Elasticsearch 自定义分词实战:原理、组成与业务落地
分词是 Elasticsearch 构建倒排索引的核心环节,直接决定了检索的精准度与效率。
中文因无天然分隔符,原生分词器常难以满足复杂业务需求------自定义分词器成为破局关键。
本文从分词基础原理出发,拆解 ES 分词器的三大核心组件,结合 通用自定义分词 与 Ngram 分词 两大典型场景,详解设计思路、实现步骤与业务适配方案,为开发者提供可落地的技术参考。
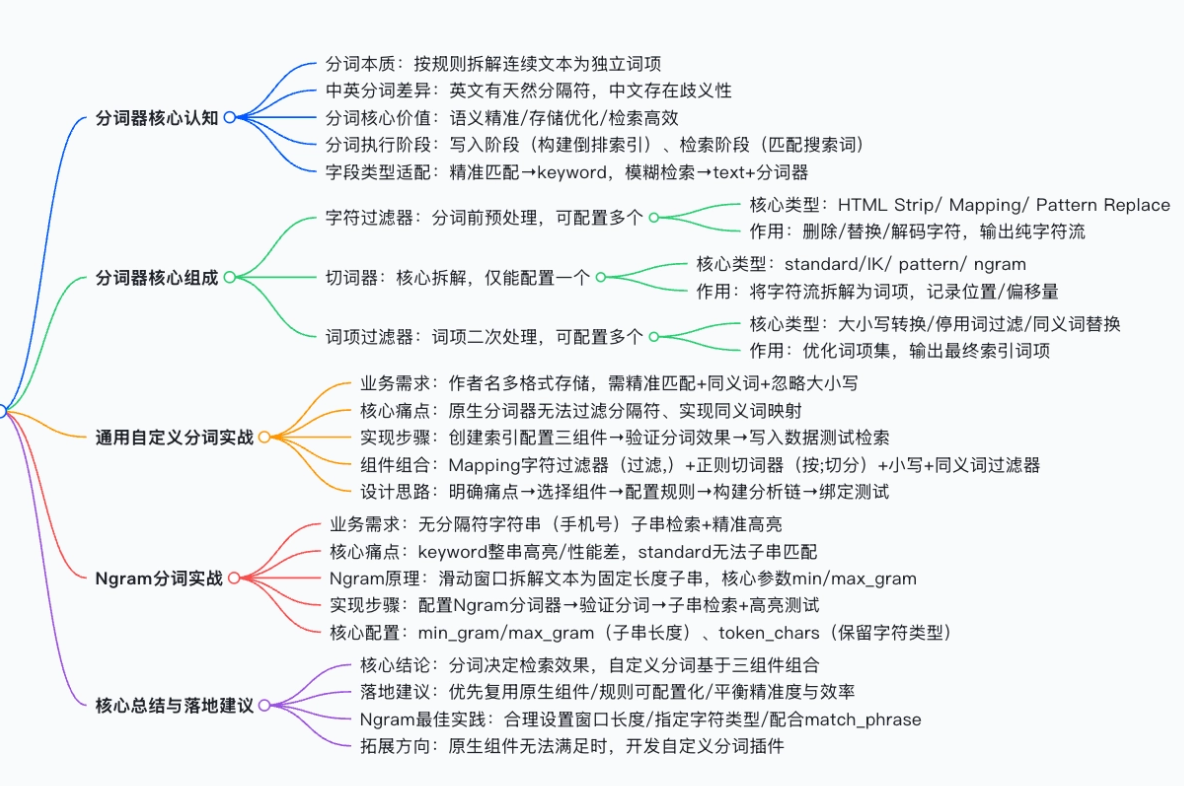
一、分词器核心认知:为什么需要分词?
1.1 分词的本质:语言的结构化拆解
分词是将连续文本字符串 按规则拆解为独立词项(Token) 的过程。不同语言差异显著:
- 英文 :以空格/标点天然分隔(如
you cannot use→you / cannot / use),规则简单; - 中文 :无天然分隔符,存在严重歧义 。例如:
杭州市长春药店❌ 错误分词:杭州 / 市长 / 春药 / 店✅ 正确分词:杭州市 / 长春 / 药店
中文分词的准确性,直接决定搜索系统的可用性。
1.2 分词的三大核心价值
| 维度 | 说明 |
|---|---|
| 语义维度 | 单字无完整语义,词项才是语义基本单位 |
| 存储维度 | 按词项索引 vs 按单字索引 → 大幅减少倒排索引体积 |
| 时间维度 | 倒排索引基于词项构建 →O(1) 时间匹配文档,提升检索效率 |
示例 :搜索
深入浅出Elasticsearch
- 若按单字索引:匹配大量含"深""入""浅"的无关文档;
- 若按词项索引:仅匹配完整标题,精准度跃升。
1.3 分词执行的两个阶段
ES 在以下两个阶段执行分词,必须保证规则一致:
| 阶段 | 作用 | 配置方式 |
|---|---|---|
| 写入阶段 | 对 text 字段分词,生成倒排索引 |
Mapping 中 analyzer 参数 |
| 检索阶段 | 对用户输入的查询词分词,匹配索引 | 默认使用字段的 search_analyzer(若未指定则用 analyzer) |
✅ 测试工具 :使用 _analyze API 快速验证分词效果:
json
POST _analyze
{
"analyzer": "ik_max_word",
"text": "昨天,小明和他的朋友们去了市中心的图书馆"
}1.4 字段类型与分词策略
| 字段类型 | 是否分词 | 适用场景 | 示例 |
|---|---|---|---|
keyword |
❌ 不分词 | 精准匹配(品牌、ID、分类) | "brand": "Apple" |
text |
✅ 分词 | 模糊检索(标题、描述、内容) | "title": "Elasticsearch 实战指南" |
原则 :**精准匹配用
keyword,模糊检索用text + 自定义分词器**。
二、ES 分词器的三大核心组件
ES 的分词器(Analyzer)由以下三部分按顺序协同工作构成:
[字符过滤器] → [切词器] → [词项过滤器]所有自定义分词器,均基于这三部分的组合配置实现。
2.1 字符过滤器(Character Filter):分词前的预处理
- 作用 :对原始文本进行字符级修改/过滤(如删标签、替换敏感词)
- 执行顺序 :第一步,可配置多个,按序执行
- 常用类型 :
html_strip:移除 HTML 标签(可保留指定标签)mapping:按映射表替换字符(如,→ 空)pattern_replace:正则替换(如手机号脱敏)
✅ 示例 :保留 <a> 标签,其余 HTML 全部清除
json
"char_filter": {
"my_char_filter": {
"type": "html_strip",
"escaped_tags": ["a"]
}
}2.2 切词器(Tokenizer):文本的核心拆解
- 作用 :将字符流拆为独立词项(Token)
- 关键约束 :必须且只能配置一个
- 常用类型 :
standard:标准分词(按空格/标点)ik_smart/ik_max_word:IK 中文分词(粗粒度 / 细粒度)pattern:正则切分(如按;分割)ngram:滑动窗口切分,用于子串匹配
2.3 词项过滤器(Token Filter):词项的精细化处理
- 作用:对 Token 进行二次加工(大小写、停用词、同义词等)
- 执行顺序:第三步,可配置多个,按序执行
- 核心类型 :
lowercase/uppercase:统一大小写stop:过滤停用词(支持自定义列表)synonym:同义词扩展,提升召回率length:过滤过短/过长词项
▶ 停用词实战
json
"filter": {
"my_stop_filter": {
"type": "stop",
"stopwords": ["www", "的", "了"],
"ignore_case": true
}
}▶ 同义词实战(两种模式)
a,b => c:单向替换(good,nice → excellent)a,b,c:双向等价(手机,移动电话,cellphone互为同义)
json
"synonyms": ["leileili => lileilei", "meimeihan => hanmeimei"]三、通用自定义分词实战:作者名称精准匹配
3.1 业务痛点
作者字段格式如:Li,LeiLei;Han,MeiMei,需实现:
- 过滤
,和;分隔符; - 忽略大小写(
lileilei匹配Li,LeiLei); - 支持同义映射(
leileili↔lileilei)。
原生分词器无法同时满足,需自定义分析链。
3.2 实现步骤
步骤 1:创建索引 + 自定义分词器
json
PUT /booksdemo
{
"settings": {
"analysis": {
"char_filter": {
"my_char_filter": { "type": "mapping", "mappings": [",=>"] }
},
"tokenizer": {
"my_tokenizer": { "type": "pattern", "pattern": "\\\\;" }
},
"filter": {
"my_synonym_filter": {
"type": "synonym",
"synonyms": ["leileili => lileilei", "meimeihan => hanmeimei"]
}
},
"analyzer": {
"my_analyzer": {
"char_filter": ["my_char_filter"],
"tokenizer": "my_tokenizer",
"filter": ["lowercase", "my_synonym_filter"]
}
}
}
},
"mappings": {
"properties": {
"name": { "type": "text", "analyzer": "my_analyzer" }
}
}
}步骤 2:验证分词效果
json
POST booksdemo/_analyze
{ "analyzer": "my_analyzer", "text": "LeiLei,Li;MeiMei,Han" }
// 输出: ["lileilei", "hanmeimei"]步骤 3:写入数据 + 检索测试
json
POST /booksdemo/_search
{
"query": { "match": { "name": "lileilei" } }
}
// ✅ 匹配两条记录3.3 设计方法论
通用自定义分词 = 按需组合三大组件
- 明确痛点:列出原生分词器缺失的能力;
- 选型组件:匹配字符过滤器 / 切词器 / 词项过滤器;
- 配置规则:定义映射、正则、同义词等;
- 组装分析链 :按
char_filter → tokenizer → token_filter顺序; - 绑定 + 测试 :用
_analyze验证,再上线。
四、Ngram 分词实战:子串匹配与精准高亮
4.1 业务痛点
对手机号 13611112222 检索:
keyword类型:只能全匹配,wildcard性能差,高亮整串;text + standard:无法拆分子串,无法部分匹配。
目标 :高效子串检索 + 仅高亮匹配部分。
4.2 Ngram 原理
- 滑动窗口算法:按固定长度从左到右滑动;
- 关键参数 :
min_gram:最小子串长度(如 4)max_gram:最大子串长度(如 11)token_chars:仅保留数字/字母等
示例 :
13611112222→1361,3611,6111,1111, ...,2222
4.3 实战:手机号子串检索
步骤 1:创建索引 + Ngram 分词器
json
PUT my_index_phone
{
"settings": {
"index.max_ngram_diff": 10,
"analysis": {
"analyzer": {
"phoneNo_analyzer": {
"tokenizer": "phoneNo_tokenizer"
}
},
"tokenizer": {
"phoneNo_tokenizer": {
"type": "ngram",
"min_gram": 4,
"max_gram": 11,
"token_chars": ["digit"]
}
}
}
},
"mappings": {
"properties": {
"phoneNo": { "type": "text", "analyzer": "phoneNo_analyzer" }
}
}
}步骤 2:检索 + 高亮
json
POST my_index_phone/_search
{
"highlight": { "fields": { "phoneNo": {} } },
"query": {
"match_phrase": { "phoneNo": "1111" }
}
}✅ 结果 :仅 1111 被高亮,非整串!
4.4 适用场景与最佳实践
✅ 适用场景
- 手机号、订单号、身份证等无分隔符 ID
- 拼音/简拼检索(
zs→张三) - 替代
wildcard提升模糊查询性能
⚠️ 最佳实践
- 合理设置
min_gram/max_gram:避免索引爆炸; - 指定
token_chars:过滤无效字符; - 用
match_phrase:防止跨子串误匹配; - 慎用于长文本 :Ngram 会导致索引体积剧增!
五、总结与落地建议
5.1 核心结论
| 要点 | 说明 |
|---|---|
| 分词决定检索质量 | 尤其在中文场景,自定义分词是刚需 |
| 三组件模型是基石 | char_filter → tokenizer → token_filter |
| 两类主流方案 | 通用组合(解决分隔符/同义词) + Ngram(解决子串匹配) |
| 测试先行 | 务必用 _analyze 验证分词结果 |
5.2 落地建议
- 优先复用原生组件 :90% 需求可通过组合实现,无需开发插件;
- 配置外置化:同义词、停用词等存为文件,便于维护;
- 平衡粒度与性能:细粒度 → 高召回但大索引;粗粒度 → 高性能但低召回;
- Ngram 谨慎使用 :仅用于短字符串 ID 类字段;
- 业务定制化 :电商、金融、医疗等场景需专属分词策略。
六、拓展:自定义分词插件开发(高级)
当原生组件无法满足时(如行业词典、自研算法),可:
- 基于
analysis-api开发自定义 Tokenizer/Filter; - 打包为 ES 插件,部署至集群;
- 在索引中引用。
⚠️ 注意 :插件需兼容 ES 版本,增加运维成本------非必要不开发。
结语 :分词不是"配置一下就行"的小事,而是搜索系统成败的关键一环。
掌握自定义分词,你便掌握了 Elasticsearch 检索能力的"命门"。