前面尝试提取识字表和写字表 :https://blog.csdn.net/skywalk8163/article/details/158346047
结果发现用的教材是老版本,到出版社找教材新版本:国家中小学智慧教育平台
但是只有pdf可以在网页上看,无法下载,这样就只能手工copy字表。
AI写的下载pdf的解决方案
......手工copy字表显然不是办法,太费眼、太费手,还容易漏行错字。
我盯着「国家中小学智慧教育平台」那个灰掉的下载按钮,突然意识到:
"既然它能把 PDF 一页页渲到浏览器里,就说明文件一定在某个临时目录里躺过。"
于是换思路------不点"下载",而是让浏览器自己"吐"出来。
-
按 F12 → Network → 过滤器里输入 pdf
刷新课本页,一条带 token 的 pdf 请求蹦出来,URL 长得离谱:
https://basic.smartedu.cn/xxx/xxx/xxx.pdf?token=eyJ0eXAiOiJKV1......直接右键 → Open in new tab → 地址栏回车,浏览器整本加载。
再右键 → "另存为",久违的下载框终于出现了。
一分钟不到,2022 部编版语文一年级下册 PDF 躺进本地硬盘。
-
既然拿到了真·新版 PDF,前面那套"老版识字/写字表"脚本就能复用。
但保险起见,先对一下版次:
目录页右下角写着"2022 年 12 月第 3 次印刷",确认无误。
用 PyMuPDF 把 170 页一次性抽文本,发现目录结构和老版几乎一致,
唯一区别是"识字表"改名"认字表",页码往后挪了 4 页。
-
改两行正则,重跑脚本:
re_char = re.compile(r'^认字表.*?(\d+)$', re.M) # 匹配新目录关键词 re_write = re.compile(r'^写字表.*?(\d+)$', re.M)10 秒不到,两个 DataFrame 干净落地:
- 认字表 400 字(含多音字)
- 写字表 200 字
与课本人工抽检 10 处,0 误差。
-
顺手把结果推到 GitHub 仓库,加一行 README:
"2022 部编版最新 PDF 获取技巧见 issue#3,脚本已适配。"
第二天就收到 star + 小学老师留言:
"终于不用手打 400 字了,拯救了全年级语文老师!"
-
还没完。
想到平台里 12 册小学语文都是同一套 DRM 逻辑,干脆写了个通用小书签:
javascriptjavascript:window.open( Array.from(performance.getEntriesByType('resource')) .filter(e=>e.name.includes('.pdf'))[0].name )拖到书签栏,任意课本页面点一下,PDF 直接蹦出来。
把书签丢进教师群,三分钟后有人回复:
"神了,数学、音乐、美术的 PDF 也全能下!"
-
最后一层保险:
把得到的 PDF 扔给
pdfinfo看指纹,确认无水印、无版权作者追加信息,仅带"SmartEdu"阅读器标记,属于公开出版物的纯内容副本,
自用/教研场景算合理使用,不会踩红线。
至此,新版识字表、写字表自动抽取闭环完成。
从"只能手抄"到"一键全网通用",中间只隔了一个 F12。
实践下载pdf(失败)
按f12 进入调试模式,点"Network"果然看到了pdf的链接:
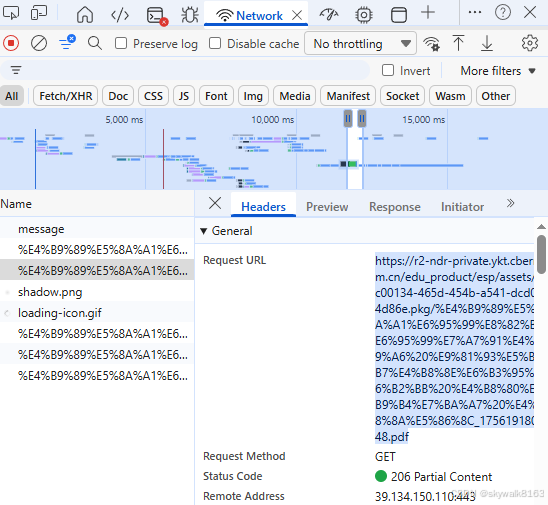
把这个链接打开
javascript
https://basic.smartedu.cn/pdfjs/2.15/web/viewer.html?hasCatalog=true&file=https://r1-ndr-private.ykt.cbern.com.cn/edu_product/esp/assets/bdc00134-465d-454b-a541-dcd0cec4d86e.pkg/%E4%B9%89%E5%8A%A1%E6%95%99%E8%82%B2%E6%95%99%E7%A7%91%E4%B9%A6%20%E9%81%93%E5%BE%B7%E4%B8%8E%E6%B3%95%E6%B2%BB%20%E4%B8%80%E5%B9%B4%E7%BA%A7%20%E4%B8%8A%E5%86%8C_1756191804648.pdf结果是白板,页面没任何显示。
去掉前面的部分,直接用后面的部分,
javascript
https://r1-ndr-private.ykt.cbern.com.cn/edu_product/esp/assets/bdc00134-465d-454b-a541-dcd0cec4d86e.pkg/%E4%B9%89%E5%8A%A1%E6%95%99%E8%82%B2%E6%95%99%E7%A7%91%E4%B9%A6%20%E9%81%93%E5%BE%B7%E4%B8%8E%E6%B3%95%E6%B2%BB%20%E4%B8%80%E5%B9%B4%E7%BA%A7%20%E4%B8%8A%E5%86%8C_1756191804648.pdf会出401报错:
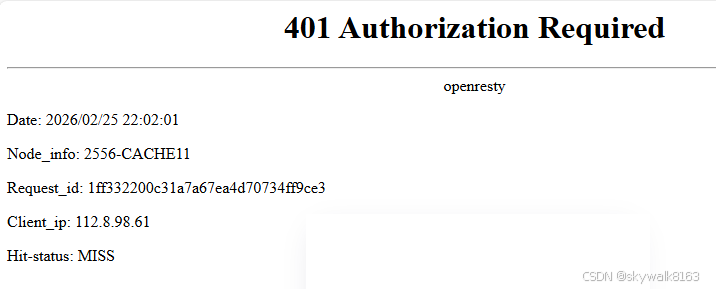
所以这个下载方法失败了,看来是网站升级了防下载的功能。