好久没写文章了,最近有一些对 AI 的看法,不吐不快。这篇文章,也是在 GPT 基于一个粗糙的草稿的润色下完成的,配图也是 Agent 帮忙搞定的。看起来缺少一些我过往文章的一些文风,不过这对 AI 也并不是难事,算了,懒得喂给它学习了。整体也写的挺好的,能清楚表达意义,文字上没一个错别字,要知道以前手写文章时候,光改错别字、断句啥的都需要整理好久。好了,不再啰嗦,开启正文。
现在 AI 大模型的流行,某种程度上反而证明了:这个世界很多地方,本质上就是个巨大的"草台班子" 。

目前主流的 LLM(大语言模型),本质更像一个"超大规模的文本预测器":给定上文,去预测下一个最可能出现的词(更准确地说是 token),然后一个 token 接一个 token 地生成完整回答。
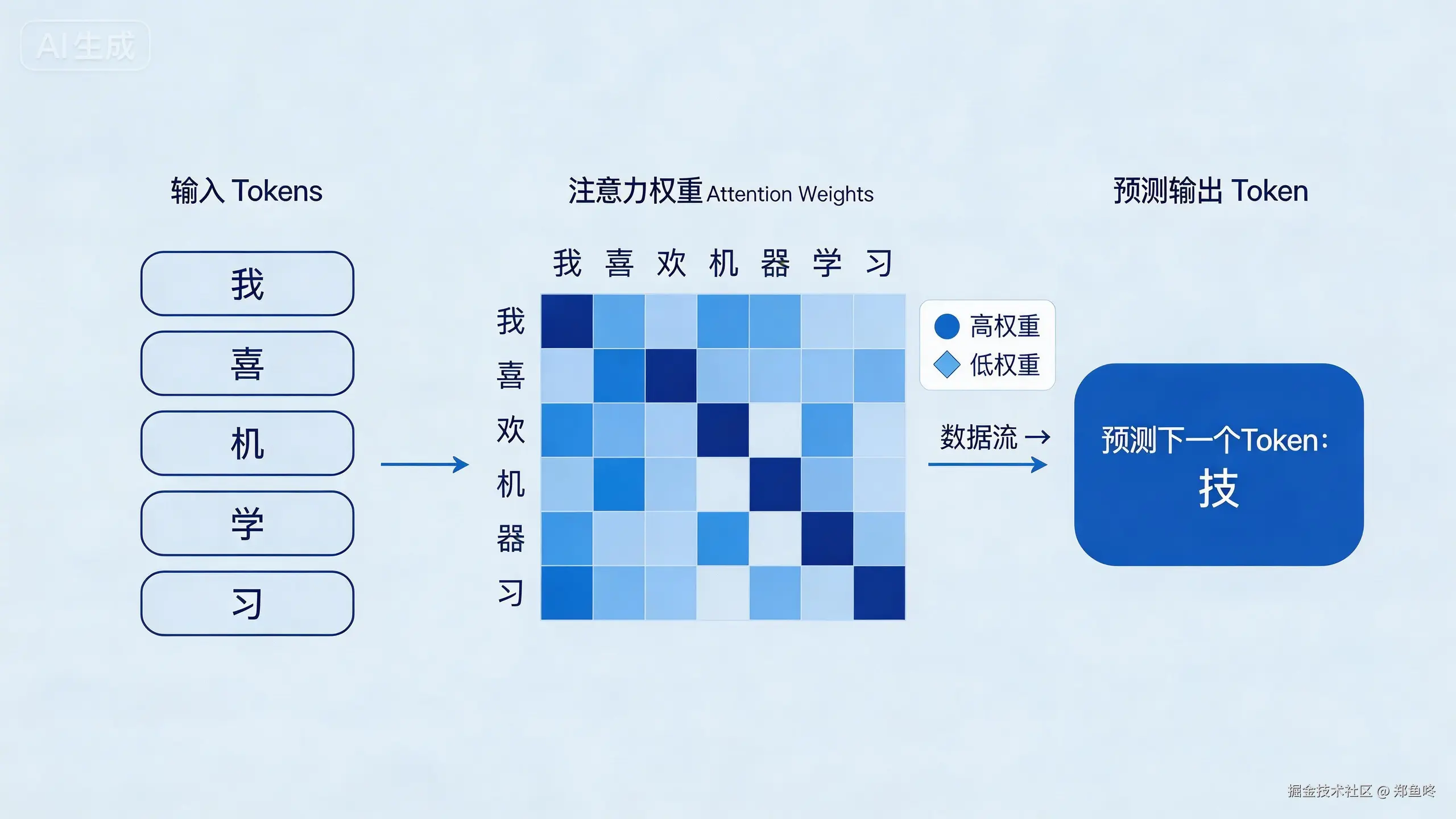
在生成过程中,得益于 Transformer 的注意力机制,模型会"回头看"前面哪些词更重要------也就是它会抓重点。这使得它对语言的把握明显强于传统 NLP。再加上对互联网公开知识的海量预训练,LLM 的每次迭代看起来都在向"智能"靠近一步。
但这并不等于它学会了"思考"。
更准确地说,它学到的是大量"推理文字的写法与套路" ,以及一些可泛化的模式,比如类比、归纳、分步求解等。因此它能输出看起来很像推理的内容,却仍然可能胡编乱造(幻觉),生成听上去合理但事实错误的结论。
这有点像一些逻辑不太好的人写文章:每个字都认识,读起来也顺,但连起来其实不知道在说什么。因为它并没有真正的逻辑思维能力。
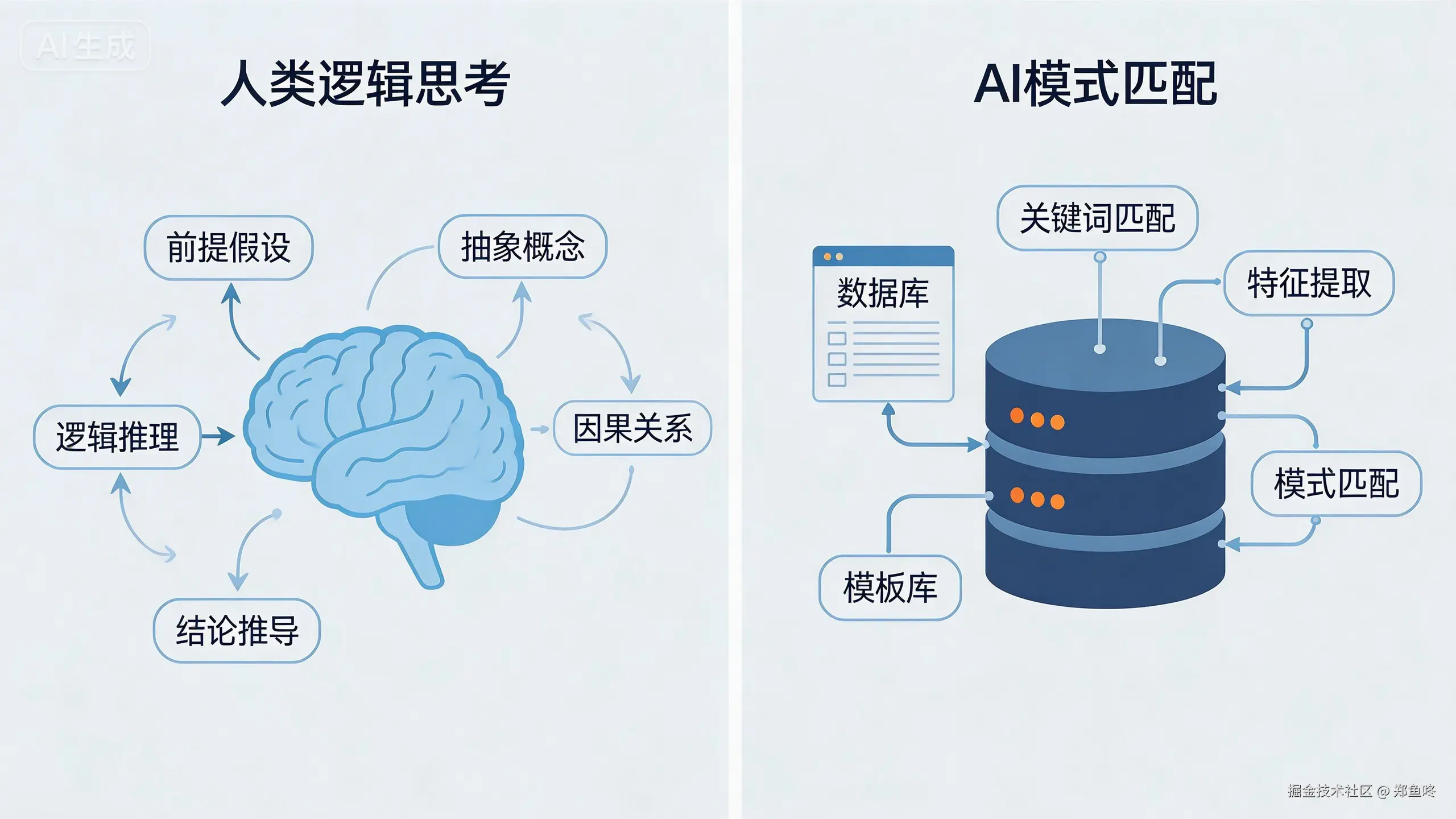
但这还不是最关键的问题。更要命的是:它缺乏持续的创新能力。
人类能在物种进化中胜出,不只是因为会一代代模仿学习,更因为会创新------在总结规律的基础上提出新问题、发明新工具、开辟新路径。而现阶段的 AI 并不具备这一点。这也是为什么杨立昆并不认可"只靠文本训练"就能实现真正 AGI 的原因之一。
即便如此,LLM 的能力仍然强到"足够好用" ,甚至在很多场景里效果惊艳,超过了大量工作的真实要求。
比如程序员为什么都喜欢 Claude Code?很重要的原因是:这类模型训练时吸收了大量"人类解决编程问题的过程数据",例如 Stack Overflow、GitHub Issue 等。那些数据里不只是代码片段,还包含了程序员定位 bug、分析原因、尝试方案、权衡取舍的思路。模型通过学习这些内容,等于也"照着套路"学会了。
 这意味着它在很多任务上可以达到中级程序员的水平,能相对独立地解决问题。
这意味着它在很多任务上可以达到中级程序员的水平,能相对独立地解决问题。
但它依然很难做出真正的创新。
例如,它并不会自己发现传统 DOM 操作开发视图的结构性问题,然后发明 React、Vue 这类框架来解决;它更多是在既有范式内堆代码、补功能。除非你明确提示,它才会进一步抽象、优化、重构。
同样,它也缺乏"自主的审美能力" :不知道什么是更好的工程实践、什么是更差的工程实践;很多时候能写出能跑的代码,但不一定能写出长期可维护、可演进的系统。
不过,这并不妨碍它替代大量初级程序员的工作。因为我刚才说的那种抽象能力与工程审美,现实中很多程序员也并不具备。
也正因为如此,LLM 的爆火从另一个角度说明:很多工作并没有想象中那么高大上。大量岗位的产出,本质上就是在既有模板、流程和经验里做"可用的拼装",靠模仿同事也能把事情糊弄过去。
这恰恰证明了:这世界就是个巨大的草台班子。