hello同学们!好久不见
总结
还是先上总结
- Token 是 AI 模型处理文本的最小单位,也是计费和数量单位,可以是单词、字符、标点符号或子词。
- 1 个 Token 的计算方式取决于语言和分词算法:英文中 1 个 Token 大约为 3-4 个字母,中文中 1 个 Token 大约为 1个汉字。 具体看该模型算法,这只是估算。
- 模型的输入输出token越多则越贵。
- 目前主流的token计算方法有BPE、WordPiece、SentencePiece。GPT系列用的就是BPE算法,gemini系列用的是SentencePiece方法
- 大模型不直接接收字符,它只接收 字符映射的id数组,比如:杭州天气怎么样 => 杭州,天气,怎么样 => 75232, 10452, 184901
- openai 模型的计费参考网址:developers.openai.com/api/docs/pr...
详解
在人工智能(AI)领域,特别是在自然语言处理(NLP)和大语言模型(如GPT、BERT等)中,Token 是文本处理的最小单位。它可以是一个单词、一个字符、一个标点符号,甚至是一个子词(subword)。 Token 的具体定义和计算方式取决于所使用的分词算法和模型规则。
Token 的基本定义
Token 是什么?
Token 是文本经过 Tokenizer(如 BPE、WordPiece、SentencePiece)编码后得到的基本处理单位,也是大模型计算和计费的基础单位。
Token 不一定等同于单词,它可能是完整单词、子词、字符或标点。例如,英文句子
"Hello, world!"可能被拆分为:
rust"Hello, world!" --> Tokenization--> ["Hello", ",", "world", "!"]-->[2343,3534,1443,9876]这其中的 2343,3534,1443,9876 每一项代表一个token,数字则代表该字符的映射id
Token 的作用
- 标准化处理:将文本分解为 Tokens 后,便于模型进行统一处理和分析。
- 降低计算复杂度:直接处理原始文本会导致计算复杂度过高,而 Token 化后的文本更容易存储和处理。
- 提高模型性能:Token 化有助于模型更好地理解和学习文本中的模式和结构。
Token的单位
token计费中的K和M是数量单位,而非存储大小单位。
gpt-4o模型计费单位中的 输入 1m/2.5美元的意思是,每输入 1百万个token,收费2.5美元,不是每输入1MB token收费2.5美元。
128k,32k,1M这些单位代表允许context window为128000token,32000token和1000000token。
1k === 1000
1M === 1百万
context window 简单介绍:就是当次输入给大模型以及当次大模型输出token的总和
Token的计算方法
(1)按"词"划分(Word-level Tokenization)
- 原理:把句子拆成完整单词或词组
- 英文常用,用空格或标点切分
- 中文不适用(没有空格分词)
- 优点:简单、直观
- 缺点:无法处理未登录词(OOV)、生成能力受限
已知是按词划分,首先程序得知道有这个"词"的存在。所以会有一个模型词表
OOV 解释,"OOV" 是 Out-Of-Vocabulary 的缩写,也就是 "未登录词" ,意思是 模型词表里没有出现过的词或符号。
例子:
css
I love AI! → ["I", "love", "AI", "!"] → [23,4322,1244,34453]这个方法基本上也已经被淘汰了。毕竟不论什么词库,都不能100%匹配。和我们国家的生僻字差不多。有些生僻字,打字都打不出来。就是不在词库里的原因。
(2)按"字符"划分(Character-level Tokenization)
- 原理:每个字符一个 Token
- 中文天然适用,英文每个字母也是一个 token
- 优点:没有未登录词问题,灵活
- 缺点:Token 数量大计算量高,
例子:
css
hello → ["h", "e", "l", "l", "o"] → [12,34,654,34,54]这个方法目前主流的模型已经淘汰他了,计算成本高、显存占用大。完了最后以token数量计费的时候还死贵死贵。
(3)按"子词/字节对"划分(Subword Tokenization)
-
核心方法:BPE、WordPiece、SentencePiece
-
原理:
- 从字符开始
- 迭代合并高频邻接字符或子词组合
- 构建固定大小词表
-
优点:
- 兼顾 未登录词处理 和 Token 数量控制
- 英文和中文都适用
-
缺点:
- 拆分规则依赖训练语料
- Token 数量不固定
GPT系列用的就是BPE算法,Gemini系列用的是SentencePiece方法
例子:
scss
unbelievable → ["un", "believ", "able"] (WordPiece)
机器学习 → ["机器学习"] 或 ["机器", "学习"] (BPE)BPE、WordPiece、SentencePiece 这三玩意都是把句子分词的一种算法
(4)混合方法
-
主要是 Google 提出的,支持:
- 纯字符模式
- BPE 模式
- Unigram 模式
-
特别适合中文、日文、韩文等无空格语言
Token 的应用
Token 的计费方式
许多大模型服务商(如 OpenAI、DeepSeek 等)按 Tokens 数量计费。例如,输入和输出的 Tokens 总数会被计算为总消耗量。假设输入消耗 100 Tokens,输出消耗 200 Tokens,则总消耗为 300 Tokens。
而每个模型的计费标准不一样,同一个模型的输出输出计费也不一样,如下
- 以 GPT‑4o 模型为例,它的计费标准是输入 token 每 1M 约 2.5美元,输出token 每1M约10美元。
- 而以GPT‑5 模型为例它的计费标准是输入token每1M约1.25美元输出token每1M约10美元。
gemini系列计费网址 ai.google.dev/gemini-api/...
openai 计费网址(gpt系列):developers.openai.com/api/docs/pr...
token在模型中最大可输入输出限制
token在模型中最大可输入输出限制叫做 context window ,context window 的大小 决定了模型一次性能够处理的最大 Tokens 数量(包括输入和输出)。例如:
- context window 为 8k Token 的模型 可以处理约 8,000 个汉字的上下文,比如 GPT‑4 标准版
- context window 为 32k Token 的模型 可以处理约 32,000 个汉字的上下文,比如 GPT‑4-32k 模型
- context window 为 128k Token 的模型 可以处理约 128,000 个汉字的上下文,比如 GPT‑4o 模型
实际可处理的汉字数取决于文本中是否包含英文、标点或高频词组,因为这些会影响 Token 划分。
这里的大小限制(上下文)是指:我们最后发给大模型的token数 + 大模型预计可能吐出来的token数
模型context window最大限制不是唯一的,不同的模型可能不一样
从文本到模型输入
上一个小节解释的是,一个句子怎么进行分词。但是这个分词最后还不是输入给大模型的内容。
大模型不直接接收字符,它只接收 字符映射的id数组
我们以"杭州天气怎么样"这句话和gpt-4o作为案例
- 第一步:他会先被分词为 杭州,天气,怎么样
- 第二步:分词找到该词的词库id 为 75232, 10452, 184901
- 第三步:把 75232, 10452, 184901 传入到 大模型等待回复
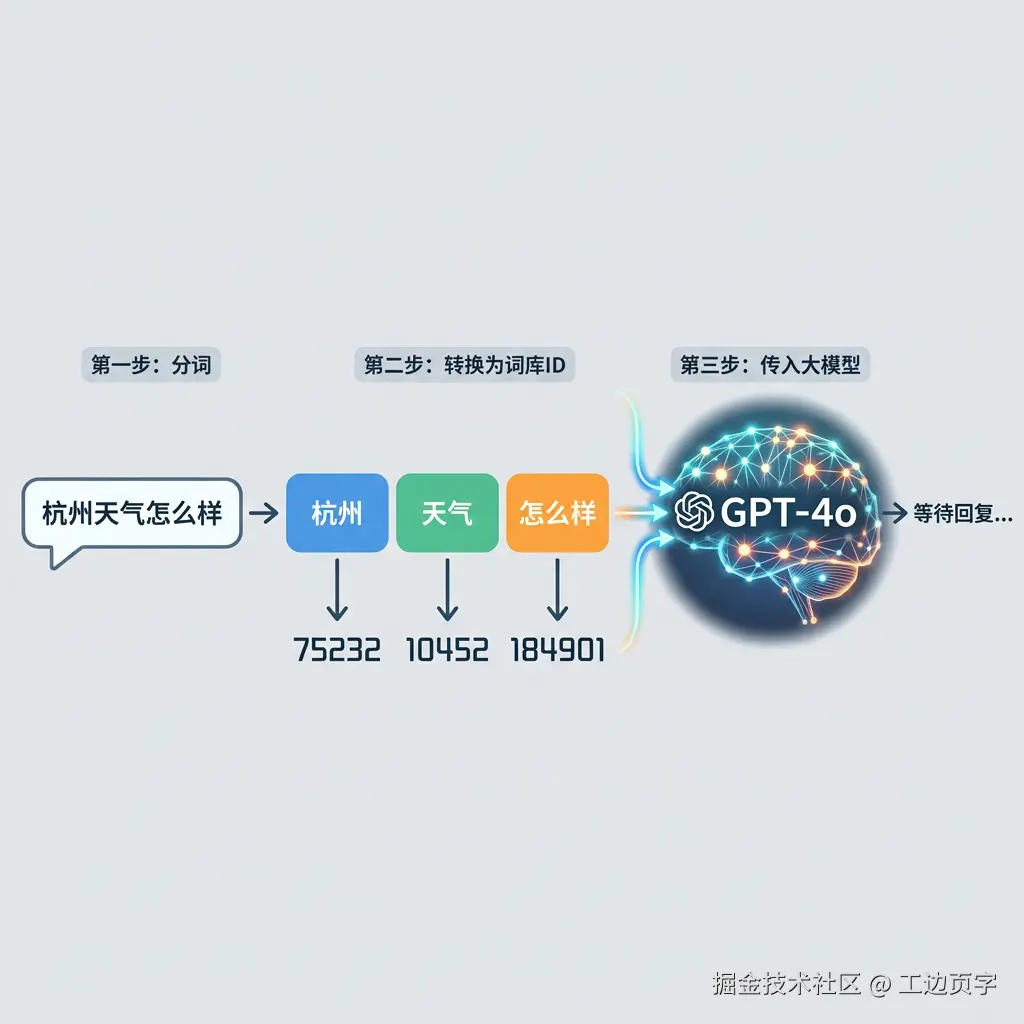
杭州天气怎么样 => 杭州,天气,怎么样 => 75232, 10452, 184901 ,这个数组里三个项,这就是3个token。
用代码尝试一下
以下使用 BPE 方法进行分词计算token,和GPT系列是同一种算法
按如下流程走就好:api-docs.deepseek.com/zh-cn/quick...
js计算token的方法
js
const tiktoken = require('tiktoken');
// 选择编码器(例如,GPT-4 使用 cl100k_base)
const encoding = tiktoken.get_encoding('cl100k_base');
// 输入文本
const text = "Hello, world! 你好,世界!";
// 计算 Token 数
const tokens = encoding.encode(text);
const tokenCount = tokens.length;
console.log(`Token 数: ${tokenCount}`);java的计算方法
java
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.9.3</version>
</dependency>
java
import okhttp3.*;
public class OpenAITokenCounter {
private static final String API_KEY = "your_openai_api_key";
private static final String API_URL = "https://api.openai.com/v1/completions";
public static int countTokens(String text) throws IOException {
OkHttpClient client = new OkHttpClient();
// 构建请求体
String json = String.format("{\"model\": \"gpt-3.5-turbo\", \"prompt\": \"%s\", \"max_tokens\": 1}", text);
RequestBody body = RequestBody.create(json, MediaType.parse("application/json"));
// 构建请求
Request request = new Request.Builder()
.url(API_URL)
.post(body)
.addHeader("Authorization", "Bearer " + API_KEY)
.addHeader("Content-Type", "application/json")
.build();
// 发送请求并获取响应
Response response = client.newCall(request).execute();
String responseBody = response.body().string();
// 解析响应中的 Token 数
// 注意:实际 API 响应可能需要更复杂的解析
return responseBody.split("\"total_tokens\":")[1].split(",")[0].trim();
}
public static void main(String[] args) {
try {
String text = "Hello, world! 你好,世界!";
int tokenCount = countTokens(text);
System.out.println("Token 数: " + tokenCount);
} catch (IOException e) {
e.printStackTrace();
}
}
}python的计算方法
python
from transformers import GPT2Tokenizer
# 加载分词器
tokenizer = GPT2Tokenizer.from_pretrained("gpt2")
# 输入文本
text = "Hello, world! 你好,世界!"
# 计算 Token 数
tokens = tokenizer.encode(text)
token_count = len(tokens)
print(f"Token 数: {token_count}")我们用python举个例子如下
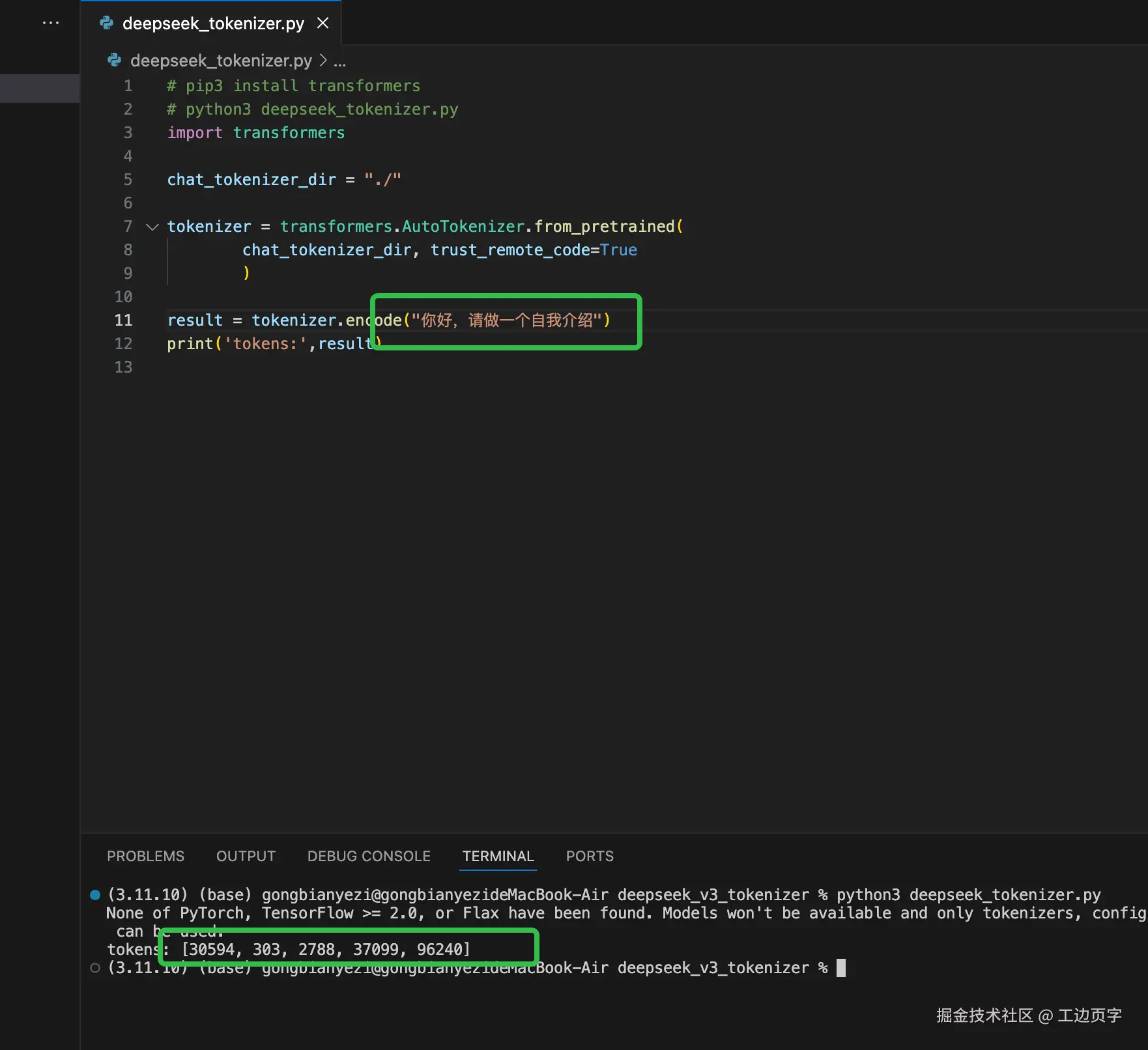
注意:再次强调,这是使用 BPE的算法算出来的token,不是所有模型都是这个算法,gpt系列用的是该算法。
最后
hello,我最近有点失业。如果有工作内推的小伙伴可以加我一下,我的大致情况如下
我的情况是:
工作经验4年+ 干过小公司的前端技术leader。
近两年都是全栈,侧重前端+node(electron main侧)
有过C端Ai产品开发经验
我的缺陷是:专科
v:18758683311
我的诉求是:杭州宁波,南京苏州,深圳广州厦门,稳定的远程也行。除泰国缅甸柬埔寨外的外派驻场也行。
我期望的薪资是:足额公积金18-20,非足额公积金20-22
此内容还在,工作就还在找,求有缘人内推。