Python 学习第 16 天,从今天起正式开始将 Python 应用到数据分析的实战中<( ̄︶ ̄)↗GO!
|--------|-----------|------------|
| 功能 | Excel | Python |
| 数据处理量 | 1 万行以内 | 100 万行以上 |
| 自动化 | 手动操作 | 代码一件执行 |
上一篇我们简单介绍了数据的分类、统计指标、异常值识别与处理,以及小样本数据在 Excel 环境下可做的操作。Excel 的各种函数虽已大大减小了我们逐一计算、处理数据的工作量,但其仍有大量的手动工作、人工校验。对此,我们可以用 Python 去进一步减少这些重复性工作。
一、工具准备
1. Anaconda
Anaconda 是一个为数据科学、机器学习和 Python / R 编程打造的开源 "工具箱"。其预装了 Python / R 的解释器,也包含了几百个数据科学领域常用的数据库(如,Numpy、Pandas、Matplotlib、Scikit-learn等)。同时,其内置了强大的环境管理和包管理工具,让新手免于处理环境配置与包版本冲突问题,且能够跨平台使用。
浏览器搜索 Anaconda 进入其官网下载匹配自身电脑的版本即可(可以不注册 / 登录账号):Download Anaconda Distribution | Anaconda


注意:
(1) 安装包不能与应用程序存放到同一文件夹中;
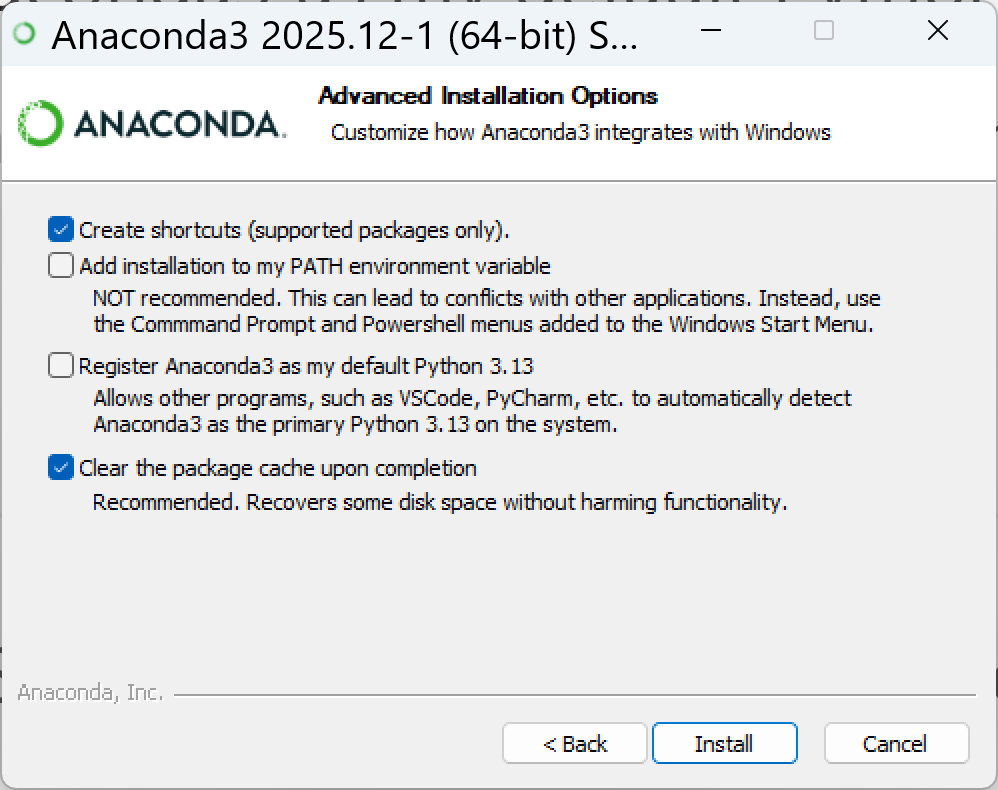
(2) 安装时建议勾选项如下:
2. Jupyter Notebook
Jupyter Notebook 是一个网页版交互式编程、写作、演示工具。其可以运行 Python、R、Julia 等计算机语言。它可以一步一步地执行每一个代码块 cell,在 cell 之外可以用文字去记录 / 描述所展示的内容和操作,方便我们在数据分析中查看每一步的结果。同时,它也支持以 PDF、HTML、Markdown、slides 格式导出分享,在 Anaconda 中自带,打开即用,不用另行匹配操作环境。


notebook 文件后缀一般为 .ipynb。
在 cell 内或 cell 外的空白处点击快捷键,能够快速对 notebook 进行操作:
|------------|------------------------------------------|
| 快捷键 | 效果 |
| esc | 从 "输入" 模式中退出,到 "命令" 模式 |
| a | 在 cell 上方增加一个 cell |
| b | 在 cell 下方增加一个 cell |
| dd | 删除当前 cell |
| m | 切换到 markdown 模式(出现的窗格用于记录文字,不会当作代码执行) |
| y | 切换到 code 模式(出现的窗格是代码块 cell,内部内容要被当作代码执行) |
| ctril + 回车 | 运行当前 cell |
| shift + 回车 | 运行当前 cell,并创建一个新的 cell |
3. PyCharm
Python 的一个编译器,其内涵智能代码提示、检查和专业调试,也适配 Anaconda、虚拟环境,不仅对新手友好,也是专业 Python 开发工具。如果已经在 PyCharm 官网下载、安装了 PyCharm,其 "文件 - 新建" 中可创建 Jupyter Notebook 文件,这样既可把控每段代码的执行,也可以享受 PyCharm 的智能辅助。
而在 Anaconda 中也可以下载、打开 PyCharm,再用其创建 Jupyter Notebook。

二、常用库
1. Numpy
用于数据的基础数值计算。核心是 ndarry,即 "多维数组",适用于处理多维数据、一维苦列表、二维表格、三维立体数据等。内置多种计算方式,也是 Pandas、Scikit - learn 的创建基础。
通过 import 引用,通过 变量名.函数名() 调用内置函数,代码示例:
import numpy as np
# 创建一维数组
arr = np.array([1, 2, 3, 4])
# 向量化运算
print(arr * 2) # 输出:[2 4 6 8]
# 求均值
print(np.mean(arr))运行结果:
[2 4 6 8]
2.52. Pandas
用于数据的分类、清洗、分析。核心是 DataFrame(表格)和 Series(单列),专门处理 .xls、.xlsx、.cvs 文件。常用于表格化操作(筛选、排序、去重、填充)、缺失值处理(fillna()、dropna())、数据聚合分组、时间序列处理等。
通过 import 引用,通过 变量名.函数名() 调用内置函数,代码示例:
import pandas as pd
# 创建表格
df = pd.DataFrame({
"姓名": ["张三", "李四", "王五"],
"年龄": [20, 25, 30],
"薪资": [5000, 8000, 10000]
})
# 筛选年龄 > 25的行
print(df[df["年龄"] > 25])
# 计算薪资均值
print(df["薪资"].mean())运行结果:
姓名 年龄 薪资
2 王五 30 10000
7666.6666666666673. Matplotlib
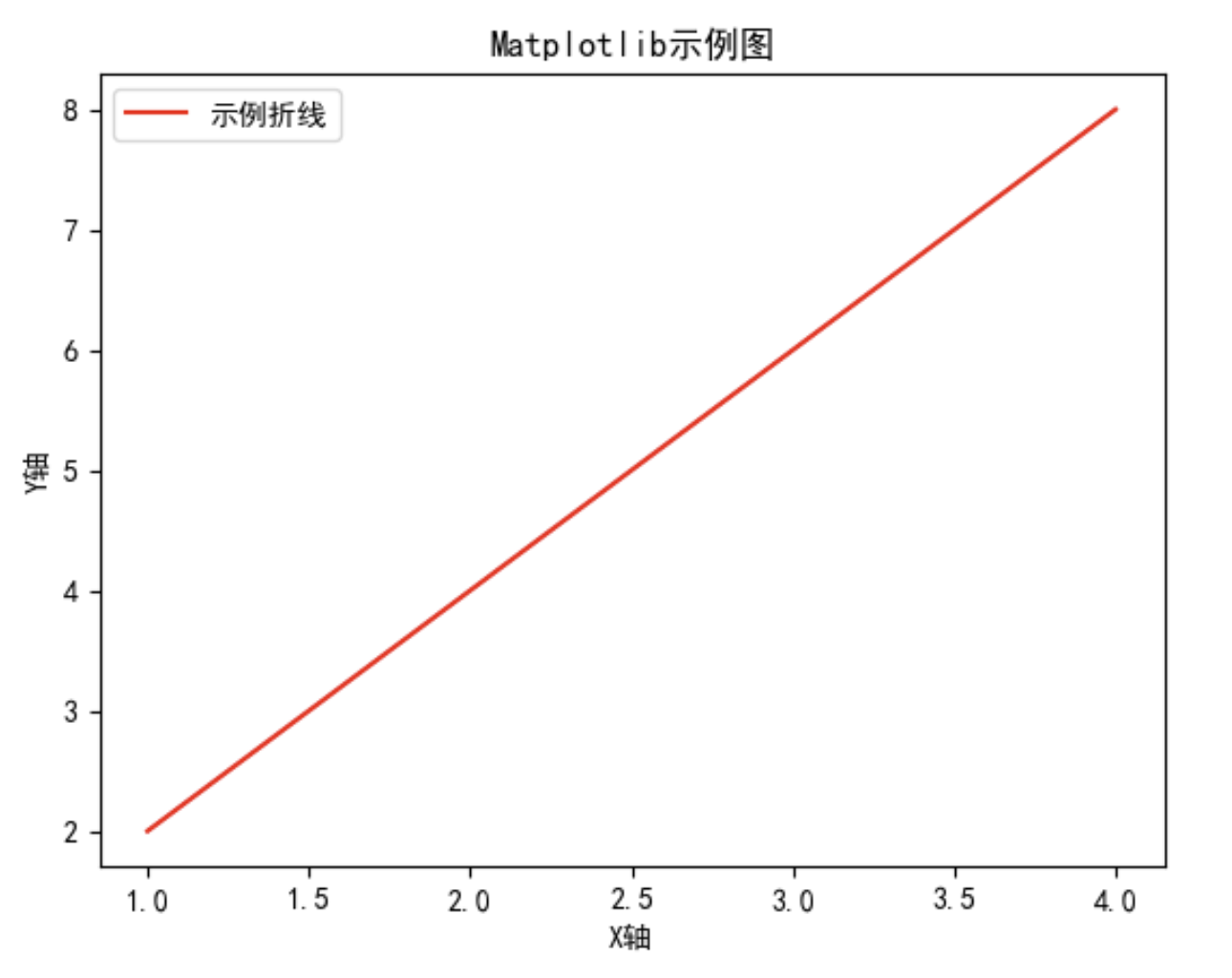
用于数据的美化、展示,即 "生成图表" "可视化"。可用于绘制折线图(plot)、柱状图(bar)、散点图(scatter)、直方图(hist)、饼图(pie)等,也可以控制其颜色、字体、坐标轴、标题、图例等细节,可在 Jupyter Notebook 中直接显示图表,也能导出为图片 / PDF。它也是更多数据可视化库的基础。
通过 import 引用,通过 变量名.函数名() 调用内置函数,代码示例:
import matplotlib.pyplot as plt
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
x = np.array([1, 2, 3, 4])
y = np.array([2, 4, 6, 8])
# 画折线图
plt.plot(x, y, color="red", label="示例折线")
plt.xlabel("X轴") # X轴标签
plt.ylabel("Y轴") # Y轴标签
plt.title("Matplotlib示例图") # 标题
plt.legend() # 显示图例
plt.show() # 显示图表运行结果:
4. Seaborn
基于 Matplotlib 创建的更美观的可视化库。