🗺️ 智旅云图后端学习指南
本文档从 0 开始讲解如何阅读和理解这个 AI 旅行规划项目的后端代码。
1. 项目概览
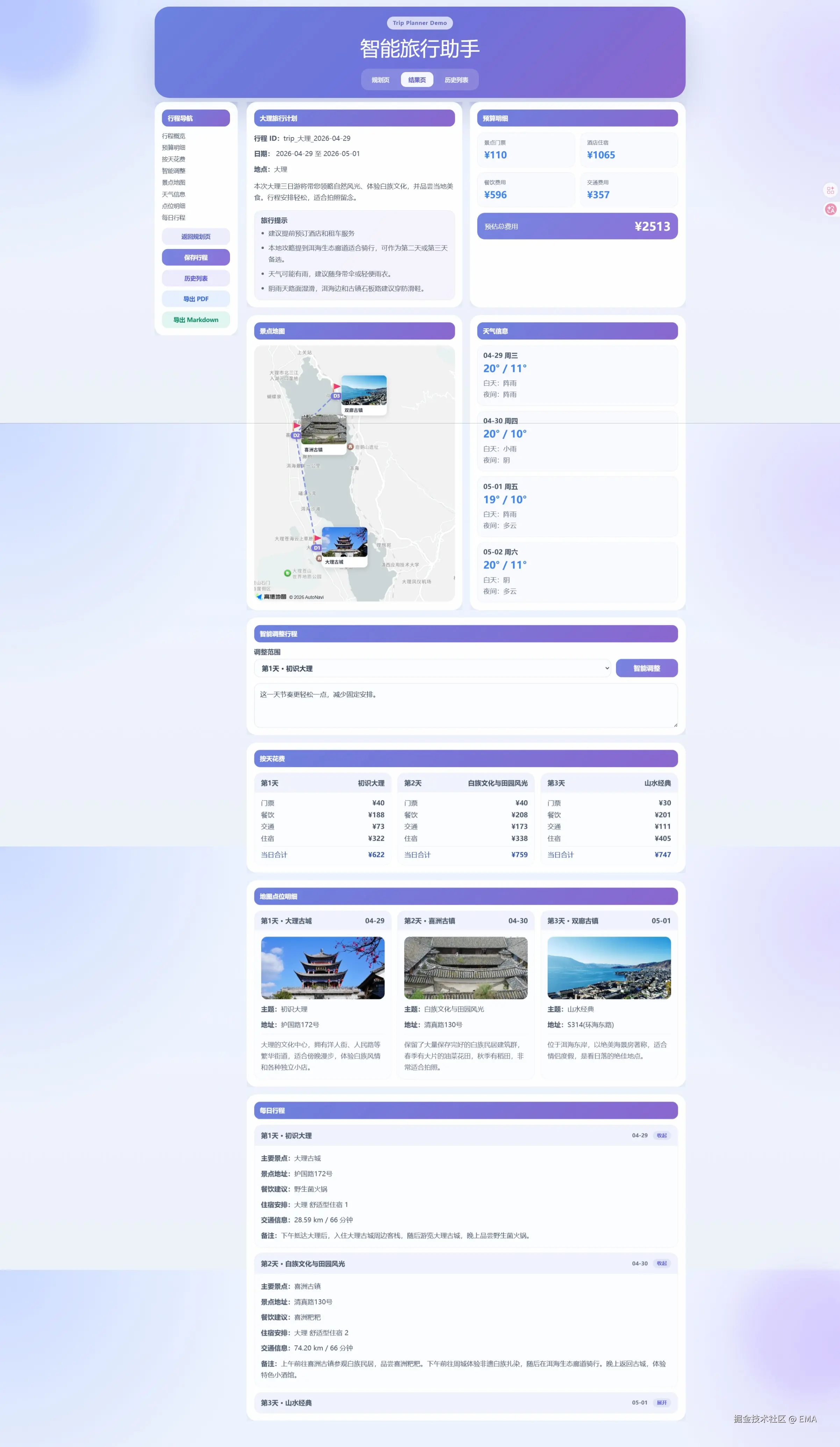
1.1 项目定位
智旅云图是一个面向中文旅行场景的 AI 旅行规划系统,核心价值在于:
- 🧠 LLM 行程生成 :基于 LangChain + DashScope 调用
qwen-max生成结构化旅行计划 - 📚 RAG 攻略增强:本地 Markdown 攻略 + Chroma 向量检索,为生成结果补充目的地上下文
- 🗺️ 高德地图接入:补充景点地址、经纬度、POI ID、路线距离、耗时和景点图片
- 🌦️ 天气感知提示:前端展示天气预报,并根据雨天/阴天自动修正旅行提示
- ⚡ Redis 缓存层:覆盖天气、地图、RAG 检索与 Rerank 结果缓存
- 📄 文档导出:支持 Markdown 和中文 PDF 导出
1.2 技术栈
| 层级 | 技术 | 版本 |
|---|---|---|
| Web框架 | FastAPI | >=0.110 |
| 数据验证 | Pydantic | >=2.6 |
| ORM | SQLAlchemy | >=2.0 |
| LLM框架 | LangChain | >=0.2 |
| 向量库 | ChromaDB | >=0.5 |
| 缓存 | Redis | >=5.0 |
| HTTP客户端 | HTTPX | >=0.27 |
| PDF生成 | ReportLab | >=4.0 |
1.3 目录结构
text
backend/
├── app/ # 核心应用代码
│ ├── config.py # 环境变量配置、数据库连接
│ ├── api/ # 接口路由层
│ │ ├── main.py # FastAPI 入口
│ │ └── routes/ # trip/export/weather 路由
│ ├── services/ # 业务服务层
│ │ ├── trip_service.py # 行程主编排逻辑
│ │ ├── cache_service.py # Redis缓存封装
│ │ ├── map_service.py # 高德地图服务
│ │ ├── weather_service.py # 天气服务
│ │ ├── storage_service.py # SQLite持久化
│ │ └── export_service.py # 文档导出
│ ├── agents/ # LLM Agent层
│ │ ├── trip_planner_agent.py # 行程生成Agent
│ │ └── tools/
│ │ └── rag_tool.py # Query Rewrite工具
│ ├── rag/ # RAG检索层
│ │ ├── vector_db.py # Chroma入库与检索
│ │ └── retriever.py # 检索封装与Rerank
│ └── models/ # 数据模型
│ ├── schemas.py # Pydantic请求/响应模型
│ └── db_models.py # SQLAlchemy数据库模型
├── data/ # 本地攻略文档
├── scripts/ # 辅助脚本(ingest/测试)
├── tests/ # pytest测试
├── .env.example # 环境变量模板
└── requirements.txt # 依赖清单2. 核心配置与环境
2.1 配置文件 (app/config.py)
这是项目的配置中心,负责:
-
数据库配置
- SQLite 数据库路径:
backend/db/app.db - SQLAlchemy Engine 和 Session 配置
- SQLite 数据库路径:
-
LLM 配置(通过环境变量注入)
LLM_API_KEY:DashScope API KeyLLM_MODEL:模型名称(如qwen-max)LLM_BASE_URL:API 端点(DashScope 兼容 OpenAI)LLM_TIMEOUT_SECONDS:超时时间LLM_MAX_RETRIES:重试次数
-
RAG 配置
CHROMA_DB_DIR:Chroma 向量库持久化目录CHROMA_COLLECTION_NAME:集合名称EMBEDDING_MODEL:嵌入模型(如text-embedding-v4)RERANK_MODEL:重排序模型(如qwen3-rerank)
-
Redis 配置
REDIS_ENABLED:是否开启缓存REDIS_URL:Redis 连接地址- 各类型缓存的 TTL 设置(天气/地图/RAG/Rerank)
-
高德地图配置
AMAP_API_KEY:高德 Web 服务 KeyENABLE_AMAP_ENRICHMENT:是否开启地图信息补全
2.2 环境变量模板 (.env.example)
env
# LLM
LLM_PROVIDER=openai_compatible
LLM_API_KEY=your_dashscope_api_key
LLM_MODEL=qwen-max
LLM_BASE_URL=https://dashscope.aliyuncs.com/compatible-mode/v1
LLM_TIMEOUT_SECONDS=60
LLM_MAX_RETRIES=1
# RAG
CHROMA_DB_DIR=db/chroma_db
CHROMA_COLLECTION_NAME=travel_guides
EMBEDDING_MODEL=text-embedding-v4
RERANK_MODEL=qwen3-rerank
# Redis
REDIS_ENABLED=false
REDIS_URL=redis://127.0.0.1:6379/0
REDIS_KEY_PREFIX=trip_planner
# 高德地图
AMAP_API_KEY=your_amap_web_service_key
ENABLE_AMAP_ENRICHMENT=true3. 数据模型
3.1 Pydantic Schemas (app/models/schemas.py)
核心模型关系
TripRequest(请求)→ Itinerary(行程)→ DayPlan(单日)→ SpotItem/MealItem/HotelItem/TransportItem关键模型解析
TripRequest - 用户行程生成请求:
python
class TripRequest(BaseModel):
destination: str # 目的地
start_date: DateType # 出发日期
end_date: DateType # 结束日期
travelers: int # 人数
budget: float # 预算
preferences: list[str] # 偏好标签(美食/亲子/自然等)
pace: str | None # 节奏(轻松/适中/紧凑)
dietary_preferences: list[str] # 饮食偏好
hotel_level: str | None # 酒店档次
special_notes: str | None # 额外要求(如"想看日落")Itinerary - 完整行程数据结构:
python
class Itinerary(BaseModel):
trip_id: str # 行程唯一标识
destination: str # 目的地
summary: str # 行程概述
days: list[DayPlan] # 逐日行程
estimated_budget: float # 总预算
budget_breakdown: BudgetBreakdown # 预算拆分
tips: list[str] # 旅行提示
source_notes: list[str] # RAG来源说明DayPlan - 单日行程:
python
class DayPlan(BaseModel):
day_index: int # 第几天(从1开始)
date: DateType | None # 日期
theme: str | None # 当天主题
spots: list[SpotItem] # 景点安排
meals: list[MealItem] # 餐饮安排
hotel: HotelItem | None # 住宿安排
transport: list[TransportItem] # 交通安排
notes: list[str] # 备注BudgetBreakdown - 预算拆分:
python
class BudgetBreakdown(BaseModel):
transport: float # 交通
hotel: float # 住宿
meals: float # 餐饮
tickets: float # 门票
other: float # 其他
total: float # 总计3.2 SQLAlchemy Models (app/models/db_models.py)
TripRecord - 数据库表模型:
python
class TripRecord(Base):
__tablename__ = "trip_records"
id: Mapped[int] = mapped_column(primary_key=True)
trip_id: Mapped[str] = mapped_column(String(100), unique=True, index=True)
destination: Mapped[str]
summary: Mapped[str]
itinerary_json: Mapped[str] # 完整行程的JSON字符串
created_at: Mapped[datetime]
updated_at: Mapped[datetime]设计要点:使用 JSON 字符串存储完整行程,便于灵活扩展而无需修改表结构。
4. 接口层(API Routes)
4.1 入口文件 (app/api/main.py)
python
app = FastAPI(
title="Trip Planner Demo Backend",
description="MVP backend for the intelligent travel assistant.",
version="0.1.0",
)
# CORS 跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=["http://localhost:5173", "http://127.0.0.1:5173"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 注册路由
app.include_router(trip_router)
app.include_router(export_router)
app.include_router(weather_router)4.2 Trip 路由 (app/api/routes/trip.py)
| 方法 | 路径 | 功能 | 响应模型 |
|---|---|---|---|
| POST | /trip/generate |
生成行程 | Itinerary |
| POST | /trip/edit |
智能编辑 | Itinerary |
| POST | /trip/save |
保存行程 | {"message", "trip_id"} |
| GET | /trip |
历史列表 | TripListResponse |
| GET | /trip/{trip_id} |
行程详情 | TripDetailResponse |
| DELETE | /trip/{trip_id} |
删除行程 | {"message", "trip_id"} |
核心代码示例:
python
@router.post("/generate", response_model=Itinerary)
def generate_trip(request: TripRequest) -> Itinerary:
"""生成结构化 itinerary。"""
return generate_trip_itinerary(request)5. 服务层(Services)
5.1 Trip Service (app/services/trip_service.py) - 核心编排
这是最核心的业务编排层,负责:
- 行程生成主流程 (
generate_trip_itinerary) - 智能编辑流程 (
edit_trip_itinerary) - 预算计算
- 地图信息补全
行程生成流程
scss
用户请求 → collect_trip_context(RAG检索) → generate_planner_draft(LLM生成)
↓
预算拆分计算 → _maybe_enrich_itinerary_with_map_data(地图补全) → 返回Itinerary关键代码解析:
python
def generate_trip_itinerary(request: TripRequest) -> Itinerary:
# 1. 计算天数
day_count = (request.end_date - request.start_date).days + 1
# 2. RAG检索获取攻略上下文
rag_contexts = collect_trip_context(
destination=request.destination,
preferences=request.preferences,
pace=request.pace,
special_notes=request.special_notes,
)
# 3. LLM生成结构化草稿
llm_draft = generate_planner_draft(request, rag_contexts, day_count)
# 4. 构建每日行程
days = []
for index in range(day_count):
# 根据LLM结果或规则构建DayPlan
...
# 5. 地图信息补全(可选)
return _maybe_enrich_itinerary_with_map_data(itinerary, city=request.destination)预算计算机制
项目实现了智能预算拆分,考虑多种因素:
- 酒店档次权重:豪华(0.62) > 高档(0.56) > 舒适(0.50) > 经济(0.40)
- 美食偏好加成:有"美食"偏好时餐饮预算增加12%
- 节奏影响:紧凑节奏交通预算更高,轻松节奏更低
- 周末溢价:周五、周六住宿费用增加18%
- 首尾日加成:首尾日交通预算增加
python
def _estimate_ticket_cost(spot_name: str, description: str | None) -> float:
"""根据景点关键词估算门票"""
text = f"{spot_name} {description or ''}"
if any(keyword in text for keyword in ("古城", "古镇", "公园")):
return [0.0, 20.0, 30.0, 40.0][bucket] # 低收费或免费
if any(keyword in text for keyword in ("寺", "博物馆", "遗址")):
return round(60.0 + (bucket * 18.0), 2) # 中等收费
if any(keyword in text for keyword in ("索道", "缆车", "游船")):
return round(120.0 + (bucket * 28.0), 2) # 高收费5.2 Cache Service (app/services/cache_service.py)
设计亮点:
- 懒加载:Redis 客户端按需初始化
- 优雅降级:Redis 不可用时自动跳过缓存,不影响主流程
- 统一 Key 前缀:避免多项目缓存键冲突
- JSON 序列化:自动处理复杂数据类型的缓存
python
def _get_redis_client():
"""懒加载 Redis 客户端;不可用时返回 None"""
global _redis_client
if not REDIS_ENABLED:
return None
if redis is None:
logger.warning("Redis 依赖未安装,缓存功能跳过")
return None
if _redis_client is not None:
return _redis_client
# 尝试连接
try:
client = redis.Redis.from_url(REDIS_URL, decode_responses=True)
client.ping()
_redis_client = client
return _redis_client
except Exception as exc:
logger.warning("Redis 连接失败:%s", exc)
return None缓存类型与 TTL:
| 缓存类型 | TTL | 说明 |
|---|---|---|
| 天气 | 30分钟 | 天气变化较慢 |
| 地图 | 24小时 | POI信息相对稳定 |
| RAG检索 | 6小时 | 攻略内容不变但query可能变化 |
| Rerank结果 | 6小时 | 相同query+候选集结果稳定 |
5.3 Map Service (app/services/map_service.py)
对接高德地图 Web 服务,提供:
- 地理编码 (
geocode_address):地址 → 经纬度 - POI搜索 (
search_places):关键词 → 景点信息(含图片) - 路线估算 (
estimate_route):两点 → 距离/耗时/打车费用
python
def enrich_itinerary_with_map_data(itinerary: Itinerary, city: str | None = None) -> Itinerary:
"""补全 itinerary 中的地图字段"""
for day in itinerary.days:
for spot in day.spots:
_enrich_spot(spot, city=city) # 补充地址、坐标、POI ID、图片
if day.hotel is not None:
_enrich_hotel(day.hotel, city=city)
for transport in day.transport:
_enrich_transport(transport, city=city) # 补充路线距离和耗时
return itinerary5.4 Weather Service (app/services/weather_service.py)
通过高德天气 API 获取未来天气预报,支持缓存。
python
def get_weather_forecast(city: str) -> dict[str, Any]:
"""获取指定城市的未来天气预报"""
cache_key = f"weather:forecast:{city.lower()}"
cached_value = get_cached_json(cache_key)
if cached_value is not None:
return cached_value
# 先地理编码获取城市编码
geocode = geocode_address(city, city=city)
city_code = geocode.get("adcode") if geocode else city
# 调用高德天气API
payload = _request_amap_weather("/weather/weatherInfo", {"city": city_code, "extensions": "all"})
...5.5 Storage Service (app/services/storage_service.py)
SQLite 持久化操作:
| 函数 | 功能 |
|---|---|
save_itinerary |
保存/更新行程 |
get_itinerary_by_trip_id |
查询单个行程 |
list_saved_itineraries |
获取历史列表 |
delete_itinerary_by_trip_id |
删除行程 |
python
def save_itinerary(itinerary: Itinerary) -> str:
init_db() # 自动创建表
session = SessionLocal()
try:
itinerary_json = json.dumps(itinerary.model_dump(mode="json"), ensure_ascii=False)
# 存在则更新,不存在则新建
existing_record = session.query(TripRecord).filter(
TripRecord.trip_id == itinerary.trip_id
).first()
if existing_record is None:
record = TripRecord(...)
session.add(record)
else:
existing_record.summary = itinerary.summary
existing_record.itinerary_json = itinerary_json
session.commit()
return itinerary.trip_id
finally:
session.close()5.6 Export Service (app/services/export_service.py)
支持两种导出格式:
- Markdown:轻量级,便于分享
- PDF:结构化排版,适合打印
python
def itinerary_to_markdown(trip_detail: TripDetailResponse) -> str:
"""渲染成 Markdown"""
lines = [
f"# {itinerary.destination} 行程单",
f"- 目的地:{itinerary.destination}",
f"- 预计预算:{itinerary.estimated_budget:.2f} 元",
"## 行程概述",
itinerary.summary,
"## 每日安排",
...
]
return "\n".join(lines)
def itinerary_to_pdf_bytes(trip_detail: TripDetailResponse) -> bytes:
"""渲染成 PDF 二进制内容"""
from reportlab.platypus import SimpleDocTemplate, Paragraph, Table
...6. Agent 层(LLM 调用)
6.1 Trip Planner Agent (app/agents/trip_planner_agent.py)
负责结构化行程生成 和单日编辑:
核心数据结构
python
class PlannerDraft(BaseModel):
"""LLM 返回的结构化行程草稿"""
summary: str # 整体概述
tips: list[str] # 旅行提示
days: list[PlannerDayDraft] # 每日草稿
class PlannerDayDraft(BaseModel):
"""单日草稿"""
day_index: int # 第几天
theme: str # 当天主题
spot_name: str # 主要景点
spot_description: str # 景点说明
meal_name: str # 餐饮建议
meal_notes: str # 餐饮说明
daily_note: str # 当天备注生成流程
python
def generate_planner_draft(request: TripRequest, rag_contexts: list[str], day_count: int) -> PlannerDraft | None:
# 1. 创建 LLM 客户端
llm = _build_chat_llm()
if llm is None:
return None # 优雅降级
# 2. 构建 Prompt
system_prompt = "你是一名旅行规划助手。请用中文生成简洁的结构化旅行草稿..."
human_prompt = f"""
目的地:{request.destination}
天数:{day_count}
预算:{request.budget}
本地攻略上下文:
{rag_contexts}
...
"""
# 3. 调用 LLM
response = llm.invoke([("system", system_prompt), ("human", human_prompt)])
# 4. 解析 JSON 输出
json_text = _extract_json_object(str(response.content))
result = PlannerDraft.model_validate(json.loads(json_text))
return result关键设计:
- 结构化输出要求:强制 LLM 返回 JSON 格式,便于程序解析
- 优雅降级:LLM 不可用时返回 None,服务层回退到规则实现
- 用户诉求落实:如"想看日落"必须在具体某天的安排中体现
6.2 RAG Tool (app/agents/tools/rag_tool.py)
负责Query Rewrite - 将用户的旅行需求转换成适合向量检索的查询词:
双重策略
- LLM-based Rewrite(优先):用 qwen-max 将自然语言需求转换成检索关键词
- Rule-based Rewrite(fallback):基于规则提取关键词
python
def build_destination_query(destination: str, preferences: list[str] | None,
pace: str | None, special_notes: str | None) -> str:
# 优先 LLM 改写
llm_query = llm_rewrite_query(destination, preferences, pace, special_notes)
if llm_query:
return llm_query
# Fallback 到规则级
return _rule_based_query(destination, preferences, pace, special_notes)规则级关键词提取示例:
python
rule_keywords = [
(("日落", "傍晚"), "大理", ["日落", "傍晚", "洱海", "双廊"]),
(("日出", "清晨"), "大理", ["日出", "才村", "龙龛"]),
(("拍照", "出片"), None, ["拍照", "摄影", "出片"]),
(("美食", "小吃"), None, ["美食", "小吃"]),
(("骑行",), "大理", ["骑行", "洱海生态廊道"]),
(("熊猫",), "成都", ["大熊猫", "熊猫"]),
]7. RAG 层(检索增强)
7.1 Vector DB (app/rag/vector_db.py)
负责离线数据入库 和在线向量检索:
离线流程
scss
本地攻略(.md) → _split_markdown_into_chunks(按标题切分) → _build_embeddings(生成向量) → ChromaDB
python
def ingest_guide_chunks_to_chroma() -> int:
"""把本地攻略片段写入 Chroma"""
embeddings = _build_embeddings()
collection = _get_chroma_collection()
chunks = load_guide_chunks() # 读取并切分 Markdown
documents = [_build_document_text(chunk) for chunk in chunks]
vectors = embeddings.embed_documents(documents)
collection.upsert(
ids=[chunk["id"] for chunk in chunks],
documents=documents,
metadatas=[{"title": chunk["title"], "source": chunk["source"]} for chunk in chunks],
embeddings=vectors,
)
return len(chunks)在线检索
python
def search_guide_chunks(query: str, top_k: int = 3) -> list[dict[str, str]]:
"""优先向量检索,fallback关键词匹配"""
chroma_results = _search_guide_chunks_by_chroma(query, top_k)
if chroma_results:
return chroma_results
return _search_guide_chunks_by_keywords(query, top_k) # 降级方案7.2 Retriever (app/rag/retriever.py)
负责检索结果重排序 和缓存管理:
Rerank 策略
- Cross-encoder Rerank(优先):调用 qwen3-rerank 做语义重排序
- Rule-based Rerank(fallback):基于关键词匹配打分
python
def rerank_guide_chunks(query: str, matched_chunks: list[dict[str, str]],
top_k: int, destination: str | None = None) -> list[dict[str, str]]:
# 先查缓存
cache_key = _build_rerank_cache_key(query, matched_chunks)
cached = get_cached_json(cache_key)
if cached is not None:
return cached
# 优先 Cross-encoder
dashscope_results = _rerank_with_dashscope(query, matched_chunks, top_k)
if dashscope_results:
set_cached_json(cache_key, results, expire_seconds=REDIS_RERANK_TTL_SECONDS)
return results
# Fallback 规则级
return _rule_based_rerank(query, matched_chunks, top_k, destination)规则级打分逻辑:
| 条件 | 分数调整 | 说明 |
|---|---|---|
| 关键词在标题中 | +3 | 标题匹配权重更高 |
| 关键词在正文中 | +1 | 正文匹配权重较低 |
| "文档开头"噪声 | -8 | 文档开头信息量低 |
| "行程"标题 | +4 | 行程类片段更相关 |
| "行程参考"标题 | -4 | 过于泛化,降权 |
| 目的地不匹配 | -5 | 跨目的地污染降权 |
8. 核心业务流程
8.1 行程生成流程
arduino
POST /trip/generate
↓
trip.py(路由层)
↓
trip_service.py(主编排)
↓
① rag_tool.py → Query Rewrite(LLM-based / 规则 fallback)
↓
retriever.py → RAG缓存检查 → ChromaDB向量召回 → 噪声预过滤 → Cross-encoder Rerank
↓
② trip_planner_agent.py → 组装Prompt → qwen-max生成 → Pydantic校验
↓
③ map_service.py(逐景点)→ 地理编码 → POI搜索 → 路线估算 → 图片补充
↓
④ weather_service.py → 天气预报查询(可选)
↓
⑤ 预算拆分计算
↓
返回 Itinerary8.2 智能编辑流程
bash
POST /trip/edit
↓
trip.py(路由层)
↓
trip_service.py(主编排)
↓
① 定位目标 DayPlan(解析 edit_scope)
↓
② trip_planner_agent.py → generate_day_edit_draft(LLM编辑)
↓
失败则 fallback 到规则编辑(关键词匹配)
↓
③ 替换目标 DayPlan 的 theme/spots/meals/notes
↓
④ map_service.py 重新 enrich(清除旧坐标,重新查询)
↓
⑤ 更新 tips 和 source_notes
↓
返回更新后的 Itinerary8.3 保存与导出流程
bash
POST /trip/save → storage_service.py → SQLite 持久化
GET /export/{trip_id}/markdown
↓
storage_service.py 读取 itinerary
↓
export_service.py → Jinja2 渲染 Markdown
GET /export/{trip_id}/pdf
↓
storage_service.py 读取 itinerary
↓
export_service.py → ReportLab 生成中文 PDF
↓
Content-Disposition 返回下载文件名9. 辅助脚本
9.1 数据入库 (scripts/ingest_data.py)
首次使用前执行,将本地攻略文档写入 ChromaDB:
bash
cd backend
python scripts/ingest_data.py9.2 RAG 调试 (scripts/debug_rag_retrieval.py)
调试检索效果,输出:
- 检索 query
- top-k 召回片段
- rerank_score 与 rerank_reasons
9.3 RAG 评估 (scripts/evaluate_rag_retrieval.py)
量化评估检索效果:
- Top1/TopK 命中率
- MRR(平均倒数排名)
- Noise Rate(噪声率)
- Latency(延迟)
- Cross-destination Pollution(跨目的地污染)
10. 测试与验证
10.1 运行测试
bash
cd backend
pytest tests/test_api_trip.py -q # API 测试
pytest tests/test_services_trip.py -q # 服务层测试
pytest tests/test_rag_retriever.py -q # RAG 测试10.2 手动验证
bash
# 启动后端
uvicorn app.api.main:app --host 0.0.0.0 --port 8000
# 访问 Swagger UI
http://127.0.0.1:8000/docs
# 测试行程生成
curl -X POST "http://127.0.0.1:8000/trip/generate" \
-H "Content-Type: application/json" \
-d '{
"destination": "大理",
"start_date": "2024-07-01",
"end_date": "2024-07-03",
"travelers": 2,
"budget": 3000,
"preferences": ["美食", "自然风景"],
"pace": "轻松"
}'11. 关键技术亮点
11.1 RAG 在线优化
| 优化项 | 效果 |
|---|---|
| LLM-based Query Rewrite | Top1 命中率 80%→86.7% |
| Cross-encoder Rerank | Top1 命中率 86.7%→93.3% |
| 噪声预过滤 | 减少低质量片段干扰 |
| Rerank 缓存 | 延迟 728ms→425ms(降 41.6%) |
11.2 缓存设计
- 多层缓存:天气/地图/RAG/Rerank 各自独立配置
- 优雅降级:Redis 不可用时自动跳过,不影响主流程
- 统一前缀 :
trip_planner:{type}:{key}避免冲突
11.3 异常处理
- LLM 调用失败:回退到规则实现
- 地图服务失败:跳过 enrich,保留基础行程
- 缓存失败:跳过缓存,不影响业务
12. 学习路径建议
- 入门 :先理解
schemas.py和db_models.py,掌握数据结构 - 核心流程 :阅读
trip_service.py,理解行程编排逻辑 - LLM 调用 :学习
trip_planner_agent.py的 Prompt 设计 - RAG 检索 :深入
vector_db.py和retriever.py - 外部集成 :了解
map_service.py和weather_service.py - 实战:运行测试、调试 RAG、修改 Prompt
13. 常见问题
Q1:如何添加新目的地攻略?
- 在
backend/data/目录下新建{city}_guide.md - 执行
python scripts/ingest_data.py重新入库 - 在
rag_tool.py中添加目的地相关的关键词规则
Q2:如何开启缓存?
- 启动 Redis:
docker run -d --name tripplanner-redis -p 6379:6379 redis:7 - 在
.env中设置REDIS_ENABLED=true - 重启后端服务
Q3:地图信息不显示?
检查:
AMAP_API_KEY是否配置正确ENABLE_AMAP_ENRICHMENT是否为true- 网络是否能访问高德 API
附录:核心文件职责速查
| 文件 | 职责 | 关键功能 |
|---|---|---|
app/config.py |
配置中心 | 环境变量、数据库连接 |
app/api/main.py |
API入口 | FastAPI应用配置、路由注册 |
app/api/routes/trip.py |
行程路由 | 生成/编辑/保存/查询/删除 |
app/services/trip_service.py |
业务编排 | 行程生成、预算计算、地图补全 |
app/services/cache_service.py |
缓存管理 | Redis封装、优雅降级 |
app/services/map_service.py |
地图服务 | POI搜索、地理编码、路线估算 |
app/agents/trip_planner_agent.py |
LLM调用 | 行程生成、单日编辑 |
app/agents/tools/rag_tool.py |
Query改写 | LLM-based/规则级 |
app/rag/vector_db.py |
向量检索 | Chroma入库与查询 |
app/rag/retriever.py |
检索封装 | Rerank、缓存 |
app/models/schemas.py |
数据模型 | Pydantic请求/响应 |
app/models/db_models.py |
数据库模型 | SQLAlchemy表定义 |
本文档基于智旅云图项目 v0.1.0 版本编写