目录
1.解决实际问题
在现实生活中面对大部分问题只知道特征空间中的训练样本和它们对应的标签,并不知道决策面的具体形态是什么样的。
所以解决实际问题的思路是:假定神经网络是某一种结构-->将训练数据输入到网络中-->估计这个网络的待求参数(即权重w和偏置b)。
2.假定网络结构
基于此思路问题变为:怎么能假定合适的网络结构?最重要的两个因素就是它的层数以及每层神经元的个数。神经网络本质是对某一函数的估计或近似,网络的层数和每层神经元个数越多,这个网络表示的函数也就越复杂
因为算法模型的复杂度要和训练样本的复杂度相匹配,所以一般训练样本较多的情况下,模型的层数以及每层神经元的个数也要多一些。同样地,训练样本少的时候,层数和每层神经元个数也要设置的少一些。但是对于具体问题究竟用多少层多少神经元,并没有一个直接的答案。
3.优化待求参数
假定好网络结构之后,接下来就要优化待求参数。
3.1梯度下降法
由于y是关于w和b的非凸函数(即有多个局部极值),因此采用梯度下降法求解局部极小值。
过程为:先随机初始化w和b。 随后进行如下的迭代更新:

偏导就是某一方向的切线斜率,我们可以先想像一个二元函数的曲面,在平常解方程的时候,由于直接告诉了二元函数的具体形式,所以可以直接通过偏导为0求出极值点。但是现在我们并不知道真实的曲面形态,所以只能"走一步看一步",在当前点找出最陡的方向,往下移动,如此重复直到找到局部极值点为止。
可能有人会想,我们不是已经假定好网络结构了吗,那这就代表着w和b的函数已知了,为什么不能直接通过求偏导等于0来确定极值点呢?简单点来说是因为方程太复杂了,根本解不出来。所以采用梯度下降法进行迭代逼近。
3.2学习率:
上图中公式里的α表示:学习率(一个足够小的正数),它是最重要的超参数之一,根据前面的描述,有一个问题就是每次往最陡的方向移动多少? 学习率控制的就是这个,必须设置的恰当,如果过大那么可能会越过局部极值点,如果过小,那么会浪费资源,很久都不能收敛到极值点。
4.后向传播算法
网络结构中的待求参数(w和b)太多,如果逐一计算它们的偏导数那么会很花费计算资源和计算时间,后向传播算法就是根据链式求导法则,通过这些待求参数之间的相互关联简化偏导计算。
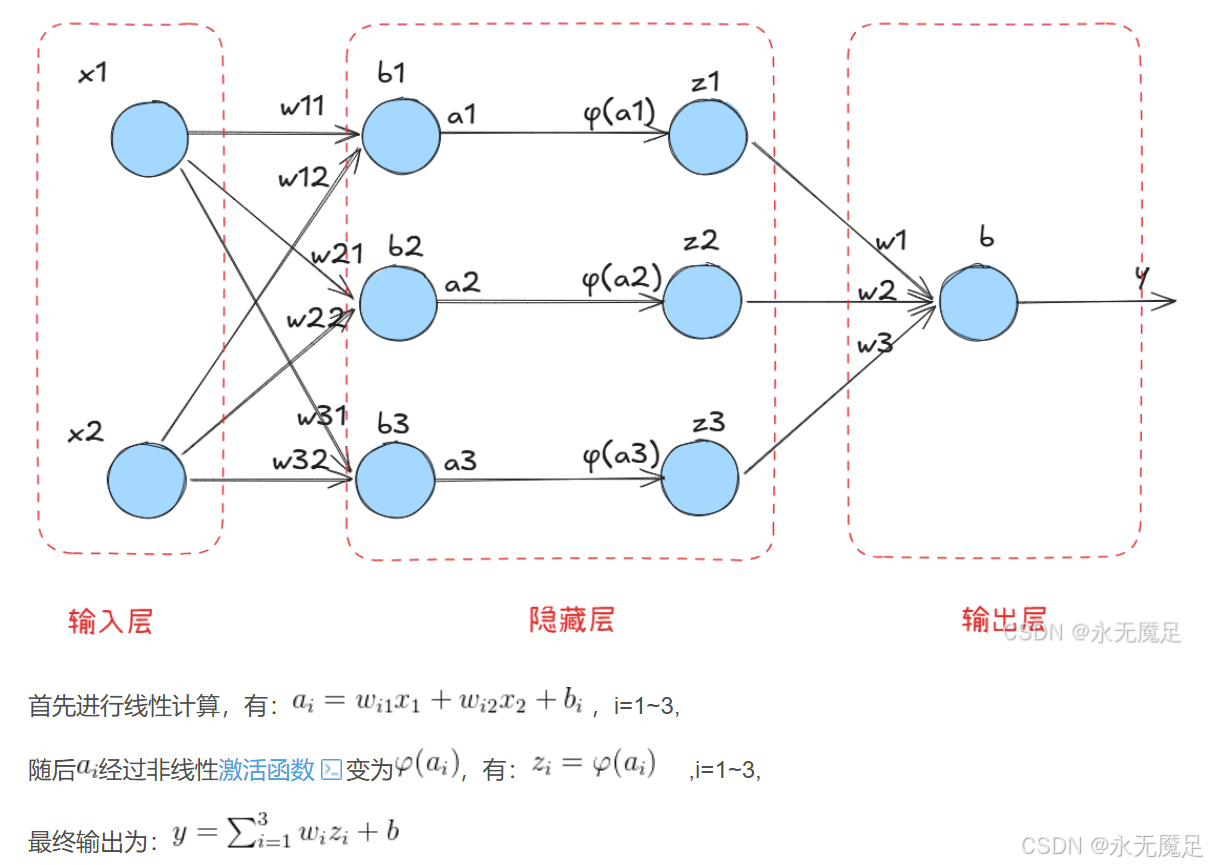
比如该网络结构,我们会定义一个关于Y(标签)和y(模型输出)的目标函数E。我们可以先求出枢纽点的偏导,即对y、的偏导。再通过链式法则去求各个待求参数的偏导就会容易很多。
5.改进
5.1非线性函数
这一改进其实在之前已经有讨论过,所以不作过多赘述。如图:

5.2目标函数(损失函数)
在分类问题中经常采用基于SOFTMAX和交叉熵的目标函数。SOFTMAX函数形式如下:
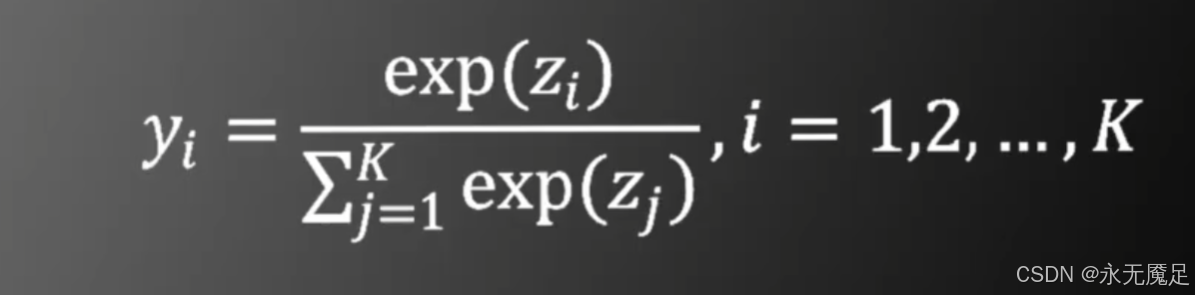
由该公式可见它是将多层神经网络的输出Z的向量的分量取exp之后再进行归一化变为了向量Y的分量
。很明显有
。
基于交叉熵的目标函数如下:
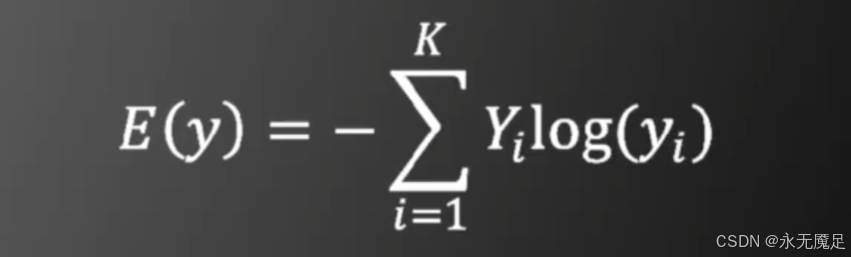
该公式表示两个概率分布Y和y之间的相似程度。注意有以下两个事实:
5.3随机梯度下降
如果对每个训练样本都要进行一次参数更新,那么训练收敛就会非常慢,并且单一数据如果存在误差,就会传到每一个参数中去。
所以在实际应用中,是输入一批样本,然后求出这些样本的梯度平均值,根据该平均值去改变参数,每一批的样本数称为Batch Size。通过Batch Size会将所有训练数据分割为不同批次(Batch)。
按照Batch将所有训练样本遍历一次,称为一个EPOCH。需要注意的是在每个EPOCH中,我们会将所有训练样本次序打乱一次,然后再去划分。
6.独热向量
之前讨论输出还有标签总是用一维变量±1去表示。实际面对多分类(k类)问题时用k维向量去表示:比如为一类,
为另一类,把这种只有一个分量是1,其余的都是0的单位向量称为独热向量。
向量长度即类别个数,分量即类别,为1的分量即所属哪个类别。
而模型的原始输出一般是一个k维向量,每个分量是实数值。在经过softmax函数之后转为概率分布向量(每个分量值在0,1之间,且所有分量和为1),里面的分量是对某一类别的预测的概率。比如:。推理时,会取概率最大的分量位置(索引)作为模型预测的类别。
注意:用softmax的原因是交叉熵的输入要求,所以要对模型原始输出进行处理,将其转换为合法的概率分布。