目录
- 第一阶段:准备环境与硬件
-
- [1.1 什么是vLLM](#1.1 什么是vLLM)
- [1.2 硬件要求](#1.2 硬件要求)
- [1.3 驱动要求](#1.3 驱动要求)
- [第二阶段:conda 环境 + vLLM](#第二阶段:conda 环境 + vLLM)
-
- [2.1 安装conda](#2.1 安装conda)
- [2.2 创建独立的 conda 环境](#2.2 创建独立的 conda 环境)
- [2.3 再次查看 NVIDIA 环境](#2.3 再次查看 NVIDIA 环境)
- [2.4 使用 Pip 安装 vLLM](#2.4 使用 Pip 安装 vLLM)
- [2.5 验证安装](#2.5 验证安装)
- [第三阶段:vLLM 使用](#第三阶段:vLLM 使用)
-
- [3.1 下载模型](#3.1 下载模型)
- [3.2 vLLM加载模型](#3.2 vLLM加载模型)
- [3.3 接口调用](#3.3 接口调用)
- [3.4 Lora适配器](#3.4 Lora适配器)
第一阶段:准备环境与硬件
1.1 什么是vLLM
vLLM 是一个开源的、高性能的大语言模型推理与服务框架,吞吐量可达传统方案的8-20倍。
1.2 硬件要求
-
GPU:
NVIDIA显卡(推荐 RTX 3090/4060/4090 或 A100/H100) -
显存:起码
8GB -
系统:建议使用
Ubuntu 22.04 / 24.04(本文以 24.04 为例)
1.3 驱动要求
-
驱动:确保你的驱动版本
nvidia-smi显示的CUDA Version不低于12.4 -
CUDA环境:确保下载的CUDA版本是小于等于nvidia-smi显示的CUDA Version -
驱动以及
CUDA环境安装网上资料很多,这里不再赘述
bash
# 查看英伟达显卡驱动
nvidia-smi
# 查看安装的CUDA版本
nvcc-V第二阶段:conda 环境 + vLLM
2.1 安装conda
如果还没有 Conda,推荐安装轻量级的 Miniconda,核心优势是可以为不同项目隔离依赖,甚至支持不同的 Python 版本
bash
# 下载 Miniconda 安装脚本
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
# 执行安装
bash Miniconda3-latest-Linux-x86_64.sh
# 按照提示完成安装,记得选 "yes" 初始化 conda init
# 重新加载 shell 配置
source ~/.bashrc2.2 创建独立的 conda 环境
建议下载3.11 或者 3.12的python环境
bash
# 创建名为 qwenEnv 的环境,指定 Python 3.11(vLLM 要求 3.11-3.13)
conda create -n qwenEnv python=3.11 -y
# 激活环境
conda activate qwenEnv
# 确认 Python 版本
python --version # 应显示 Python 3.11.x2.3 再次查看 NVIDIA 环境
请在conda 的环境中,再次确认 nvidia-smi 和 nvcc-V 可以正常输出,并且与原本主机中的输出一致。
如果不能输出,或者显示找不到命令,则可能需要在conda 的环境中再次安装一遍cuda的 工具包(可参考其余资料)
2.4 使用 Pip 安装 vLLM
vLLM 官方推荐通过 pip 安装,安装时间可能比较长,和网络环境相关
vLLm安装也会自动下载PyTorch,主要是和python以及CUDA版本相关
bash
# 确保在 conda activate qwenEnv 状态下
# 升级 pip
pip install --upgrade pip
# 配置国内源(中国大陆用户推荐,加速下载)
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
# 安装 vLLM,conda 环境会自动识别到正确的 CUDA 路径
pip install vllm2.5 验证安装
安装后先验证 PyTorch和CUDA,其中torch.cuda.is_available()需要显示为true
bash
# 确保在 conda activate qwenEnv 状态下
# 检查 PyTorch 和 CUDA
python -c "import torch; print(f'PyTorch: {torch.__version__}'); print(f'CUDA: {torch.cuda.is_available()}'); "再验证vLLM,正常输出版本即可
bash
# 确保在 conda activate qwenEnv 状态下
python -c "import vllm; print(f'vLLM: {vllm.__version__}')"第三阶段:vLLM 使用
3.1 下载模型
国内用户建议登录魔塔社区下载模型:https://www.modelscope.cn/home
使用官方的流程下载大模型,因模型比较大,所以下载时间会比较长
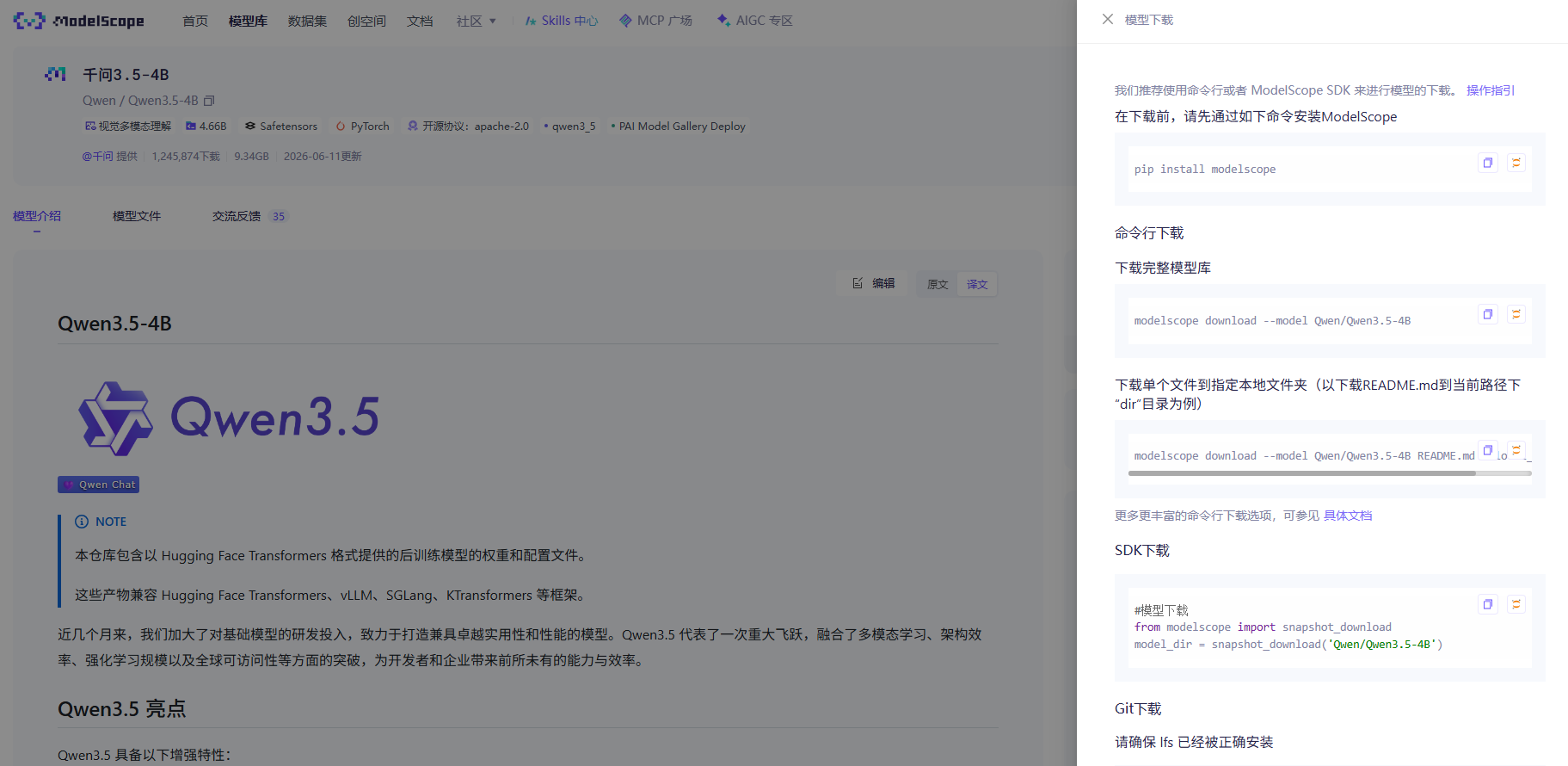
将下载完毕的模型导入到conda虚拟环境中,我这里下载的是qwen3.5-4B模型
3.2 vLLM加载模型
假设我将下载好的模型放置在/work/ai/model位置,以下是最基础的vLLM加载模型命令
详细的vLLM命令可以参考官方文档:https://docs.vllm.com.cn/en/latest/index.html
bash
vllm serve /work/ai/model
--trust-remote-code
--host 0.0.0.0 --port 8899
--tensor-parallel-size 1
--quantization bitsandbytes
--gpu-memory-utilization 0.8
--max-model-len 4096
--max-num-seqs 16参数含义如下:
trust-remote-code: 强制相信第三方下载模型--host 0.0.0.0 --port 8899:允许所有ip地址访问,访问的本地端口是8899tensor-parallel-size 1:并行显卡数量,单笔记本,所以就是1quantization bitsandbytes:开启4bit量化,降低现存占用gpu-memory-utilization 0.8:允许使用的现存上限,表示最多只能用电脑80%显存max-model-len 4096:支持的最大上下文长度max-num-seqs 16:支持的最大并发请求数量
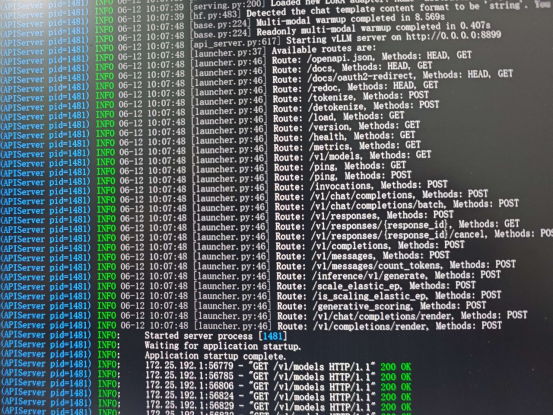
第一次启动模型可能需要加载参数,需要个几分钟
当出现Application startup complete时,即表示启动成功
3.3 接口调用
如上图所示,vLLM包含众多接口,其中最核心的接口即为对话接口/v1/chat/completions
我们可以通过http://服务IP地址:服务端口/v1/chat/completions来发送对话请求,示例如下
bash
curl http://127.0.0.1:8899/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model":"/work/ai/model",
"message":[{"role":"user","content":"你好,介绍一下自己"}],
"temperature":0.7,
"max_tokens":512
}'此时模型会正常的回答,但是由于开启了思考模式,所以回复时间很长,一个问题可能需要几分钟,此时我们可以再添加一个参数,用于关闭思考模式,此时回答速度会快很多
bash
curl http://127.0.0.1:8899/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model":"/work/ai/model",
"message":[{"role":"user","content":"你好,介绍一下自己"}],
"temperature":0.7,
"max_tokens":512,
"chat_template_kwargs":{"enable_thinking":false}
}'参数含义如下:
model表示加载的模型地址,如果使用基底模型,则model位置直接写模型的绝对路径即可message为发送的消息,system表示系统提示词,user表示用户提问内容temperature在0-1之间,数值越小回答越稳定,趋向于训练的结果;值越大则回答内容越发散max_tokens表示单词模型输出的最大内容上限"enable_thinking":false表示关闭思考模式
添加了系统提示词以及关闭思考模式的完整请求如下
bash
curl http://127.0.0.1:8899/v1/chat/completions
-H "Content-Type: application/json"
-d '{
"model":"/work/ai/model",
"message":[
{"role":"system","content":"你是一个文档整理专家,将以下内容整理为规范的文字信息,保留原意、口语转书面语,使用标准文本格式。"},
{"role":"user","content":"嗯...我好像没有听见有人叫我,但是我还是回头看了一眼,啥都没有。"}],
"temperature":0.7,
"max_tokens":512,
"chat_template_kwargs":{"enable_thinking":false}
}'当然,利用工具,例如postman发送请求也是可以的
3.4 Lora适配器
模型通过Lora训练后可输出参数文件夹。一般来说,加载的基地模型是不会改变的,而且通过加载不同的Lora参数文件夹来实现不同的功能。具体的模型训练可以参考我的这篇文章:不写一行代码,在 Linux 上微调大模型?LLaMA-Factory 真·保姆级教程
倘若此时我已经训练出三种Lora模型参数,分别对应医生、情感专家和论文专家
则当前加载模型的命令就变成了如下所示
bash
vllm serve /work/ai/model
--enable-lora
--lora_modules
doctorLora=/work/ai/LLaMA-Factory/saves/Qwen3.5-4B-Base/lora/doctorLora
emotionLora=/work/ai/LLaMA-Factory/saves/Qwen3.5-4B-Base/lora/emotionLora
thesisLora=/work/ai/LLaMA-Factory/saves/Qwen3.5-4B-Base/lora/thesisLora
--trust-remote-code
--host 0.0.0.0 --port 8899
--tensor-parallel-size 1
--quantization bitsandbytes
--gpu-memory-utilization 0.8
--max-model-len 6144 --max-num-seqs 4参数含义:
enable-lora表示允许加载lora适配器lora_modules表示具体的适配器,利用键值对来加载(key=value),不同的键值对利用空格分隔即可
接口访问参数也发生了一部分变化,具体来说model位置由基底模型的绝对路径改成lora适配器的名称(key)即可
bash
{
"model":"emotionLora",
"messages":[
{"role":"system","content":"你是一个情感专家,请温柔的回答我的问题。"},
{"role":"user","content":"我感觉很寂寞。"}],
"temperature":0.1,
"max_tokens":3000,
"chat_template_kwargs":{"enable_thinking":false}
}