一、RAG 核心概念
1.1 什么是 RAG?
检索增强生成(Retrieval-Augmented Generation, RAG) 是一种融合信息检索技术 与大语言模型(LLM) 的 AI 生成框架。其核心逻辑是:先从外部知识库精准检索相关信息,再将检索结果作为上下文喂给大模型,由大模型结合检索内容生成准确、事实性强的回答。
RAG 技术最初由 Meta AI 研究院(FAIR)在 2020 年提出,现已成为解决大模型 "幻觉" 问题、接入专属知识库的主流方案。
1.2 为什么需要 RAG?
RAG 主要解决大语言模型的三大核心痛点:
| 痛点 | 描述 | RAG 解决方案 |
|---|---|---|
| 幻觉现象 | 模型自信地生成与事实不符的内容 | 基于检索到的真实信息生成答案 |
| 知识时效性 | 训练数据存在时间窗口限制,无法获取最新信息 | 动态更新外部知识库,无需重新训练模型 |
| 专属知识接入 | 无法访问企业内部文档、私有数据等 | 构建专属知识库,实现私有数据的安全利用 |
| 可解释性差 | 输出结果缺乏可追溯的知识来源 | 提供引用来源,支持答案验证 |


1.3 RAG 核心优势
- 低成本知识更新:无需重新训练昂贵的大模型
- 高准确性:显著减少幻觉,提升回答的事实性
- 数据安全:私有数据无需上传用于模型训练
- 可追溯性:答案可关联到具体的知识来源
- 灵活性:支持多种数据源和文档格式
1.4 关键术语解释
- 嵌入(Embedding):将文本转换为高维向量表示,保留语义信息
- 向量数据库:专门存储和检索向量数据的数据库,支持高效的相似度搜索
- 分块(Chunking):将长文档分割成适合向量化和检索的小片段
- 召回(Retrieval):从知识库中找到与用户问题相关的文档片段
- 重排序(Reranking):对初步召回的结果进行更精细的相关性排序
- 上下文窗口:大模型一次能处理的最大文本长度
二、RAG 基本原理
2.1 混合记忆系统
RAG 的核心创新在于其独特的混合记忆系统架构,巧妙结合了两种记忆的优点:
-
参数化记忆(Parametric Memory):
- 存储在大语言模型的数十亿甚至数万亿个网络参数中
- 包含预训练过程中学到的通用世界知识和语言能力
- 优点:语言流畅性好、推理能力强
- 缺点:静态、更新成本高、易产生幻觉
-
非参数化记忆(Non-Parametric Memory):
- 存储在外部知识库(如向量数据库)中
- 包含企业文档、产品手册、最新资讯等特定知识
- 优点:动态可更新、可解释性强、成本低
- 缺点:缺乏语言生成能力
RAG 通过一个可微分的访问机制,使这两种记忆系统能够协同工作。模型不再仅仅依赖其 "大脑" 中的固有知识,而是学会在需要时 "查阅书籍"。
2.2 开卷考试类比
理解 RAG 最简单的方式是将其比作开卷考试:
- 大模型 = 聪明但记忆力有限的学生
- 外部知识库 = 考试时可以查阅的课本和资料
- RAG 系统 = 帮助学生快速找到相关知识点并组织答案的助手
在闭卷考试中(纯 LLM),学生只能依靠自己记住的知识回答问题,容易记错或答不上来。而在开卷考试中(RAG),学生可以先查阅相关资料,再基于资料给出准确的答案。
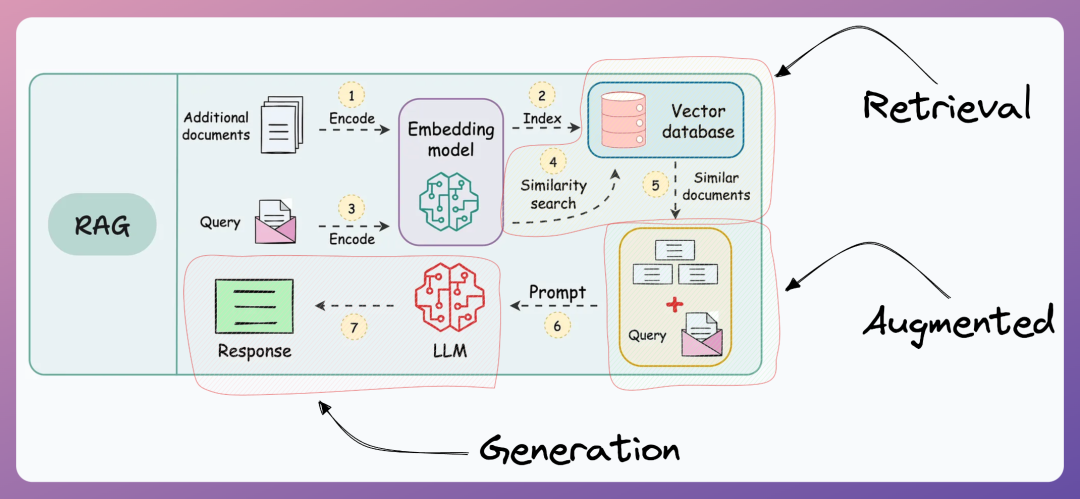
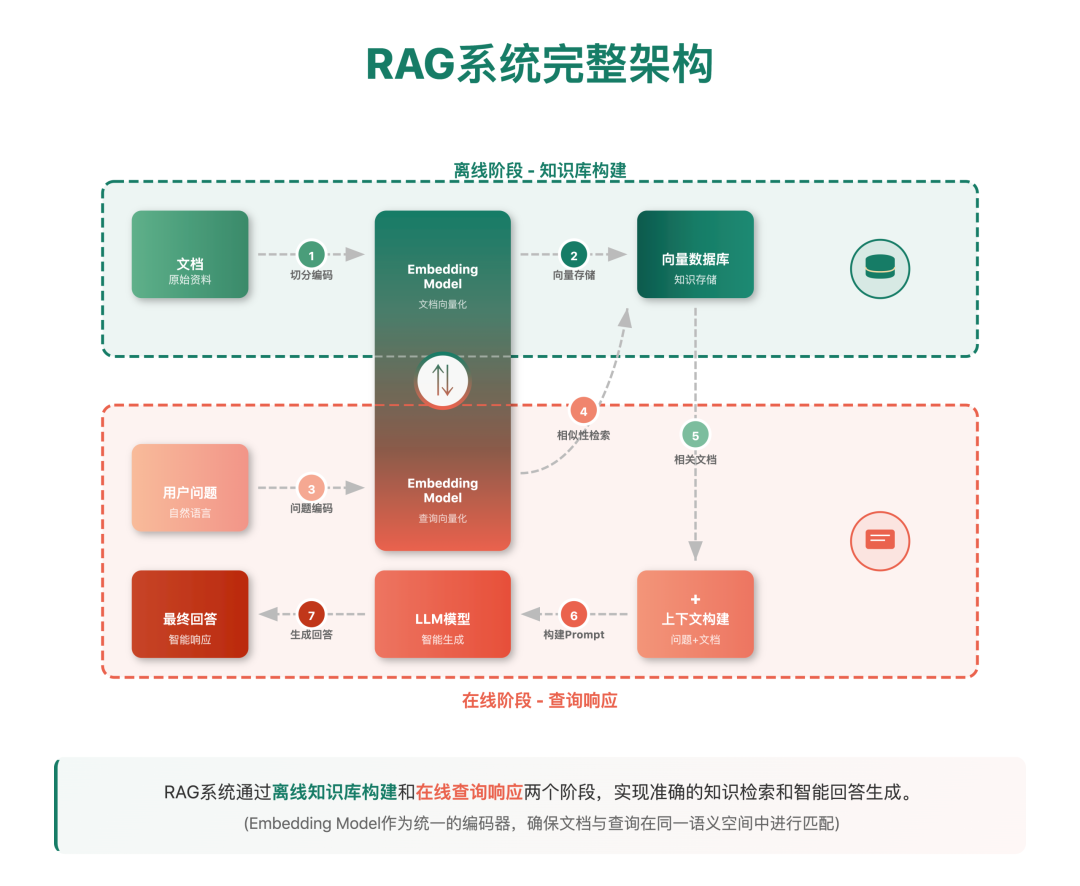
三、RAG 完整流程概览
RAG 系统的工作流程分为两个主要阶段:离线知识库构建阶段 和在线问答生成阶段。
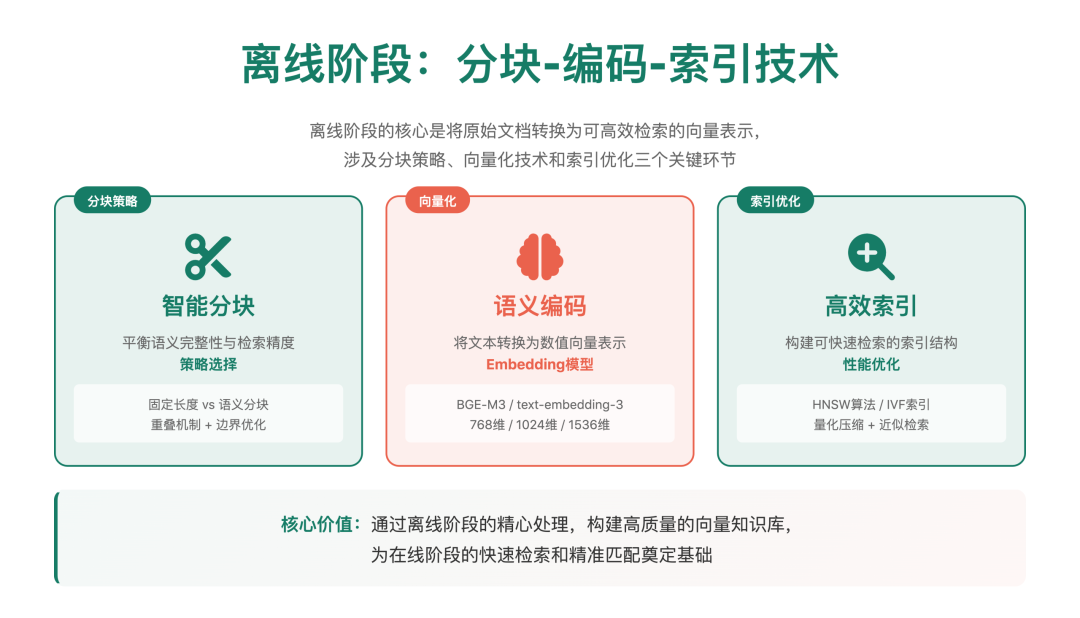
3.1 离线流程:知识库构建
这是一次性的预处理过程,当知识库内容更新时需要重新执行。
- 数据采集:收集各种格式的原始数据(PDF、Word、HTML、Markdown、数据库等)
- 文档解析:将不同格式的文档转换为纯文本格式
- 文本清洗:去除无关内容、格式标记、重复信息等
- 文本分块:将长文本分割成适合向量化的小片段(通常 100-1000 个 token)
- 向量化:使用嵌入模型将每个文本块转换为高维向量
- 索引构建:将向量和对应的原始文本存储到向量数据库中,建立索引
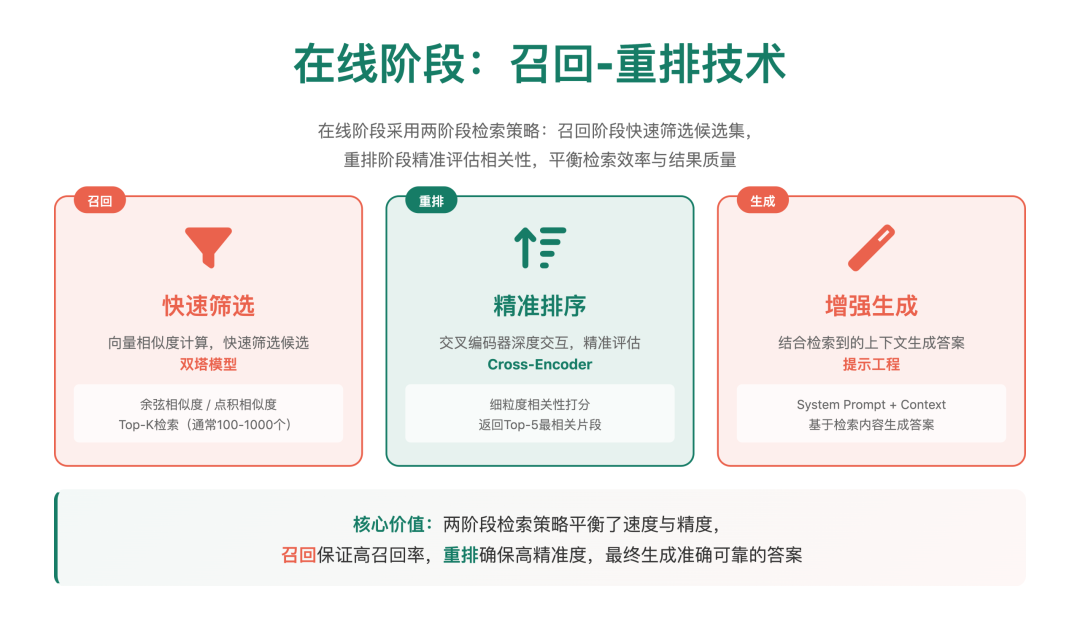
3.2 在线流程:问答生成
当用户提出问题时实时执行的过程。
- 问题向量化:使用相同的嵌入模型将用户问题转换为向量
- 检索召回:在向量数据库中搜索与问题向量最相似的 Top-K 个文本块
- 结果重排序(可选但推荐):使用更精确的模型对召回结果进行重新排序
- 上下文构建:将最相关的文本块拼接成上下文
- 提示词构建:将用户问题和上下文组合成符合大模型要求的提示词
- 答案生成:将提示词输入大模型,生成基于上下文的回答
- 结果返回:将生成的答案和引用来源返回给用户
3.3 朴素 RAG vs 高级 RAG
RAG 技术已经从最初的朴素版本演进到了更复杂的高级版本:
| 特性 | 朴素 RAG(Naive RAG) | 高级 RAG(Advanced RAG) |
|---|---|---|
| 检索方式 | 单一向量相似度搜索 | 混合搜索(向量 + 关键词)、多阶段检索 |
| 查询处理 | 直接使用原始查询 | 查询改写、多查询生成 |
| 结果处理 | 直接使用 Top-K 结果 | 重排序、上下文压缩、自动合并 |
| 分块策略 | 固定大小分块 | 语义分块、递归分块、滑动窗口 |
| 反馈机制 | 无 | 自我评估、纠错机制、迭代检索 |
| 适用场景 | 简单问答、小型知识库 | 复杂查询、大型知识库、生产环境 |
四、RAG 完整流程详细介绍
1. 数据处理(离线阶段)
1.1 数据采集
概念:数据采集是 RAG 系统的基础,指从多种来源获取不同格式的数据,为后续处理提供原始素材。
多源数据类型:
- 结构化数据:有固定 schema,如数据库表、Excel 表格、CSV 文件,易于查询和分析。
- 半结构化数据:有一定结构但不严格,如 Markdown、HTML、JSON、XML,包含标签或标记来分隔语义元素。
- 非结构化数据:无预定义结构,如纯文本、PDF 文档、图片、音频、视频,需额外处理才能提取语义信息。
数据来源:
- 内部文档:企业 Wiki、技术文档、会议纪要、内部报告。
- 公开网页:通过爬虫获取的行业资讯、技术博客、公开知识库。
- 知识库:第三方专业知识库(如维基百科、行业数据库)。
- API 接口:通过 RESTful API、GraphQL 等获取的动态数据(如新闻 API、金融数据 API)。
1.2 数据清洗与预处理
概念:对原始数据进行格式转换、去噪、去重等操作,将其转化为统一、干净的文本格式,提升后续处理质量。
核心步骤
-
格式转换
- PDF 转文本:使用
PyPDF2、pdfplumber提取文本;复杂排版 PDF 可结合LayoutLM等模型理解布局。 - OCR 识别:对扫描版 PDF、图片中的文字,使用
PaddleOCR、Tesseract进行识别。 - 音频转文字:使用 OpenAI Whisper、Azure Speech 等将音频 / 视频转录为文本。
- PDF 转文本:使用
-
数据清洗
- 去重:通过哈希(如 MD5)或相似度计算(如 MinHash)去除重复内容。
- 去噪:去除页眉页脚、广告、无关链接、特殊符号(如
�)。 - 格式统一:统一大小写、标点符号(如中文全角转英文半角)、日期格式。
示例代码(PDF 转文本 + 简单清洗)
python
import pdfplumber
import re
def pdf_to_clean_text(pdf_path):
text = ""
with pdfplumber.open(pdf_path) as pdf:
for page in pdf.pages:
text += page.extract_text() or ""
# 简单清洗:去除多余换行和空格
text = re.sub(r'\n+', '\n', text)
text = re.sub(r' +', ' ', text)
return text
clean_text = pdf_to_clean_text("example.pdf")1.3 文本分段 (Chunking)
概念:将长文本切分为较小的、语义相对完整的片段(Chunk),是 RAG 效果的关键环节 ------ 分段过大易丢失细节,过小易破坏语义连贯性。
核心技术与挑战
- 挑战:平衡 "语义完整性" 与 "检索粒度",避免跨段落语义断裂。
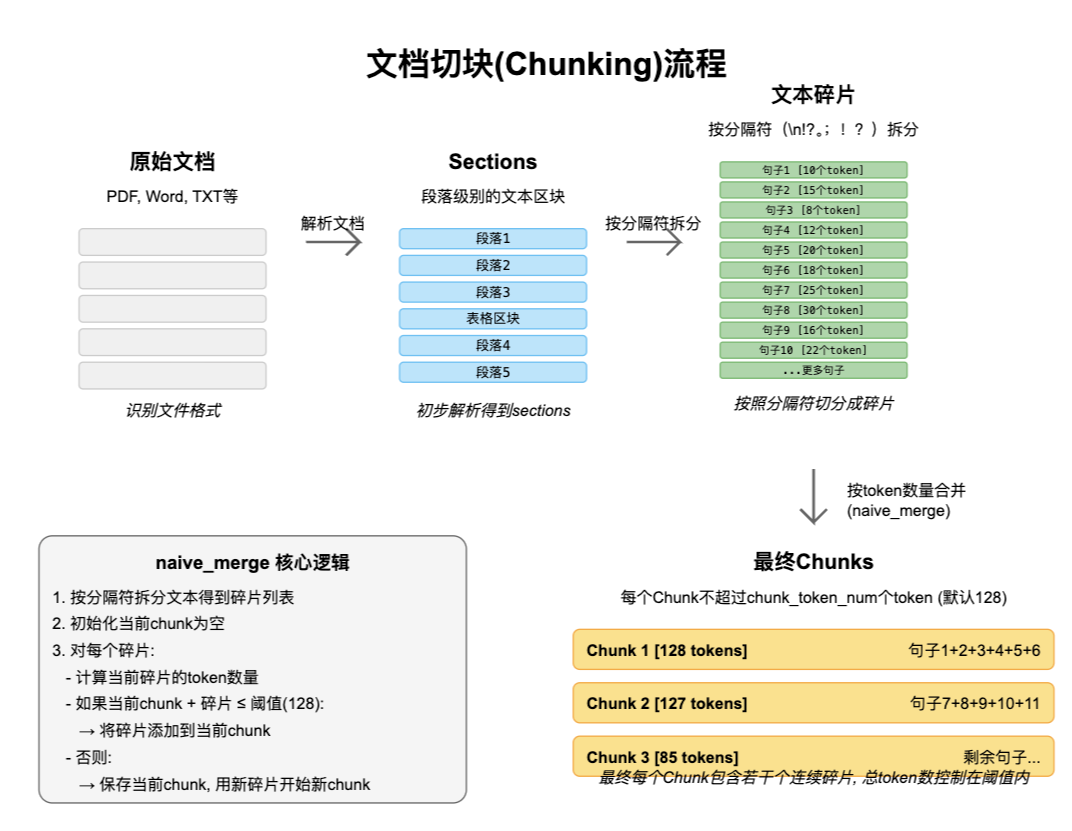
分段策略
-
固定长度分段
- 按字符数(如 500 字符)或 Token 数(如 512 Token)切分,简单高效但易切断语义。
- 示例代码(按 Token 数分段,使用
tiktoken)
python
import tiktoken
def fixed_length_chunking(text, chunk_size=512, chunk_overlap=50):
tokenizer = tiktoken.get_encoding("cl100k_base")
tokens = tokenizer.encode(text)
chunks = []
for i in range(0, len(tokens), chunk_size - chunk_overlap):
chunk_tokens = tokens[i:i + chunk_size]
chunks.append(tokenizer.decode(chunk_tokens))
return chunks
chunks = fixed_length_chunking(clean_text)-
语义分段
- 基于语义边界切分:按句子(
spaCy、nltk)、段落(\n\n)、章节(Markdown 标题#)切分,保留语义完整性。 - 进阶:使用
LangChain的RecursiveCharacterTextSplitter,按优先级尝试分隔符(["\n\n", "\n", "。", " ", ""])。
- 基于语义边界切分:按句子(
-
混合分段策略
- 固定长度 + 语义重叠:在固定长度分段基础上,让相邻 Chunk 重叠部分 Token(如 50-100 Token),避免语义丢失。
分段大小与重叠率选择原则
- 小文档(如短文):Chunk 大小 256-512 Token,重叠率 10%-20%。
- 长文档(如书籍):Chunk 大小 512-1024 Token,重叠率 20%-30%。
- 需结合 Embedding 模型的最大输入长度(如 BGE-base 最大 512 Token)调整。
1.4 向量化 (Embedding)
概念:将文本片段转换为高维稠密向量(数值数组),向量能捕捉文本的语义信息 ------ 语义相似的文本,向量距离更近。
向量表示原理
- 底层逻辑:通过预训练语言模型(如 BERT 系列),将文本映射到一个语义空间中,向量的每一维代表某种抽象语义特征(如 "科技感"、"情感倾向")。
主流嵌入模型
| 模型 | 特点 | 适用场景 |
|---|---|---|
| OpenAI Embedding | 效果稳定,API 调用便捷 | 快速原型、通用场景 |
| BGE (BAAI) | 开源中英双语效果好,支持小 / 中 / 大版本 | 中文场景、私有化部署 |
| M3E | 轻量级,中文优化,速度快 | 移动端、低资源场景 |
| Sentence-BERT | 专注语义相似度,适合句子级匹配 | 问答、检索系统 |
| Cohere Embedding | 支持多语言,有轻量 / 高质量版本 | 企业级应用 |
嵌入维度选择
- 维度越高:语义表达越丰富,但存储成本高、检索速度慢。
- 常见维度:128(轻量)、256(平衡)、512(通用)、1024+(高精度)。
- 建议:先试 512 维度,根据效果调整。
多模态嵌入
- 文本 - 图像:如
CLIP、BLIP-2,将图像和文本映射到同一向量空间,支持 "以文搜图"。 - 文本 - 音频:如
Wav2Vec2+ 文本模型,实现音频与文本的联合检索。
示例代码(使用 BGE 向量化)
python
from sentence_transformers import SentenceTransformer
# 加载 BGE 模型
model = SentenceTransformer('BAAI/bge-small-zh-v1.5')
# 对文本片段向量化
chunks = ["这是第一个文本片段", "这是第二个文本片段"]
embeddings = model.encode(chunks)
print(f"向量维度: {embeddings.shape[1]}") # 输出: 5122. 向量存储(离线阶段)
2.1 向量数据库基础
概念:专门用于存储、索引和检索高维向量的数据库,核心能力是 "相似性搜索"------ 给定查询向量,快速返回最相似的 Top-K 向量。
核心功能
- 向量存储:存储向量及其对应的元数据(如原始文本、来源、时间戳)。
- 相似性搜索:基于向量距离快速检索相似内容。
- 元数据过滤:先通过元数据(如 "来源 = 内部文档")过滤,再做向量搜索,提升精度。
相似性度量方法
| 方法 | 公式 / 原理 | 适用场景 |
|---|---|---|
| 余弦相似度 | 计算向量夹角的余弦值,范围 -1, 1 | 文本语义匹配(常用) |
| 欧氏距离 | 计算向量空间中的直线距离 | 图像、数值型数据 |
| 点积 | 计算向量对应元素乘积之和 | 归一化后的向量(等价余弦) |
索引技术
索引是加速相似性搜索的关键 ------ 通过对向量进行预处理,避免 "暴力搜索"(遍历所有向量,速度慢)。
| 索引类型 | 原理 | 优势 | 劣势 |
|---|---|---|---|
| HNSW | 基于层次化小世界图,构建多层近邻图 | 搜索速度快、精度高 | 内存占用大 |
| IVF | 将向量聚类成多个 "倒排列表",先搜聚类中心 | 内存占用小、适合大规模数据 | 精度略低于 HNSW |
| FAISS | Facebook 开源,支持 HNSW/IVF 等多种索引 | 性能极致、优化完善 | 需结合其他数据库使用 |
| Annoy | 基于随机投影树,内存映射存储 | 内存占用极低、适合静态数据 | 构建索引慢 |
| ScaNN | Google 开源,通过各向异性量化优化 | 高精度、高吞吐 | 配置较复杂 |
向量数据库 vs 传统数据库
| 维度 | 向量数据库 | 传统数据库(MySQL/PostgreSQL) |
|---|---|---|
| 核心能力 | 相似性搜索(Top-K) | 精确匹配、范围查询 |
| 数据类型 | 高维向量 + 元数据 | 结构化 / 半结构化数据 |
| 索引方式 | HNSW/IVF 等向量索引 | B + 树、倒排索引 |
| 适用场景 | RAG 检索、推荐系统、以图搜图 | 事务处理、结构化查询 |
2.2 主流向量数据库
开源向量数据库
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Chroma | 轻量级,API 简单,适合快速原型 | 个人项目、Demo |
| FAISS | 性能极致,但需自行封装存储和元数据 | 大规模数据、性能敏感场景 |
| Milvus | 企业级,支持分布式、多种索引,功能全 | 生产环境、大规模部署 |
| Qdrant | 支持丰富的元数据过滤,API 友好 | 需复杂过滤的场景 |
| Weaviate | 结合知识图谱,支持语义搜索 | 知识增强型 RAG |
商业向量数据库
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| Pinecone | 全托管,无需运维,弹性扩展 | 企业级生产环境 |
| Zilliz Cloud | Milvus 的云服务版,提供托管和监控 | 不想自行运维 Milvus 的用户 |
| Weaviate Cloud | Weaviate 的云服务,结合知识图谱能力 | 知识密集型应用 |
2.3 向量存储优化
索引构建策略
- 批量构建:离线阶段一次性构建索引,适合静态数据(如历史文档),构建效率高。
- 增量构建:实时添加新向量时动态更新索引,适合动态数据(如新闻流),需平衡实时性与性能。
数据分片与分布式部署
- 当数据量达亿级时,通过分片(Sharding)将数据分布到多个节点,并行检索提升速度(如 Milvus、Qdrant 支持分布式)。
冷热数据分离
- 热数据(近期高频访问):使用高性能索引(如 HNSW),存内存。
- 冷数据(历史低频访问):使用低成本索引(如 IVF),存磁盘。
元数据设计与过滤优化
- 元数据设计:将常用过滤条件(如
source、date、category)作为元数据字段,避免全量扫描。 - 过滤优化:使用 "预过滤"(先过滤元数据,再搜向量)或 "后过滤"(先搜向量,再过滤元数据),根据数据量选择 ------ 元数据过滤后剩余数据少用 "预过滤",否则用 "后过滤"。
示例代码(使用 Chroma 存储向量)
python
import chromadb
from chromadb.utils import embedding_functions
# 初始化 Chroma 客户端(持久化存储)
client = chromadb.PersistentClient(path="./chroma_db")
# 使用 BGE 作为嵌入函数(需先安装 sentence-transformers)
embedding_func = embedding_functions.SentenceTransformerEmbeddingFunction(
model_name="BAAI/bge-small-zh-v1.5"
)
# 创建集合(类似表)
collection = client.create_collection(
name="my_documents",
embedding_function=embedding_func,
metadata={"hnsw:space": "cosine"} # 使用余弦相似度
)
# 添加文档(自动向量化并存储)
collection.add(
documents=["这是第一个文档片段", "这是第二个文档片段"],
metadatas=[{"source": "doc1"}, {"source": "doc2"}],
ids=["chunk1", "chunk2"]
)
# 相似性搜索
results = collection.query(
query_texts=["查询相关内容"],
n_results=2
)
print(results)3.查询预处理(在线阶段)
概念:用户输入的查询往往存在表述模糊、歧义、不完整、口语化等问题,直接用于检索会导致召回率低、相关性差。查询预处理通过对原始查询进行优化,使其更符合检索系统的 "理解习惯",从而大幅提升后续检索的准确性。
3.1 基础清洗
- 去除无关字符:特殊符号、多余空格、换行符、表情符号
- 错别字修正:使用
pycorrector、TextBlob等工具修正中文 / 英文错别字 - 格式统一:统一大小写、标点符号(中文全角转半角)
3.2 查询改写(Query Rewriting)
将模糊、口语化的查询转换为清晰、结构化的检索式。
- 示例 :
- 原始查询:"RAG 怎么弄?"
- 改写后:"RAG 系统的搭建步骤和核心技术是什么?"
- 实现方式 :
-
规则改写:基于模板匹配(适合常见问题)
-
大模型改写:用轻量大模型(如 Qwen-7B、Llama-3-8B)生成改写后的查询
-
示例代码(大模型改写):
pythonfrom openai import OpenAI client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama") def rewrite_query(query): prompt = f""" 将以下用户查询改写为更适合检索的清晰、具体的问题。 要求:保留核心语义,去除口语化表达,补充必要的上下文。 原始查询:{query} 改写后的查询: """ response = client.chat.completions.create( model="qwen:7b", messages=[{"role": "user", "content": prompt}], temperature=0.1 ) return response.choices[0].message.content.strip()
-
3.3 多查询生成(Multi-Query Generation)
一个查询生成多个不同表述的检索式,从多个角度召回相关内容,解决 "语义漂移" 问题。
- 示例 :
- 原始查询:"RAG 的优缺点"
- 生成的多查询:
- RAG 技术的优势和局限性是什么?
- 检索增强生成相比纯大模型有哪些好处和不足?
- RAG 系统在实际应用中的挑战和优势?
- 实现逻辑:让大模型基于原始查询生成 3-5 个不同角度的查询,然后分别进行检索,最后合并去重结果。
3.4 查询分类与路由
先判断查询类型,再决定后续处理流程:
- 事实性问题:直接检索知识库回答(如 "Python 的列表和元组有什么区别?")
- 推理问题:需要多步检索和推理(如 "如何用 RAG 搭建一个企业客服系统?")
- 闲聊问题:直接由大模型回答,无需检索
- 超出知识库范围:直接告知用户无法回答
4.混合检索
纯向量检索虽然擅长语义匹配,但存在以下问题:
- 语义漂移:查询和文档语义相似但关键词不同时,可能漏检
- 精确匹配差:对专有名词、代码、数字等精确内容的匹配效果差
- 长尾问题:对低频、小众内容的召回率低
混合检索核心架构
向量检索 + 关键词检索 + 元数据过滤,三者结合,兼顾语义匹配和精确匹配。
4.1 向量检索(语义匹配)
- 原理:将用户查询转换为向量,在向量数据库中搜索 Top-K 相似的 Chunk
- 优化点:
- 动态 Top-K:根据查询复杂度调整返回数量(简单问题返回 3-5 个,复杂问题返回 10-20 个)
- 相似度阈值过滤:过滤掉相似度低于阈值的结果(如余弦相似度 < 0.6)
- 多向量检索:一个 Chunk 生成多个向量(标题向量、摘要向量、全文向量),分别检索后合并
4.2 关键词检索(精确匹配)
-
原理:基于倒排索引,匹配查询和文档中的关键词
-
主流算法:BM25(比传统 TF-IDF 效果更好)
-
实现工具:Elasticsearch、Whoosh、LangChain 的
BM25Retriever -
示例代码(LangChain BM25 检索):
pythonfrom langchain.retrievers import BM25Retriever from langchain.text_splitter import RecursiveCharacterTextSplitter # 假设documents是离线阶段处理好的文档列表 text_splitter = RecursiveCharacterTextSplitter(chunk_size=512, chunk_overlap=50) splits = text_splitter.split_documents(documents) # 构建BM25检索器 bm25_retriever = BM25Retriever.from_documents(splits) bm25_retriever.k = 10 # 检索 bm25_results = bm25_retriever.invoke("RAG的分段策略")
4.3 元数据过滤(缩小检索范围)
-
原理:先通过元数据过滤掉不相关的文档,再进行向量 / 关键词检索
-
常用元数据字段:
source(来源)、date(时间)、category(类别)、author(作者) -
示例(Chroma 元数据过滤):
python# 只检索2024年发布的内部文档 results = collection.query( query_texts=["RAG的向量数据库选择"], n_results=10, where={"source": "内部文档", "date": {"$gte": "2024-01-01"}} )
4.4 结果融合
将向量检索和关键词检索的结果合并,去除重复项。常用融合算法:
- Reciprocal Rank Fusion (RRF):根据两个检索结果的排名计算综合得分,效果最好
- 加权求和:给向量检索和关键词检索分配不同的权重(如向量 0.7,关键词 0.3)
混合检索示例代码(LangChain)
python
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
# 初始化向量检索器
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
vectorstore = Chroma.from_documents(splits, embeddings, persist_directory="./chroma_db")
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
# 初始化BM25检索器(同上)
bm25_retriever = BM25Retriever.from_documents(splits)
bm25_retriever.k = 10
# 构建混合检索器(RRF融合)
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.6, 0.4]
)
# 混合检索
mixed_results = ensemble_retriever.invoke("RAG的分段策略")5. 检索结果重排序
概念: 混合检索返回的 Top-K 结果中,往往有很多不相关或相关性较低的内容。重排序使用一个更强大的交叉编码器(Cross-Encoder) ,对查询和每个检索结果进行逐对相似度打分,然后重新排序,将最相关的结果排在前面。
为什么不直接用交叉编码器做检索?
- 交叉编码器效果好,但速度慢(O (n) 复杂度),无法处理大规模数据
- 正确的做法是:先用快速的检索器(向量 + BM25)召回前 20-50 个结果,再用重排序模型精排,平衡速度和效果
主流重排序模型
| 模型 | 特点 | 适用场景 |
|---|---|---|
| BGE-Reranker | 开源中英双语效果最好,支持小 / 中 / 大版本 | 中文场景、私有化部署 |
| Cohere Rerank | API 调用便捷,效果稳定 | 企业级应用、快速原型 |
| CrossEncoder | Sentence-BERT 系列,支持多语言 | 通用场景 |
| Jina Reranker | 轻量级,速度快 | 低延迟场景 |
重排序实现与优化
示例代码(BGE-Reranker)
python
from sentence_transformers import CrossEncoder
# 加载重排序模型
reranker = CrossEncoder("BAAI/bge-reranker-small")
def rerank_results(query, results, top_n=5):
# 构建查询-文档对
pairs = [(query, doc.page_content) for doc in results]
# 计算相似度得分
scores = reranker.predict(pairs)
# 按得分排序
ranked_results = sorted(zip(scores, results), key=lambda x: x[0], reverse=True)
# 返回前top_n个结果
return [doc for score, doc in ranked_results[:top_n]]
# 使用
reranked_results = rerank_results("RAG的分段策略", mixed_results, top_n=5)优化策略
- 多级重排序:先用轻量模型(如 BGE-Reranker-small)粗排,再用重模型(如 BGE-Reranker-large)精排
- 结合元数据重排序:给权威来源、最新文档额外加分(如内部文档 + 0.1 分,2024 年文档 + 0.05 分)
- 批量处理:一次处理多个查询 - 文档对,提升吞吐量
6.上下文构建
**概念:**将重排序后的 Chunk 拼接成大模型可以理解的上下文,核心挑战是:
- 上下文窗口限制:大模型的上下文长度有限(如 GPT-3.5-turbo 是 16K,Llama-3-8B 是 8K)
- Lost in the Middle 现象:大模型对上下文开头和结尾的内容记忆更好,中间的内容容易被忽略
- 信息冗余:多个 Chunk 可能包含重复信息,浪费上下文窗口
6.1 核心技术
上下文拼接与组织
-
按相关性排序:将最相关的 Chunk 放在最前面,次相关的放在后面
-
添加元数据标注 :给每个 Chunk 添加来源信息,方便大模型引用和用户溯源
plaintext
[来源:RAG技术白皮书.pdf,第3页] 文本分段是RAG效果的关键环节,分段过大易丢失细节,过小易破坏语义连贯性。 [来源:LangChain官方文档,2024-01-15] 推荐使用RecursiveCharacterTextSplitter进行文本分段,它会按优先级尝试不同的分隔符。 -
添加逻辑分隔符 :用
---或\n\n分隔不同的 Chunk,让大模型清楚区分不同的信息块
上下文窗口管理
- 动态截断:计算上下文的 Token 数,超过大模型窗口限制时,截断相关性最低的 Chunk
- 滑动窗口:对于超长文档,使用滑动窗口逐段检索和生成
- 上下文压缩 :用轻量大模型对每个 Chunk 进行摘要,保留核心信息,减少 Token 占用
- 示例:LangChain 的
ContextualCompressionRetriever
- 示例:LangChain 的
解决 "Lost in the Middle"
- 将最相关的 Chunk 放在上下文的开头和结尾
- 重要信息重复出现(如在开头和结尾都提到核心结论)
- 使用结构化的上下文(如分点、编号),让大模型更容易提取信息
7. 提示词工程
7.1 RAG 专用提示词结构
一个好的 RAG 提示词应该包含以下 5 个部分:
- 系统角色定义:明确大模型的身份和任务
- 回答规则约束:核心是 "只能使用提供的上下文回答,不知道就说不知道"
- 上下文信息:检索到的相关内容
- 用户查询:用户的原始问题
- 输出格式要求:如分点回答、引用来源、使用 Markdown 格式
7.2 标准 RAG 提示词模板
python
你是一个专业的知识助手,只能基于以下提供的上下文内容回答用户的问题。
【回答规则】
1. 严格使用上下文中的信息,不得编造内容
2. 如果上下文中没有相关信息,直接回答"抱歉,我没有找到相关信息"
3. 回答要简洁明了,逻辑清晰,分点阐述
4. 重要信息请标注来源,格式为[来源:文档名,页码/日期]
【上下文】
{context}
【用户问题】
{query}
【回答】7.3 提示词优化技巧
-
明确禁止幻觉:反复强调 "不得编造内容"、"不知道就说不知道"
-
引用标注要求:强制要求大模型标注信息来源,方便后续校验
-
思维链引导 :对于复杂问题,要求大模型一步步推理
请先分析上下文内容,然后分步骤回答问题,每一步都要有依据。 -
格式约束:明确要求输出格式(如 Markdown、JSON),提升回答的可读性
-
示例引导:给一个正确的回答示例,让大模型模仿
8.大模型生成与结果后处理
8.1 大模型参数调优
RAG 场景下,大模型参数的设置原则是保证准确性和一致性:
- 温度(temperature):0-0.3,越低越准确,避免生成随机内容
- Top-p:0.1-0.5,限制生成的 Token 范围
- 最大生成长度:根据回答长度需求设置,一般不超过 2048 Token
8.2 流式输出
为了提升用户体验,建议使用大模型的流式输出功能,让用户可以实时看到回答的生成过程。
-
示例代码(OpenAI 流式输出): python
运行
pythonresponse = client.chat.completions.create( model="gpt-3.5-turbo", messages=messages, stream=True ) for chunk in response: if chunk.choices[0].delta.content: print(chunk.choices[0].delta.content, end="")
8.3 结果校验与幻觉检测
即使有 RAG,大模型仍然可能生成幻觉,需要进行结果校验:
-
引用校验:检查回答中的每个引用是否在上下文中存在
-
事实校验:用事实校验模型(如 FactScore)检查回答的准确性
-
自我检查 :让大模型自己检查回答是否符合上下文
plaintext
请检查以下回答是否严格基于提供的上下文,如果有编造的内容,请修改。 上下文:{context} 回答:{answer} 修改后的回答: -
多模型交叉验证:用多个不同的大模型生成回答,对比一致性
五、完整 RAG 系统全流程代码示例
以下是一个基于 LangChain+Chroma+BGE+Qwen 的完整 RAG 系统实现,整合了离线 + 在线所有核心环节:
python
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.vectorstores import Chroma
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain.retrievers import EnsembleRetriever, BM25Retriever
from langchain_community.llms import Ollama
from langchain.chains import RetrievalQA
from langchain.prompts import PromptTemplate
from sentence_transformers import CrossEncoder
# ---------------------- 离线阶段(已提前执行) ----------------------
# 1. 数据加载与清洗
loader = PyPDFLoader("RAG技术白皮书.pdf")
documents = loader.load()
# 2. 文本分段
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50,
separators=["\n\n", "\n", "。", " ", ""]
)
splits = text_splitter.split_documents(documents)
# 3. 向量化与存储
embeddings = HuggingFaceEmbeddings(model_name="BAAI/bge-small-zh-v1.5")
vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db"
)
vectorstore.persist()
# ---------------------- 在线阶段 ----------------------
# 1. 初始化检索器
vector_retriever = vectorstore.as_retriever(search_kwargs={"k": 10})
bm25_retriever = BM25Retriever.from_documents(splits)
bm25_retriever.k = 10
ensemble_retriever = EnsembleRetriever(
retrievers=[vector_retriever, bm25_retriever],
weights=[0.6, 0.4]
)
# 2. 初始化重排序模型
reranker = CrossEncoder("BAAI/bge-reranker-small")
# 3. 自定义检索链(包含重排序)
class RerankRetrievalQA(RetrievalQA):
def _get_docs(self, query):
# 混合检索
docs = self.retriever.invoke(query)
# 重排序
pairs = [(query, doc.page_content) for doc in docs]
scores = reranker.predict(pairs)
ranked_docs = sorted(zip(scores, docs), key=lambda x: x[0], reverse=True)
return [doc for score, doc in ranked_docs[:5]]
# 4. 初始化大模型
llm = Ollama(model="qwen:7b", temperature=0.1)
# 5. 构建提示词
prompt_template = """
你是一个专业的RAG技术助手,只能基于以下提供的上下文内容回答用户的问题。
【回答规则】
1. 严格使用上下文中的信息,不得编造内容
2. 如果上下文中没有相关信息,直接回答"抱歉,我没有找到相关信息"
3. 回答要简洁明了,逻辑清晰,分点阐述
4. 重要信息请标注来源,格式为[来源:{source}]
【上下文】
{context}
【用户问题】
{question}
【回答】
"""
PROMPT = PromptTemplate(
template=prompt_template,
input_variables=["context", "question"]
)
# 6. 构建RAG链
rag_chain = RerankRetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=ensemble_retriever,
return_source_documents=True,
chain_type_kwargs={"prompt": PROMPT}
)
# 7. 运行RAG系统
query = "RAG系统的文本分段策略有哪些?如何选择合适的分段大小?"
result = rag_chain.invoke(query)
print("回答:")
print(result["result"])
print("\n来源文档:")
for doc in result["source_documents"]:
print(f"- {doc.metadata['source']},第{doc.metadata['page']}页")六、RAG 面试题全集
1. 什么是 RAG?全称 & 核心思想
解答 RAG:Retrieval-Augmented Generation,检索增强生成。核心思想:
- 大模型存在知识截止日期、幻觉、私有知识缺失问题;
- 不直接让大模型凭空回答,先从私有知识库 / 外部文档中检索和问题相关的真实上下文;
- 将「用户问题 + 检索到的上下文」一起塞入大模型 Prompt;
- 大模型基于给定真实资料生成答案,实现:
- 减少幻觉
- 实时 / 私有知识问答
- 可溯源、可解释
2. RAG 与 微调(Fine-tune)的区别 & 选型
解答
表格
| 维度 | RAG | 微调 FT |
|---|---|---|
| 原理 | 实时检索外部知识,上下文约束生成 | 修改模型权重,内化知识 / 风格 |
| 知识更新 | 增量更新文档即可,实时生效 | 需重新训练,成本高、更新慢 |
| 数据要求 | 少量文档即可,无需标注 | 需要大量高质量标注数据 |
| 成本 | 低,推理阶段增加检索开销 | 算力 / 时间 / 人力成本极高 |
| 可控性 | 答案可溯源、内容可控 | 容易过拟合、难溯源 |
| 适用场景 | 私有知识库、文档问答、实时资讯 | 对话风格、任务对齐、特定能力强化 |
选型结论:
- 知识问答、企业知识库、文档咨询 → 优先 RAG
- 固定话术、角色定制、指令跟随强化 → 搭配微调
3. RAG 能解决大模型哪些核心问题?
- 幻觉问题:强制基于检索真实文档生成,减少编造;
- 知识时效性:模型训练数据有时间截止,RAG 接入最新文档;
- 私有域知识:企业内部文档、业务数据不泄露、不依赖模型预训练;
- 上下文长度限制:通过分段检索,突破单轮上下文窗口限制;
- 合规可追溯:回答内容来自指定文档,便于审计合规。
4. 原生大模型、RAG、Agent 的关系
- 原生大模型:仅靠预训练知识,能力上限固定;
- RAG:给模型喂参考资料,解决知识缺失;
- Agent:给模型规划 & 工具调用能力(检索、联网、代码、数据库);
实际业务:Agent + RAG 是主流,RAG 是 Agent 最核心的工具之一。
5. 标准 RAG 完整流程是什么?
两大阶段:离线预处理阶段 + 在线推理阶段
(1)离线数据预处理
- 文档加载:PDF/Word/Markdown/ 网页 / 数据库文本解析;
- 文本清洗:去空格、乱码、页眉页脚、特殊符号、无效内容;
- 文本分块(Chunk):长文档切分成固定长度片段;
- Embedding 向量化:将文本块转为向量;
- 向量入库:向量存入向量数据库,同时保存原始文本、元数据。
(2)在线问答推理
- 用户问题输入;
- 问题向量化:Query 生成 Embedding;
- 向量检索:向量库相似度匹配,召回 Top-K 文本块;
- 重排序(Rerank):对召回结果精细化打分,过滤无关内容;
- Prompt 拼接:指令模板 + 检索上下文 + 用户问题;
- LLM 生成:大模型输出答案;
- (可选)答案引用、溯源、格式整理。
6. 什么是文本分块(Chunking)?为什么必须分块?
解答 Chunking:将超长文档切分为固定长度、语义相对完整的短文本片段。
必要性:
- Embedding 模型有最大输入长度限制;
- 向量检索以「块」为最小单位,整块语义更完整;
- 避免上下文过长超出 LLM 窗口,降低推理成本;
- 提升检索精准度:细粒度片段更容易匹配局部问题。
常见分块方式
- 固定长度切分(滑动窗口):简单粗暴,通用;
- 语义分块:基于语义相似度分割,语义完整性更高;
- 规则分块:按标题、段落、章节、特殊分隔符分割;
- 层级分块:大块 + 小块混合(父子块 RAG)。
7. 分块大小如何选择?影响是什么?
- 块太小:语义碎片化,上下文不足,回答不完整;
- 块太大 :冗余信息多,检索噪声大,超出 LLM 上下文,推理慢;经验值
- 通用场景:300~800 token;
- 长文档 / 技术文档:500~1000 token;
- 短问答 / 话术:200~400 token。
8. 什么是 Embedding?工作原理
解答 Embedding:将自然语言文本 映射为低维稠密向量,语义相似的文本,向量空间距离更近。
- 输入:一段文本;
- 输出:固定长度浮点向量(如 768/1024/2048 维);
- 核心:语义向量化,让机器可计算文本相似度。
9. 常见向量相似度计算方式 & 区别
- **余弦相似度(Cosine)**最常用,忽略向量长度,只关注方向,适合文本 Embedding;
- **欧氏距离(Euclidean)**关注绝对距离,受向量模长影响大;
- **点积(Dot Product)**适合归一化后的向量,计算速度快;
工业级 RAG:统一使用余弦相似度。
10. 为什么检索到相似文本,实际却不相关?(检索失效)
常见原因:
- 语义鸿沟:Embedding 模型能力弱,字面相似、语义不相关;
- 分块不合理:切分破碎、语义断裂;
- Query 未优化:用户问题口语化、太短、歧义多;
- 向量库召回策略单一:仅向量检索,缺乏关键词补充;
- 领域不匹配:通用 Embedding 不适配垂直业务(医疗 / 法律 / 金融)。
11. 什么是 稀疏检索 & 稠密检索?区别
- 稠密检索(Dense) :基于 Embedding 向量匹配,语义级召回,擅长语义同义、改写问题;
- 稀疏检索(Sparse) :基于关键词匹配(BM25、TF-IDF),字面匹配,擅长专有名词、数字、专业术语;
业界最优方案:混合检索(BM25 + 向量检索),互补短板。
12. 什么是 Rerank 重排序?作用是什么
解答 Rerank 重排序:向量检索粗召回 Top-K(如 10~20 条)后,使用轻量打分模型对所有召回文档和问题做精细语义匹配打分,重新排序、过滤低相关内容。
核心作用:
- 剔除向量召回的噪声、弱相关文档;
- 提升上下文质量,减少 LLM 负担;
- 大幅提升 RAG 答案准确率;
- 成本低:Rerank 模型小、推理快。
典型链路:向量召回Top20 → Rerank 打分筛选Top5 → 送入LLM
13. 常用向量数据库有哪些?选型对比
主流向量库
- 开源轻量:FAISS、Chroma、Qdrant、Milvus Lite
- 企业级分布式:Milvus、Weaviate、PGVector(Postgres 插件)
- 云服务:阿里云向量检索、腾讯云向量库、Pinecone
选型原则
- 小体量、快速落地:Chroma / Qdrant / FAISS
- 大数据量、高并发、持久化:Milvus
- 原有 PG 数据库生态:PGVector
14. 向量库索引类型?作用
- 暴力检索(FLAT):全量比对,精准、慢,小数据量用;
- ANN 近似最近邻索引 :牺牲一点点精度,换百倍提速,工业标配;如:IVF、HNSW、ANNOY,HNSW 是目前 RAG 最常用索引。
15. 向量数据库和传统数据库区别
- 传统库:擅长结构化数据、精准条件查询;
- 向量库:擅长亿级向量快速相似度检索,专为高维向量优化;
- 向量库一般同时支持:向量检索 + 标量过滤(时间、文档来源、权限)。
16. 基础 RAG 有哪些缺点?
- 单轮向量检索语义能力有限;
- 上下文拼接过长,LLM 忽略关键信息;
- 无法处理复杂多轮、拆分问题;
- 无法理解文档层级、表格、图片、复杂结构;
- 容易引入无关上下文,造成干扰。
17. 主流高级 RAG 方案 原理简述
- Hybrid RAG 混合检索向量检索 + BM25 关键词检索融合,解决纯语义丢失关键词问题;
- Query 改写 / 扩展对用户问题做:同义改写、拆分、补充关键词、扩写,提升召回;
- Rerank 重排序粗召回 + 精排,过滤噪声;
- 上下文压缩 / 摘要对检索内容精简,剔除冗余,缩短上下文;
- **层级 RAG(父子块)**大块存概要,小块存细节,先搜大块定位章节,再搜小块精准内容;
- 多模态 RAG图文解析、表格解析、OCR + 向量检索;
- Self-RAG / 自适应 RAG模型自行判断是否需要检索、检索几轮、是否需要重查。
18. 多轮对话下的 RAG 如何实现?
难点:历史对话有上下文,单 Question 无法代表真实意图。方案:
- 问题压缩 & 重构 :将历史对话 + 当前问题,改写为独立完整问题;
- 用重构后的问题做向量检索;
- Prompt 同时带入「历史对话 + 检索文档 + 当前问题」。
19. 如何处理表格 / 图片 / PDF 复杂文档 RAG?
- PDF:版式解析、去除水印、按章节分块;
- 表格:表格结构化解析,转为 Markdown/JSON 再分块嵌入;
- 图片:OCR 提取文字 + 多模态 Embedding;
- 版式复杂文档:使用专业文档解析器(LayoutLM、PDF-Parse)。
20. RAG 场景下 Prompt 模板核心要素
必备组成:
- 角色指令:你是专业知识库问答助手;
- 约束规则:只能基于参考资料回答,资料没有就说不知道,禁止编造;
- 参考上下文:RAG 检索回来的片段;
- 用户问题;
- 输出要求:简洁、分点、标注来源、禁止冗余。
21. 如何抑制 RAG 幻觉?
- Prompt 强约束:无依据内容禁止回答、明确告知局限性;
- 提升检索质量:混合检索 + Rerank,保证上下文相关;
- 答案溯源:输出时标注引用文档片段;
- 上下文精简:过滤无关噪声,减少模型混淆;
- 事实校验:Agent 模式下二次检索验证关键信息。
22. RAG 性能瓶颈在哪里?
- Embedding 推理速度(大批量文档入库慢);
- 向量库检索延迟(高并发下);
- Rerank 模型推理耗时;
- LLM 生成速度;
- 上下文过长导致推理 Token 成本高。
23. 优化 RAG 推理速度的手段
- Embedding/Rerank 模型量化、蒸馏、部署加速(TensorRT/ONNX);
- 向量库合理建索引(HNSW),加缓存;
- 限制召回数量,精简上下文;
- 高频问题缓存问答结果;
- 离线预计算所有文档向量,线上只做检索。
24. RAG 如何做效果评估?
自动指标
- 检索层:召回率 Recall、精准率 Precision、MRR;
- 生成层:RAGAS、TruLens、BLEU、ROUGE、语义相似度;人工评估
- 答案准确性、完整性、是否幻觉、引用正确性。
25. 什么是上下文窗口污染?如何解决
定义:检索大量无关、冗余上下文塞进 Prompt,模型被干扰,回答跑偏、遗漏重点。解决:
- Rerank 过滤低相关内容;
- 上下文压缩、摘要;
- 限制最大上下文长度;
- 层级检索缩小范围。
26. 垂直领域 RAG 效果差怎么优化?
- 替换领域专属 Embedding 模型(法律 / 医疗 / 金融);
- 优化分块策略,贴合行业文档结构;
- 加入行业词典、专有名词增强稀疏检索;
- 微调领域 Rerank 模型;
- 清洗高质量领域语料,优化文档质量。
27. RAG 安全与权限怎么做?
- 文档打标签:部门、权限、用户角色;
- 向量检索时附加标量过滤,只召回当前用户有权限的文档;
- 敏感内容脱敏,入库前屏蔽隐私数据。