RAG与Agent性能调优:16.如何科学调节切片长度与滑动窗口,结合倒排索引与向量锁引对比优化
Gitee地址:https://gitee.com/agiforgagaplus/OptiRAGAgent
文章详情目录:RAG与Agent性能调优
上一节:第15节:政府文档结果总是遗漏关键点?构建高精度水直领域检索系统
下一节:
如何自动化评估切片策略的索引方式?
在构建RAG系统的时候,文本切片策略和索引方式都是影响性能的重要因素之一。当切片长度或索引设置不合理时,可能导致
- 检索不完整,上下文割裂
- 冗于信息过多,影响生成质量
- 语意表达不完整,影响向量匹配效果
因此,我们需要评估RAG系统的整体能力和每一部分的能力
使用RAGAS进行系统评估
RAGAS简介与核心指标
其是一个专为RAG系统设计和评估的工具,提供了以下核心指标
- Answer Relevance:生成的答案是否与问题相关?
- Context Precision:检索到的上下文是否相关?
- Context Recall:检索到的上下文是否包含回答所需要的信息
- Faithfulness:生成答案是否基于检索到的内容?
测评流程
- 构建测试数据集:准备一组问题,真实答案,检索到的上下文
- 运行评估:使用RAGAS工具计算各项指标
- 分析结果: 根据评估结果调整切片策略、索引策略等优化系统性能
实战
%pip install --upgrade ragas
from ragas.metrics import answer_relevancy, context_precision, context_recall, faithfulness
from ragas import evaluate
import pandas as pd
from datasets import Dataset
# 构建测试数据集
data = {
"question": ["RAG 系统如何优化切片策略?", "向量索引和倒排索引有什么区别?"],
"answer": ["可以通过 RAGAS 测评工具评估不同切片策略的性能,优化切片长度和滑动窗口配置。", "向量索引基于语义匹配,而倒排索引基于关键词匹配。"],
"contexts": [["RAGAS 提供了多种评估指标,如 Answer Relevance、Context Precision 等。", "切片长度和滑动窗口配置对检索性能有重要影响。"], ["倒排索引适用于关键词匹配,而向量索引适用于语义匹配。", "向量索引需要更多计算资源,但能捕捉语义相似性。"]],
"ground_truth": ["RAGAS 提供了多种评估指标,如 Answer Relevance、Context Precision 等。切片长度和滑动窗口配置对检索性能有重要影响。", "倒排索引适用于关键词匹配,而向量索引适用于语义匹配。向量索引需要更多计算资源,但能捕捉语义相似性。"]
}
dataset = Dataset.from_pandas(pd.DataFrame(data))
# 执行评估
result = evaluate(
dataset,
metrics=[answer_relevancy, context_precision, context_recall, faithfulness]
)
print(result)对比分析:倒排索引 vs 向量索引
倒排索引(Inverted Index)
适用场景:关键词匹配、快速检索
- ✅ 高效检索
- ✅ 支持布尔查询
- ❌ 语义理解弱
- ❌ 对关键词依赖强
向量索引( Vector Index)
适用场景:语义匹配、模糊检索
- ✅ 语义理解能力强
- ✅ 支持模糊匹配
- ❌ 计算成本高
- ❌ 对切片长度敏感
实验对比
# 安装必要的库
%pip install ragas pandas datasets sentence-transformers scikit-learn
import pandas as pd
import numpy as np
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
from sentence_transformers import SentenceTransformer
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import faithfulness, answer_relevancy, context_recall, context_precision
import torch
# 1. 构建文档库 (Corpus)
# 我们创建一个小型的知识库,检索器将从这里寻找答案。
corpus = [
"RAGAS是一个评估检索增强生成 (RAG) 系统性能的框架。",
"RAGAS提供了多种评估指标,例如答案相关性 (Answer Relevance) 和上下文精度 (Context Precision)。",
"优化切片策略对提升检索性能至关重要,包括调整块大小 (chunk size) 和重叠 (overlap)。",
"向量索引利用嵌入技术,能捕捉文本的语义相似性,适合处理概念匹配。",
"倒排索引通过关键词映射文档,检索速度快,非常适合关键词搜索。",
"语义搜索不依赖于精确的关键词,而是理解查询背后的意图。",
]
# 2. 实现两种检索策略
#策略一:倒排索引 (Inverted Index) - 基于 TF-IDF
# 这是一个经典的关键词匹配方法。
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(corpus)
feature_names = vectorizer.get_feature_names_out()
def retrieve_with_inverted_index(query, top_k=2):
"""使用倒排索引 (TF-IDF) 检索上下文"""
query_vector = vectorizer.transform([query])
scores = cosine_similarity(query_vector, tfidf_matrix).flatten()
# 获取得分最高的 top_k 个文档的索引
top_k_indices = np.argsort(scores)[-top_k:][::-1]
return [corpus[i] for i in top_k_indices if scores[i] > 0]
# 策略二:向量索引 (Vector Index) - 基于 Sentence Transformers
# 这是一个现代的语义匹配方法。
model = SentenceTransformer('all-MiniLM-L6-v2')
corpus_embeddings = model.encode(corpus, convert_to_tensor=True)
######### GPU Only ############
# def retrieve_with_vector_index(query, top_k=2):
# """使用向量索引 (Sentence Transformer) 检索上下文"""
# query_embedding = model.encode(query, convert_to_tensor=True)
# # 计算余弦相似度
# scores = cosine_similarity(query_embedding.unsqueeze(0), corpus_embeddings)[0]
# # 获取得分最高的 top_k 个文档的索引
# top_k_indices = np.argsort(scores)[-top_k:][::-1]
# return [corpus[i] for i in top_k_indices]
### CPU support ###
def retrieve_with_vector_index(query, top_k=2):
"""使用向量索引 (Sentence Transformer) 检索上下文"""
query_embedding = model.encode(query, convert_to_tensor=True)
# 使用 torch 计算余弦相似度
scores = torch.nn.functional.cosine_similarity(
query_embedding.unsqueeze(0), corpus_embeddings, dim=1
).cpu().numpy()
top_k_indices = np.argsort(scores)[-top_k:][::-1]
return [corpus[i] for i in top_k_indices if scores[i] > 0]
# 3. 构建对比测试数据集
# 我们设计两个问题:一个关键词明确,一个偏向语义。
questions = [
"RAGAS有哪些评估指标?", # 问题1: 关键词"RAGAS"和"指标"很明确
"如何根据意思找到相关的文档?" # 问题2: 语义化问题,没有直接的关键词
]
ground_truths = [
"RAGAS提供了多种评估指标,如答案相关性 (Answer Relevance) 和上下文精度 (Context Precision)。",
"语义搜索或向量索引可以根据文本的含义而非精确关键词来查找文档。"
]
# 为每个问题生成两种检索结果和对应的答案
data_samples = []
for i, q in enumerate(questions):
# 使用倒排索引
inverted_contexts = retrieve_with_inverted_index(q)
# 使用向量索引
vector_contexts = retrieve_with_vector_index(q)
# 模拟生成器基于不同上下文生成的答案
inverted_answer = f"根据关键词检索,RAGAS的指标包括:{inverted_contexts[0]}" if inverted_contexts else "未找到相关信息。"
vector_answer = f"根据语义理解,要通过意思找到文档,可以使用向量索引和语义搜索。相关信息:{vector_contexts[0]}" if vector_contexts else "未找到相关信息。"
# 将倒排索引的结果添加到数据集
data_samples.append({
"question": q,
"contexts": inverted_contexts,
"answer": inverted_answer,
"ground_truth": ground_truths[i],
"retrieval_method": "Inverted Index"
})
# 将向量索引的结果添加到数据集
data_samples.append({
"question": q,
"contexts": vector_contexts,
"answer": vector_answer,
"ground_truth": ground_truths[i],
"retrieval_method": "Vector Index"
})
# 转换为 Hugging Face Dataset
dataset = Dataset.from_list(data_samples)
# 4. 执行评估
# 注意:Ragas的评估也依赖大语言模型,请确保你已配置好相应的API Key (如OpenAI)
# os.environ["OPENAI_API_KEY"] = "YOUR_API_KEY"
result = evaluate(
dataset,
metrics=[
context_precision, # 上下文精度: 检索到的上下文与问题的相关度
context_recall, # 上下文召回率: 检索到的上下文是否覆盖了真实答案
faithfulness, # 忠实度: 答案是否忠实于检索到的上下文
answer_relevancy, # 答案相关性: 答案与问题的相关度
],
)
# 5. 打印和分析结果
# 获取 Ragas 的评估结果
df_metrics = result.to_pandas()
# 提取原始数据中的元信息(如 retrieval_method、question 等)
df_original = pd.DataFrame(data_samples)
# 合并两个 DataFrame(按行索引)
df_combined = pd.concat([df_original.reset_index(drop=True), df_metrics.reset_index(drop=True)], axis=1)
# 打印需要的列
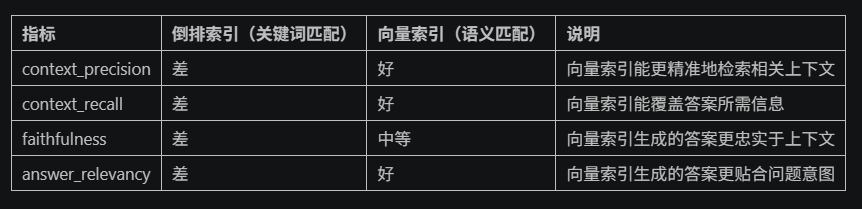
print(df_combined[[
"retrieval_method", "question",
"context_precision", "context_recall",
"faithfulness", "answer_relevancy"
]])
建议
- 扩大测试数据集:增加更多问题,验证淡化能力
- 调整topK检索数量:尝试不同topK的值,看是否影响评估结果
- 使用更强大的嵌入模型
- 可视化结果对比:用柱状图或雷达图对比不同方法在各项指标上的表现
如何科学设置切片长度与滑动窗口?
切片长度的影响
- 过短:信息不完整,影响语义表达
- 过长:检索效率低,影响生存速度
滑动窗口的作用
- 避免上下文割裂
- 提升语义连续性
实战:自动测试不同切片策略
import pandas as pd
import numpy as np
from datasets import Dataset
from ragas import evaluate
from ragas.metrics import answer_relevancy, context_precision, context_recall, faithfulness
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 模拟文档内容
text = """
RAGAS 提供了多种评估指标,如 Answer Relevance、Context Precision 等。
切片长度和滑动窗口配置对检索性能有重要影响。
可以通过实验对比不同切片策略,选择最优配置。
"""
# 切片函数
def chunk_text(text, chunk_size=200, chunk_overlap=50):
splitter = RecursiveCharacterTextSplitter(
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
separators=["\n", ".", " "]
)
return splitter.split_text(text)
# 测试不同切片策略
def test_chunking_strategy(text, chunk_sizes=[100, 200, 300], chunk_overlaps=[20, 50, 100]):
results = []
for size in chunk_sizes:
for overlap in chunk_overlaps:
chunks = chunk_text(text, size, overlap)
# 构造数据集
data = {
"question": ["RAG 系统如何优化切片策略?"],
"answer": ["可以通过 RAGAS 测评工具评估不同切片策略的性能,优化切片长度和滑动窗口配置。"],
"contexts": [chunks],
"ground_truth": ["RAGAS 提供了多种评估指标,如 Answer Relevance、Context Precision 等。切片长度和滑动窗口配置对检索性能有重要影响。"]
}
# 转换为 Dataset 格式
dataset = Dataset.from_pandas(pd.DataFrame(data))
# 评估
result = evaluate(dataset, metrics=[
answer_relevancy, context_precision, context_recall, faithfulness
])
# 转换为 DataFrame 并添加 chunk 配置信息
result_df = result.to_pandas()
result_df["chunk_size"] = size
result_df["chunk_overlap"] = overlap
results.append(result_df)
# 合并所有结果
return pd.concat(results, ignore_index=True)
# 执行测试
results_df = test_chunking_strategy(text)
# 重命名列(可选)
results_df = results_df.rename(columns={
"answer_relevancy": "answer_relevancy",
"context_precision": "context_precision",
"context_recall": "context_recall",
"faithfulness": "faithfulness"
})
# 输出结果
print(results_df[[
"answer_relevancy", "context_precision", "context_recall", "faithfulness",
"chunk_size", "chunk_overlap"
]])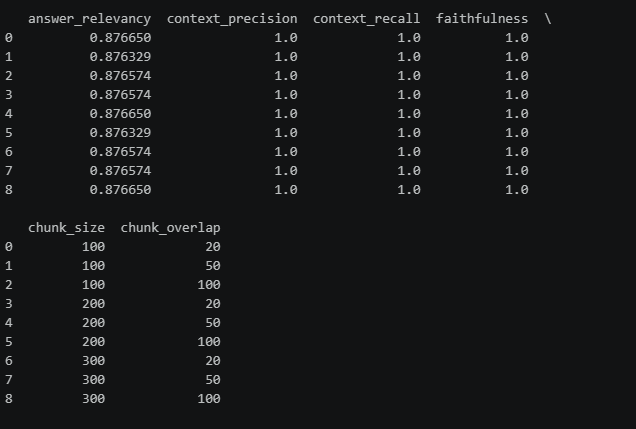
从数据可以看出:
- 所有切片策略下,context_precision、context_recall 和 faithfulness 均为满分(1.0),说明无论采用哪种 chunk_size 和 chunk_overlap,检索系统都能准确找到相关上下文,且生成的答案忠实于上下文。
- answer_relevancy 略有波动,但整体差异极小(仅在小数点后四位),说明所有策略生成的答案都高度相关。
虽然不同切片策略之间指标差异极小,但chunk_size = 200, chunk_overlap = 50 的组合在 answer_relevancy 上表现最好。
RAG切片优化的三大核心原则
- 切片长度:200 字符 ,兼顾信息完整与检索效率
- 滑动窗口:50 字符 ,避免上下文割裂
- 索引策略:优先使用向量索引 ,提升语义匹配能力
🚀 进阶建议: 搭建完整的 LangChain + RAGAS + LangSmith 评估流水线,实现 RAG 系统的持续优化与自动化调参。