最近,一批顶级通用大模型参加了三场特殊的 "工业执业考试"。
结果出乎意料:即便是 GPT-5.2 Thinking (high) 、Gemini-3.1-Pro 这类叱咤风云的选手,面对真实的工业工程语境,也并不得心应手。
能写诗、能编程的通用 AI,为什么搞不定一条生产线?
答案藏在一家低调的工业 AI 明星公司------思谋科技 ,以及他们自研、专为工业打造的大模型 IndustryGPT 给出的解题思路里。
要知道,在这三次考试中,IndustryGPT 不仅在通用榜单霸榜,更在万条工业基准和 "执业级" 工程考场上,打败了 GPT-5.2 Thinking (high)与 Gemini-3.1-Pro。

这场 "考试" 的比分本身或许没那么重要,但它撕开了一道口子,让人们看清了通用大模型在真实产业场景下的能力边界。
当模型真正走进生产线,参与工程决策,"聪明" 只是基础能力,合规、严谨、可靠才是核心指标。
这也意味着,大模型赋能实体经济,正在从概念验证走向真刀实枪的验收期。而工业,无疑是这场大考中最硬核的考场。
问题是:中国制造业,到底需要什么样的 AI?
三场考试,看清通用模型的 "工业盲区"
IndustryGPT,是思谋科技发布的全球首个专注于工业场景的多模态大模型。
为了回答 "制造业需要什么样的 AI" 这个问题,思谋做了一件事:把市面上几款主流大模型拉进来,跟 IndustryGPT 一起考了三场试。
第一场,考工业知识 "广度"。
为了建立客观可比的评测基准,思谋选取权威开源中文数据集 SuperGPQA 中与工业相关的题目子集,对 IndustryGPT 与 GPT-5.2 Thinking (high) 、Gemini-3.1-Pro 等国际顶尖通用大模型进行了横向测试。
SuperGPQA 是目前中文领域覆盖面最广、题目质量最高的综合知识评测数据集之一,其工业相关子集涵盖了工程技术、制造工艺、材料科学等多个专业方向。
结果显示:IndustryGPT 取得同类模型中的 SOTA,在工业专业知识的广度、问答准确率上,超越了 GPT-5.2 Thinking (high) 、Gemini-3.1-Pro 等顶尖通用模型。
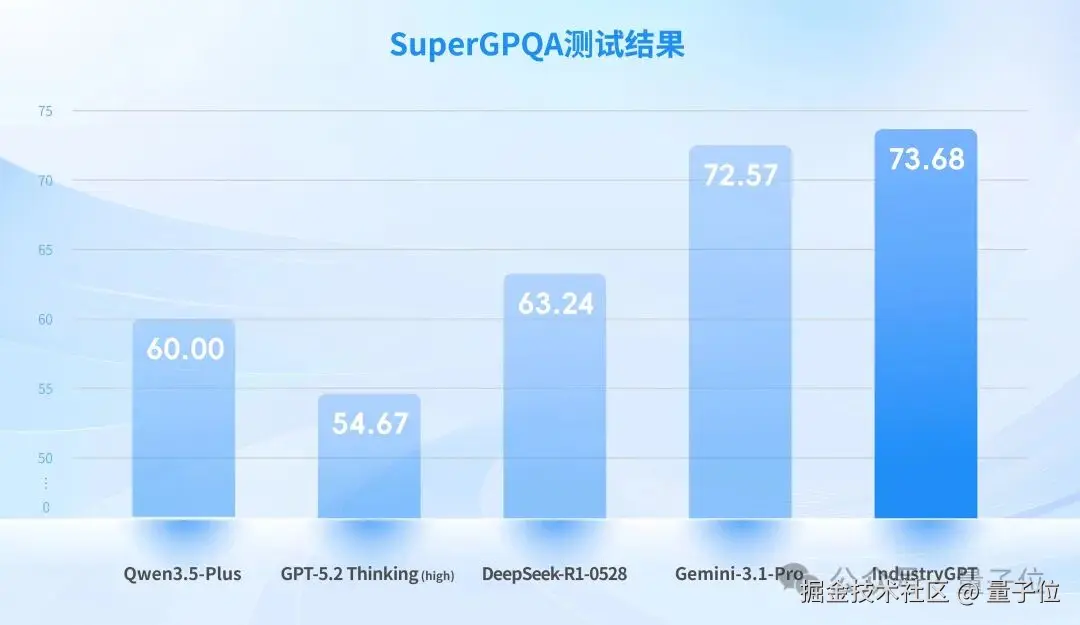
这说明它在工业专业知识上构建了核心的竞争壁垒,解决了通用大模型 "工业知识浅、专业问答错漏多" 的基础问题。
不过嘛,开源 benchmark 只是第一道门槛。
SuperGPQA 虽然覆盖面广,但工业场景的专业深度和多样性远超标准测试集的范畴------一套通用的考题,很难考出模型在真实产线上的 "手感"。更何况,业界目前本就缺少专门针对工业场景的评测数据集。
要想考出大模型在工业场景的真实水平,还得自己出题!!

于是有了第二场考试:考工业知识深度。
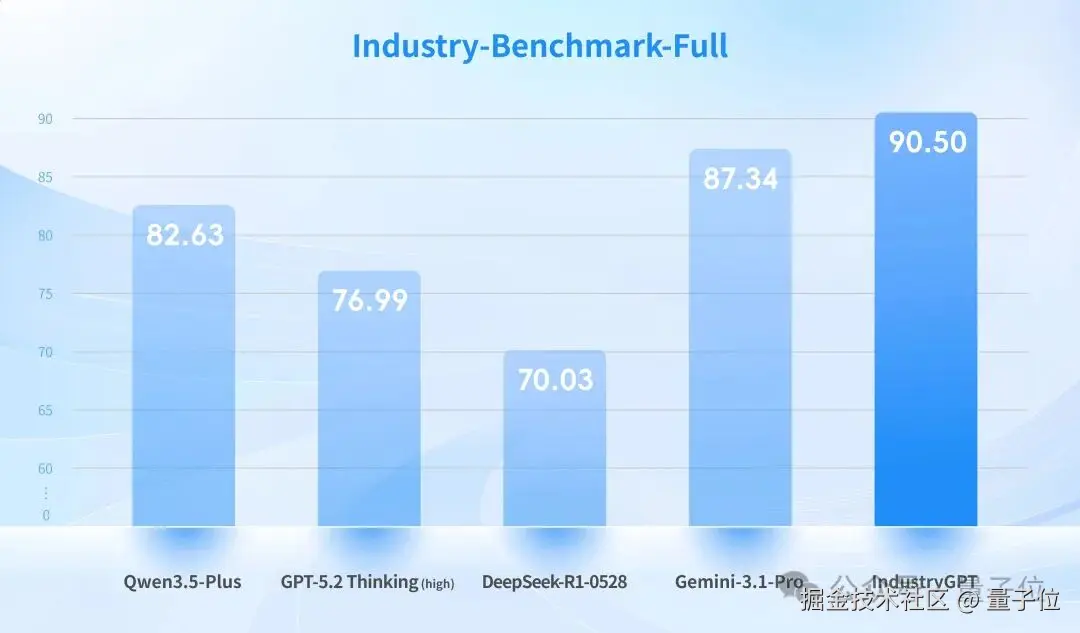
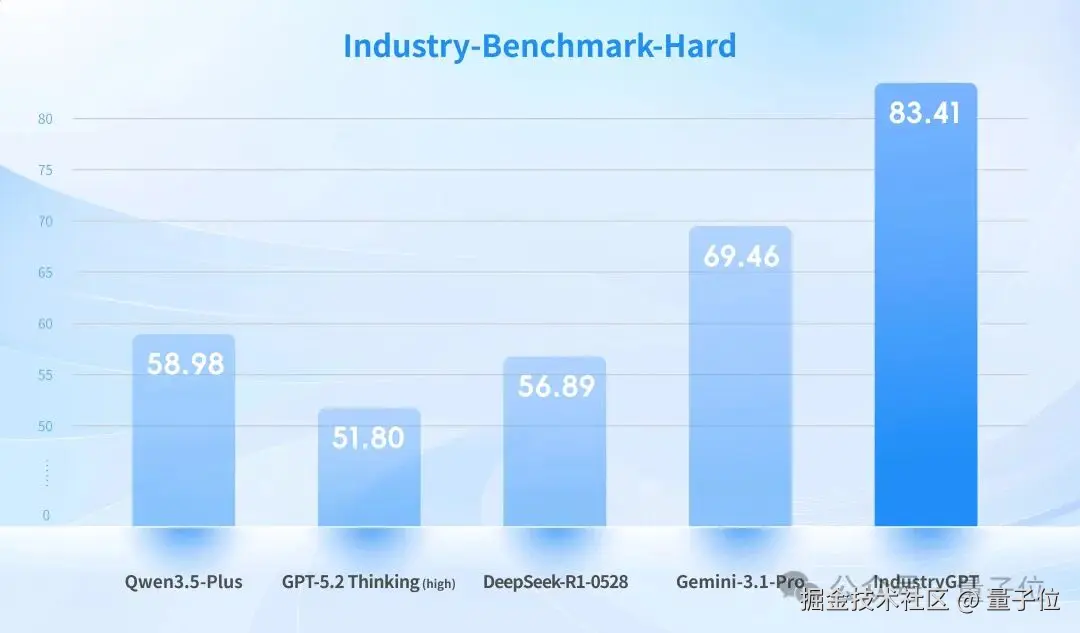
思谋自建了一套系统化的工业知识基准评测数据集 ,包括 12 个工业相关子领域,涵盖机械、光学、电气等核心工程学科,覆盖 3C 电子、建筑、矿业、纺织等典型工业领域。
这套 benchmark 还真不是盖的:题目总数量超万条,超过目前所有开源工业数据集。

思谋特意设置了一批高难度的 "困难问题",用于模拟真实工业环境中的复杂决策场景。
结果 IndustryGPT 领先的不是一点半点:在 "困难问题" 子集上,GPT-5.2 Thinking (high)和 Gemini-3.1-Pro 统统翻车,而 IndustryGPT 不仅取得 SOTA,还实现了超过 20% 的相对性能提升。
如果你以为,工业 AI 只要在自家考卷上赢了就算数,那就太低估工业世界的 "狠" 了。
AI 真要在工业场景里干活,就不能只会答题,还必须具备参与真实工程决策的能力。
于是,思谋继续上强度 ,组织了第三场考试------考 "执业资格"。
他们自主构建了全球首个以执业资格难度为标尺、以工程强制规范为刚性约束、以可落地工程决策能力为核心的大模型评测基准,彻底跳出通用学术 benchmark 的局限。
好家伙,直接从知识理解测试,拉高到了工程决策能力测试。

这套评测框架,对齐中美最高级别官方执业资格考试,参照中国全国注册工程师执业资格考试及美国 NCEES FE/PE 考试框架。
数据集涵盖电气、机械、化工、土木 等核心工程学科,问题以真实工程场景为背景,要求模型在多重约束条件下完成法规条文精准匹配、多步骤数值推导,以及跨规范冲突情形下的优先级判断与风险控制。
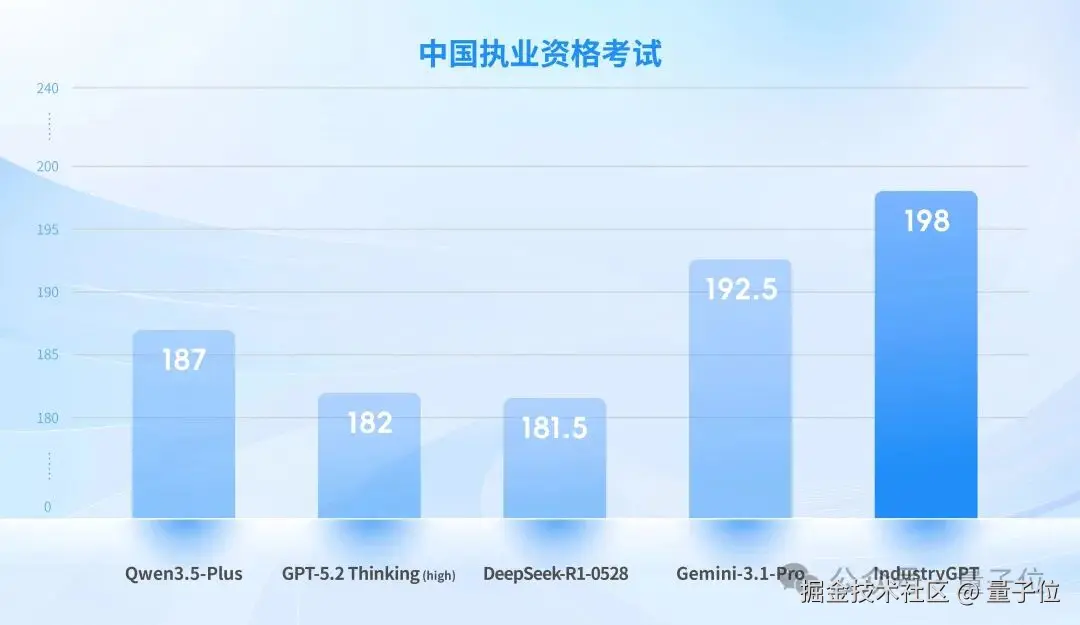
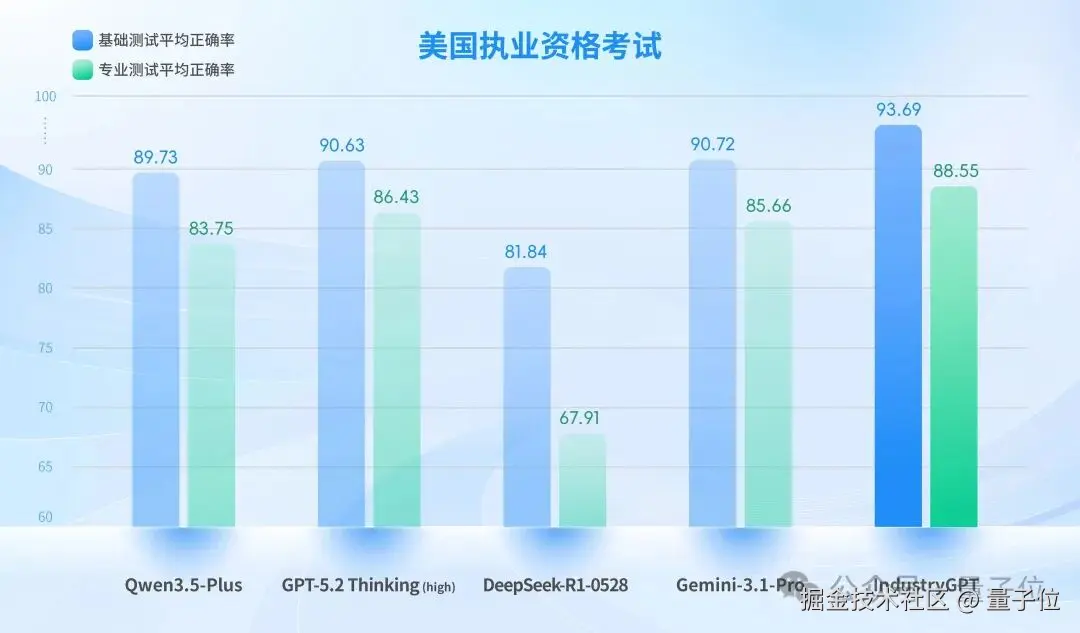
注:平均正确率由电气、机械、化工、土木等学科得分取平均计算得出
对比 GPT-5.2 Thinking (high) 等顶尖通用模型,IndustryGPT 在两项测试中均取得 SOTA 结果。
IndustryGPT 不仅在法规条文的精确引用与规范一致性方面展现出更高的稳定度,在跨规范冲突处理、工程假设合理性控制等关键指标上也处于领先地位。综合来看,在实际执业场景中,其针对复杂工程方案的综合推理评估与辅助决策能力更为出色。
一整个就是逼近真实执业工程师的水平。
这三场考试指向同一个判断:工业场景对 AI 的需求,和通用场景存在结构性差异。通用模型在常识层面表现良好,但在规范遵从、边界控制、复杂决策等工业刚需上,仍然稍逊一筹。
不只是考得好,是真能下产线
评测成绩只是门槛,真正关键的是:模型能否嵌入生产系统,成为业务流程的一部分。
而 IndustryGPT 给出的答案是:通过与智能体 技术的深度融合,在多个高标准场景中实现感知 - 决策 - 执行的完整闭环。
SMore ViMo 就是一个典型的行业模型 + Agent 落地形态。它依托 IndustryGPT 的原生 Agent 能力,将客户从项目启动到可运行模型的落地周期,从行业平均 14 天压缩至 3 天以内。
在工业质检环节 中,可自动识别、归类缺陷属性,并通过闭环校验修正精度,效率飙升 200%。
结果也很突出:90% 以上的常见异常由系统自主解决,核心经验从个人变为组织资产。
这几类场景都说明:通用模型 "能说" 但不敢用,行业模型 "能做" 且能负责。
大模型 "验收标准" 正在重构
三场考试以及落地案例背后,指向一个更核心的问题:工业场景对大模型的 "验收标准" 正在发生根本性重构。
过去几年,大模型更多是以 "智能水平" 被评价:参数规模、通用榜单排名、多轮对话能力、代码生成能力...... 这些指标在互联网场景里成立,但在工业场景中,却远远不够。
工业 AI 还需要具备三项核心能力,这也是通用模型目前难以通过后期微调实现的:

第一,边界控制能力。
在工业环境中,越界往往意味着风险。模型不仅要给出正确的结果,还要在规范约束和安全边界内运行。
IndustryGPT 没有简单照搬通用大模型常用的 RLHF 训练方式,而是进一步引入 "规范一致性奖励模型" 与 "计算过程奖励模型"。
模型在训练中不仅根据最终答案是否正确获得反馈,更会对中间推理步骤是否符合工程标准、计算路径是否严谨进行细粒度评估。
这也让模型逐步形成对安全边界、数值精度和规范冲突处理的稳定偏好,从而在复杂工程问题中表现出更高的可靠性与一致性。

第二,规范遵从能力。
工业生产有严格的强制性规范,是必须执行的红线。
在这一点上,IndustryGPT 做到了 "先学规范,再学表达" 。它并未沿用通用互联网语料为主的训练范式,而是对工业知识体系进行了结构化重构。
通过将工程规范、国家标准、工艺文档、设备手册等专业内容进行层级化整理,然后再喂给大模型------让模型在训练阶段便形成了 "规范优先" 的知识表达方式,其在回答问题时天然遵循工程语境。
第三,任务执行能力。
工业场景不需要纸上谈兵的 AI。IndustryGPT 的 Agent 架构使其能够调用工具、拆解任务、执行流程,将抽象理解能力转化为可执行的工程流程。
这种 "认知 + 执行" 一体化的架构,使模型能够在真实工业环境中完成多步骤任务,而不是停留在文本建议层面。

综合来看,IndustryGPT 的能力提升路径,代表了工业大模型一个清晰的技术方向:从 "通用智能" 转向 "可执业智能"------
模型不再只是理解世界,而是能够严格遵循工业规则,在真实的强约束条件下,稳定、合规、高效地完成工程任务,实现从实验室到生产线的跨越。
随着 "AI + 制造" 的逐步深入落地和铺开,这三项能力,正在成为工业客户评估 AI 供应商的新标准。
中国制造业需要什么样的工业 AI?
关于工业 AI 的路线之争,行业内的讨论从未停止。目前主流的技术路线分为两派:
一派是 "通用大模型 + 行业微调" 路线,核心逻辑是先打造强大的通用底座,再通过行业数据微调,适配工业场景的需求;
另一派则是 "原生工业垂类大模型" 路线,以思谋 IndustryGPT 为代表,核心逻辑是从底层训练范式开始,就针对工业场景的特性进行重构,原生适配工业的规则与需求。
两条路线的分歧点不在于技术路径本身,而在于对 "验收标准" 的不同理解。
如果验收标准是 "能回答工业问题",那么微调路线足以交卷。
但如果验收标准是 "能嵌入产线、能按规范干活、能对结果负责",情况就不一样了。
因为边界控制、规范遵从、任务执行这三项能力,与通用模型的训练范式存在根本性冲突------通用大模型的核心是 "泛化理解",而工业大模型的核心是 "精准执行",后者无法通过后期微调获得,必须从底层训练范式开始重构。

2025 年,我国 AI 核心产业规模突破了 1.2 万亿,但和制造业的融合还卡在 "技术不接地气、场景落不深" 的阶段。
今年 1 月,工信部等八部门印发《"人工智能 + 制造" 专项行动实施意见》,明确提出到 2027 年 "推出 1000 个高水平工业智能体"------"智能体"三个字,就是对 "验收标准" 的定调:要的是能执行的 AI,不是只能回答的 AI。

2026 年,随着大模型进入应用阶段,竞争正在从 "参数竞赛" 转向"落地验收"。
IndustryGPT 对 GPT-5.2 Thinking (high) 等国际顶尖通用大模型那 20% 的领先幅度,真正的意义并非 "谁赢了考试",而是反映出目前主流通用模型和真实产业需求之间,依然存在系统性错位。
这种错位,恰恰印证了工业垂类大模型的核心价值:在 AI 与制造业深度融合的过程中,通用大模型是重要的技术底座,但贴合产业需求的原生垂类大模型,才是实现技术落地的核心抓手。
回到一开始的问题:中国制造业,到底需要什么样的 AI?
AI 赋能实体经济,终局不是比谁更 "聪明",而是比谁更 "落地"。对中国万千制造企业和无数复杂场景而言,AI 的价值从来不是 "炫技",而是 "赋能"。
思谋 IndustryGPT 的探索,是 AI 产业落地大幕的开始。整个行业的答案,还藏在更多躬身入局的实践中。
欢迎在评论区留下你的想法!
--- 完 ---