本章涵盖
- 使用 LangGraph 构建由大语言模型驱动的智能体
- 注册并使用工具,以支持智能体的动态执行
- 调试智能体执行过程与工具调用
- 使用 LangGraph 预构建组件简化智能体开发
- 使用 LangSmith 观察智能体执行过程
在第 5 章中,我们探讨了 agentic workflows(智能体式工作流)与 agents(智能体)之间的区别。你已经了解到,agentic workflows 本质上是确定性的:它们的逻辑建立在带有条件分支的流程之上,而这些分支取决于应用当前的状态。这类工作流可以在 LangGraph 中优雅地建模为基于节点的图,你也已经看到了一个完整的、可动手实践的系统示例。
而智能体的运作方式则不同。它们并不是沿着预先确定好的流程前进,而是依赖动态的、对上下文敏感的决策机制。在大语言模型(LLM)的帮助下,智能体会根据任务不断演化的上下文,自主决定要使用哪些工具,以及这些工具应按什么顺序调用。这些决策并不是预先写死的;相反,它们会随着智能体持续评估前一步行动的输出并据此调整策略,而一步步展开。
在本章中,你将把这些理念付诸实践,构建一个多工具旅行信息智能体。你会从一个简单版本开始:先实现一个只使用单个工具、用于提供目的地信息的智能体。然后,你会将它扩展为一个真正的多工具智能体,使其既能回答旅行目的地相关问题,也能回答这些地点的当前天气情况。
随着内容推进,我会向你介绍构建多工具智能体所需的核心概念,重点会放在工具调用协议(tool-calling protocol)上。你将先从零开始手工实现这一协议,以真正理解其中的每一个细节;随后你会看到,LangGraph 内置的能力如何帮助你简化智能体架构、减少实现复杂度。
本章构建的多工具智能体,还将成为后续章节中更高级、多智能体系统的基础。让我们开始吧------前面还有很多值得探索的内容。
11.1 从简单开始:构建一个单工具旅行信息智能体
在这一节中,我们将通过构建一个简单的旅行信息智能体,为后续的智能体应用打下基础。这个初始智能体只会使用一个工具:一个向量存储检索器,用来回答关于康沃尔(Cornwall)各个目的地和度假地的问题,其知识来源是 Wikivoyage(www.wikivoyage.org)上的内容。这些内容会被切分为若干文本块,并存入向量存储,以便高效检索。
如果你已经跟着本书前面关于高级 Retrieval-Augmented Generation(RAG,检索增强生成)的章节学习过,那么你应该已经熟悉如何获取内容源并填充向量存储。在这里,我们会在这一基础之上继续推进,但重点将放在智能体机制本身。
11.1.1 项目准备
让我们使用 Visual Studio Code(VS Code)来创建一个新的 Python 项目。这个流程同样也可以非常顺畅地在 Cursor 中使用。
创建虚拟环境并安装依赖
首先,创建 Python 虚拟环境,并安装所有必需的依赖。你可以在本书的 Manning 网站配套资源中找到 requirements.txt 文件,也可以在与第 11 章对应的 GitHub 仓库中找到它。
在 VS Code 中打开一个新的 PowerShell 终端(选择 Terminal > New Terminal),进入 ch11 项目目录,然后创建并激活一个新的虚拟环境:
PS C:\Github\building-llm-applications\ch11> python -m venv env_ch11
PS C:\Github\building-llm-applications\ch11> .\env_ch11\Scripts\activate
(env_ch11) PS C:\Github\building-llm-applications\ch11>虚拟环境激活后,安装所需依赖:
scss
(env_ch11) PS C:\Github\building-llm-applications\ch11> pip install -r .\requirements.txt至此,你的项目开发环境就已经准备好了。
添加 OpenAI API Key
在项目根目录下创建一个 .env 文件,并加入你的 OpenAI API Key:
ini
OPENAI_API_KEY=<Your OPENAI_API_KEY>配置 VS Code 调试
为了方便调试,在 .vscode 目录中加入如下 launch.json:
bash
{
"version": "0.2.0",
"configurations": [
{
"name": "Python Debugger: Current File",
"type": "debugpy",
"request": "launch",
"program": "${file}",
"console": "integratedTerminal"
}
]
}建议你使用 main_x_y.py 这种命名规则来组织实现文件。这里 x 表示功能模块(例如,main_01_01.py 表示最初的旅行信息智能体,main_02_01.py 表示加入天气功能后的版本),而 y 表示该功能的迭代版本。这样做可以让你更容易对比不同版本,也更方便跟踪实现过程的演进。
注意:本章中的代码示例有意进行了简化,目的是突出核心功能。为了便于理解与学习,示例中省略了错误处理和防御式编程相关内容。
11.1.2 加载环境变量
当你的 .env 文件准备好之后,创建一个名为 main_01_01.py 的代码文件。在脚本顶部、导入语句之后(这里为简洁起见省略了导入语句------完整列表请参考 GitHub 仓库),按照下面的方式加载 API Key。
代码清单 11.1 加载环境变量
bash
load_dotenv() #1
#1 从 .env 文件中加载环境变量11.1.3 准备旅行信息向量存储
为了让我们的旅行信息智能体能够回答关于康沃尔各目的地的问题,我们首先需要一种能够高效存储并检索相关信息的方法。这里的方法借鉴了你在第 8 章 8.3 节和 8.4 节中学到的高级 RAG 技术,但为了更适应智能体场景做了适当简化。整体思路如下:我们将从 Wikivoyage 下载一组康沃尔目的地的旅行内容,把文本切分成可管理的块,将这些文本块嵌入为向量表示,然后存入 Chroma 向量存储中。此外,我们还会使用单例模式封装初始化逻辑,以确保在智能体生命周期内,向量存储只被构建一次。下面的代码就完成了这个向量存储的构建,使得智能体在运行时能够轻松检索相关旅行信息。
代码清单 11.2 准备旅行信息向量存储
python
UK_DESTINATIONS = [ #1
"Cornwall",
"North_Cornwall",
"South_Cornwall",
"West_Cornwall",
]
async def build_vectorstore(
destinations: Sequence[str]) -> Chroma: #2
"""Download Wikivoyage pages and create
a Chroma vector store."""
urls = [f"https://en.wikivoyage.org/wiki/{slug}"
for slug in destinations] #3
loader = AsyncHtmlLoader(urls) #3
print("Downloading destination pages ...") #3
docs = await loader.aload() #3
splitter = RecursiveCharacterTextSplitter(
chunk_size=1024, chunk_overlap=128) #4
chunks = sum([splitter.split_documents([d])
for d in docs], []) #4
print(f"Embedding {len(chunks)} chunks ...") #5
vectordb_client = Chroma.from_documents(
chunks, embedding=OpenAIEmbeddings()) #5
print("Vector store ready.\n") #5
return vectordb_client #6
_ti_vectorstore_client: Chroma | None = None #7
def get_travel_info_vectorstore() -> Chroma: #8
global _ti_vectorstore_client
if _ti_vectorstore_client is None:
if not os.environ.get("OPENAI_API_KEY"):
raise RuntimeError(
"""Set the OPENAI_API_KEY env
variable and re-run.""")
_ti_vectorstore_client = asyncio.run(
build_vectorstore(UK_DESTINATIONS))
return _ti_vectorstore_client #9
ti_vectorstore_client = get_travel_info_vectorstore() #10
ti_retriever = ti_vectorstore_client.as_retriever() #11
#1 康沃尔目标目的地列表------可以根据需要扩展
#2 异步函数:构建并返回向量存储
#3 下载每个目的地对应的 Wikivoyage 内容
#4 将下载下来的文档切分成可管理的文本块
#5 对每个文本块生成嵌入,并存入 Chroma 向量存储
#6 返回初始化好的向量存储
#7 向量存储客户端的单例缓存
#8 获取/初始化缓存向量存储的函数
#9 返回缓存中的向量存储客户端实例
#10 创建向量存储客户端
#11 从向量存储中创建一个检索器这段配置首先定义了一个与康沃尔相关的目的地列表,它将作为后续信息检索的基础。异步函数 build_vectorstore() 会为每一个目的地构造 URL,并使用异步加载器抓取对应的 Wikivoyage 页面。页面下载完成后,文本会被切分成带有重叠的文本块,以确保每个文本块在上下文上保持足够的语义完整性。随后,这些文本块会通过 OpenAI 的嵌入模型转为向量,并存入 Chroma 向量数据库中,从而支持按语义相似度进行快速搜索。
为了避免不必要的重复计算和重复下载,这里使用了单例模式来管理向量存储客户端。get_travel_info_vectorstore() 函数会确保向量存储只构建一次,后续所有检索都会复用这一实例。最后,我们实例化向量存储客户端,并从中创建一个 retriever 对象------这个 retriever 将成为智能体访问康沃尔旅行信息的接口。借助这一基础设施,智能体就能高效回答关于目的地的问题,并且其知识来源是直接从 Wikivoyage 获取的最新内容。
11.2 让智能体能够调用工具
现在我们已经准备好了向量存储检索器,下一步就是把这个检索能力暴露为一个智能体可调用的工具。这也正是"工具调用(tool calling)"这一概念的切入点------它是现代智能体框架中的一项重要进展。
11.2.1 从函数调用到工具调用
像 OpenAI 这样的 LLM 最初引入的是函数调用(function calling)机制:模型可以根据提示需求,请求调用某个特定函数,并传入结构化参数。这个概念随后迅速演化成更一般化的工具调用协议(tool-calling protocol),如今已被主要的 LLM 提供商广泛支持。借助工具调用,模型不仅可以调用自定义函数,还可以调用各种内建或外部"工具",从代码执行到外部 API 查询都可以纳入支持范围。
定义:工具(tool)是指 LLM 可以通过工具调用协议调用的任意外部函数、服务或能力。工具让模型的能力超越纯文本生成,例如执行代码、查询数据库或调用 API------模型通过传入结构化输入并接收结构化输出来完成这些操作。
你可能会问,为什么工具调用这么重要?为什么不直接让智能体通过普通 REST API 端点访问功能呢?
关键原因在于灵活性。之所以我们需要智能体,而不是固定的 agentic workflows,是因为在很多场景下,我们事先无法准确预测会需要哪些工具、这些工具需要以什么顺序调用,或者用户的问题应如何映射为工具参数。在这种情况下,硬编码 API 调用远远不够。
智能体的优势就在于,它可以动态地做出这些决策:选择合适的工具、决定调用顺序,并构造符合工具参数要求的输入。现代 LLM 正是围绕这一能力被专门训练出来的,工具调用也因此成为其响应协议中的内建能力(例如 OpenAI Responses API)。简而言之,工具调用解锁了多工具智能体所依赖的那种自适应推理能力。
这一演进极大地简化并增强了智能体实现方式,尤其是在采用 ReAct(Reasoning and Acting,推理与行动)设计模式时更是如此。ReAct 模式由 Yao 等人在 2022 年论文《ReAct: Synergizing Reasoning and Acting in Language Models》(arxiv.org/abs/2210.03...)中提出,它允许 LLM 交替进行推理步骤("thoughts")和工具调用("actions")。实际上,这意味着模型可以把一个任务拆解成更小的部分,在合适的时候调用工具,并一步一步综合结果得出答案。图 11.1 以流程图形式给出了 ReAct 模式的简化示意。
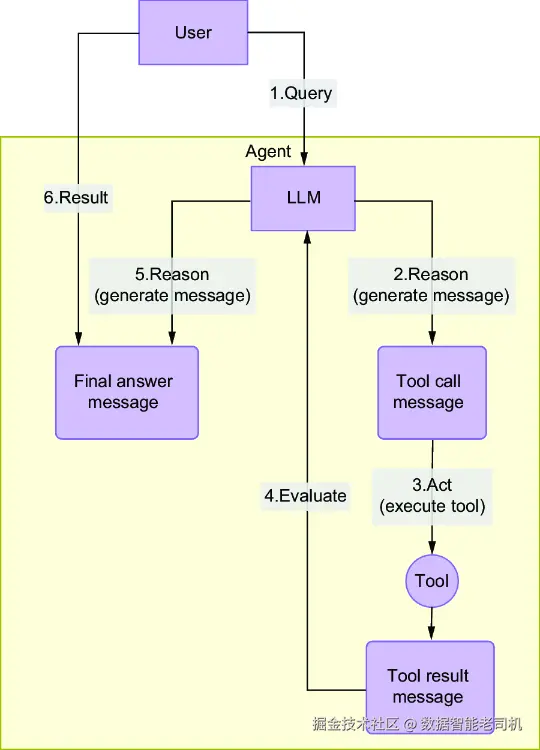
图 11.1 ReAct 模式在推理与行动之间交替进行,使智能体能够处理用户问题:先思考、再根据需要调用工具、然后继续推理,最终给出答案。
如图所示,ReAct 模式从用户问题开始。智能体首先进入"推理"阶段,在这里 LLM 分析输入并决定下一步该怎么做。如果需要更多信息或额外操作,智能体就会进入"行动"阶段,调用一个或多个工具------例如执行语义搜索或调用外部 API。
一旦工具返回结果,智能体又会重新进入"推理"阶段,将新获得的信息纳入思考过程。这可能会触发进一步的工具调用,也可能使智能体判断出自己已经拥有足够上下文,可以直接回答。整个过程在智能体输出"最终答案"时结束。
这种在推理与行动之间来回切换的过程,正体现了 ReAct 模式的核心,也正是现代智能体能够动态组合思考与行动来解决用户问题的关键所在。
注意:随着 OpenAI Responses API 的推出,从函数调用向工具调用的迁移进一步加速。Responses API 专门为结构化工具使用而设计,在智能体应用场景中,已经在很大程度上取代了旧的 Completion API。
11.2.2 工具调用是如何与 LLM 协同工作的
OpenAI 的工具调用支持多种工具类型------包括用户自定义函数、代码解释器,以及像网页浏览这样的原生能力。从高层来看,当你向 LLM 注册一个工具时,你实际上是在暴露该函数的签名(函数名和参数)以及一段文本描述。模型随后会在运行时根据用户输入和当前对话上下文,决定什么时候使用哪个工具,以及如何使用它。
在 LangGraph 中,工具既可以通过基于类的方式注册,也可以通过装饰器方式注册。为了更清晰简洁,我们会使用装饰器方案。下面我们把语义搜索能力实现为一个使用 @tool 装饰的函数,使其可供智能体通过工具调用协议使用。
代码清单 11.3 使用 LangGraph 的属性式工具定义
python
@tool #1
def search_travel_info(query: str) -> str: #2
"""Search embedded Wikivoyage content for
information about destinations in England."""
docs = ti_retriever.invoke(query) #3
top = docs[:4] if isinstance(docs, list) else docs #3
return "\n---\n".join(
d.page_content for d in top) #4
#1 使用 @tool 装饰器定义工具
#2 定义工具函数:接收查询,执行语义搜索,并从向量存储返回字符串结果
#3 在向量存储上执行语义搜索,并返回前四条结果
#4 将前四条结果拼接成一个字符串这个被装饰的函数 search_travel_info() 现在已经被识别为一个工具:它接收用户查询,在向量存储中搜索相关的 Wikivoyage 内容,并把最多四条结果拼接成一个字符串返回。@tool 装饰器会确保这个函数的名称、描述以及参数模式都能暴露给 LLM,用于工具调用。
11.2.3 向 LLM 注册工具
为了让智能体能够使用我们的语义搜索工具,我们必须将它注册到 LLM 中,这样模型才会知道这个函数的签名以及它的用途。在 LangChain 中,这一过程是通过 bind_tools 协议完成的;不过,先看看它在 OpenAI API 层面是如何工作的,会更有助于理解。
随着 OpenAI Responses API 的推出,工具和函数的注册方式变得更加标准化,也更明确。你现在需要提供一个结构化的工具定义,其中包含工具名称、描述以及参数模式。之后,模型就可以在响应中明确请求工具调用,并在需要时传入参数。更多细节可以参考 OpenAI 的函数调用文档(mng.bz/Bzag)。
示例:使用 OpenAI API 手动注册工具
假设你想把我们的 search_travel_info 函数直接暴露给 OpenAI API(而不借助 LangChain),那么你需要像下面这样定义这个工具的模式。请注意,这个例子仅用于说明原理,并不包含在本书配套源码中。
代码清单 11.4 使用 OpenAI API 手动注册工具
makefile
search_travel_info_tool = {
"type": "function", #1
"function": {
"name": "search_travel_info", #2
"description": "Search embedded Wikivoyage content for information about destinations in England.", #3
"parameters": { #4
"type": "object", #5
"properties": {
"query": { #6
"type": "string",
"description": "A natural language query about a destination in England." #7
}
},
"required": ["query"] #8
}
}
}
response = client.chat.completions.create(
model="gpt-5", #9
messages=[
{"role": "user", "content": "Tell me about surfing in Cornwall."} #10
],
tools=[search_travel_info_tool], #11
tool_choice="auto", #12
)
#1 指定该对象是一个函数工具(符合 OpenAI 的工具调用模式)
#2 被注册的工具/函数名称
#3 对工具功能的人类可读描述
#4 这个字典描述函数接受的参数
#5 参数以对象形式传递(即具名参数字典)
#6 函数接受一个名为 "query" 的参数
#7 对 "query" 参数内容的描述
#8 "query" 是该工具的必需参数
#9 指定用于补全的 OpenAI 模型
#10 提供初始用户消息(要回答的问题)
#11 注册工具,使模型知道它在需要时可以调用它
#12 允许模型自动决定是否以及何时使用该工具在这个例子中,你显式定义了工具的元数据和参数,然后通过 API 调用中的 tools 参数传给模型。当模型判断自己需要调用 search_travel_info 时,它会在响应中返回一个结构化的工具调用请求。接下来,就需要由你的应用真正去执行这个 Python 函数,把模型生成的参数传进去;如果对话还要继续,就再把函数的返回结果发送回 LLM。
在 LangChain 中注册工具
LangChain 会把这一整套流程自动化。你只需要把工具定义成一个带装饰器的 Python 函数(就像前面的代码清单 11.3 那样),然后把它注册到 LLM 上即可。下面的代码展示了这一过程。
代码清单 11.5 在 LangChain 中注册工具
ini
TOOLS = [search_travel_info] #1
llm_model = ChatOpenAI(
model="gpt-5-mini", #2
use_responses_api=True) #2
llm_with_tools = llm_model.bind_tools(TOOLS) #3
#1 定义工具列表(本例中只有一个工具)
#2 实例化 LLM 模型,使用 GPT-5-mini,并启用 Responses API
#3 将工具绑定到 LLM 模型上,使其能够生成包含工具调用的响应这里,我们先列出可用工具(目前只有 search_travel_info),实例化 gpt-5-mini 聊天模型(启用 Responses API),然后通过 .bind_tools(TOOLS) 将这些工具暴露给模型,以供其进行工具调用。
LangChain 会自动处理 Python 代码与 OpenAI 函数/工具调用协议之间的转换,包括根据你的函数签名和 docstring 自动生成相应的 JSON Schema。这样一来,每当模型接收到用户消息时,它就能自主决定是否、以及何时调用任何已注册工具,并按照工具调用协议组织自己的响应。
注意:如果你使用的并不是 OpenAI 模型,或者你不想使用 Responses API,工具调用通常仍然是可以工作的------只是不同模型在能力和响应结构上可能会有所不同。旧的 Completion API 依然可用,但对于大多数智能体应用场景而言,更新的 Responses API 在清晰性、能力以及与当前最佳实践的一致性方面都更值得推荐。
11.2.4 智能体状态:跟踪对话
在我们的实现中,智能体的状态非常简单:它只是一个 LLM 消息集合,用于跟踪整个对话过程。定义如下:
kotlin
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]这里,AgentState 只包含一项:消息序列,它记录了用户、智能体以及工具响应之间的所有消息往来。这使得整个设计保持了简洁。
11.2.5 执行工具调用
工具执行逻辑的核心,是一个节点:它会检查 LLM 最近一次返回的消息,从中提取模型请求的所有工具调用,然后用提供的参数执行相应的函数。每个工具的输出随后都会被包装成一条消息,并附加到对话状态中。下面给出一个简化版本的实现。
代码清单 11.6 从零实现工具执行
ini
class ToolsExecutionNode: #1
"""Execute tools requested by the LLM in the last AIMessage."""
def __init__(self, tools: Sequence): #2
self._tools_by_name = {t.name: t for t in tools}
def __call__(self, state: dict): #3
messages: Sequence[BaseMessage] = state.get("messages", [])
last_msg = messages[-1] #4
tool_messages: list[ToolMessage] = [] #5
tool_calls = getattr(last_msg, "tool_calls", []) #6
for tool_call in tool_calls: #7
tool_name = tool_call["name"] #8
tool_args = tool_call["args"] #9
tool = self._tools_by_name[tool_name] #10
result = tool.invoke(tool_args) #11
tool_messages.append(
ToolMessage(
content=json.dumps(result), #12
name=tool_name,
tool_call_id=tool_call["id"],
)
)
return {"messages": tool_messages} #13
tools_execution_node = ToolsExecutionNode(TOOLS) #14
#1 定义工具执行节点
#2 使用工具列表初始化工具执行节点
#3 定义 __call__ 方法,当该节点被调用时执行
#4 获取消息列表中的最后一条消息
#5 初始化工具消息列表,用于收集工具调用结果
#6 从最后一条消息中获取工具调用
#7 遍历这些工具调用
#8 获取工具调用中的工具名称
#9 获取工具调用中的参数
#10 从工具列表中取出相应工具
#11 用参数调用该工具
#12 把工具结果加入工具消息列表
#13 返回工具消息列表,其中包含所有工具调用结果
#14 实例化工具执行节点,供 LangGraph 图中的节点使用这种模式允许智能体在一个步骤中处理多个工具调用。ToolsExecutionNode 会检查 LLM 最新的响应,按名称调用每个请求的工具,收集执行结果,并把这些结果格式化成后续对话步骤可以使用的消息。在一个典型的智能体工作流中,这些工具结果会再被传回 LLM,由它融合这些新信息,继续推理,或者直接生成最终答案回复用户。
内置的 ToolNode 类
实际上,在真实项目里你通常不需要自己手写这些逻辑,因为 LangGraph 已经提供了一个内置类 ToolNode,它执行的就是与我们自定义 ToolsExecutionNode 相同的工作。对于大多数应用场景,你完全可以直接写:
ini
tools_execution_node = ToolNode(TOOLS)这样就不必手工实现工具执行逻辑,从而大大简化智能体开发过程。
现在你已经明白工具执行是如何管理的,接下来我们来看一下:由 LLM 驱动的智能体,是如何决定应该调用哪些工具,或者判断自己是否已经拥有足够信息来生成最终答案的。
11.2.6 LLM 节点:协调推理与行动
接下来,我们将一个 LLM 节点加入到 LangGraph 工作流中,如下所示。
代码清单 11.7 LLM 节点
python
def llm_node(state: AgentState): #1
"""LLM node that decides whether
to call the search tool."""
current_messages = state["messages"] #2
response_message = llm_with_tools.invoke(
current_messages) #3
return {"messages": [response_message]} #4
#1 定义 LLM 节点
#2 从智能体状态中获取当前消息
#3 使用当前消息调用 LLM 模型。LLM 会自行决定是调用搜索工具,还是直接返回答案。
#4 返回响应消息,其中包含工具调用或最终答案这个节点会接收智能体状态(也就是消息列表),并把它们转发给 LLM 处理。由于我们使用的是一个启用了工具调用能力的 LLM(llm_with_tools),模型会自动知道什么时候应该发出工具调用请求,什么时候应该直接生成最终答案:
- 如果最后一条消息是用户问题,LLM 可以决定是否请求一个或多个工具调用,以检索相关信息。
- 如果最后一条或最后几条消息是工具执行结果,LLM 会将这些结果纳入自身推理过程,并进一步决定:要么生成最终答案,要么继续请求更多工具调用。
模型最终返回的可能是两类消息之一:
一种是 AIMessage,其 content 字段中直接包含最终答案;另一种则是在 tool_calls 字段中包含额外工具调用请求------具体取决于当前场景。
这种灵活的、反应式的循环机制,正是所有现代智能体实现的核心所在,也是今天的 LLM 智能体之所以如此强大的原因。
11.3 组装智能体图
现在,我们已经准备好了 LLM 节点和工具执行节点,下一步就是把它们组装成一个真正可运行的智能体图。在 LangGraph 中,智能体是以有向图的形式组织的:每个节点表示一个组件(例如 LLM 或工具执行器),而边则表示这些节点之间数据与控制流可能如何流动。
代码清单 11.8 展示了如何把我们的单工具旅行信息智能体组装成一个图。图中的每个节点都对应于 LLM 或工具执行逻辑中的一个。
代码清单 11.8 基于工具的智能体图
makefile
builder = StateGraph(AgentState) #1
builder.add_node("llm_node", llm_node) #2
builder.add_node("tools", tools_execution_node) #2
builder.add_conditional_edges("llm_node",
tools_condition) #3
builder.add_edge("tools", "llm_node") #4
builder.set_entry_point("llm_node") #5
travel_info_agent = builder.compile() #6
#1 定义图构建器
#2 把 LLM 节点和工具节点加入图中
#3 给图添加条件边,用于决定是执行工具调用,还是返回答案并结束图执行
#4 添加从工具节点到 LLM 节点的边
#5 将入口点设置为 LLM 节点
#6 编译图11.4 理解智能体图的结构
如图 11.2 所示,我们的智能体图由两个主要节点构成:LLM 节点负责推理与生成工具调用,而 tools 节点负责执行被请求的工具并返回结果。对话流程会在这两个节点之间交替流转,这正是本章前面介绍的 ReAct 模式的具体体现。
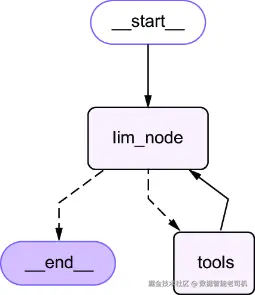
图 11.2 条件图逻辑会先把每个用户查询路由到 LLM 节点,然后再根据是否需要工具调用,动态决定是流向 tools 节点,还是直接结束流程。
这个结构中最关键的部分,是将 LLM 节点连接到后续步骤的条件边。这个条件边由 tools_condition 函数控制------它是 LangGraph 中的一个预构建工具函数。该函数会检查 LLM 最近返回的消息:
- 如果消息中包含
tool_calls属性(也就是说,LLM 正在请求一个或多个工具调用),那么图的执行流就会被路由到名为"tools"的节点。 - 如果没有检测到工具调用,那么流程就会被引导到
END节点,从而终止图执行,并向用户输出最终答案。
这一机制让智能体能够在每一个回合中动态决定:是继续推理、执行行动,还是结束本轮交互。
我们显式地将图的入口点设置为 "llm_node",确保每一个用户问题都首先由语言模型处理。(作为替代,你也可以通过 graph_builder.add_edge(START, "llm_node"),从 START 节点连一条边到 "llm_node",效果是一样的。)通过调用 builder.compile() 来编译这个图,我们就完成了旅行信息智能体的构建,它已经可以接收问题,并智能地使用自己的工具来查找相关旅行信息。
11.5 运行智能体聊天机器人:Read-Eval-Print Loop
构建智能体驱动聊天机器人的最后一步,就是实现用户界面------一个简单的循环,不断接收用户问题并返回答案,直到用户选择退出。这个经典模式称为 Read-Eval-Print Loop(REPL,读取-求值-打印循环),它是用户与旅行信息智能体之间最直接的桥梁。
从高层来看,这个聊天循环会监听输入、把用户问题包装成消息结构、调用智能体图,然后打印出助手回复。整个过程会持续不断地进行,从而形成真正的对话体验。下面这段代码展示了如何用 Python 实现这个聊天循环。
代码清单 11.9 聊天机器人 REPL
python
def chat_loop(): #1
print("UK Travel Assistant (type 'exit' to quit)")
while True:
user_input = input(
"You: ").strip()
if user_input.lower() in \
{"exit", "quit"}: #3
break
state = {"messages":
[HumanMessage(content=user_input)]} #4
result = travel_info_agent.invoke(
state) #5
response_msg = result["messages"][-1] #6
print(
f"Assistant: {response_msg.content}\n") #7
if __name__ == "__main__":
chat_loop()
#1 定义聊天循环
#2 获取用户输入
#3 如果用户输入是 "exit" 或 "quit",则退出循环
#4 创建初始状态,其中包含一条带有用户输入的 HumanMessage
#5 使用初始状态调用图
#6 从结果中获取最后一条消息,该消息包含最终答案
#7 打印上一条消息 content 中的助手最终答案这个循环会先欢迎用户,然后等待用户输入问题,并持续处理,直到用户输入 exit 或 quit。每次输入都会被包装成一个 HumanMessage,并传给你刚刚构建好的旅行信息智能体。智能体的回复会从图执行结果中提取出来,再显示给用户。
至此,你已经准备好运行自己的第一个智能体聊天机器人了。现在就可以试着向它询问康沃尔的目的地或活动,亲身体验它是如何在这个框架中完成推理、信息检索与对话回应的。接下来我们就来看看它实际运行时的表现。
11.6 执行一次请求
现在,旅行信息智能体已经构建完成,接下来我们通过运行和调试实现代码,一步步观察智能体是如何工作的。这种动手式的演练能帮助你真正看到 LangGraph 框架在执行过程中,如何协调 LLM 与工具之间的流转。
11.6.1 逐步调试
首先,打开你的 main_01_01.py 文件,并使用你之前在 launch.json 中配置好的 Python 调试配置,以调试模式运行它。为了跟踪智能体的执行流程,请在下列函数的开头设置断点:
search_travel_info()ToolsExecutionNode.__call__()llm_node()
准备好了吗?按下 F5(或点击 IDE 中的播放图标),让我们一起走一遍智能体的工作流。
向量存储创建
启动脚本后,你会看到向量存储被创建并填充了旅行信息。在调试控制台中,你会看到类似图 11.3 的输出。

图 11.3 启动时、向量存储创建阶段的输出
聊天循环启动
接着,聊天循环会启动,并等待你的输入:
bash
UK Travel Assistant (type 'exit' to quit)
You:输入你的问题,然后按 Enter:
vbnet
You: Suggest three towns with a nice beach in CornwallLLM 节点激活
此时,你在 llm_node() 中设置的断点会被触发。检查 state["messages"]:
ini
HumanMessage(content='Suggest three towns with a nice beach in Cornwall', additional_kwargs={}, response_metadata={})继续单步执行(按 F10)到下一行,把这条消息发送给 LLM。由于 LLM 已经配置了工具调用能力,现在查看返回的 response_message:
ini
AIMessage(content=[],
...
tool_calls=[
{'name': 'search_travel_info', 'args': {'query': 'beach towns in Cornwall'}, 'id': 'call_L4PwmeyLkrkYX2PfC2gY6ri6', 'type': 'tool_call'},
{'name': 'search_travel_info', 'args': {'query': 'best beaches in Cornwall'}, 'id': 'call_XPNctNtyIKVetJa3ruM9z7d5', 'type': 'tool_call'},
{'name': 'search_travel_info', 'args': {'query': 'top seaside towns Cornwall'}, 'id': 'call_RAWMLwdFVALuIbJxWKfta5yp', 'type': 'tool_call'}],
...)这里,LLM 生成了三个工具调用------每个调用都使用了一个稍有不同的查询语句去调用你的语义搜索工具。注意,模型会主动改写这些查询,以尽可能扩大信息覆盖范围,这一点和第 9 章讨论的思路一致。也就是说,你不需要手工实现查询改写------LLM 会自己处理这件事。
工具执行节点
继续执行(按 F5)。工具调用列表会被加入消息列表中。条件边上的 tools_condition 检测到存在工具调用,因此将流程路由到 ToolsExecutionNode.__call__()。你设置在那里的断点此时会触发。
接着,查看 state["messages"]:
css
[HumanMessage(content='Suggest three towns with a nice beach in Cornwall', additional_kwargs={}, response_metadata={}),AIMessage(content=[], ... ,
tool_calls=[{'name': 'search_travel_info', 'args': {'query': 'beach towns in Cornwall'}, 'id': 'call_L4PwmeyLkrkYX2PfC2gY6ri6', 'type': 'tool_call'},{'name': 'search_travel_info', 'args': {'query': 'best beaches in Cornwall'}, 'id': 'call_XPNctNtyIKVetJa3ruM9z7d5', 'type': 'tool_call'},{'name': 'search_travel_info', 'args': {'query': 'top seaside towns Cornwall'}, 'id': 'call_RAWMLwdFVALuIbJxWKfta5yp', 'type': 'tool_call'}] , ...)
]最后一条消息(也就是来自 LLM 的那条)此时还没有 content 内容------因为模型尚未回答,它还需要更多信息;但其中已经包含了必须执行的工具调用。该节点会提取这些调用,然后依次遍历每一个请求,获取工具名与参数,并执行对应工具:
ini
result = tool.invoke(tool_args)你可以单步跟进去,观察 search_travel_info() 是如何被执行的。每一次语义搜索结果(即从向量存储中返回的文档)都会被收集成一个 ToolMessage,供下一轮 LLM 推理使用。
工具调用结果传回给 LLM
继续执行(按 F5),你会回到 llm_node()。此时,state["messages"] 中已经包含了用户原始问题、LLM 发出的工具调用指令,以及每个工具执行后的结果:
ini
[HumanMessage(content='Suggest three towns with a nice beach in
Cornwall', additional_kwargs={}, response_metadata={}),
AIMessage(content=[], ... ,
tool_calls=[{'name': 'search_travel_info', 'args': {'query': 'beach
towns in Cornwall'}, ...}, ...]),
ToolMessage(content='...', name='search_travel_info',
tool_call_id='call_L4PwmeyLkrkYX2PfC2gY6ri6'),
ToolMessage(content='...', name='search_travel_info',
tool_call_id='call_XPNctNtyIKVetJa3ruM9z7d5'),
ToolMessage(content='...', name='search_travel_info',
tool_call_id='call_RAWMLwdFVALuIbJxWKfta5yp')]每一条工具消息的内容,都会为 LLM 提供生成最终答案所需的事实信息。继续单步执行下面这一行:
ini
response_message = llm_with_tools.invoke(current_messages)然后查看 response_message:
vbnet
AIMessage(content=[{'type': 'text', 'text': "Three towns in Cornwall with nice beaches are:\n\n1. Newquay - Known as the UK's surfing capital with popular beaches like Fistral Beach.\n2. St Ives - A picturesque town with beautiful sandy beaches.\n3. Falmouth - Located on the south coast with beaches like Gyllyngvase beach.\n\nThese towns offer great beach experiences along with other attractions.", 'annotations': []}], ...)现在,content 字段已经有值了,里面就是 LLM 综合工具结果后生成的答案。而 tool_calls 字段已经消失------说明模型已经不再需要外部工具,而是完成了信息整合与回答生成。
完成这次请求
当执行离开 llm_node() 后,条件边上的 tools_condition 会再次检查是否还有新的工具调用。由于这次没有了,流程将直接结束。当主调用返回时:
ini
result = travel_info_agent.invoke(state)result.messages 列表的最后一条就是包含最终答案的 AIMessage:
css
{'messages': [
HumanMessage(content='Suggest three towns with a nice beach in Cornwall', ...),
AIMessage(content=[], tool_calls=[...]),
ToolMessage(...), ToolMessage(...), ToolMessage(...),
AIMessage(content=[{'type': 'text', 'text': "Three towns in Cornwall with nice beaches are:\n\n1. Newquay - Known as the UK's surfing capital with popular beaches like Fistral Beach.\n2. St Ives - A picturesque town with beautiful sandy beaches.\n3. Falmouth - Located on the south coast with beaches like Gyllyngvase beach.\n\nThese towns offer great beach experiences along with other attractions.", 'annotations': []}], ...)
]随后,聊天机器人会把答案显示给用户,并继续等待下一次输入:
vbnet
UK Travel Assistant (type 'exit' to quit)
You: Suggest three towns with a nice beach in Cornwall
Assistant: [{'type': 'text', 'text': "Three towns in Cornwall with nice beaches are:\n\n1. Newquay - Known as the UK's surfing capital with popular beaches like Fistral Beach.\n2. St Ives - A picturesque town with beautiful sandy beaches.\n3. Falmouth - Located on the south coast with beaches like Gyllyngvase beach.\n\nThese towns offer great beach experiences along with other attractions.", 'annotations': []}]
You:到这里,你已经逐步观察了智能体处理一次用户请求的全过程:理解问题、生成工具调用、执行工具、再综合结果形成最终答案。通过这种以调试驱动的方式走读执行流程,你能非常深入地理解 LangGraph 中智能体式推理与行动的机制。
11.7 扩展你的智能体:加入天气预报工具
到目前为止,我们的智能体已经可以通过对整理好的旅行内容进行语义搜索,来回答旅游相关问题。但现实中的旅行建议,往往还依赖一些动态、实时的信息------比如天气!在这一节中,你将学习如何通过加入第二个工具来扩展智能体能力,使它能够根据当前天气状况给出更贴合上下文的回答。
11.7.1 实现一个模拟天气服务
为了便于演示,先把你的 main_01_01.py 复制成一个新脚本,命名为 main_02_01.py。这样做有助于你清晰跟踪智能体能力的每一次演进。
首先,我们引入一个模拟天气服务(mock weather service)。这个服务会模拟任意城镇的实时天气数据,并返回天气状况(如晴天或下雨)以及温度。WeatherForecastService 的实现如下所示。
代码清单 11.10 WeatherForecastService
ini
class WeatherForecast(TypedDict):
town: str
weather: Literal["sunny", "foggy", "rainy", "windy"]
temperature: int
class WeatherForecastService:
_weather_options = ["sunny", "foggy", "rainy", "windy"]
_temp_min = 18
_temp_max = 31
@classmethod
def get_forecast(cls, town: str) \
-> Optional[WeatherForecast]: #1
weather = random.choice(cls._weather_options)
temperature = random.randint(cls._temp_min, cls._temp_max)
return WeatherForecast(town=town,
weather=weather,
temperature=temperature)
#1 定义 get_forecast 方法,它会返回一个 WeatherForecast 对象这个模拟服务会在几个天气选项中随机挑选一种天气状况,并在一个典型的康沃尔夏季温度区间内随机生成温度值。后面如果你愿意,也完全可以把它替换成一个真实的天气 API。
11.7.2 创建天气预报工具
有了这个模拟服务之后,下一步就是创建一个包装它的工具,让天气数据对智能体可用。下面展示了如何定义这个工具函数,并把它加入智能体的工具集中:
python
@tool
def weather_forecast(town: str) -> dict:
"""Get a mock weather forecast for a given town. Returns a
WeatherForecast object with weather and temperature."""
forecast = WeatherForecastService.get_forecast(town)
if forecast is None:
return {"error": f"No weather data available for '{town}'."}
return forecastweather_forecast 工具会为给定城镇提供一个模拟天气预报。当传入一个城镇名称时,它会返回一个字典,其中包含该地点的天气状况(如晴天、雾天、雨天或大风)以及温度。如果无法获取数据,则返回一条错误信息。借助这个工具,智能体就可以把模拟的实时天气信息纳入自己的回答之中。
11.7.3 更新智能体以支持多工具
最后,确保你的 LLM 模型已经设置为支持工具调用,并且能识别这两个可用工具:
ini
TOOLS = [search_travel_info, weather_forecast] #1
llm_model = ChatOpenAI(
model="gpt-5-mini", #2
use_responses_api=True #2
)
llm_with_tools = llm_model.bind_tools(TOOLS) #3
#1 定义工具列表(本例中为 search_travel_info 和 weather_forecast)
#2 实例化 LLM 模型,使用 GPT-5-mini,并启用 Responses API 进行工具调用
#3 将工具绑定到 LLM 模型,使其具备工具调用能力完成这一步之后,你的智能体就已经具备同时处理旅行问题和天气查询的能力了,也因此拥有了为用户提供更准确、更有用回答的基础。在接下来的小节中,你将看到如何引导 LLM 更有效地使用这两个工具,以及如何观察智能体实际展现出的新能力。这个过程不仅展示了如何扩展智能体的工具集,也说明了为什么基于 LangGraph 与 LangChain 的智能体系统能够采用模块化、渐进式的方式不断增强能力------这正是它们如此强大的原因所在。
11.8 执行多工具智能体
现在,天气预报工具已经注册完成,你的智能体已经可以综合旅行信息与实时天气条件来生成答案了。这种模块化方法最妙的一点在于:新增一个工具,并不需要改变智能体图本身的结构。所有编排工作都由 LLM 和工具调用协议来完成。
11.8.1 运行多工具智能体(初始行为)
让我们来实际测试一下新能力。像之前一样,先设置断点------尤其是在工具执行节点和 LLM 节点中,同时也在 weather_forecast() 开头加一个断点。然后以调试模式运行 main_02_01.py,并输入以下提示:
vbnet
You: Suggest two Cornwall beach towns with nice weather提交查询之后,第一个断点会在 llm_node() 中触发。单步执行到最后一行,然后检查 response_message.tool_calls 的值:
css
[{'name': 'weather_forecast', 'args': {'town': 'Newquay'}, 'id': 'call_3nIgMLIFgMZBvVvrTHbRh2lj', 'type': 'tool_call'}, {'name': 'weather_forecast', 'args': {'town': 'Falmouth'}, 'id': 'call_Qfv5ENGOXhEUUcAAEamDyoQU', 'type': 'tool_call'}]这里,LLM 只是简单地挑了两个它"知道"的城镇(Newquay 和 Falmouth),然后直接去查询它们的天气(你在实际运行时可能会得到不同的城镇组合),但它完全没有先去调用你的语义搜索工具。这种行为很典型:模型默认优先依赖自己的预训练知识,而不是使用你显式提供的工具------而这恰恰是我们希望避免的,因为那样不够可靠,也不够准确。
为什么会这样?因为 LLM 在根据自己的预训练知识行动,直接使用了它"已知"的康沃尔信息,而不是去查询你提供的最新数据源。
11.8.2 用系统指令改进 LLM 的工具使用行为
为了引导 LLM 倾向使用工具、而不是依赖自身幻觉式知识,让我们把它的说明信息和工具描述写得更清晰一些。先把脚本复制一份,命名为 main_02_02.py,然后更新工具定义,为每个工具补充描述:
python
@tool(description="""Search travel information
about destinations in England.""")
def search_travel_info(query: str) -> str:
...
@tool(description="Get the weather forecast, given a town name.")
def weather_forecast(town: str) -> dict:
...接着,在 llm_node() 中加入一个引导性的 SystemMessage:
ini
system_message = SystemMessage(content="""You are a helpful assistant
that can search travel information and get the weather forecast.
Only use the tools to find the information
you need (including town names).""")
current_messages.append(system_message)更新后的 llm_node() 函数如下。
代码清单 11.11 引导工具选择
python
def llm_node(state: AgentState): #1
"""LLM node that decides whether to call the search tool."""
current_messages = state["messages"] #2
system_message = SystemMessage(content="""You are a helpful assistant
that can search travel information and get the weather forecast.
Only use the tools to find the information
you need (including town names).""") #3
current_messages.append(system_message) #4
response_message = llm_with_tools.invoke(
current_messages) #5
return {"messages": [response_message]} #6
#1 定义 LLM 节点
#2 从智能体状态中获取当前消息
#3 向当前消息中添加 system message,用来设定助手的行为方式
#4 把 system message 追加到当前消息列表中
#5 使用当前消息调用 LLM 模型。LLM 会自行决定是调用搜索工具,还是返回答案。
#6 返回响应消息,其中包含工具调用或答案现在,重新以调试模式启动应用,并输入如下问题:
vbnet
You: Suggest two Cornwall beach towns with nice weather当第一次在 llm_node() 命中断点时,检查追加 system message 前后的 current_messages。然后再查看 response_message------这一次,你会看到如下工具调用:
arduino
{'name': 'search_travel_info', 'args': {'query': 'beach towns in Cornwall'}, 'id': 'call_rJrYwfFG4BwaUPWBaQeUrn7o', 'type': 'tool_call'}这意味着什么?意味着现在 LLM 已经被迫先使用你的语义搜索工具去寻找候选海滨城镇,而不会再直接从自己的"知识"中随意挑选。这能显著降低幻觉风险,并保证回答所依据的数据来自你的知识库。
继续单步执行代码(按 F5)。在你再次把 current_messages 提交给 LLM 之前,此时的消息内容大致会如下所示:
bash
[HumanMessage(content='Suggest 2 Cornwall beach towns with nice weather', additional_kwargs={}, response_metadata={}),
SystemMessage(content='You are a helpful assistant that can search travel information and get the weather forecast. Only use the tools to find the information you need (including town names).', additional_kwargs={}, response_metadata={}),
AIMessage(content=[], ..., tool_calls=[{'name': 'search_travel_info', 'args': {'query': 'beach towns in Cornwall'}, 'id': 'call_rJrYwfFG4BwaUPWBaQeUrn7o', 'type': 'tool_call'}], ...),
ToolMessage(content='"<p id=\"mwrg\">Cornwall, in particular Newquay, is the UK's <b id=\"mwrw\"><a rel=\"mw:WikiLink\" href=\"//en.wikivoyage.org/wiki/Surfing\" title=\"Surfing\" id=\"mwsA\">surfing</a></b> capital, with equipment hire and surf schools present on many of the county's beaches, and events like the UK championships or Boardmasters festival.</p>\n---\n...</section><section ...', name='search_travel_info', tool_call_id='call_rJrYwfFG4BwaUPWBaQeUrn7o'),
SystemMessage(content='You are a helpful assistant that can search travel information and get the weather forecast. Only use the tools to find the information you need (including town names).', additional_kwargs={}, response_metadata={})]从 ToolMessage 中,LLM 现在已经获得了来自向量存储的若干潜在海滨城镇候选信息。
接着,当你再次执行到 llm_node() 时,LLM 就会对其中两个城镇发起天气预报工具调用:
css
AIMessage(content=[], ..., tool_calls=[{'name': 'weather_forecast', 'args': {'town': 'Newquay'}, 'id': 'call_OoDb7UwfrWF8c79DrfK2w9mp', 'type': 'tool_call'}, {'name': 'weather_forecast', 'args': {'town': 'St Ives'}, 'id': 'call_4Q4IaMIU9qO6sgfp4ls2Lwxw', 'type': 'tool_call'}], ...)你实际运行时 LLM 选择的城镇可能会不同,但它们一定会来自你语义搜索工具返回的结果。
继续单步执行天气工具调用。你检查到的每个 ToolMessage 大致会是这样:
css
ToolMessage(content='{"town": "Newquay", "weather": "foggy", "temperature": 20}', name='weather_forecast', tool_call_id='...')
ToolMessage(content='{"town": "St Ives", "weather": "windy", "temperature": 22}', name='weather_forecast', tool_call_id='...')如果这些城镇的天气不够理想怎么办?那就继续执行到下一轮 LLM 响应,你会看到类似如下的内容:
ini
AIMessage(content=[], ...,
tool_calls=[
{'name': 'weather_forecast', 'args': {'town': 'Perranporth'}, 'id': 'call_LOqaMnreszfHb5vItFCapRSk', 'type': 'tool_call'},
{'name': 'weather_forecast', 'args': {'town': 'Falmouth'}, 'id': 'call_iaOeeYAIxK1lyShjwPdLWQ6b', 'type': 'tool_call'}], ...)这里,LLM 又去为另外两个城镇查询天气,很可能是因为前一批结果没有满足"nice weather"的要求。这个过程会一直持续,直到智能体找到两个天气状况合适的城镇。最后,在最终一轮工具调用之后,LLM 会生成一个综合的、基于事实的回答:
vbnet
AIMessage(content=[{'type': 'text', 'text': 'Two beach towns in Cornwall with nice weather currently are:\n\n1. Perranporth - The weather is sunny with a temperature of 31°C.\n2. Falmouth - The weather is windy but still warm with a temperature of 28°C.\n\nWould you like more information about these towns or other beach towns in Cornwall?', 'annotations': []}]从用户视角来看,显示效果会是:
vbnet
UK Travel Assistant (type 'exit' to quit)
You: Suggest two Cornwall beach towns with nice weather
Assistant: [{'type': 'text', 'text': 'Two beach towns in Cornwall with nice weather currently are:\n\n1. Perranporth - The weather is sunny with a temperature of 31°C.\n2. Falmouth - The weather is windy but still warm with a temperature of 28°C.\n\nWould you like more information about these towns or other beach towns in Cornwall?', 'annotations': []}]总的来说,通过改进工具描述并借助系统提示提供清晰指令,你可以引导 LLM 以多步、基于事实的工作流来串联工具使用------先搜索海滨城镇,再根据实时天气进行筛选。这样生成的答案就会既动态,又可靠。
练习:尝试把模拟天气工具替换成真实 API,例如使用 LangChain 的 OpenWeatherMap 集成。这样,你的智能体就真正具备实时能力了!
11.9 使用预构建组件实现快速开发
到目前为止,你已经从底层一步一步构建了一个智能体:自己搭建图结构、编排工具调用,并且在调试器里逐行观察了整个过程。现在,你已经对工具调用在底层是如何运作的有了扎实理解。
不过,在大多数生产环境场景中,你通常会希望减少样板代码,更快完成开发------同时在必要时仍然保有透明性和可观测性。LangGraph 提供了一些预构建的智能体组件,比如 ReAct agent,它们已经把大量编排逻辑封装好了。下面我们就来看看:切换到这种预构建方案之后,你的智能体实现会被简化到什么程度。
11.9.1 重构为使用 LangGraph ReAct 智能体
首先,把你上一版脚本(main_02_02.py)复制成一个新文件:main_03_01.py。这次重构不仅会去掉底层编排代码,还能确保你的智能体遵循一个已经被充分验证、专为可靠工具使用设计的交互模式。
导入 RemainingSteps 工具
在脚本顶部加入以下导入:
javascript
from langgraph.managed.is_last_step import RemainingSteps移除手动工具绑定
现在,你可以删除那一行把工具绑定到 LLM 上的代码:
ini
llm_with_tools = llm_model.bind_tools(TOOLS)预构建智能体会在内部帮你完成这件事。
更新 AgentState
修改 AgentState 的定义,加入一个 remaining_steps 字段。这个字段能让智能体以受控方式管理还剩多少轮工具调用:
kotlin
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], operator.add]
remaining_steps: RemainingSteps删除手工定义的节点与图构建逻辑
接下来就是最大的简化之处:删除你自定义的 ToolsExecutionNode 和 llm_node,以及所有显式的图连线代码。把它们全部替换为一行对 LangGraph 内置 ReAct 智能体的实例化:
ini
travel_info_agent = create_react_agent(
model=llm_model,
tools=TOOLS,
state_schema=AgentState,
prompt="""You are a helpful assistant that
can search travel information and get the weather forecast.
Only use the tools to find the information you need
(including town names).""")就这样!现在,由 ReAct agent 自动替你完成流程编排、工具调用与答案合成。
11.9.2 运行预构建智能体
当你运行 main_03_01.py,然后输入我们熟悉的测试问题:
vbnet
You: Suggest two Cornwall beach towns with nice weather
Assistant: [{'type': 'text', 'text': 'Two beach towns in Cornwall with nice weather are:\n\n1. St Ives - It has sunny weather with a temperature around 26°C.\n2. Newquay - It also enjoys sunny weather with a temperature around 22°C.\n\nBoth towns are popular for their beautiful beaches and pleasant weather.', 'annotations': []}]你会发现:答案依然是正确的、基于事实的,但代码却少了很多。
11.9.3 使用 LangSmith 进行观察与调试
切换到高级抽象之后,一个常见担忧是:可见性会不会降低?也就是说,你怎么知道智能体是否真的按照正确的推理步骤在执行?虽然你依然可以直接调试工具函数,但智能体内部的流程本身会变得不那么直接可见。这正是 LangSmith 发挥作用的地方。LangSmith 可以提供完整的追踪与执行分析,包括工具调用、LLM 推理过程,以及中间状态。
11.9.4 启用 LangSmith 追踪
要启用追踪,请在你的 .env 文件中加入以下内容:
ini
LANGSMITH_TRACING=true
LANGSMITH_ENDPOINT="https://api.smith.langchain.com"
LANGSMITH_API_KEY="<your-langsmith-api-key>"
LANGSMITH_PROJECT="langchain-in-action-react-agent"重新运行应用并提交一个问题之后,你可以登录 LangSmith(smith.langchain.com):
- 在左侧边栏的 Observability 菜单中选择 Tracing Projects。
- 在右侧面板里点击你的项目(
langchain-in-action-react-agent)。 - 打开最新的一条 trace。
你将看到完整的执行追踪,如图 11.4 所示。
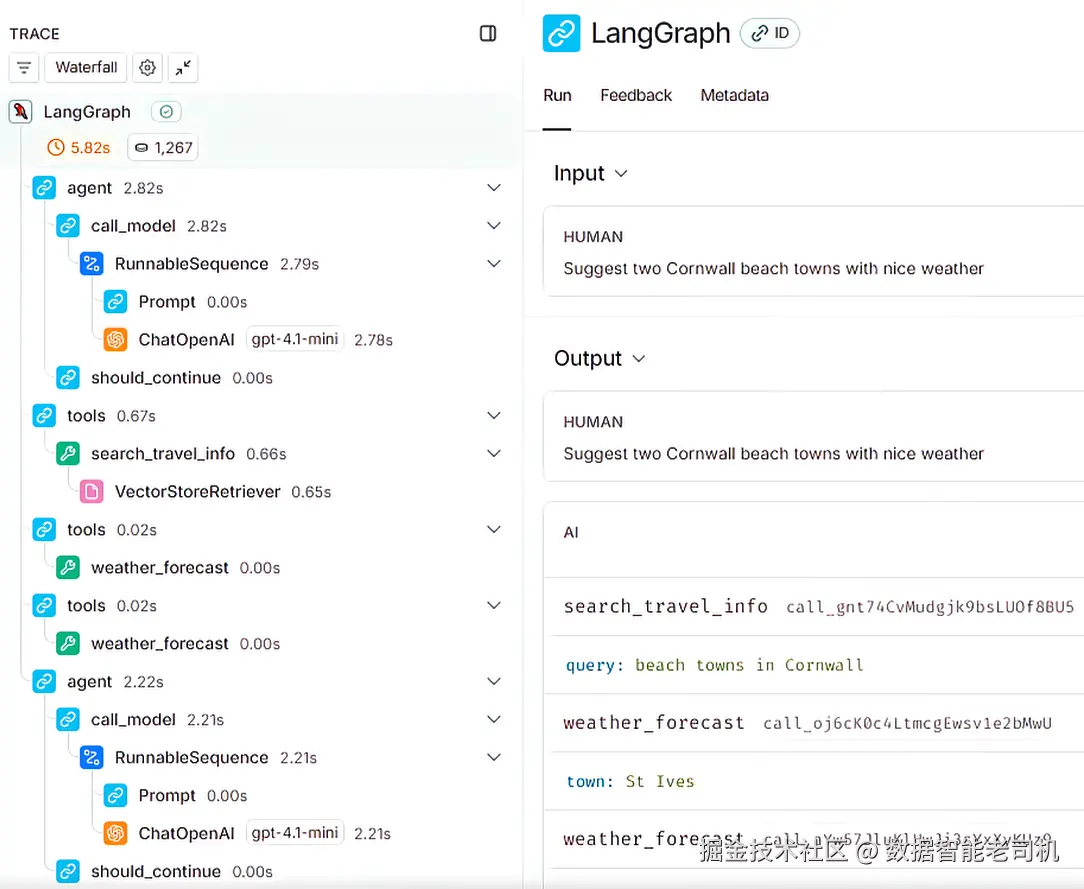
图 11.4 LangSmith 智能体执行追踪。该追踪可视化展示了智能体在回答"Suggest two Cornwall beach towns with nice weather"这一提示时的每一步工作流,包括 LLM 调用、工具调用以及消息流转。
LangSmith 的图形化 trace 会显示每一次工具调用、每一个 LLM 步骤以及消息流的整个过程。因此,即便你使用的是预构建智能体,依然可以审计、调试并准确理解智能体在每个阶段到底做了什么。
总结来说,把 LangGraph 的预构建智能体组件与 LangSmith 的可观测能力结合起来,你就可以快速构建稳健、适合生产环境的智能体应用------同时在需要时仍然保持完全的透明性与控制能力。这种工作方式,已经成为今天许多现实世界 AI 智能体系统的基础。
小结
- LangGraph 可以通过两种方式构建智能体:一种是基于节点的架构(显式图结构,使用硬编码条件路由);另一种是 ReAct 智能体(内置"推理-行动"循环,自动进行工具选择)。
- 工具注册是指用带类型提示和 docstring 的 Python 函数来定义工具,LLM 可以发现并调用它们。docstring 会成为工具描述,用于引导 LLM 进行工具选择。
- LLM 会读取工具描述,并根据用户问题决定调用哪个工具。因此,工具描述要写得清晰、具体,说明何时使用该工具,以及它期望什么输入。
- 状态检查可以揭示:LLM 选择了哪个工具、传递了什么参数、工具返回了什么结果,以及智能体如何利用这些结果继续执行或结束流程。这对调试和优化非常有帮助。
- 工具描述应明确写出输入参数、预期输出以及适用场景。例如:
search_customer(name: str) -> dict: Finds customer records by name. Use when user asks about specific customer details. - 多工具工作流会在多个工具之间串联输出,而这整个顺序由 LLM 自动编排。例如:
search_customer → get_orders → calculate_total会根据用户请求自动发生。 - 这个调用顺序不需要硬编码逻辑。只要提供清晰的工具描述,并通过测试验证结果,你就可以让 LLM 自主完成工具链路编排。
- LangGraph 中的 ReAct agent 提供了内置的工具调用、错误管理与重试逻辑。与手工构建带条件边的图相比,它能显著简化智能体创建过程。
- LangSmith trace 会捕获完整执行流。它会展示 LLM 的推理步骤、工具选择决策、中间输出以及最终响应,并以可视化时间线形式呈现。
- 每一条 trace 还包括 token 数量、延迟以及错误状态,便于调试失败的智能体运行过程。
- 基于工具调用的智能体,是多智能体系统的基础。不同专长的智能体(如 researcher、writer、reviewer)可以拥有各自不同的工具集,再由 supervisor agent 统一协调。
- 工具函数在可能的情况下,最好返回结构化数据(字典、列表),而不是字符串。结构化返回更方便 LLM 提取具体字段,而不需要去解析非结构化文本。
- 工具选择效果高度依赖工具描述质量。应通过样例查询反复测试,看智能体是否选择了正确工具;如果选择错误,就要回头修改描述。
- 在工具中实现自定义错误处理时,建议用
try-except包装工具逻辑,并返回结构化错误消息,例如:{"error": "Customer not found", "details": "..."}。