最近在用 Trae 集成 MiMo 模型进行多轮工具调用时,频繁遇到
Invalid request (400)错误。经过排查,发现是 MiMo API 新增了对reasoning_content字段的回传要求。本文记录完整排查过程,并介绍社区大佬 Mintneko 提供的 Proxy 解决方案。
一、问题现象
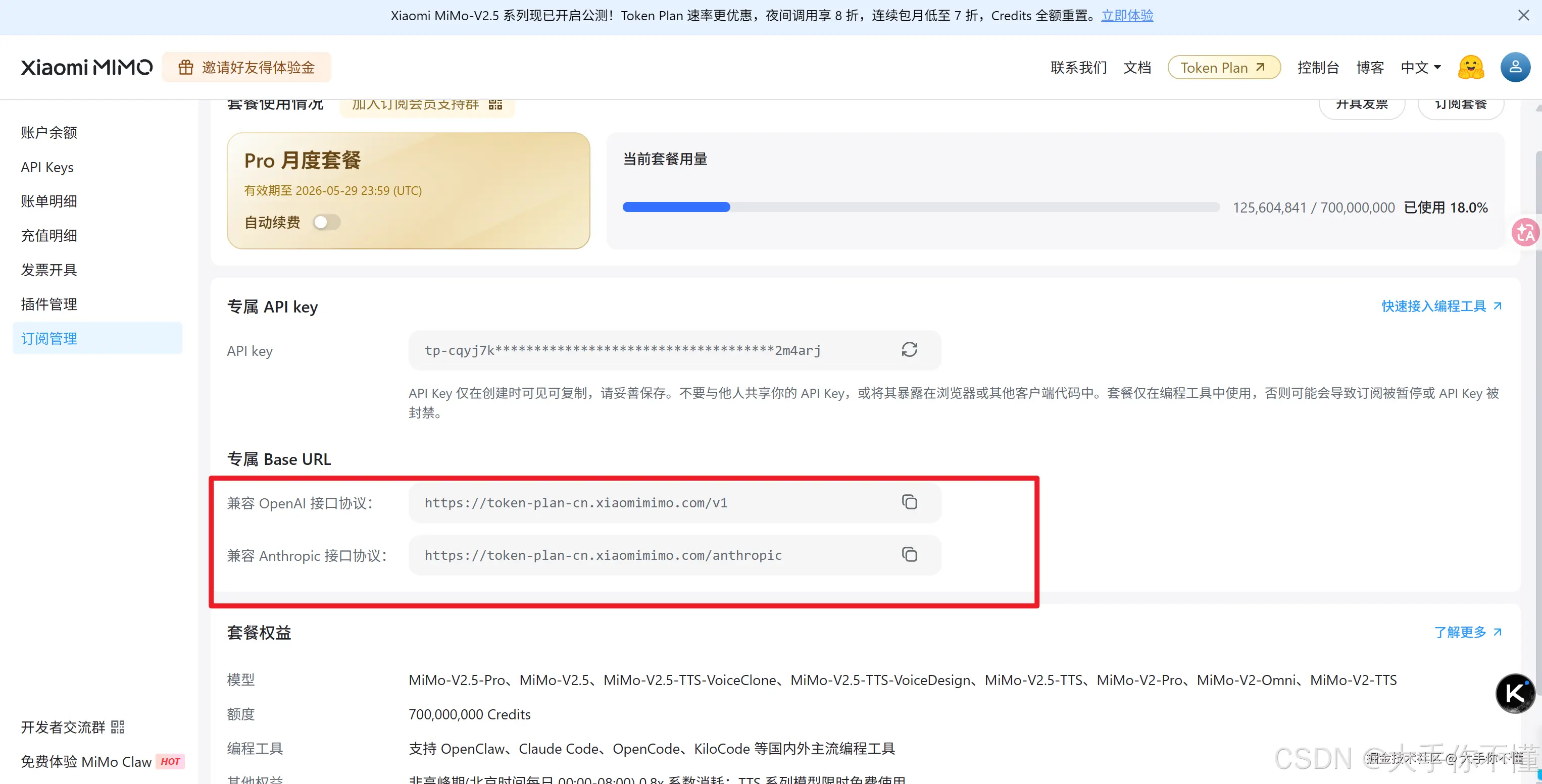
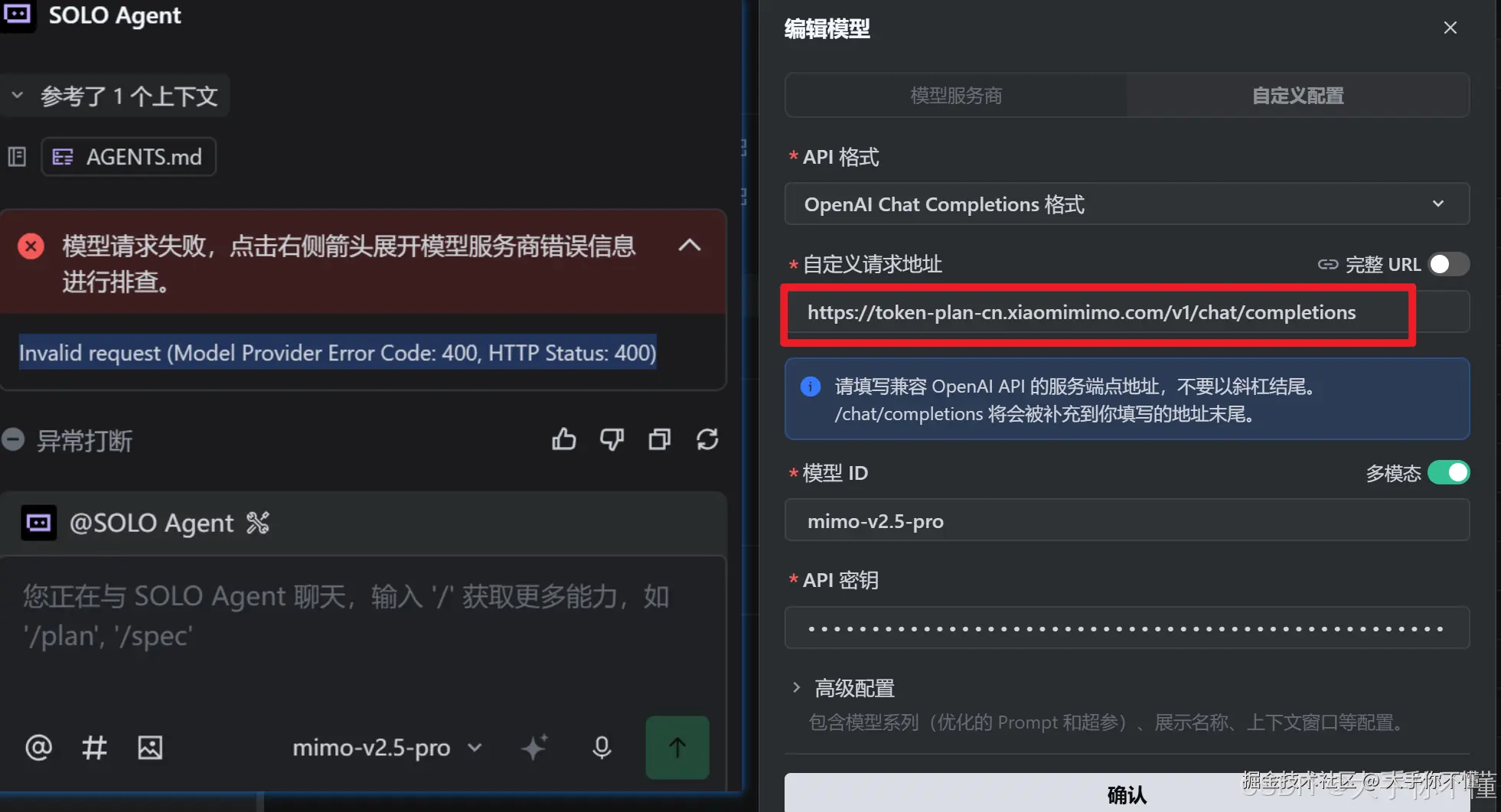
在 Trae 中使用 MiMo 模型(如 mimo-v2.5-pro)进行多轮对话,当模型在历史消息中产生过工具调用(tool_calls)后,后续轮次的请求会直接报错:
这个路径之前mimo官方有个trae的对接文档,不知道为啥现在没了?应该就是发那个问题公告的原因:trae现在不支持 之前官方给的trae的对接链接是(在token plan 的基础url上添加chat/completions ,因为trae不会自己添加):所以我这里之前的url是(之前好使,最近不行了。。。。。): token-plan-cn.xiaomimimo.com/v1/chat/com...
less
Invalid request (Model Provider Error Code: 400, HTTP Status: 400) 单轮对话或者不涉及工具调用的对话一切正常,问题只在多轮 + 工具调用的场景下复现。
二、排查过程
2.1 官方公告
经过搜索,发现 MiMo 官方平台近期发布了一则公告:
公告链接:关于 Agent 类产品多轮会话中回传 reasoning_content 的说明
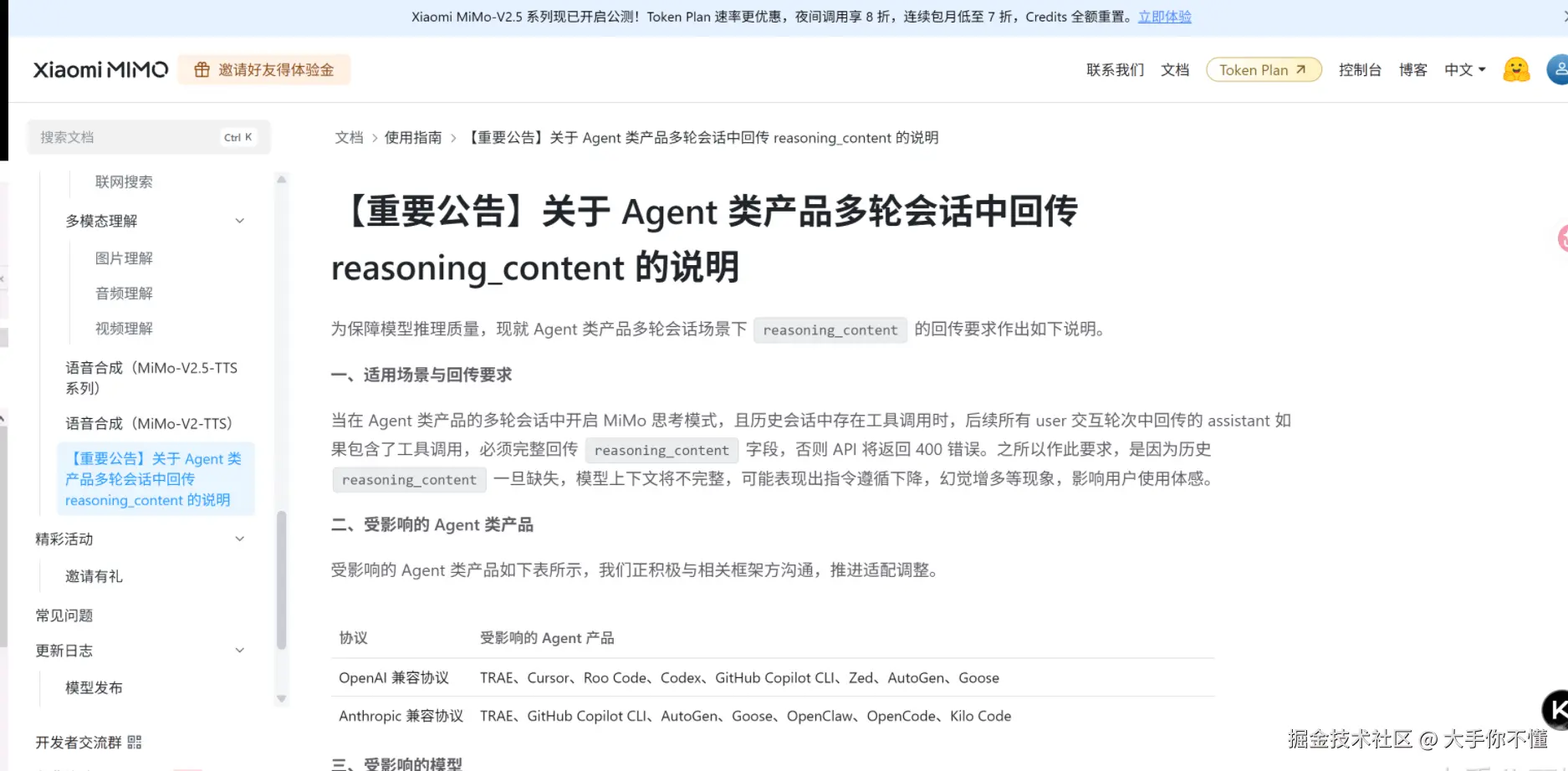
关于 Agent 类产品多轮会话中回传 reasoning_content 的说明
当在 Agent 类产品的多轮会话中开启 MiMo 思考模式,且历史会话中存在工具调用时,后续所有 user 交互轮次中回传的 assistant 如果包含了工具调用,必须完整回传
reasoning_content字段,否则 API 将返回 400 错误。之所以作此要求,是因为历史
reasoning_content一旦缺失,模型上下文将不完整,可能表现出指令遵循下降、幻觉增多等现象。
受影响的产品包括:TRAE、Cursor、Roo Code、GitHub Copilot CLI、Zed、AutoGen、Goose 等。
受影响的模型包括:MiMo-V2.5-Pro、MiMo-V2.5、MiMo-V2-Pro、MiMo-V2-Omni、MiMo-V2-Flash。
2.2 根因分析
简单来说,问题的链条是这样的:
TypeScript
用户发起多轮对话
↓
Trae 构造请求时,将历史 assistant 消息(含 tool_calls)写入 messages
↓
但 Trae 没有回传这些 assistant 消息的 reasoning_content 字段
↓
MiMo API 发现:有 tool_calls 却没有 reasoning_content → 400 错误为什么 Trae 不传 reasoning_content? 这其实是大多数 Agent 框架的通用行为。这些框架遵循 OpenAI 的标准协议,只关注 content 和 tool_calls 字段,对 reasoning_content 这种扩展字段默认会忽略。所以历史消息中的推理内容在转发过程中被"丢弃"了。
2.3 正确的回传方式
按照官方文档,正确的做法是把 assistant 消息的完整字段都保留下来:
TypeScript
# 错误 ❌ --- 缺少 reasoning_content
messages.append({
"role": "assistant",
"content": "",
"tool_calls": [...]
})
# 正确 ✅ --- 完整回传
messages.append({
"role": "assistant",
"content": "",
"tool_calls": [...],
"reasoning_content": "The user wants to know... I should call..."
})但在 Trae 这类客户端中,我们无法手动控制它构造 messages 的方式。这就需要一个中间层来帮忙------也就是 Proxy。
三、解决方案:MiMo Reasoning Content Proxy
在 GitHub 上找到了社区大佬 Mintneko 提供的代理方案 mimo-proxy,原理非常巧妙。
3.1 核心思路
在 Trae 和 MiMo API 之间加一层本地代理,代理负责:
- 1.拦截并缓存 :每次 MiMo 返回的 assistant 消息中如果包含
reasoning_content,就把它缓存起来 - 2.自动注入 :后续请求经过代理时,检查历史消息中是否有 assistant 消息缺少
reasoning_content,如果有,就从缓存中取出注入回去 - 3.兜底降级 :如果缓存中找不到(比如代理刚启动、缓存过期等),就把该 assistant 消息的
tool_calls剥离掉,降级为纯文本,避免触发 400
TypeScript
Trae ──→ Proxy (localhost:8899) ──→ MiMo API
│ │
│ ① 注入 reasoning_content │
│ ② 缓存返回的 reasoning │
│←──────────────────────────←│3.2 脚本逐模块解析
下面对脚本的各个核心模块做一个详细介绍。
模块一:配置区
TypeScript
MIMO_API_BASE = "https://token-plan-cn.xiaomimimo.com/v1" # MiMo API 地址
LISTEN_HOST = "0.0.0.0" # 监听地址
LISTEN_PORT = 8899 # 监听端口
CACHE_MAX_SIZE = 2000 # 缓存最大条目数
CACHE_TTL = 7200 # 缓存过期时间(秒)代理监听在本地 8899 端口,Trae 的 API Base URL 改为 http://127.0.0.1:8899/v1 即可。缓存采用 LRU 策略,最多存 2000 条,每条 2 小时过期。
模块二:缓存机制
这是整个方案的核心。缓存有两套索引:
| 索引方式 | 键 | 用途 |
|---|---|---|
| 哈希索引 | SHA256(content + tool_calls)[:16] |
按消息内容精确匹配 |
| Tool Call ID 索引 | tool_call_id |
按工具调用 ID 反查 |
python
def _msg_hash(msg: dict) -> str:
content = msg.get("content") or ""
tool_calls = json.dumps(msg.get("tool_calls") or [], sort_keys=True)
raw = f"{content}||{tool_calls}"
return hashlib.sha256(raw.encode()).hexdigest()[:16]为什么要两套索引?因为 Trae 在回传历史消息时,消息内容可能被稍作修改(比如拼接了工具结果),但 tool_call_id 通常是不变的。所以优先用哈希匹配,匹配不到再用 tool_call_id 反查,提高命中率。
缓存操作使用 Python 的 OrderedDict 实现标准 LRU:
python
def _cache_get(key: str) -> str | None:
if key in _cache:
val, ts = _cache[key]
if time.time() - ts < CACHE_TTL: # 未过期
_cache.move_to_end(key) # 移到末尾(最近使用)
return val
del _cache[key] # 过期则删除
return None
def _cache_set(key: str, value: str):
if key in _cache:
del _cache[key]
_cache[key] = (value, time.time())
while len(_cache) > CACHE_MAX_SIZE: # 超出容量则淘汰最久未用的
_cache.popitem(last=False)模块三:注入与降级逻辑
这是处理请求的核心函数。遍历 messages 中的每条 assistant 消息,检查是否需要处理:
python
def inject_reasoning(messages: list[dict]) -> tuple[int, int]:
for i, msg in enumerate(messages):
if msg.get("role") != "assistant":
continue
if not msg.get("tool_calls"): # 没有 tool_calls → 不需要处理
continue
if msg.get("reasoning_content"): # 已经有 reasoning_content → 跳过
continue
# 尝试从缓存中查找
cached = _cache_get(_msg_hash(msg))
if not cached:
cached = _find_by_tool_call_ids(msg)
if cached:
# ✅ 命中缓存 → 注入 reasoning_content
msg["reasoning_content"] = cached
else:
# ⚠️ 未命中 → 降级:剥离 tool_calls,转为纯文本
del msg["tool_calls"]
# 同时在 content 中保留工具调用的摘要
msg["content"] += " [Called get_current_weather]"降级策略 的思路很聪明:MiMo API 只对「有 tool_calls 但没有 reasoning_content」的消息报 400。那我把 tool_calls 去掉,模型自然就不会要求 reasoning_content 了。虽然丢失了结构化的工具调用信息,但至少不会报错,而且在 content 中保留了工具调用的文本摘要,模型仍然能理解上下文。
模块四:流式响应处理
代理需要在流式传输过程中同时做两件事:逐块转发给客户端 + 逐步累积完整消息用于缓存。
python
async def _stream_proxy(client, url, headers, body):
acc_content = ""
acc_reasoning = ""
acc_tool_calls = []
async with client.stream("POST", url, headers=headers, json=body) as resp:
async for raw_chunk in resp.aiter_bytes():
# 解析 SSE 数据
# 累积 reasoning_content、content、tool_calls
# 原样转发给客户端
yield _sse(payload)
# 收到 [DONE] 时,将完整消息缓存
if payload == "[DONE]":
if acc_reasoning and (acc_content or acc_tool_calls):
_cache_set_with_index(hash, acc_reasoning, tool_call_ids)这个设计确保了缓存的实时性 :模型的每一次响应,只要有 reasoning_content,都会在流结束后立即缓存,后续轮次立刻可用。
模块五:错误处理与重试
v1.4 版本重点增强了错误处理:
- 5xx 错误自动重试:最多 3 次,间隔递增(1s、2s)
- 4xx 错误直接透传:客户端参数问题,不重试
- 超时处理:流式模式和非流式模式都有独立的超时重试逻辑
- 空内容兜底 :如果 MiMo 只返回了
reasoning_content而content为空,自动将reasoning_content作为content返回
python
# 空 content 兜底
if not msg.get("content") and not msg.get("tool_calls") and msg.get("reasoning_content"):
msg["content"] = msg["reasoning_content"]模块六:API 端点
代理暴露了与 MiMo API 完全兼容的端点:
| 端点 | 说明 |
|---|---|
POST /v1/chat/completions |
核心:聊天补全(带注入/降级逻辑) |
GET /v1/models |
模型列表(直接透传) |
GET / |
代理状态页 |
GET /health |
健康检查 |
四、使用步骤
4.1 拉取mimo-proxy项目
bash
git clone https://github.com/Mintneko/mimo-proxy.git如果你拉不下来,可以参考我上一篇博客,里面有github处理方案: 用 OpenCode 装 Skills 一直失败,它说是网不好,但浏览器明明能上 git Hub 啊?
或者你也可以将mimo_proxy.py下载到本地,在本地直接启动就行:
4.2 安装依赖
bash
pip install starlette uvicorn httpx 4.3 启动代理
bash
python mimo_proxy.py 启动后会看到:
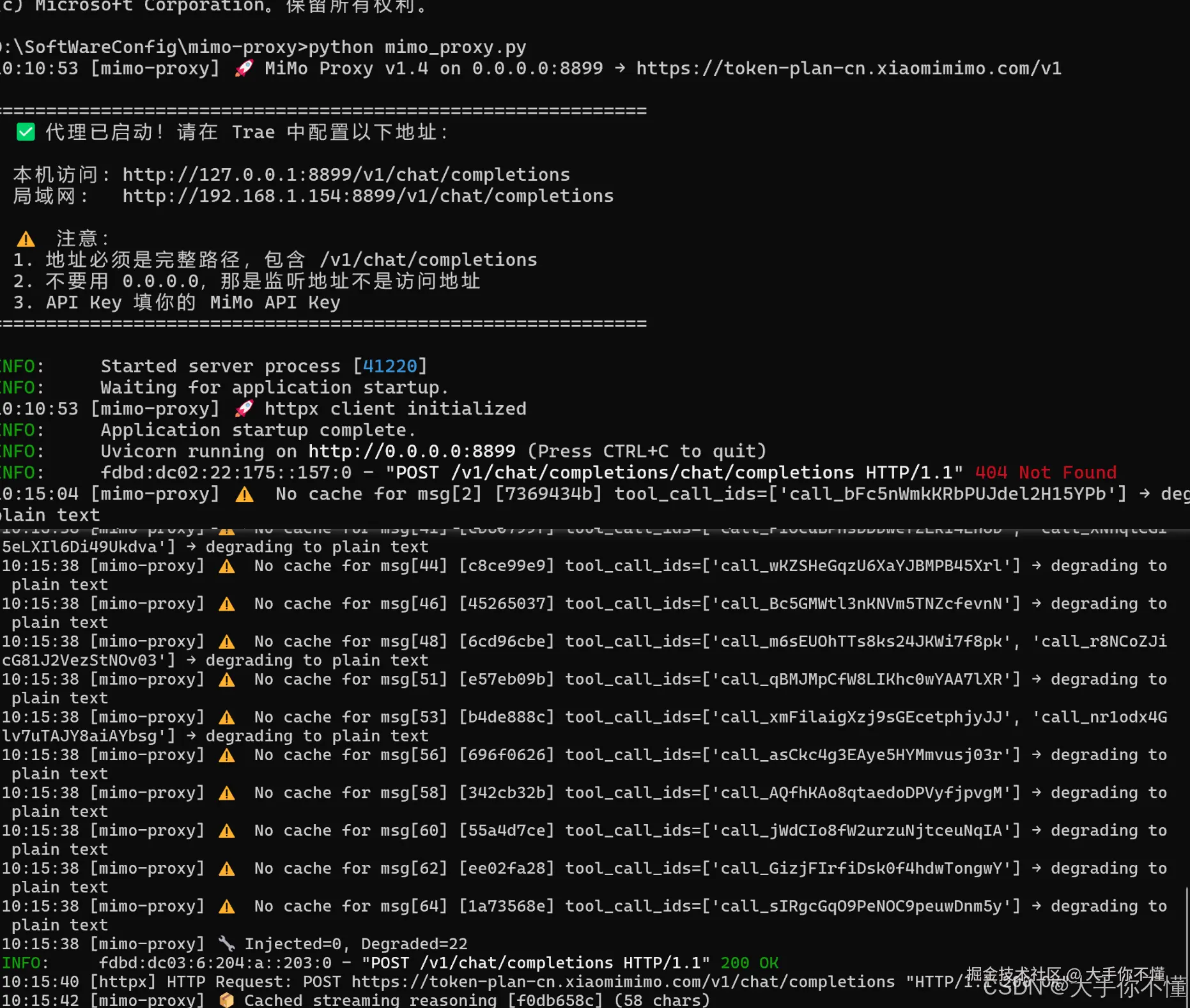
bash
Microsoft Windows [版本 10.0.26200.8117]
(c) Microsoft Corporation。保留所有权利。
D:\SoftWareConfig\mimo-proxy>python mimo_proxy.py
10:10:53 [mimo-proxy] 🚀 MiMo Proxy v1.4 on 0.0.0.0:8899 → https://token-plan-cn.xiaomimimo.com/v1
============================================================
✅ 代理已启动!请在 Trae 中配置以下地址:
本机访问: http://127.0.0.1:8899/v1/chat/completions
局域网: http://192.168.1.154:8899/v1/chat/completions
⚠️ 注意:
1. 地址必须是完整路径,包含 /v1/chat/completions
2. 不要用 0.0.0.0,那是监听地址不是访问地址
3. API Key 填你的 MiMo API Key
============================================================
INFO: Started server process [41220]
INFO: Waiting for application startup.
10:10:53 [mimo-proxy] 🚀 httpx client initialized
INFO: Application startup complete.
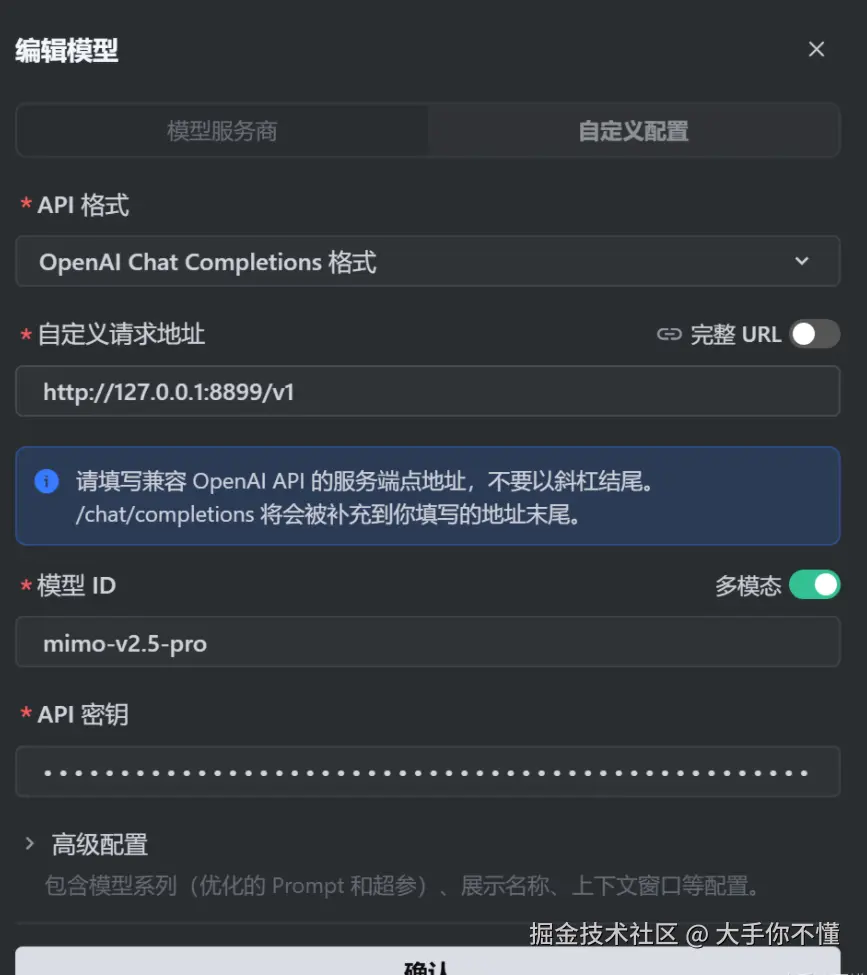
INFO: Uvicorn running on http://0.0.0.0:8899 (Press CTRL+C to quit)4.4 配置 Trae
在 Trae 的模型设置中:
- API Base URL :
http://127.0.0.1:8899/v1 - API Key:填你的 MiMo API Key(代理会原样透传)
- Model :
mimo-v2.5-pro(或其他受影响模型)
4.5 验证
配置完成后,正常在 Trae 中使用 MiMo 模型即可。多轮对话 + 工具调用场景下,400 错误不会再出现。
五、方案原理总结
整个方案可以用一句话概括:
用空间换正确性 ------通过本地缓存
reasoning_content,在请求转发时自动补全缺失字段,从而绕过 Agent 框架不回传扩展字段的问题。
TypeScript
第一轮请求
用户 → Trae → Proxy → MiMo API
│
←←←←←←←←←←←←←←│ 返回 reasoning_content
│ │
│ ① 缓存到本地 │
↓
本地缓存
第二轮请求(Trae 丢失了 reasoning_content)
用户 → Trae → Proxy ──→ MiMo API
│ ↑
│ ② 从缓存 │
│ 注入回去 │
↓ │
注入后的完整 messages三层保障:
- 1.缓存命中 → 注入:最佳情况,完整保留模型推理上下文
- 2.缓存未命中 → 降级:剥离 tool_calls,避免 400,保留基本对话能力
- 3.API 错误 → 重试:5xx 自动重试 3 次,提高稳定性
六、写在最后
这个问题本质上是 MiMo 为了保证推理质量而新增的协议要求,与现有 Agent 框架的兼容性还在逐步推进中。在框架方完成适配之前,Mintneko 的这个 Proxy 方案是一个非常实用的过渡方案------部署简单、侵入性低、对 Trae 的使用完全透明。
感谢 Mintneko 大佬的开源贡献。
参考链接:
- MiMo 官方公告:【重要公告】关于 Agent 类产品多轮会话中回传 reasoning_content 的说明
- mimo-proxy 项目:mimo-proxy