机构: 百度
代码: https://github.com/WhyChaos/TRE-Encouraging-Exploration-in-the-Trust-Region
Abstract
熵正则化是强化学习(RL)中提升探索能力的标准技术。然而,在大语言模型(LLMs)中,它往往效果甚微,甚至会导致性能下降。我们认为,这种失败源于大语言模型所固有的累积尾部风险(cumulative tail risk),这种风险来自其庞大的词表规模以及较长的生成序列长度。
在这样的环境下,标准的全局熵最大化会将概率质量不加区分地分散到大量处于尾部的无效 token 上,而不是集中于合理候选项,从而破坏连贯的推理过程。
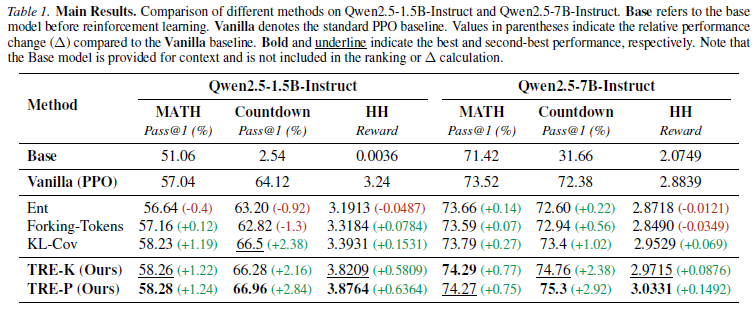
为了解决这一问题,我们提出了 Trust Region Entropy(TRE) 方法。该方法鼓励模型仅在其"信任区域(trust region)"内进行探索。我们在数学推理任务(MATH)、组合搜索任务(Countdown)以及偏好对齐任务(HH)上进行了大量实验,结果表明,TRE 在各项任务中均稳定优于标准 PPO、传统熵正则化方法以及其他探索基线方法。
Contribution
• We introduce Trust Region Entropy (TRE), a method that encourages exploration strictly within a trust region via local entropy maximization.
• We demonstrate through extensive experiments on mathematical reasoning (MATH), combinatorial search (Countdown), and preference alignment (HH) that TRE consistently outperforms vanilla PPO, standard entropy regularization, and other exploration baselines.
Related Works
RL for LLM Alignment
Following the standard Reinforcement Learn-ing from Human Feedback (RLHF) pipeline (Ouyang et al., 2022), models initially trained via supervised fine-tuning are further optimized using algorithms such as Proximal Policy Optimization (PPO) (Schulman et al., 2017) to maxi-mize non-differentiable reward signals. This paradigm has proven effective across various domains, from improving helpfulness and safety (Bai et al., 2022) to enhancing mathematical reasoning capabilities (Guo et al., 2025; Yu et al., 2025).
Entropy Regularization
Entropy regularization is a cornerstone technique in modern RL, encouraging exploration via the entropy term.
While highly effective in low-dimensional continuous control, naive entropy maximization proves problematic for LLMs due to massive vocabulary sizes (Cui et al., 2025).
To mitigate this, contemporaneous works have proposed selective constraint mechanisms.(选择性约束机制)
For instance, Wang et al. (2025) propose Forking-Tokens, which restricts optimization to steps with high entropy to preserve exploratory potential.
Similarly, Cui et al. (2025) introduces KL-Cov, which identifies steps with high covariance(协方差) be-tween advantage estimates and log-probabilities, selectively imposing a strong KL penalty on these critical steps to sta-bilize training dynamics.
Trust Region
The concept of a Trust Region is foun-dational tostable optimization in reinforcement learning.
先解释Trust Region 是啥:
在策略梯度(Policy Gradient)里,我们本质是在做:
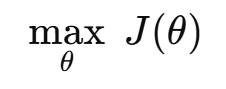
问题是:
-
如果一步更新太大 👉 policy 分布剧烈改变
-
重要性采样比率会爆炸
-
训练不稳定甚至崩溃
尤其你做 LLM RL 时,这个问题更明显 ------
policy 是 50k 维 softmax,更新稍微大一点就会乱。
所以核心问题变成:
❓ 如何保证每次 policy 更新不要偏离太远?
这就是 Trust Region 思想的来源。
TRPO → PPO 的演进其实是 "理论最优 + 复杂约束" → "工程可行 + 近似替代"
TRPO (2015)Trust Region Policy Optimization
TRPO (Schulman et al., 2015) constrains the policy update by enforcing a strict KL-divergence constraint on a surrogate objective, ensuring monotonic improvement while maintaining stability. This surrogate objective is designed to approximate the true objective while keeping the updates within a trust region defined by the KL-divergence.
核心思想
直接在优化问题里加入一个 KL 约束
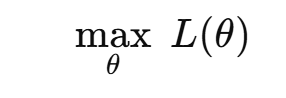
subject to:
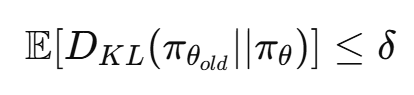
新策略不能离旧策略太远(KL距离受限)
surrogate objective
原始目标J(θ)不好直接优化,所以构造一个 surrogate
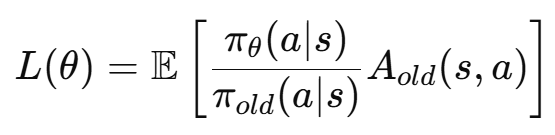
也就是 importance sampling + advantage
**PPO (2017)**Proximal Policy Optimization
In contrast, **PPO (Schul-man et al., 2017)**simplifies this approach by introducing a clipped surrogate objective that penalizes large policy de-viations, making it more tractable and efficient, while still achieving similar stability to TRPO.
它不再写约束优化,而是直接修改目标函数
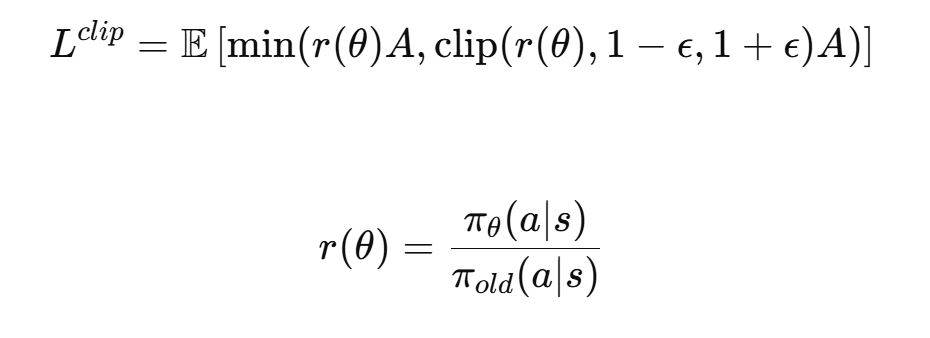
clip 在干什么?
当:
ratio 在区间内 → 正常更新
ratio 超过范围 → 被截断
这相当于:
不用 KL constraint
但"软性限制"policy变化幅度
它近似实现了 trust region。
Preliminaries
这个应该就是类似于task_definition
RL for LLMs
1. 核心思想:把 LLM 看成一个策略 πθ
把"文本生成"重新解释成"序列决策问题"
也就是说:
-
生成每一个 token = 做一次 action
-
上下文 = state
-
整个回答 = 一条 trajectory
-
reward 在最后给
这和强化学习完全一致。
2. LLM 是一个 softmax policy
LLM 定义为一个参数化的 softmax policy πθ
一个神经网络st 输出 zt
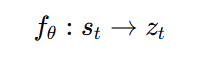
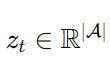
softmax 定义 policy
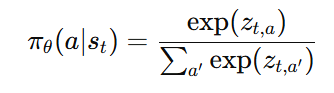
-
z_{t,a} = token a 的 logit
-
softmax 把它变成概率
-
πθ 就是"选某个 token 的概率"
3. 整个回答的概率
生成一个完整回答 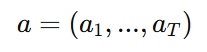
的概率是 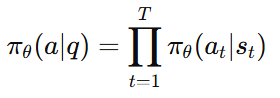
这叫自回归 factorization
和标准 language modeling 完全一致。
* 自回归: 用"过去"来预测"现在"。chain rule of probability(概率链式法则)
4. MDP 建模
把之前的步骤建模为episodic MDP
MDP = Markov Decision Process(马尔可夫决策过程)
它是强化学习的数学框架,包含 5 个东西:
(S,A,P,r,γ)
分别是:
-
S:状态空间 (states)
-
A:动作空间 (actions)
-
P:状态转移概率
-
r:奖励函数
-
γ:折扣因子
Markov 的意思是:未来只依赖现在,不依赖更早的过去。只要当前状态包含了所有历史信息,就够了。
P(st+1∣st,st−1,...,s1)=P(st+1∣st)
MDP 有两种类型:
Continuing MDP: 没有终点 一直运行下去 (e.g机器人控制)
Episodic MDP: 有明确的开始, 有明确的结束, 每次运行叫一个 episode (比如: 下棋一局/ 打游戏一局/ 生成一次回答)
在这里,我们的RL 过程建模为
状态 (State)
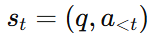
-
prompt
-
已经生成的 token
动作 (Action)
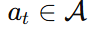
词表里的一个 token。
状态转移 (Transition)
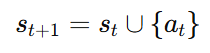
拼接一个 token, 而且是 deterministic, 没有环境随机性。
奖励函数
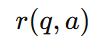
注意:reward 是针对完整序列的。
e.g 数学题答对 = 1 答错 = 0 或者 reward model 给分
RL 目标函数
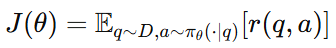
-
从数据集中采样 prompt q
-
用当前 policy 生成回答 a
-
计算 reward
-
最大化期望 reward
这就是标准 policy gradient 目标。
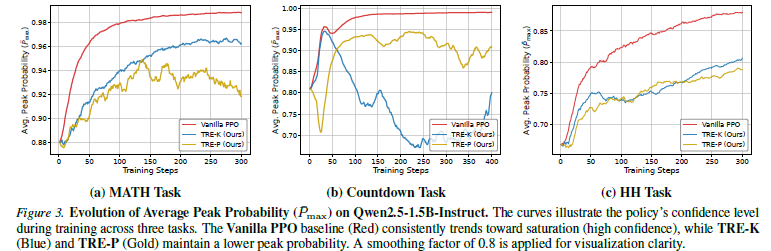
Trust Region Entropy (TRE)
不在"整个词表"上做 entropy,而只在"可信候选区域"里做 entropy
普通 entropy regularization
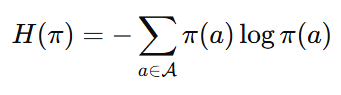
鼓励把概率分布变平, 但是LLM 的动作空间 ∣A∣≈50,000
大多数 token 是:语义无关/ 语法不合法/ 完全错误
如果你鼓励"全局"变平:
概率会被推到:巨大的尾部垃圾 token 上
这就是cumulative tail risk
Trust Region
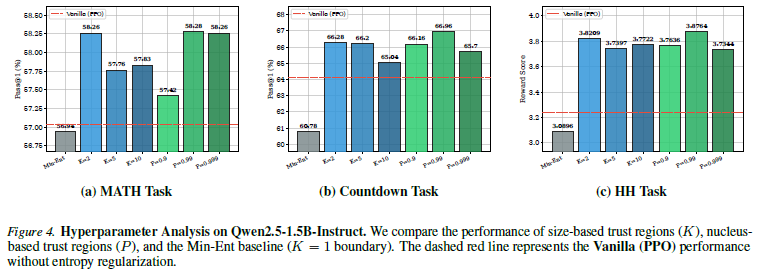
1️⃣ Top-K 集合(TRE-K)
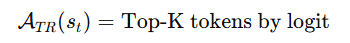
也就是:
-
按当前 logits 排序
-
取前 K 个 token
-
不涉及旧 policy
-
不涉及额外优化
这是最简单的定义。
2️⃣ Top-p / Nucleus 集合(TRE-P)
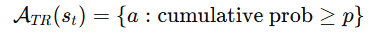
也就是:
-
先 softmax
-
按概率排序
-
累加到 ≥ p(比如 0.9)
-
得到 nucleus
这个更自适应。
TRE
他们定义: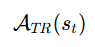
叫做trust region 内的 token 集合
他们从完整 logits: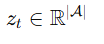
抽取子向量: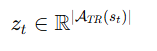
然后只在这个子空间里做 softmax:
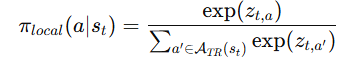
分母只在 trust region 内求和,叫做renormalized local distribution
然后他们算 local entropy
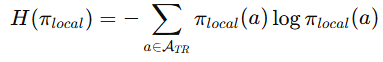
只衡量"合理候选"之间的多样性而不是整个词表的混乱程度。
特殊情况处理:
- 极度自信
当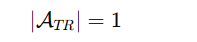
模型极度自信,只剩一个合理 token。那 entropy 自动变成0, 这一步不做正则
- scaling
entropy 的最大值是: log(∣A∣)
如果 trust region 很小,比如 K=5:最大 entropy 只有: log5
但全词表 entropy 最大是: log50000
尺度差很多,所以他们乘了一个比例:
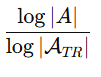
最终TRE loss
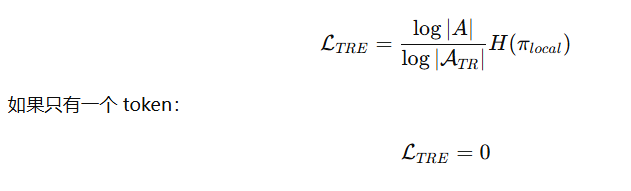
最终训练目标
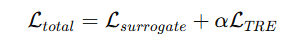
本质是PPO loss + local entropy
Experiment