监督学习核心算法:逻辑回归(Logistic Regression)
逻辑回归是机器学习中最基础、最常用的分类算法 ,名字里虽然有 "回归",但它解决的是分类问题(尤其是二分类问题)。它简单、高效、可解释性强,是工业界和学术界的 "入门必学 + 实战常用" 算法。
一、分类问题为什么"回归"
说到回归,我们第一反应应该是线性回归算法 ,而逻辑回归的分类算法就是在线性回归上得来的,逻辑回归是在线性回归算法的基础上套了一个转换函数 。下面我们对比一下线性回归,说说:为什么需要逻辑回归?
线性回归算法实现(多变量) :
y^=w1x1+w2x2+⋯+b \hat{y} = w_1 x_1 + w_2 x_2 + \dots + b y^=w1x1+w2x2+⋯+b
线性回归的取值范围是(-∞, +∞),我们可以进行训练得到一个房价预测等模型,但是对于只需要判断:患者是否患病、是否是邮箱垃圾等 分类的情况时,我们只需要 1 Or 0 (y ∈{0,1}),此刻线性回归模型就会显得特别别扭,因为线性回归的预测值可能远大于1或远小于0,很难解释成"属于某一类的概率"。
二、Sigmoid解决二类分化
那么能否在线性回归 输出上套一个函数,把输出值压缩到 0 到 1 之间 呢?而这个压缩后的值,就可以解释为"样本属于正类的概率",而逻辑回归就使用了一种名为 Sigmoid (σ)的函数
σ(z)=11+e−z \sigma(z) = \frac{1}{1 + e^{-z}} σ(z)=1+e−z1
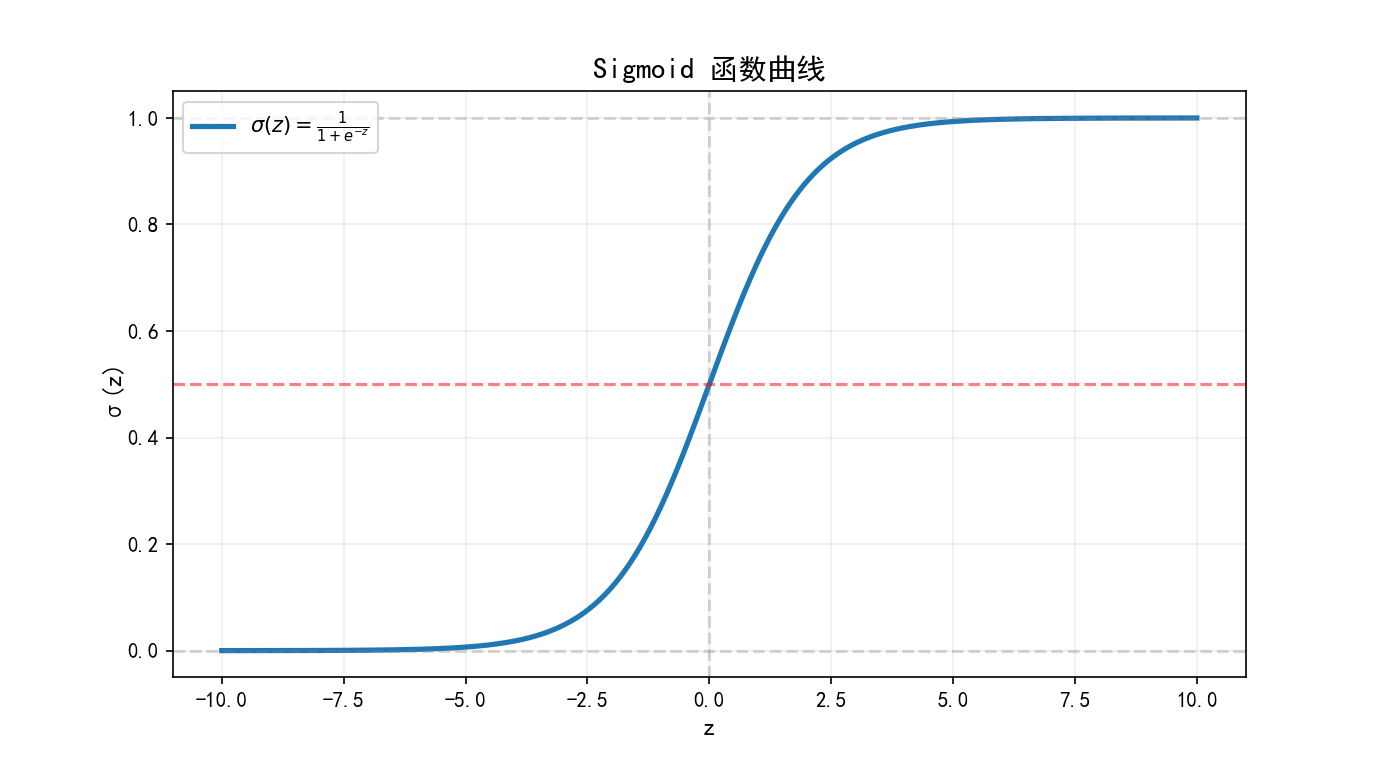
不难发现,sigmoid它有两个极好的性质:
- z→+∞z →+∞ 时,σ(z)→1 σ (z)→1
- z→−∞z →−∞ 时,σ(z)→0 σ (z)→0
由上可得,我们的逻辑回归算法公式如下:
P(y=1∣x)=σ(wTx+b)=11+e−(wTx+b) P(y=1|x) = \sigma\left(w^T x + b\right) = \frac{1}{1 + e^{-(w^T x + b)}} P(y=1∣x)=σ(wTx+b)=1+e−(wTx+b)1
所以,我们可以做出以下规定:
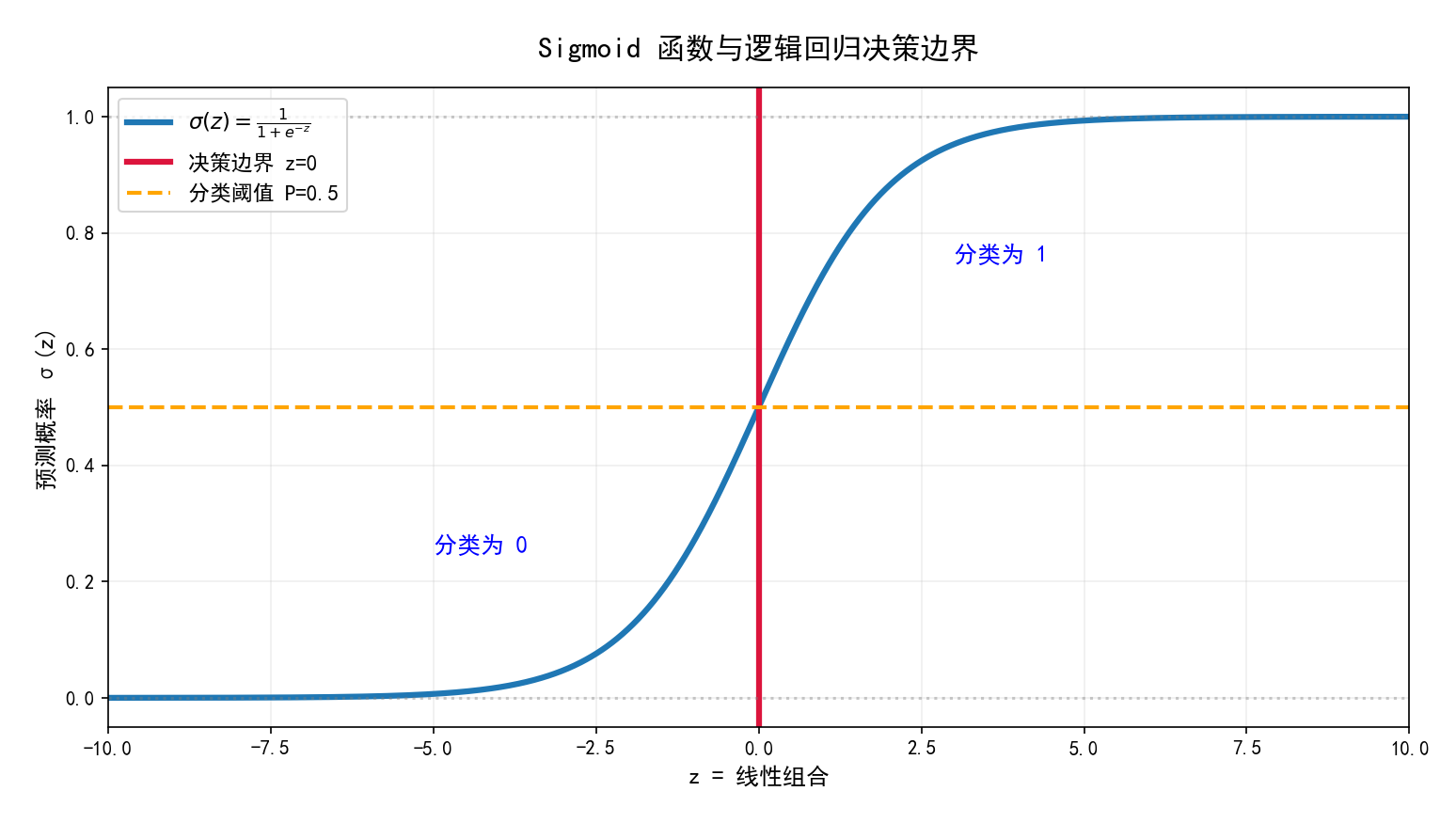
已知 z = 0 时,σ = 0.5,,所以当 σ > 0.5 时,我们判断为 1 ,当 σ < 0.5 时,我们判断为 0,至此我们的逻辑回归预测模型算法公司就确定下来了!此外 ,当 z = 0 时 wTx+b=0w^T x + b = 0wTx+b=0 ,这也称为逻辑回归的决策边界方程,它是一个超平面(在二维空间中就是一条直线)。如图红线:
三、损失函数的分析:为什么这样最好?
在线性回归算法中,有如下损失函数(均方误差) :
J(w,b)=12m∑i=1m(h(x(i))−y(i))2 J(w, b) = \frac{1}{2m}\sum_{i=1}^{m}{(h(x^{(i)}) - y^{(i)})}^2 J(w,b)=2m1i=1∑m(h(x(i))−y(i))2
逻辑回归公式是由线性回归公式改造而来的,那么损失函数是否可以复用呢?分析如下:
y^=σ(z)=11+e−z,z=wTx+b \hat{y} = \sigma(z) = \frac{1}{1 + e^{-z}},\quad z = w^T x + b y^=σ(z)=1+e−z1,z=wTx+b
其中 y^∈(0,1)\hat{y} \in (0, 1)y^∈(0,1) 是预测概率 ,真实标签 y∈{0,1}y \in \{0, 1\}y∈{0,1}。
单个样本的 MSE 损失为:
L=(y−y^)2 L=(y−\hat y)^2 L=(y−y^)2
这式子本身写出来没有任何语法错误,但把它用在二分类 + Sigmoid 输出的场景下,会导致找不到全局最优解问题。
- MSE + sigmoid 损失函数图
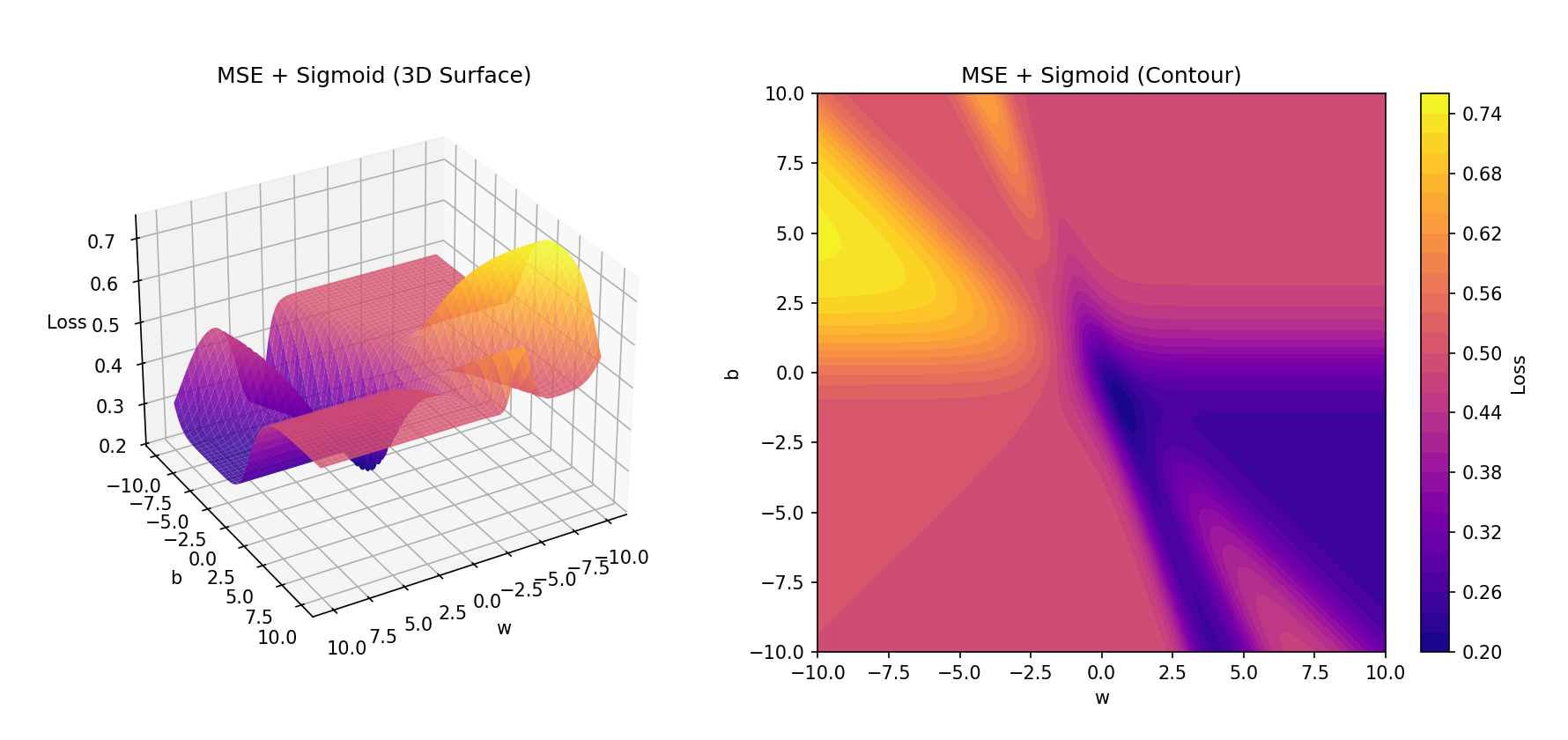
- 左图用 3D 曲面展示损失的起伏,可以清楚地看到不止一个凹陷区域(局部极小),也就是非凸的直观证据。
- 右图是等高线图,颜色越深表示损失越小。你会看到多个分离的低谷闭合圈,梯度下降如果初始化在某个坑的边缘,就很容易陷进去,找不到全局最优。
- 线性回归的 MSE 损失函数图
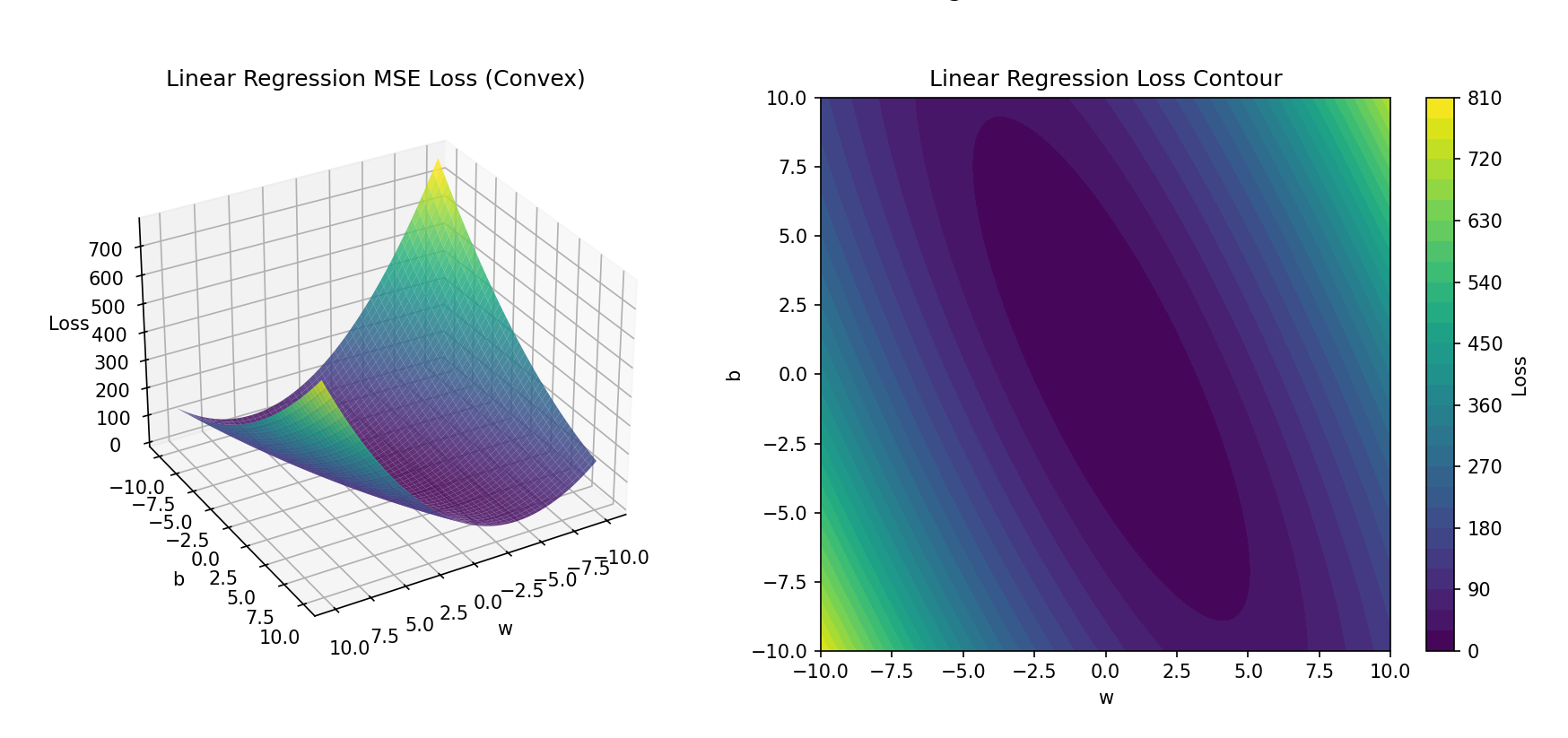
- 我们可以看见线性回归+MSE中的损失函数3D图是一个碗状的,并且只有一个全局最低点,这样就不会导致找不到全局最低点。
综上所述,使用线性规划的损失损失函数 MSE + Sigmoid 在逻辑回归的算法中不可靠的,我们继续从本质来分析损失函数的正确定义:
对于单个样本:
- 如果真实标签 y=1y=1y=1,我们希望 y^\hat yy^ 越大越好,损失越小
- 如果真实标签 y=0y=0y=0 ,我们希望 y^\hat yy^ 越小越好,损失越小
所以,我们可以用下面这个公式将这两种情况合起来 :
p=(y^)y⋅(1−y^)(1−y) p = (\hat y)^y ⋅ (1 - \hat y)^{(1-y)} p=(y^)y⋅(1−y^)(1−y)
其实逻辑回归的损失函数就是源于概率论的最大似然估计 ,而上面是单个似然样本,我们总的结果我们希望所有样本的联合概率最大化(预测最准) ,所以有:
L(w,b)=∏i=1ny^iyi(1−y^i)1−yi L(w, b) = \prod_{i=1}^{n} \hat{y}_i^{y_i} (1-\hat{y}_i)^{1-y_i} L(w,b)=i=1∏ny^iyi(1−y^i)1−yi
lnL(w,b)=ln(∏i=1ny^iyi(1−y^i)1−yi) \ln L(w, b) = \ln(\prod_{i=1}^{n} \hat{y}_i^{y_i} (1-\hat{y}_i)^{1-y_i}) lnL(w,b)=ln(i=1∏ny^iyi(1−y^i)1−yi)
lnL(w,b)=∑i=1nyilny\^i+(1−yi)ln(1−y\^i) \ln L(w,b) = \sum_{i=1}^{n} \left y_i \\ln \\hat{y}_i + (1-y_i) \\ln (1-\\hat{y}_i) \\right lnL(w,b)=i=1∑nyilny\^i+(1−yi)ln(1−y\^i)
两边去取得符号,将最大化得联合概率转化为最小化得损失(添加符号后,预测越准,值越小) :
−1nlnL(w,b)=−1n∑i=1nyilny\^i+(1−yi)ln(1−y\^i) -\frac{1}{n} \ln L(w,b) = -\frac{1}{n} \sum_{i=1}^{n} \left y_i \\ln \\hat{y}_i + (1-y_i) \\ln (1-\\hat{y}_i) \\right −n1lnL(w,b)=−n1i=1∑nyilny\^i+(1−yi)ln(1−y\^i)
所以我们令:
J(w,b)=−1nlnL(w,b) J(w, b) = -\frac{1}{n}\ln L(w,b) J(w,b)=−n1lnL(w,b)
所以有:
J(w,b)=−1n∑i=1nyilny\^i+(1−yi)ln(1−y\^i) J(w, b) =-\frac{1}{n} \sum_{i=1}^{n} \left y_i \\ln \\hat{y}_i + (1-y_i) \\ln (1-\\hat{y}_i) \\right J(w,b)=−n1i=1∑nyilny\^i+(1−yi)ln(1−y\^i)
这就是我们逻辑回归的损失函数,通常被称为:交叉熵损失函数。
四、梯度下降
逻辑回归的损失函数我们已经拿到了,现在我们只需要进行梯度下降,逻辑回归的梯度下降与线性回归的梯度下降使用同样的偏导方式进行。
单次逻辑回归的梯度下降更新如下:
梯度计算:
∂J∂w=1n∑i=1n(y^i−yi)xi \frac{\partial J}{\partial w} = \frac{1}{n} \sum_{i=1}^{n} (\hat{y}_i - y_i) x_i ∂w∂J=n1i=1∑n(y^i−yi)xi
∂J∂b=1n∑i=1n(y^i−yi) \frac{\partial J}{\partial b} = \frac{1}{n} \sum_{i=1}^{n} (\hat{y}_i - y_i) ∂b∂J=n1i=1∑n(y^i−yi)
参数更新:
w=w−α⋅∂J∂w w = w - \alpha \cdot \frac{\partial J}{\partial w} w=w−α⋅∂w∂J
b=b−α⋅∂J∂b b = b - \alpha \cdot \frac{\partial J}{\partial b} b=b−α⋅∂b∂J
我们下面只需要像线性规划一样将参数 w,bw,bw,b,不断更新即可,当参数不变时就达到了损失函数的最小值了。
最重要的一点: 参数 w,bw,bw,b 必须同步更新!
五、逻辑回归的优缺点
优点
- 简单高效:计算速度快,适合大规模数据集
- 可解释性强 :每个特征的权重 WjW_jWj 可以直接解释为该特征对结果的影响程度
- 输出概率:不仅能给出分类结果,还能给出结果的置信度
- 易于实现和调优:只有学习率和正则化两个主要超参数
缺点
- 只能处理线性可分问题:对于非线性数据,需要手动构造特征交叉
- 对多重共线性敏感:如果特征之间高度相关,会导致参数估计不稳定
- 容易欠拟合:模型复杂度较低,对于复杂问题可能表现不佳
六、C++代码的简单实现(单特征)
cpp
#include <iostream>
#include <vector>
#include <cmath>
#include <iomanip>
double sigmoid(double z){
return 1/ (1 + exp(-z));
}
class SimpleLogisticRegression {
private:
double _w;
double _b;
double _learning_rate;
int _train_count;
public:
SimpleLogisticRegression(double learning_rate = 0.1, int train_count = 100)
:_w(0), _b(0), _learning_rate(learning_rate), _train_count(train_count)
{
}
// x 为训样本,y 为训练标签
void fit(const std::vector<double>& x, const std::vector<int>& y){
int n = x.size();
for(int i = 0; i < _train_count; i++){
double loss = 0.0;
double dw = 0.0, db = 0.0;
// 遍历每一个样本
for(int j = 0; j < n; j++){
double z = _w * x[j] + _b;
double y_pred = sigmoid(z);
double eps = 1e-15;
y_pred = std::max(eps, std::min(1 - 1e-15, y_pred));
loss += -(y[j] * log(y_pred) + (1 - y[j]) * log(1 - y_pred));
double error = y_pred - y[j];
dw += error * x[j];
db += error;
}
// 平均损失
loss /= n;
dw /= n;
db /= n;
_w -= _learning_rate * dw;
_b -= _learning_rate * db;
if (i % 100 == 0) {
std::cout << "Iter " << i << " Loss: " << loss << std::endl;
}
}
}
double predict_proba(double x) {
return sigmoid(_w * x + _b);
}
int predict(double x){
return predict_proba(x) >= 0.5 ? 1 : 0;
}
// 获取参数
double get_w() const { return _w; }
double get_b() const { return _b; }
void print_params() const {
std::cout << "w = " << _w << ", b = " << _b << std::endl;
}
};
int main() {
// 生成一维线性可分数据
// 负类:x 在 0~2 左右,标签 0
// 正类:x 在 3~5 左右,标签 1
std::vector<double> x = {0.2, 0.5, 1.0, 1.3, 1.8, 3.1, 3.5, 4.0, 4.3, 4.9};
std::vector<int> y = {0, 0, 0, 0, 0, 1, 1, 1, 1, 1};
SimpleLogisticRegression model(0.1, 1000);
model.fit(x, y);
std::cout << "\nTrained parameters:" << std::endl;
model.print_params();
// 预测几个测试点
std::cout << "\nTest predictions:" << std::endl;
std::vector<double> test_x = {0.8, 2.5, 3.8, 5.0};
for (double val : test_x) {
double prob = model.predict_proba(val);
int cls = model.predict(val);
std::cout << "x = " << val << " -> prob = " << prob
<< ", class = " << cls << std::endl;
}
// 输出决策边界(P(y=1) = 0.5,即 z=0 => x = -b/w)
if (abs(model.get_w()) > 1e-10) {
std::cout << "\nDecision boundary x = " << -model.get_b() / model.get_w() << std::endl;
} else {
std::cout << "\nWeight is zero, decision boundary undefined." << std::endl;
}
return 0;
}七、Python代码的简单实现(单特征)(AI生成)
python
import math
def sigmoid(z):
return 1 / (1 + math.exp(-z))
class SimpleLogisticRegression:
def __init__(self, learning_rate=0.1, train_count=100):
self.w = 0.0
self.b = 0.0
self.lr = learning_rate
self.epochs = train_count
def fit(self, x, y):
n = len(x)
for i in range(self.epochs):
loss = 0.0
dw = 0.0
db = 0.0
for j in range(n):
z = self.w * x[j] + self.b
y_pred = sigmoid(z)
eps = 1e-15
y_pred = max(1e-15, min(1 - 1e-15, y_pred))
loss += -(y[j] * math.log(y_pred) + (1 - y[j]) * math.log(1 - y_pred))
error = y_pred - y[j]
dw += error * x[j]
db += error
loss /= n
dw /= n
db /= n
self.w -= self.lr * dw
self.b -= self.lr * db
if i % 100 == 0:
print(f"Iter {i} Loss: {loss}")
def predict_proba(self, x):
return sigmoid(self.w * x + self.b)
def predict(self, x):
return 1 if self.predict_proba(x) >= 0.5 else 0
def get_params(self):
return self.w, self.b
def print_params(self):
print(f"w = {self.w}, b = {self.b}")
if __name__ == "__main__":
# 生成一维线性可分数据
x = [0.2, 0.5, 1.0, 1.3, 1.8, 3.1, 3.5, 4.0, 4.3, 4.9]
y = [0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
model = SimpleLogisticRegression(learning_rate=0.1, train_count=1000)
model.fit(x, y)
print("\nTrained parameters:")
model.print_params()
# 预测几个测试点
print("\nTest predictions:")
test_x = [0.8, 2.5, 3.8, 5.0]
for val in test_x:
prob = model.predict_proba(val)
cls = model.predict(val)
print(f"x = {val} -> prob = {prob:.6f}, class = {cls}")
# 决策边界
w, b = model.get_params()
if abs(w) > 1e-10:
print(f"\nDecision boundary x = {-b / w:.4f}")
else:
print("\nWeight is zero, decision boundary undefined.")
test_x:
prob = model.predict_proba(val)
cls = model.predict(val)
print(f"x = {val} -> prob = {prob:.6f}, class = {cls}")
# 决策边界
w, b = model.get_params()
if abs(w) > 1e-10:
print(f"\nDecision boundary x = {-b / w:.4f}")
else:
print("\nWeight is zero, decision boundary undefined.")