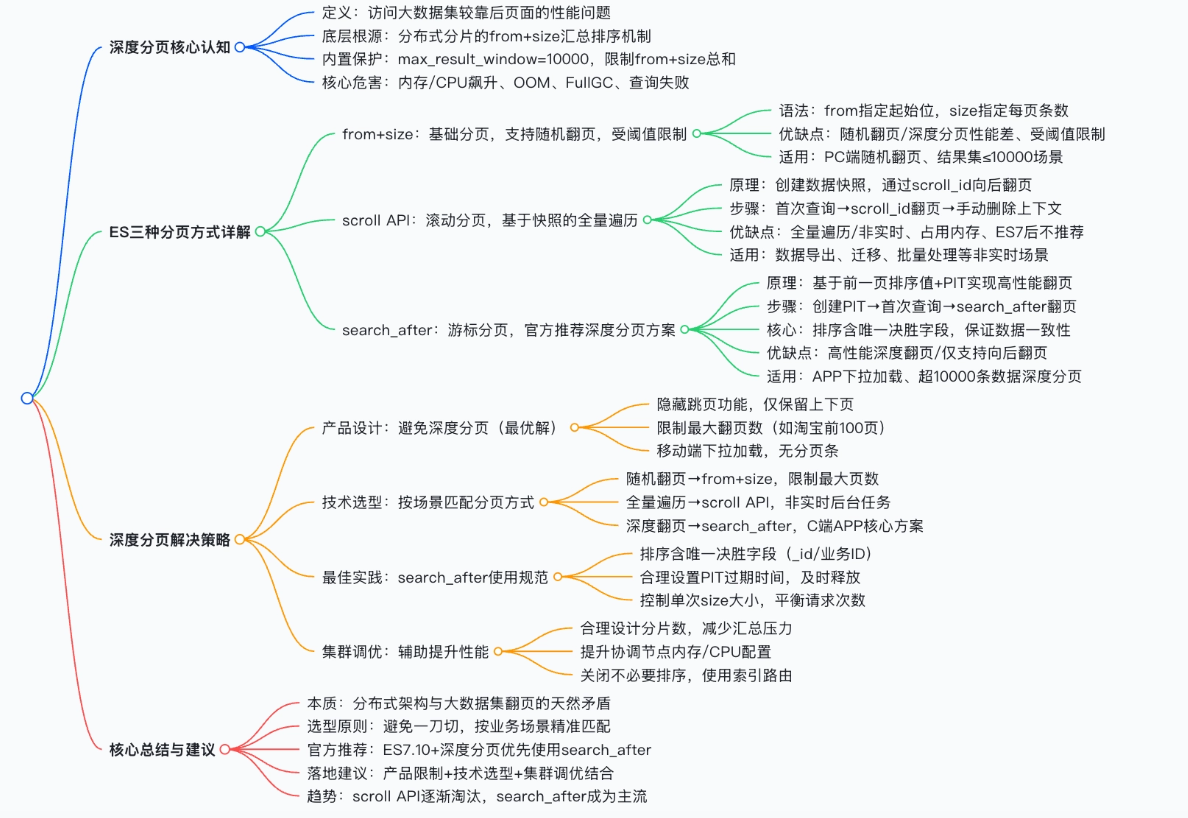
一、深度分页:是什么?为什么会出现问题?
1.1 什么是深度分页?
- 查询耗时随页码深度指数级增长;
- 内存与 CPU 资源消耗剧增;
- 超过阈值后直接被 ES 拒绝。
1.2 ES 分页的底层执行机制(from + size)
ES 是分布式搜索引擎,数据分布在多个分片上。标准分页(from + size)的执行流程如下:
- 请求分发:协调节点将查询广播至所有分片;
- 分片执行 :每个分片独立查询并返回 前
from + size条记录 到内存; - 结果汇总 :协调节点收集所有分片的结果(共
N × (from + size)条); - 二次排序 + 裁剪 :全局排序后,仅保留
[from, from + size)区间的数据返回。
💡 核心痛点:
当
from = 10000,size = 100时,每个分片需加载 10100 条 数据,协调节点需对 所有分片的 10100 条 进行全局排序------最终却只返回 100 条!资源浪费极其严重。
1.3 ES 的保护机制:max_result_window
为防止 OOM,ES 默认设置:
json
index.max_result_window = 10000即 from + size ≤ 10000,否则抛出异常。
-
示例:每页 20 条 → 最多翻到第 500 页;
-
可通过以下方式修改(不推荐随意调大 ):
jsonPUT /your_index/_settings { "index.max_result_window": 20000 }
1.4 为什么不能简单调大 max_result_window?
调大阈值只是 **"掩盖问题"**,而非解决问题:
- 分片仍需加载大量数据到堆内存;
- 协调节点排序压力剧增,极易触发 Full GC 或 OOM;
- 分布式环境下,分片越多,性能衰减越快。
二、ES 三大分页方式深度对比
| 维度 | from + size |
scroll API |
search_after |
|---|---|---|---|
| 性能 | ❌ 深度翻页性能差 | ⚠️ 中等(快照开销) | ✅ 高性能 |
| 翻页能力 | ✅ 支持随机跳页 ❌ 受限于 10000 | ❌ 仅向后翻页 ✅ 支持全量遍历 | ❌ 仅向后翻页 ✅ 无限深度 |
| 实时性 | ✅ 实时 | ❌非实时(快照) | ✅近实时(PIT 轻量视图) |
| 资源占用 | ❌ 高(深度时) | ⚠️ 中(上下文驻留内存) | ✅ 低 |
| ES 官方推荐 | 基础场景 | ❌ES7+ 已不推荐 | ✅ES7.10+ 主推方案 |
| 使用复杂度 | ✅ 简单 | ⚠️ 需管理 scroll_id |
⚠️ 需管理 PIT+ 排序值 |
2.1 from + size:基础但危险
语法示例
json
GET /index/_search
{
"query": { "match_all": {} },
"from": 0,
"size": 10
}适用场景
- 小数据集(≤10000 条);
- PC 端支持 随机跳页 的搜索(如百度、京东);
- 后台管理系统。
⚠️ 限制
- 绝对不可用于深度分页;
- 超过
max_result_window直接失败。
2.2 scroll API:全量遍历的"老方案"
核心原理
- 首次查询创建 数据快照(snapshot);
- 后续通过
scroll_id获取下一批数据; - 快照基于首次查询时刻,后续写入不可见。
使用流程
-
首次查询 (带
scroll参数):jsonGET /index/_search?scroll=5m { "query": { ... }, "size": 100 } -
后续翻页 :
jsonPOST /_search/scroll { "scroll": "5m", "scroll_id": "xxx" } -
手动清理 (重要!):
jsonDELETE /_search/scroll { "scroll_id": "xxx" }
适用场景
- 数据导出、迁移、批量处理;
- 不要求实时性的后台任务。
❌ 缺陷
- 非实时;
- 上下文长期驻留内存,易造成资源泄漏;
- ES 7+ 官方已不推荐用于分页。
2.3 search_after:官方主推的深度分页方案 ✅
核心优势
- 基于 游标(cursor) 思想,无深度限制;
- 使用 Point In Time (PIT) 保证一致性;
- 资源占用远低于
scroll; - 支持 近实时查询。
关键要求
- 必须指定排序字段;
- **必须包含唯一决胜字段(tiebreaker)**,如
_id,避免重复或跳过数据。
使用流程
-
创建 PIT(Point In Time)
jsonPOST /index/_pit?keep_alive=5m→ 返回
pit_id -
首次查询
jsonGET /_search { "query": { "term": { "status": "active" } }, "pit": { "id": "pit_id", "keep_alive": "1m" }, "size": 20, "sort": [ { "timestamp": "asc" }, { "_id": "asc" } // ← 唯一决胜字段! ] } -
后续翻页(使用上一页最后一条的排序值)
jsonGET /_search { "query": { "term": { "status": "active" } }, "pit": { "id": "pit_id", "keep_alive": "5m" }, "size": 20, "sort": [ { "timestamp": "asc" }, { "_id": "asc" } ], "search_after": [1678901234567, "doc_999"] // ← 上一页最后一条的值 } -
释放 PIT(可选但推荐)
jsonDELETE /_pit { "id": "pit_id" }
适用场景
- APP 下拉加载更多(天然向后翻页);
- 电商商品列表、内容流(超 10000 条);
- 对性能和一致性有要求的 C 端业务。
三、深度分页的根本解决策略
✅ 策略 1:产品设计上规避深度分页(最优解)
最好的优化,是不让问题发生。
- PC 端:隐藏"跳转到第 N 页",仅保留"上一页/下一页";
- 限制最大页数 :如淘宝、京东仅展示前 100 页;
- 移动端 :采用 无限下拉加载 ,天然适配
search_after。
✅ 策略 2:按业务场景精准选型
| 业务场景 | 推荐方案 | 原因 |
|---|---|---|
| PC 搜索 / 后台管理(需跳页) | from + size |
支持随机跳页,且控制在 10000 内 |
| 数据导出 / 批量处理 | scroll |
全量遍历,无需实时 |
| APP 下拉 / 超长列表 | search_after |
高性能、无限深度、近实时 |
✅ 策略 3:用 search_after 实现高性能深度分页
若必须深度分页,请严格遵循以下最佳实践:
- 排序字段必须含唯一决胜字段 (如
_id); - PIT 过期时间合理设置(如 1~5 分钟),可在每次请求中续期;
- 单次
size控制在 20~100,平衡性能与请求次数; - 查询结束后主动删除 PIT,避免资源泄漏。
✅ 策略 4:集群级辅助优化
- 合理分片:避免过多分片(建议 ≤ 节点数 × 2);
- 提升协调节点配置:高内存 + 多核 CPU;
- 关闭非必要排序 :若无需排序,可按
_doc(最快); - **使用路由(routing)**:减少查询涉及的分片数。
四、总结与核心建议
🔑 核心结论
from + size≠ 深度分页方案 ------ 仅适用于 ≤10000 条的随机翻页;scroll已过时 ------ 仅用于非实时全量处理;search_after是未来 ------ ES 7.10+ 官方主推,性能与一致性兼得;- 产品设计 > 技术调优 ------ 限制用户行为是最高效解法。
🛠 落地建议
- 产品侧:PC 限页数,APP 用下拉;
- 开发侧 :封装
search_after工具类,统一处理 PIT 与游标; - 运维侧:监控堆内存、GC 频率,防止 OOM;
- 架构侧 :新项目**直接放弃
scroll**,全面拥抱search_after。