摘要
本文系统介绍了大语言模型格式化生成技术,涵盖Output Parsers、LlamaIndex结构化输出、提示工程技巧及Function Calling等核心方法,并对比了提示词约束、JSON模式、控制生成等RAG场景下的格式优化实现路径。
1. 格式化生产
从大语言模型(LLM)那里获得一段非结构化的文本在应用中常常不满足实际需求。为了实现更复杂的逻辑、与外部工具交互或以用户友好的方式展示数据,需要模型能够输出具有特定结构的数据,例如 JSON 或 XML。接下来将讨论实现格式化生成的几种主流方法,包括LangChain、LlamaIndex 等框架内置的解决方案,不依赖框架的实现思路,以及一种更强大的技术------Function Calling。
1.1. 为什么需要格式化生成?
先来看几个具体的应用场景:
- RAG 驱动的电商客服:当用户询问"推荐几款适合程序员的键盘"时,我们希望 LLM 返回一个包含产品名称、价格、特性和购买链接的 JSON 列表,而不是一段描述性文字,以便前端直接渲染成商品卡片。
- 自然语言转 API 调用 :用户说"帮我查一下明天从上海到北京的航班",系统需要将这句话解析成一个结构化的 API 请求,如
{"departure": "上海", "destination": "北京", "date": "2025-07-18"}。 - 数据自动提取:从一篇新闻文章中,自动抽取出事件、时间、地点、涉及人物等关键信息,并以结构化形式存入数据库。
在这些场景中,格式化生成是连接 LLM 的自然语言理解能力和下游应用程序的程序化逻辑之间的关键。
1.2. 格式化生成的实现方法
1.2.1. Output Parsers(输出解析器)
LangChain 提供了多种开箱即用的解析器,例如:
- StrOutputParser:最基础的输出解析器,它简单地将 LLM 的输出作为字符串返回。
- JsonOutputParser:可以解析包含嵌套结构和列表的复杂 JSON 字符串。
- PydanticOutputParser:通过与 Pydantic 模型结合,可以实现对输出格式最严格的定义和验证。
接下来通过一个具体的代码示例,重点分析 PydanticOutputParser 的工作原理。它通过将用户定义的 Pydantic 数据模型转换为详细的格式指令,并注入到提示词中,来引导 LLM 生成严格符合该数据结构的 JSON 输出。最后再将模型返回的 JSON 字符串安全地解析为 Pydantic 对象实例。
# (此处省略了导入和 LLM 初始化代码)
# 1. 定义期望的数据结构
class PersonInfo(BaseModel):
"""用于存储个人信息的数据结构。"""
name: str = Field(description="人物姓名")
age: int = Field(description="人物年龄")
skills: List[str] = Field(description="技能列表")
# 2. 基于 Pydantic 模型,创建解析器
parser = PydanticOutputParser(pydantic_object=PersonInfo)
# 3. 创建提示模板,注入格式指令
prompt = PromptTemplate(
template="请根据以下文本提取信息。\n{format_instructions}\n{text}\n",
input_variables=["text"],
partial_variables={"format_instructions": parser.get_format_instructions()},
)
# 4. 创建处理链 (假定 llm 已被初始化)
chain = prompt | llm | parser
# 5. 执行调用
text = "张三今年30岁,他擅长Python和Go语言。"
result = chain.invoke({"text": text})
# 6. 打印结果
print(result)
# name='张三' age=30 skills=['Python', 'Go语言']Copy to clipboardErrorCopied- 定义数据模型 :使用 Pydantic 的
BaseModel定义PersonInfo类,这不仅是一个 Python 对象,更是一个清晰的数据结构规范(Schema)。Field中的description描述文本将直接作为指令提供给大模型,因此其表述需要清晰准确。 - 生成格式指令 :当
PydanticOutputParser实例化后,其get_format_instructions()方法会执行以下操作:
- 调用 Pydantic 模型的
.model_json_schema()方法,提取出该数据结构的 JSON Schema 定义。 - 对该 Schema 进行简化,并将其嵌入到一个预设的、指导性的提示模板中。这个模板明确要求 LLM 输出一个符合该 Schema 的 JSON 对象。
- 构建并执行调用链 :通过 LangChain 表达式语言(LCEL),将
prompt、llm和parser链接起来。当调用链被触发时:
prompt会将用户输入(text)和上一步生成的格式指令(format_instructions)组合成最终的提示,发送给llm。llm根据这个包含严格格式要求的提示,生成一个 JSON 格式的字符串。
- 解析与验证 :
PydanticOutputParser接收到 LLM 返回的字符串后,会执行一个两步解析过程:
- 首先,它继承自
JsonOutputParser,会将 LLM 输出的文本字符串解析成一个 Python 字典。 - 然后,最关键的一步,它会使用
PersonInfo.model_validate()方法,用定义的数据模型来验证这个字典。如果字典的键和值类型都符合PersonInfo的定义,解析器就会返回一个PersonInfo的实例对象;如果验证失败,则会抛出一个OutputParserException异常。
1.2.2. LlamaIndex 的输出解析
LlamaIndex 的输出解析与生成过程紧密结合,主要体现在两大核心组件中,分别是响应合成(Response Synthesis)和结构化输出(Structured Output)。
在 RAG 流程中,检索器召回一系列相关的文本块(Nodes)后,并不是简单地将它们拼接起来。响应合成器(Response Synthesizer)负责接收这些文本块和原始查询,并以一种更智能的方式将它们呈现给 LLM 以生成最终答案。例如,它可以逐块处理信息并迭代地优化答案(refine 模式),或者将尽可能多的文本块压缩进单次 LLM 调用中(compact 模式)。这个阶段的默认目标是生成一段高质量的文本回答。
当需要 LLM 返回结构化数据(如 JSON)而非纯文本时,LlamaIndex 主要使用 Pydantic 程序(Pydantic Programs) 。这与 LangChain 的 PydanticOutputParser 思想一致:
- 定义 Schema:开发者首先定义一个 Pydantic 模型,明确所需输出的数据结构、字段和类型。
- 引导生成:LlamaIndex 会将这个 Pydantic 模型转换成 LLM 能理解的格式指令。如果底层的 LLM 支持 Function Calling,LlamaIndex 会优先使用该功能以获得更可靠的结构化输出。如果不支持,它会回退到将 JSON Schema 注入到提示词中的方法。
- 解析验证:最后,LLM 返回的输出会被自动解析并用 Pydantic 模型进行验证,确保其类型和结构完全正确,最终返回一个 Pydantic 对象实例。
1.2.3. 不依赖框架的简单实现思路
如果不想依赖特定的框架,也可以通过提示工程的技巧来实现格式化生成。主要思路是在提示中给出清晰、明确的指令和示例。以下是一些实用技巧:
- 明确要求 JSON 格式:在提示中直接、强硬地要求模型"必须返回一个 JSON 对象"、"不要包含任何解释性文字,只返回 JSON"。
- 提供 JSON Schema:在提示中给出你想要的 JSON 对象的模式(Schema),描述每个键的含义和数据类型。
- 提供 few-shot 示例:给出 1-2 个"用户输入 -> 期望的 JSON 输出"的完整示例,让模型学习输出的格式和风格。
- 使用语法约束 :对于一些本地部署的开源模型(如通过
llama.cpp运行的模型),可以使用 GBNF (GGML BNF) 等语法文件来强制约束模型的输出,确保其生成的每一个 token 都严格符合预定义的 JSON 语法。这是最严格也是最可靠的非 Function Calling 方法。
1.3. Function Calling技术
Function Calling(或称 Tool Calling)是近年来 LLM 领域的一个重要进展,提升了模型与外部世界交互和生成结构化数据的能力。
1.3.1. Function Calling概念与工作流程
Function Calling 的本质是一个多轮对话流程,让模型、代码和外部工具(如 API)协同工作。其核心工作流如下:
- 定义工具:首先,在代码中以特定格式(通常是 JSON Schema)定义好可用的工具,包括工具的名称、功能描述、以及需要的参数。
- 用户提问:用户发起一个需要调用工具才能回答的请求。
- 模型决策 :模型接收到请求后,分析用户的意图,并匹配最合适的工具。它不会直接回答,而是返回一个包含
tool_calls的特殊响应。这个响应相当于一个指令:"请调用某某工具,并使用这些参数"。 - 代码执行 :应用接收到这个指令,解析出工具名称和参数,然后在代码层面实际执行这个工具(例如,调用一个真实的天气 API)。
- 结果反馈 :将工具的执行结果(例如,从 API 获取的真实天气数据)包装成一个
role为tool的消息,再次发送给模型。 - 最终生成:模型接收到工具的执行结果后,结合原始问题和工具返回的信息,生成最终的、自然的语言回答。
Function Calling 的实现原理可以做一个区分:它其实不是模型在主动执行代码,而是由模型充当"强人工智能指挥调度"。简单来说,这是一种让大语言模型与世界交互的标准化"握手"协议。
核心本质:不是模型在执行,而是以结构化指令调用
一个关键点需要先明确:大语言模型本身并不能直接运行代码 。它的核心能力是理解和生成文本。所以,Function Calling 并非指模型去执行了你的函数,而是模型在执行它的"本职工作"------生成一段结构化文本。它是一个"请求-响应 "的标准化模式,模型只负责根据用户输入,精确地告诉你 "我判断现在需要调用你定义的 X 工具,并且我应该传递 Y 和 Z 这些参数给它"。
标准化接口:模型的"地图",告诉AI"我可以去哪里"
为了让模型知道它能调用哪些"工具",开发者需要通过API向模型提供一个标准化的"工具清单"。这是整个流程的起点。这份清单通常会使用 JSON Schema 格式定义(现在许多云平台已统一采用OpenAI格式)。
假设你需要一个查询天气的功能,工具清单会这样描述:
{
"tools": [{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "获取指定地点的当前天气状况",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如: 北京"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位"
}
},
"required": ["location", "unit"]
}
}
}]
}这里的 description 对模型决策至关重要,它描述了工具的价值;而 parameters(location, unit)则定义了调用它所需的精确"要素"。
1.3.2. Function Calling 实践
交互流程:一次标准的"请求-响应"闭环。有了清单,AI的指挥调度就可以开始了。一次完整的Function Calling交互遵循一个三步循环模式。
第1步:提出请求 (Request): 你的应用程序将用户问题 和上一步定义好的tools清单一同发给AI模型。
例如,用户问:"请问北京现在的实时温度和华氏度是多少?"
**第2步:解析与调度 (Parse & Dispatch):**AI模型接收请求后,会结合提示词进行判断:
-
理解意图:判断是否需要调用外部工具。
-
匹配工具 :在提供的工具清单中,找到最符合需求的那一个 (
get_current_weather)。 -
提取参数 :从自然语言中提取出结构化的参数 (
{"location": "北京", "unit": "fahrenheit"})。
模型随后会返回一个结构化的响应,通常是JSON格式。{
"tool_calls": [{
"id": "call_123",
"function": {
"name": "get_current_weather",
"arguments": "{"location":"北京", "unit":"fahrenheit"}"
}
}]
}
**第3步:执行与回应 (Execute & Respond):**你的后端程序负责执行这一部分:
- 解析响应 :获取到模型返回的
name及其arguments。 - 执行真实函数 :在你的代码中,去调用真正能查询天气的API(如
weather_api.get_current("北京", "fahrenheit"))。 - 将结果回填 :把API返回的真实数据(如
"72°F, sunny"),作为新消息再次发给AI模型。{ "role": "tool", "tool_call_id": "call_123", "content": "当前北京天气晴朗,温度是72°F。" }
- 最终回复:AI模型收到工具的真实执行结果后,会组织成最终的、自然、友好的语言回复给用户
1.3.3. Function Calling 的优势
相比于单纯通过提示工程"请求"模型输出 JSON,Function Calling 的优势在于:
- 可靠性更高:这是模型原生支持的能力,相比于解析可能格式不稳定的纯文本输出,这种方式得到的结构化数据更稳定、精确。
- 意图识别:它不仅仅是格式化输出,更包含了"意图到函数的映射"。模型能根据用户问题主动选择最合适的工具。
- 与外部世界交互:它是构建能执行实际任务的 AI 代理(Agent)的核心基础,让 LLM 可以查询数据库、调用 API、控制智能家居等。
2. 格式优化相关问题思考
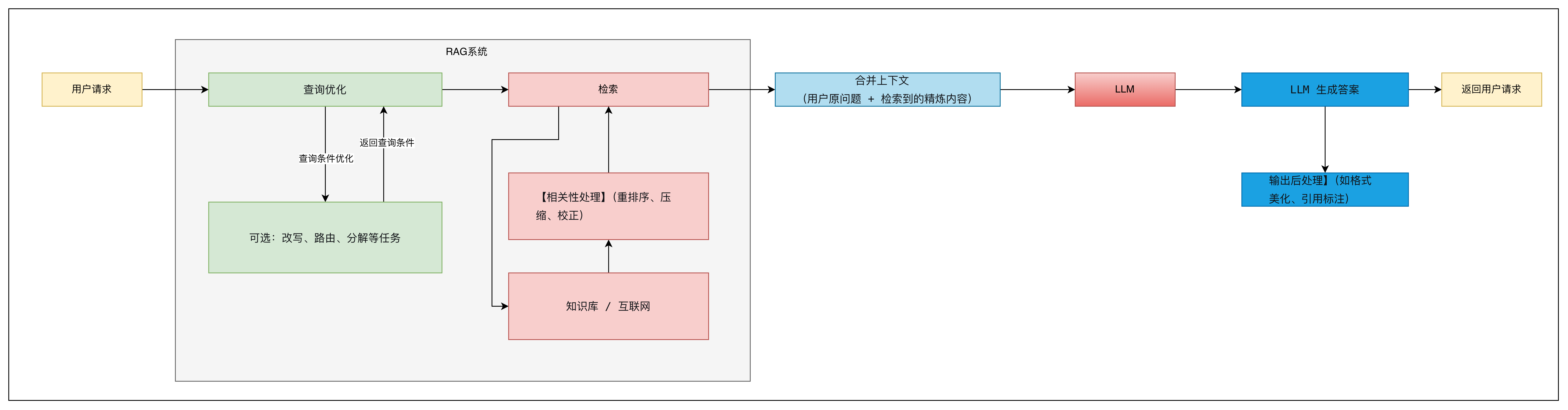
在RAG系统中通常指的是对LLM生成的原始文本答案,进行结构化、格式化或规范化处理 ,使其变成符合业务要求的最终输出(例如JSON、Markdown表格、带引用的带格式文本、XML等)。下面我来系统解释它的主要作用 和常见实现方式。
2.1. 格式生成的主要作用
|------------------|------------------------------------------------------------------------------------------------|
| 作用 | 说明 |
| 1. 便于程序解析与集成 | 下游系统(如前端、移动App、自动化流程)需要机器可读的结构化数据,而不是自由文本。例如:输出{"answer": "...", "sources": [...]}方便直接渲染。 |
| 2. 提升用户体验 | 用户看到的答案可以有清晰的分段、列表、表格、引用链接、加粗强调等,而不是一大段无格式的纯文本。 |
| 3. 约束LLM输出范围 | 通过格式约束(如只允许输出JSON),可以避免LLM产生自由发挥的废话、问候语、额外解释,从而降低幻觉和token浪费。 |
| 4. 支持多轮/工具调用 | 在Agent场景中,LLM需要输出可执行的函数调用参数(如{"action": "query_weather", "params": {"city": "北京"}}),必须严格格式化。 |
| 5. 便于审计与溯源 | 强制输出包含引用来源的格式(如[1]),让用户知道答案依据,提高可信度。 |
2.2. RAG格式生成的实现方式
常见实现方式分为两大类:约束生成 和后处理解析。实际系统中常组合使用。
2.2.1. 提示词约束(最常用)
直接在系统提示或用户提示中明确要求输出格式,配合few-shot示例。示例:
请根据以下文档回答问题。你必须只输出一个JSON对象,格式如下:
{"answer": "你的答案", "sources": ["来源1", "来源2"]}
不要输出任何其他文字。优点 :简单,与模型无关。
缺点:模型可能不遵守(尤其小模型);格式错误时需要重试。
2.2.2. 输出解析器(Output Parser)
使用LangChain、LlamaIndex等框架提供的PydanticOutputParser、StructuredOutputParser等组件。工作流程:
- 定义Pydantic模型(如
class Answer(BaseModel): answer: str; sources: List[str]) - 解析器自动生成提示词约束,并解析LLM输出为对象。
- 如果解析失败,可以自动重试或抛出异常。
示例(LangChain):
parser = PydanticOutputParser(pydantic_object=Answer)
prompt = PromptTemplate(
template="...\n{format_instructions}\n...",
partial_variables={"format_instructions": parser.get_format_instructions()}
)优点 :结构化强,异常好处理。
缺点:依赖于框架,对模型格式遵循能力要求较高。
2.2.3. JSON模式 / JSON Mode
很多LLM API(如OpenAI、Anthropic、本地VLLM)支持response_format={"type": "json_object"}强制输出合法JSON。示例:
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "..."}],
response_format={"type": "json_object"}
)此时你必须在提示词中明确要求输出JSON,API会保证返回的字符串可被json.loads解析。
优点 :保证语法正确,降低解析失败率。
缺点:只保证JSON语法,不保证字段结构符合预期(仍需后验证)。
2.2.4. 函数调用 / Tool Call
通过LLM的function calling能力,让LLM输出结构化参数。本质上是一种最严格的格式生成。示例(OpenAI):
tools = [{
"type": "function",
"function": {
"name": "answer_question",
"parameters": {
"type": "object",
"properties": {
"answer": {"type": "string"},
"sources": {"type": "array", "items": {"type": "string"}}
},
"required": ["answer", "sources"]
}
}
}]LLM会返回tool_calls,其中的参数就是结构化JSON。
优点 :可靠性极高,原生支持多轮工具调用。
缺点:需要模型支持function calling;每次调用的token消耗略高。
2.2.5. 正则/模板后处理
如果LLM输出格式不稳定,可以先用正则表达式或字符串模板提取关键字段,然后手动组装成目标格式。
示例 :LLM输出"答案:xxx。来源:1 文档A",后处理解析出{"answer": "xxx", "sources": ["文档A"]}。
优点 :兼容任何模型,灵活。
缺点:对复杂结构化输出(如嵌套JSON)维护困难,容易出错。
2.2.6. 控制生成(Grammar / Guidance)
使用guidance、lmql、outlines等库,通过语法规则强制LLM按模板生成。这在本地模型(如Llama)上特别有效。示例(outlines):
from outlines import models, generate
model = models.transformers("microsoft/phi-2")
generator = generate.json(model, Answer)
result = generator("根据文档回答问题...")优点 :100%符合格式,不产生无效token。
缺点:通常只适用于本地模型,对闭源API不适用。