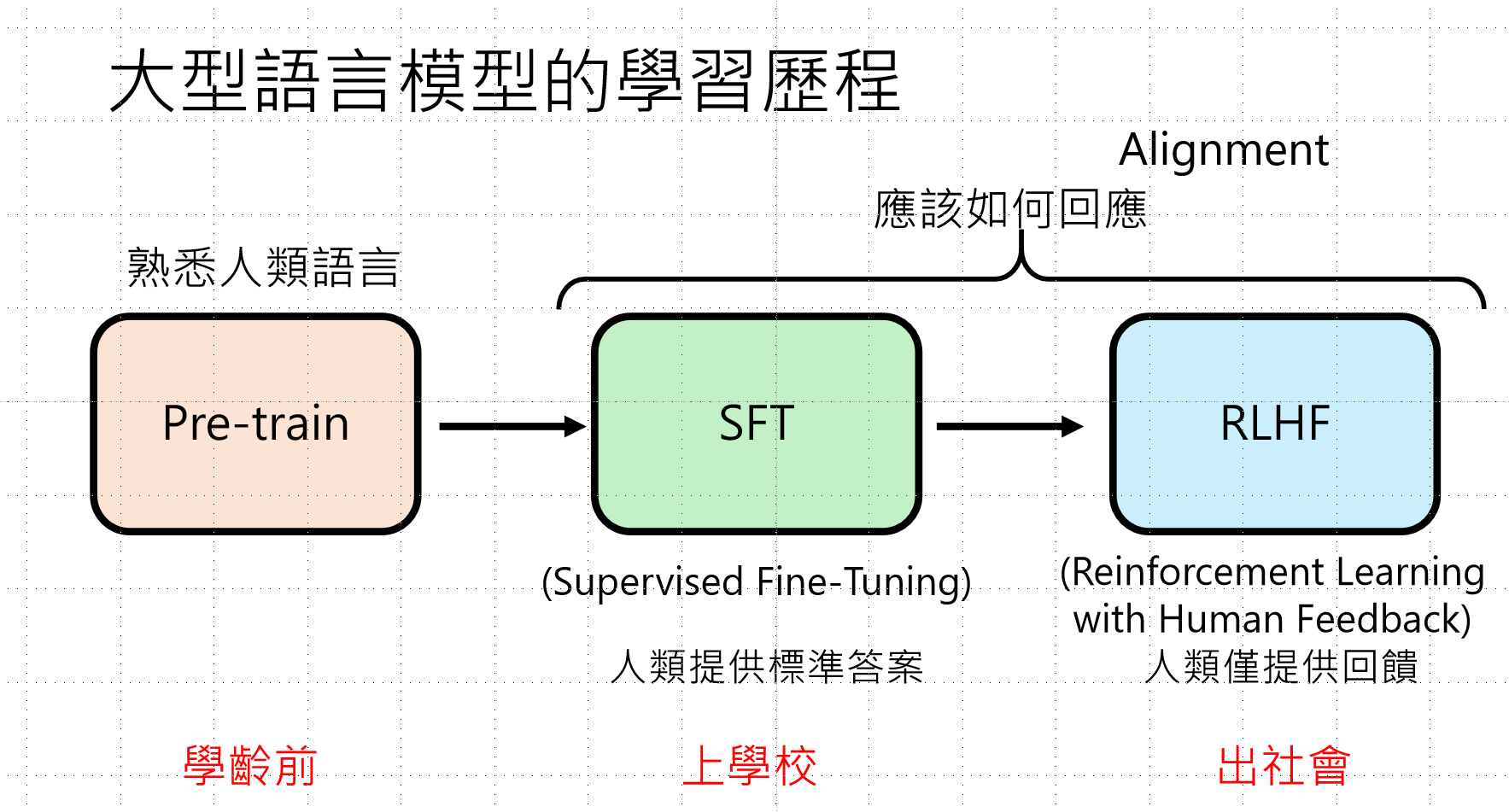
一、核心概念:三阶段学习框架
大型语言模型(LLM)的学习过程分为三个主要阶段,每个阶段本质上都是在学习"文字接龙"(即分类题)。关键在于,每个新阶段开始时,都会使用前阶段训练好的参数作为初始值(Initialization),这保证了知识的连续传承。
|-------------|-------------------|---------------------------------|--------|--------|
| 阶段 | 名称 | 学习方式 | 人类参与程度 | 类比人生阶段 |
| Stage 1 | Pre-train(预训练) | 自督导学习(Self-supervised Learning) | 极少 | 学龄前 |
| Stage 2 | SFT(监督式微调) | 督导式学习(Supervised Learning) | 提供标准答案 | 上学校 |
| Stage 3 | RLHF(基于人类反馈的强化学习) | 强化学习(Reinforcement Learning) | 仅提供反馈 | 出社会 |
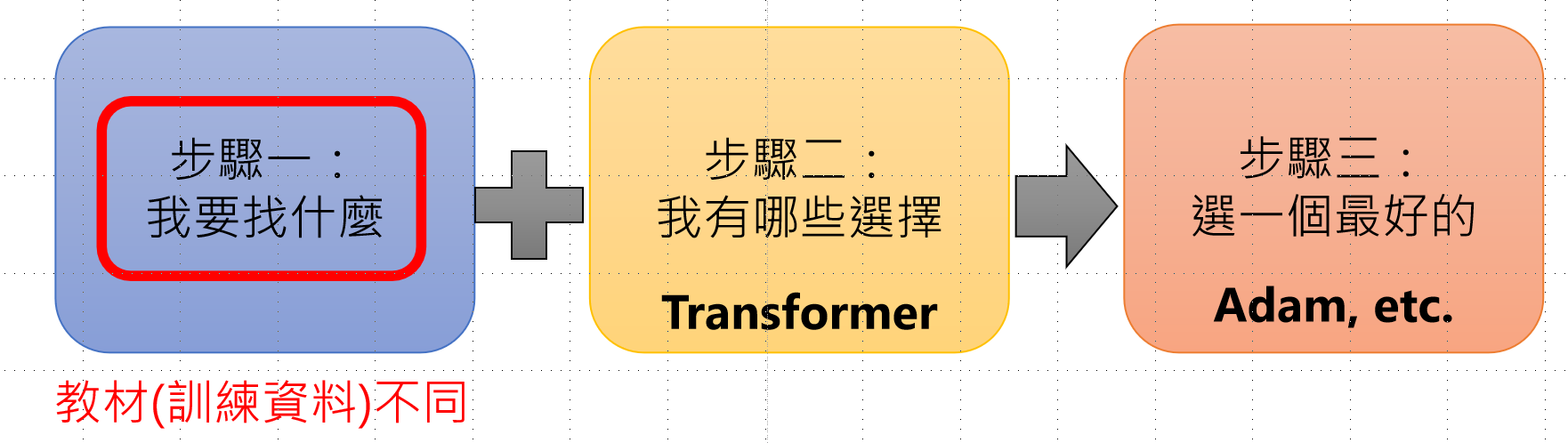
每一阶段的训练与我们之前将的模型训练步骤是一致的,都是三部曲,不同阶段的区别在于训练资料有所不同,而其他的不变,因为我们需要用到之前训练阶段的参数,所以我们的架构不会改变。
训练三部曲的一致性:三个阶段都遵循相同的训练步骤:
- 步骤一 :确定要找什么(教材/训练资料不同 ← 这是唯一区别)
- 步骤二 :确定有哪些选择(Transformer架构)
- 步骤三 :选择最好的(Adam等优化器)
二、第一阶段:预训练(Pre-training)
2.1 学习目标
预训练阶段的目标是学会正确地做文字接龙,这需要大量的资料去让模型掌握两种核心知识:
语言知识(Linguistic Knowledge)
- 理解语法、语义、上下文关系
- 例如:"这个人突然就___" → "跑"✓、"飞"✓、"的"✗
世界知识(World Knowledge)
- 掌握事实性信息
- 例如:"水的沸点是摄氏___在低气压下" → "一百度"✓✗、"五十度"✗✓(需要理解条件)
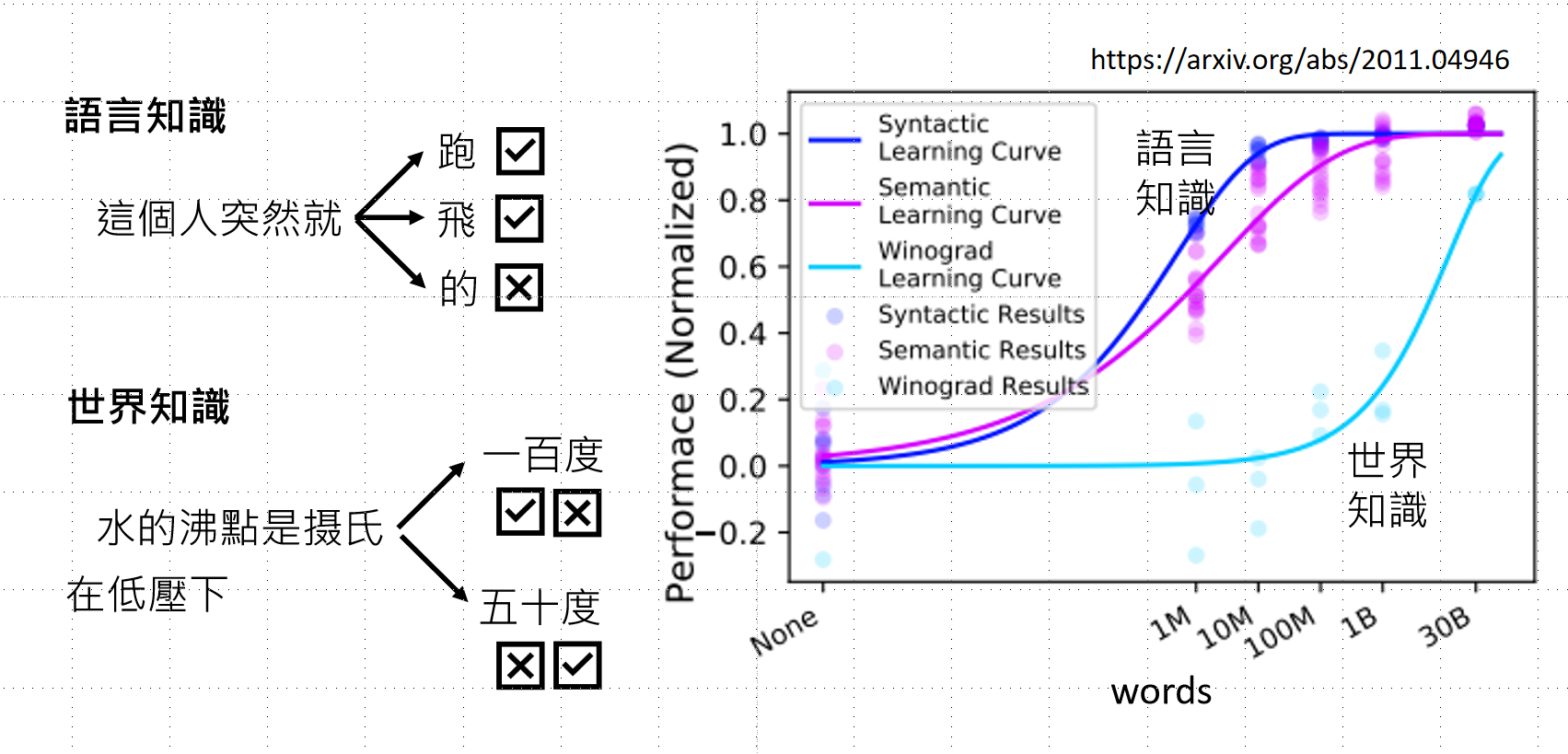
2.2 数据规模与Scaling Law
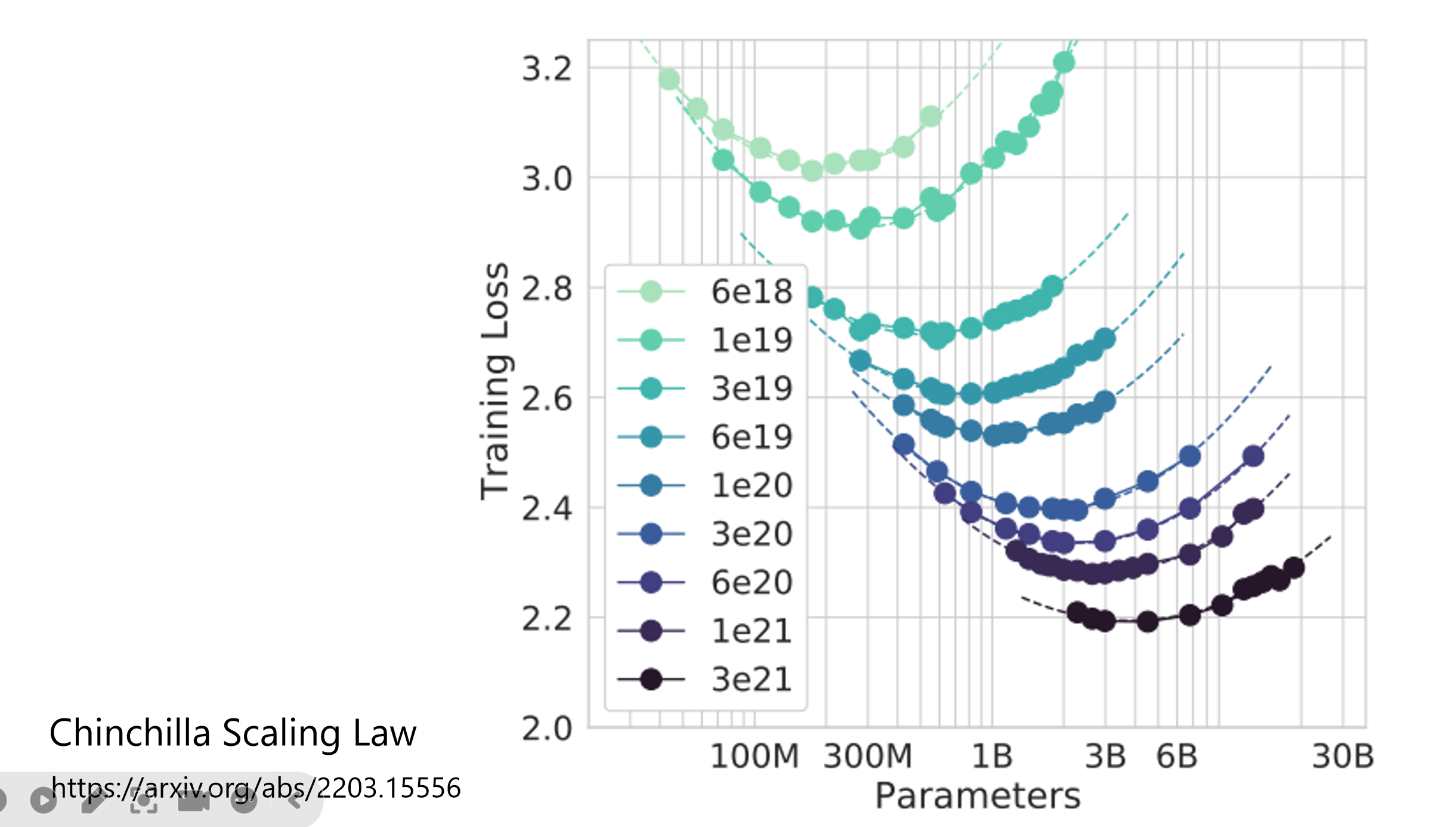
预训练需要海量数据 ,通常达到300亿(30B)tokens级别。从上图右侧的学习曲线可以看出:
- 语言知识(蓝/紫线):在1M-100M数据量时快速饱和
- 世界知识(青线):需要到1B-30B数据量才显著提升
但是模型对于这些资料,不是直接进行死记硬背,而是去进行压缩,对于训练资料只是有一些印象,无法完全的复现,是将这些资料压缩存入,如果要模型输出这些内容,会存在一定的失真情况。
2.3 数据质量 vs 数据数量、
在现实情况中,资料越多对于模型的训练更好。但是也有现实限制,比如算力是有限的
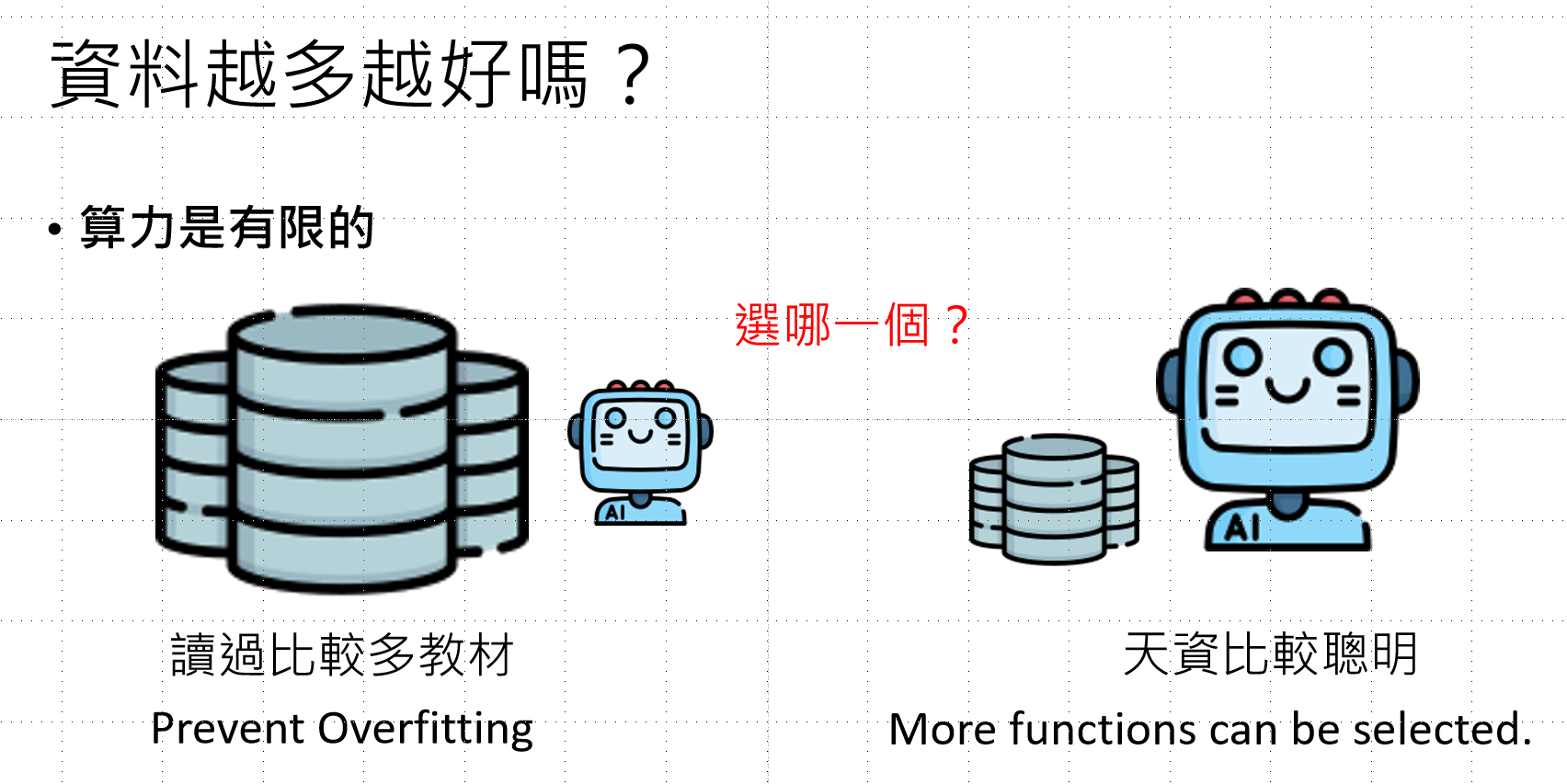
在实际训练中面临算力限制的权衡:
- 左侧路径:大量数据 + 较小模型 → 防止过拟合(Prevent Overfitting)
- 右侧路径:少量数据 + 较大模型 → 更多可学习函数(More functions can be selected
关键发现 :低质量数据会导致loss骤然上升,因此数据清洗至关重要。
同时我们还要考虑资料的品质,低质量的资料会让模型的loss骤然变化。所以我们还要对取到的资料进行清理
2.4 数据清洗流程
现代LLM训练采用多阶段数据清洗流程(以DCLM-Baseline为例):
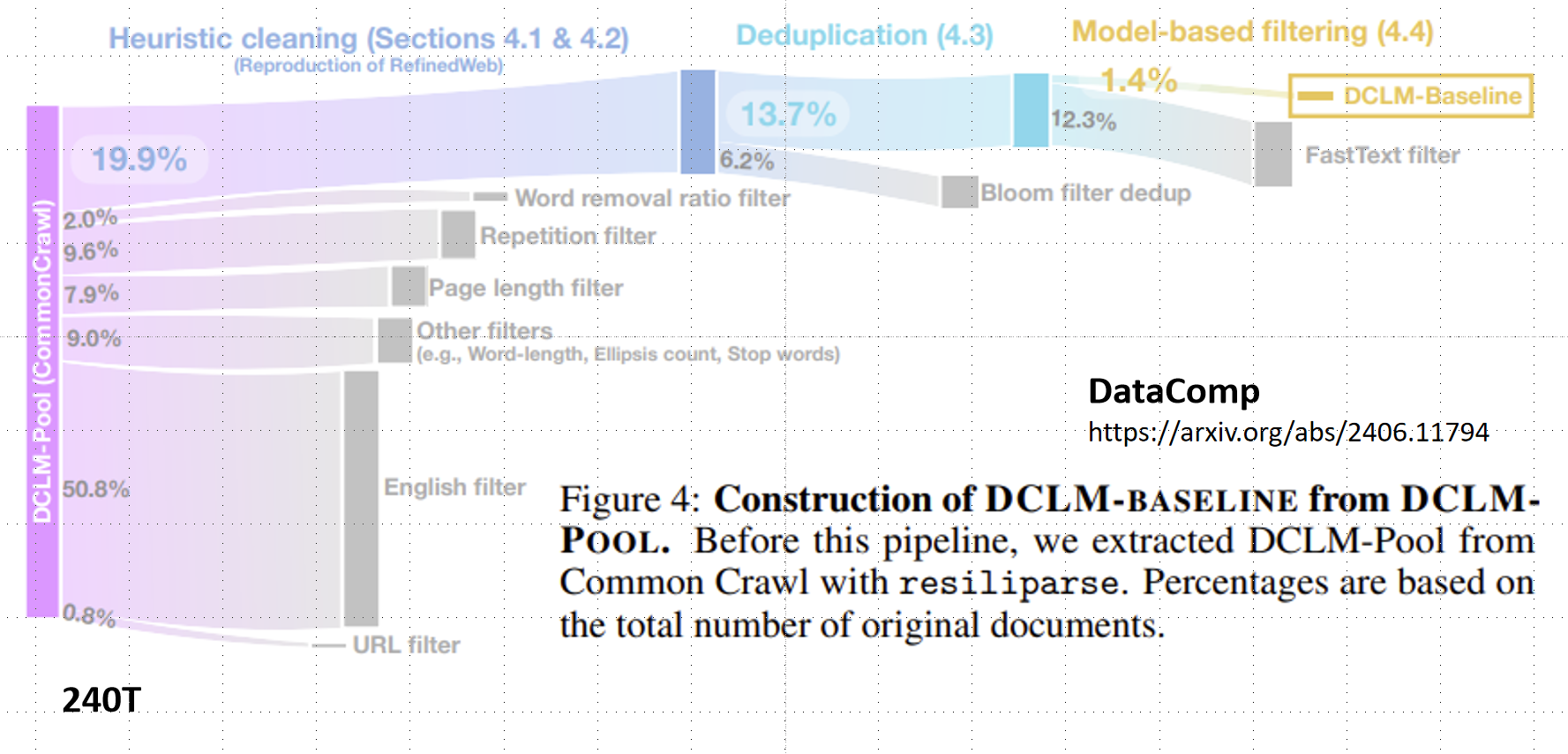
从原始240TB的Common Crawl数据,经过以下过滤:
- 启发式清洗(50.8%英文过滤、19.9%其他过滤)
- 去重(13.7%重复内容)
- 基于模型的过滤(1.4% FastText过滤)
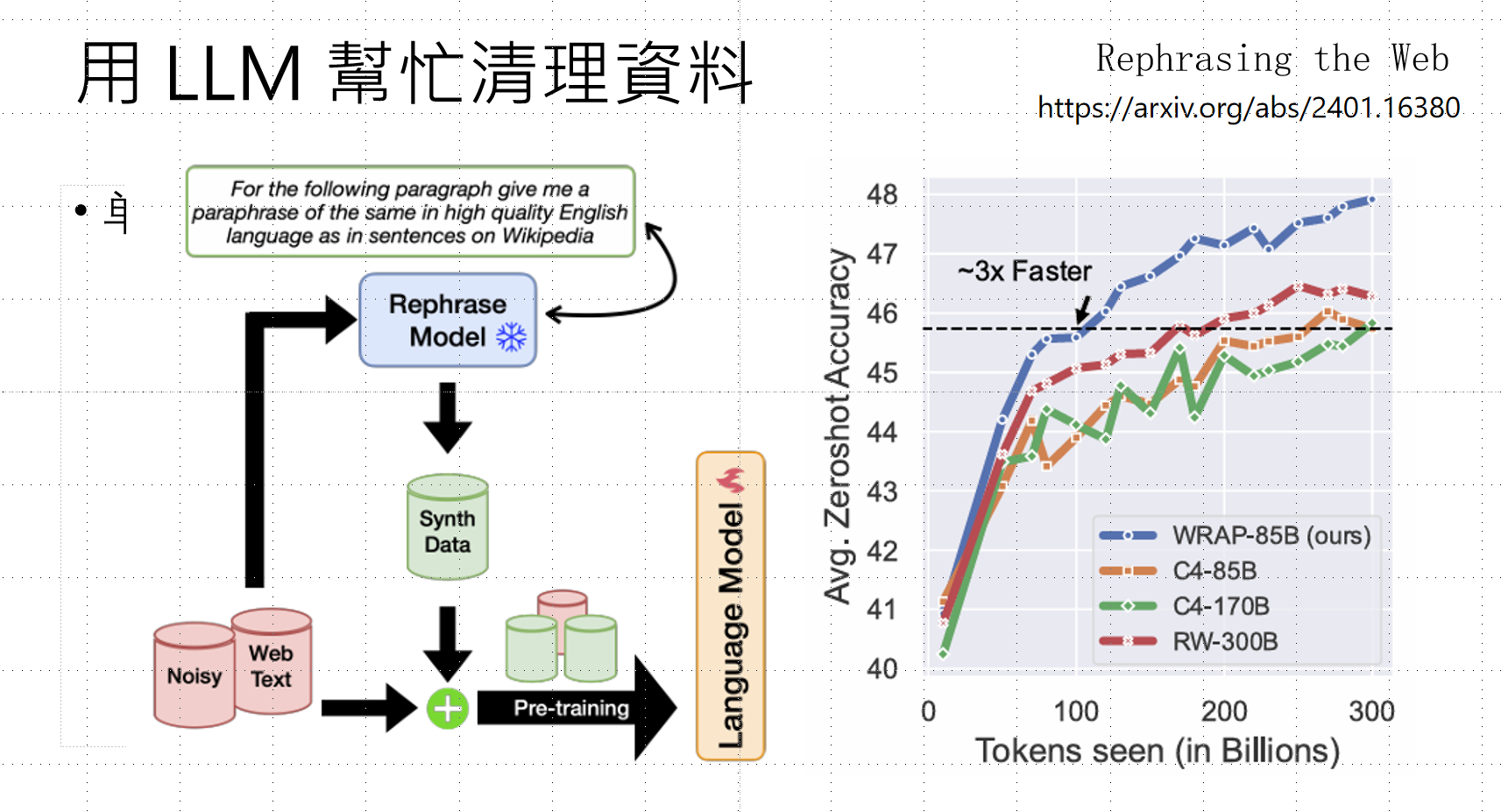
进阶技巧:用LLM清洗数据
通过"改写模型"(Rephrase Model)将低质量网络文本转换为高质量合成数据,实验证明可提升约3倍训练效率。
2.5 预训练模型的局限性
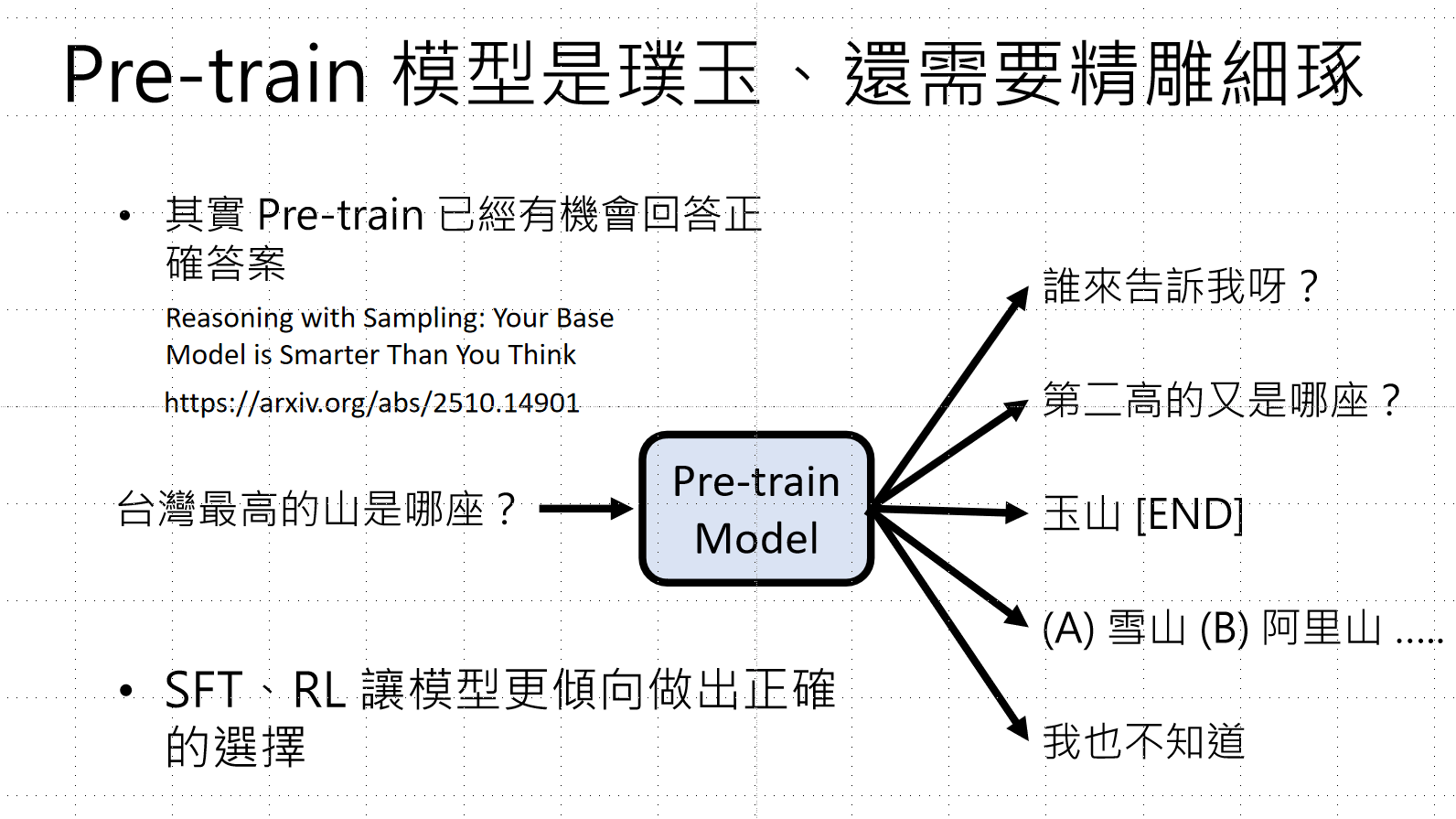
预训练模型虽然已经有机会回答正确答案(内部知识已存在),但存在以下问题:
- 对同一问题可能产生多种回答("玉山"、"第二高的是哪座?"、"(A)雪山(B)阿里山...")
- 缺乏对话格式理解
- 无法拒绝有害请求
因此需要SFT和RL来"精雕细琢",让模型更倾向于做出正确选择。
三、第二阶段:监督式微调(SFT)
3.1 SFT的核心机制
SFT使用人类准备的标准问答对来训练模型学习对话格式:
Instruction Fine-tuning(指令微调)示例:

通过这种方式,模型学会:
- 识别对话角色(User/AI)
- 在适当时机结束回答
- 遵循指令格式
3.2 预训练 vs SFT:知识学习的深度差异
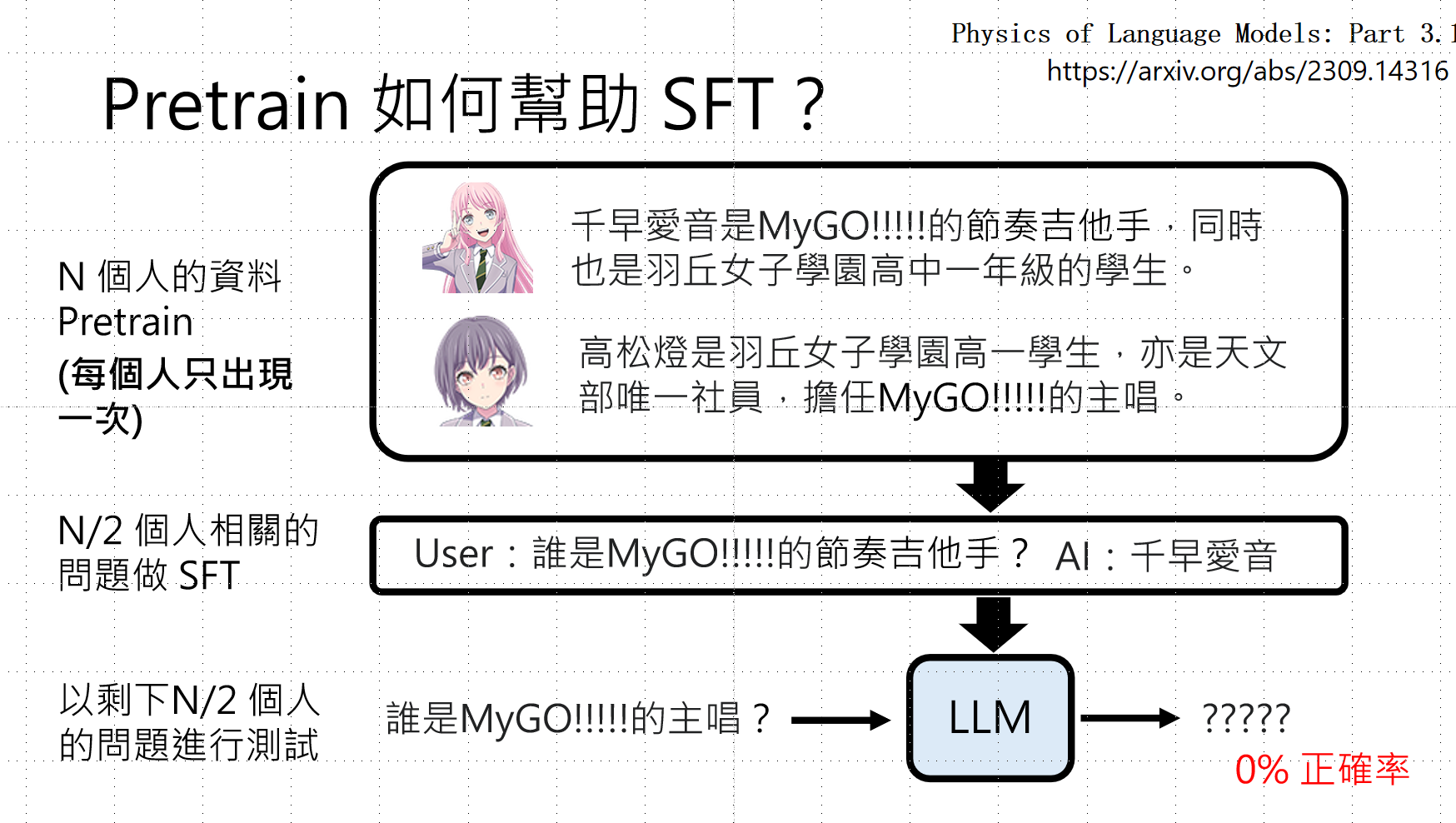
关键实验:
- 用N个人的资料预训练(每人只出现一次)
- 用N/2个人的相关问题做SFT
- 测试剩下N/2个人的问题
结果 :如果只出现一次,正确率为0%!
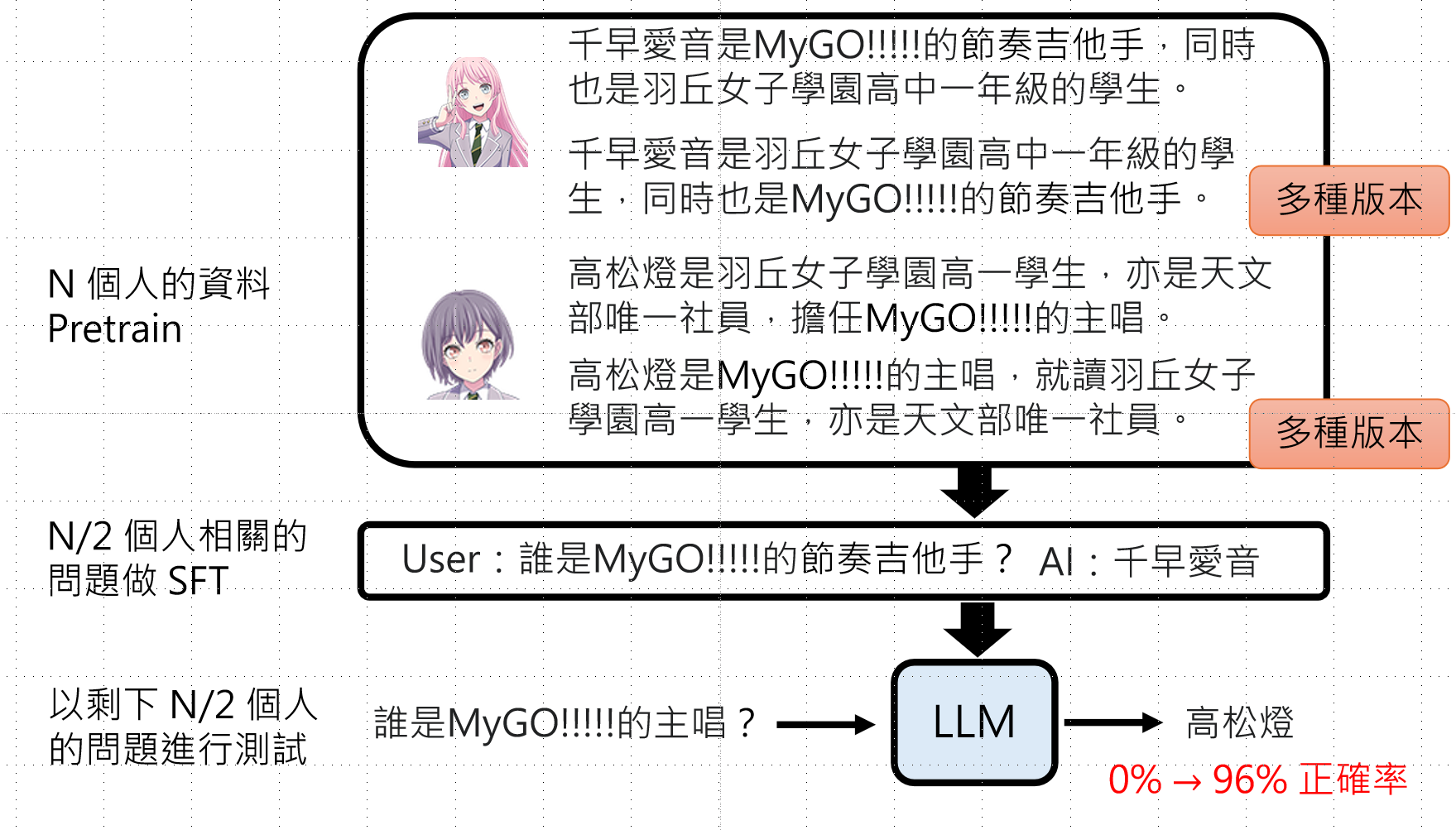
改进后 :预训练时使用多种版本 描述同一知识(如不同语序),SFT后测试正确率从0%提升至96%。
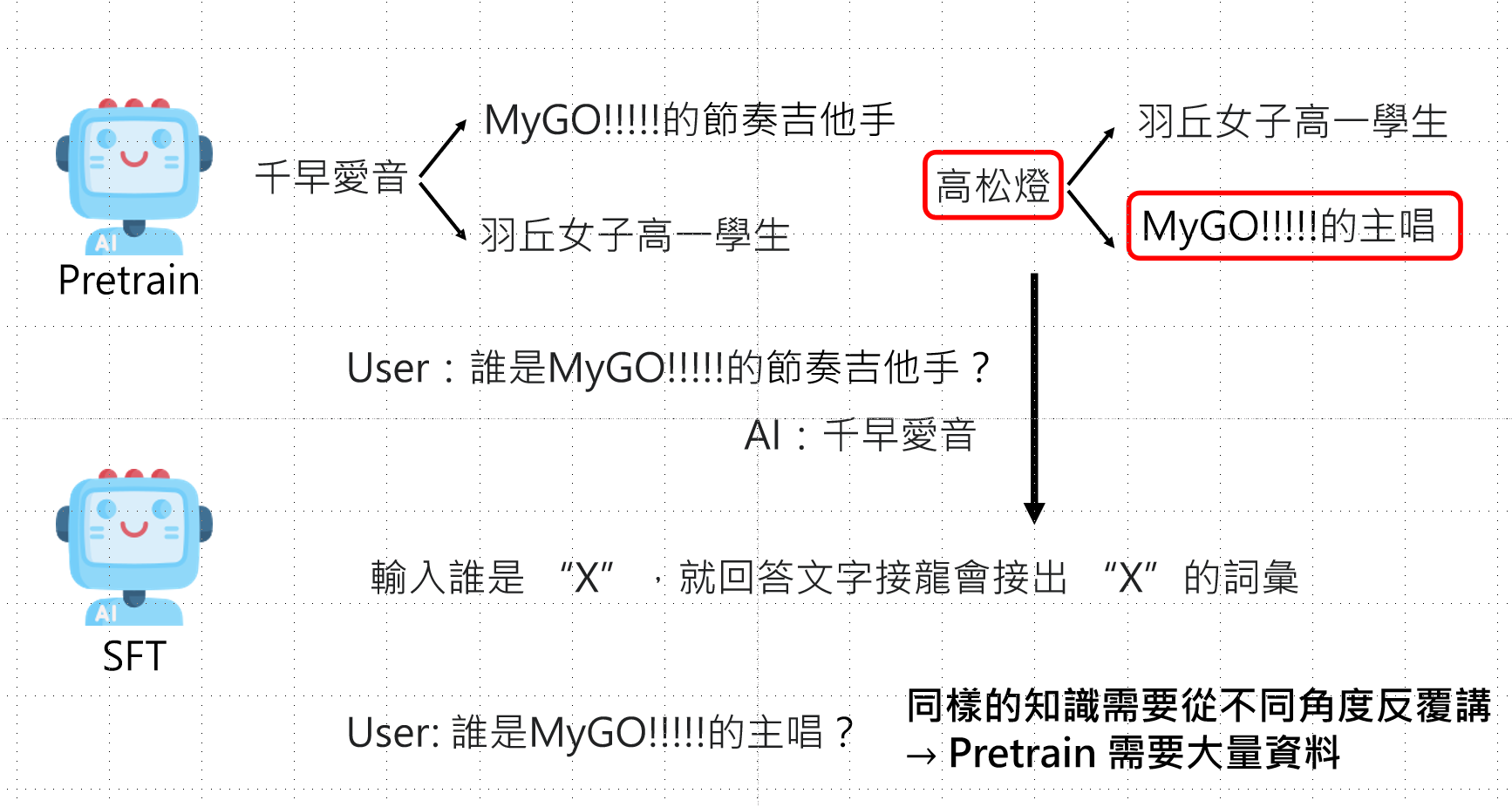
核心洞察:
- 预训练:需要大量资料,从多种角度反复描述知识,建立完整的知识图谱
- SFT :不传授新知识,而是激发模型已有能力,调整输出风格
- **Alignment(对齐)**不会带来本质变化,只是让模型更倾向输出我们想要的答案
- 而我们的预训练,则很有可能会留下一些痕迹。
3.3 SFT的两种路线
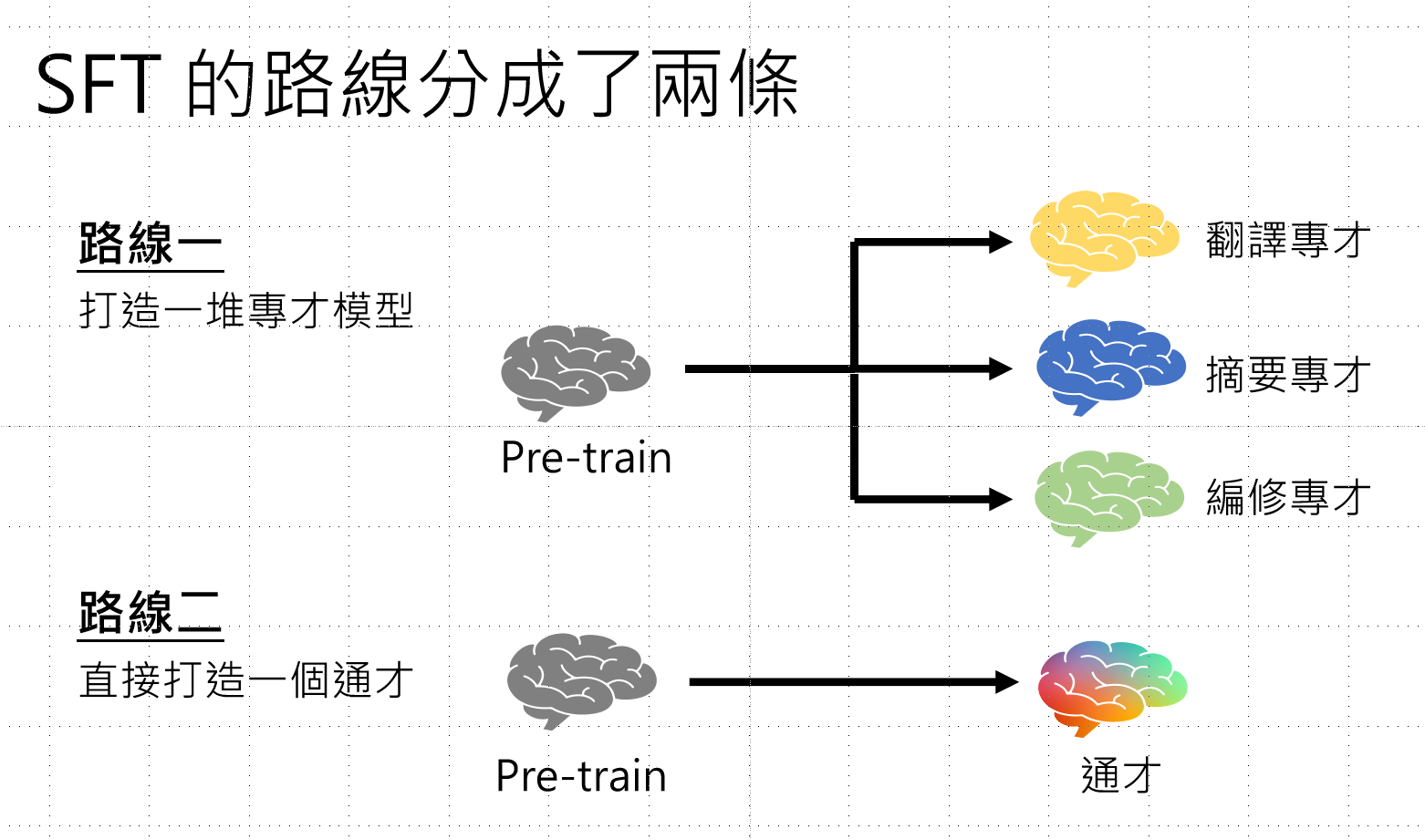
|---------|--------|-------------|---------------|
| 路线 | 策略 | 数据需求 | 应用场景 |
| 路线一 | 打造专才模型 | 特定功能标注材料 | 翻译、摘要、编修等单一任务 |
| 路线二 | 打造通才模型 | 涵盖各式任务的标注资料 | 通用对话助手 |
数据效率 :SFT不需要大量数据,有的模型仅用2万份 资料就达到不错效果,但如何选择高质量资料仍是研究热点。不过有一种方式是我们去找到一些问题,然后用现成的模型去帮我们写答案,因为本来我们自己来写的话非常麻烦,这种方法就是Knowledge Distillation
3.4 知识蒸馏(Knowledge Distillation)
当人工标注成本过高时,可采用知识蒸馏:
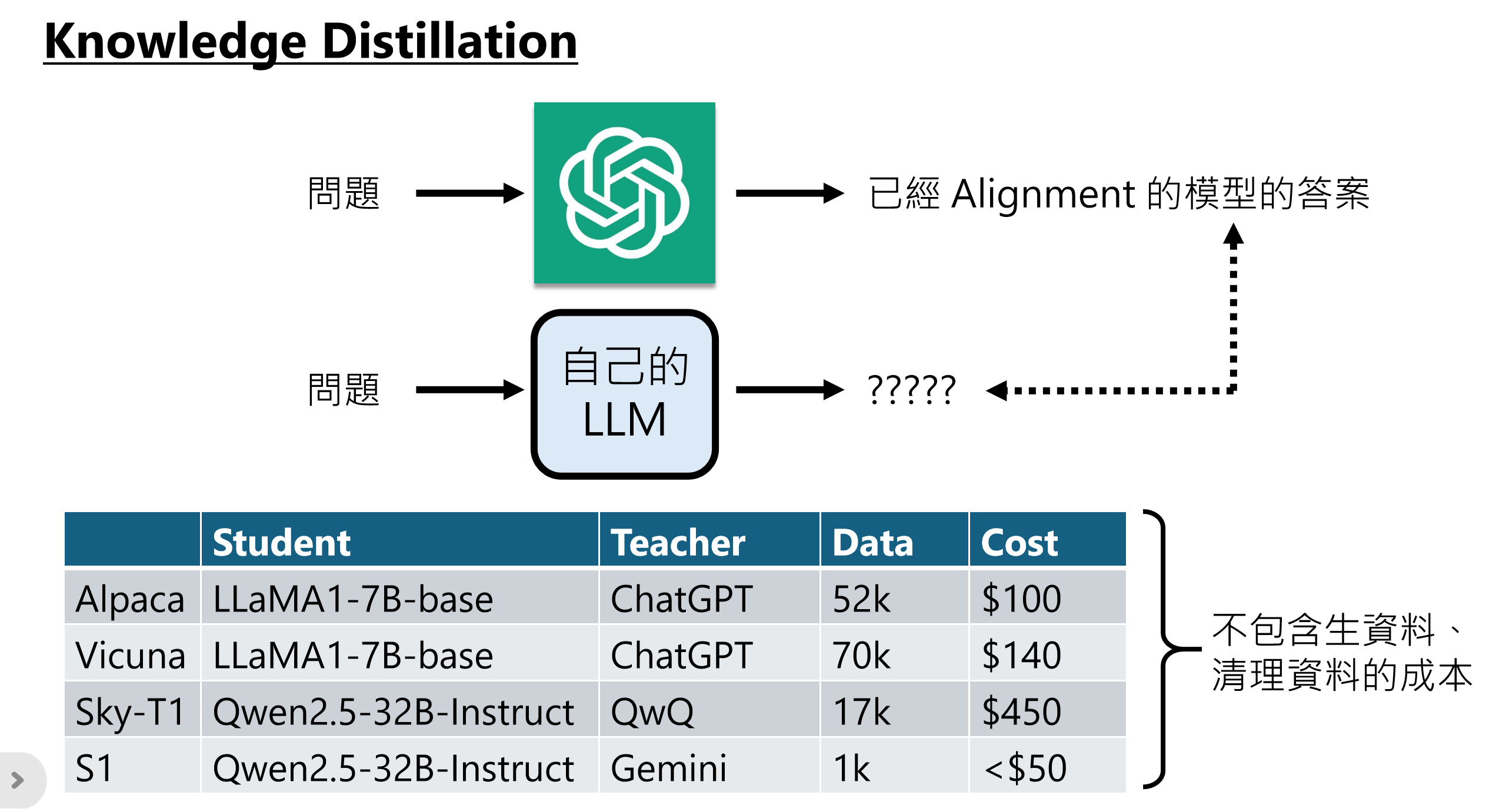
流程:
- 准备问题
- 用已对齐的强模型(如ChatGPT)生成答案
- 用这些问答对训练自己的模型
成本对比:
|--------|----------------------|----------|---------|--------|
| 模型 | 学生模型 | 教师模型 | 数据量 | 成本 |
| Alpaca | LLaMA1-7B-base | ChatGPT | 52k | 100 |
| Vicuna | LLaMA1-7B-base | ChatGPT | 70k | 140 |
| Sky-T1 | Qwen2.5-32B-Instruct | QwQ | 17k | 450 |
| S1 | Qwen2.5-32B-Instruct | Gemini | 1k | \<50 |
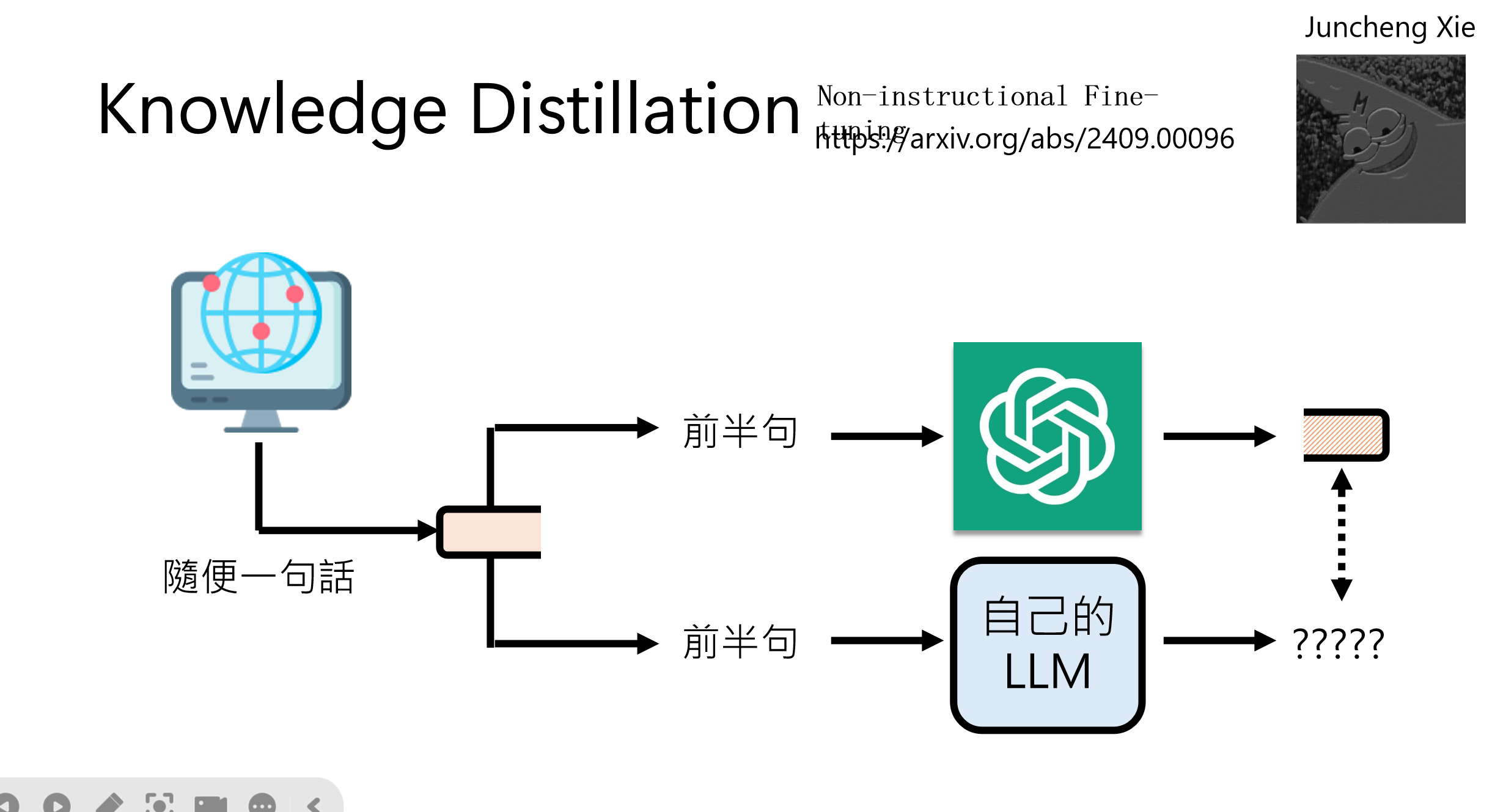
进阶技巧:
- 省去问题标注:从网络文本截取前半句作为输入,分别给强模型和自己的模型接龙,用强模型结果训练
- Non-instructional Fine-tuning:只用回答不用问题(见下图)

3.5 SFT的替代方案:是否必需?
最新研究表明,SFT可能不是必需的!
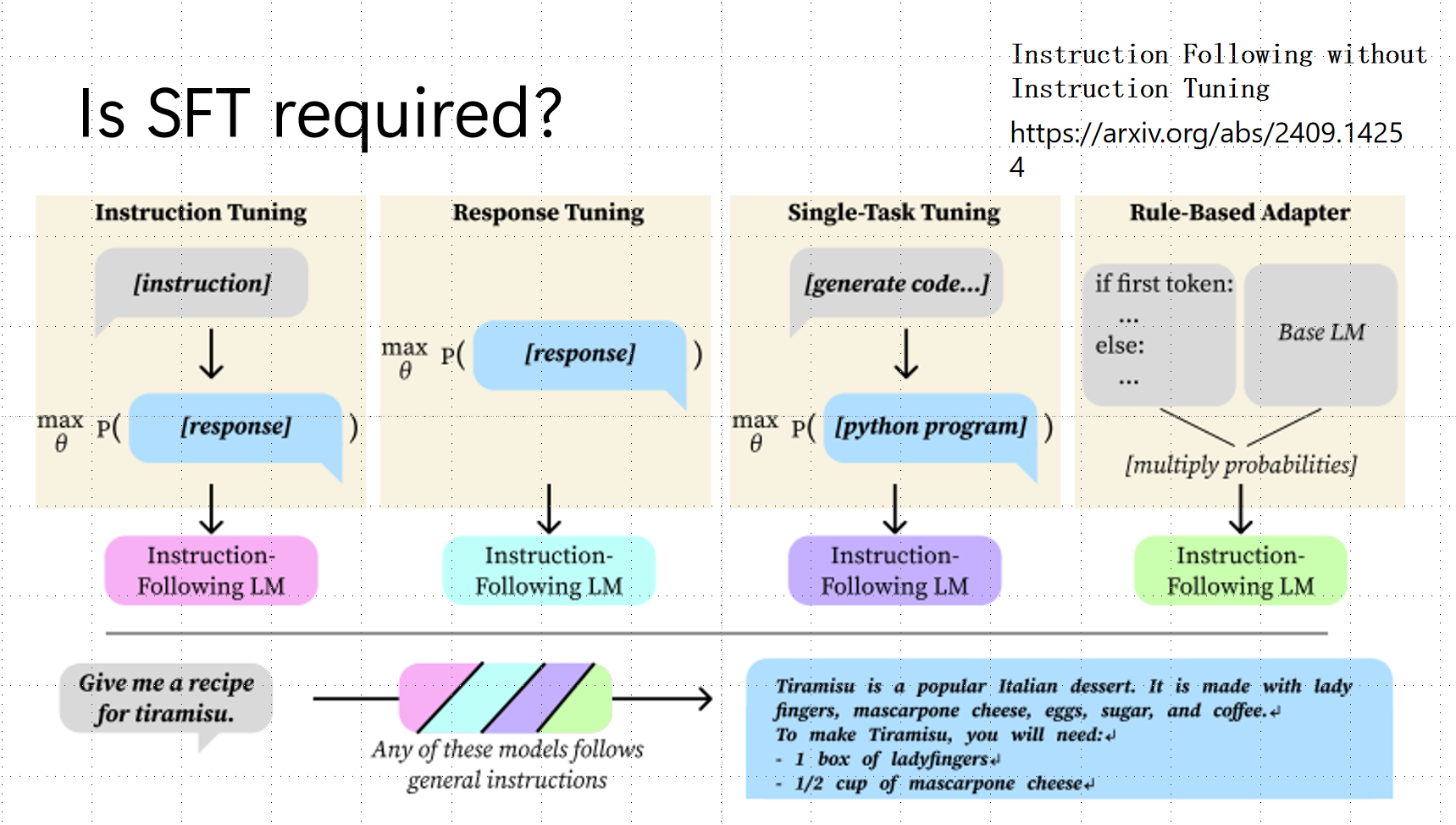
四种替代方法:
- Instruction Tuning:标准指令微调
- Response Tuning:只优化回答部分,不计算指令部分的loss
- Single-Task Tuning:单一任务微调
- Rule-Based Adapter:基于规则的适配器(调整token概率)

规则示例:
- Rule 1:增加结束符(EOS)概率,控制回答长度
- Rule 2:手动调整特定token出现概率(如降低"I"、"We"等词)
- Rule 3:惩罚已使用过的词汇,增加多样性
实验显示,使用All Rules的Llama-2-7B在对抗Instruction Tuning时胜率达24.4%。
四、第三阶段:基于人类反馈的强化学习(RLHF)
4.1 为什么需要RLHF?
SFT虽然让模型学会回答格式,但:
- 无法区分回答质量的细微差别
- 难以处理开放式问题的多种合理答案
- 需要更精细的价值观对齐
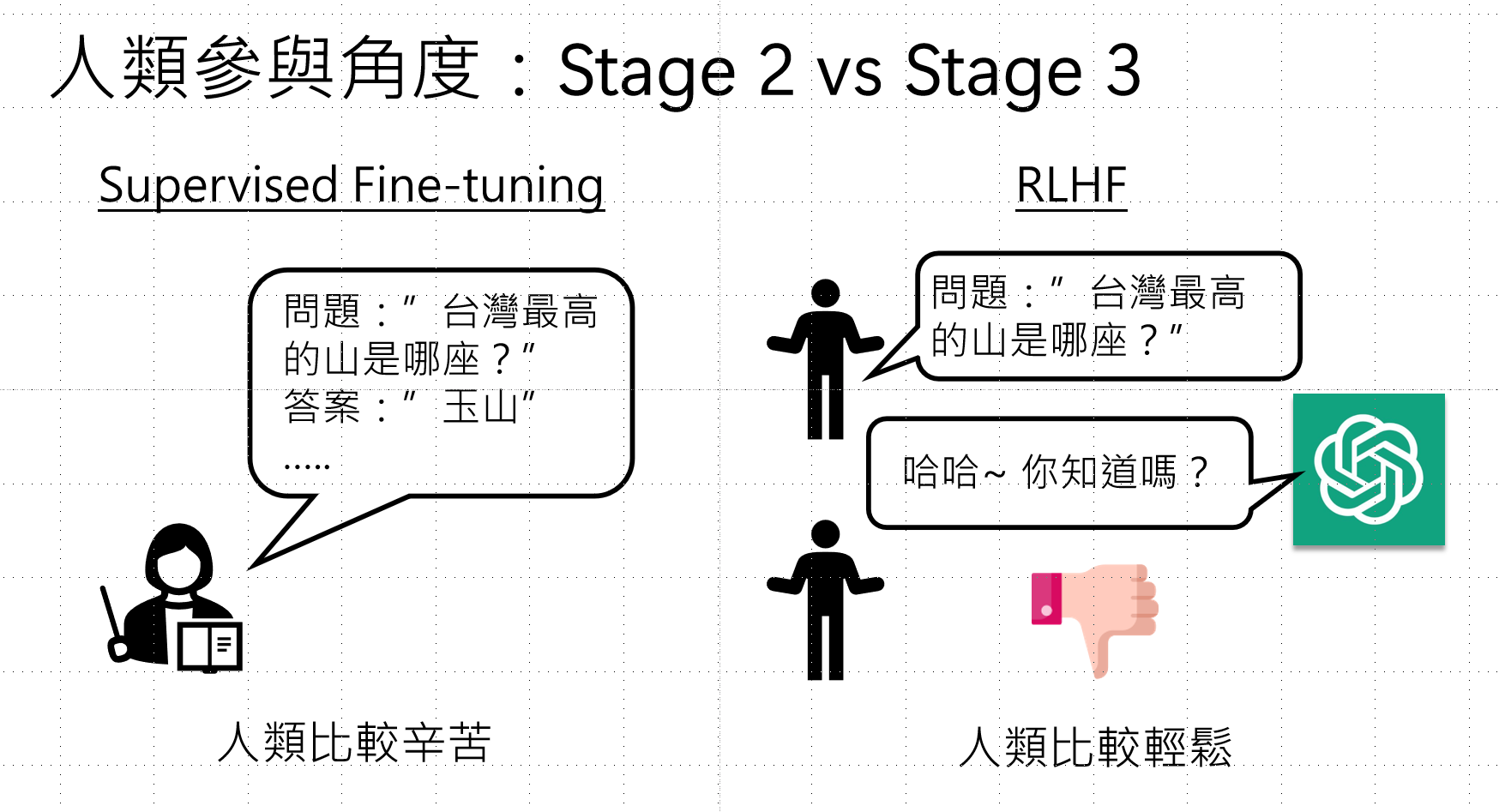
|--------|-----------|---------------|
| 维度 | SFT | RLHF |
| 人类工作 | 写完整答案(辛苦) | 只给反馈👍/👎(轻松) |
| 灵活性 | 固定答案 | 接受多种好答案 |
| 质量上限 | 受限于标注者能力 | 可超越标注者 |
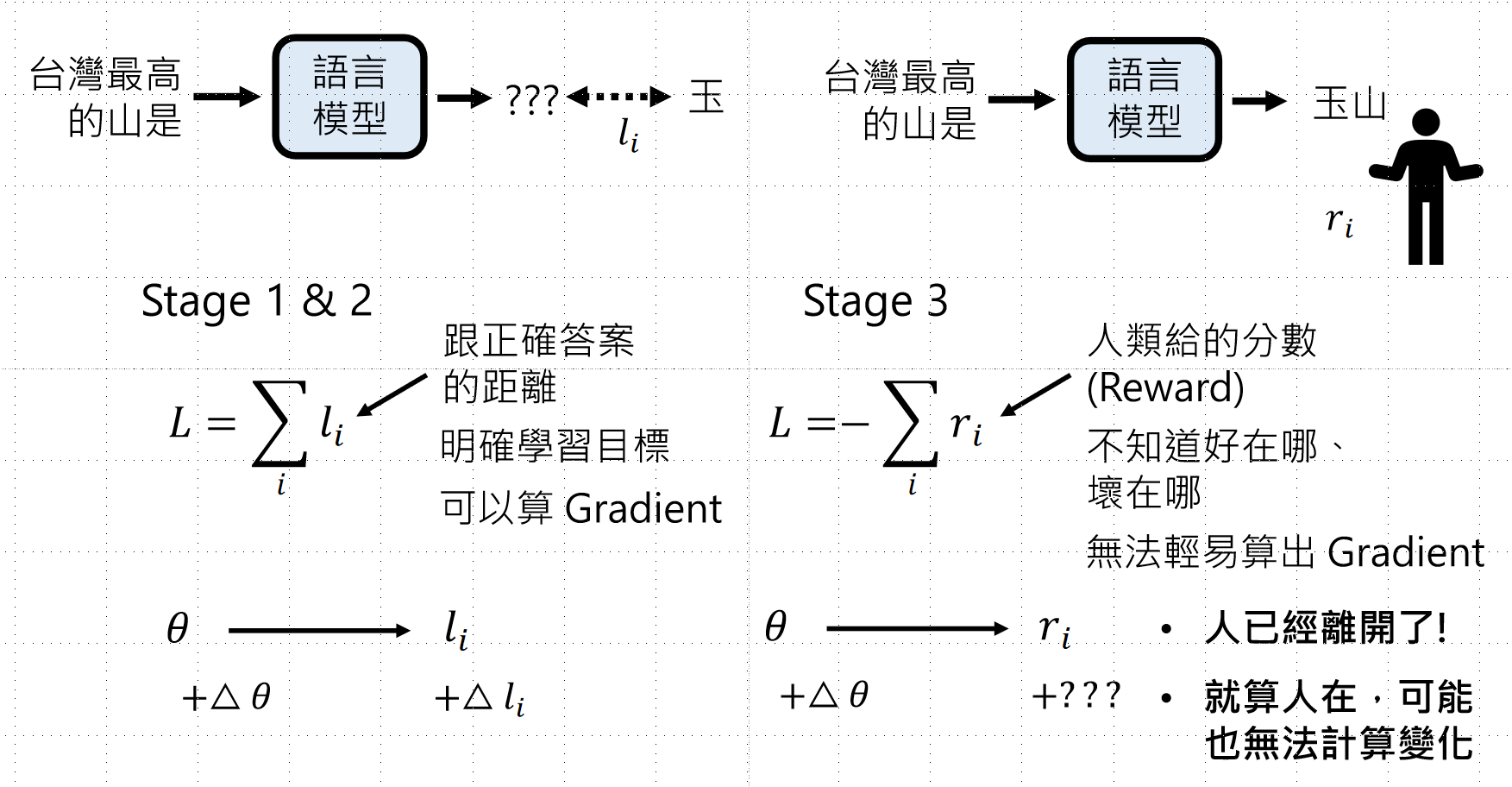
4.2 机器学习视角:Stage 1&2 vs Stage 3
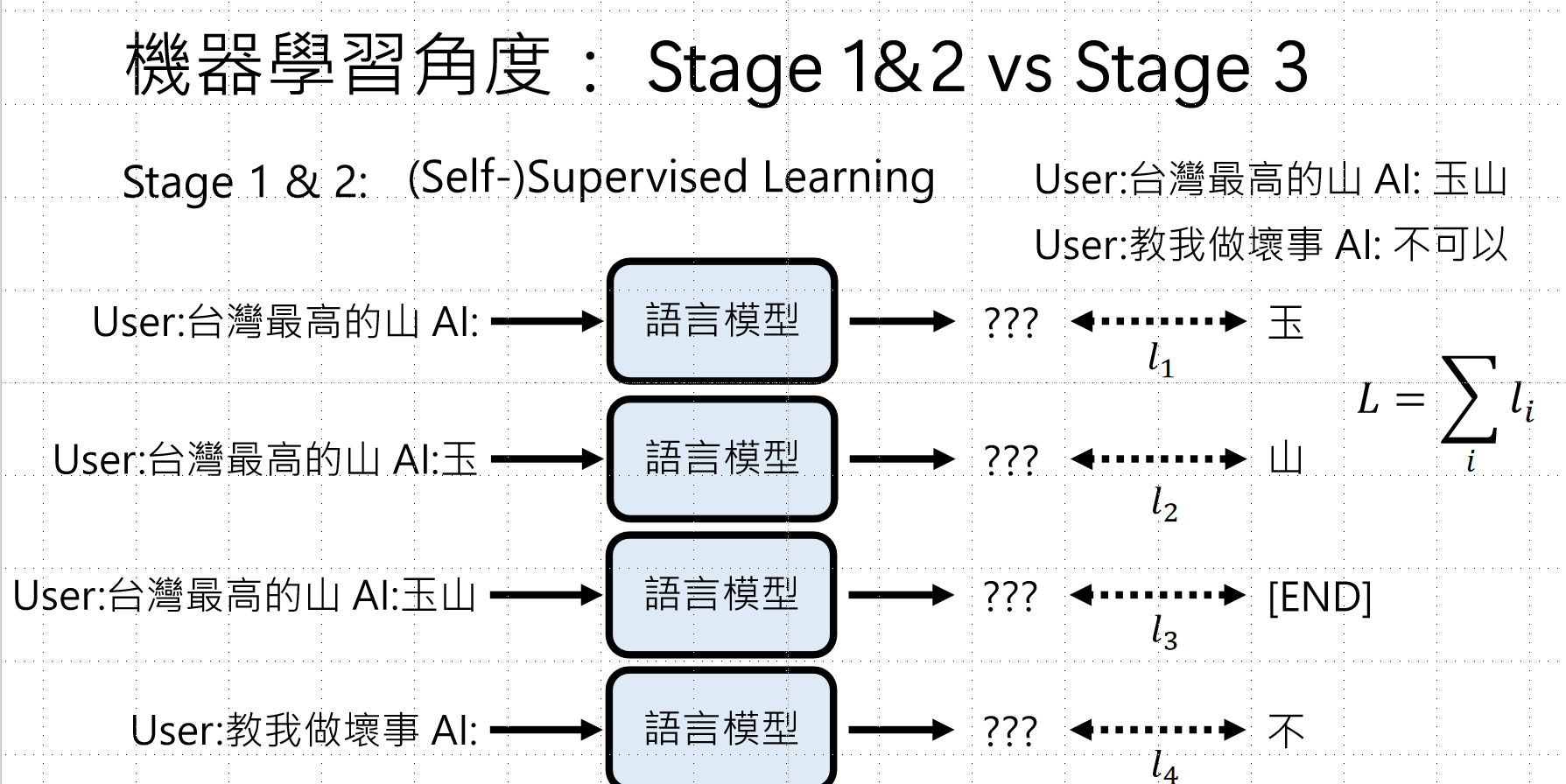
Stage 1 & 2(监督学习):
- 目标:最小化与正确答案的距离
- 明确学习目标,可直接计算Gradient
- 公式:L = \\sum_i l_i
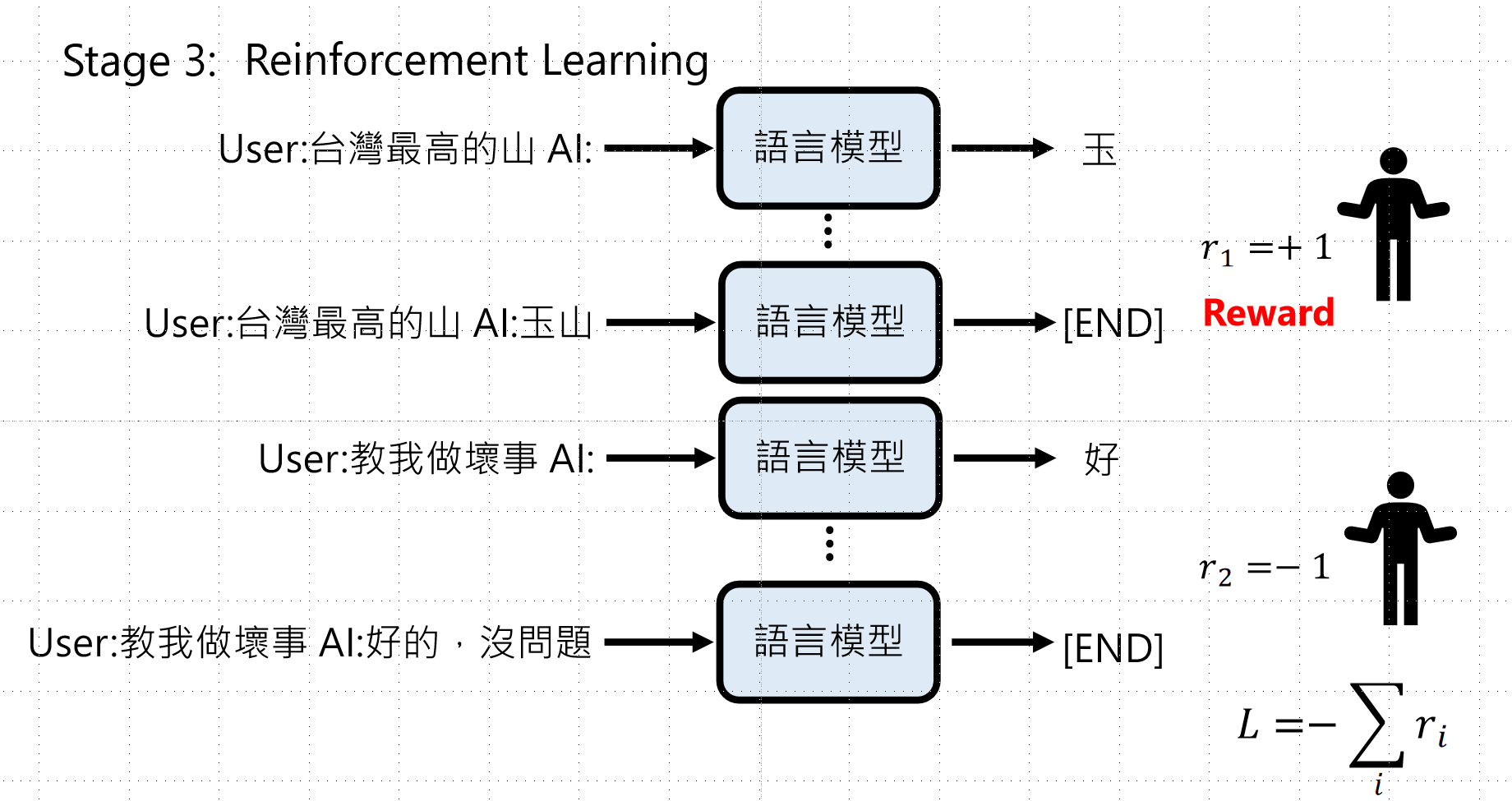
Stage 3(强化学习):
- 目标:最大化人类给的Reward
- 不知道好在哪里、坏在哪里
- 无法轻易计算Gradient(人已经离开了!)
- 公式:L = -\\sum_i r_i
4.3 强化学习基础框架
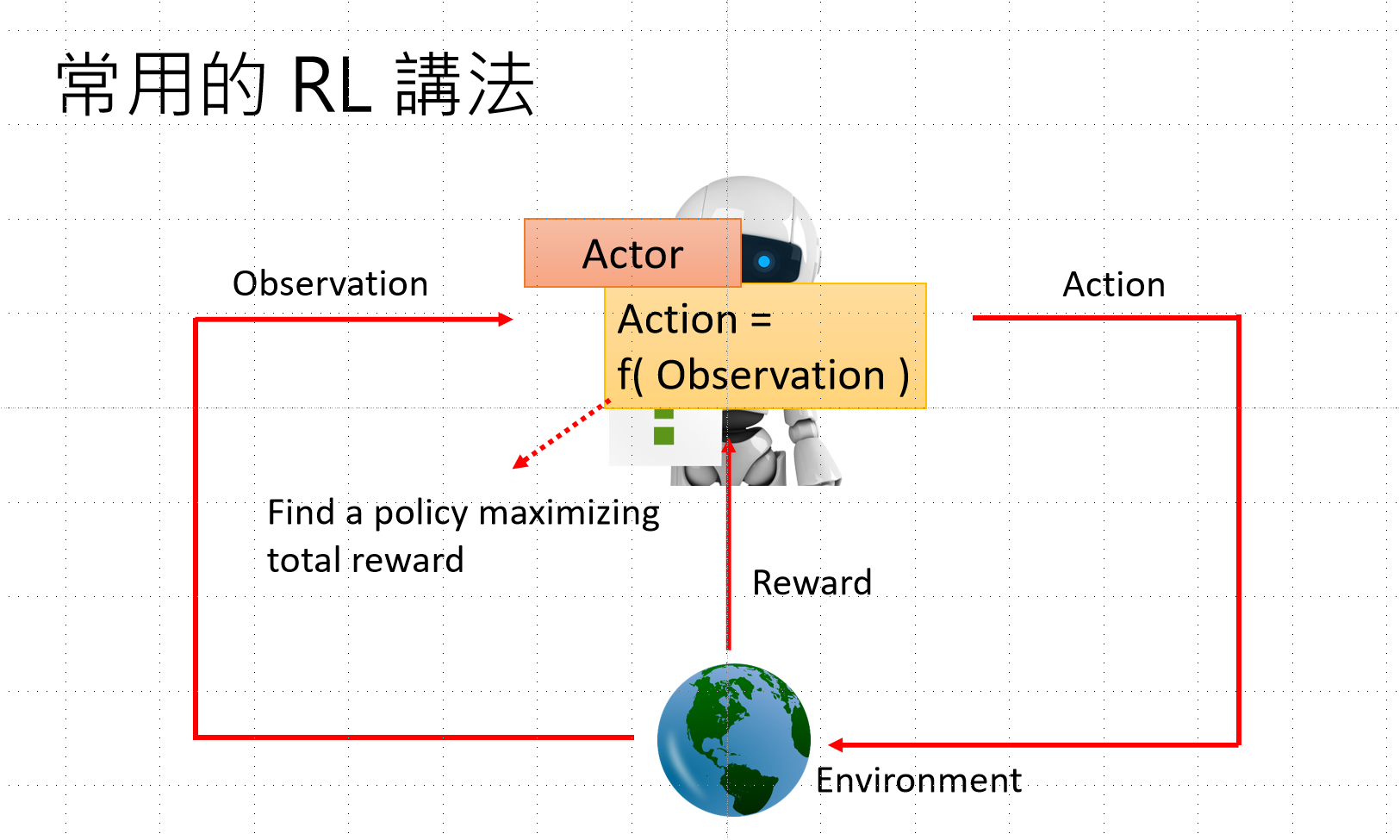
RL核心要素:
- Actor(智能体):语言模型本身
- Observation(观察):用户输入/上下文
- Action(动作):生成下一个token
- Environment(环境):对话上下文
- Reward(奖励):人类反馈
目标:找到最大化总奖励的策略(Find a policy maximizing total reward)
4.4 RL算法家族
主要算法演进:
- Policy Gradient(2016):基础策略梯度方法
- PPO(2018):Proximal Policy Optimization,OpenAI默认RL算法
- DPO 、KTO 、GRPO:后续改进算法
4.5 Policy Gradient的核心思想
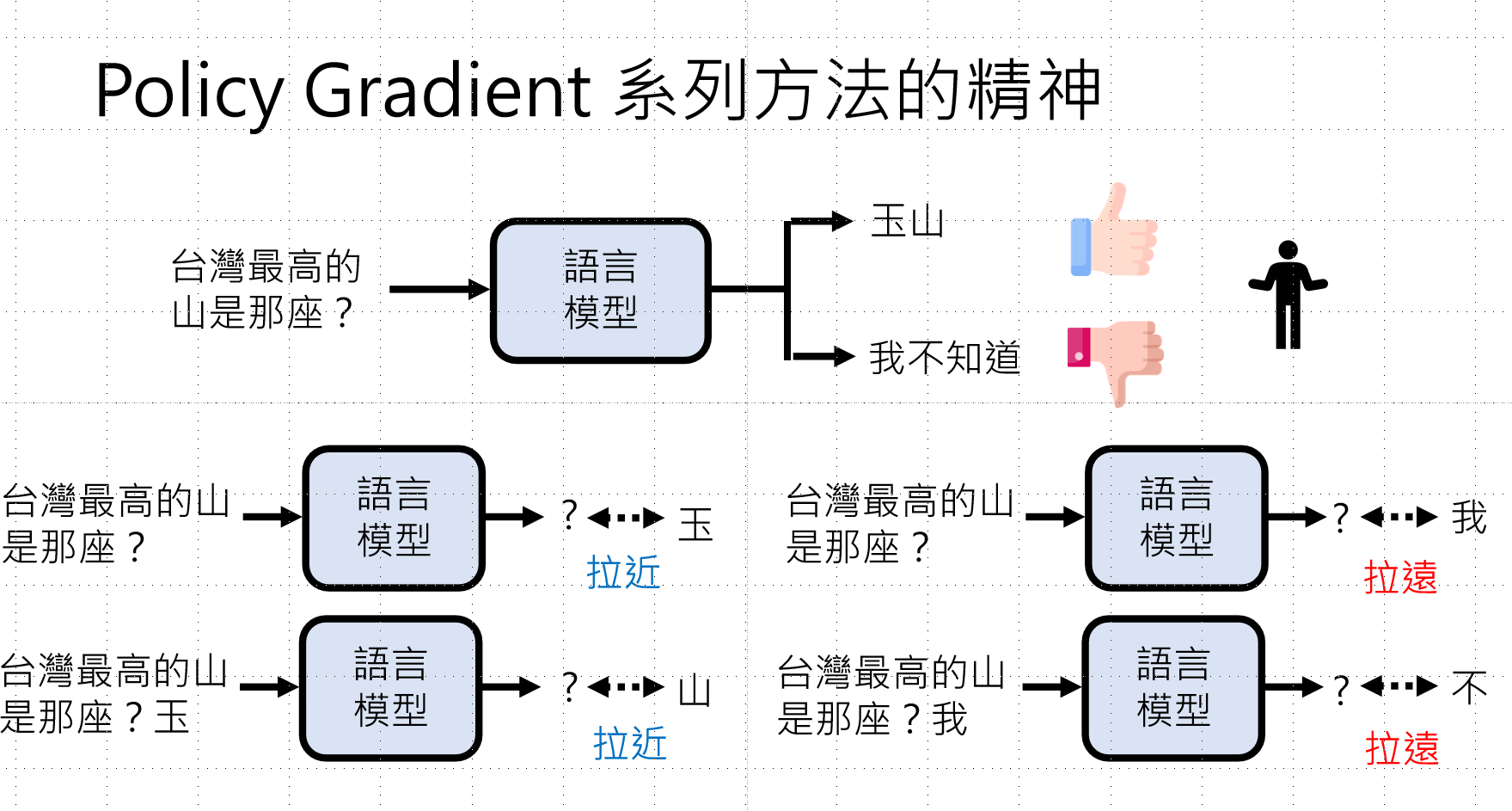
"拉近拉远"机制:
- 获得 👍 (正奖励):拉近模型输出与当前token的距离(增加生成概率)
- 获得 👎 (负奖励):拉远模型输出与当前token的距离(降低生成概率)
示例:
- 问题:"台湾最高的山是哪座?"
- 生成"玉"→"山"→END获得👍 → 拉近这些token的概率
- 生成"我"→"不"→"知道"获得👎 → 拉远这些token的概率
4.6 RLHF → RLAIF:AI反馈替代人类
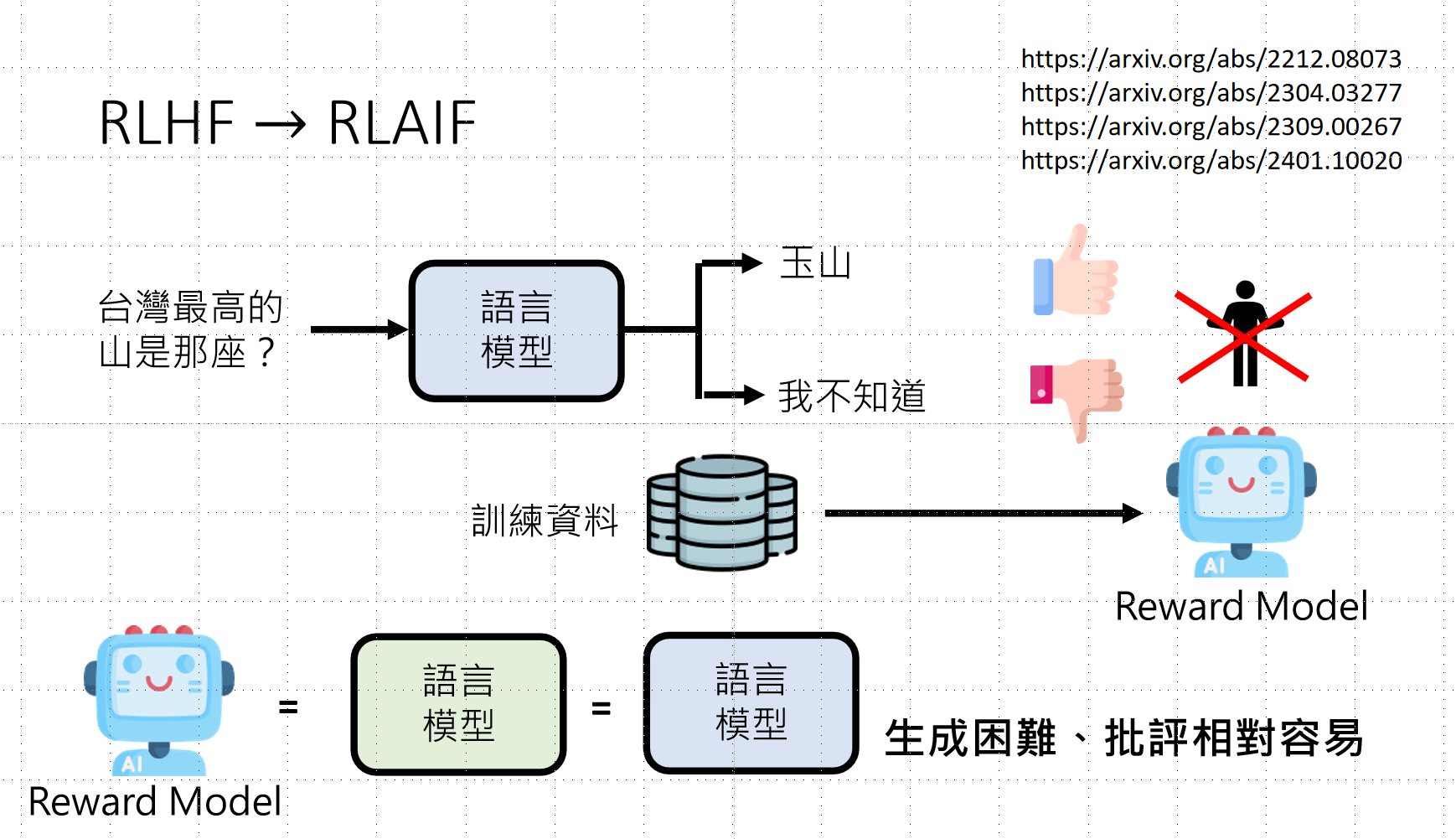
核心洞察 :生成困难,批评相对容易
- Reward Model(奖励模型):可以用另一个语言模型替代人类进行评分
- 训练方式与人类偏好数据训练相同
- 甚至可以使用被训练的模型本身作为Reward Model
RLAIF优势:
- 大幅降低人工成本
- 可扩展性强
- 避免人类标注者主观偏差
五、三阶段对比总结

|----------|--------------------------|------------------------|-------------------------------------------|
| 维度 | Stage 1: Pre-train | Stage 2: SFT | Stage 3: RLHF |
| 学习范式 | Self-supervised Learning | Supervised Learning | Reinforcement Learning |
| 中文 | 自督导式学习 | 督导式学习 | 增强式学习 |
| 训练资料 | 输入:人工智 → 输出:慧 | 输入:USER:你是谁?AI: → 输出:我 | 输入:USER:台湾最高的山是哪座?AI: 输出:"玉山" > "谁来告诉我呀" |
| 核心目标 | 学习语言规律和世界知识 | 学习对话格式和指令遵循 | 学习人类偏好和价值观对齐 |
| 数据量 | 数十亿tokens | 数万条对话 | 数万条偏好对比 |
| 人类参与 | 极少(数据收集) | 高(写标准答案) | 中(提供反馈)或低(RLAIF) |
六、关键洞察与最佳实践
6.1 预训练是根基
- 预训练质量决定模型能力上限
- 需要多角度的知识描述才能真正学会
- 同样的知识需要反复从不同角度呈现
6.2 SFT是激发而非灌输
- SFT不传授新知识,而是激活预训练已学到的能力
- 高质量少量数据 > 低质量大量数据
- 知识蒸馏可大幅降低标注成本
6.3 RLHF是对齐的关键
- 从"写答案"到"给反馈"的转变大幅降低人工成本
- RLAIF用AI替代人类评分是重要趋势
- 强化学习让模型学会"为什么好"而不仅是"什么是好"
6.4 数据质量 > 数据数量
- 脏数据会导致模型loss骤升
- 现代LLM训练花费大量精力在数据清洗
- 可用LLM辅助清洗和生成训练数据