最近做 AI 应用时,经常会遇到一堆很容易混在一起的词:
Agent、RAG、Tool Calling、Skill、MCP、Prompt、Resource、Runtime......
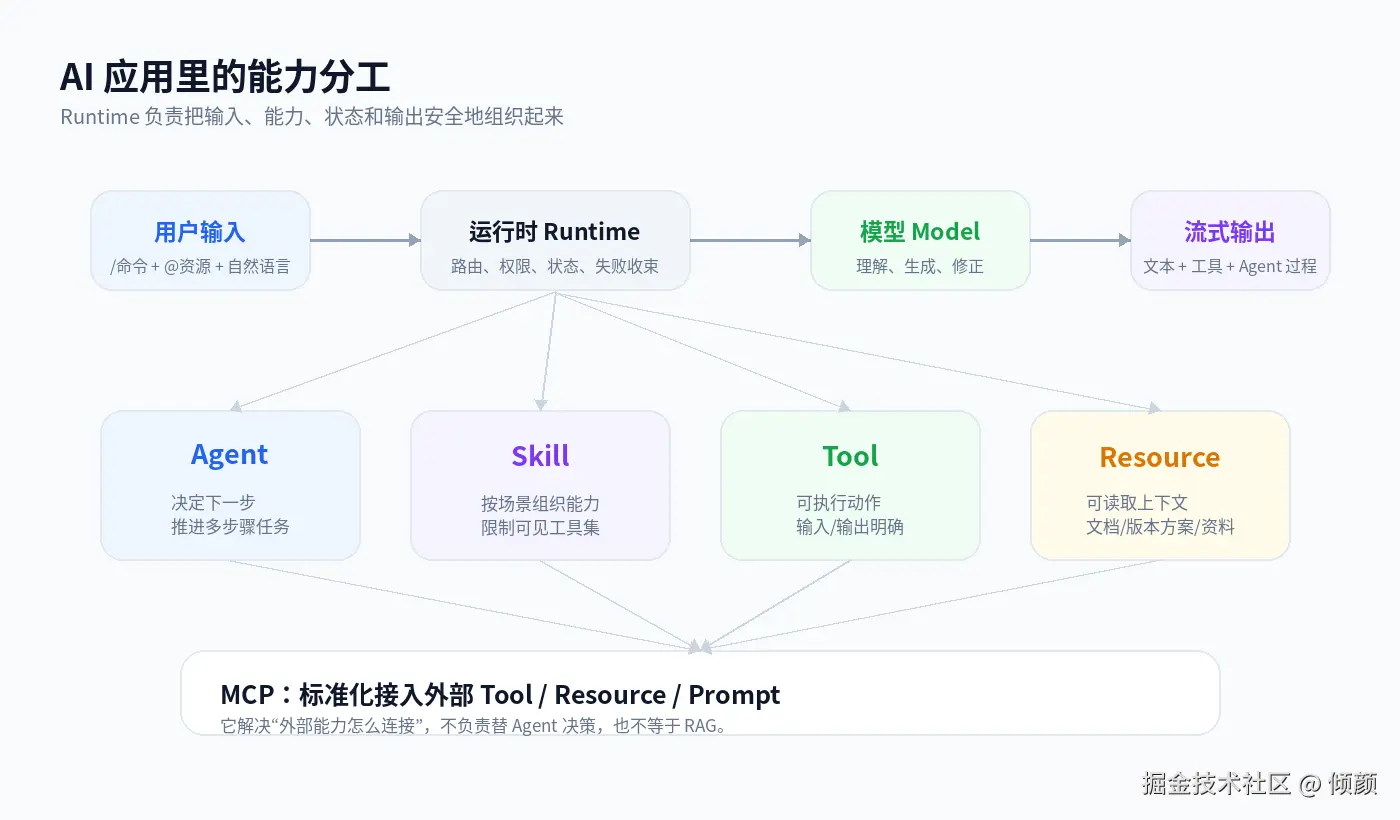
这些词看起来都和"大模型能力增强"有关,也经常一起出现在 AI 应用架构图里。但真正落到工程实现时,它们解决的问题并不是同一层。
我在做 AI Mind 的过程中,也踩过这个认知坑。AI Mind 是我自己做的一个 AI 应用运行时实验项目,从普通聊天、工具调用、技能分组、MCP 接入,一直迭代到最近的可控 Tasklist Agent。项目做得越往后,我越明显感觉到:如果不先把这些概念的边界拆清楚,代码很容易越写越乱。
这篇文章不做百科式定义,而是从 AI 应用工程实现的角度,聊聊这些概念到底怎么分工。
先给一个结论:
读文档不等于 RAG,调工具不等于 Agent,接入 MCP 也不等于做了 Agent 平台。
更工程化一点说:
| 概念 | 一句话理解 | 解决的问题 |
|---|---|---|
| Agent | 根据目标和上下文推进多步骤任务 | 谁来决定下一步 |
| RAG | 检索外部知识并注入上下文 | 知识从哪里来 |
| Tool | 模型可以调用的具体能力 | 能执行什么动作 |
| Skill | 按场景组织起来的一组能力 | 能力怎么分组 |
| MCP | 外部 Tool / Resource / Prompt 的标准化接入方式 | 外部能力怎么连接 |
| Resource | 可读取的上下文资料 | 读什么内容 |
| Prompt | 任务模板或行为约束 | 怎么指导模型 |
| Runtime | 调度输入、能力、状态和输出 | 整个链路怎么跑起来 |
下面一个个拆开看。
1. Agent:不是会调工具就叫 Agent
很多人一说 Agent,就会想到"模型会调用工具"。但我现在更愿意把 Agent 理解成:
Agent 是围绕一个目标,能够推进多步骤任务,并根据中间结果决定是否继续、修正或结束的一条执行链路。
普通聊天通常是这样:
用户问一句
模型答一句Tool Calling 通常是这样:
用户提出问题
模型判断需要某个工具
调用工具
模型基于工具结果回答Agent 则更进一步:
用户给出目标
Agent 读取上下文
生成中间产物
调用工具校验或补充信息
根据结果决定是否修正
最终输出结果所以 Agent 的关键不只是"有没有调用工具",而是:它是否围绕一个目标进行多步骤推进。
但在真实工程里,可靠的 Agent 通常不应该完全自由。
我不太认同"Agent 就应该让模型想干嘛就干嘛"。实际项目里,Agent 应该有资源边界、工具边界、最大步骤数、失败策略和输出约束。否则模型一旦误判,就可能读错资料、调错工具,甚至进入无意义循环。
比如 AI Mind 最近做的第一个 Agent,是一个"版本方案转任务清单 Agent"。它的作用是:基于项目里的版本方案文档,生成一份可执行的 tasklist 草稿。
它的触发条件很明确:
ruby
/tasklist + @docs://versions/*.md也就是说,用户必须显式选择 /tasklist 命令,并且引用一个版本方案文档,系统才会进入这个 Agent。
它的执行流程也很受控:
diff
读取版本方案
-> 提取方案里的关键信息
-> 生成 tasklist 草稿 v1
-> 校验 tasklist 结构
-> 必要时最多自动修正一次
-> 再次校验
-> 输出最终 tasklist 草稿这里模型主要负责生成和修正文稿,运行时负责控制路径、资源边界、状态转移和失败收束。
所以我更愿意把它叫做:
可控 Agent,而不是自由 Agent。
Agent 的价值不是"模型无限自由",而是在有限边界内完成多步骤任务。
2. RAG:不是读文档就叫 RAG
RAG 也是一个很容易被泛化的词。
很多时候,只要系统能读取文档,大家就会说"这个项目做了 RAG"。但严格一点看,读文档和 RAG 不是一回事。
RAG 解决的是:
模型本身不知道某些知识时,系统先从外部知识库里检索相关内容,再把这些内容注入上下文,让模型基于这些内容回答。
一个相对完整的 RAG 链路,一般会涉及:
文档切分 chunking
向量化 embedding
索引 indexing
检索 retrieval
重排 rerank
上下文注入
模型生成也就是说,RAG 的核心不只是"读",而是"检索"。
如果用户明确指定一个文件:
less
@docs://README.md 总结这个文档系统直接读取这个文件并交给模型总结,这更像 Resource 读取,而不是完整 RAG。
AI Mind 当前也没有把自己包装成 RAG 项目。
现在 AI Mind 做的是受控文档资源读取,例如:
arduino
docs://README.md
docs://architecture/runtime-boundary.md
docs://versions/*.md用户显式引用某个资源,运行时读取这个资源,然后把它注入当前任务上下文里。
它没有做:
arduino
chunking
embedding
vector index
retrieval
rerank所以我不会说 AI Mind 当前已经实现了完整 RAG。
这个例子反而说明了一个很重要的边界:
读文档不等于 RAG。
后续如果 AI Mind 做文档切分、向量索引、按问题召回相关上下文,那才是进入 RAG 方向。
3. Tool:模型可以调用的具体能力
Tool 是 AI 应用里最容易理解,但也最容易和 Agent 混淆的概念。
我更倾向于把 Tool 理解成:
一个输入明确、输出明确、可以被运行时执行的具体能力。
比如:
查询天气
计算日期
读取资源
校验 tasklist 结构
检查文档一致性Tool 通常会有结构化描述:
输入是什么
输出是什么
失败怎么表达
当前任务是否允许调用在 AI Mind 的 Tasklist Agent 里,一个比较典型的 Tool 是:
任务清单结构校验工具(validate_tasklist_structure)它的作用不是生成 tasklist,而是校验 Agent 生成出来的 tasklist 草稿结构是否合格。
它会检查:
vbnet
有没有标题
有没有来源方案
有没有 Step
有没有 checklist
有没有验证内容
有没有工程验证
有没有暂停点这个 Tool 的实现也不是"再问一次大模型",而是用 Markdown 结构解析和确定性规则来校验。
大致思路是:
python
解析 Markdown
识别标题、列表、任务项
根据规则输出 pass / warning / fail这里的分工很关键:
生成由模型完成,结构校验由确定性 Tool 完成。
如果所有事情都交给模型,系统会很飘;如果把可确定的问题交给规则工具,整个 Agent 链路就会稳定很多。
Tool 和 Agent 的区别也可以这样理解:
Tool 是一个具体能力,Agent 是组织这些能力推进任务的执行链路。
调了一个 Tool,不代表就是 Agent。
4. Tool、RAG、Agent 放在一起对比
这三个概念最容易混在一起,可以单独放在一起看:

Tool 更像一个明确动作:
diff
用户问题
-> 调用一个明确工具
-> 得到工具结果
-> 模型整理回答RAG 更像知识增强链路:
diff
用户问题
-> 检索相关知识
-> 注入上下文
-> 模型基于知识回答Agent 更像目标驱动的多步骤任务:
diff
目标任务
-> 读取上下文 / 调用工具
-> 观察结果并修正
-> 最终完成任务所以:
Tool 解决动作问题,RAG 解决知识问题,Agent 解决任务推进问题。
这三者可以组合,但不是同一个东西。
5. Skill:不是单个函数,而是一组能力的组织方式
Skill 这个词,不同项目可能叫法不一样。有人叫 Skill,有人叫 Capability,有人叫 Mode,有人叫 Toolset。
在 AI Mind 里,我更愿意把 Skill 理解成:
按任务场景组织起来的一组能力。
Tool 是单个能力,而 Skill 是能力分组。
比如 AI Mind 里有两类基础 Skill:
阅读技能(reader-skill)
工具技能(utility-skill)阅读技能更偏阅读类任务:
读取文档
总结内容
注入上下文
处理 Resource工具技能更偏通用工具类任务:
计算
日期
转换
结构化小工具为什么需要 Skill?
因为真实 AI 应用里,Tool 会越来越多。如果每次都把所有工具直接暴露给模型,模型选择工具的成本会上升,误调用的概率也会上升。
Skill 的价值在于:
先判断当前任务属于什么场景
再暴露这个场景下需要的有限能力也就是说,Skill 是一个能力组织层。
它不是最终执行层,也不是 Agent 本身。它更像在运行时里帮我们回答一个问题:
当前任务应该让模型看到哪些能力?
在 AI Mind 的演进里,我不是一开始就做 Agent,而是先做 Tool Calling,再做多工具运行时,再逐步收敛出阅读技能和工具技能。到 v0.1.0,才引入第一个受控单 Agent。
这个顺序对我来说是比较自然的:
先有具体工具
再有工具运行时
再有能力分组
再有受控 Agent6. MCP:不是 Agent,也不是 RAG,而是能力接入协议
MCP 也很容易被误解成 Agent。
但从工程上看,MCP 解决的是另一个问题:
外部能力怎么标准化接入 AI 应用。
MCP 可以暴露几类东西:
Tool
Resource
Prompt也就是说,MCP 更像一个连接协议。
它不负责决定任务怎么做,也不负责知识怎么检索,更不等于 Agent 平台。
比如 AI Mind 接入 MCP 后,可以用统一方式拿到:
本地文档资源
远程上下文资源
外部工具
任务模板
服务来源
执行状态这里 MCP 解决的是连接问题:
外部服务怎么告诉 AI 应用:我有哪些 Tool?
外部服务怎么告诉 AI 应用:我有哪些 Resource?
外部服务怎么告诉 AI 应用:我有哪些 Prompt?但至于什么时候用这些能力、怎么组织这些能力、失败后怎么办,是 Runtime 或 Agent 要解决的问题。
一句话:
MCP 提供能力,Agent 决定什么时候用能力,Runtime 负责把能力安全地跑起来。
7. 放到 AI Mind 里看一遍
把这些概念放回 AI Mind,会更清楚。
| AI 应用概念 | AI Mind 中的体现 |
|---|---|
| Agent | 版本方案转任务清单 Agent |
| Tool | 任务清单结构校验工具 |
| Skill | 阅读技能 / 工具技能 |
| MCP | 本地 / 远程 MCP 能力接入 |
| Resource | 版本方案文档、README、架构文档 |
| Prompt | 文档总结 / tasklist 生成相关模板 |
| Runtime | 聊天运行时、工具运行时、流式输出内核 |
| RAG | 当前未做完整 RAG,只做受控文档资源读取 |
以 Tasklist Agent 为例。
用户输入:
ruby
/tasklist @docs://versions/v0.0.12-docs-resource-composer-capability-tool-runtime.mdAI Mind 不是直接把这句话丢给模型,让模型自由发挥,而是先从输入框里识别结构化信息:
bash
命令:/tasklist
资源:docs://versions/*.md只有这两个条件同时满足,才会进入 Agent。
进入 Agent 后,运行时会按受控路径推进:
markdown
1. 读取用户显式引用的版本方案
2. 提取版本方案里的目标、非目标、关键变更、测试计划等信息
3. 生成 tasklist 草稿 v1
4. 调用任务清单结构校验工具
5. 如果结构有问题,最多修正一次
6. 再次结构校验
7. 输出可复制的 tasklist 草稿整个过程会通过 Agent 执行面板展示出来:
读取版本方案
生成 tasklist 草稿 v1
校验 tasklist 结构 v1
自动修正 tasklist 草稿 v2
再次校验 tasklist 结构 v2
输出最终答案AI Mind 的实际效果图:
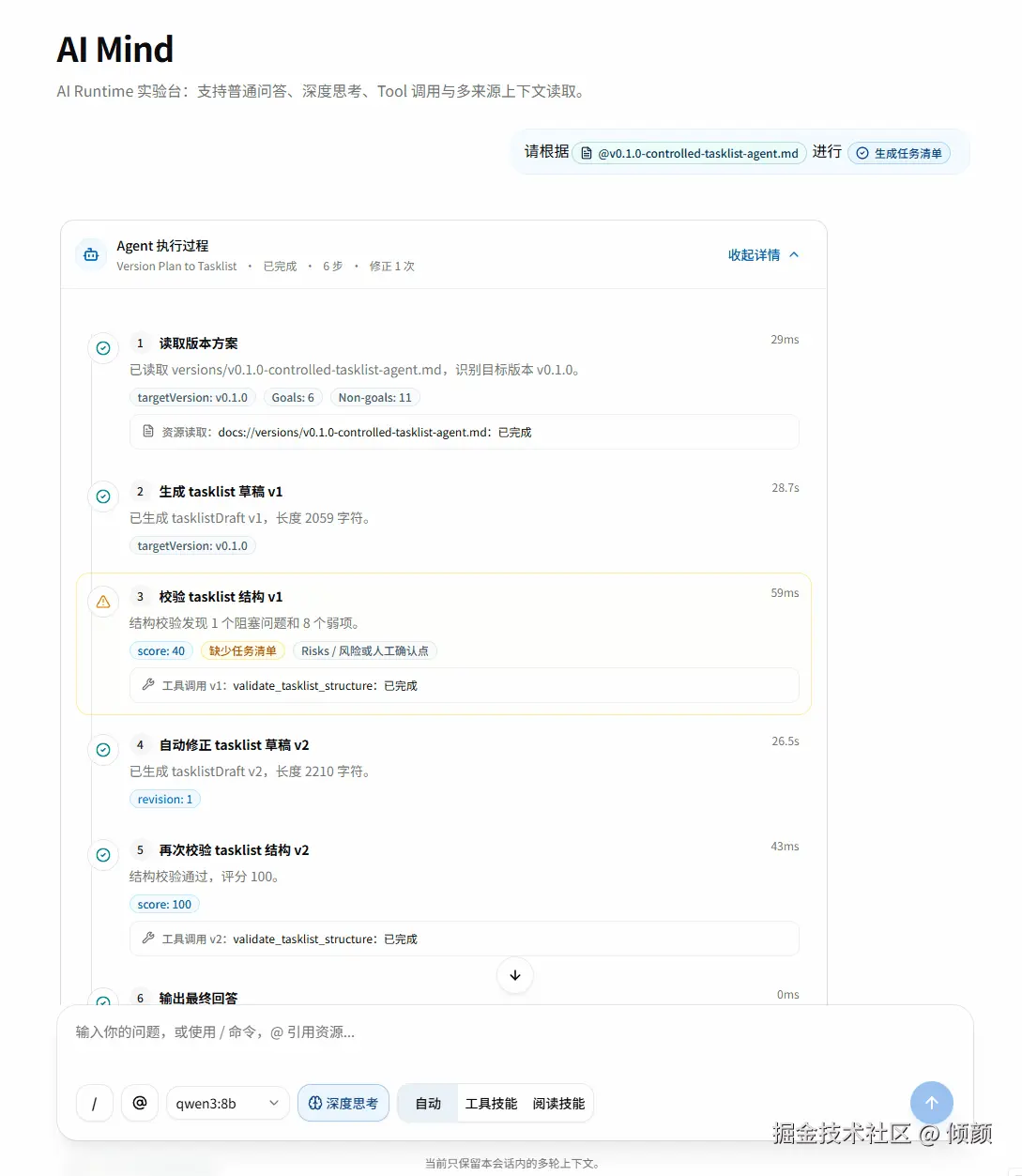
这里可以看到几个概念的分工:
arduino
输入框负责结构化输入
Resource 负责提供版本方案上下文
Agent 负责多步骤任务推进
Tool 负责结构校验
Runtime 负责状态控制和边界约束
Stream 负责展示过程和结果这个例子里没有完整 RAG,因为没有检索和召回。它只是用户显式引用版本方案,系统读取这个 Resource 并用于生成 tasklist。
这也是我想强调的边界:
受控 Resource 读取不是 RAG,但它是很多 AI 应用走向 RAG 之前的一步。
8. 一张图串起来
再把这些概念放到一条链路里看:
swift
用户输入
↓
输入层(/命令 + @资源)
↓
运行时
↓
Skill / Agent
↓
Tool / Resource / Prompt
↓
MCP / 本地能力
↓
模型
↓
流式输出 / Agent 执行面板这张图里,每一层解决的问题都不一样。
输入层解决输入结构化问题:
bash
用户到底是普通提问,还是 /summary,还是 /tasklist?
用户有没有 @ 引用资源?运行时解决执行和边界问题:
当前任务应该走普通问答,还是走 Skill,还是进入 Agent?
哪些资源能读?
哪些工具能用?
最多执行几步?
失败后怎么收束?Skill 解决能力分组问题:
这是阅读类任务,还是工具类任务?
应该暴露哪些能力?Agent 解决多步骤推进问题:
现在走到哪一步?
是否需要修正?
是否可以输出最终结果?Tool 解决具体执行问题:
校验结构
计算日期
查询信息
转换格式Resource 解决上下文来源问题:
读取哪个文档?
读取哪个版本方案?
读取哪个外部上下文?MCP 解决外部能力接入问题:
外部服务怎么把 Tool / Resource / Prompt 暴露给 AI 应用?流式输出解决可观察性问题:
用户怎么看到模型正在做什么?
工具调用有没有完成?
Agent 走到哪一步?把这些边界拆开,AI 应用就不会变成一坨混在一起的 prompt 和工具调用。
9. 总结:先分清层次,再谈架构
做 AI 应用时,我现在越来越觉得,概念本身不难,难的是不要把所有东西混在一起。
读文档不等于 RAG。
调工具不等于 Agent。
接入 MCP 不等于做了 Agent 平台。
Skill 不是单个函数,而是一组能力的组织方式。
Tool 是具体能力,Agent 是多步骤任务推进链路。
MCP 是能力接入协议,Runtime 才是把这些能力组织、约束、执行和展示出来的工程层。
最后再用一句话收束:
Agent 解决决策问题。
RAG 解决知识问题。
Tool 解决动作问题。
Skill 解决能力组织问题。
MCP 解决外部能力接入问题。
Runtime 解决这些东西怎么安全、稳定、可观察地跑起来。AI Mind 目前也不是完整 AI 平台。它更像一个持续迭代的 AI Runtime 实验项目。
从 Tool Calling,到 Skill Runtime,到 MCP 接入,再到可控 Tasklist Agent,我更关注的是一步步把这些边界拆清楚,而不是一开始就把所有概念都堆进来。
这也是我写这篇文章的原因:
真正做 AI 应用时,先分清这些概念的分工,再决定要不要引入它们。
最后,如果你对这些概念在真实项目里的落地感兴趣,可以看看我正在持续迭代的开源项目:
AI Mind:一个围绕 AI Runtime、Tool / Resource / Prompt、MCP 和受控 Agent 逐步演进的 AI 应用实验项目。
GitHub:github.com/HWYD/ai-min...
目前项目已经完成 v0.1.0 的受控 Tasklist Agent:基于版本方案生成 tasklist 草稿,并通过结构校验和 Agent 执行面板展示完整过程。
⭐ 如果觉得项目有参考价值,欢迎 Star 支持一下,也欢迎一起交流 AI 应用前端、MCP、Agent Runtime 这些方向。
后续我也会在掘金专栏继续更新 AI Mind 的迭代过程,包括 MCP、Agent Runtime、可控 Agent、LangGraph 等方向。