研究团队: 本工作由华中科技大学(Huazhong University of Science and Technology)与百度(Baidu Inc.)联合完成。
作者列表:Xianjin Wu, Dingkang Liang, Tianrui Feng, Kui Xia, Yumeng Zhang, Xiaofan Li, Xiao Tan, Xiang Bai。

-
论文标题:Generation Models Know Space: Unleashing Implicit 3D Priors for Scene Understanding
核心问题:视频生成模型真的理解世界吗?
生成模型,到底能不能理解世界,或者说,它们能否促进对世界的理解?这是我们在推进 Generation Models Know Space 这项研究时,最核心的出发点。
过去在 3D 场景理解这个领域,我们往往习惯于一种思维定势:如果要让模型懂空间,就必须给它显式的 3D 数据,比如点云,或者在系统里硬塞进复杂的几何重建模块。这就导致整个理解链路非常沉重,而且严重受限于高质量的三维标注数据。
但当我们观察这两年飞速发展的视频生成模型时,我们意识到了一个常常被忽视的事实。当一个模型能够自然地生成一段视角切换、包含复杂遮挡关系的视频时,它其实已经在内部默默处理了深度、透视和物理距离。如果它不懂三维几何,生成的画面早就崩塌成了一堆混乱的像素。
所以 Motivation 变得非常清晰且直接:既然这些在大规模无标注视频上训练出的生成模型,为了造出逼真的画面,已经偷偷掌握了物理世界的空间逻辑,我们为什么还要舍近求远,去重新教理解模型学几何?
这篇论文提出了 VEGA-3D,旨在释放深藏于生成大模型内部的 3D 先验知识。研究表明,生成模型不仅是一个高超的"画师",更像是一个开箱即用的"空间知识库"。它将物理规律与几何结构压缩进参数之中,由生成任务催生出的隐式空间表征,具有很强的迁移能力,并能够直接服务于理解任务。
这不仅是一次技术路线的替换,更是一种研究范式的转变。我们不再将"生成"和"理解"视作彼此平行的两条轨道。尤其在具身智能场景下,当机器人需要在复杂物理空间中完成感知、推理与交互时,模型对三维环境的尺度感、几何直觉和空间一致性的把握,往往正是关键瓶颈。而借助生成模型反哺理解,则为突破这一瓶颈提供了一条极具潜力的新路径。
基于这一思路,来自华中科技大学与百度的联合团队设计了 VEGA-3D 框架,用于系统挖掘并利用生成模型中的空间先验,从而提升模型在场景理解、空间推理与具身任务中的表现。
它把物理法则压缩在了自己的参数里,这种为了生成而被迫建立的隐式空间表征极其强大,且可以直接迁移到理解任务中。在具体实现上,VEGA-3D 将视频生成模型(如 Wan2.1)作为 "潜在世界模拟器",通过自适应门控机制,将生成模型在中间去噪阶段展现出的纯粹 3D 结构先验,与原有的语义特征进行优雅融合。
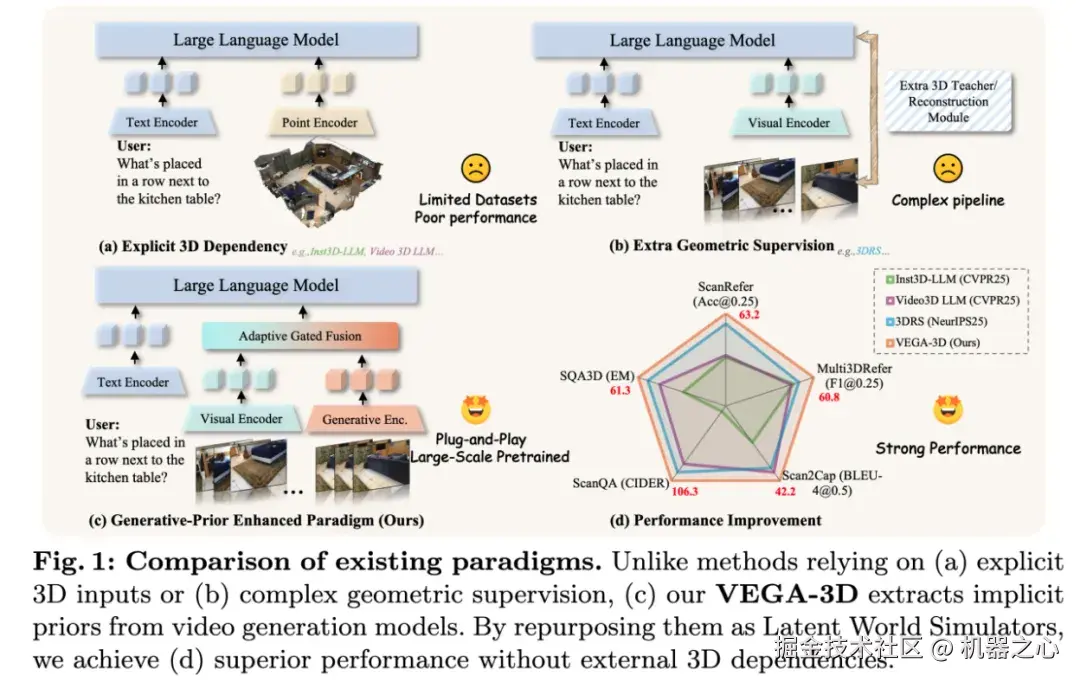
Figure 1 摒弃复杂的 3D 依赖和几何监督,VEGA-3D 开创了生成先验增强的新范式。
为什么视频生成模型能懂 3D?因为要生成一段符合常理、时间连贯的视频,生成模型在内部必然学会了物体遮挡、相机运动带来的视差以及交互物理法则。VEGA-3D 的核心创新就在于如何 "榨干" 这股隐式力量:
- 将视频生成模型作为 "潜在世界模拟器"
摒弃了只用生成模型 "画图" 的常规思路,VEGA-3D 将冻结的视频扩散模型引入视觉流。为了彻底激活其内部的几何结构认知,研究团队通过在其前向过程中注入特定水平的噪声(Noise Injection),提取其在中间去噪阶段和中间网络层(如 DiT layer 20)的时空特征。此时的特征,完美平衡了底层纹理与高层抽象,蕴含着最纯粹的 3D 结构先验。
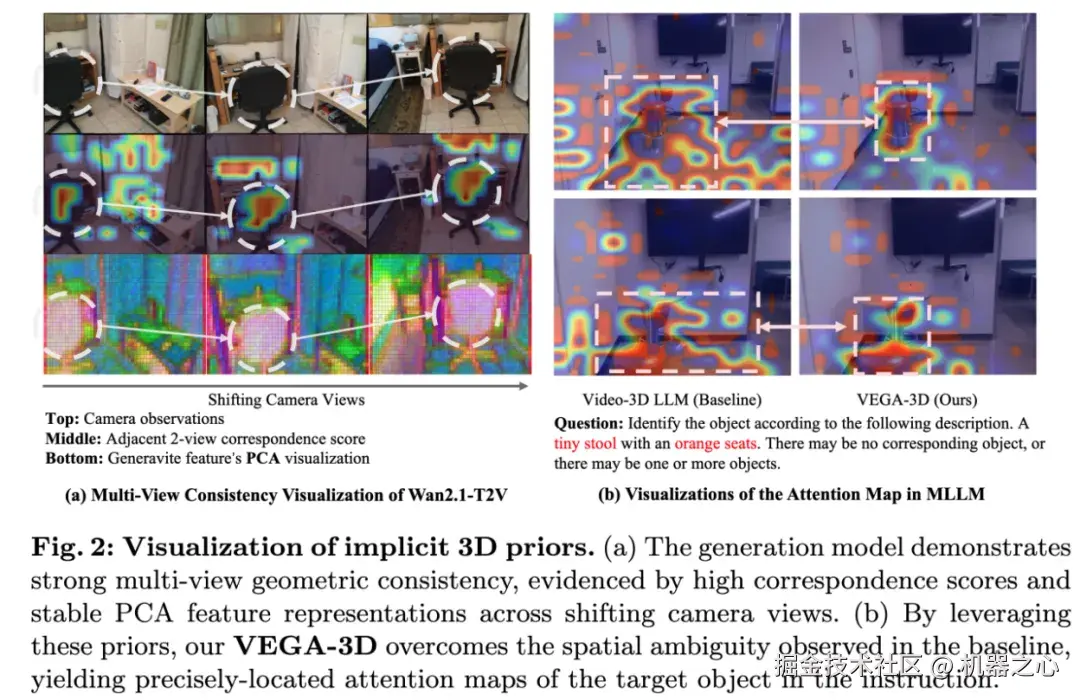
Figure 2 可视化证明,Wan2.1 在不同视角下展现出惊人的多视角几何一致性。结合 VEGA-3D,大模型的注意力图瞬间精准锁定了目标物体,彻底告别 "空间盲区"。
- Token 级自适应门控融合
连续的物理生成特征与离散的语义特征天然存在 "语义 - 几何鸿沟"。如果简单粗暴地相加,只会导致信号冲突。 VEGA-3D 独创了自适应门控融合机制:对于每一个空间 Token,网络会动态计算一个权重门控,让模型在回答 "这是什么"(依赖语义先验)和 "它在哪里"(依赖生成空间先验)时,自适应地调节两股特征的比例,实现真正的优势互补。
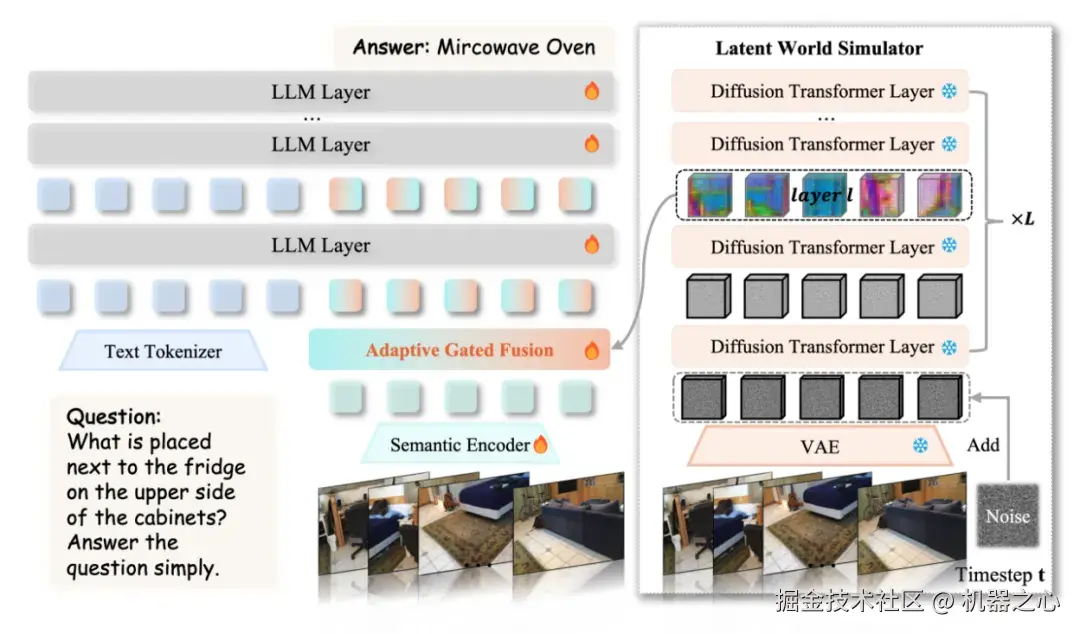
Figure 3VEGA-3D 极简而优雅的架构设计,即插即用,双流视觉编码。
深度剖析:为什么 "多视角一致性"
是解锁空间认知的密钥?
评价一个模型是否真正理解真实物理世界,关键在于其能否在不同视角下保持几何结构的一致性。为了揭示这一底层逻辑,我们对特征域进行了深入分析。
实验表明,多视角一致性得分与下游 3D 理解任务的归一化综合得分(NOS)呈现出极其显著的正相关。传统的判别式模型在应对 3D 任务时往往会遇到瓶颈:例如 DINOv3-Large 和 V-JEPA v2 的一致性得分分别为 61.90% 和 72.00%。即便是专门针对 3D 提取的判别模型 VGGT,其一致性得分也仅达到 77.21%。这说明传统的降维压缩过程不可逆地丢失了密集的物理与几何细节。
相反,以 Wan2.1 为代表的视频生成大模型展现出了降维打击般的空间理解力。Wan2.1-VACE 和 Wan2.1-T2V 的多视角一致性得分分别飙升至惊人的 97.04% 和 96.88%。这意味着,为了 "不穿帮" 地生成连贯视频,DiT 架构被迫在脑海中构建了极其鲁棒的 3D 物体结构。当 VEGA-3D 将这股强大的隐式先验释放出来时,它为多模态大模型提供了一个坚实的 "空间锚点",直接驱动了下游性能的暴涨。
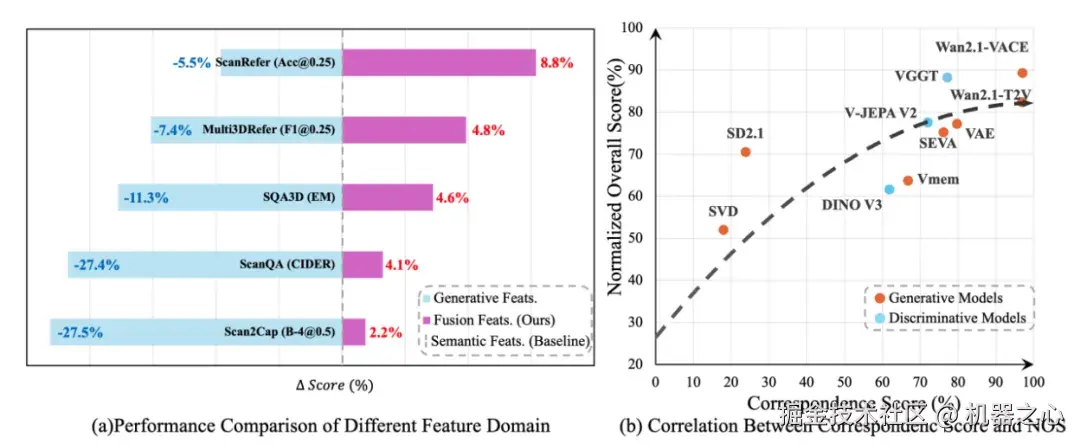
Figure 4 多视角一致性得分与下游 3D 理解性能呈强正相关,DiT 架构的生成模型完胜传统判别式模型
实验结果:
依靠这套机制,VEGA-3D 展现出了出色下游任务统治力,并且这一切提升都不需要任何额外的 3D 标注数据:
-
3D 场景理解全面领先:在 ScanRefer(视觉定位)、ScanQA(空间问答)等 5 个基准测试中,VEGA-3D 将原有基线模型(Video-3D LLM)的定位精度和准确率拉升至全新高度,ScanRefer Acc@0.5 从 51.7 大幅提升至 56.2。
-
空间推理无死角:在专门诊断模型视觉 - 空间技能的 VSI-Bench 上,引入 VEGA-3D 后的 Qwen2.5VL-7B 在相对距离、相对方向和路线规划等子任务上获得一致性暴涨。
-
赋能具身智能 (Embodied AI):更硬核的是,在 LIBERO 机器人仿真操作基准中,将生成先验注入到 OpenVLA 视觉流后,机器人在复杂物体交互和长视野(Long-horizon)任务上的成功率突破原有瓶颈,平均成功率达到 97.3%。
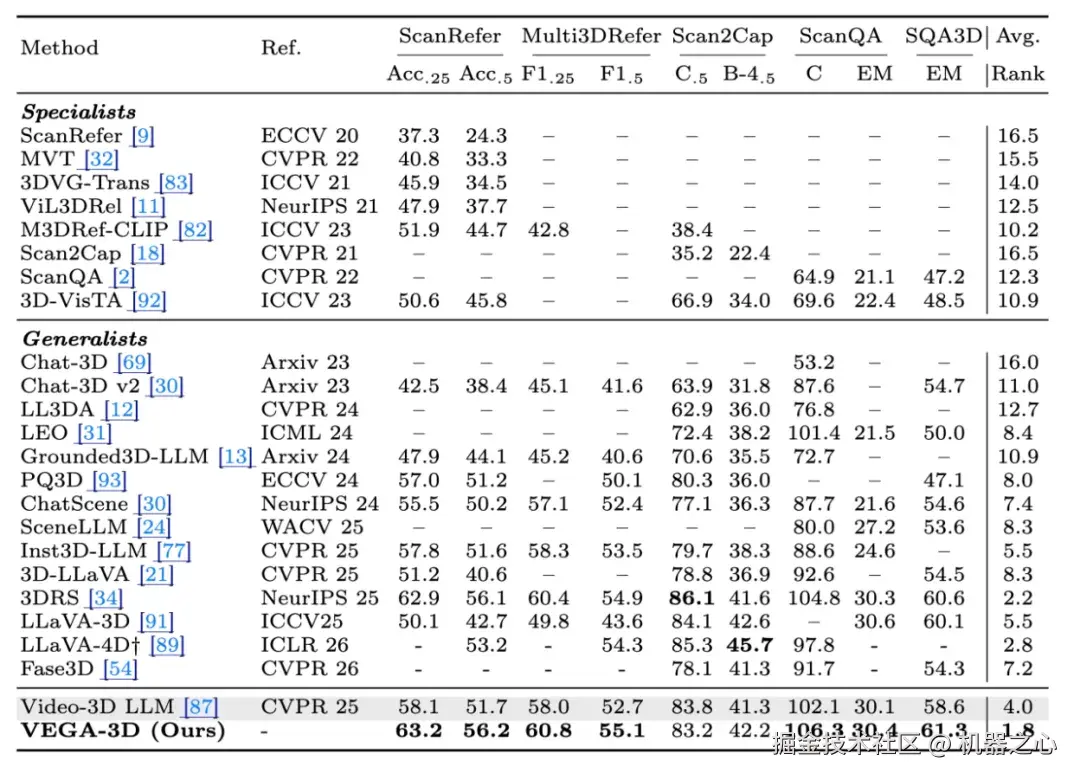
Figure 5 3D 场景理解中, ScanRefer 和 ScanQA 数据集等空间定位与问答任务全面领先
总结与展望:探索 3D 推理的下一个前沿
VEGA-3D 不仅仅是一个性能卓越的系统,它更向整个社区传递了一个重要的设计思路:大模型 3D 空间推理的下一个突破口,也许不在于继续堆叠海量且昂贵的 3D 数据,而在于如何释放生成式基础模型体内早已沉睡的 "物理先验"。作为一种高扩展性、数据高效的基础设施,随着未来视频生成模型(如 Sora、Wan 等)的进一步进化,VEGA-3D 的上限将被无限拉高。