文章目录
-
-
- 引言:当AI开始"胡说八道"时,法务正在承担代价
- 核心一:交付物之变------从"给出答案"到"制造证据链"
- [核心二:颗粒度革命------从"Token切分"到"条款级索引(Clause-level Chunking)"](#核心二:颗粒度革命——从“Token切分”到“条款级索引(Clause-level Chunking)”)
-
- [法务 RAG 的强制性元数据架构设计](#法务 RAG 的强制性元数据架构设计)
- 核心三:拒绝权------建立"拒答门禁"的生死线
- 核心四:交互重构------结构化报告与双向溯源
-
- [1. 结构化约束(JSON Schema)的心理学与工程学](#1. 结构化约束(JSON Schema)的心理学与工程学)
- [2. UI层面的终极信任:Bbox 级双向溯源](#2. UI层面的终极信任:Bbox 级双向溯源)
- 核心五:审计与回放------法务系统的"黑匣子"
- 核心六:迁移与底座------拒绝供应商锁定 (Vendor Lock-in)
- 结语:从"生成能力"到"可信系统工程"
-
导语:在通用大模型的语境下,AI产生的"幻觉"(Hallucination)或许只是社交媒体上博人一笑的段子;但在法律合规领域,幻觉就是一场实打实的"官司",是足以毁掉职业生涯的定时炸弹。本文将从高级架构师与算法工程师的视角,深度拆解法务大模型落地的底层逻辑:为什么法务场景的终局不是"更聪明的Chatbot",而是"可溯源的证据链引擎"?
引言:当AI开始"胡说八道"时,法务正在承担代价
2023年,美国纽约的一位律师在法庭上引用了由ChatGPT编造的6个虚假判例,最终不仅面临巨额罚款,还受到了严厉的司法制裁(著名的 Mata v. Avianca 案)。这起事件犹如一记警钟,彻底击碎了法律界对生成式AI盲目崇拜的滤镜。
根据 Thomson Reuters 及 Stanford HAI 的基准研究记录,在复杂的法律阅读理解与推理任务中,未经严格工程约束的大模型,其幻觉比例和事实错误率不容忽视。在合同审查、合规问答、尽职调查等高风险(High-Stakes)场景中,哪怕是1%的虚构条款引用,都可能导致千万级别的商业损失。
作为系统架构师,我们必须清醒地认识到一个残酷的工程真相:法务场景对 RAG(检索增强生成)系统的要求,绝不是让它变得"更会聊",而是要让它变得"更敢说不知道"。我们要构建的,不是一个满嘴跑火车的"赛博律师",而是一台精密、严谨、每一步输出都具备可追责确定性的"可信审查仪器"。
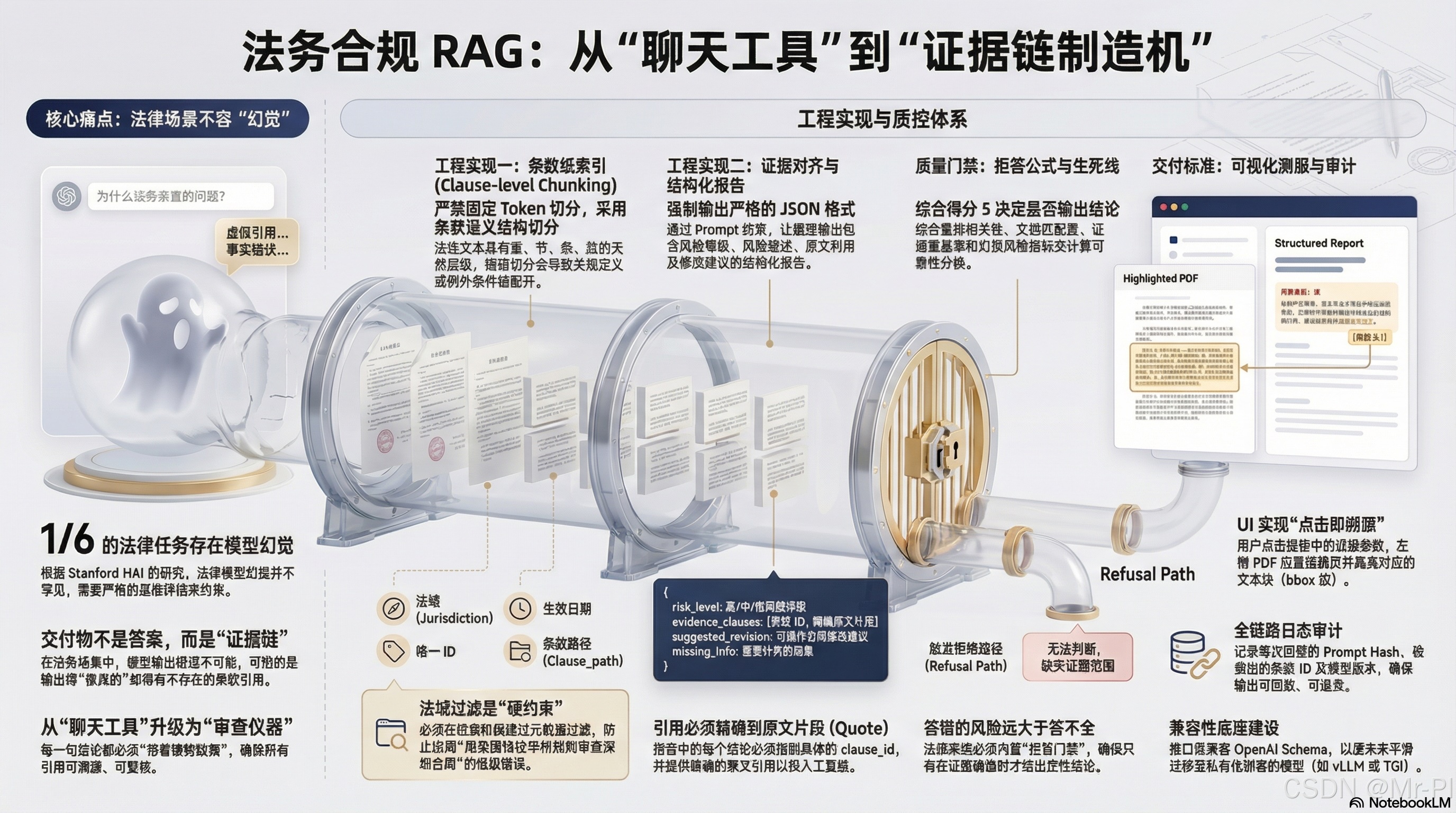
核心一:交付物之变------从"给出答案"到"制造证据链"
在通用搜索场景下,用户期待的是"总结好的最终答案"。但在法律合规的核心业务中,交付物从来不是一个"看起来像真的"结论,而是**"结论+严密的证据链条"**。
法务工作的专业护城河在于:每一个结论都必须能够追溯到原始法律条文或合同准则。
"法务 RAG 的护城河不是'会写',而是'能证明'。"
这意味着,我们必须在系统架构层面,彻底放弃对大语言模型(LLM)"博识天下"的幻想。LLM 在法务系统中的角色,应该从"包含所有知识的数据库"降级为"戴着镣铐跳舞的中央处理器(CPU)"。
我们可以用下面这个流程图来对比传统RAG与法务级RAG的本质区别:
法务证据链 RAG (Evidentiary RAG)
是
否
用户提问/审查请求
元数据硬过滤 + 向量/稀疏混合检索
条款级重排 Reranking
拼接到严格的 JSON Schema Prompt
大模型提取原文, 执行逻辑推理
后置校验: 引用真实性比对
是否触发拒答门禁?
返回缺失信息清单
生成带PDF坐标的结构化证据报告
传统问答 RAG (Generative RAG)
用户提问
向量检索获取 Top-K 文本块
拼接到 Prompt
大模型自由发挥生成答案
直接展示给用户
在法务RAG中,大模型的核心任务是利用其强大的自然语言理解(NLU)能力去重组检索到的证据链,而不是由它来发明事实。
核心二:颗粒度革命------从"Token切分"到"条款级索引(Clause-level Chunking)"
如果你还在用 LangChain 默认的 RecursiveCharacterTextSplitter(比如按 1000 Token 切分,Overlap 200)来处理法律合同,那么你的系统从第一步就已经走向了失败。
传统"固定长度切分"是法律文本处理的灾难。 想象一下,一个复杂的"不可抗力"条款被无情地从中间切断;或者一个关键的"赔偿上限(Cap on Liability)"定义丢失了它前置的限制条件。这种上下文的物理割裂,必然会导致模型在后续推理时产生严重的幻觉或误导性结论。
真正的法务级 RAG 必须实现条款级语义结构切分(Clause-level Chunking)。我们需要将文档解析为抽象语法树(AST),按照"章、节、条、款、项"的天然语义边界进行解析,并将法律属性硬编码进向量数据库的元数据(Metadata)中。
法务 RAG 的强制性元数据架构设计
每一次 Chunking,都必须携带以下维度的强约束信息:
doc_id: 文档唯一标识(确保多文档审查时源头不乱)。jurisdiction: 法域(如 Delaware, 深圳)。这是防止"法域错配"的硬门禁。clause_path: 如["第3章", "第2条", "第1款"],提供清晰的树状索引。effective_date: 生效日期与版本(防止引用被废止的旧法)。source_bbox: PDF 坐标[page, x0, y0, x1, y1],实现像素级的 UI 溯源。
Python 算法示例:基于正则与 NLP 的条款树状解析(简化版)
python
import re
from typing import List, Dict
class LegalDocumentParser:
def __init__(self):
# 定义章、条的正则表达式模式
self.chapter_pattern = re.compile(r"^(第[一二三四五六七八九十百]+章)\s+(.*)")
self.article_pattern = re.compile(r"^(第[一二三四五六七八九十百]+条)\s+(.*)")
def parse_to_clause_chunks(self, text: str, doc_metadata: Dict) -> List[Dict]:
lines = text.split('\n')
chunks =[]
current_chapter = "未分类"
current_article = "未分类"
current_buffer =[]
for line in lines:
line = line.strip()
if not line:
continue
# 匹配章
chapter_match = self.chapter_pattern.match(line)
if chapter_match:
current_chapter = chapter_match.group(1)
continue
# 匹配条
article_match = self.article_pattern.match(line)
if article_match:
# 保存上一个条款的 Chunk
if current_buffer:
chunks.append(self._build_chunk(current_buffer, current_chapter, current_article, doc_metadata))
current_buffer =[]
current_article = article_match.group(1)
current_buffer.append(line)
else:
current_buffer.append(line)
# 收尾最后一个 Chunk
if current_buffer:
chunks.append(self._build_chunk(current_buffer, current_chapter, current_article, doc_metadata))
return chunks
def _build_chunk(self, buffer: List[str], chapter: str, article: str, metadata: Dict) -> Dict:
content = "\n".join(buffer)
return {
"content": content,
"metadata": {
**metadata,
"clause_path": f"{chapter}-{article}",
"chunk_type": "legal_clause"
}
}
# 这种工程手段,比指望大模型自己去猜上下文要可靠100倍。与其寄希望于模型能在 prompt 里分清不同法域的细微差别,不如在数据检索层(Vector DB)通过 Metadata Filter 直接完成法域的物理隔断,实现**"用工程手段解决模型弱点"**。
核心三:拒绝权------建立"拒答门禁"的生死线
在法律任务中,有一个铁律:"答错的风险远大于答不全(False Positives are worse than False Negatives)"。
为了实现"可靠性中心设计(Reliability-Centered Design)",系统必须内置一套工程化的决策逻辑,我们称之为"拒答门禁(Refusal Gate)"。当系统找不到足够支撑结论的证据时,它必须优雅地闭嘴。
在算法架构上,我们将这一过程量化为一个综合置信度分数 S S S:
S = α ⋅ s r e r a n k + β ⋅ s d o c _ m a t c h + γ ⋅ s c o v e r a g e − δ ⋅ r h a l l u c i n a t i o n S = \alpha \cdot s_{rerank} + \beta \cdot s_{doc\match} + \gamma \cdot s{coverage} - \delta \cdot r_{hallucination} S=α⋅srerank+β⋅sdoc_match+γ⋅scoverage−δ⋅rhallucination
公式参数解析:
- s r e r a n k s_{rerank} srerank:条款级重排得分。来自 Cross-Encoder 或 BGE-Reranker 的相关性评分。如果最高分低于 0.6,说明根本没搜到相关条款。
- s d o c _ m a t c h s_{doc\_match} sdoc_match:元数据匹配度。法域、合同类型、有效性等是否完全契合当前审查要求(通常是 1 或 0 的硬性布尔值)。
- s c o v e r a g e s_{coverage} scoverage:证据覆盖率。用户提问的关键风险点(Entities/Claims),在提取的原文中覆盖的比例。
- r h a l l u c i n a t i o n r_{hallucination} rhallucination:幻觉惩罚项。这是一个后置校验项。我们可以引入一个轻量级的 NLI(自然语言推理)模型,判断 LLM 生成的结论与检索到的原文之间是"蕴含(Entailment)"、"矛盾(Contradiction)"还是"中立(Neutral)"。如果出现矛盾,惩罚项急剧上升。
拒答路径(Refusal Path)的执行:
当 S < T h r e s h o l d S < Threshold S<Threshold 时,系统强行熔断生成任务,转而进入异常处理分支:
拒绝输出"合规/不合规"的判断,转而列出缺失的证据范围或建议业务方补充的信息。
这种机制彻底改变了 AI 的性格------从一个拼命讨好、爱表现的学生,变成了一个冷酷、谨慎、讲求证据的法官。
核心四:交互重构------结构化报告与双向溯源
法务 RAG 的理想交付形态绝不是一个像微信一样的对话框(Chatbot UI),而是一个由 JSON 驱动的、具备高度交互性的结构化审查报告(Structured Audit Report)。
1. 结构化约束(JSON Schema)的心理学与工程学
从架构心理学来看,当你允许模型输出自由文本时,它很容易通过"文学修辞"、"模棱两可的套话"来蒙混过关。但当你强制模型以 JSON 格式输出,并指定严格的 Schema 时,你实际上是在迫使模型在指定的槽位(Slots)里填充硬生生的证据。
利用 OpenAI 的 Function Calling 或开源模型的 Structured Outputs 特性,我们可以定义如下 Pydantic 结构:
python
from pydantic import BaseModel, Field
from typing import List, Optional
class Evidence(BaseModel):
clause_id: str = Field(description="原文条款的唯一ID")
exact_quote: str = Field(description="从原文中一字不差提取的引文")
relevance: str = Field(description="该条款为何与当前风险点相关")
class LegalRiskAssessment(BaseModel):
risk_level: str = Field(enum=["High", "Medium", "Low", "Unknown"])
conclusion: str = Field(description="基于证据的最终法律结论")
evidences: List[Evidence] = Field(description="支撑该结论的证据链,若无证据必须为空")
missing_info: Optional[str] = Field(description="如果无法得出结论,指出缺失了什么前置条件")2. UI层面的终极信任:Bbox 级双向溯源
在产品设计上,必须遵循"左侧原文阅读器、右侧结构化报告"的双屏对比逻辑。
我们利用元数据中的 Bbox(Bounding Box)坐标,实现像素级的双向联动:
- 正向追溯: 用户点击右侧报告中的
evidence_clause,左侧的 PDF 渲染器瞬间滚动到对应页码,并用高亮框(Highlight Marker)精准框出该条款的坐标范围。 - 反向验证: 这种设计将"引用"从单纯的文本装饰,转变为肉眼可立刻复核的证据锚点(Evidence Anchor)。
这是建立专业律师对 AI 系统信任的唯一基石。只有当法务人员发现自己可以瞬间核实 AI 的每一句话时,他们才会真正接纳这个工具。
核心五:审计与回放------法务系统的"黑匣子"
在自动驾驶领域,事故发生后需要查阅"黑匣子"数据;在法律场景中同样如此。一个不具备"可回放性(Reproducibility)"的系统,是不具备商用价值的。
如果同一份供应商合同,在周一审查时提示"无风险",在周三审查时却提示"存在违约风险",这种不可解释的系统波动对于法务团队而言,就是一场合规性灾难(Compliance Liability)。
作为高级系统架构师,必须在系统中引入完备的"审计黑匣子(Audit Blackbox)":
- 全链路 Trace 记录: 将每一次请求的
prompt_hash、retrieved_clause_ids、召回相关性得分、大模型版本号、Temperature 配置,落盘存储到 ClickHouse 或 Elasticsearch 中。 - 争议样本池(Human-in-the-loop): 当法务专家对 AI 的审查结论进行修改或点踩(Thumbs down)时,该条 Case 自动进入"争议样本池"。算法工程师介入复盘,是 Chunking 切分错了?是 Rerank 漏掉了关键约束?还是大模型推理逻辑断裂?
- 回归评测体系(Regression Testing): 在系统迭代时,使用类似 LegalBench-RAG 的领域基准测试集进行自动化评测。确保调整了一个 prompt 或者更换了一个模型版本后,存量的 10,000 个测试用例(尤其是历史易错案)依然能够得到稳定的正确结果。
核心六:迁移与底座------拒绝供应商锁定 (Vendor Lock-in)
对于法务这种极其注重数据隐私与机密性的敏感业务,**"数据出域限制"与"私有化部署"**是企业级架构避不开的命题。很多顶尖律所或跨国企业的合规要求,绝对禁止将未脱敏的合同文本发送给公有云的 API。
因此,在架构设计之初,就必须实现大语言模型(LLM)算力层的抽象与解耦。
高级架构师通常会采用如下多层架构:
非敏感通用任务/高复杂度推理
极度机密合同审查
Legal RAG Application Layer
LLM Gateway / Router
OpenAI GPT-4 / Claude 3.5 Sonnet
Private API Endpoint
vLLM / TGI Inference Engine
私有化部署模型: Llama-3-70B / Qwen2-72B / 内部法务微调模型
通过引入 LiteLLM 或自行编写的 Provider 抽象层,锁定与 OpenAI Schema 的兼容性协议。当企业由于数据安全要求,必须从公有云大模型迁移到本地机房部署的 Qwen(通义千问)或 Llama 时,业务层的核心逻辑、JSON Schema 解析器、提示词工程无需重写,只需修改 Gateway 层的路由配置即可实现平滑切换。
结语:从"生成能力"到"可信系统工程"
回望过去两年的大模型浪潮,我们走过了一段充满泡沫的弯路。法务 RAG 的产品化本质,绝对不是在贩卖大模型那华丽流畅的"文笔",而是在构建一套严密的"可信系统工程(Trustworthy Systems Engineering)"。
在未来的企业级 AI 竞赛中,衡量一个法务大模型价值的标准,将彻底从"它知道多少法律概念"转向"它能为自己的每一句话提供多少铁证"。
当我们将证据溯源(Evidence)、工程复核(Verification)、链路审计(Audit)与架构迁移(Portability)这四个维度深度嵌入系统的血脉时,AI 才能真正褪去"玩具"的标签。它不再是一个会偶尔讲笑话、偶尔闯大祸的赛博助理,而是演变成为一个让法务总监敢于签字、让企业敢于交付的真正生产力引擎。
继续分别阅读RAG 五大应用场景 :
(零)总论
(一)
(二)
(三)
(五)