一、函数作用
这个函数是数据标准化(Z-Score 标准化) 函数,专门对两组数据 x_raw(自变量)做标准化处理,并返回标准化后的数据 + 记录标准化参数的对象。
具体做了这 4 件事:
- 计算
x_raw的均值 和标准差 - 用 Z-Score 公式对两组数据分别标准化:
标准化值 = (原始值 - 均值) / 标准差 - 处理标准差为 0的极端情况(避免除以 0 报错)
- 返回:标准化后的 x、标准化后的 beta、标准化信息对象(保存均值 / 标准差,方便后续还原数据)
二、核心好处(为什么要写这个函数?)
1. 避免除以 0 错误(鲁棒性强)
代码里做了关键防护:
python
运行
x_scale = float(np.std(x_raw)) or 1.0
if x_scale < 1e-12: x_scale = 1.0- 如果数据全是同一个数(标准差 = 0),直接把分母设为 1.0
- 不会崩溃、不会产生无穷大数值
- 这是工程化代码必备的容错处理
2. 数据同步标准化,保持一致性
- 同时标准化
x和beta - 适合回归模型、拟合、机器学习场景
- 保证输入和系数在同一量纲体系下计算,结果更稳定
3. 保留标准化参数,支持逆标准化
- x 的均值、x 的标准差
- beta 的均值、beta 的标准差
- 自定义 u 值
用途 :后续你可以用这些参数,把标准化后的数据还原成原始数据 ,这在模型预测、结果展示时必须用到。
4. 统一量纲,提升模型 / 计算效果
标准化最核心的价值:
- 消除单位不同 (比如米和千克)、数值量级差距大(比如 1 和 10000)的影响
- 让梯度下降、回归、优化算法收敛更快、更稳定
- 避免大数值变量 "主导" 计算结果
5. 代码复用、简洁规范
把标准化逻辑封装成函数:
- 不用重复写均值、标准差计算
- 一处修改,全局生效
- 可读性强,团队协作更方便
三、适用场景
这个函数最常用在:
- 线性回归 / 多项式拟合
- 机器学习模型训练前的数据预处理
- 数值优化、方程求解
- 需要对输入和系数同时归一化的科学计算
四、总结
核心一句话
这是一个安全、健壮、可还原 的双变量 Z-Score 标准化函数,专门用于预处理数据,让计算更稳定、模型效果更好,同时避免程序崩溃。
关键优点
- 防除零错误,代码鲁棒性拉满
- 同步标准化两组数据,保持一致性
- 保存标准化参数,支持数据还原
- 统一量纲,优化模型 / 数值计算效果
- 封装复用,代码简洁规范
五、测试
python
import numpy as np
# 定义一个简单的类,用来保存标准化信息(方便后续还原数据)
import numpy as np
# 标准化信息类:保存均值、标准差,方便后续还原数据
class NormalizationInfo:
def __init__(self, data_mean, data_std, custom_value=0.0):
self.data_mean = data_mean # 原始数据的均值(一看就懂)
self.data_std = data_std # 原始数据的标准差(一看就懂)
self.custom_value = custom_value # 自定义额外参数
def normalize_data(original_data, custom_value=0.0):
"""
【单变量数据标准化】Z-Score 标准化
作用:把数据变成 均值=0,标准差=1 的标准分布,消除量纲影响
自动防止除以0错误,非常稳定
参数:
original_data: 原始数据(列表 或 numpy数组)
custom_value: 可选,自定义额外值
返回:
标准化后的数据 + 标准化信息对象
"""
# 计算原始数据的均值和标准差
mean_val = np.mean(original_data)
std_val = np.std(original_data)
# 安全处理:如果标准差接近0,就设为1,避免除以0报错
if std_val < 1e-12:
std_val = 1.0
# 标准化核心公式
standardized_data = (original_data - mean_val) / std_val
# 返回标准化结果 + 记录均值和标准差(用于还原数据)
return standardized_data, NormalizationInfo(mean_val, std_val, custom_value)
# ===================== 示例使用 =====================
if __name__ == "__main__":
# 测试用的原始数据
test_data = np.array([1, 2, 3, 4, 5])
# 执行标准化
data_after_standard, standard_info = normalize_data(test_data)
# 输出结果
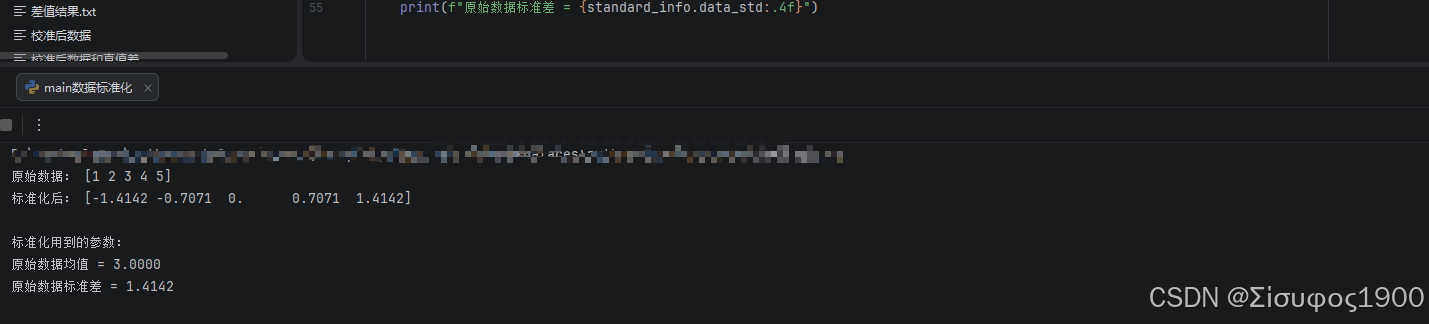
print("原始数据:", test_data)
print("标准化后:", np.round(data_after_standard, 4))
print("\n标准化用到的参数:")
print(f"原始数据均值 = {standard_info.data_mean:.4f}")
print(f"原始数据标准差 = {standard_info.data_std:.4f}")