一、机器学习算法分类
机器学习的核心在于算法 ,而根据数据集是否有标签 ,我们可以将机器学习算法分为四大类 。掌握这些分类,就像拥有了机器学习的地图,能让我们在面对不同问题时快速判断方向,而不是盲目选择模型。
机器学习本质上解决的是从数据中学习规律的问题,不同的数据形态决定了我们该用哪种学习方式。
1. 有监督学习
有监督学习是最常见、应用最成熟的一类算法,也是工业界落地最多的一种形式。
定义 :输入数据由特征值 和目标值 组成。简单来说,训练数据是带标签的,也就是每条数据都有标准答案。
换句话说,我们是在学习一个从输入 到输出的映射关系。
类比 :就像学生在老师的指导下学习。老师提供题目(特征 )和标准答案(标签 ),学生通过不断练习,学会看到题目就能写出正确答案。这种有答案参考的学习方式,就是有监督学习。 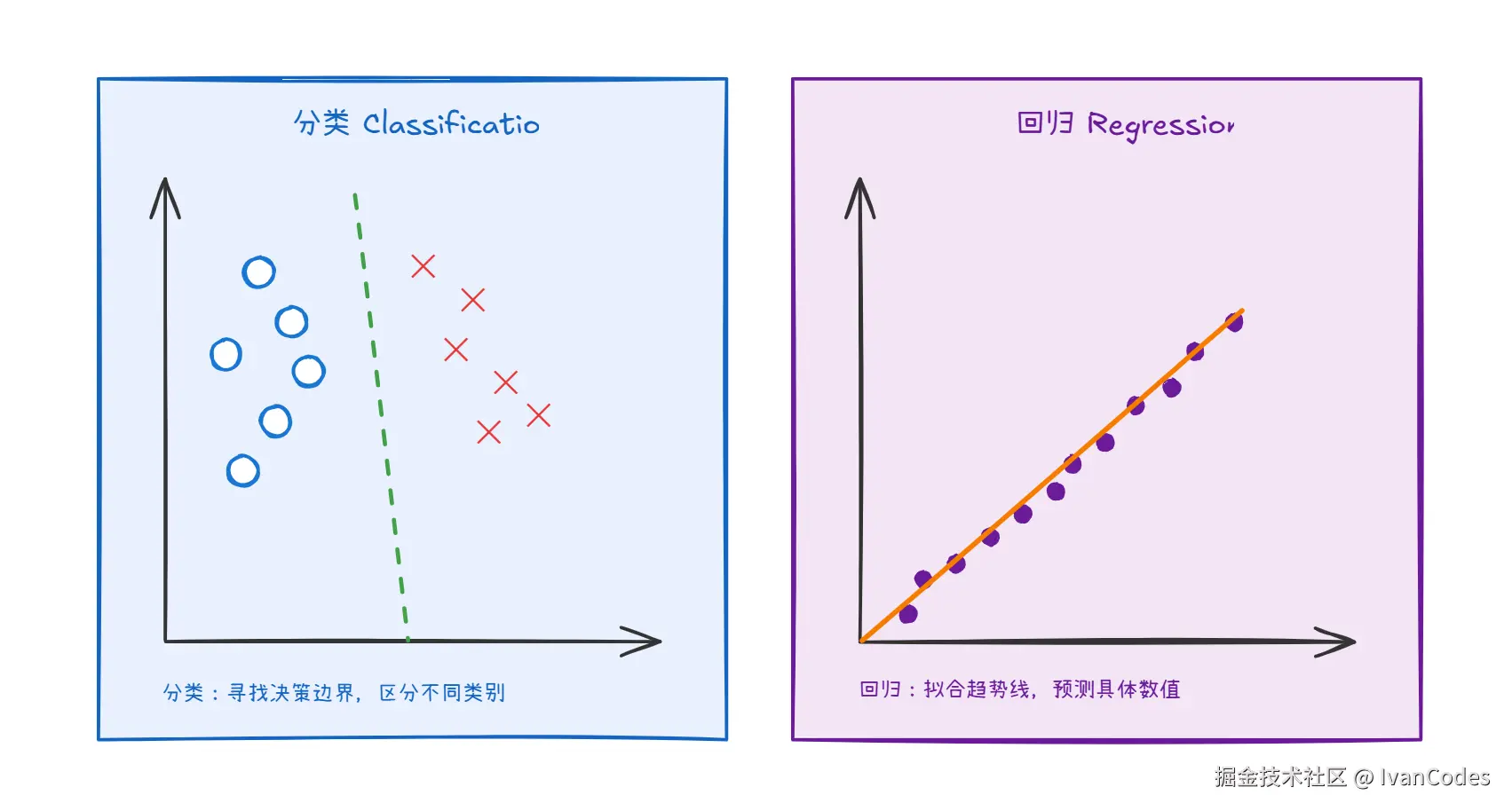 核心任务:
核心任务:
分类 :目标值是离散的(不连续)。例如:垃圾邮件检测(是/否)、图像识别(猫/狗/车)。本质是将样本划分到不同类别。
回归 :目标值是连续数值。例如:预测明天的气温、预测房价。本质是预测一个具体数值。
分类预测类别,回归预测数值。
2. 无监督学习
定义:输入数据没有标签 。机器只拿到一堆数据,不知道它们代表什么,需要自己去发现数据内部的结构 和规律。
类比:就像给小孩一堆积木,不告诉他怎么分类,他可能会根据颜色 或形状 ,自发地分成几堆。这种主动归纳,就是无监督学习的核心。 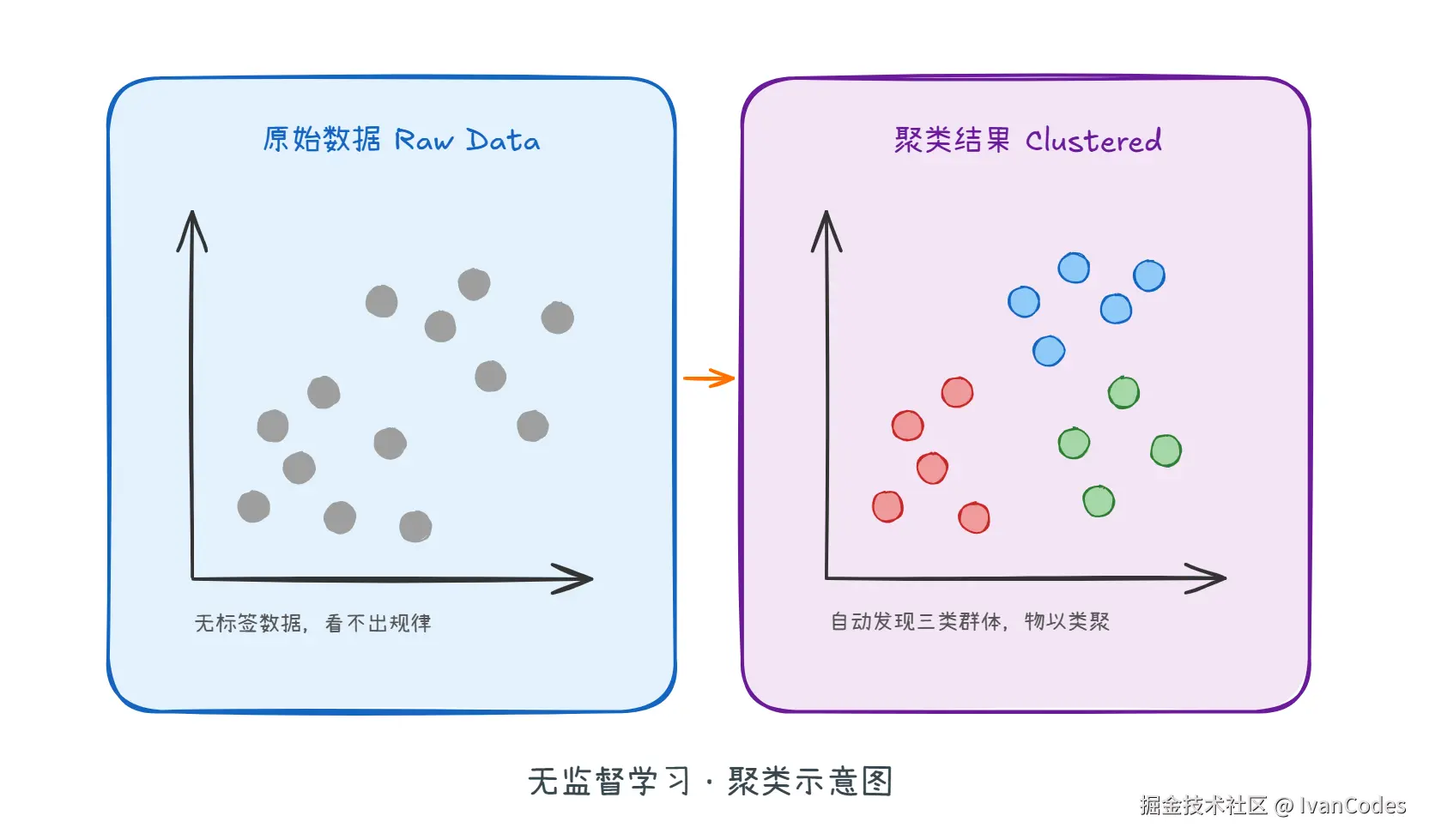 核心任务:
核心任务:
聚类 :根据样本间的相似性,将样本划分为不同组。常见应用包括客户细分 、异常检测。
降维 :在保留主要信息的情况下减少特征数量,用于数据压缩或可视化分析。
一句话理解:无监督学习的核心是发现隐藏结构。
3. 半监督学习
背景:现实中数据很多 ,但人工标注成本很高。特别是在医学、语音识别等领域,标注往往需要专业人员参与。
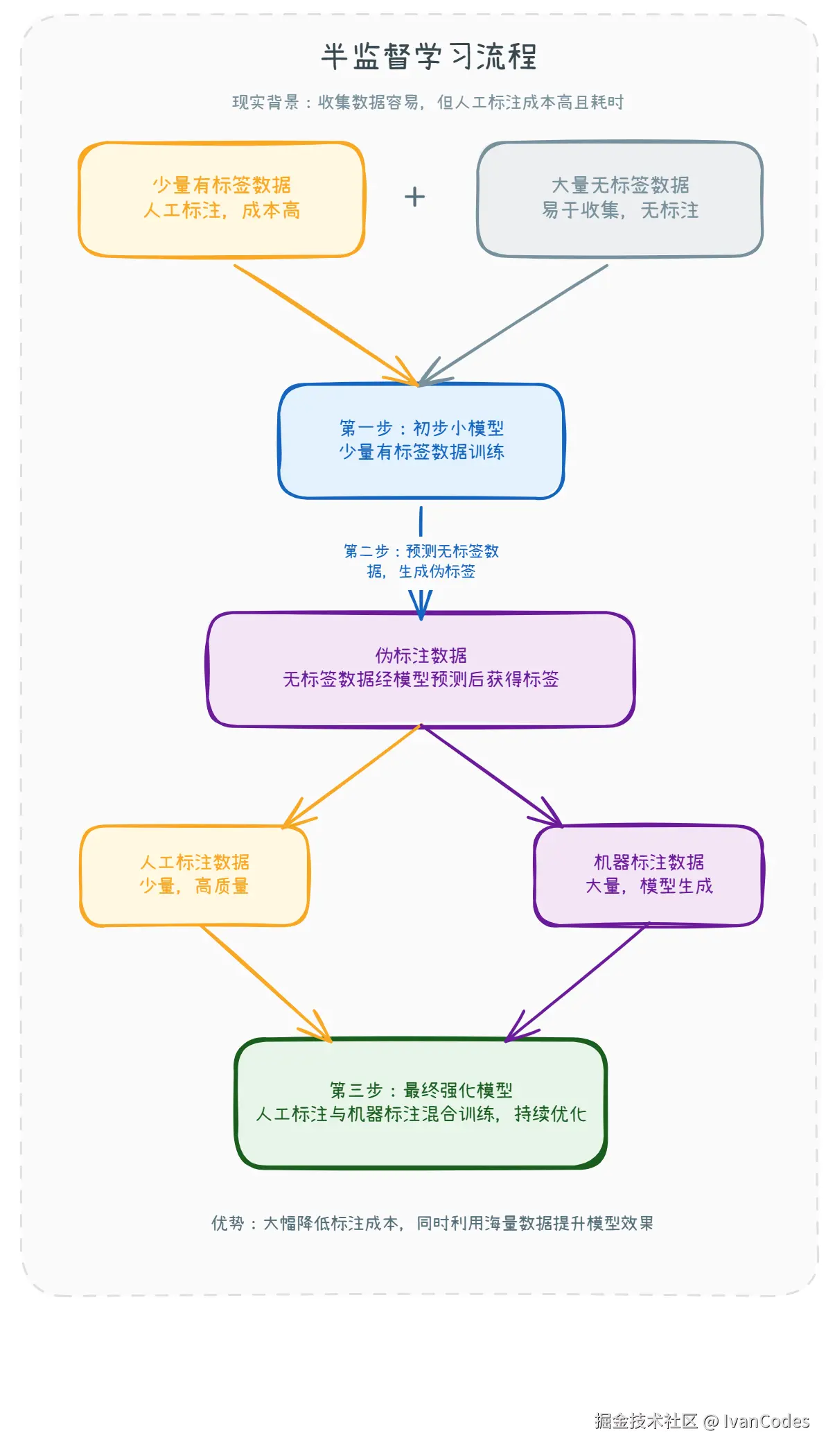
定义:利用少量有标签数据 和大量无标签数据进行训练。
它的核心思想是:用少量人工知识带动大量数据学习。
工作流程:
- 先用少量有标签数据训练一个初始模型。
- 用模型预测无标签数据,生成伪标签。
- 将真实标签与伪标签数据结合,再次训练模型,不断优化。
优势:降低标注成本,同时充分利用海量数据。
4. 强化学习
定义:一个智能体 在环境 中不断尝试,根据获得的奖励 或惩罚 调整行为策略,目标是最大化累积奖励。
强化学习强调试错机制 和长期收益。
核心四要素:
智能体 :做出决策的主体,如 AlphaGo、机器人 环境 :交互场景,如 围棋棋盘、迷宫 行动 :执行的动作,如 落子、移动 奖励 :环境反馈,如 +1 分 或 -1 分 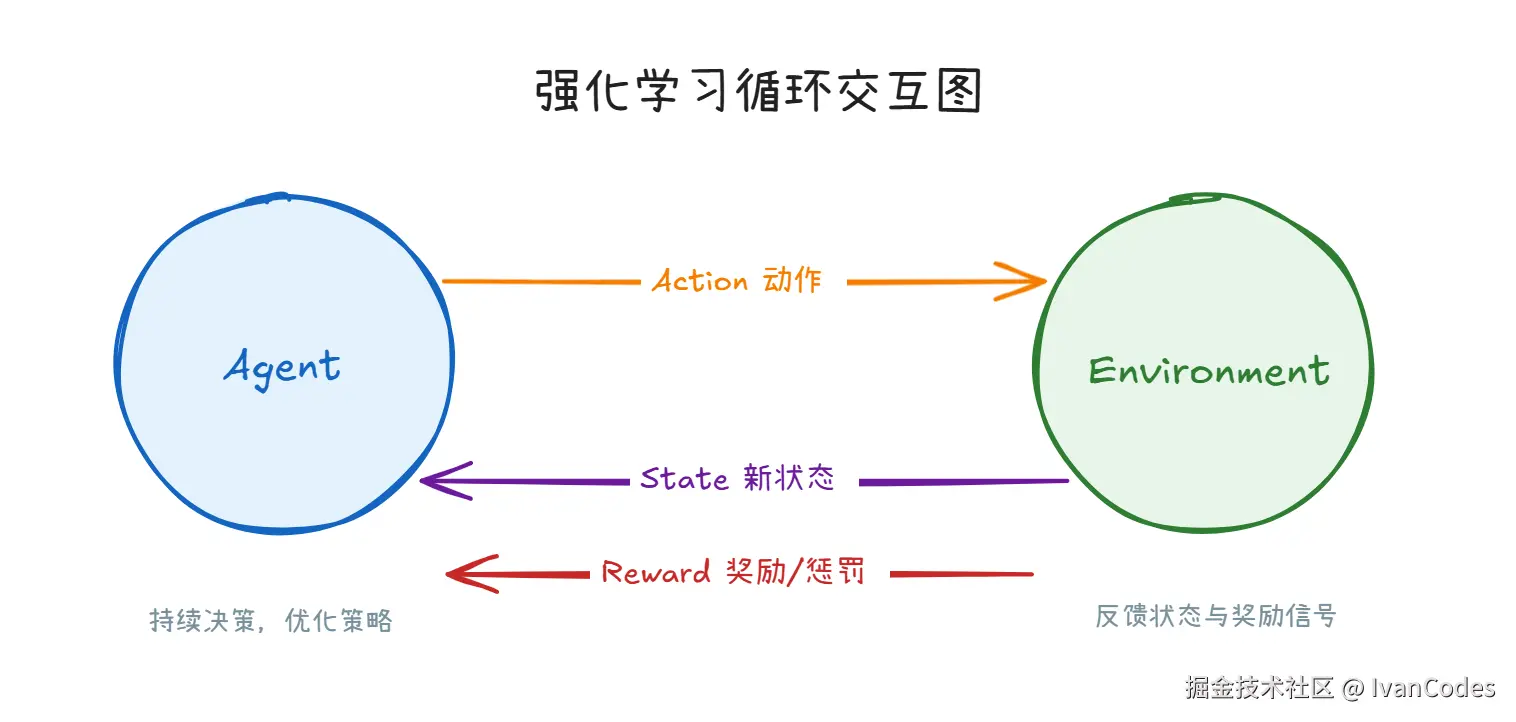 案例 :小孩学走路、训练小狗、本质上都是通过奖励反馈调整行为。
案例 :小孩学走路、训练小狗、本质上都是通过奖励反馈调整行为。
5. 算法分类总结
| 学习方式 | 关键特征 | 核心任务 | 典型案例 |
|---|---|---|---|
| 有监督学习 | 有标签 (输入+结果) | 分类、回归 | 房价预测、人脸识别 |
| 无监督学习 | 无标签 (只有输入) | 聚类、降维 | 客户分群、数据压缩 |
| 半监督学习 | 少量标签 + 大量无标签 | 分类、回归 | 网页分类、医学影像分析 |
| 强化学习 | 动态交互、奖励机制 | 决策控制 | 自动驾驶、游戏AI |
二、机器学习建模流程
做一个机器学习项目,就像做一道菜,需要有清晰步骤,否则很容易"翻车"。
标准流程七步走:
1.获取数据 :没有数据就没有模型,数据是基础。 2. 数据基本处理:清洗脏数据,处理缺失值和异常值。
- 特征工程 :把数据转换为模型可理解的形式,这是最关键的一步。
- 模型训练:选择算法,让模型学习数据规律。
- 模型评估:使用测试集打分,判断模型效果。
- 结果预测:上线部署,对新数据进行预测。
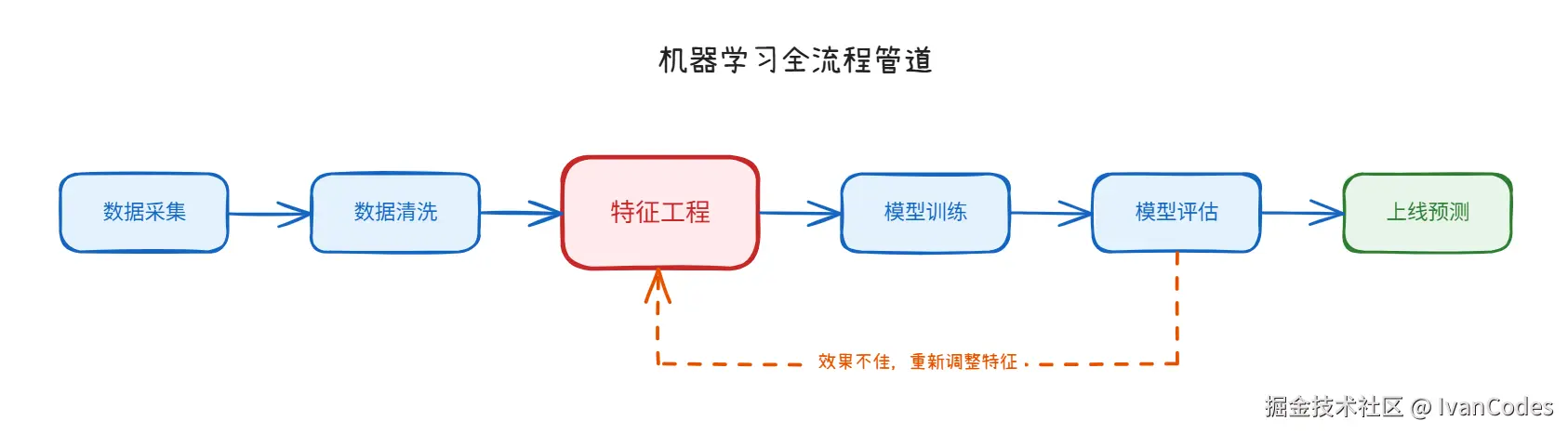
核心主线可以理解为:数据 → 特征 → 模型 → 评估 → 应用
三、特征工程
行业里有一句非常经典的话:
"数据和特征决定上限,模型只是逼近上限。"
很多时候模型效果不好,不是算法不够复杂,而是特征不够好。
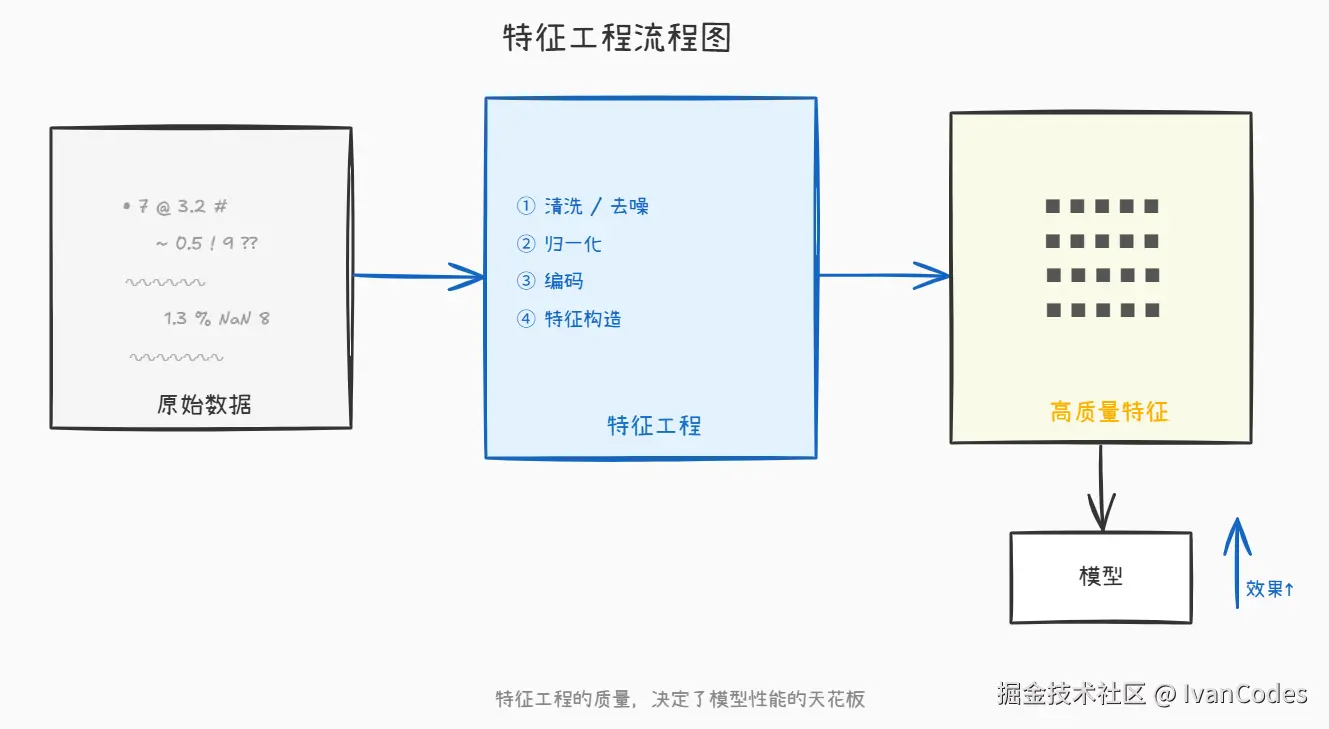
1. 什么是特征工程?
特征工程是利用专业知识对数据进行加工处理,将原始数据转换为更有表达力的特征。
简单理解就是:把原材料加工成更容易被模型理解的形式。
好的特征往往比复杂模型更重要。
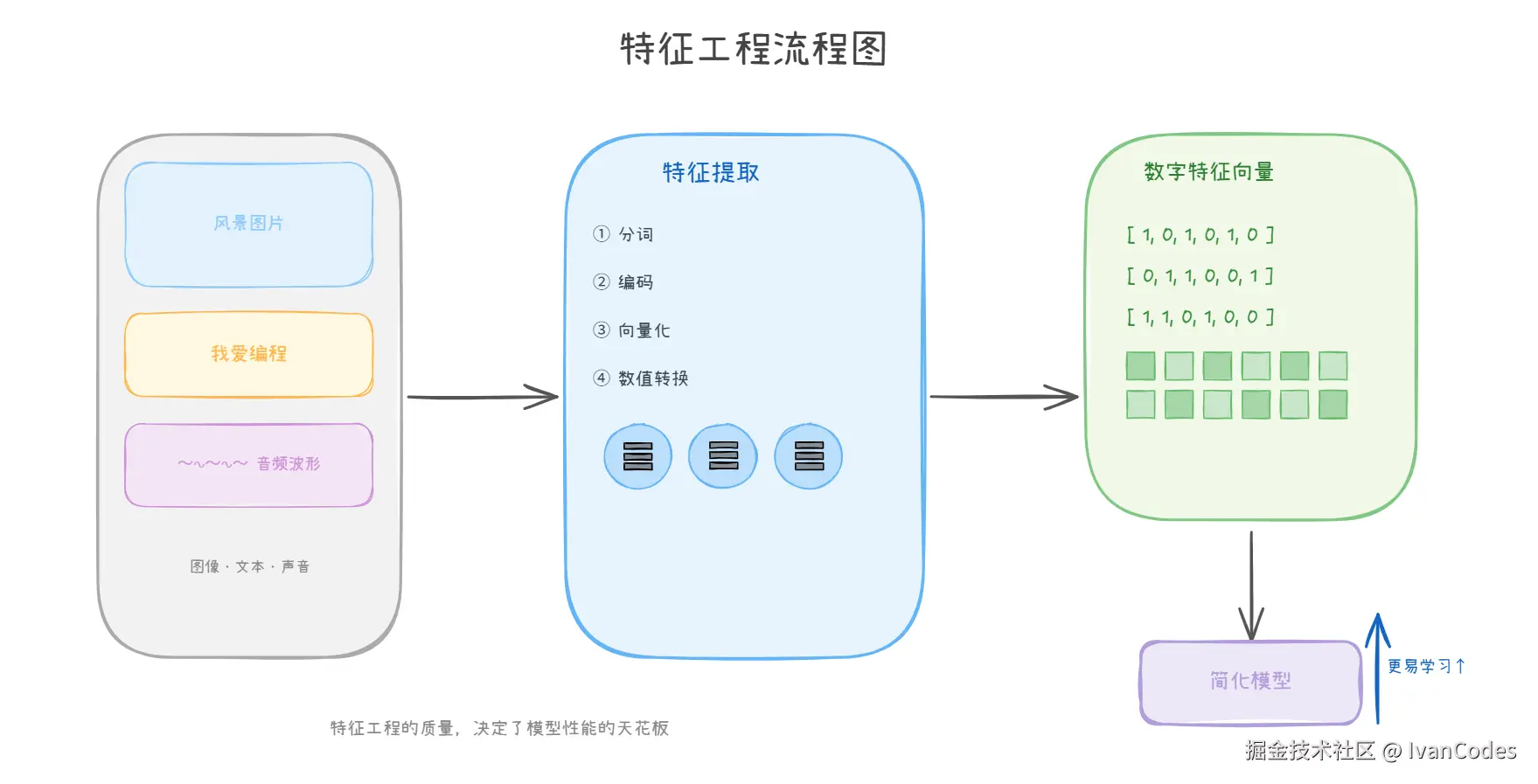
2. 特征提取
机器只认识数字,不认识图片、文本或声音。
定义 :将原始数据转换为数值特征。
例如 :文本转向量,图片转像素矩阵。本质是一切数据都要数值化。
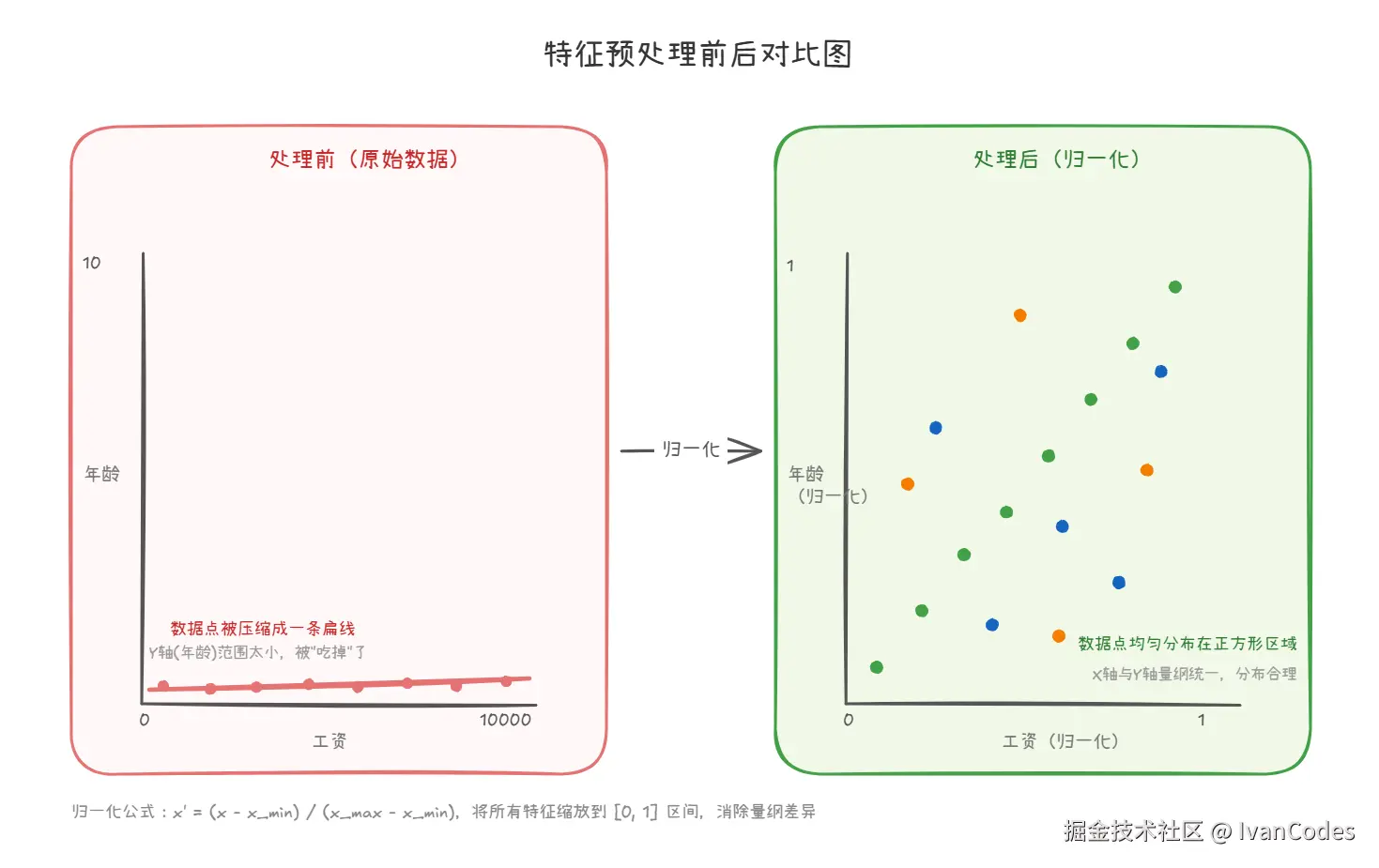
3. 特征预处理
痛点:量纲不统一。
解决方法:通过归一化 或标准化将特征缩放到统一范围。
作用:让不同特征影响力更公平 ,加快模型收敛速度 ,提高训练稳定性
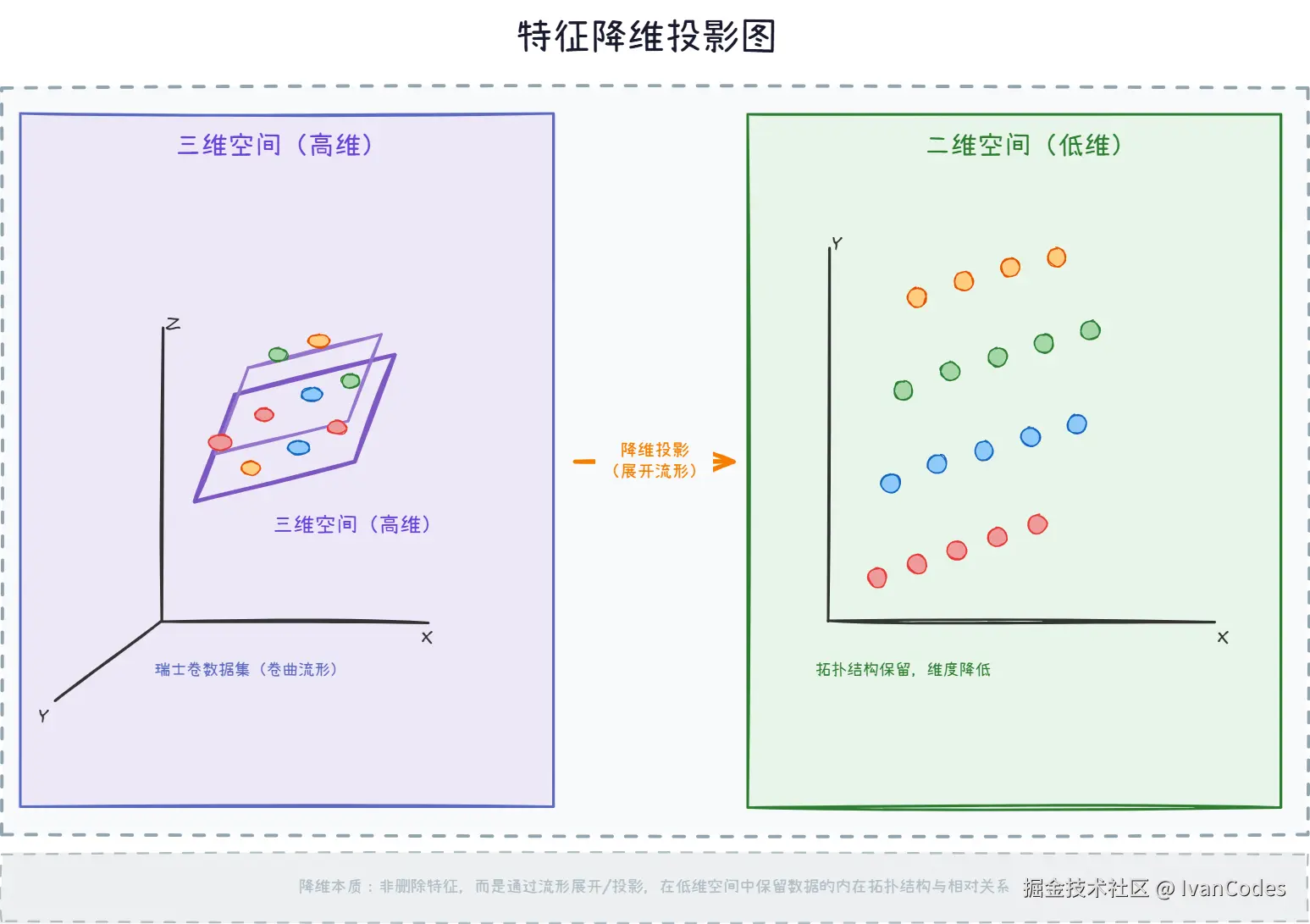
4. 特征降维
定义 :在保留主要信息前提下减少特征维度。
原因 :特征过多会增加计算成本 ,可能引入噪声 ,容易造成过拟合
效果:数据更精简,训练更高效。
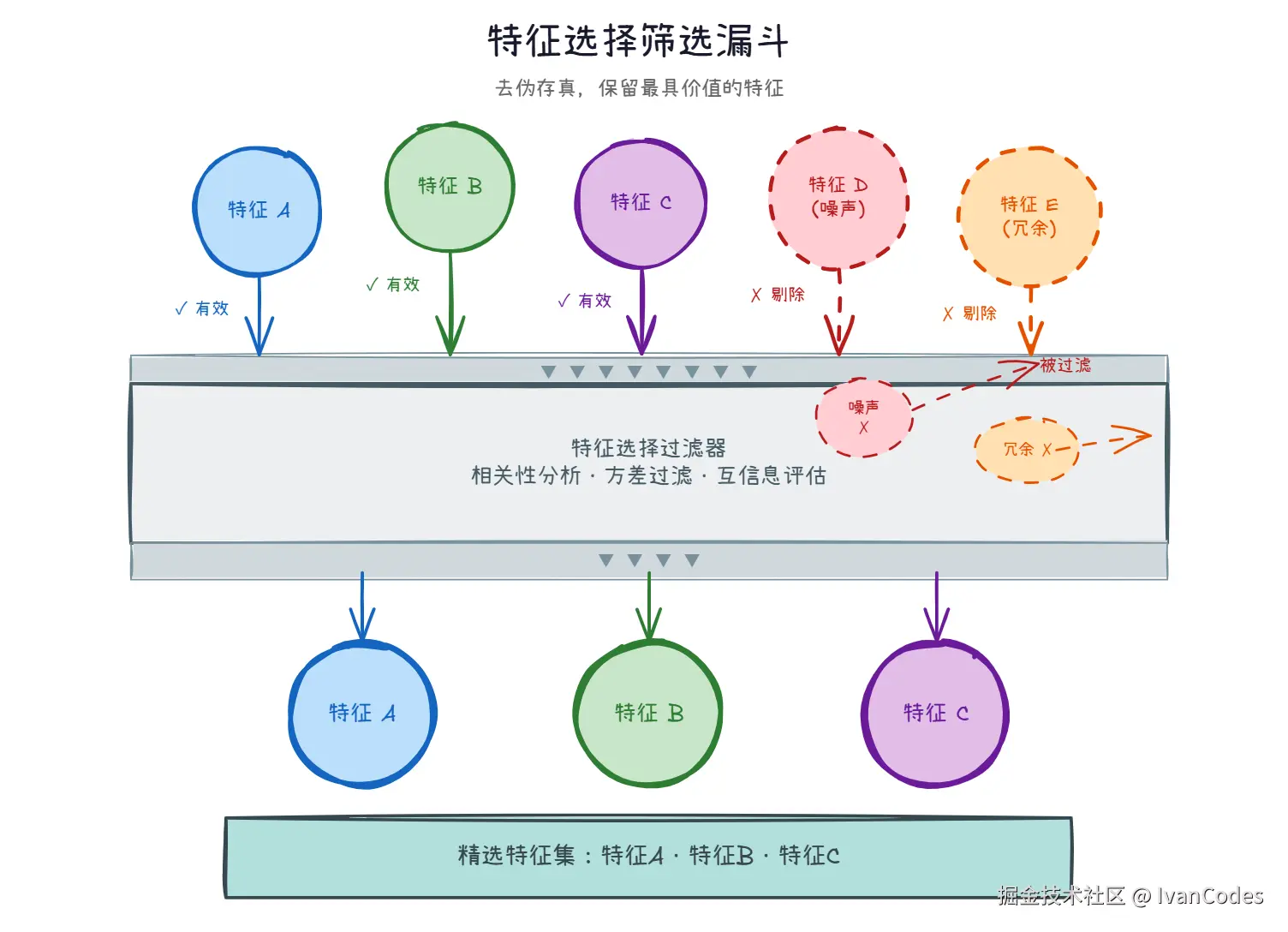
5. 特征选择
定义:筛选出最有价值的特征,删除无用或冗余特征。
区别:
降维 会生成新特征 特征选择不改变原始特征
核心目标:保留有效信息,剔除干扰因素。
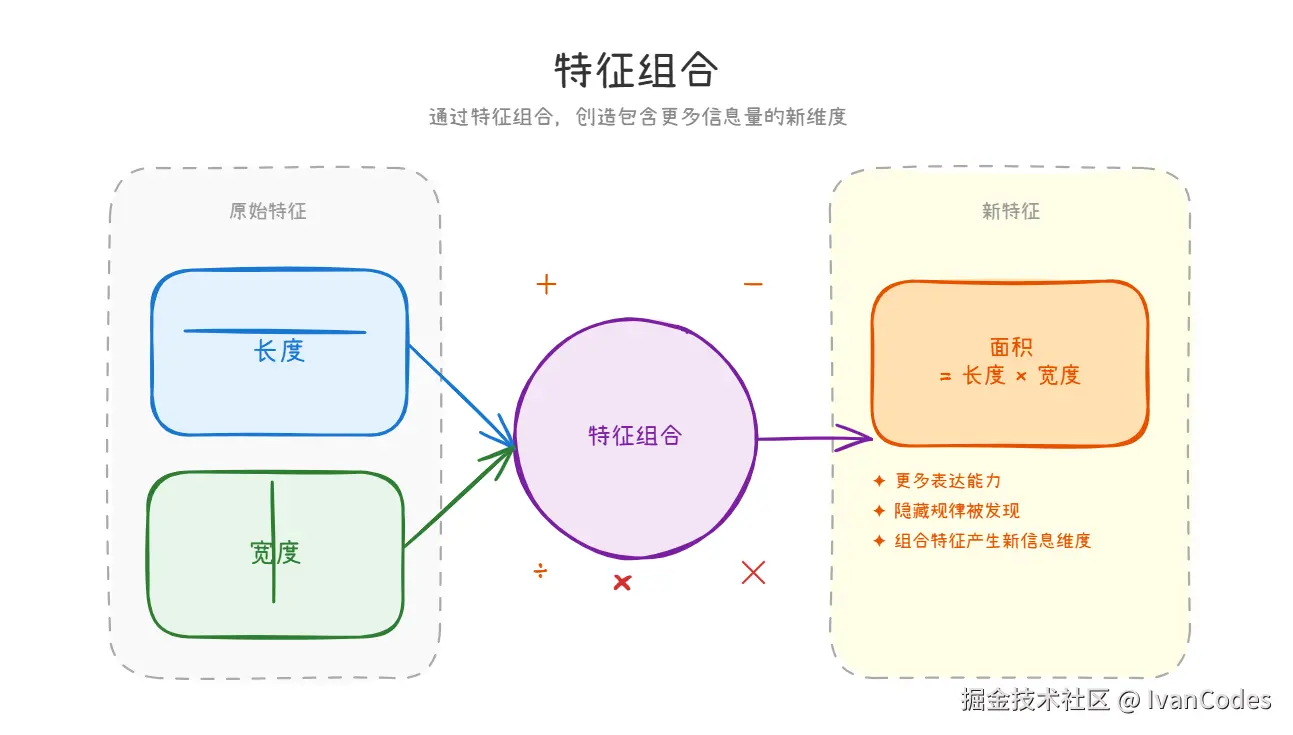
6. 特征组合
定义:通过加减乘除等运算构造新特征。
bash
案例:面积 = 长度 × 宽度很多时候,组合特征比原始特征更有表达力。