O、猎奇的文档
这里,我使用AI创建了一版大概大约2700字的《不正经有限公司 正经管理办法》,里面全是稀奇古怪的公司条例,用来后续验证我们的RAG是否生效。
- 这很好理解吧?如果你提问,回答的是这些稀奇古怪的内容,而不是常规内容,那说明你的私人知识库生效了。

你可以在这里获取到它的全文:
一、为什么需要文档切片
前面章节梳理思路时,我们提到了一下两个点:
- 【句向量】的优势是检索,它可以方便通过一个问题或者关键词,找到若干个意思邻近的句子。
- 这些句子最终还是要封装到提示词里,传递给【词向量】LLM模型进行对话。
基于以上思路,我们可以确定一个点:
- 【句向量】的句不适合太长,太长的话相当于每次和【词向量】LLM对话时都要写代大量文档,对Token和准确性都有较大伤害。
- 【句向量】的句子也不能太短,太短的话,含义表达不清楚,就容易断章取义,定位到的句子意义不明。
你不能直接把一整本书塞给向量模型。文本太长。也不能一个字一个字的喂,截断的语句会丢失信息。
所以,目前主流的思路是:
在把句子转换成句向量之前,先要通过切片工具进行有效切片,保证以下效果:
- 每个【句向量】的句不要太长。
- 每个【句向量】的句,尽量是成块的,含义明确的。
这里,我使用AI创建了一版大概大约2700字的《不正经有限公司 正经管理办法》,里面全是稀奇古怪的公司条例,用来后续验证我们的RAG是否生效。
在正式写代码之前,我们先到这个网站去做一番视觉上的尝试,以便寻找到更适合我们的切分方式: www.chunkviz.com/
二、了解切分的基本概念
打开网站 chunkviz.com 之后,我们会看到这样的操作界面:
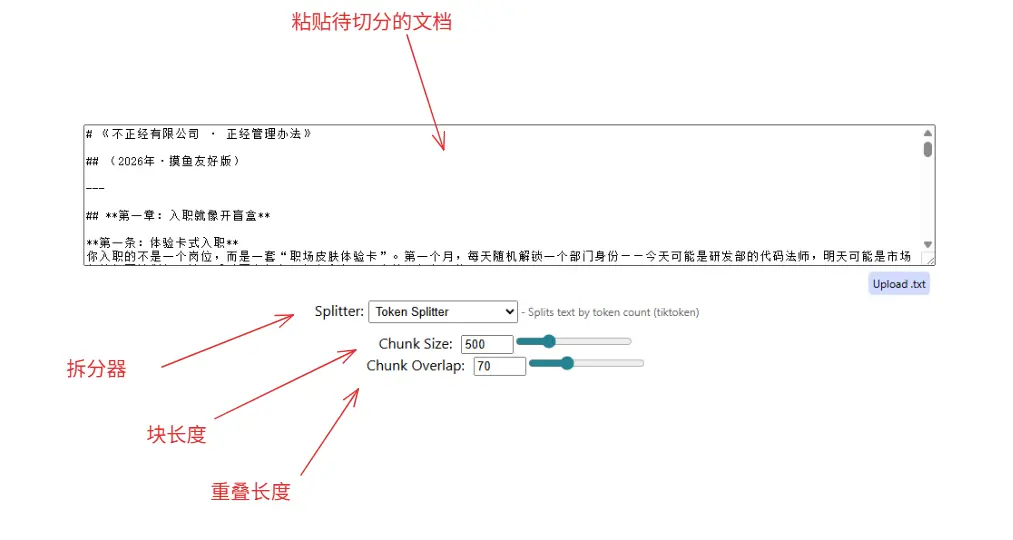
这里引入了四个概念:
- text: 待你切分的文档文本。
- Splitter: 切分器,针对各种文本提炼出的强力切割工具。有针对角色切分的,有针对编程语言切分的...等。
- ChunkSize: 块长度。每个【句向量】句子的期望字符串长度。
- ChunkOverlap:块间重叠长度。为了避免不同【句向量】的句子拆分了一个完整的句子,有些情况下会给给余量,保证句子完整。
太抽象了?
没关系,这个网站最强的地方就是提供了一个可视化的效果让你一目了然。
如果我们保持上面截图里的配置,会看到这样一张色彩斑斓的图:
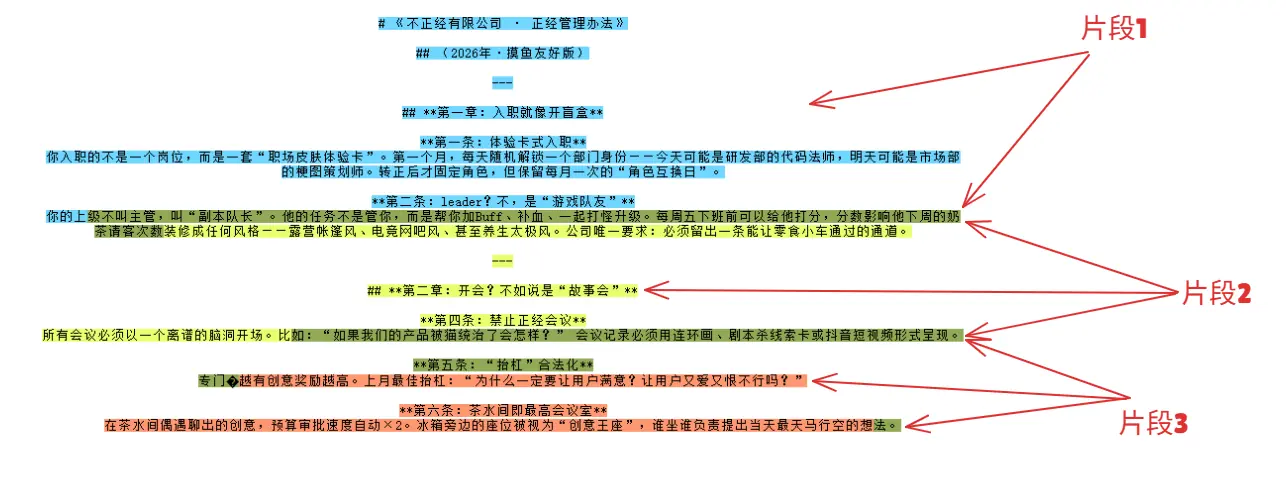
这张图里,因为我们采用了"Token Splitter",因此基本就是按 ChunkSize = 500分出了三个文本片段。
- 蓝色 + 绿色1 = 片段1
- 绿色1 + 黄色 + 绿色2 = 片段2
- 绿色2 + 粉色 + 绿色3 = 片段3
只有绿色部分是特殊的,它是【重叠片段】,也就是由 ChunkOverlap 这个参数控制的。
截图里的"每周五下班前可以给他打分,分数影响他下周的奶茶请客次数"这句话就会被【片段1】和【片段2】同时引用。
这样的好处是可以防止一句话被从中强行截断,但可能导致关键信息同时命中两个句向量。
不过这显然利大于弊。
三、选择适合你的Splitter
选择不同的 Splitter 对于拆分结果的差异是显著的。
比如,这比调整 ChunkSize 和 ChunkOverlap 的数值的效果更明显,不同的拆分器对于文本的特定格式做了更有利的优化。
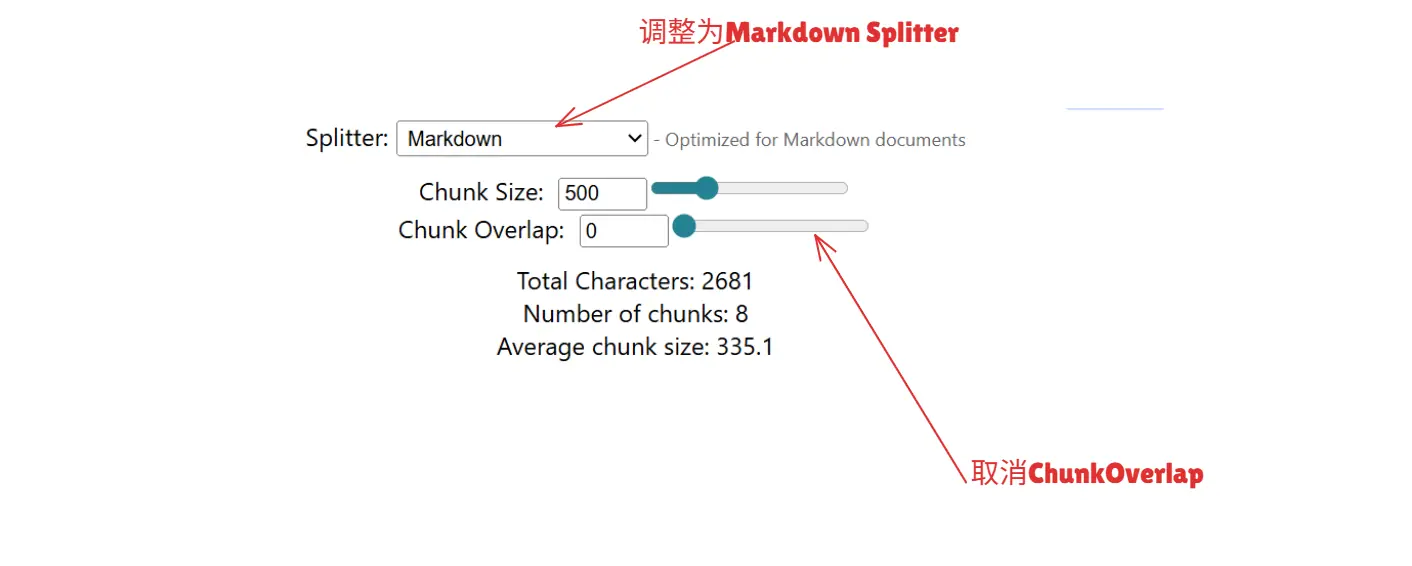
我们将上面例子的配置稍微做一下调整,如图。
再看看切分效果:
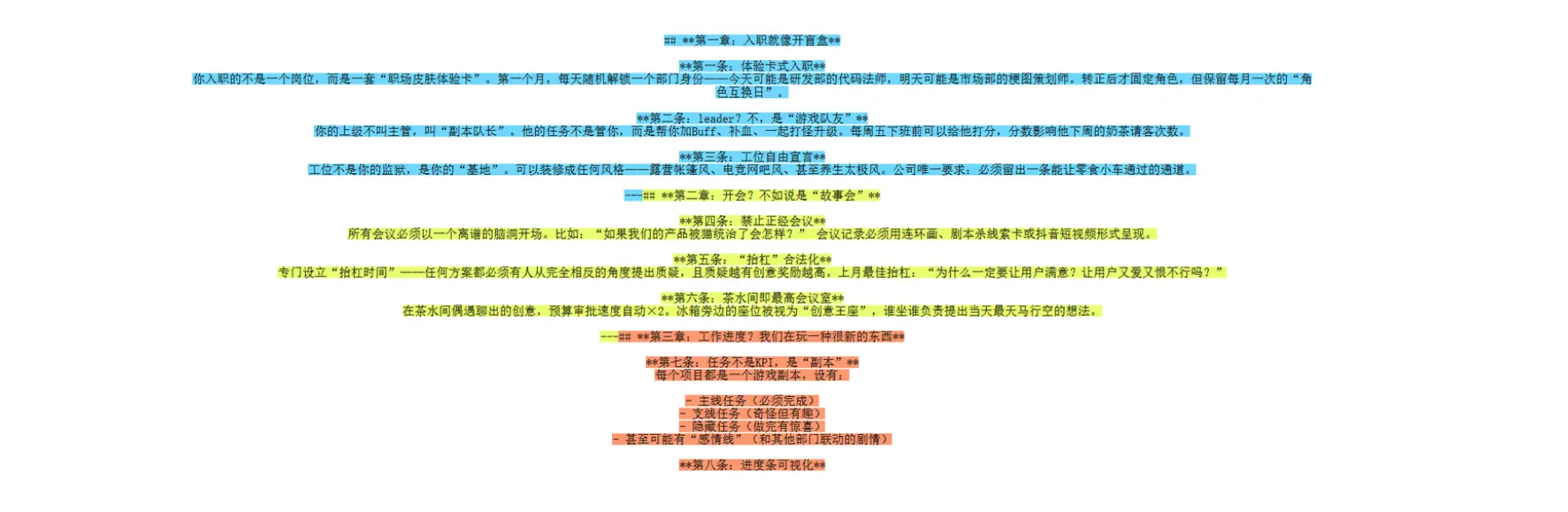
效果非常惊艳,它通过二级标题完成了文档切分。
针对不同的情况,比如Java 代码,我们还有很多 Splitter 可以选择,不过针对我们当前要实践的场景,使用 Markdown Splitter 就非常合理了。
更常见的工程选择通常是两步走:
-
保留灵魂 (MarkdownHeaderTextSplitter):先按 #、## 等标题切分。最牛的是,它会把所属的标题变成 Metadata(元数据) 挂在这个文本块上。这相当于给每段话戴上了 GPS 定位器,大模型以后看到这段话,瞬间就能知道它出自哪一章哪一节。
-
控制体型 (RecursiveCharacterTextSplitter):如果某个标题下的内容依然太长,我们再按段落、句子进行二次切分(比如限制在 400 字符内,并保留 50 字符的重叠防断句),以完美适配底层向量模型(如 bge-small 的 512 限制)。
四、在代码里切分
尝试撰写如下代码进行测试和验证:
python
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
# 1. 模拟一篇真实的 Markdown 文档
markdown_text = """
# DeepSeek 使用指南
## 1. 简介
DeepSeek 是一家专注于大语言模型的初创公司。
它的特点是性价比极高,且模型能力在开源界名列前茅。
## 2. API 调用
### 2.1 准备工作
你需要先去官网注册账号,并获取一个 API Key。请妥善保管这个 Key。
### 2.2 Python 代码示例
这里是一段如何用 Python 发起请求的代码...(假设这里有一万字)
"""
# --- 第一步:按 Markdown 标题切分 ---
# 告诉程序,我们要识别哪些级别的标题,并给它们起个名字
headers_to_split_on = [
("#", "主标题"), # 识别 #
("##", "二级标题"), # 识别 ##
("###", "三级标题"), # 识别 ###
]
# 初始化 Markdown 切分器
markdown_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=headers_to_split_on,
strip_headers=False # 保留文本里的 # 号(如果你不想要可以设为 True)
)
# 执行第一步切分
md_header_splits = markdown_splitter.split_text(markdown_text)
# --- 第二步:按字符长度二次切分 ---
# 如果某个标题下的内容特别长(比如超过了 bge-small 的 512 限制),需要再切碎
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=400, # 限制每块最大 400 字符
chunk_overlap=50 # 重叠 50 字符防断句
)
# 执行第二步切分 (注意这里用的是 split_documents,因为它已经是结构化数据了)
final_splits = text_splitter.split_documents(md_header_splits)
# --- 查看结果 ---
print(f"一共切成了 {len(final_splits)} 块\n")
for i, doc in enumerate(final_splits):
print(f"--- 第 {i+1} 块 ---")
print(f"📝 内容: {doc.page_content.strip()}")
# 除了切片,它还生成了非常关键的 metadata
print(f"🏷️ 标签(Metadata): {doc.metadata}\n")执行以上脚本,查看输出:
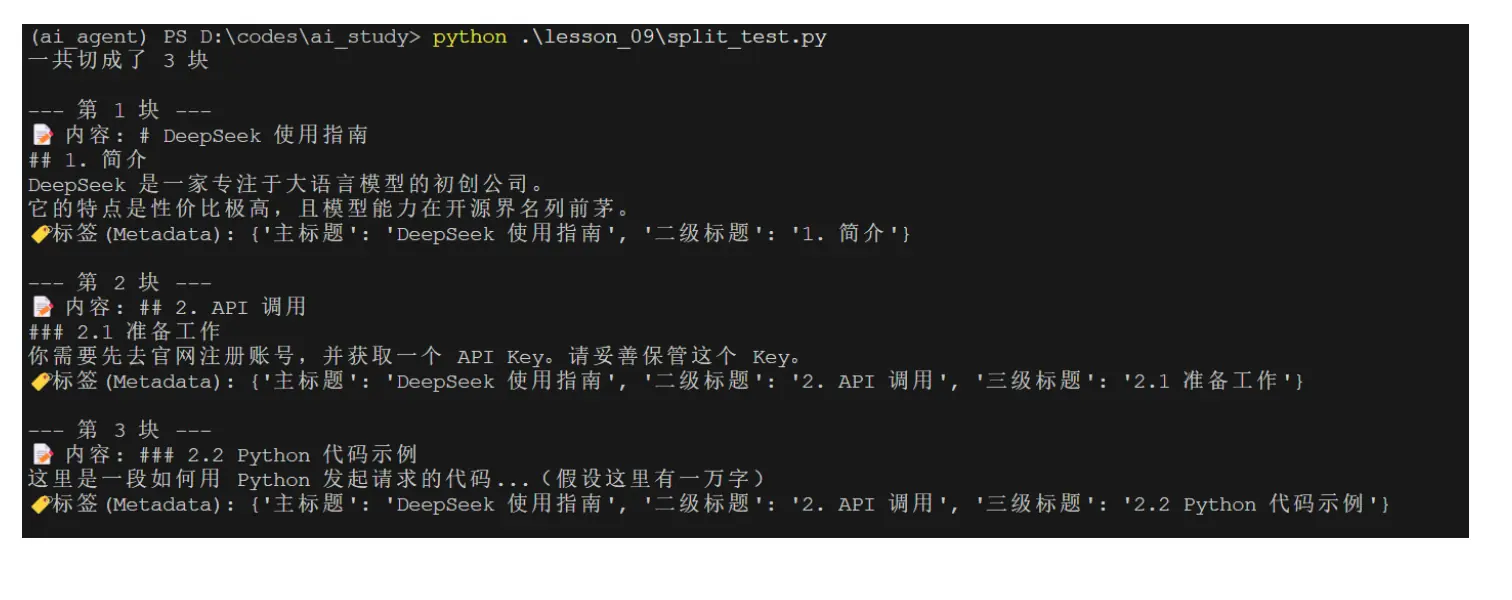
可能你注意到了,除了生成切片之外,Markdown Splitter还生成了metadata。
这东西有用吗?
太有用了兄弟!
未来你可以这样使用它:
python
results = collection.query(
query_texts=["怎么写 Python 代码?"],
n_results=2,
# 杀手锏:只在主标题是"DeepSeek 使用指南"的范围内进行向量搜索!
where={"主标题": "DeepSeek 使用指南"}
)这对企业级的应用而言,是绝对必要的。
以上相关代码我已经上传到demo仓库,你可以通过执行以下命令来体验:
bash
python .\lesson_09\split_test.py到现在为止,你已经掌握了切片的基础用发,我们可以开始下一步了。
下一步预告
本节课我们完成了文档切片,这是决定RAG质量的关键一步,在此基础上我们就可以生成我们的【句向量】数据库了。
敬请期待!
