些声音不该出现在你的耳朵里?
2.2 声源分离(Source Separation):先把世界拆开,再做决定
Source Separation 走的是另一条路,做得更"重",但也更彻底:
- 输入:一段混合音频(人声 + 环境声)
- 输出 :多条独立轨道------
voice(语音)和background(背景声)
关键区别在于:降噪是 做减法 ------我不要什么就去掉什么;分离是 做解构------先搞清楚世界由什么构成,再决定怎么处理每一部分。
2.3 一句话区分
ANC 只关心"我不想听什么",Source Separation 关心"世界由什么构成"。
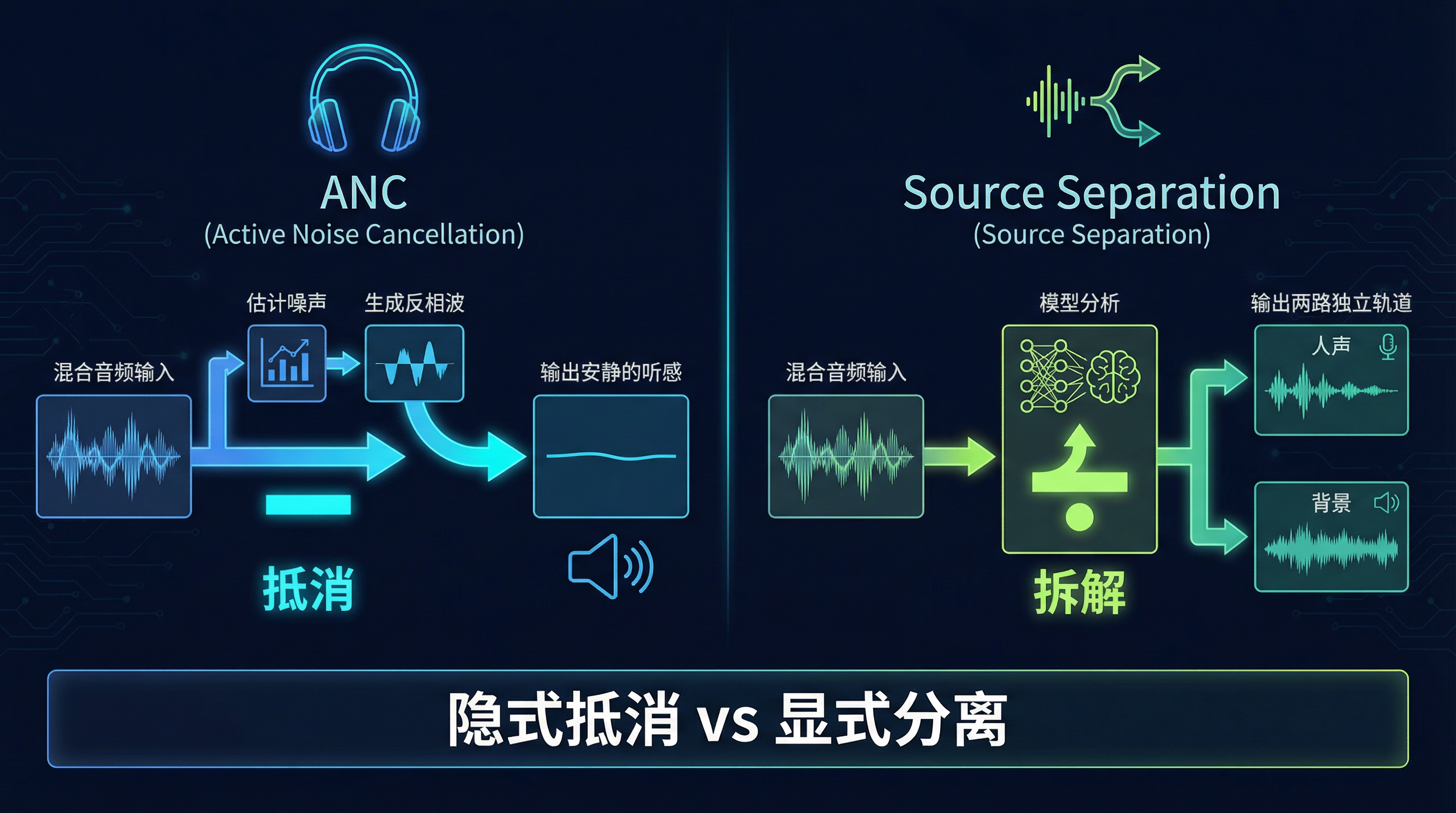
三、技术原理:同一个公式,两种解法
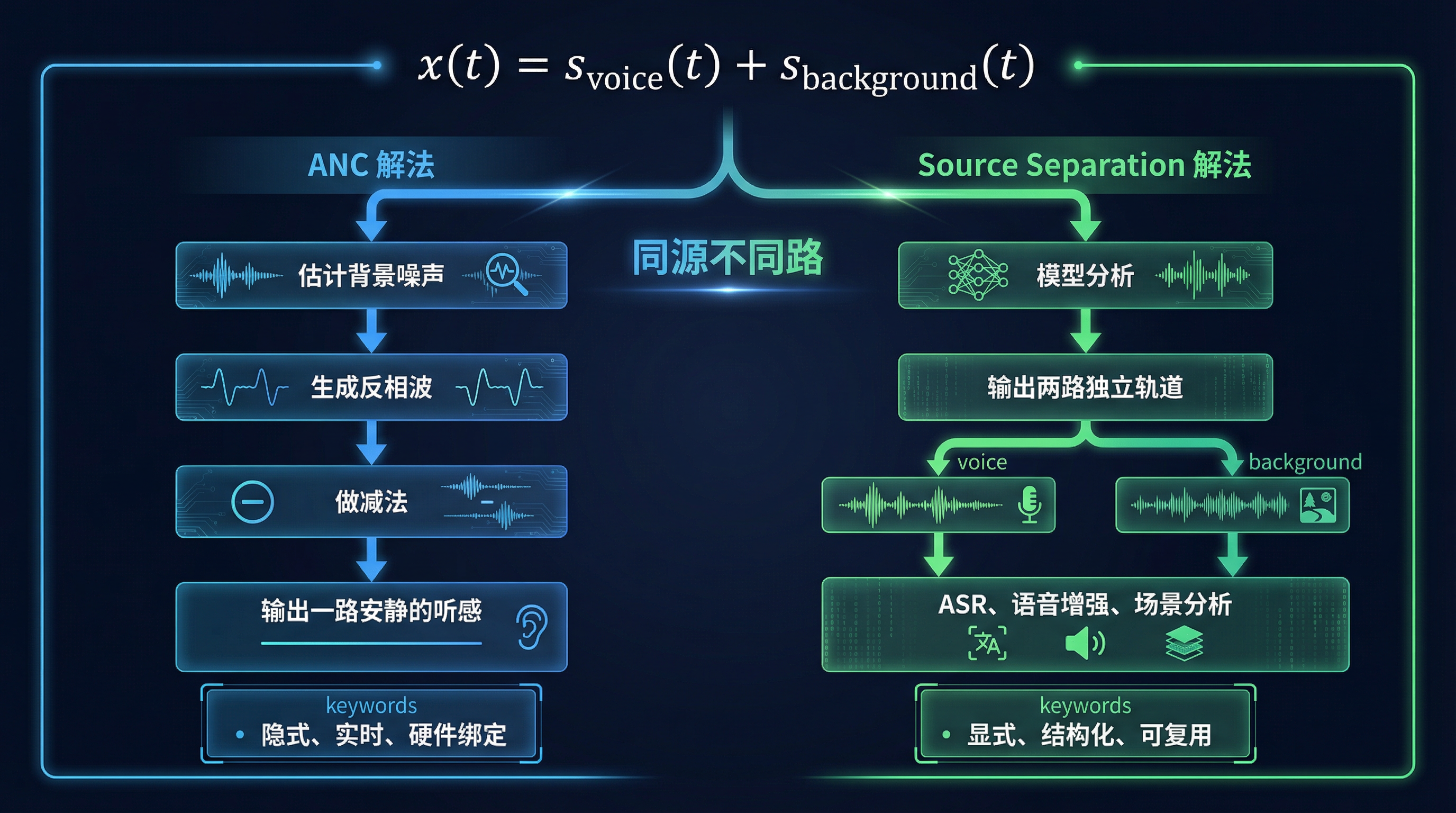
3.1 统一信号模型
不管是降噪还是分离,面对的原始信号都可以用同一个模型描述:
x(t)=svoice(t)+sbackground(t) x(t) = s_{\text{voice}}(t) + s_{\text{background}}(t) x(t)=svoice(t)+sbackground(t)
其中 x(t)x(t)x(t) 是麦克风采集到的混合信号,svoice(t)s_{\text{voice}}(t)svoice(t) 是目标语音,sbackground(t)s_{\text{background}}(t)sbackground(t) 是环境噪声。
降噪和分离,都是在对这个公式做文章------只是做法截然不同。
3.2 AirPods ANC 的解法:隐式估计 + 实时抵消
ANC 不会显式输出 voice 或 background,但它在实时估计 s^background(t)\hat{s}{\text{background}}(t)s^background(t),然后直接做减法:
s^voice(t)=x(t)−s^background(t) \hat{s}{\text{voice}}(t) = x(t) - \hat{s}_{\text{background}}(t) s^voice(t)=x(t)−s^background(t)
公式很简洁,但 它具体是怎么估计的?
(1) 结构说明
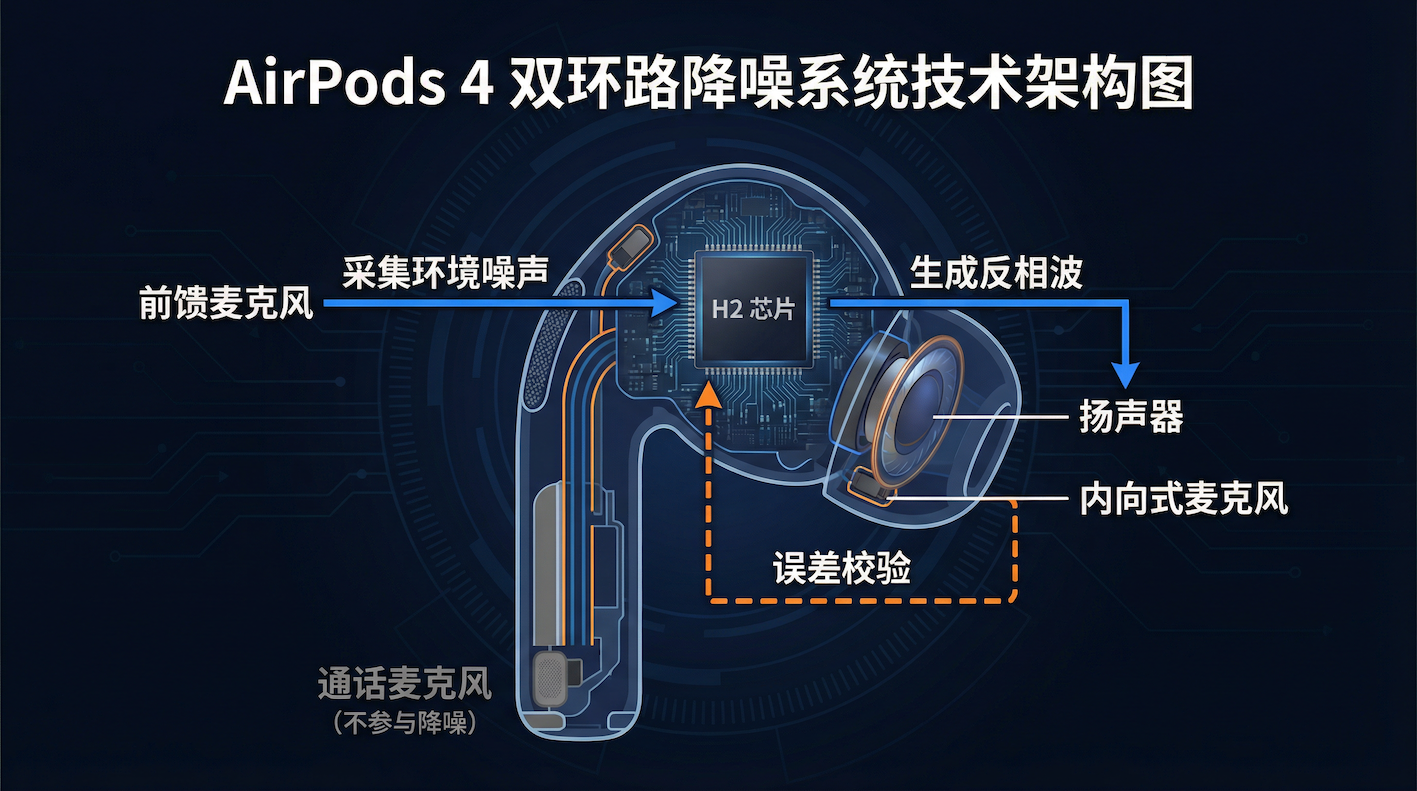
以 AirPods 4 降噪版为例,拆解发现它搭载了 3 颗 MEMS 麦克风,其中两颗专门服务于 ANC,构成了一个 "外采 + 内校"的双回路架构:
| 麦克风 | 位置 | 作用 |
|---|---|---|
| 前馈麦克风(G205) | 耳机柄外侧上方 | 拾取外界环境噪声,提供降噪的"原始输入" |
| 内向式麦克风(S341) | 出音嘴内侧 | 监测耳内实际声场,校验降噪效果 |
| 通话麦克风(S341) | 耳机柄底部 | 拾取人声,仅用于通话,不参与降噪 |
两颗降噪麦克风配合 H2 芯片,形成一个闭环:
- 前馈麦克风 在外侧采集环境噪声 s^background(t)\hat{s}_{\text{background}}(t)s^background(t),送给 H2 芯片
- H2 芯片实时计算反相波,叠加到扬声器输出上
- 内向式麦克风在耳内检测抵消效果,将残余误差反馈给芯片,实时修正
这就是"外采 + 内校"------前馈负责"估计",内向式负责"纠错"。有趣的是,AirPods 4 标准版和降噪版的核心硬件差异,就是那颗外侧的前馈麦克风。少了它,整个闭环就断了。一颗麦克风的有无,决定了产品能力的质变。
(2) 核心挑战
从工程约束看,ANC 的核心挑战不在算法复杂度,而在 "快"和"准"的平衡:
-
延迟必须极低:处理链路在微秒到毫秒级,反相波稍有延迟就对不齐,降噪立刻失效
-
硬件深度绑定:麦克风位置、扬声器特性、耳道密封性都直接影响效果
-
不追求完美分离:听感上"安静了"就够,不需要输出干净的独立轨道
ANC 是用硬件闭环换来的极致低延迟降噪,代价是放弃了信号的可解释性。
3.3 Source Separation 的解法:显式建模 + 结构化输出
Source Separation 则走了一条完全不同的路。它显式估计每一个分量:
s^voice(t)ands^background(t) \hat{s}{\text{voice}}(t) \quad \text{and} \quad \hat{s}{\text{background}}(t) s^voice(t)ands^background(t)
然后根据下游任务灵活使用:
- 保留人声 → 用于 ASR(语音识别)、字幕生成
- 抑制背景声 → 用于语音增强、通话降噪
- 再利用背景声 → 用于音频编辑、场景分析、环境音重建
ANC 输出的是一个"结果",Source Separation 输出的是一套"素材"。 前者只能听,后者可以被系统性地分析、加工和复用。
3.4 全景对比
| 维度 | AirPods ANC | Source Separation |
|---|---|---|
| 是否实时 | 是(ms 级) | 否 / 准实时 |
| 是否显式分轨 | 否 | 是 |
| 是否关心语义 | 否 | 是 |
| background 是否有价值 | 否(直接丢弃) | 是(可分析、可复用) |
| 核心约束 | 延迟、硬件、功耗 | 精度、可解释性 |
| 工程目标 | 听感优化 | 信号结构化 |
四、实践视角:什么时候该用哪种方案
4.1 先纠正一个常见误解
很多人下意识认为 "分离 = 更高级的降噪",但这是不准确的。
降噪和分离不是高低级关系,而是 同一问题在不同约束下的解法。ANC 在毫秒级延迟、毫瓦级功耗的约束下做到了极致,这是 Source Separation 短期内无法替代的。反过来,Source Separation 提供的信号结构化能力,也是 ANC 架构根本不追求的。
选哪个,取决于工程约束和下游需求,而不是"谁更先进"。
4.2 "先分离"正在成为音频系统的标准范式
但如果你的目标不只是"让人听得舒服",而是需要对音频信号做进一步的处理和分析,那情况就不一样了:
- ASR 鲁棒性提升:嘈杂环境下的语音识别,先分离再识别的效果显著优于端到端降噪
- 多说话人分析:会议记录、庭审转写,必须先知道"谁在说"才能分别转写
- 可控音频生成:播客后期、影视混音,需要独立操作每一条音轨
这些场景下,显式分离几乎是不可绕开的前置步骤 。道理很简单:只有被建模的信号,才能被系统性利用。 AirPods 不需要理解声音的结构,但音频系统工程需要。
4.3 主流工具与模型
如果你想动手尝试 Source Separation,目前生态已经相当成熟:
| 工具 / 模型 | 特点 | 适用场景 |
|---|---|---|
| Demucs (Meta) | 基于深度学习,支持音乐多轨分离(人声、鼓、贝斯、其他) | 音乐制作、歌声提取 |
| Spleeter (Deezer) | 轻量快速,预训练模型开箱即用 | 快速原型、简单分离需求 |
| SepFormer | Transformer 架构,在标准基准上性能领先 | 学术研究、高精度场景 |
| Conv-TasNet | 时域卷积方案,延迟较低 | 准实时分离、嵌入式部署探索 |
其中 Demucs 和 Spleeter 对新手最友好,几行命令就能跑起来。SepFormer 和 Conv-TasNet 更适合有一定基础、需要深度定制的场景。
五、总结:同源不同路
5.1 记住这四点
- 同一个核心问题:ANC 和 Source Separation 共享同一个本质------在混合信号中定义并处理"非目标成分"
- 不同的工程路径:ANC 用硬件闭环换极致低延迟,走隐式路线;Source Separation 用模型换信号结构化,走显式路线
- 不是高低级关系:选择取决于场景约束,而非"谁更先进"
- 趋势是"先分离":当下游任务越来越复杂,显式分离正在成为音频处理的标准前置步骤
5.2 速查对比表
| ANC | Source Separation | |
|---|---|---|
| 一句话描述 | 让你听不到噪声 | 让系统"看到"每一路声音 |
| 核心操作 | 估计噪声 → 反相抵消 | 建模信号 → 分轨输出 |
| 硬件实现 | 前馈 + 内向式麦克风闭环 | 通用计算平台(GPU / CPU) |
| 输出 | 一路"安静"的音频 | 多路独立轨道 |
| 关键约束 | 延迟、硬件、功耗 | 精度、泛化性 |
| 典型产品 | AirPods、Sony WH 系列 | Demucs、Spleeter、会议转写系统 |
5.3 一个值得关注的方向
随着端侧算力的提升(如 Apple 的 Neural Engine),ANC 和 Source Separation 的边界正在模糊。
AirPods Pro 2 的"自适应通透模式"已经在做一件有意思的事:降噪的同时,选择性保留人声------比如旁边有人跟你说话时自动放进来。这已经不是简单的"抵消噪声"了,它需要在某种程度上"理解"声音的类别。
当硬件约束不再是瓶颈,隐式方案和显式方案最终会走向融合。 未来的降噪耳机,也许就是一个跑在耳朵旁边的实时声源分离引擎。
下次戴上降噪耳机的时候,也许你会多想一秒:此刻,一颗小小的 H2 芯片正在做一件和音频实验室里同样本质的事---在混合的世界中,找到你不想听的那部分,然后让它消失。