在医学影像分析中,深度学习 常受限于高质量3D标注数据的匮乏。利用大规模**自监督学习(SSL)**进行无标注预训练,已成为打破这一瓶颈的关键路径。
本文解析的两篇论文均聚焦于"医学检测结合自监督学习"的前沿探索。第一篇针对脑部诊断,构建了首个专门处理3D头部CT的基础模型(Foundation Model) ,实现了在多项疾病分类任务中的强大泛化与少样本推理能力;第二篇则着眼于3D医学目标检测(3D Medical Object Detection),系统性评估了多种预训练策略,首次证实了基于体素重建的自监督预训练在检测任务上显著优于传统的有监督预训练。这两项研究为3D医疗人工智能的底层架构建设指明了方向。
我整理了医学检测+自监督学习方向相关论文合集,感兴趣的自取,希望能帮到你!
一、论文1:New York University 3D Foundation Model for Generalizable Disease Detection in Head Computed Tomography
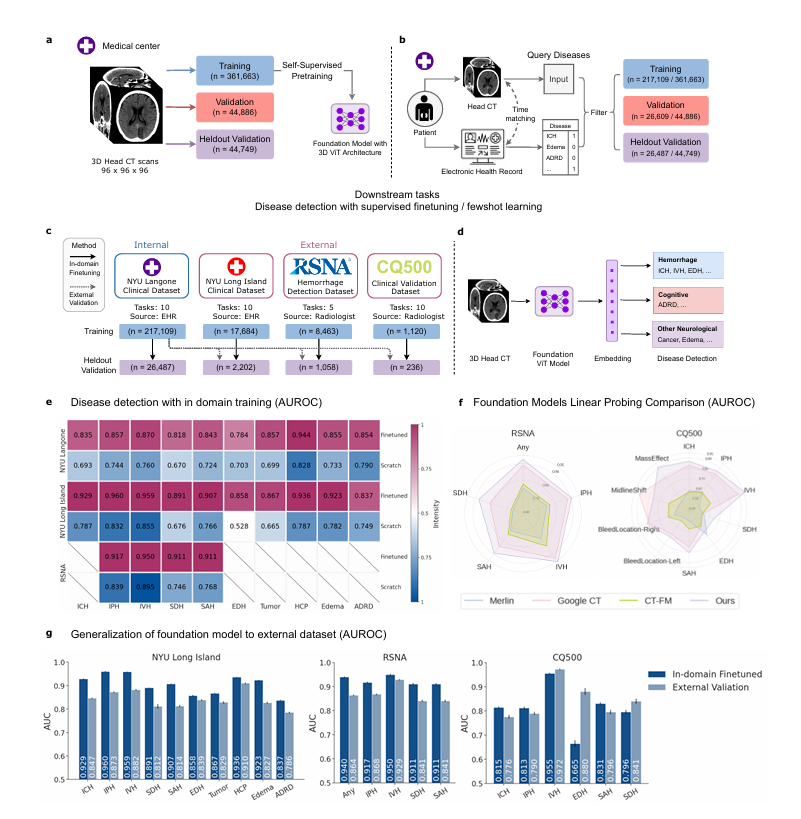
方法:
-
构建FM-HCT基础模型,利用36万例无标注数据,采用自蒸馏(Self-Distillation) 与**掩码图像建模(Masked Image Modeling, MAE)**进行SSL预训练。
-
基于**视觉变压器(Vision Transformer, ViT)**编码器直接处理3D体素块。为评估空间信息整合,模型计算注意力距离公式为:
创新点:
-
填补了专用3D头部CT基础模型的空白,无需昂贵的切片级标注即可提取三维全局通用表征。
-
在出血、脑肿瘤、相关痴呆症等10种下游疾病检测中表现出色,显著优于从头训练模型。
-
展现极高的标签效率,在**少样本学习(Few-shot Learning)**场景下仅利用极少数据便可逼近全数据微调效果。
二、论文2:MICCAI 2025 The Missing Piece: A Case for Pre-Training in 3D Medical Object Detection
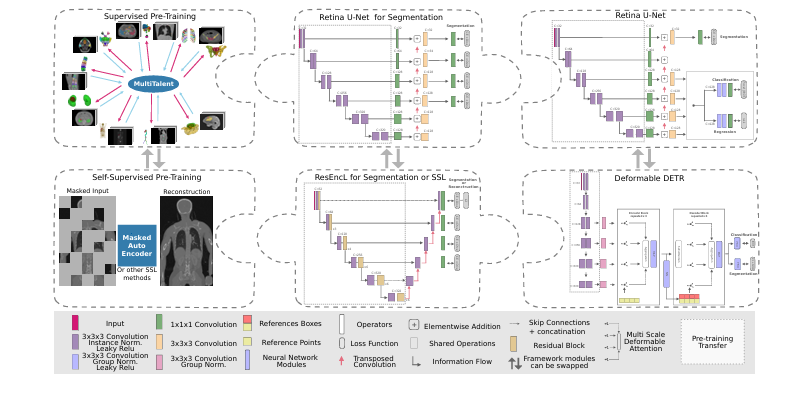
方法:
-
系统评估了有监督预训练与自监督预训练策略在3D医学目标检测中的实际影响。
-
采用Retina U-Net (CNN结构)和Deformable DETR(Transformer结构)两大先进检测器。
-
跨8个数据集,对比MultiTalent多组学分割预训练与多种SSL预训练,提取骨干网络直接迁移微调。
创新点:
-
首次全面、系统地实证研究了真正基于全3D结构的大规模预训练对3D目标检测的影响。
-
打通算法壁垒,实现目标检测与掩码自编码器等学习范式的无缝跨框架整合。
-
得出关键结论:基于重建的自监督预训练显著优于有监督预训练,而对比学习策略在此类任务中未显优势。