从一个小例子实践代数多重网格方法
文章目录
网上由很多介绍多重网格的资料,但大多是概念性的介绍,比如高低频误差,粗细网格、前后光滑和VW Cycle 等等,以致于让人看了之后,感觉自己都懂了,自己着手编程实操,却不知从何下手。本文以 C-AMG (经典代数多重网格方法)为例,从一个小例子出发,不引入过多概念和数学推导,让大家从操作层面,知道 AMG 是怎么运行的。
多重网格方法骨架
回顾一下两层网格方法,简述步骤如下(也可参考 https://blog.csdn.net/lusongno1/article/details/82941922):
1.前光滑:使用给定的 x 0 x_0 x0 作为初始解执行若干步迭代法求解 A x = b Ax=b Ax=b ,得到 x ( 1 ) x^{(1)} x(1) ;
2.细网格残差限制:构造限制算子 R R R ,将残差 r ( 1 ) : = b − A x ( 1 ) r^{(1)}:=b-A x^{(1)} r(1):=b−Ax(1) 投影到粗网格上: r C : = R r ( 1 ) r^C:=R r^{(1)} rC:=Rr(1) ;
3.粗网格求解误差方程:构造粗网格系数矩阵 A C A^C AC ,求解 A C e C = r C A^C e^C=r^C ACeC=rC ,其中 e C e^C eC 的初始猜测解为 0 ;
4.粗网格误差插值:构造磨光(插值)算子 P P P ,将粗网格求解得到的误差 e C e^C eC 投影到细网格上并校正解 x : x ( 2 ) : = x ( 1 ) + P e C x: x^{(2)}:=x^{(1)}+P e^C x:x(2):=x(1)+PeC ;
5.后光滑:使用 x ( 2 ) x^{(2)} x(2) 作为初始解,执行若干步迭代法求解 A x = b A x=b Ax=b ,得到 x n e w x_{n e w} xnew 。
在这个过程中,可以发现,残差方程 A C e C = r C A^C e^C=r^C ACeC=rC 也是个解线性方程的过程,那么就可以递归第调用这个两层网格方法,就得到了多重网格方法的计算骨架。
网格从哪来
考虑一个问题,对于线性方程组求解
A u = f A \mathbf{u}=\mathbf{f} Au=f
其中, u = u 1 , u 2 , ... , u n \mathbf{u} = {u_1,u_2,\dots,u_n} u=u1,u2,...,un。这里面就没有网格结构,那么代数多重网格方法的"网格"是从哪来?代数多重网格(AMG)是利用几何多重网格(Geometric Multigrid, GMG)的一些重要原则和理念发展起来的不依赖于实际几何网格的多重网格方法。它继承了几何多重网格的主要优点,并且可以被用于更多类型的线性方程组。代数多重网格(AMG)里的 "网格",不是几何网格,而是从矩阵 A 的非零结构里 "造" 出来的代数网格。
举例来说,考虑如下的 9*9 的对称矩阵 A A A
A = { a i j } = ∗ ∗ 0 ∗ ∗ 0 0 0 0 ∗ ∗ ∗ 0 ∗ 0 0 0 0 0 ∗ ∗ 0 ∗ ∗ 0 0 0 ∗ 0 0 ∗ ∗ 0 ∗ 0 0 ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ ∗ 0 0 ∗ 0 ∗ ∗ 0 0 ∗ 0 0 0 ∗ ∗ 0 ∗ ∗ 0 0 0 0 0 ∗ 0 ∗ ∗ ∗ 0 0 0 0 ∗ ∗ 0 ∗ ∗ A=\{a_{ij}\}= \begin{bmatrix} \ast & \ast & 0 & \ast & \ast & 0 & 0 & 0 & 0 \\ \ast & \ast & \ast & 0 & \ast & 0 & 0 & 0 & 0 \\ 0 & \ast & \ast & 0 & \ast & \ast & 0 & 0 & 0 \\ \ast & 0 & 0 & \ast & \ast & 0 & \ast & 0 & 0 \\ \ast & \ast & \ast & \ast & \ast & \ast & \ast & \ast & \ast \\ 0 & 0 & \ast & 0 & \ast & \ast & 0 & 0 & \ast \\ 0 & 0 & 0 & \ast & \ast & 0 & \ast & \ast & 0 \\ 0 & 0 & 0 & 0 & \ast & 0 & \ast & \ast & \ast \\ 0 & 0 & 0 & 0 & \ast & \ast & 0 & \ast & \ast \end{bmatrix} A={aij}= ∗∗0∗∗0000∗∗∗0∗00000∗∗0∗∗000∗00∗∗0∗00∗∗∗∗∗∗∗∗∗00∗0∗∗00∗000∗∗0∗∗00000∗0∗∗∗0000∗∗0∗∗
* 表示非零元位置。那么,如果给每个行(列)一个节点编号(也可以给个名称),比如
| | NW | N | NE | W | C | E | SW | S | SE |
|-----|----|---|----|---|---|---|----|---|----|
| NW | * | * | 0 | * | * | 0 | 0 | 0 | 0 |
| N | * | * | * | 0 | * | 0 | 0 | 0 | 0 |
| NE | 0 | * | * | 0 | * | * | 0 | 0 | 0 |
| W | * | 0 | 0 | * | * | 0 | * | 0 | 0 |
| C | * | * | * | * | * | * | * | * | * |
| E | 0 | 0 | * | 0 | * | * | 0 | 0 | * |
| SW | 0 | 0 | 0 | * | * | 0 | * | * | 0 |
| S | 0 | 0 | 0 | 0 | * | 0 | * | * | * |
| SE | 0 | 0 | 0 | 0 | * | * | 0 | * | * |此时,我给行列索引取了一个别名,即 1,2,3,4,5,6,7,8,9 = NW,N,NE,W,C,E,SW,S,SE。
若 a i j ≠ 0 a_{ij}\neq0 aij=0,我们就给第 i i i 个节点和第 j j j 个节点连上一条无向边,那么我们就能得到一张对应于 A A A 的图 G ( A ) G(A) G(A)。
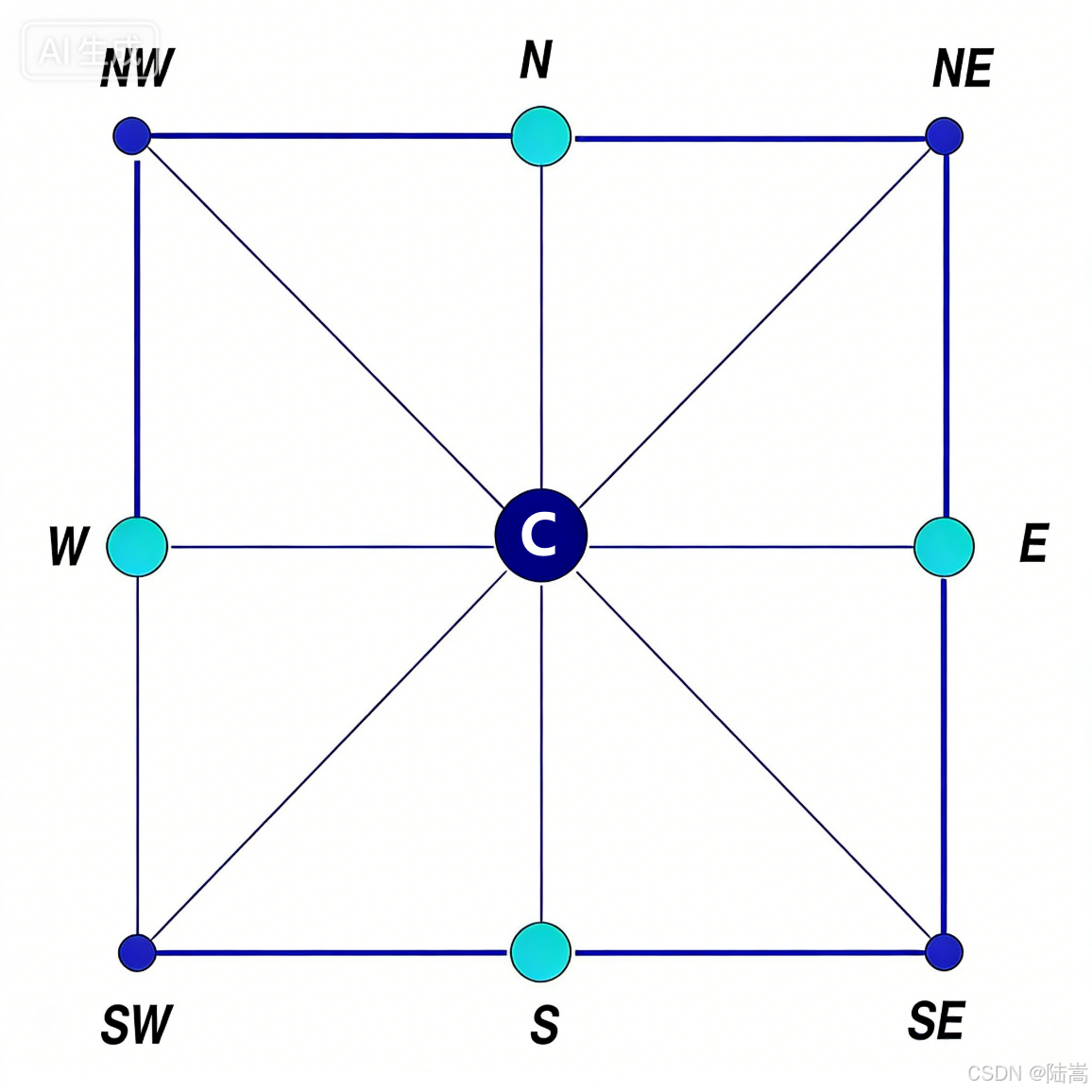
这不就从代数矩阵 A A A 中搞出网格了么。一言以蔽之,AMG 将系数矩阵视作有向邻接表,这个表对应了一张图论中的图。
限制算子和插值算子
AMG 和 GMG (几何多重网格)的区别在于构造 R R R 和 A C A^C AC 。由于 AMG 不依赖于任何实际几何网格信息,所以必须通过其他方式来定义粗网格和构造 R R R ,并且有 P = R T P=R^T P=RT 。同时, A C : = R A R T A^C:=R A R^T AC:=RART 。
粗点选取
AMG 将初始状态 A A A 对应的图作为细网格,并在其上定义粗网格。我们需要根据一定的步骤分出细网格点(细点)和粗网格点(粗点)。这个过程叫做粗化。
下面我们只讨论 C-AMG 的处理方法,不妨考虑 RS 粗化方法。
举一个 25 维矩阵的例子,假设点之间的连接关系如下图所示:
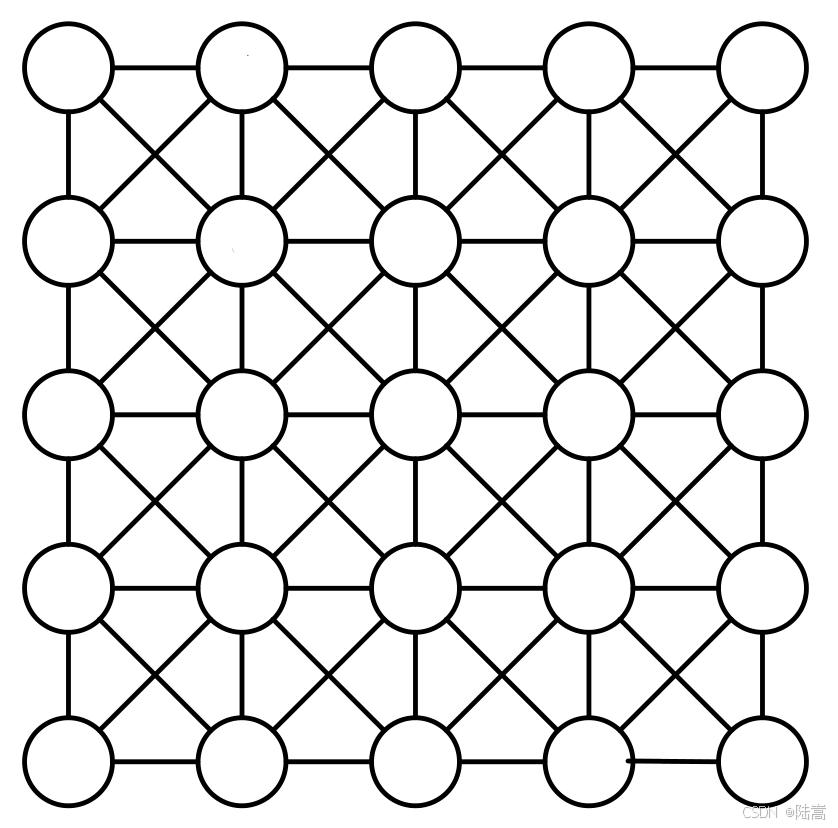
C- AMG 通过如下算法来构造粗网格:
- 为图上每一个点赋一个权重,权重值等于其邻接的点的个数(图论中的度)。------下图 (a)
- 选取当前图上未被分类的点中(未被分为粗网格点和细网格点)权重最大的点,将其加入粗网格格点集。------下图 (b)
- 将其所有邻居加入细网格格点集。------下图 ©
- 对于所有新加入细网格格点集的点,将它们的邻居的权重 +1 。------下图 (d)
- 重复 2-4,直至所有点都被分配完毕。------剩余部分
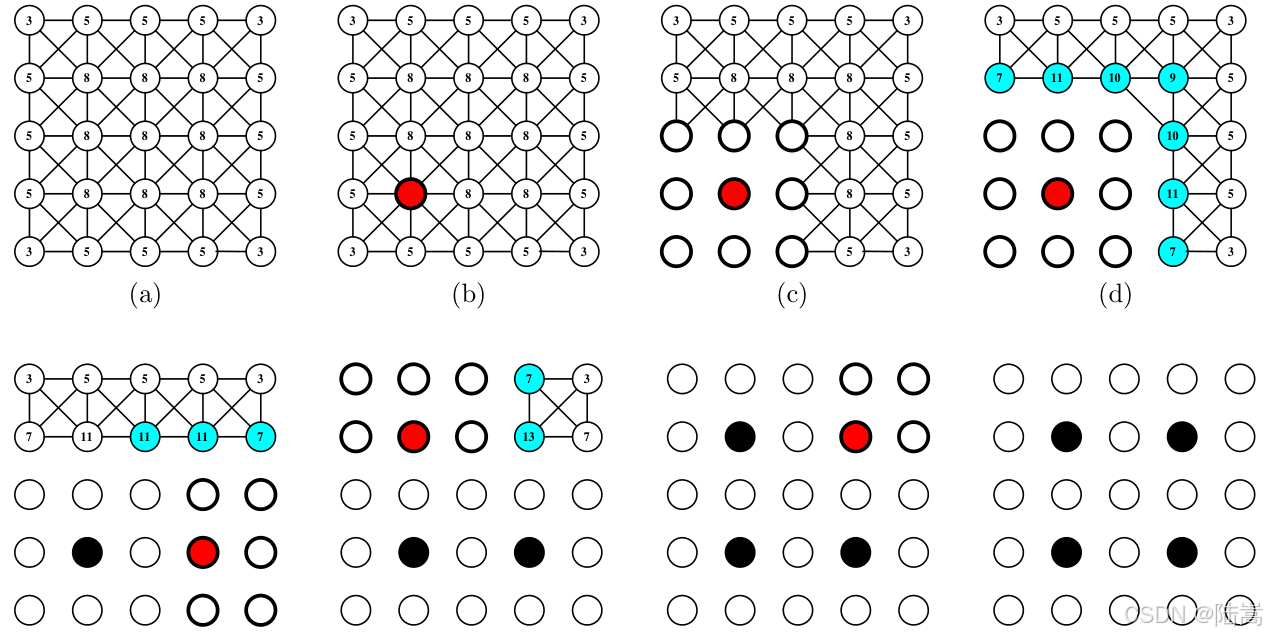
上图中,红心粗框是新更新的粗点,白心粗框维新增的细网格点,蓝心为当前步数值更新,大黑点为得到的粗点。
连接强度
【定义】给定阈值 0 < θ ≤ 1 0<\theta \leq 1 0<θ≤1,取 i ≠ j i\neq j i=j,若
∣ a i j ∣ ≥ θ max k ≠ i { ∣ a i k ∣ } . |a_{i j}| \geq \theta \max {k \neq i}\left\{|a{i k}|\right\} . ∣aij∣≥θk=imax{∣aik∣}.
我们说变量 u i u_i ui 强依赖于 u j u_j uj。
可以看得出来,连接强度取决于每一行中"相对最大"的非对角元。
对于某个网格点,在不引起混淆的情况下,不妨记为网格点 i i i 。关于网格点 i i i,我们可以定义三个集合:
- C i C_i Ci : i i i 强依赖的粗网格格点集合。
- F i s F_i^s Fis : i i i 强依赖的细网格格点集合
- F i w F_i^w Fiw : i i i 非强依赖的细网格格点集合
还是前面那个例子,这次我们把矩阵的某些值给出来,
A = { a i j } = ∗ − 3 0 − 4 − 2 0 0 0 0 − 3 ∗ − 3 0 − 4 0 0 0 0 0 − 3 ∗ 0 − 2 − 4 0 0 0 − 4 0 0 ∗ − 3 0 − 4 0 0 − 2 − 4 − 2 − 3 20 − 3 − 1 − 4 − 1 0 0 − 4 0 − 3 ∗ 0 0 − 4 0 0 0 − 4 − 1 0 ∗ − 3 0 0 0 0 0 − 4 0 − 3 ∗ − 3 0 0 0 0 − 1 − 4 0 − 3 ∗ A=\{a_{ij}\}=\left\\begin{array}{ccccccccc} \\ast \& -3 \& 0 \& -4 \& -2 \& 0 \& 0 \& 0 \& 0 \\\\ -3 \& \\ast \&-3 \& 0 \& -4 \& 0 \& 0 \& 0 \& 0 \\\\ 0 \& -3 \& \\ast \& 0 \& -2 \& -4 \& 0 \& 0 \& 0 \\\\ -4 \& 0 \& 0 \& \\ast \& -3 \& 0 \& -4 \& 0 \& 0 \\\\ -2 \& -4 \& -2 \& -3 \& 20 \& -3 \& -1 \& -4 \& -1 \\\\ 0 \& 0 \& -4 \& 0 \& -3 \& \\ast \& 0 \& 0 \& -4 \\\\ 0 \& 0 \& 0 \& -4 \& -1 \& 0 \& \\ast \& -3 \& 0 \\\\ 0 \& 0 \& 0 \& 0 \& -4 \& 0 \& -3 \& \\ast \& -3 \\\\ 0 \& 0 \& 0 \& 0 \& -1 \& -4 \& 0 \& -3 \& \\ast \\end{array}\\right A={aij}= ∗−30−4−20000−3∗−30−400000−3∗0−2−4000−400∗−30−400−2−4−2−320−3−1−4−100−40−3∗00−4000−4−10∗−300000−40−3∗−30000−1−40−3∗
其对应的粗点和细点已标记的图,如下所示:
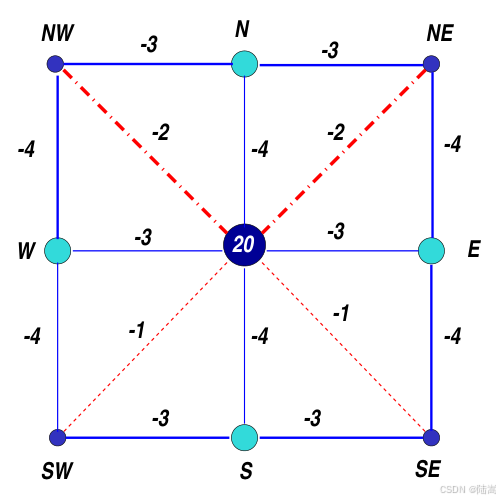
上图中,深蓝色的点为细点,浅蓝色的点为粗点,连接边上的值对应着 a i j a_{ij} aij,中间点(不妨记为 C C C)的 20,表示 a 55 a_{55} a55。
那么,由强依赖的定义(不妨取 θ = 1 / 2 \theta = 1/2 θ=1/2), C C C 弱依赖于 S W , S E {SW,SE} SW,SE(严格地说,应该是 u C u_{C} uC 弱依赖于 { u S W , u S E } \{u_{SW},u_{SE}\} {uSW,uSE},在不引起混淆的情况下,就简单这么说了,下同)。 C C C 强依赖于 { N W , N , N E , W , E , S } \{{NW,N,NE,W,E,S}\} {NW,N,NE,W,E,S}。也就是说,图中对于 C C C,除了细的两根红虚线是非强依赖,其他都是强依赖。
所以,对于 C C C 点来说,取 i = C i=C i=C,那么
- C i C_i Ci = { N , W , E , S } \{N,W,E,S\} {N,W,E,S}
- F i s F_i^s Fis = { N W , N E } \{NW,NE\} {NW,NE}
- F i w F_i^w Fiw : { S W , S E } \{SW,SE\} {SW,SE}
插值算子构造
上述多重网格方法的计算过程,关键步骤在于 A C : = R A P A^C:=RAP AC:=RAP , P = R T P=R^T P=RT ,那么粗网格到细网格的插值算子 P P P 的计算就尤为重要, P P P 是一个映射粗点集合(粗网格)到细点集合(细网格)的算子。下面阐述这个插值修正的过程。
对于节点 i i i ,如果它本身是粗网格格点,那么不需要进行插值,否则它使用 C i C_i Ci 中的粗网格格点值进行插值修正。插值修正有 4 步。依然用下图作为例子说明:
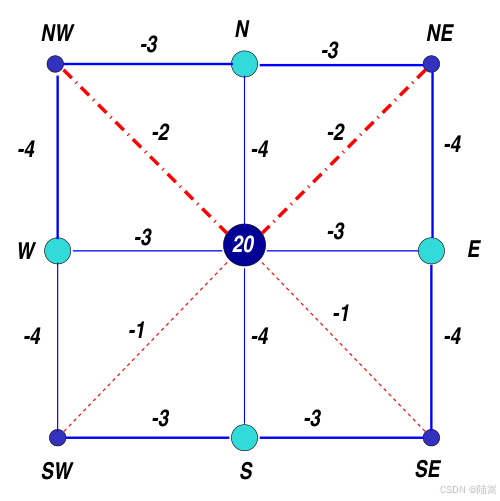
第一步: a i i a_{ii} aii 的更新。
把 i i i 的对应的非强依赖细点集合 F i w F_i^w Fiw 对应的边权值累加到 a i i a_{ii} aii,即
a i i n e w : = a i i + ∑ k ∈ F i w a i k a_{i i}^{new}:=a_{i i}+\sum_{k \in F_i^w} a_{i k} aiinew:=aii+k∈Fiw∑aik
在上图中, F i w F_i^w Fiw : { S W , S E } \{SW,SE\} {SW,SE},则 a i i n e w = 20 − 1 − 1 = 18 a_{i i}^{new} = 20-1-1=18 aiinew=20−1−1=18。
第二步, F i s F_i^s Fis 中每点的总贡献值计算。
对于 F i s F_i^s Fis 中的每一个点 k k k ,统计与他相邻的粗点集对应的边权和,即 δ k : = ∑ l ∈ C i a k l \delta_k:=\sum_{l \in C_i} a_{k l} δk:=l∈Ci∑akl
在上图中, F i s F_i^s Fis = { N W , N E } \{NW,NE\} {NW,NE},对于 N W NW NW,连接的粗点是 { N , W } \{N,W\} {N,W},那么 δ N W = − 3 − 4 = − 7 \delta_{NW} = -3-4=-7 δNW=−3−4=−7,同理 δ N E = − 3 − 4 = − 7 \delta_{NE} = -3-4=-7 δNE=−3−4=−7。
第三步:更细粗点对应边权值 a i j a_{ij} aij。
对于 C i C_i Ci 中的每一个点 j j j ,将与之相邻的 F i s F_i^s Fis 的 k k k,对应的边权乘积 a i k ∗ a k j a_{ik}*a_{kj} aik∗akj 加权累加到边权 a i j a_{ij} aij 上,即
a i j n e w : = a i j + ∑ k ∈ F i s a k j a i k δ k a_{i j}^{n e w}:=a_{i j}+\sum_{k \in F_i^s} a_{k j} \frac{a_{i k}}{\delta_k} aijnew:=aij+k∈Fis∑akjδkaik
换个角度看,也就是将 F i s F_i^s Fis 中每一个点的边权重新分配给与之相邻的 C i C_i Ci 中的点对应的边上(程序上一般通过遍历 F i s F_i^s Fis 来计算)。
在上图中,对于 N ∈ C i N\in C_i N∈Ci,跟他邻接的 F i s F_i^s Fis 中的点有 N W NW NW 和 N E NE NE。那么,
a i , N n e w : = a i , N + a i , N E ∗ a N E , N δ N E + a i , N W ∗ a N W , N δ N W = − 4 + ( − 2 ) ∗ ( − 3 ) − 7 + ( − 2 ) ∗ ( − 3 ) − 7 = − 4 − 12 7 a_{i,N}^{new}:=a_{i,N}+\frac{a_{i,NE}*a_{NE,N}}{\delta_{NE}}+\frac{a_{i,NW}*a_{NW,N}} {\delta_{NW}} = -4+\frac{(-2)*(-3)}{-7}+\frac{(-2)*(-3)}{-7} = -4-\frac{12}{7} ai,Nnew:=ai,N+δNEai,NE∗aNE,N+δNWai,NW∗aNW,N=−4+−7(−2)∗(−3)+−7(−2)∗(−3)=−4−712
同理可得
a i , W n e w = a i , E n e w : = − 3 + ( − 2 ) ∗ ( − 4 ) − 7 = − 3 − 8 7 a_{i,W}^{new}=a_{i,E}^{new}:= -3+\frac{(-2)*(-4)}{-7} = -3-\frac{8}{7} ai,Wnew=ai,Enew:=−3+−7(−2)∗(−4)=−3−78
a i , S n e w = a i , S a_{i,S}^{new}=a_{i,S} ai,Snew=ai,S
第四步:线性组合插值修正。
权重取负单位化后,则有了当前点变量 s i s_i si 关于其邻接粗点变量的线性表出,
s i : = ∑ j ∈ C i w i j s j , w i j : = − a i j n e w a i i n e w s_i:=\sum_{j \in C_i} w_{i j} s_j, w_{i j}:=-\frac{a_{i j}^{n e w}}{a_{i i}^{n e w}} si:=j∈Ci∑wijsj,wij:=−aiinewaijnew
在上面的例子中,
s i = 1 18 4 s S + ( 4 + 12 7 ) s N + ( 3 + 8 7 ) s W + ( 3 + 8 7 ) s E . s_i = \frac{1}{18}\left4 s_S+\\left(4+\\frac{12}{7}\\right) s_N+\\left(3+\\frac{8}{7}\\right) s_W+\\left(3+\\frac{8}{7}\\right) s_E\\right . si=1814sS+(4+712)sN+(3+78)sW+(3+78)sE.
通过上述的插值操作,我们就顺利地把 i i i 点通过周边相邻的粗网格点表出。遍历不同的细点,都可以有一个表出方式,这个表出方式就张成了一个矩阵 n × m n\times m n×m 规模的矩阵 P P P, n n n 是图中细点的数量, m m m 是图中粗点的数量。
在上面的例子中, P = { w i j } , i = 1 , ... , 9 i = 1 , ... , 4 P = \{w_{ij}\},i=1,\dots,9 \space\space i=1,\dots,4 P={wij},i=1,...,9 i=1,...,4。有了插值节点后,限制算子 R = P T R=P^T R=PT。
光滑子
在 AMG 的执行过程中,还有一个关键的组件 Smoother(光滑子),用于前光滑和后光滑,用户消除高频误差。
AMG 中常见的光滑子主要有 点光滑子(Jacobi、加权 Jacobi、Gauss--Seidel、SOR/SSOR)、因子分解类(ILU/IC)、多项式光滑子(典型是 Chebyshev),以及面向耦合系统或各向异性的 块光滑子 / Schwarz / 线光滑子等。其中最典型的是 Jacobi、Gauss--Seidel 和 Chebyshev。设线性方程组 A x = b Ax=b Ax=b,并作分裂 A = D + L + U A=D+L+U A=D+L+U(其中 D D D 为对角部分, L , U L,U L,U 分别为下/上三角部分)。
加权 Jacobi 的一步迭代可写为
x ( k + 1 ) = x ( k ) + ω D − 1 ( b − A x ( k ) ) , x^{(k+1)} = x^{(k)} + \omega D^{-1}\bigl(b - Ax^{(k)}\bigr), x(k+1)=x(k)+ωD−1(b−Ax(k)),
其优点是实现简单、并行性好。Gauss--Seidel(前向)可写为
( D + L ) x ( k + 1 ) = b − U x ( k ) , (D+L)x^{(k+1)} = b - Ux^{(k)}, (D+L)x(k+1)=b−Ux(k),
通常平滑能力更强但并行性较差。SOR 在 GS 基础上引入松弛参数 ω \omega ω,可写为
( D + ω L ) x ( k + 1 ) = ω b − ω U + ( ω − 1 ) D x ( k ) , (D+\omega L)x^{(k+1)} = \omega b - \bigl\\omega U + (\\omega - 1)D\\bigrx^{(k)}, (D+ωL)x(k+1)=ωb−ωU+(ω−1)Dx(k),
当参数选取合适时可加速收敛。并行 AMG 中常用 Chebyshev 光滑子,本质是对残差做多项式校正:
x ( k + 1 ) = x ( k ) + p m ( A ) ( b − A x ( k ) ) , x^{(k+1)} = x^{(k)} + p_m(A)\bigl(b - Ax^{(k)}\bigr), x(k+1)=x(k)+pm(A)(b−Ax(k)),
其中 p m p_m pm 是在目标特征值区间上优化的 Chebyshev 多项式,兼顾较强平滑效果与高并行性。若问题存在强耦合(如弹性、流体)或强各向异性,则常改用 Block Jacobi / Block GS、Schwarz、线光滑子来提升鲁棒性。
程序实现
找应给程序实现的最小闭包,串一遍整个过程。不到 500 行代码,就可以实现一便完整的 C-AMG 算法。
clc
clear
% 构造 2D Poisson 矩阵(5点格式)
nx = 20; ny = 20;
ex = ones(nx,1); Tx = spdiags([-ex 2*ex -ex], -1:1, nx, nx);
ey = ones(ny,1); Ty = spdiags([-ey 2*ey -ey], -1:1, ny, ny);
A = kron(speye(ny), Tx) + kron(Ty, speye(nx));
% 右端项(用真解验证)
x_true = ones(nx*ny,1);
b = A * x_true;
% 直接调用 AMG 求解
[x, info] = amg_vcycle_solve(A, b);
% 查看误差与收敛信息
fprintf('AMG relres = %.3e, iters = %d\n', info.relres, info.iters);
fprintf('relative error = %.3e\n', norm(x-x_true)/norm(x_true));
function [x, info] = amg_vcycle_solve(A, b, opts)
%AMG_VCYCLE_SOLVE 使用代数多重网格(AMG) V-cycle 求解 Ax=b(单文件版)
%
% 用法:
% x = amg_vcycle_solve(A, b)
% [x, info] = amg_vcycle_solve(A, b)
% [x, info] = amg_vcycle_solve(A, b, opts)
%
% 输入:
% A - 稀疏/稠密方阵(建议 SPD / M-矩阵风格,如 Poisson)
% b - 右端向量
% opts - 参数结构体(可选),字段如下:
% .theta 强连接阈值,默认 0.5
% .max_levels 最大层数,默认 8
% .min_coarse_n 最粗层阈值,默认 16
% .nu1 前光滑步数,默认 2
% .nu2 后光滑步数,默认 2
% .omega Jacobi 权重,默认 0.75
% .max_cycles V-cycle 最大次数,默认 20
% .tol 相对残差停止阈值,默认 1e-10
% .x0 初始解,默认零向量
% .verbose 是否打印迭代信息,默认 true
%
% 输出:
% x - 数值解
% info - 信息结构体:
% .relres 最终相对残差
% .resvec 每次循环相对残差
% .iters 实际 V-cycle 次数
% .levels AMG 层数
% .coarse_sizes 每层未知量规模
% .flag 0 收敛, 1 未达到 tol
%
% 说明(与我的博客对齐的核心实现):
% 1) 粗化按"权重=度数 -> 选最大权重点为粗点 -> 邻居设细点 -> 新细点邻居权重+1"
% 2) 插值算子 P 按四步法:
% aii_new, delta_k, aij_new, w_ij = -aij_new/aii_new
% 3) R = P', Ac = R*A*P
%
% 作者:
% lusong@lsec.cc.ac.cn
%
% -------------------- 参数与输入检查 --------------------
if nargin < 3, opts = struct(); end
opts = apply_default_opts(opts);
n = size(A,1);
b = b(:);
if ~issparse(A)
A = sparse(A);
end
x = zeros(n,1);
% -------------------- 建立 AMG 层级 --------------------
levels = amg_setup(A, opts);
% -------------------- V-cycle 外层迭代 --------------------
r = b - A*x;
nr0 = norm(r);
if nr0 == 0
info = struct();
info.relres = 0;
info.resvec = 0;
info.iters = 0;
info.levels = numel(levels);
info.coarse_sizes = cellfun(@(lv) size(lv.A,1), levels);
info.flag = 0;
return;
end
resvec = zeros(opts.max_cycles+1,1);
resvec(1) = 1.0;
if opts.verbose
fprintf('AMG hierarchy levels: %d\n', numel(levels));
for ell = 1:numel(levels)
fprintf(' Level %d: n = %d\n', ell, size(levels{ell}.A,1));
end
fprintf('\nV-cycle iteration:\n');
fprintf('iter relres\n');
fprintf('----------------------\n');
fprintf('%3d %.3e\n', 0, resvec(1));
end
flag = 1;
iters = 0;
for k = 1:opts.max_cycles
x = amg_vcycle(levels, 1, x, b, opts);
r = b - A*x;
relres = norm(r)/nr0;
resvec(k+1) = relres;
iters = k;
if opts.verbose
fprintf('%3d %.3e\n', k, relres);
end
if relres < opts.tol
flag = 0;
break;
end
end
resvec = resvec(1:iters+1);
info = struct();
info.relres = resvec(end);
info.resvec = resvec;
info.iters = iters;
info.levels = numel(levels);
info.coarse_sizes = cellfun(@(lv) size(lv.A,1), levels);
info.flag = flag;
end
%% ========================================================================
% 参数默认值
% ========================================================================
function opts = apply_default_opts(opts)
if ~isfield(opts,'theta') || isempty(opts.theta), opts.theta = 0.5; end
if ~isfield(opts,'max_levels') || isempty(opts.max_levels), opts.max_levels = 8; end
if ~isfield(opts,'min_coarse_n') || isempty(opts.min_coarse_n), opts.min_coarse_n = 16;end
if ~isfield(opts,'nu1') || isempty(opts.nu1), opts.nu1 = 2; end
if ~isfield(opts,'nu2') || isempty(opts.nu2), opts.nu2 = 2; end
if ~isfield(opts,'omega') || isempty(opts.omega), opts.omega = 0.75; end
if ~isfield(opts,'max_cycles') || isempty(opts.max_cycles), opts.max_cycles = 20; end
if ~isfield(opts,'tol') || isempty(opts.tol), opts.tol = 1e-10; end
if ~isfield(opts,'verbose') || isempty(opts.verbose), opts.verbose = true; end
end
%% ========================================================================
% AMG setup: 构建层级
% ========================================================================
function levels = amg_setup(A, opts)
levels = {};
ell = 1;
while true
lvl = struct();
lvl.A = A;
n = size(A,1);
% 1) 强连接矩阵(按博文)
S = strength_matrix_doc(A, opts.theta);
% 2) 粗化(按博文步骤)
[isC, isF] = coarsen_by_doc_rule(A, S);
nc = nnz(isC);
if nc == 0 || nc >= n
lvl.is_coarsest = true;
levels{ell} = lvl;
break;
end
% 3) 插值算子(按博文四步法)
P = build_P_doc(A, S, isC, isF);
if isempty(P) || size(P,2) == 0 || size(P,2) >= n
lvl.is_coarsest = true;
levels{ell} = lvl;
break;
end
R = P';
Ac = R * A * P;
% 粗层矩阵异常时停止递归
if size(Ac,1) >= n || nnz(Ac) == 0
lvl.is_coarsest = true;
levels{ell} = lvl;
break;
end
lvl.is_coarsest = false;
lvl.S = S;
lvl.isC = isC;
lvl.isF = isF;
lvl.P = P;
lvl.R = R;
levels{ell} = lvl;
% 下一层
A = Ac;
ell = ell + 1;
end
end
%% ========================================================================
% AMG V-cycle 递归
% ========================================================================
function x = amg_vcycle(levels, ell, x, b, opts)
A = levels{ell}.A;
if levels{ell}.is_coarsest
x = A \ b;
return;
end
% 前光滑
x = weighted_jacobi(A, b, x, opts.nu1, opts.omega);
% 残差并限制
r = b - A*x;
rc = levels{ell}.R * r;
% 粗网格误差方程
ec = zeros(size(rc));% 0 初值
ec = amg_vcycle(levels, ell+1, ec, rc, opts);
% 插值校正
x = x + levels{ell}.P * ec;
% 后光滑
x = weighted_jacobi(A, b, x, opts.nu2, opts.omega);
end
%% ========================================================================
% 加权 Jacobi 光滑
% ========================================================================
function x = weighted_jacobi(A, b, x, nu, omega)
d = diag(A);
d(abs(d) < eps) = 1;
for t = 1:nu
r = b - A*x;
x = x + omega * (r ./ d);
end
end
%% ========================================================================
% 强连接矩阵(按博文定义)
% |a_ij| >= theta * max_{k!=i} |a_ik| (i ~= j)
% ========================================================================
function S = strength_matrix_doc(A, theta)
n = size(A,1);
S = spalloc(n, n, nnz(A));
for i = 1:n
cols = find(A(i,:));
cols(cols == i) = [];
if isempty(cols), continue; end
vals = abs(full(A(i,cols)));
m = max(vals);
if m <= 0, continue; end
strong = cols(vals >= theta * m);
if ~isempty(strong)
S(i,strong) = true;
end
end
S = spones(S);
end
%% ========================================================================
% 粗化(按博文步骤)
% 1. 权重=邻接度
% 2. 选最大未分类点为粗点
% 3. 邻居设为细点
% 4. 新细点邻居权重 +1
% 5. 重复直到分类完成
% ========================================================================
function [isC, isF] = coarsen_by_doc_rule(A, S)
n = size(A,1);
% 从 A 非零结构造图(无向,去对角)
G = spones(A);
G = spones(G | G');
G = G - diag(diag(G));
state = zeros(n,1); % 0未分类, 1粗点, -1细点
w = full(sum(G,2)); % 初始权重=度数
while any(state == 0)
U = find(state == 0);
[~, id] = max(w(U));
i = U(id);
% 选粗点
state(i) = 1;
% 邻居 -> 细点(只改未分类点)
Ni = find(G(i,:));
newF = Ni(state(Ni) == 0);
state(newF) = -1;
% 新细点的邻居权重 +1(只对未分类点加)
for k = newF(:)'
Nk = find(G(k,:));
uu = Nk(state(Nk) == 0);
w(uu) = w(uu) + 1;
end
end
isC = (state == 1);
isF = (state == -1);
% 保底:确保每个细点至少有一个强依赖粗点(便于按博文构造插值)
for i = find(isF)'
Si = find(S(i,:));
if isempty(Si) || ~any(isC(Si))
isF(i) = false;
isC(i) = true;
end
end
end
%% ========================================================================
% 插值算子 P(按博文四步法)
%
% 集合:
% C_i = i 强依赖的粗点集合
% F_i^s = i 强依赖的细点集合
% F_i^w = i 非强依赖的细点集合(在 i 的细点邻居里剔除 F_i^s)
%
% 四步:
% 1) aii_new = aii + sum_{k in F_i^w} a_ik
% 2) delta_k = sum_{l in C_i} a_kl
% 3) aij_new = aij + sum_{k in F_i^s} a_kj * (a_ik / delta_k)
% 4) w_ij = -aij_new / aii_new
% ========================================================================
function P = build_P_doc(A, S, isC, isF)
n = size(A,1);
cpts = find(isC);
nc = numel(cpts);
cid = zeros(n,1);
cid(cpts) = 1:nc; % 粗点全局编号对应的局部编号是 1:nc
% 邻接(从 A 的非零结构,去对角)
G = spones(A);
G = G - diag(diag(G));
% 预分配
chunk = max(64, 8*nnz(isF) + nnz(isC));
I = zeros(chunk,1);
J = zeros(chunk,1);
V = zeros(chunk,1);
ptr = 0;
for i = 1:n
if isC(i)
% 粗点直接注入
ptr = ptr + 1;
[I,J,V] = ensure_capacity(I,J,V,ptr,chunk);
I(ptr) = i;
J(ptr) = cid(i);
V(ptr) = 1.0;
continue;
end
% 细点 i:构造 C_i, F_i^s, F_i^w
neigh_i = find(G(i,:)); % 所有邻居(按 A 非零结构)
Si = find(S(i,:)); % 强依赖集合
Ci = Si(isC(Si)); % 强依赖粗点集合
Fis = Si(isF(Si)); % 强依赖细点集合
% 非强依赖细点集合:细点邻居中剔除强依赖细点
Fi_all = neigh_i(isF(neigh_i));
Fiw = setdiff(Fi_all, Fis);
% 若无强依赖粗点,尝试用邻居粗点兜底(数值保底)
if isempty(Ci)
Ci = neigh_i(isC(neigh_i));
if isempty(Ci)
j = find(isC,1,'first');
if isempty(j), continue; end
ptr = ptr + 1;
[I,J,V] = ensure_capacity(I,J,V,ptr,chunk);
I(ptr) = i; J(ptr) = cid(j); V(ptr) = 1.0;
continue;
end
end
% ---------- 第一步:更新 a_ii ----------
aii_new = full(A(i,i));
if ~isempty(Fiw)
aii_new = aii_new + sum(full(A(i,Fiw)));
end
if abs(aii_new) < 1e-14
% 保底防除零
aii_new = full(A(i,i));
if abs(aii_new) < 1e-14
aii_new = 1.0;
end
end
% ---------- 初始化 a_ij^new = a_ij ----------
mCi = numel(Ci);
aij_new = zeros(mCi,1);
for t = 1:mCi
j = Ci(t);
aij_new(t) = full(A(i,j));
end
% ---------- 第二步 & 第三步 ----------
for kk = 1:numel(Fis)
k = Fis(kk);
% delta_k = sum_{l in C_i} a_{k,l}
delta_k = 0.0;
for t = 1:mCi
l = Ci(t);
delta_k = delta_k + full(A(k,l));
end
if abs(delta_k) < 1e-14
continue;
end
aik = full(A(i,k));
if abs(aik) < 1e-14
continue;
end
% a_ij^new = a_ij^new + a_kj * (a_ik / delta_k)
for t = 1:mCi
j = Ci(t);
akj = full(A(k,j));
if abs(akj) > 0
aij_new(t) = aij_new(t) + akj * (aik / delta_k);
end
end
end
% ---------- 第四步:w_ij = -a_ij^new / a_ii^new ----------
row_written = false;
for t = 1:mCi
j = Ci(t);
wij = -aij_new(t) / aii_new;
if abs(wij) < 1e-15
continue;
end
ptr = ptr + 1;
[I,J,V] = ensure_capacity(I,J,V,ptr,chunk);
I(ptr) = i;
J(ptr) = cid(j);
V(ptr) = wij;
row_written = true;
end
% 保底:如果该细点行没有写入任何项
if ~row_written
j = Ci(1);
ptr = ptr + 1;
[I,J,V] = ensure_capacity(I,J,V,ptr,chunk);
I(ptr) = i;
J(ptr) = cid(j);
V(ptr) = 1.0;
end
end
I = I(1:ptr); J = J(1:ptr); V = V(1:ptr);
P = sparse(I, J, V, n, nc);
% 零行保底
zrows = find(sum(spones(P),2) == 0);
if ~isempty(zrows) && nc > 0
for t = 1:numel(zrows)
P(zrows(t),1) = 1.0;
end
end
end
function [I,J,V] = ensure_capacity(I,J,V,ptr,chunk)
if ptr > numel(I)
I = [I; zeros(chunk,1)]; %#ok<AGROW>
J = [J; zeros(chunk,1)]; %#ok<AGROW>
V = [V; zeros(chunk,1)]; %#ok<AGROW>
end
end参考文献:
R. D. Falgout: An Introduction to Algebraic Multigrid
Yousef Saad: Iterative Methods for Sparse Linear Systems
谷同祥等:迭代方法和预处理技术(下册)