PyTorch实战(30)------使用TorchScript和ONNX导出通用PyTorch模型
0. 前言
我们已经深入探讨了PyTorch 模型部署,这可能是将 PyTorch 模型投入生产系统中最关键的一环。在本节中,我们将聚焦另一个重要维度:模型导出。我们已经学习了如何在经典的 Python 脚本环境中保存和加载 PyTorch 模型。但是我们还需要更多的方式来导出 PyTorch 模型,主要是出于以下考虑:
- 首先,
Python解释器通过全局解释器锁 (Global Interpreter Lock,GIL) 限制单线程运行 (目前Python正在逐步移除GIL),这阻碍了操作并行化 - 其次,目标运行环境(如某些系统或设备)可能不支持
Python
为解决这些问题,PyTorch 提供了高效且与平台/语言无关的模型导出方案,使模型能脱离训练环境运行。我们首先探讨 TorchScript,它能将序列化优化后的 PyTorch 模型转换为中间表示 (Intermediate Representation, IR),从而在非 Python 环境(如 C++ 程序)中运行。接着探讨 ONNX 标准,该技术支持以通用格式保存模型,以便导入其他深度学习框架或跨编程语言使用。
1. TorchScript 简介
TorchScript 是将 PyTorch 模型投入生产环境中的关键工具,原因有两个:
PyTorch默认采用即时执行模式 (eager execution)。虽然这种模式便于调试,但逐操作执行时频繁的内存读写会导致推理延迟增高,且难以进行全局优化。为此,PyTorch提供了基于Python子集的即时 (just-in-time,JIT) 编译器解决方案。JIT编译器通过整体分析模型所有操作,将其编译为单一复合计算图(而非逐行解释执行),生成的TorchScript代码实质上是静态类型的Python子集。这种编译方式带来多重性能提升:消除全局解释器锁 (Global Interpreter Lock,GIL) 实现多线程支持,同时可应用多种图结构优化- 生产环境往往需要更高性能(如更快速、内存效率更高)的
C++等语言支持,或需在不支持Python的硬件设备上部署。此时TorchScript展现出独特优势------当PyTorch模型被编译为中间表示 (Intermediate Representation,IR) 后,可通过TorchScript编译器序列化为C++兼容格式,最终借助PyTorch C++ API(LibTorch) 在C++推理程序中加载运行
本节已多次提及 PyTorch 模型的 JIT 编译机制,现在我们将具体探讨两种将 PyTorch 模型编译为 TorchScript 格式的方法。
2. 使用 TorchScript 进行模型追踪
一种方法是通过模型追踪 (tracing) 实现 PyTorch 代码到 TorchScript 的转换。该方法需要提供 PyTorch 模型对象和一个虚拟输入样例 (dummy input)。顾名思义,追踪机制会记录这个虚拟输入在模型(神经网络)中的流动过程,捕捉所有运算操作,最终生成可视图化的 TorchScript 中间表示 (Intermediate Representation, IR)------既支持图形化展示,也可转换为 TorchScript 代码。接下来,同样以手写数字分类模型为例演示追踪 PyTorch 模型的过程。
(1) 首先,导入所需库:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
import numpy as np
from PIL import Image(2) 接下来,定义并实例化模型对象:
python
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.cn1 = nn.Conv2d(1, 16, 3, 1)
self.cn2 = nn.Conv2d(16, 32, 3, 1)
self.dp1 = nn.Dropout(0.10)
self.dp2 = nn.Dropout(0.25)
self.fc1 = nn.Linear(4608, 64) # 4608 is basically 12 X 12 X 32
self.fc2 = nn.Linear(64, 10)
def forward(self, x):
x = self.cn1(x)
x = F.relu(x)
x = self.cn2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dp1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dp2(x)
x = self.fc2(x)
op = F.log_softmax(x, dim=1)
return op
model = ConvNet()(3) 然后,加载模型权重:
python
PATH_TO_MODEL = "./convnet.pth"
model.load_state_dict(torch.load(PATH_TO_MODEL, weights_only=False, map_location="cpu"))(4) 然后,加载一张示例图像:
python
image = Image.open("./digit_image.jpg")(5) 接下来,定义数据预处理函数,并将预处理函数应用于示例图像:
python
def image_to_tensor(image):
gray_image = transforms.functional.to_grayscale(image)
resized_image = transforms.functional.resize(gray_image, (28, 28))
input_image_tensor = transforms.functional.to_tensor(resized_image)
input_image_tensor_norm = transforms.functional.normalize(input_image_tensor, (0.1302,), (0.3069,))
return input_image_tensor_norm
input_tensor = image_to_tensor(image)(6) 同时,还需要执行以下代码,否则所有被追踪模型的参数都需要梯度计算,因此必须在 torch.no_grad() 上下文中加载模型:
python
model.eval()
for p in model.parameters():
p.requires_grad_(False)(7) 加载具有预训练权重的 PyTorch 模型对象后,使用虚拟输入来追踪模型:
python
demo_input = torch.ones(1, 1, 28, 28)
traced_model = torch.jit.trace(model, demo_input)本节所用的虚拟输入是一个所有像素值都设置为 1 的图像。
(8) 查看追踪生成的模型计算图:
python
traced_model.graph输出结果如下所示:
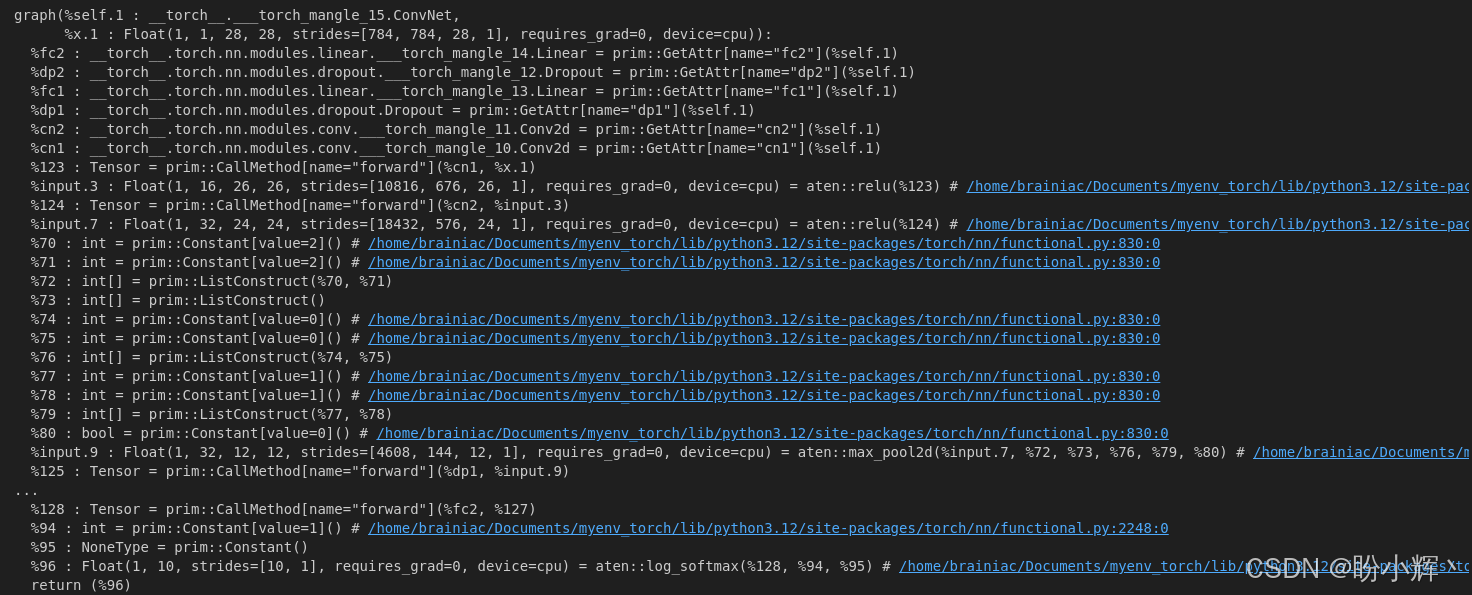
直观来看,计算图起始部分显示模型各层初始化过程(如 fc2、dp2 等层),末端则呈现最后的 softmax 层。可以看到,该计算图采用静态类型变量的低级语言描述,其语法形式与 TorchScript 语言非常相似。
(9) 除了查看计算图,我们还可以通过以下命令获取追踪模型对应的 TorchScript 代码:
python
print(traced_model.code)执行后将输出如下类 Python 代码,这些代码定义了模型的 forward 传播方法:

这段代码正是我们在 步骤 2 中使用 PyTorch 编写的等效 TorchScript 实现。
(10) 接下来,导出(保存)追踪后的模型:
python
torch.jit.save(traced_model, 'traced_convnet.pt')(11) 加载保存的模型:
python
loaded_traced_model = torch.jit.load('traced_convnet.pt')需要注意的是,这里我们不需要分别加载模型的架构和参数。
(12) 最后,使用该模型进行推理:
python
loaded_traced_model(input_tensor.unsqueeze(0))输出结果如下:
shell
tensor([[-9.9644e+00, -1.1098e+01, -2.3822e-03, -8.3610e+00, -8.2592e+00,
-1.1988e+01, -8.2979e+00, -1.0842e+01, -6.4784e+00, -1.1229e+01]])(13) 可以通过在原模型上重新运行推理来验证结果:
python
model(input_tensor.unsqueeze(0))输出结果与第 12 步相同,验证了我们的追踪模型运行正常。得益于 TorchScript 无需 GIL 的特性,可以使用追踪模型替代原始 PyTorch 模型对象来构建更高效的Flask 模型服务器。虽然追踪是 JIT 编译 PyTorch 模型的有效方法,但它也存在一些局限性。
例如,若模型的前向传播包含条件分支(如 if 语句)或循环结构(如 for 语句),追踪机制仅能捕获其中一条执行路径的运算流程。为确保此类控制流模型的准确转换,我们需要采用另一种编译机制------脚本化 (scripting)。
3. 使用 TorchScript 进行模型脚本化
复用上一小节代码,然后继续完成本节内容。
(1) 脚本化转换无需提供虚拟输入,直接通过以下代码将 PyTorch 模型转为 TorchScript:
python
scripted_model = torch.jit.script(model)(2) 查看脚本化后的模型图:
python
scripted_model.graph输出格式与追踪模型类似,如下图所示:
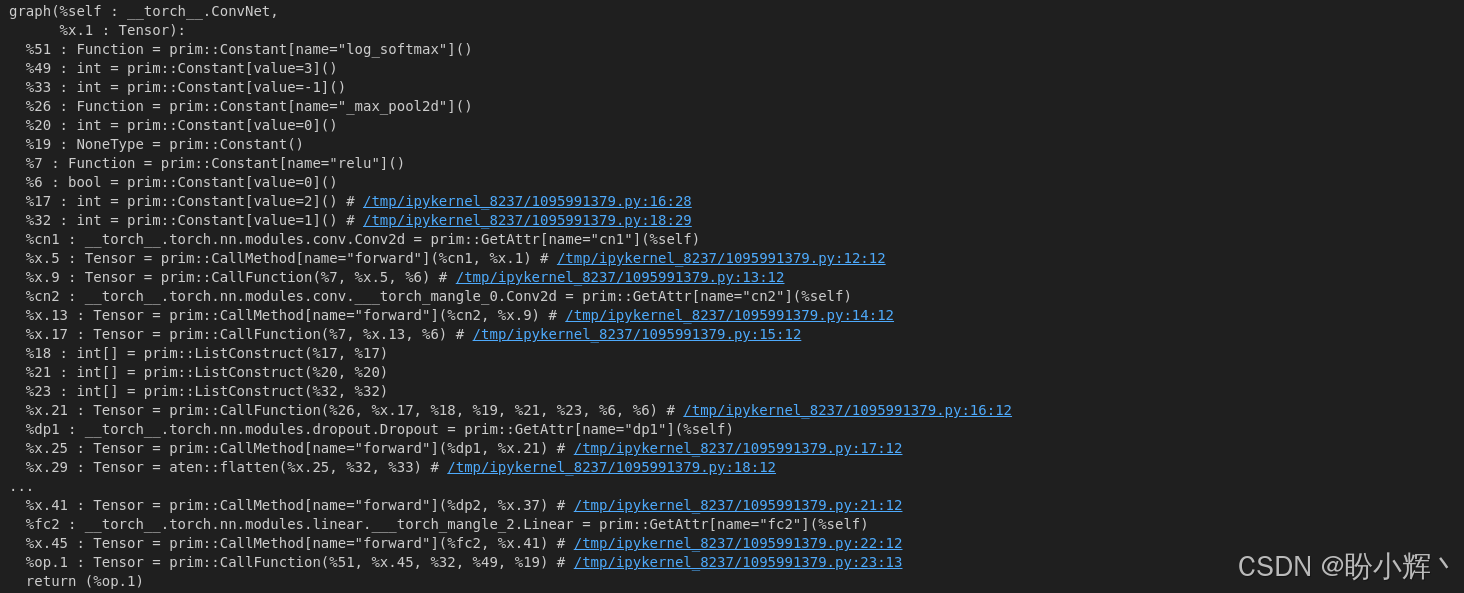
可见计算图仍以逐行描述的底层脚本形式呈现,但注意此处计算图结构与上一小节的追踪结果存在差异,这表明使用追踪与脚本化在代码编译策略上有所不同。
(3) 通过运行以下代码查看等效的 TorchScript 代码:
python
print(scripted_model.code)输出结果如下所示:

本质上,流程与上一小节类似;然而,由于编译策略的不同,代码签名上存在细微差异。
(4) 同样地,脚本化模型可通过以下方式导出并重新加载:
python
torch.jit.save(scripted_model, 'scripted_convnet.pt')
loaded_scripted_model = torch.jit.load('scripted_convnet.pt')(5) 最后,使用脚本化模型进行推理:
python
loaded_scripted_model(input_tensor.unsqueeze(0))输出结果应与上一小节步骤 12 完全一致,由此验证脚本化模型运行符合预期。
与追踪模型类似,脚本化模型同样不受 GIL 限制,因此在 Flask 服务部署时可显著提升性能。下表展示了两种编译策略的对比特征:
| Tracing | Scripting |
|---|---|
| 需要虚拟输入 | 不需要虚拟输入 |
| 通过将虚拟输入传递给模型,记录固定的数学操作序列 | 通过检查 PyTorch 代码中的 nn.Module 内容,生成 TorchScript 代码/图 |
| 无法处理模型前向传播中的多个控制流(如 if-else) | 对处理各种控制流(如 if-else、循环等)非常有用 |
| 即使模型包含不被 TorchScript 支持的 PyTorch 功能,也能正常工作 | 只有在 PyTorch 模型不包含 TorchScript 不支持的功能时,才有效 |
我们已经展示了如何将 PyTorch 模型转换并序列化为 TorchScript 模型。在下一节中,我们将暂时脱离 Python,展示如何使用 C++ 加载 TorchScript 序列化模型。
4. 在 C++ 中运行 PyTorch 模型
在某些场景下,Python 可能成为性能瓶颈,或者我们无法在目标环境中运行基于 PyTorch 和 Python 训练的机器学习模型。为此,本节将利用导出的 TorchScript 序列化模型(包括追踪和脚本化两种方式),演示如何在 C++ 代码中执行模型推理。
在开始之前,我们需要安装 CMake 以支持 C++ 代码编译。完成安装后,在当前工作目录下创建名为 cpp_convnet 的文件夹,后续操作都将在此目录中进行。
(1) 编写用于运行模型推理流程的 C++ 文件:
cpp
#include <torch/script.h>
#include <opencv2/core.hpp>
#include <opencv2/imgcodecs.hpp>
#include <opencv2/highgui.hpp>
#include <opencv2/imgproc.hpp>
#include <iostream>
using namespace cv;
using namespace std;
int main(int argc, char **argv) {
Mat img = imread(argv[2], IMREAD_GRAYSCALE);首先,使用 OpenCV 库将 .jpg 图像文件读取为灰度图像。
(2) 然后,将灰度图像调整为 28x28 像素,即本节模型所需输入规格:
cpp
resize(img, img, Size(28, 28));(3) 接着,将图像数组转换为 PyTorch 张量:
cpp
auto input_ = torch::from_blob(img.data, { img.rows, img.cols, img.channels() }, at::kByte);本节所有与 torch 相关的操作都需使用 libtorch 库------这是 PyTorch C++ API 的核心组件。若已安装 PyTorch,则无需单独安装 LibTorch。
(4) 由于 OpenCV 读取的灰度图像维度为 (28, 28, 1),我们需要将其转换为 (1, 28, 28) 格式以满足 PyTorch 要求。接着将张量重塑为 (1,1,28,28) 形状,其中第一个维度表示推理时的 batch_size,第二个维度为通道数,对于灰度图像而言为 1:
cpp
auto input = input_.permute({2,0,1}).unsqueeze_(0).reshape({1, 1, img.rows, img.cols}).toType(c10::kFloat).div(255);
input = (input - 0.1302) / 0.3069;由于 OpenCV 读取的图像像素值范围为 0-255,我们首先将其归一化到 [0,1] 区间(通过除以 255 实现)。接着按照预处理标准,使用均值 0.1302 和标准差 0.3069 对图像进行标准化处理。
(5) 加载已经导出的 JIT 编译后的 TorchScript 模型对象:
cpp
auto module = torch::jit::load(argv[1]);
std::vector<torch::jit::IValue> inputs;
inputs.push_back(input);(6) 最后,进入模型预测阶段,使用加载的模型对象,利用提供的输入数据执行前向推理:
cpp
auto output_ = module.forward(inputs).toTensor();(7) 输出变量 output_ 存储着每个类别的预测概率分布。提取概率最高的类别标签并打印:
cpp
auto output = output_.argmax(1);
cout << output << '\n';(8) 最终,退出 C++ 例程:
cpp
return 0;
}(9) 此外,还需要在同一工作目录中编写一个 CMakeLists.txt 文件:
shell
cmake_minimum_required(VERSION 3.12 FATAL_ERROR)
set(CMAKE_CXX_STANDARD 17)
set(CMAKE_CXX_STANDARD_REQUIRED ON)
set(CMAKE_CXX_EXTENSIONS OFF)
add_compile_options(-std=c++17)
project(cpp_convnet)
find_package(Torch REQUIRED)
find_package(OpenCV REQUIRED)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${TORCH_CXX_FLAGS}")
add_executable(cpp_convnet cpp_convnet.cpp)
target_link_libraries(cpp_convnet pthread)
target_link_libraries(cpp_convnet ${TORCH_LIBRARIES} ${OpenCV_LIBS})
set_property(TARGET cpp_convnet PROPERTY CXX_STANDARD 14)该文件本质上是库安装和构建脚本,类似于 Python 项目中的 setup.py 文件。此外,还需要设置 OpenCV_DIR 环境变量:
shell
$ export OpenCV_DIR=/usr/lib/x86_64-linux-gnu/cmake/opencv4/(10) 接下来,需要实际运行 CMakeLists 文件完成构建。我们在当前工作目录中创建一个新目录,并从该目录中运行构建过程来。在命令行中,需执行以下命令:
shell
$ mkdir build
$ cd build
$ cmake -DCMAKE_PREFIX_PATH=/home/brainiac/Documents/myenv_torch/lib/python3.12/site-packages/torch ..
$ cmake --build . --config Release第三行需要提供 LibTorch 的安装路径。要获取系统中的路径,可在 Python 中执行以下代码:
python
import torch
torch.__path__输出类似以下结果:
shell
# /lib/python3.12/site-packages/torch执行第三行命令将输出类似以下结果:

执行第四行命令将输出以下内容:

成功执行以上步骤后,将生成名为 cpp_convnet 的 C++ 编译二进制文件。运行该可执行程序,即通过 C++ 模型对样本图像进行推理。可以选择以下两种方式输入模型:
-
使用脚本化模型作为输入:
shell$ ./cpp_convnet ../../scripted_convnet.pt ../../digit_image.jpg -
或者,使用追踪模型作为输入:
shell$ ./cpp_convnet ../../traced_convnet.pt ../../digit_image.jpg
两种方式均应输出如下结果:
shell
2
[ CPULongType{1} ]可以看到,C++ 模型正常运行。需注意的是,由于 C++ 使用 OpenCV 而 Python 使用 PIL 进行图像处理,像素编码方式存在细微差异,这将导致预测概率略有不同。但只要正确实施归一化处理,最终预测结果并不会出现显著差异。
至此我们完成了 PyTorch 模型在 C++ 环境中的推理实践。在本节中,我们学习了如何将训练好的 PyTorch 深度学习模型移植到 C++ 环境,以提高预测效率,同时为在没有 Python 环境的系统(例如某些嵌入式系统、无人机等)中部署模型开辟了可能性。
接下来,我们将讨论一个通用的神经网络建模格式------ONNX (Open Neural Network Exchange),它能实现跨深度学习框架、编程语言和操作系统的模型互通。具体而言,我们将介绍如何将 PyTorch 训练的模型导入 TensorFlow 进行推理。
5. 使用 ONNX 导出 PyTorch 模型
在生产系统中,有些已部署的机器学习模型大多是使用某个深度学习库(例如 TensorFlow )编写的,并配有成熟的模型服务基础设施。如果某个模型是使用 PyTorch 编写的,我们希望能够使用 TensorFlow 来运行它,可以通过 ONNX 等标准化框架可使其兼容 TensorFlow 服务策略。
ONNX (Open Neural Network Exchange) 是一种通用格式,它将深度学习模型的基本操作(如矩阵乘法和激活函数)进行标准化,这些操作在不同的深度学习库中有不同的实现方式。ONNX 使我们能够灵活地使用不同的深度学习库、编程语言,甚至不同的运行环境来执行同一个深度学习模型。
在本节,我们将介绍如何在 TensorFlow 中运行一个使用 PyTorch 训练的模型。我们将首先将 PyTorch 模型导出为 ONNX 格式,然后将该 ONNX 模型加载到 TensorFlow 代码中。
除了 TensorFlow 外,还需要安装 onnx 和 onnx2tf 这两个库。首先,复用《使用 TorchScript 进行模型追踪》小节中的步骤 1 到 11,然后继续执行以下步骤。
(1) 首先,安装所需库:
shell
$ pip install onnx onnx2tf tf_keras onnx_graphsurgeon ai_edge_litert sng4onnx(2) 与模型追踪类似,我们将一个虚拟输入传入已加载的模型:
python
demo_input = torch.ones(1, 1, 28, 28)
torch.onnx.export(model, demo_input, "convnet.onnx")这将保存一个 ONNX 格式的模型文件。其底层使用的模型序列化机制与模型追踪中的机制相同。
(3) 接下来,加载保存的 ONNX 模型,并将其转换为 TensorFlow 模型:
python
onnx2tf.convert(
input_onnx_file_path="convnet.onnx",
output_folder_path="convnet_tf",
non_verbose=True,
)(4) 然后,加载序列化的 TensorFlow 模型,以解析模型的计算图。以验证我们是否正确加载了模型结构,并识别计算图的输入和输出节点:
python
model = tf.saved_model.load("./convnet_tf/")
model输出结果如下所示:
python
<tensorflow.python.saved_model.load.Loader._recreate_base_user_object.<locals>._UserObject at 0x7e0fc83c6ae0>(5) 最后,我们在 TensorFlow 模型上运行推理,为示例图像生成预测结果:
python
# Perform inference
output = model(input_tensor.unsqueeze(-1))
# Print the output
print("Model Output:", output)输出结果如下所示:

可以看到,TensorFlow 和PyTorch版本的模型预测结果完全相同。这验证了 ONNX 框架的成功运行。我们可以进一步分析 TensorFlow 模型,理解 ONNX 如何通过利用模型计算图中的底层数学运算,在不同的深度学习库中重新生成完全相同的模型。
小结
在本节中,我们将深入探讨使用 TorchScript 导出 PyTorch 模型。通过序列化,TorchScript 使模型与 Python 生态系统独立,从而使得模型可以在其他环境中加载,例如基于 C++ 的环境。我们还跨越 Torch 框架与 Python 生态的边界,研究机器学习通用开放格式 ONNX,该技术能帮助我们将 PyTorch 训练的模型导出至非 PyTorch 甚至非 Python 环境。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习
PyTorch实战(25)------使用PyTorch构建DQN模型
PyTorch实战(26)------PyTorch分布式训练
PyTorch实战(27)------自动混合精度训练
PyTorch实战(28)------PyTorch深度学习模型部署
PyTorch实战(29)------使用TorchServe部署PyTorch模型