
本文作者:云舒,TRAE 产品运营
我们在上一篇已经带大家认识了 Token 和上下文窗口,那在 TRAE 中究竟应该如何节省 Token 呢?本文将从 AI Coding 的六问心法出发,到 10 个具体场景的小技巧,手把手教你如何用 TRAE 更省钱!

Token 花销的构成
我们在上一篇的文章中已经理解了 Token 的概念,这里简单回顾一下,你与大模型进行一次对话的成本,可以简单理解为一个公式:
总费用 = 未命中缓存的输入 Token× 输入单价 + 输出 Token× 输出单价 + 缓存 Token× 缓存单价(如有)
-
输入 Token: 你发给模型的所有内容,包括本轮提问、历史对话摘要、通过 *# *引用的代码/文件/文档等。
-
输出 Token: 模型返回给你的所有内容,包括文字回复、代码产物、工具调用信息等。
-
缓存 Token: 部分模型为优化长对话与重复请求,缓存历史上下文计算状态所消耗的 Token。后续收到相似请求时可直接复用,减少重新推理与 Token 消耗。
因此,输入和引用的上下文体量、多轮交互的长度、选用模型的差异以及工具调用返回内容的多少,都会直接影响最终的 Token 消耗与费用。

AI Coding 的六问心法
在正式开始介绍节省 Token 的技巧之前,先帮你建立一个更重要的共识:好的提问,比任何"省流小窍门"都更关键。 这 6 个问题就是所有技巧的底层"检查清单",几乎适用于你与 AI 交互的所有场景。
你可以把它们当成一张"提问前体检单":问题没想清楚的地方,用这 6 个问题补齐;表达不够清楚的部分,用这 6 个问题重新打磨。
不仅能从源头减少大量无效 Token 消耗,还能让 AI 的回答更聚焦、更可用!
-
「目标是否唯一」如果任务复杂,先拆解,再分步执行。当你切换任务时,建议新开一个对话。
-
「信息是否必要」只提供与当前任务直接相关的信息。问自己:"AI 完成这个任务,真的需要这些信息吗?"避免投喂整个项目或无关的文档。
-
「指令是否清晰」使用清晰、无歧义的动词和限定词,避免使用"优化一下"、"处理一下"等模糊指令。
-
「角色是否设定」为 AI 指定一个明确的角色(如"资深 Go 语言架构师"、"代码审查专家"),能让其输出更聚焦、更专业。
-
「格式是否指定」明确要求 AI 的输出形态,如"返回 JSON 格式"、"使用 Markdown 表格",能避免后续不必要的格式转换和沟通。
-
「示例是否提供」对于复杂或特定的输出要求,"Show, don't tell"。提供一个简单的输入输出示例,比大段的文字描述更有效。

10 个技巧教你更会管理上下文
技巧一:适时新开对话,保持任务焦点
对话历史是 Token 消耗的隐形杀手,在持续的对话中,每一轮的交互记录都会被累积并作为新的上下文发送给 AI。当一个对话承载了多个不相关的任务时,历史信息不仅会占用上下文窗口,还会形成信息噪声,干扰 AI 对当前任务的理解。
场景举例
-
任务切换时: 刚修复完一个 Bug,现在要开始开发一个新功能。
-
对话过长时: 你发现已经和 AI "聊"了半个下午,它的回复开始变慢,或者需要你反复提醒之前的要求。
-
AI 陷入困境时: AI 连续几次都没能解决你的问题,开始重复给出错误的方案,或者"钻牛角尖"。
如何做
-
一事一议: 遵循"一个任务,一个对话"的原则。当你要从"改 Bug"切换到"写文档"时,果断点击"新对话"按钮。
-
及时停止过长对话: 当一个对话已经持续了十几轮甚至几十轮,感觉 AI 的响应开始变慢或出现偏差时,应主动开启新对话或者使用上下文压缩。
-
携带关键信息开启新对话: 如果新任务需要旧对话中的某些背景,将旧对话中由 AI 或你总结的最终结论、关键代码片段或核心设计,作为初始背景信息复制到新对话中。
-
果断打破无效循环: 如果 AI 连续 3 次没修好一个问题,不要继续纠缠, 把当前代码回滚或整理思路后,新开一个会话,重新描述问题。
技巧二:精准限定范围,减少噪声输入
向 AI 提供上下文时, "少即是多"是一条黄金法则。 喂给 AI 过多无关或冗余的信息,就如同让一个人去图书馆帮你找一段资料,你却把整排书架的书都推到他面前。AI 需要花费额外的计算资源(Token)去阅读、理解和筛选这些无关信息,这不仅增加了成本,还极大地提高了它被误导、抓错重点的风险。
场景举例
-
代码分析: 需要 AI 审查或修改一个大项目中的某个具体函数。
-
文档问答: 想基于一份几十页的产品文档,询问其中某个功能的具体设计。
-
问题排查: 需要 AI 帮忙分析日志文件,但只有特定时间段的日志与问题相关。
如何做
-
用「#」精准引用:T RAE 支持多种类型的上下文引用能力,在处理复杂项目时,通过 # 符号引用相关文件或代码片段,能够让 AI 能够更好地理解您的意图和项目背景。尽量引用具体的函数、类 或 代码块,而不是整个文件。例如: #UserService.login 比 #UserService.ts 节省 Token。
-
AI 描述指定明确的路径: 如果你知道具体文件路径,直接告诉 AI,而不是让它搜索。指定行号范围读取文件,避免读取整个大文件。例如:"请检查文件 /src/utils/auth.go 的第 88 到 105 行,是否存在安全漏洞。
-
只添加必要文件 : 比起习惯性地把整个文件夹或大量无关文件加入 Chat,只添加相关文件和代码会更节约 Token。
技巧三:优化输入内容,有效沟通
与 AI 沟通,就像给下属分配任务。指令越清晰、具体,包含的背景信息越充足,对方就越能一次性产出符合你预期的结果。模糊或过于宽泛的指令(比如"优化下这段代码")容易导致 AI 的猜测和试错,每一次返工,都是对 Token 和时间的双重浪费。
举个🌰:比起"优化这段代码","重构这段代码,将其中处理用户验证的逻辑提取到一个独立的函数中,并增加错误处理机制"更容易获得符合预期的回答。
场景举例
-
代码生成: 需要 AI 帮你写一个新功能或模块。
-
文档撰写: 让 AI 帮你起草一份技术方案。
-
复杂查询: 需要 AI 结合多个条件进行分析和总结。
如何做
-
明确角色与格式: 在指令开头为 AI 设定一个角色(如"你是一位资深前端架构师"),能让它的输出更专业。同时,明确你想要的输出格式(如"请以 Markdown 表格形式返回")。
-
一次性把话说完 : 尽量在一个 Prompt 里包含所有必要约束条件(如:使用什么库、在这个文件改、不要动原有逻辑等)。
-
提供伪代码或思路 : 如果你心里有方案,可以直接告诉 AI。让 AI "填空"比"开放式作文"更省 Token,也更准确。
-
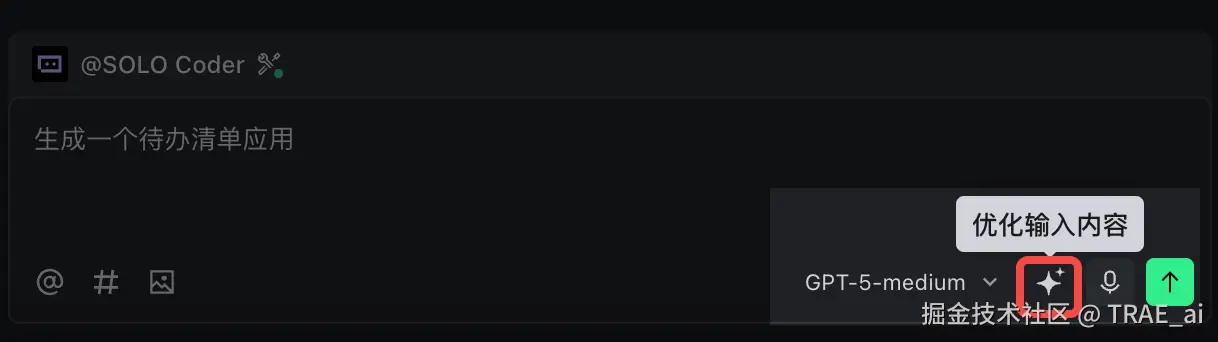
善用内置优化: TRAE IDE 内置了 Prompt 优化能力,在 AI 对话输入框中输入 Prompt 后,点击 优化输入内容 按钮,让 AI 帮你将口语化的表达转化为结构更清晰、信息量更丰富的专业指令。你还可以修改或者重试,完善输入内容。
技巧四:批量处理,降低交互频率
每一次与 AI 的交互,都是一次完整的"请求-响应"循环,其中包含了上下文处理、模型推理等多个环节,这些都会产生固定的开销。频繁、碎片化的"你问一句,我答一句",就像不停地拨打电话,每次都要重新寒暄一遍,效率低下。将多个相关的子任务打包成一个结构清晰的复合指令,一次性发给 AI,能让它在更完整的语境中思考,减少重复的上下文开销。提升整体效率。
场景举例
-
多文件修改: 需要在项目的多个组件中,进行类似的样式或逻辑调整。
-
关联任务流: 需要 AI 先创建一个组件,然后为这个组件编写测试用例。
-
并行信息检索: 需要 AI 同时帮你查找好几个不同问题的资料。
如何做
在发起请求前,思考是否可以将多个相关步骤合并为一次性指令。
-
并行执行搜索: 需要搜索多个内容时,让 AI 一次性并行搜索。
-
合并相似操作: 需要修改多个相似的地方时,一次性说明所有修改点。例如:"请在以下三个组件中(Button.tsx , Card.tsx , Input.tsx ),将所有 color="primary" 的属性改为 variant="solid" 。"
-
打包完整任务流: 将相关联的问题打包,让 AI 一次性返回所有结果。
示例:"请创建一个新的 Button 组件:
-
使用 TypeScript 和 Styled-components。
-
支持 primary 和 secondary 两种变体。
-
同时 为这个组件编写 Jest 单元测试,覆盖点击事件和样式渲染。"
技巧五:主动引导输出,给出辅助指令
AI 的输出同样会消耗 Token,冗长、无关的输出还会增加你的阅读和筛选成本。默认情况下,AI 倾向于提供详尽的解释、完整的代码块以及友好的寒暄,但在很多场景下,这些都是不必要的。通过在指令中明确输出的范围和格式,可以有效减少不必要的生成内容,实现"精确打击"。
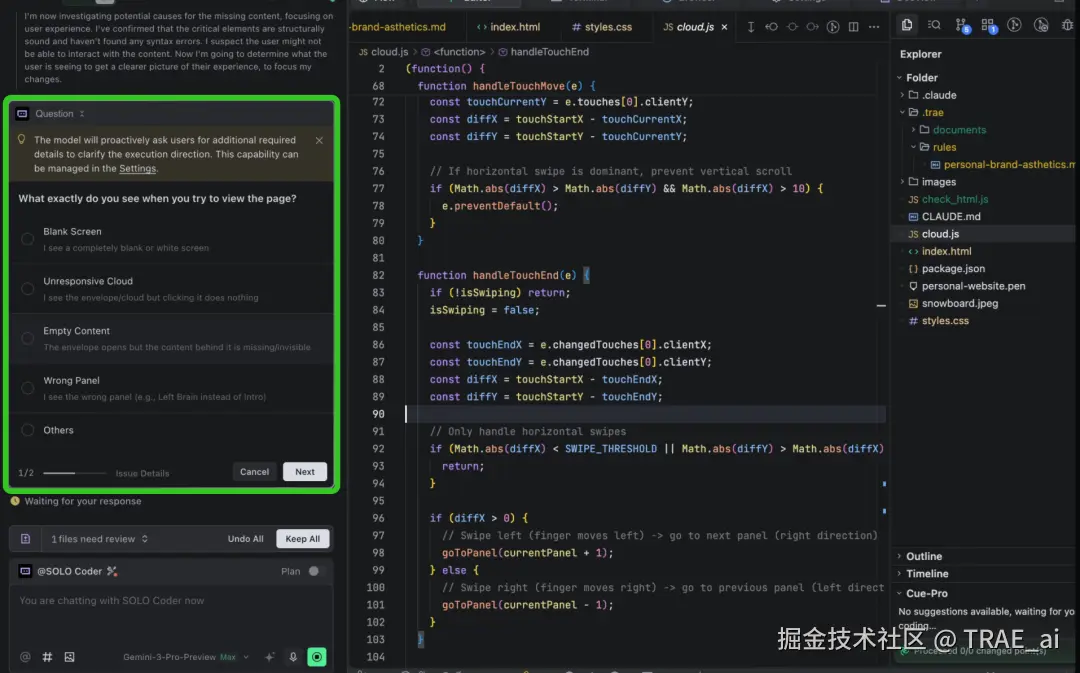
TRAE IDE 最新提供了 Question 功能 ,支持模型主动向用户提问(Ask User Questions) ,一般是在执行任务过程中,AI 遇到多种可行方案或需要了解用户偏好时,会主动暂停并向用户提问,确保最终结果符合你的预期。
场景举例
-
快速拿到代码: 你很清楚自己要做什么,只是需要 AI 帮你快速生成一小段代码。
-
格式化输出: 你需要 AI 返回特定格式的数据,如 JSON 或 Markdown 表格,以便直接用于后续程序。
-
避免模型持续陷入循环: 发现 AI 开始"胡言乱语"或在同一个错误上反复打转。
如何做
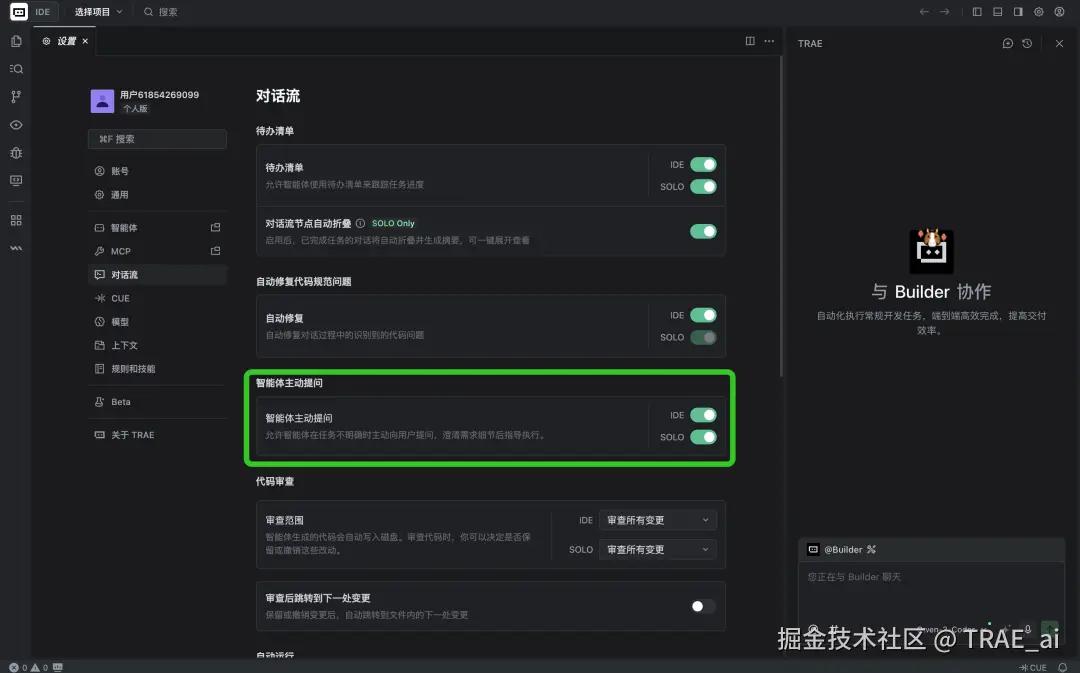
- 打开智能体主动提问(Question ): 除 Chat 和 Sub Agent 之外都支持模型主动提问,你可以在设置中手动开启/关闭这一功能,让模型引导你澄清问题。
- 明确要求"不要解释": 在你的指令末尾加上一句"直接给出代码,不要解释"或"只需要最终结果,无需分析过程"。
- 指定输出格式: 明确告诉 AI 你想要的格式,例如:"请将对比结果以 Markdown 表格的形式返回"。
- 主动打断无效输出: 当发现 AI 的输出已经偏离主题或明显错误时,立即点击"停止生成"。不要等它生成完几百行错误代码再告诉它错了,那几百行代码的 Token 你已经白白支付了。
TRAE IDE 内置了智能死循环检测,当实时监测到模型在反复输出同样或类似的内容时,会自动中断生成,主动为你避免无效的 Token 消耗。
技巧六:先计划再行动,用 Plan / Spec 驾驭复杂任务
对于复杂的开发任务,比如从零开始搭建一个新模块或进行大规模重构,直接让 AI "开干"风险很高。它可能会误解你的意图,或者选择一个不理想的技术路径,导致后期大量的返工。Plan/Spec 模式的核心思想是"谋定而后动"。在动手写代码前,先让 AI 生成一份详细的开发计划或规格说明书,你确认了它的思路和步骤后,再让它执行。
SOLO Coder 已经支持 Plan 和 Spec 模式,在处理复杂任务时,可以先开启 Plan/Spec 再发送指令。
往期文章:一文理解 Spec 模式。
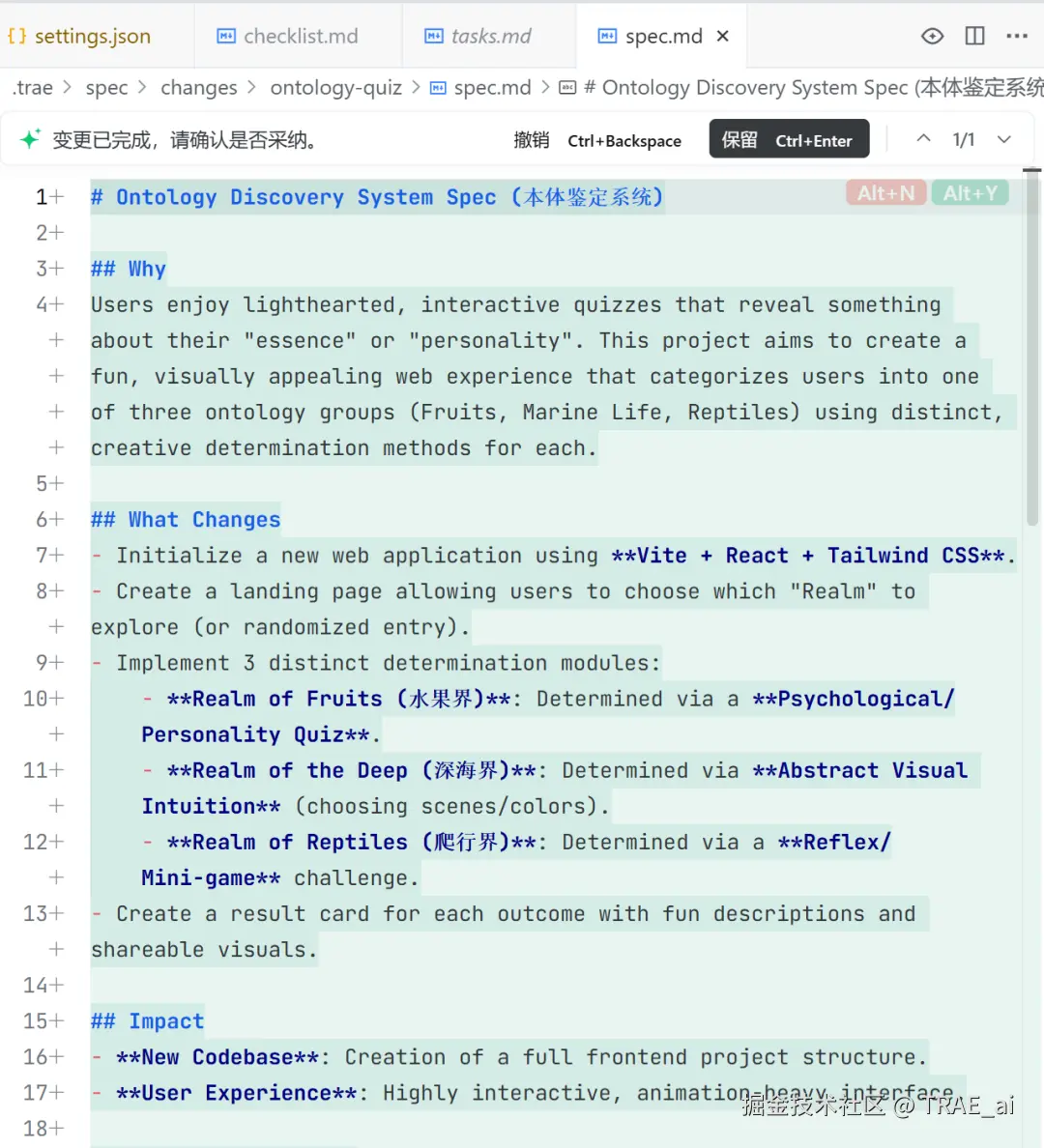
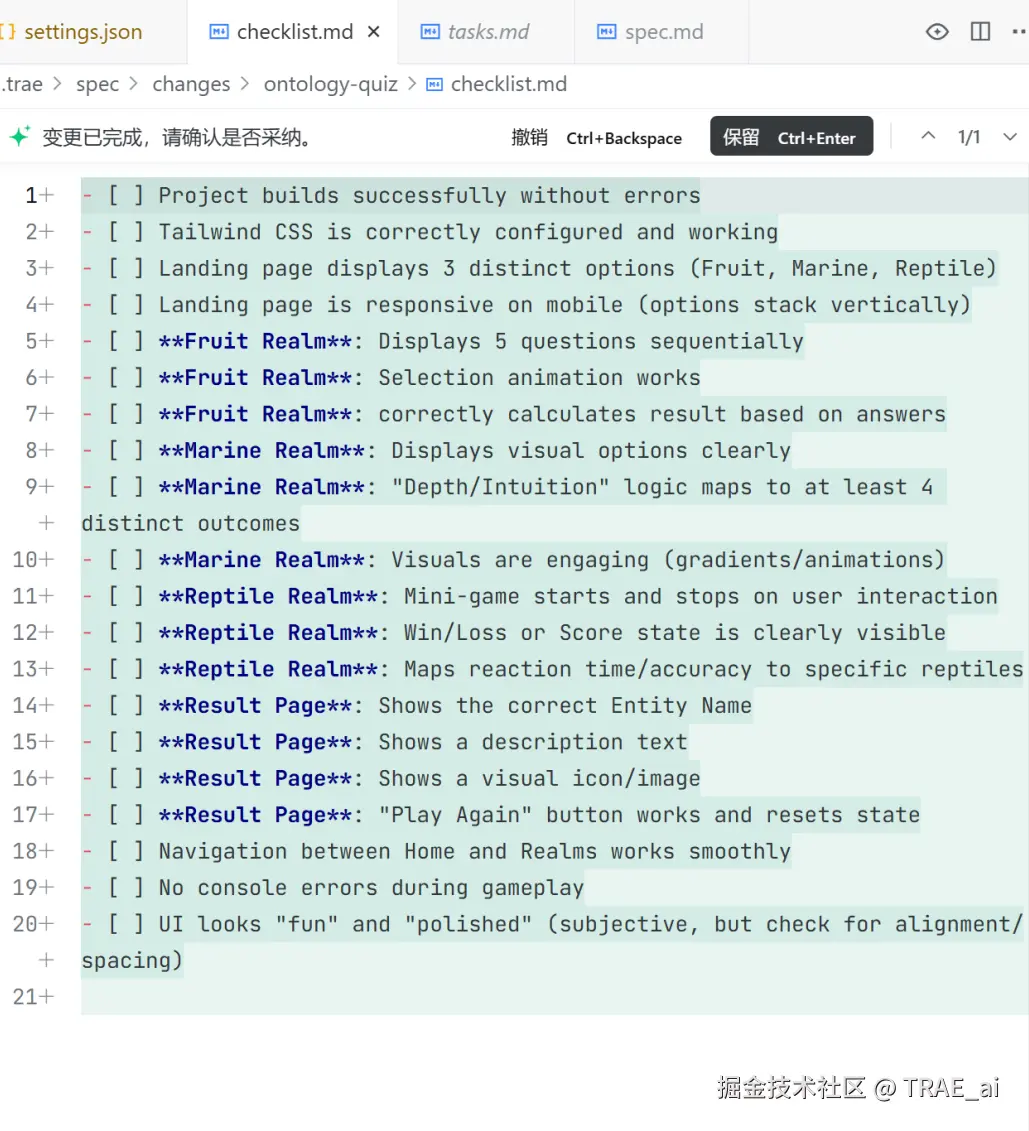
当你需要从零搭建新系统、新模块或进行大规模跨文件重构时,Spec 模式下,SOLO Coder 在动手写代码之前,会自动生成需求大纲(spec.md)→ 任务清单(tasks.md)→ 验收标准(checklist.md) ,再进入开发,确保 AI 理解并正确执行意图。

场景举例
-
从零搭建新系统: 需要规划一个全新项目的技术栈、目录结构和核心模块。
-
中小型功能开发: 需要创建一个包含多个文件和函数的新功能。
-
模块级重构: 需要对现有代码进行结构性调整,涉及多个文件的改动。
如何做
-
使用 /plan 命令: 对于中等复杂度的任务,在对话框输入 /plan 然后跟上你的需求。AI 会先输出一份详细的执行计划(比如会创建哪些文件、修改哪些函数),你检查并同意后,它才会开始写代码。
-
使用 /spec 命令: 对于更复杂、系统性的任务,使用 /spec 。AI 会依次生成需求大纲 (spec.md) -> 任务清单 (tasks.md) -> 验收标准 (checklist.md)。 你需要逐一确认这些文档,AI 才会进入最终的代码实现阶段,确保每一步都在你的掌控之中。
技巧七:善用上下文压缩,为对话"减负"
随着对话的进行,上下文会不断累积,最终可能超出模型的最佳处理范围,导致其"遗忘"对话早期的关键信息,或者将注意力过多地分散在不重要的细节上。
上下文压缩功能,如同为长篇会议记录划重点,它通过智能算法提炼出对话至今的核心信息,去除冗余和不重要的部分,形成一个精简版的"会议纪要"。这能帮助模型重新聚焦于最重要的任务背景,同时减少后续交互的 Token 消耗。
场景举例
-
任务阶段性完成时: 一个复杂任务的第一阶段(如"需求分析")已结束,即将进入第二阶段("技术设计"),此时压缩一下,让 AI "忘记"第一阶段的讨论细节,只记住结论。
-
AI 响应质量下降时: 你发现 AI 的回答开始变得不着边际,或者反复纠结于之前已经解决的问题,这通常是上下文过于臃肿的信号。
-
对话主题轻微转移时: 虽然我们推荐用新对话处理新任务,但有时在同一对话内,任务的焦点也会发生细微变化。在变化发生前,压缩一下上下文,有助于平稳过渡。
怎么做?
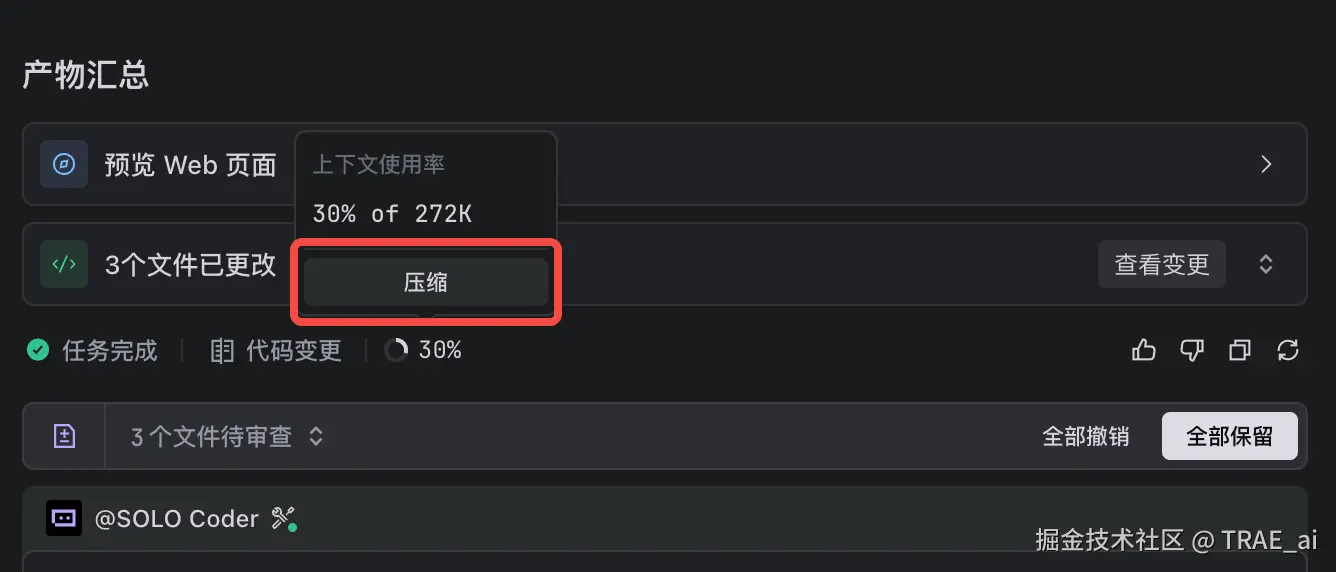
TRAE IDE 提供了上下文进度展示与压缩能力:当上下文过长时系统会自动压缩,你也可以手动触发,将冗余信息折叠起来,保留真正有价值的部分,让模型更聚焦。
-
手动压缩: 在 TRAE IDE 中,当对话轮数增多,你会看到上下文进度条变长。可以点击压缩按钮,手动为对话"减负"。
-
自动压缩: TRAE IDE 也内置了自动压缩机制。当检测到上下文接近临界值时,系统会自动在后台进行智能压缩,保证对话的流畅性。
技巧八:固化长期知识,构建专属"工具库"
在日常工作中,我们有大量的个人偏好、团队规范和项目约束是长期不变的。如果每次都在对话中重复声明(例如,"我们的代码风格是 a"、"禁止使用 b 库"、"接口返回格式必须是 c"),可以将这些"长期知识"固化到 AI 工具的配置中,充分利用 TRAE 提供的 Rules(规则)、Skills(技能)、Memory(记忆)等功能,提高效率。
场景举例
-
个人编码习惯: 你偏爱函数式编程,或习惯使用特定的命名法。
-
团队开发规范: 团队有统一的 Git 提交信息格式、目录结构约定等。
-
项目特定约束: 当前项目必须兼容某个版本的浏览器,或者必须使用公司内部的某个 UI 组件库。
如何做
TRAE 提供了三种构建工具:Rules(规则)、Skills(技能) 和 Memory(记忆)。
- 使用 Rules 固化个人习惯和项目级约束:
- 通过配置个人规则,可以避免重复输入相同的要求。例如,希望模型始终输出中文,默认遵循程序员的最佳实践,生成简洁、解耦的代码,而不是冗长的实现。配置规则后,模型生成的代码会更符合个人编码习惯和标准。
- 通过配置项目规则,定义那些在整个项目生命周期内都应遵守的、硬性的、不变的规范。
更多关于 Rules 的最佳实践可阅读:如何让 AI 更"听话"|Rules 高效使用指南
- 使用 Skills 模板化高频任务流:
一个 Skills 通常以一个文件夹的形式存在,里面主要装着三样东西:一份说明书(SKILL.md)、一堆操作脚本(Script)、以及一些参考资料(Reference)。你可以把一个 Skill 想象成一个打包好的"技能包"。它把完成某个特定任务所需的领域知识、操作流程、要用到的工具、以及最佳实践全都封装在了一起。当 AI 面对相应请求时,就能像一位经验丰富的专家那样,有条不紊地自主执行。
更多关于 Skills 的最佳实践可阅读:从理解到应用 | 在 TRAE 中快速上手 Skills
- 打开 Memory 保存你的偏好
TRAE 国际版已经支持 Memory(记忆)功能,记忆由 TRAE 自动生成和更新,以保持对话间的上下文。支持全局记忆和项目记忆两种类型,这些"记忆"能让 AI 在新会话或跨项目协作时,也能快速适应你的工作风格和团队的特定语境,减少沟通成本,提升输出一致性与协作效率。
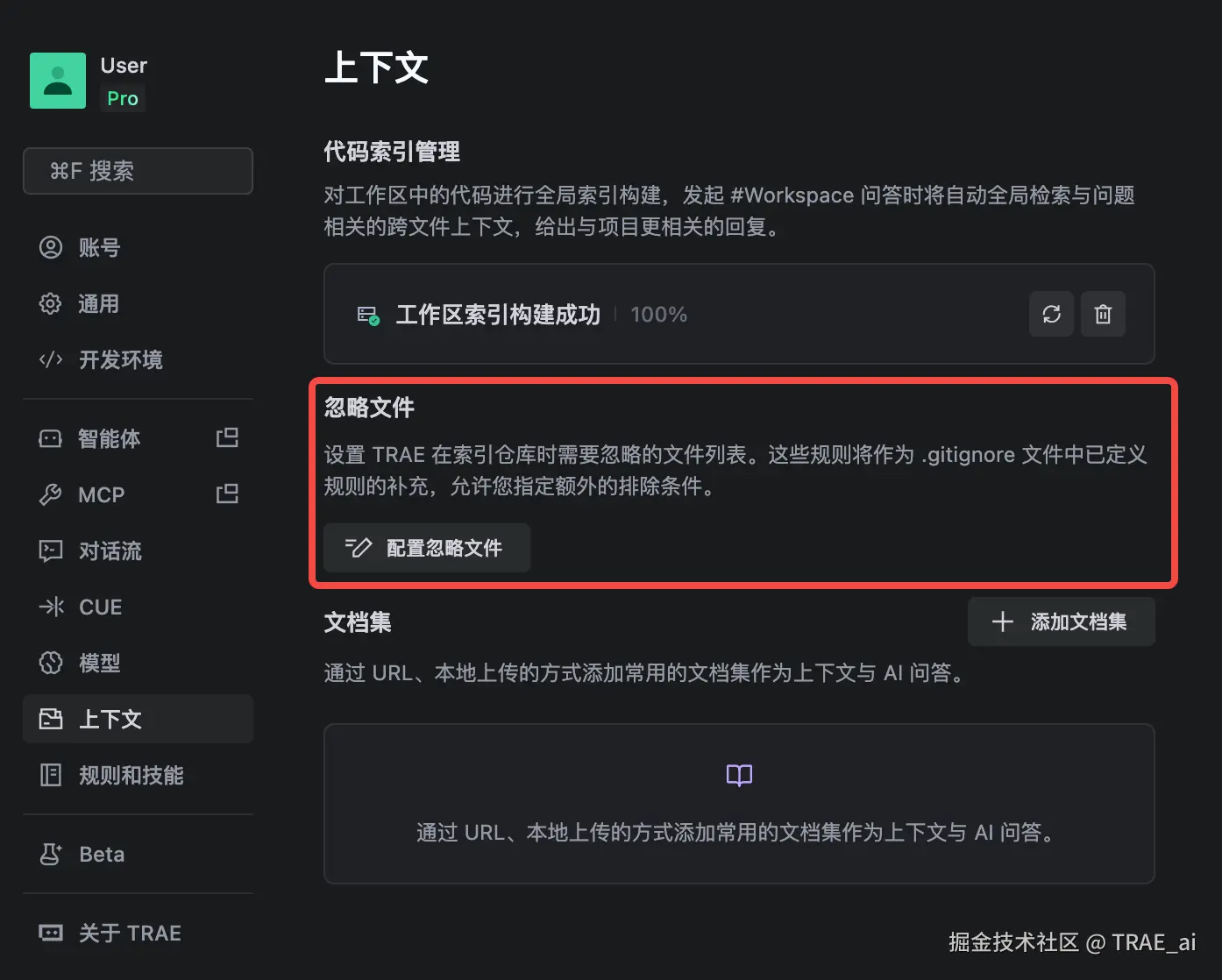
技巧九:配置 Ignore 文件,从源头切断噪声
在大型软件项目中,通常会存在对 AI 理解代码逻辑没有帮助、但体积较大的文件或目录。在项目根目录把体积大、噪声高内容明确排除掉,例如**dist/ **、**build/ **、日志文件、测试覆盖率报告等,可以避免在引用文件、全局检索或自动收集上下文时,不小心把这些带进对话上下文,导致 Token 飙升。
场景举例
-
当你使用 AI 的全局搜索或代码库分析等功能时。
-
在添加项目文件到对话上下文时,避免误操作。
如何做
- 配置忽略文件: 类似于 .gitignore ,你可以在 TRAE 添加需要忽略的文件列表,这些规则将作为 .gitignore文件中已定义规则的补充。
技巧十:根据任务选择模型,利用模型优势
不同的语言模型在能力、速度和成本上存在显著差异。通常,能力更强、上下文窗口更大的模型,其单位 Token 的价格也更高。由于不同模型在开发过程中的不同环节各有所长,选择模型的核心并非"哪款模型最优",而是哪款模型最适配你要交付的任务。在实际应用中,并非所有任务都需要"最强大脑"来处理。根据任务复杂度和成本要求选择合适的模型,能够有效帮助成本控制。
除此之外,我们不建议你在同一个任务中频繁地切换模型,因为每一次模型切换会清空缓存,导致输入 token 增长,如需切换模型,可以总结核心内容带到新的会话中,参见技巧一。
场景举例
-
日常编码: 编写常规的业务逻辑、修复简单的 Bug、写单元测试等。
-
复杂任务: 进行大型代码库的重构、设计新系统的架构、分析复杂的性能问题。
-
特定领域: 需要生成前端页面(可能需要审美能力强的模型),或进行特定语言的深度优化。
如何做
- 简单任务用"性价比"模型: 对于日常的、重复性高的编码任务,优先选择价格更低的国产模型。它们速度快、成本低,足以胜任大部分工作。
- 复杂任务用"高性能"模型: 当你遇到真正的挑战,比如需要深度思考的架构设计、跨模块的大型重构,或者当前模型陷入困境无法解决问题时,再切换到更强大的模型。把钱花在刀刃上。
- 打破思维定式: 如果发现当前模型陷入了思维的死胡同,不妨切换到另一个不同系列的模型试试。不同模型在代码生成、问题分析上的"思路"和风格差异,有时能给你带来意想不到的启发。
模型选择思路可参考:模型选择指南|TRAE 中国版 SOLO 模式
国际版模型选择思路文章也正在输出中,敬请期待!

写在最后:TRAE 在上下文管理方面的优化
除了提供主动式上下文管理能力外,TRAE 还在产品层面进行了深度优化,帮助各位开发者降低 Token 消耗与使用成本。
-
智能死循环检测: 实时监测模型推理状态,发现循环输出主动中断,避免产生更多无效空耗。
-
缓存命中率优化: 通过上下文结构与编码策略优化,提升 Context Caching 的命中率,直接降低实际计费成本。
-
智能上下文压缩: 在不影响理解与生成质量的前提下,自动对历史对话进行无损压缩;配合异步处理机制,同时实现"省量"与"提速"。
-
Agent 任务分层架构: 将代码搜索、文件检索等高 Token 消耗任务交由子 Agent 独立处理,保持主对话上下文的纯净与轻量。
-
模型定向优化: 针对不同模型的特点定制系统提示词,充分发挥各模型优势,提升效率并降低冗余消耗。
你有哪些管理上下文、高效利用用量的小技巧?欢迎在评论区分享呀!
下一篇《如何用 TRAE 更省钱(下)》,我们将为大家带来 TRAE 国际版模型选择指南哦!