在 Kubernetes 上运行 LLM 时,最根本的挑战之一,就是如何管理体量巨大的模型数据。LLM 的大小从几 GB 到接近 1 TB 不等,而要高效地把这些数据引入集群、并让运行时能够访问它们,就必须进行审慎设计。
这些模型的主体部分是模型参数,而这部分数据通常极其庞大。表 2-1 列出了一些较为知名、且可以自行运行的模型的参数规模与大小。实际上,可选模型远不止这些,但仅从这组样本中,你已经能看到非常大的差异范围:有些大型模型几乎不适合按需使用,而另一些更轻量的模型则可以在你自己的集群中运行,并且需要时也能较轻松地下载。
表 2-1. 开源模型及其大小
| 名称 | 厂商 | 参数量 | 大小 |
|---|---|---|---|
| Llama 4 Maverick | Meta | 4000 亿(MoE,活跃参数 170 亿) | ~800 GB |
| DeepSeek-V3 | DeepSeek | 6710 亿(MoE,活跃参数 370 亿) | ~700 GB |
| Llama 3.1 405B | Meta | 4050 亿 | ~750 GB |
| Qwen3-235B | Alibaba | 2350 亿(MoE,活跃参数 220 亿) | ~118 GB |
| Mixtral 8x22B | Mistral | 1410 亿(MoE,活跃参数 390 亿) | ~88 GB |
| GPT-OSS 120B | OpenAI | 1170 亿(MoE,活跃参数 50 亿) | ~70 GB |
| Gemma 2 27B | 270 亿 | ~54 GB | |
| Granite 13B | IBM | 130 亿 | ~26 GB |
| Falcon 2 11B | TII | 110 亿 | ~22 GB |
| Mistral 7B | Mistral | 70 亿 | ~14 GB |
即便是更小的模型,对于 Kubernetes 管理员来说,在集群内高效地管理它们也仍然会带来显著挑战。要成功运行 LLM,关键在于理解如何有效地存储并组织这些大型数据集。
本章将探讨如何在 Kubernetes 集群中高效管理这些数据量巨大的制品。大多数时候,机器学习模型都可以被视作黑盒,由第 1 章介绍的推理服务进行访问。不过,理解这些模型在分发时所使用的打包格式,依然对成功集成非常有价值。下一节将概述最重要的几种 LLM 存储格式。
运行 LLM 的另一个关键方面,是弄清楚去哪里找到模型数据,以及如何获取模型数据。我们将在"模型注册表"一节中讨论模型注册表的概念,它为模型发现与访问提供了一种实用方案。
最后,模型必须被下载到集群中,才能真正被使用。"在 Kubernetes 中访问模型数据"将介绍 Kubernetes 原生方式下高效获取并访问模型数据的方法。
带着这张路线图,我们先从考察 LLM 数据是如何被打包和存储的开始。
模型数据存储格式
在处理 LLM 时,我们首先注意到的就是它们惊人的体量,通常以"十亿级参数"来衡量。但像 Hugging Face 这样的平台上共享的模型,包含的并不仅仅是原始权重参数。这些被分发的模型通常还包含元数据,在某些情况下,还包含模型架构本身,也就是神经网络各层与 Transformer 模块是如何连接起来的定义。
对于运维人员来说,这类分发出来的模型往往像黑盒一样存在。但理解它们被存储为何种格式仍然非常关键,因为并不是每一种打包后的模型都能在每一种运行时上运行,正如第 1 章所述。有些格式非常灵活,可以被多个运行时支持;而另一些格式则与特定运行时平台深度绑定。
从高层来看,模型存储格式可以分成两类:
仅权重格式
这类格式只存储神经网络学到的参数,也就是权重和偏置。它不包含模型架构、超参数和元数据,因此运行时必须事先知道如何重建网络结构,然后再把这些权重应用上去。
自包含格式
自包含格式会同时存储权重与模型架构,以及超参数和其他元数据。它们允许模型在不预先了解网络结构的情况下被加载并运行,因此作为独立制品部署时会更加方便。
这两类之间的边界并不是绝对清晰的,而是渐进的。有些看起来像自包含的格式,仍然可能依赖外部组件,例如语言模型所需的 tokenizer 文件。
对于 LLM 来说,趋势正在向 GGUF 和 Safetensors 这样的"基本自包含"格式发展。这些格式简化了分发过程,但仍然与专门的运行时紧密耦合。真正意义上的运行时独立性------即一个模型不管最初基于什么训练框架,只要环境兼容,就能在任意运行时中加载并运行------目前仍在推进中。"CNCF ModelPack 规范"中介绍的 CNCF ModelPack,就是朝着这个方向标准化的一次尝试。在这种思路下,模型数据被打包进 Open Container Initiative(OCI)容器镜像中(见"什么是 OCI?")。
理想情况下,就像 OCI 容器镜像抽象了应用内部细节一样,模型存储格式也应当在模型数据(由数据科学家产出)与模型执行(由生产环境中的 MLOps/DevOps 工程师管理)之间划出清晰边界。然而,当前生态更重视的是让模型尽快可运行,而不是优先统一运行时兼容性。随着这个领域逐渐成熟,我们预计模型创建与部署之间会出现更明确的分离。
仅权重格式
仅权重模型格式只存储训练后神经网络的数值参数(权重和偏置),而不包含模型架构或预处理组件。这类格式在开发与实验阶段非常常见,因为此时灵活性和最低开销往往更重要。
由于仅权重格式缺少架构信息,运行时必须事先知道网络结构。只有这样,运行时才能正确重建模型,并应用存储下来的权重。因此,仅权重格式与各自对应的机器学习框架紧密耦合。
最常用的仅权重格式,主要对应当前两大主流机器学习框架:PyTorch 与 TensorFlow。虽然两个框架都有自己的序列化格式,但 PyTorch 已经成为 LLM 开发的事实标准(更多细节见第 6 章)。一些用于 LLM 和其他 AI 模型的常见仅权重格式包括:
PyTorch State Dict(.pt, .pth)
PyTorch 原生的权重张量序列化格式,使用的是 torch.nn.Module 的 state_dict 方法。在开发和微调阶段,它被广泛用于 Llama、GPT、BLOOM 等 LLM。
TensorFlow checkpoints(.ckpt)
TensorFlow 生态中主要用于存储模型权重的一种格式。它曾广泛用于 BERT 等模型,但随着使用自有格式的 PyTorch 在生成式 AI 领域占据主导地位,这种格式在现代 LLM 中的重要性已经下降。
NumPy arrays(.npy, .npz)
NumPy 原生的数值数组序列化格式。它在存储较小模型或单独权重矩阵时仍然有用,但缺乏现代 LLM 部署所需的结构和元数据。
这些格式主要存储原始张量数据,只包含极少量元数据,因此非常紧凑,但也依赖外部运行时代码。
如图 2-1 所示,以仅权重格式存储的模型,在推理时需要重建出相同的网络架构。你必须在推理环境中手动复刻训练时的架构,以确保训练和推理两端都能正确解释这些存储的权重张量。
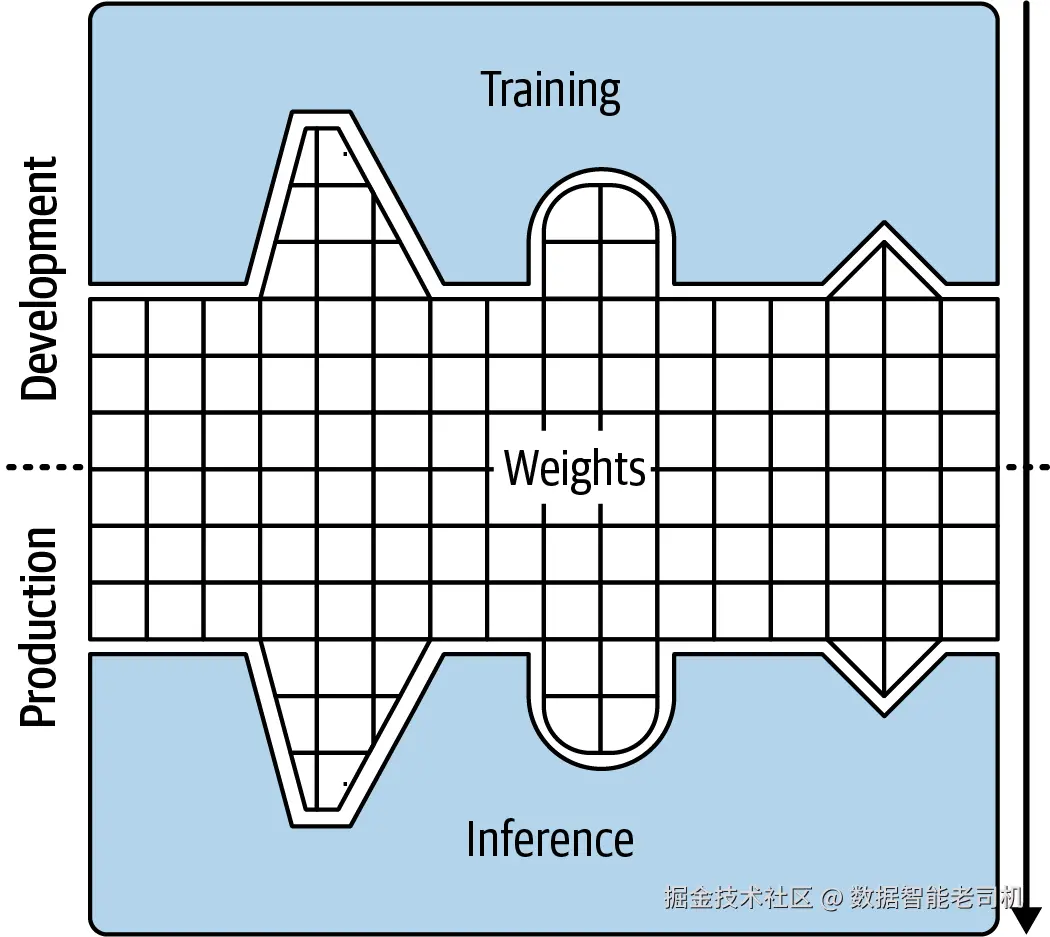
图 2-1. 以仅权重格式存储的模型示例
虽然仅权重存储格式非常适合开发与实验阶段,但它与用于评估这些参数的机器学习代码耦合得非常紧。
自包含格式
对于生产部署来说,更合适的是以自包含格式存储和分发的模型,因为它们打包的不只是原始权重。这类格式包含了关键元数据与结构信息,使模型更容易在多个运行时环境中共享和运行,而不需要依赖训练时所用的原始代码库。
自包含模型可以携带以下信息:
权重与偏置
神经网络的数值参数,构成了模型大小的主体部分。
模型架构
要么是对某个知名架构的引用,要么是以层连接图的形式显式描述。
Tokenizer 与词表数据
在语言模型中,这些数据通常用于在推理前对文本做预处理。
超参数
例如训练时使用的学习率、批大小、epoch 数等信息。
其他元数据
例如模型来源、作者信息以及其他有助于模型发现与可复现性的上下文描述。
一些自包含格式还支持预处理和后处理脚本,用于在推理前转换输入,并在推理后把输出变换成可用形式。
图 2-2 展示了一个以自包含格式存储的模型示意图,在这种情况下,所有组件都被打包在一起,使运行时不再依赖原始训练代码。
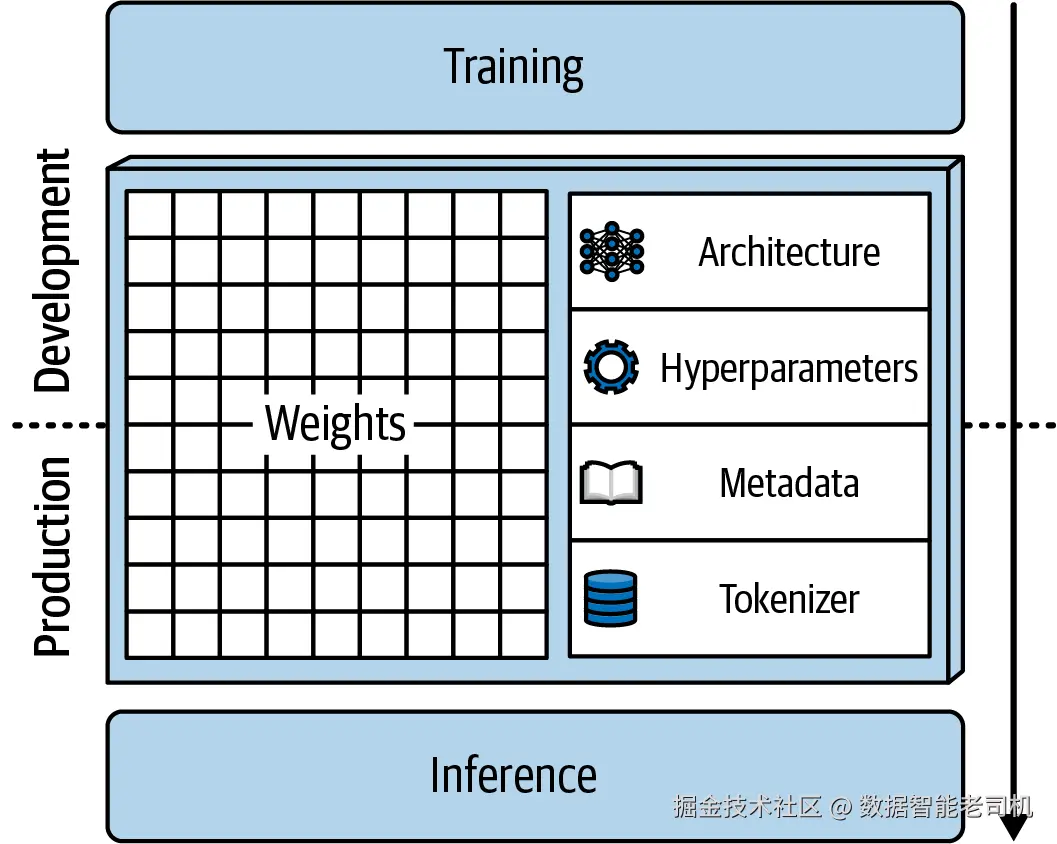
图 2-2. 自包含模型示例,其中运行时独立于训练代码
虽然完全自包含格式的目标,是把推理所需的一切都封装进去,但在 2026 年的现实中,这样的格式其实还不存在。今天并没有哪一种被广泛使用的格式,能够把推理所需的所有组件------模型权重、tokenizer、词表数据和完整架构------全部封装进单个制品中。因此,即便那些常被描述为"自包含"的格式,更准确地说也只是"基本自包含",因为它们仍然依赖外部组件和运行时依赖。
这类"基本自包含"格式可能会打包模型权重和部分元数据,但通常会缺少 tokenizer 或详细模型架构等关键部分,因此仍然依赖特定推理运行时或框架,去"理解"如何正确解释其中存储的数据。比如,常见的 Safetensors 和 GGUF(后文会详细介绍)虽然包含模型权重和一些元数据,但要完成完整的模型推理,仍需要额外的外部组件。
常见的"基本自包含"LLM 格式包括:
Safetensors(.safetensors)
一种强调安全与高效权重存储的"基本自包含"格式,在 Hugging Face 等平台上被广泛用于 LLM。与标准 PyTorch 权重文件相比,它在安全性与性能上都有提升,但 tokenizer 信息(如 tokenizer.json)以及模型架构定义并不会嵌入其中,因此仍需额外文件或运行时知识来完整重建模型。详见"Safetensors"。
GGUF/GGML(.gguf, .ggml)
为高效处理量化权重而优化的专用自包含格式,支持 CPU 与 GPU 执行。它们包含模型权重和基础架构元数据,但依然与 llama.cpp、vLLM 这类专门为高效处理量化结构而设计的运行时紧密耦合。GGUF 也可以存储 tokenizer 数据(如词表数据和特殊 token)。关于 GGUF 的更多内容,见"GGUF 与 GGML"。
ONNX(.onnx)
一种面向模型互操作的通用自包含格式。它通常被描述为自包含,因为它存储了模型权重、架构和元数据,但对于 LLM 来说,它缺少 tokenizer 和词表数据等关键组件,因此实际上也只是"基本自包含",需要额外文件才能完成完整语言模型推理。详见"ONNX"。
TensorFlow SavedModel
一种完全自包含、基于目录的格式,存储权重、架构和辅助文件。它在 TensorFlow 生态中很常见,但在现代 LLM 中很少使用。
Hugging Face Transformers
Hugging Face Transformers 格式更准确地说,是一种打包约定,而不是单独的模型格式。它将模型组织为一个目录,目录中包含运行语言模型所需的多个关键文件。这一约定通常包括:以 Safetensors(.safetensors)或 PyTorch state_dict(.bin)形式存储的模型权重,以及两个关键文件:tokenizer.json 和 config.json。这两个文件在确保模型能够处理输入数据、并在推理时应用正确架构方面起着核心作用。
TOKENIZER.JSON 与 CONFIG.JSON
tokenizer.json 和 config.json 是在 Hugging Face 生态及更广泛环境中高效运行 LLM 的关键组件。
tokenizer.json 存储了分词规则和词表映射,用于把原始文本转换成 token ID。它定义了输入文本如何被切分成 token,通常使用 Byte-Pair Encoding(BPE)等技术,并且包含用于 padding、序列起始和序列结束标记的特殊 token。
config.json 则描述模型架构和超参数,其中包含层数、注意力头数量、隐藏层维度、前馈层维度等信息。它通常还会指定模型类型(例如 llama),并影响运行时如何重建模型图。
这两个文件共同保证模型既能正确预处理输入(tokenizer.json),又能构建出所需网络结构(config.json)。没有它们,运行时既无法正确地对输入文本进行 tokenization,也无法在推理时加载正确的模型架构。
这些文件如今已经成为机器学习社区中的事实标准,其用途也早已超出 Hugging Face 自身生态。Hugging Face 之外的框架和工具,也经常采用这些约定,以实现模型互操作性和一致性。
正如我们已经看到的,当前大多数 LLM 模型格式都属于"基本自包含"这一类,它们经常省略 tokenizer、词表数据和预处理逻辑等关键组件。即便存在这些缺口,一些格式仍因在可移植性与效率之间取得平衡而获得了广泛采用。如今在 LLM 部署中最常见的是 Safetensors 和 GGUF/GGML,它们都针对高效权重存储和元数据支持进行了优化。
ONNX 虽然在 LLM 中使用得较少,但它作为一种更接近完全自包含的格式,仍然具有参考意义------只是要真正适用于 LLM,它仍需加入 tokenizer 定义等额外要素。接下来的几节中,我们将更详细地讨论 ONNX、Safetensors 和 GGUF/GGML。
追求真正的模型可移植性
接下来的三节会深入到具体模型格式的技术细节。虽然这些内容看起来似乎与 Kubernetes 运维关系不大,但它们实际上回应了一个根本性的运维问题:如何在模型数据与运行时执行之间建立清晰分离。
目标是实现真正的模型可移植性,也就是让模型像 Docker 彻底改变了任意软件负载跨环境部署那样,能够作为自包含制品被分发和执行。要实现这种层面的可移植性,就需要在模型文件结构和可执行它们的运行时两方面都达到更广泛的标准化。理想情况下,以标准化格式存储的模型,应该可以被任意兼容运行时加载。这将消除因 tokenization、量化或架构差异而产生的手工调整需求。这样的变化将赋能更丰富的工具与框架生态,减少对特定生态系统的绑定,并使模型分发像分发容器化应用那样顺畅。
这种分离,正是运维人员一直追求的圣杯:把模型视为可互换的制品,而不再受限于执行它们的运行时。我们距离这个理想还没真正达到,但通过考察现有格式,我们可以看到自己已经离"真正的运行时---模型独立"有多近了。
如果你对模型发现与分发的实际问题比格式内部原理更感兴趣,可以直接跳到"模型注册表"一节。
ONNX
Open Neural Network Exchange(ONNX)由 Microsoft 和 Facebook 于 2017 年共同开发,旨在提供一种与框架无关的机器学习模型表示格式。ONNX 的目标是统一模型在不同工具之间共享的方式,使开发者可以在一个框架中训练模型,再在另一个框架中部署,而无需依赖框架特定的转换。
ONNX 模型存储在单个 .onnx 文件中,并使用 Protocol Buffers(Protobuf)来实现紧凑性和平台中立性。每个文件包含三个主要组成部分。
第一,计算图定义了网络结构和数据流。
第二,学习得到的参数,包括权重和偏置。
第三,元数据描述输入/输出规范、算子集以及版本信息。
这种结构使 ONNX 成为一种很有希望的自包含格式示例,因为它把架构、权重和操作相关元数据都组合在一个单一制品中。
然而,ONNX 对 LLM 来说仍显不足,因为它缺少 tokenizer、词表数据和预处理逻辑等关键组件。对于自然语言生成这类任务来说,缺失这些信息意味着 .onnx 模型旁边必须额外提供其他文件。没有这些组件,仅靠 ONNX 模型本身无法把原始文本转换为 tokenized 输入,因此它并不适合现代 LLM 部署。这一缺口使它在语言模型语境下不能算是真正完全自包含。
ONNX 在 ONNX Runtime、TensorRT、OpenVINO 和 Triton Inference Server 等运行时中都得到广泛支持,因此具有很高的可移植性,但这种兼容性仍然取决于模型所使用的运算集合(例如矩阵乘法、卷积和注意力机制)。每个运行时都支持一个定义好的 operator set(op set),它规定了模型可使用的运算。如果模型依赖的运算超出了运行时支持范围,那么除非通过插件或自定义运行时扩展进行补充,否则模型可能无法加载。对于 LLM 这类复杂架构来说,这会进一步增加采用难度,因为 tokenization 和文本预处理本身就是模型功能不可分割的一部分。
尽管有这些局限,ONNX 仍为"完全自包含的 LLM 模型格式应该长什么样"提供了一个概念蓝图。如果它能扩展出更丰富的元数据,并原生支持 tokenizer 定义,那么它就可能为 LLM 场景提供更完整的解决方案。到 2026 年为止,ONNX 仍然更适用于计算机视觉等领域的模型,因为这些领域的预处理通常更简单,也不像语言模型那样与模型本体深度耦合。
接下来,我们来看 Safetensors。它是当前 LLM 部署中更常用的一种格式,提供了经过优化的权重处理能力,并包含一定程度的元数据支持。
Safetensors
Safetensors 由 Hugging Face 于 2021 年开发,是一种现代化的模型序列化格式,旨在安全地存储和共享机器学习模型权重,同时解决早期格式(例如 PyTorch 的 .pt 和 pickle)在安全性与性能上的问题。pickle 格式在 PyTorch 中很常见,但在反序列化模型时可以执行任意 Python 代码,因此在共享模型时会带来显著安全风险。相比之下,Safetensors 严格聚焦于张量数据存储,从根本上避免了代码执行漏洞,因此是一种更安全、更高效的模型序列化选择。
Safetensors 文件采用简单但高效的结构,如图 2-3 所示。
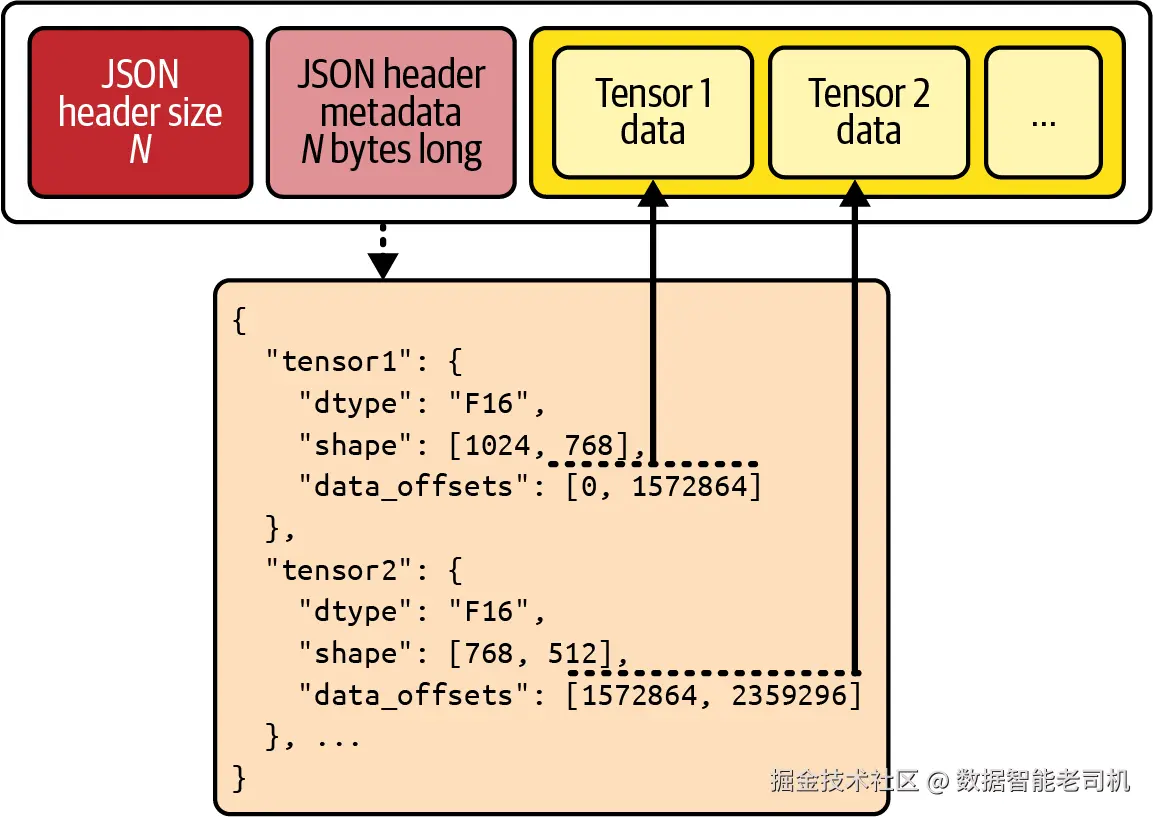
图 2-3. Safetensors 模型的内部结构
每个 .safetensors 文件都以一个 header 开始,其中包含元数据,包括一个序列化后的 JSON 对象,用于描述文件中存储的每个张量。这个 header 包含张量的数据类型、形状,以及张量数据在文件中的字节偏移位置等信息。
这种结构支持 zero-copy loading,也就是张量数据可以直接映射到内存中,而不需要额外的 CPU 拷贝开销,因此能提高推理速度,尤其适用于 LLM。
Safetensors 支持分片(sharding),允许将大型模型拆分成多个较小文件。每个分片包含模型张量的一部分,并配有一个索引文件(例如 model.safetensors.index.json)。这个索引文件把不同层中的张量名称映射到它们所在的分片文件中。
例如,Llama 4.1 405B 发布时包含 30 个 safetensor 文件,文件名类似 model-0000x-of-00030.safetensors,并带有一个 model.safetensors.index.json 文件,其内容类似示例 2-1。
示例 2-1. 将张量映射到分片文件的索引文件
json
{
"metadata": {
"total_size": 141107412992
},
"weight_map": {
"lm_head.weight": "model-00030-of-00030.safetensors",
"model.embed_tokens.weight": "model-00001-of-00030.safetensors",
"model.layers.0.input_layernorm.weight": "model-00001-of-00030.safetensors",
"model.layers.0.mlp.down_proj.weight": "model-00001-of-00030.safetensors",
"model.layers.0.mlp.gate_proj.weight": "model-00001-of-00030.safetensors",
"model.layers.0.mlp.up_proj.weight": "model-00001-of-00030.safetensors",
...
"model.layers.1.input_layernorm.weight": "model-00002-of-00030.safetensors",
"model.layers.1.mlp.down_proj.weight": "model-00002-of-00030.safetensors",
"model.layers.1.mlp.gate_proj.weight": "model-00001-of-00030.safetensors",
"model.layers.1.mlp.up_proj.weight": "model-00002-of-00030.safetensors",
...
}
}所有模型权重的总大小,以字节为单位(这个模型大约是 131 GB)。
将每个张量名称映射到保存它的具体分片文件。
示例映射表明,最终输出层的权重位于第 30 个分片文件中。
其他张量映射则展示了不同层如何分布在多个分片文件中。
分片对于超大模型尤其有用,因为单个文件可能会因存储限制而不切实际。这种方式也支持并行加载,因为不同分片可以被并发获取和处理。
尽管 Safetensors 在模型权重存储的安全性与性能上都做了改进,但它仍属于"基本自包含"格式,而不是"完全自包含"格式。它的主要局限在于:tokenizer 信息和模型架构定义并不会包含在 .safetensors 文件本身中。像 tokenizer.json 和 config.json 这样的关键文件,仍然需要在语言模型推理时单独提供。这也是为什么它仍然与 Hugging Face Transformers 生态紧密耦合,因为后者正好提供了这些额外元数据。
由于其结构清晰且强调安全序列化,Safetensors 越来越受欢迎,尤其适合用于 LLM 的存储与共享。如今,Safetensors 已成为 Hugging Face 上许多大模型的默认权重格式。
接下来,我们将讨论 GGUF,这是一种更专门面向 LLM 的格式,针对基于 CPU 的推理进行了优化,也特别适合高效部署 LLM。
GGUF 与 GGML
GPT-Generated Unified Format(GGUF)及其前身 GPT-Generated Model Language(GGML),是为在资源受限硬件(如 CPU 和边缘设备)上优化 LLM 的存储与执行而开发的专用格式。它们起源于 Georgi Gerganov 主导的 llama.cpp 项目,都聚焦于在最低硬件要求下实现高效推理。GGML 是早期重要的一步,而 GGUF 则代表了一次显著完善,解决了前者的许多限制。
GGUF 和 GGML 的一个决定性特征,是它们对量化的强调。量化是一种把模型权重从浮点数降低为更低位数表示(如 8 位、4 位,甚至 2 位整数)的技术。通过降低精度,模型的内存占用和计算开销都可以大幅减少。这使模型即便没有专用 GPU,也能在保持可接受推理精度的前提下有效运行。
GGUF 的一个关键改进点,是它对向后兼容性的重视。随着 LLM 不断演进、架构日益复杂,保持与现有工具的兼容变得越来越困难。GGUF 的模块化设计使得新模型只要核心组件不变,就能够继续与旧版本运行时兼容。这有助于避免每次模型更新时都频繁进行格式转换。向后兼容设计也减少了版本切换带来的冲击:即便 GGUF 为支持新特性而更新,已有模型仍可继续使用,而不需要重新转换。
与 ONNX 不同,后者是为广泛的机器学习任务设计的通用格式,而 GGUF 是专门为 LLM 推理打造的。它最初面向 CPU 推理,但如今已经被 llama.cpp 和 vLLM 等运行时广泛支持,可同时用于 CPU 和 GPU 执行。
与 Safetensors 相比,GGUF 试图将更多元数据直接打包进模型文件中,包括基础 tokenizer 信息和运行时元数据。Safetensors 主要专注于权重存储,元数据最小化,并依赖外部文件提供 tokenizer 定义与模型配置;而 GGUF 则把 token 映射和模型参数统一存储在一个文件中。但 GGUF 仍然依赖特定外部运行时来完成完整推理,因此它仍应归入"基本自包含"格式。
GGUF 文件采用结构化的二进制布局。它以魔数和版本字段开头,用于标识文件类型。随后是存储量化张量数据的区域,这些数据通过字节偏移方式组织,以便高效访问。元数据部分描述模型架构、量化类型和 token 映射。张量信息块则定义文件中每个张量的数据类型、形状和内存位置。
这种单文件设计对 Kubernetes 环境尤其有利,因为一致且相对自包含的制品更有利于编排与扩缩容。图 2-4 展示了 GGUF 文件的结构。

图 2-4. GGUF 文件的内部结构(来源:@mishig25, GGUF v3)
GGUF 代表了高效部署 LLM 的一次重要飞跃,尤其适合缺乏高端 GPU 的硬件环境。它对量化、自包含设计与向后兼容性的重视,解决了许多早期格式中的痛点。
当前状态与缺口
虽然 ONNX 作为通用机器学习模型的自包含格式很突出,而 GGUF 也为 LLM 提供了专门的、自包含程度较高的解决方案,但这两种格式都暴露出模型可移植性方面的重要缺口。ONNX 提供了结构化打包模型的方法,却缺少 LLM 所需的 tokenizer 等关键组件;GGUF 虽然包含基础 tokenizer 元数据,但仍与 llama.cpp 这样的特定运行时紧密绑定。
LLM 开发生态仍在快速演进。新的架构、优化技术与运行时改进层出不穷,而每一种都会引入新的专用配置,这会不断挑战"统一标准"这一目标。在这个领域真正成熟之前,像 GGUF 和 Safetensors 这样的"基本自包含"格式,仍然很可能是性能、兼容性与灵活性之间最现实的平衡点。真正的标准化,就像 OCI 在容器领域取得的成功一样,需要运行时能力与模型表示标准双双收敛,而这仍是一个尚需时日才能实现的里程碑。
虽然 GGUF 在 llama.cpp 生态中占主导地位,Safetensors 则正越来越多地被用于生产部署。它的多文件结构与 OCI 制品很契合,因为模型组件可以作为多个独立层进行分发,从而实现高效缓存和并行下载。
理解模型文件的结构与格式,有助于选择合适的工具和运行时,但归根结底,LLM 本质上只是一组文件------不管它们是完全集中在一个制品里,还是分散在多个制品中。要在 Kubernetes 环境中高效管理这些文件,就需要一种能够对其进行索引、发现和组织的机制,这正是下一节要讨论的模型注册表所扮演的角色。
模型注册表
模型注册表为管理模型、跟踪版本、实施治理以及存储机器学习制品的元数据,提供了一个中心化系统。它在机器学习生命周期中扮演关键角色,因为它连接了模型实验与生产部署这两个环节。作为模型发现机制与协作平台,模型注册表简化了模型在大规模环境中的跟踪、验证与部署方式。
与公共注册表不同,组织通常会将模型注册表作为集群内部服务部署。组织不会把这些注册表直接暴露到集群外部。注册表主要管理的是模型元数据,而不是直接存储实际模型权重或模型制品。相反,它们会引用外部对象存储(例如 AWS S3 bucket),实际模型数据则存放在那里。
这种元数据与模型存储分离的方式,使组织在管理大型模型时拥有更高灵活性,同时又能保证元数据在集群内部易于访问。
通过提供一个结构化且安全的接口来管理模型及其元数据,模型注册表成为在大规模环境中真正落地机器学习的关键工具,尤其是在像 Kubernetes 这样动态的环境中更是如此。
模型注册表位于数据科学家与 MLOps 工程师职责的交汇点上。
对于数据科学家来说,它支持在模型实验过程中创建与跟踪变更、验证性能与指标、为可复现性打包制品,以及将验证通过的模型发布到生产环境。
对于 MLOps 工程师来说,模型注册表便于部署已经批准的模型及其关联元数据,同时也支持对已部署模型进行持续监控,以观察性能、漂移以及是否需要重新训练,尽管这种程度的可观测性通常属于模型注册表核心能力之外的高级特性。
为了帮助理解本节提到的"模型实验"和"特征存储",先看下面的侧栏说明。
模型实验与特征存储
模型实验是指一个迭代过程:通过使用不同超参数(例如学习率或批大小)训练多个模型变体,来寻找表现最好的配置。每一次训练运行都会产生诸如准确率或损失值之类的指标。从 Kubernetes 的角度来看,这通常表现为 GPU 密集型训练任务,第 6 章和第 7 章会介绍。实验跟踪系统会记录这些运行的参数与指标。MLflow(本章后面会讲到)就把实验跟踪作为其更大工具集的一部分提供出来。
在机器学习中,特征是模型用来做预测的输入变量,例如在欺诈检测系统中,"过去一小时内的交易次数"或"过去 30 天的平均交易金额"。特征存储(feature store)负责在训练和推理之间以一致方式管理这些特征的计算与服务,从而避免训练-服务偏差。特征计算通常以数据管道形式运行,这部分会在第 8 章讨论。
对于生成式 AI 工作负载来说,特征的重要性没有传统机器学习中那么突出,因为 LLM 主要处理的是文本和 embedding,而不是结构化特征。Feast 是领先的开源特征存储之一,它既可管理传统机器学习特征,也可管理生成式 AI 场景(例如检索增强生成)中的文本 embedding(见"检索增强生成")。
这两个概念都突出了机器学习中的协作式工作流:数据科学家负责实验与迭代,而平台团队则提供 Kubernetes 基础设施(GPU 节点、持久化存储、批处理调度),使这些工作具备可扩展性。模型注册表则充当交接点,把成功实验产生的元数据存储起来,以备生产部署。
下面这组列表概括了定义模型注册表的核心特性,它们为公共与本地两类场景都提供了关键能力:
元数据管理
存储模型准确率、数据集血缘、性能基准以及其他关键信息。
模型发现与搜索
基于模型架构、超参数、训练数据集和性能指标等元数据来搜索并检索模型。支持范围过滤(例如 accuracy > 0.95)。
版本控制
跟踪模型与训练数据集的多个版本。模型版本管理便于比较不同模型迭代,必要时回滚;数据集版本管理则通过记录训练和评估所用的数据版本来保证可复现性。
生命周期管理
管理模型所处阶段,例如实验中、预发布、生产中以及退役。这一能力在持续开发工作流中尤为关键。
访问控制
提供细粒度权限,控制模型的可见性与使用权限,确保跨团队协作的安全性。
审计与合规
保留模型使用、审批和变更记录,以满足监管合规和可复现性要求。
数据管道
集成进 CI/CD 工作流,自动化执行模型验证、制品打包和生产发布等任务。
为了更清楚地理解这些特性在现实工具中是如何落地的,下面我们将考察四种有代表性的模型注册表:Hugging Face Model Hub、MLflow Model Registry、Kubeflow Model Registry 和 OCI Registries。
Hugging Face Model Hub
Hugging Face Model Hub 是发现和共享开源机器学习模型(包括 LLM)的标准平台。到 2026 年初,它已经托管了超过 200 万个模型,其中专门的 LLM 超过 31 万个,且全部公开可用。就像 GitHub 是开源软件开发的主要中枢一样,Hugging Face 也已经成为开源机器学习模型领域的主导平台。
目录中的每个模型条目都附带一个 Model Card。Model Card 提供了一种标准化摘要,用来描述机器学习模型的关键特征,包括其预期使用场景、训练数据集、性能基准和局限性。它通常还包含指向训练数据集的链接、评估指标和许可证信息。用户还可以通过内置的 inference widget 交互式试用模型,无需本地配置,就能直接在 Web 界面中快速测试模型。图 2-5 展示了一个 Model Card 示例。
图 2-5. Llama 3.1 的 Hugging Face Model Card(来源:Llama 3.1)
除了 Web 界面之外,Hugging Face 还提供 REST API,支持以编程方式访问其仓库。开发者可以借此查询模型、获取元数据,并将模型直接集成进自动化工作流和流水线中。这个 API 让诸如发现模型最新版本、或基于特定条件筛选模型等任务变得更加简单。
不过,虽然 Hugging Face Hub 非常适合公开模型共享和人工发现,它在生产使用中仍有限制。作为公共注册表,它并不适合那些必须对专有模型严格保密的组织。在高度自动化的工作流中,它也可能显得不足,因为这类场景通常要求模型版本能够被程序化跟踪与管理。对于这类需求,内部专用模型注册表就变得必要,以保证版本控制、可追溯性、隐私,以及与生产流水线更紧密的集成。
MLflow Model Registry
MLflow 是 Linux Foundation 旗下的一个项目,用于管理机器学习生命周期,包括实验跟踪、模型打包和模型注册表。
MLflow 由 Databricks 于 2018 年创建,旨在解决团队与环境之间机器学习实验和模型制品管理不一致的问题。自从开源之后,MLflow 凭借其简洁性和良好的集成能力,在数据科学社区中得到了广泛采用。
MLflow 的核心元素是 Tracking Server,它是管理和存储实验元数据、指标以及模型制品的中心枢纽。它提供了一个接口,数据科学家可以在其中记录结果、比较不同运行、组织模型,并将它们暴露到模型注册表中。一套丰富的可视化功能使你能够跟踪性能数据与不同超参数的变化。
在最简单的情况下,模型本身存储在本地文件系统中。对于生产环境,MLflow 支持把模型制品推送到 AWS S3 这样的外部存储系统,或者直接从 Hugging Face Hub 下载。MLflow 通过注册表元数据中保存的 artifact URI 来管理这些存储位置的引用。
MLflow Model Registry 是 Tracking Server 的一部分,它为机器学习模型的版本化、跟踪与管理提供了一个中心仓库。它允许数据科学家把模型连同丰富元数据一起注册进来,包括版本历史与性能指标。图 2-6 展示了 MLflow Model Registry 的 Web UI。
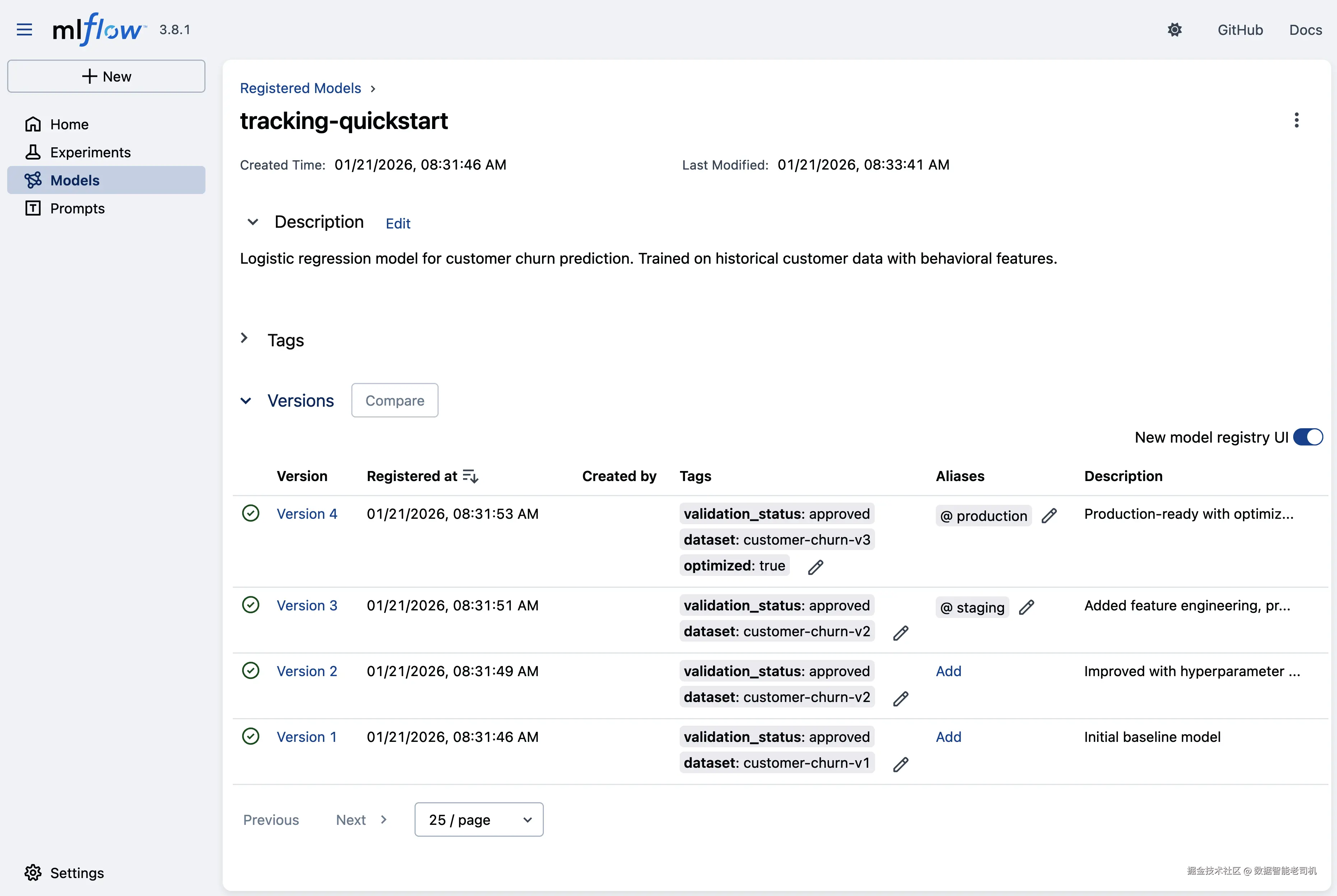
图 2-6. MLflow Model Registry UI
不过,大多数时候,数据科学家与 MLflow Model Registry 的交互都是通过编程方式进行的,就像示例 2-2 那样。
示例 2-2. 通过编程方式用 MLflow 记录并注册模型
ini
mlflow.set_tracking_uri(uri="http://localhost:8000")
mlflow.set_experiment("MLflow Demo")
params = {
"solver": "lbfgs",
"multi_class": "auto",
"max_iter": 2500,
}
with mlflow.start_run():
mlflow.log_params(params)
model_info = mlflow.sklearn.log_model(
sk_model=model,
artifact_path="my_model",
input_example=X_train,
registered_model_name="my-model",
)设置用于记录日志的 tracking server URI。
创建一个新的 MLflow 实验。
模型超参数。
记录这些超参数。
把模型本身记录到 tracking server。这里没有展示 model 和 X_train 的定义。
对于 MLOps 工程师来说,MLflow 提供了一个可用于模型发现的 REST API。示例 2-3 展示了如何获取某个模型的详细信息。
示例 2-3. 通过 MLflow REST API 搜索并列出模型
ruby
$ curl http://localhost:8000/api/2.0/mlflow/registered-models/search
{
"registered_models": [
{
"name": "my-model",
"creation_timestamp": 1736523034148,
"last_updated_timestamp": 1736524822538,
"latest_versions": [
{
"name": "my-model",
"version": "4",
"creation_timestamp": 1736524822538,
"last_updated_timestamp": 1736524822538,
"current_stage": "None",
"description": "",
"source": "mlflow-artifacts:/84948067/f0dd25483e/artifacts/my_model",
"run_id": "f0dd25483e234400b7",
"status": "READY",
"run_link": ""
}
]
}
]
}访问本地机器上运行的 MLflow server。
注册表中的模型是有版本管理的。
使用 MLflow 的 mlflow-artifacts:// 协议对模型制品进行 URI 引用。在这个本地示例中,制品存储在文件系统中,但该协议同样支持 S3 或 GCS 等外部存储。
MLflow 还提供与 Model Server 交互的 CLI 工具,如示例 2-4 所示。这里一个有趣的选项是,可以创建一个自包含的 OCI 容器镜像,然后把它推送到 OCI Registry,供 Kubernetes 集群后续使用。不过,这项能力并没有针对需要本地存储的大规模下载流量进行优化,因此并不太适合 LLM。我们将在"OCI Registry"一节中介绍如何用 OCI Registries 管理模型数据。
示例 2-4. 使用 MLflow 和 Podman 创建自包含 OCI 容器镜像
bash
$ mlflow models generate-dockerfile \
-m mlflow-artifacts:/84948067/f0dd25483e/artifacts/my_model
... INFO mlflow.models.cli: Generating Dockerfile for model mlflow-artifacts:
.../artifacts/my_model
... INFO mlflow.models.flavor_backend_registry: Selected backend
for flavor 'python_function'
... INFO mlflow.models.cli: Generated Dockerfile in directory mlflow-dockerfile
$ cd mlflow-dockerfile
$ podman build -t my_model .
STEP 1/12: FROM python:3.13.1-slim
STEP 2/12: RUN apt-get -y update && apt-get install -y --no-install-recommends nginx
....
Successfully tagged localhost/my_model:latest
a828556afe0d53d4728d872aa51fe07eaa1d4ef4faedb5a788bac9a7a7651e73使用 mlflow CLI 生成一个 Dockerfile,用来描述如何构建一个同时包含 MLflow 和模型数据的镜像。
使用 podman 创建名为 my_model 的 OCI 镜像。你也可以用 Docker 来完成构建。
NOTE
MLflow 也提供
mlflow models build-docker命令,它把这两步合并成一个操作,直接创建 Docker 镜像,而不需要单独生成 Dockerfile。本例展示的
generate-dockerfile方法更灵活,便于做自定义修改(例如替换基础镜像或添加构建后步骤),同时也能很好地配合 Podman 或 Docker 使用。
虽然 MLflow 起初并不是围绕 Kubernetes 设计的,但它仍然可以较好地部署在 Kubernetes 上。标准做法是把它作为 Web 服务部署,例如借助 Helm charts,而 PostgreSQL 通常作为其后端来存储元数据。MLflow 并不提供原生 Kubernetes CRD,因此它与 Kubernetes 的集成通常需要额外自动化来处理扩缩容和动态模型服务之类的任务。
MLflow 功能丰富,但它最初主要面向传统机器学习工作流。它的元数据管理与制品处理方式非常适合传统 ML 场景,但 LLM 因为体量大、复杂度高,往往需要更专门的处理。
从 3.0 版本开始,MLflow 对 LLM 的支持已经有了显著增强,例如通过 Transformers flavor 引入了更节省内存的 logging 方式,可以在存储制品时避免将大模型完整加载进内存。近期的增强还包括:用于提示词版本化的 Prompt Registry、统一 LLM 提供商接入的 AI gateway、原生 GenAI 评估能力、增强的 LLM 应用 tracing,以及基于引用的 logging------后者只存储 Hugging Face Hub 引用,而不是完整模型权重,从而在开发阶段显著降低存储需求。
不过,在生产部署中,为了保证可用性与性能,完整模型权重通常仍然需要被下载并本地存储。但这些做法在生产环境中也会带来问题,例如外部仓库不可用的风险,或者缺乏足够缓存机制来支持大模型的重复获取。因此,尽管 MLflow 的制品存储和模型处理方式在不断改进,但对于大规模 LLM 管理,它通常仍需要配合额外基础设施使用。比如,从注册表反复下载大模型很容易变得低效,而 MLflow 当前的制品存储方式也并未针对这种高容量数据处理进行优化。
总的来说,MLflow 主要还是聚焦于机器学习生命周期中数据科学侧的工作,为数据科学实验跟踪提供了非常丰富的能力。它最大的优势之一,是门槛较低、很容易安装到本地机器上。
虽然 MLflow 也可以部署在 Kubernetes 上,但它与 Kubernetes 的集成仍然有限。如果需要更 Kubernetes 原生的方案,那么像 Kubeflow 这样的替代方案,可以在更深层次上扩展模型注册表的概念,并提供更多 Kubernetes 集成与可观测性能力。
Kubeflow Model Registry
Kubeflow 是一个 Kubernetes 原生平台,旨在简化整个机器学习生命周期,包括模型训练、模型服务以及模型注册表管理。它最初由 Google 开发,如今已成为 CNCF 旗下的开源项目,由以下几个相对松耦合的组件构成:
Kubeflow Dashboard
一个中央控制台和入口,用于连接 Kubeflow 及其他生态组件经过身份认证后的 Web 界面。
Kubeflow Notebooks
用于在 Kubernetes 集群内部运行基于 Web 的开发环境,例如 Jupyter Notebooks。它们通过 Pod 运行,因此不需要本地安装。
Kubeflow Pipelines
Kubeflow Pipelines(KFP)是一个基于 Kubernetes 构建和部署可移植、可扩展机器学习工作流的平台。
Kubeflow Trainer
Kubeflow Trainer 为 Kubernetes 上的模型训练和微调提供统一接口。它可运行可扩展、可分布式的训练任务,支持 PyTorch、TensorFlow 等流行框架。
Kubeflow Katib
Katib 是一个 Kubernetes 原生 AutoML 项目,支持超参数调优、早停以及神经架构搜索。
模型服务
KServe(以前叫 KFServing)解决的是 Kubernetes 上的生产级模型服务问题。它最初起源于 Kubeflow,但后来独立为 CNCF 项目。我们会在"KServe"一节中详细介绍它。
Model Registry
机器学习模型的索引与目录。这个注册表是 Kubeflow 生态中的中心枢纽。本节剩余部分将聚焦于它。
图 2-7 展示了 Model Registry 与 Kubeflow 其他组件之间的交互关系。
从根本上说,Kubeflow 充分利用了 Kubernetes 的理念,所有任务------包括模型注册与训练------都被定义为容器化工作负载。与更灵活、偏实验跟踪与模型管理工具的 MLflow 不同,Kubeflow 通过 CRD、Manifest 和针对机器学习生命周期各组件的原生控制器,与 Kubernetes 建立了更深度的集成。
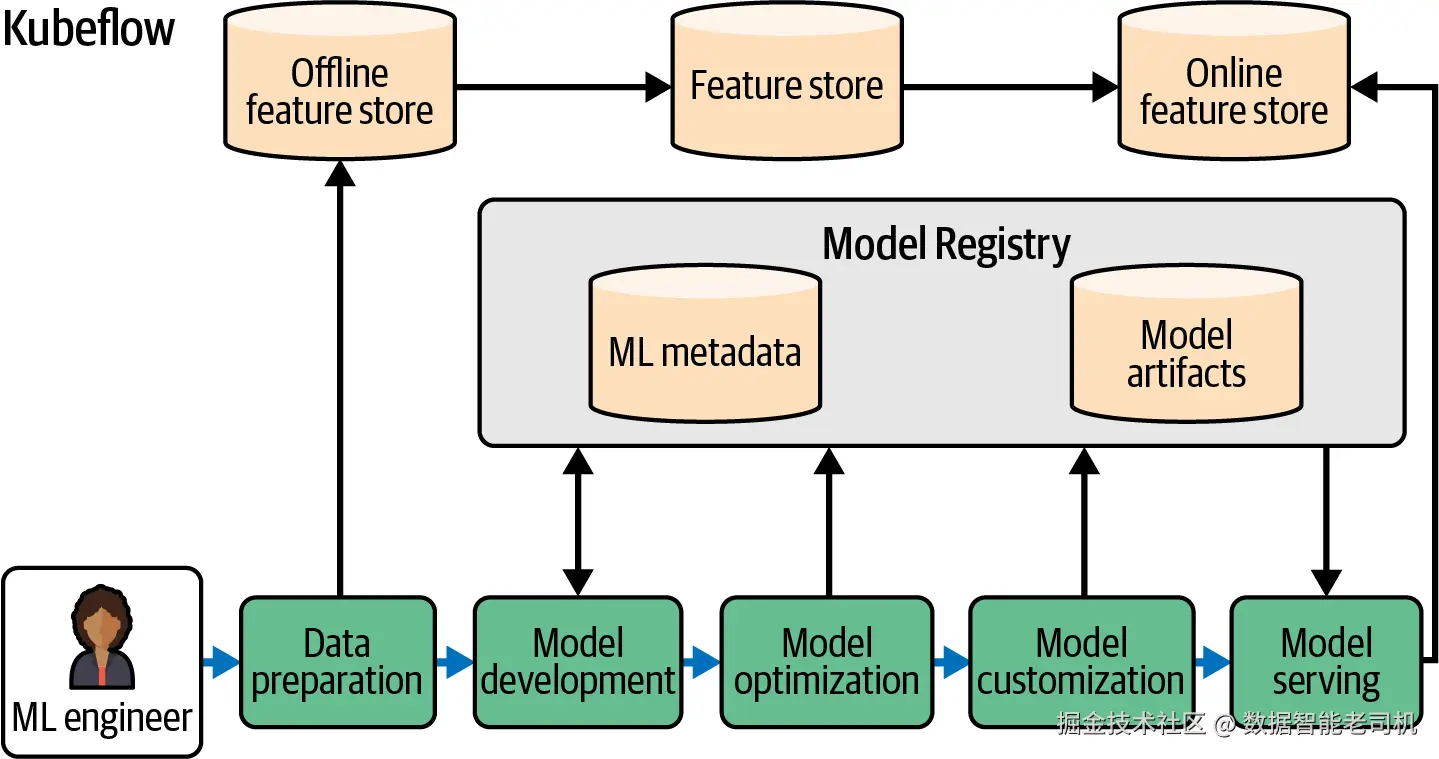
图 2-7. Kubeflow 架构以及它与 Model Registry 的交互方式
Kubeflow Model Registry 作为中心仓库,用于管理机器学习模型、模型版本以及相关元数据。它显著简化了从实验阶段走向生产部署的过程。
在内部,注册表使用灵活的实体-关系模型,在后端关系型数据库(MySQL)中存储元数据。这个模型受 Google ML Metadata 项目启发,为存储模型血缘、指标和参数提供了结构化、可扩展的方法。Kubeflow Model Registry 能够统一元数据、支持版本控制,并在 Kubeflow 各组件之间实现互操作性。这使其能够对模型版本进行稳健跟踪,并在部署或流水线触发中复用这些元数据。
该注册表依赖外部组件,例如 MySQL 用于存储元数据,并需要持久化卷来保证数据持久性。在生产环境中运行该注册表时,这一点必须纳入考虑。它通过 REST API 和 Python SDK 提供交互接口。
要使用注册表,你首先要注册一个模型及其元数据。示例 2-5 展示了如何在 Python 程序或 Jupyter Notebook 中完成这一步。
示例 2-5. 在 Kubeflow Model Registry 中注册模型
ini
from model_registry import ModelRegistry
registry = ModelRegistry(
server_address="http://model-registry-service.kubeflow.svc.cluster.local",
port=8080,
author="your name",
is_secure=False
)
rm = registry.register_model(
"iris",
"gs://kfserving-examples/models/sklearn/1.0/model",
model_format_name="sklearn",
model_format_version="1",
version="v1",
description="Iris scikit-learn model",
metadata={
"accuracy": 3.14,
"license": "BSD 3-Clause License",
}
)创建一个代理对象,用于访问运行在集群中的 Model Registry。由于使用的是集群内部服务地址(.svc.cluster.local),这段代码必须运行在集群中的某个 Pod 内。
注册一个模型,并附带元数据以及模型数据所在位置的引用(这里是 Google Cloud Storage)。
当模型被注册进注册表之后,你可以通过 Python 库轻松访问它。你也可以像示例 2-6 那样,直接通过 REST API 调用这个服务来访问模型。
示例 2-6. 在 Pod 内使用 curl 查询集群内部的 Model Registry
arduino
kubectl run -it --rm curl --image=curl --restart=Never \
http://model-registry-service.kubeflow.svc.cluster.local/...在一个临时 Pod 内运行 curl 命令,查询集群内部的 Model Registry 服务。
你还可以让 Kubeflow Model Registry 与 KServe 的 InferenceService 配合使用,从而基于注册表中指向的模型数据来初始化 InferenceService。示例 2-7 展示了这种做法。
示例 2-7. InferenceService 通过 Kubeflow Registry 访问模型数据
yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: iris-model
spec:
predictor:
model:
storageUri: "model-registry://iris/v1"
modelFormat:
name: "sklearn"
version: "1"通过模型 ID 和版本进行引用。实际的存储 URI 会从 Model Registry 元数据中取回,这增加了一层间接性,使你可以在不修改 InferenceService 的情况下更换底层存储位置。
指定模型格式,以便确定使用哪个运行时。
OCI Registry
OCI(Open Container Initiative)Registry 是一种用于存储和分发容器镜像的标准机制,在 Kubernetes 环境中非常常见。像 Docker Hub 和 Quay.io 这样的服务,让 Kubernetes 用户无需自己运行注册表,也能方便地存储和管理镜像。一些 Kubernetes 发行版(例如 Red Hat OpenShift)甚至内置了 OCI Registry。
什么是 OCI?
Open Container Initiative(OCI)定义了容器化应用与制品的管理标准。OCI 由 Docker 等公司于 2015 年在 Linux Foundation 旗下发起,旨在确保容器技术具备互操作性和厂商中立性。它从 Docker 的专有格式演进而来,目的是避免被某一家技术锁定,从而形成一个开放、可扩展的生态。
OCI 最初主要面向容器镜像,但随着 OCI artifacts 规范的出现,它如今已经支持 Helm chart、生成式 AI 模型等多种类型的制品。这使得注册表对现代工作负载而言极具通用性。关于如何结合 modelcars 使用 OCI 镜像来承载模型数据,见"Modelcars";关于 Kubernetes 中原生的 OCI image volume mounts,见"OCI Image Volume Mounts"。
OCI Registry 不只能存储容器镜像。随着 OCI 1.1 的推出,规范扩展为支持 OCI artifacts,也就是对原始镜像格式的泛化。OCI artifacts 允许你存储任意类型的数据,因此 OCI Registry 也就适合托管机器学习模型,包括 LLM。这意味着注册表可以管理完整模型文件本身,而不仅仅是引用外部存储。
OCI Registries 提供版本管理、不可变性、持久化和高效分发机制,这些特性都非常契合 LLM 托管需求。与主要存储模型元数据和外部存储引用的 MLflow 和 Kubeflow Registries 不同,OCI Registry 更强调直接存储完整模型数据本身。
LLM 模型镜像是一种"被动数据镜像(passive data images)"。你不会去执行它们;相反,你会把它们当作不可变包,用来承载模型权重和配置,供推理运行时使用。你可以像示例 2-8 那样,通过克隆一个 Hugging Face 仓库,轻松创建这样一个数据镜像。
示例 2-8. 用于创建"承载模型的容器镜像"的 Dockerfile
bash
FROM alpine/git
RUN git lfs install \
&& git clone --depth 1 https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct /models
ENTRYPOINT sh这个 Dockerfile 可以直接配合 podman 或 docker 使用,如示例 2-9 所示,来创建一个自包含 OCI 镜像文件,其中包含运行该模型所需的全部文件。为简化说明,这个示例把整个模型都放进了一个层中。在生产环境中,建议把每个模型分块作为独立层加入,这样容器运行时就能独立下载和缓存它们。
示例 2-9. 使用 Podman 构建并推送模型镜像
bash
$ podman build -f Dockerfile.model -t quay.io/rhuss/qwen2.5-0.5b-instruct .
STEP 1/3: FROM alpine/git
Trying to pull docker.io/alpine/git:latest...
Getting image source signatures
...
Writing manifest to image destination
STEP 2/3: RUN git lfs install
&& git clone https://huggingface.co/Qwen/Qwen2.5-0.5B-Instruct
&& ln -s /git/Qwen2.5-0.5B-Instruct /models
Git LFS initialized.
Cloning into 'Qwen2.5-0.5B-Instruct'...
--> b437a8f78e49
STEP 3/3: ENTRYPOINT sh
COMMIT quay.io/rhuss/qwen2.5-0.5b-instruct
--> f680df7c975f
Successfully tagged quay.io/rhuss/qwen2.5-0.5b-instruct:latest
f680df7c975f6bfc806783574003c2b17872e9bf767944380f
$ podman push quay.io/rhuss/qwen2.5-0.5b-instruct:latest 构建模型镜像。它会从 Hugging Face Hub 克隆完整仓库,因此可能需要一些时间。
把镜像推送到 Kubernetes 集群可访问的注册表中。
通过利用 OCI Registry,你可以在 Kubernetes 原生基础设施中高效地存储、版本化和分发 LLM 模型,并顺畅地融入 MLOps 流水线与声明式工作流中。关于用 modelcars 使用 OCI 镜像,见"Modelcars";关于原生 OCI 镜像卷挂载,见"OCI Image Volume Mounts"。这两种方式都允许 KServe InferenceService 直接从 OCI 镜像中加载模型数据。
在 Kubernetes 中访问模型数据
现在我们已经了解了各种模型格式,以及用于注册和发现它们的不同方案,接下来进入细节:如何在 Kubernetes 集群内部访问这些模型数据。
第 1 章介绍了多种在 Kubernetes 上提供 GenAI 模型服务的方式。它们都要求模型以某种方式被下载。对于第 1 章提到的所有运行时,获取模型数据的方法都大同小异,但为了便于说明,我们继续使用 KServe 作为一个典型示例。
最简单的情况下,你可以像示例 2-10 那样,在 InferenceService 资源中指定存储位置,通过一个指向模型数据位置的 storageUri 来完成。
示例 2-10. 从 S3 存储中获取模型数据的 InferenceService
yaml
apiVersion: "serving.kserve.io/v1beta1"
kind: "InferenceService"
metadata:
name: "mnist"
spec:
predictor:
serviceAccountName: sa
tensorflow:
storageUri: "s3://kserve-examples/mnist" 与持有认证凭据 Secret 关联的 Kubernetes ServiceAccount。
本例中使用的运行时是 TensorFlow。
指向存放模型数据文件的 S3 bucket。
这个 URI 的 schema 定义了模型数据由哪种后端存储,以及它位于何处。每个 schema 都会触发一个所谓的 storage initializer,它会以运行时 Pod 的 init-container 形式注入。你可以通过 KServe 的 ClusterStorageContainer 资源创建并部署自己的 storage initializer。
如示例 2-11 所示,在这个资源中,你需要指定一个包含自定义 storage initializer 的镜像引用,以及一个 URL schema 列表,用于匹配并触发该 initializer。与这些 schema 匹配的 URL 之后就可以在 InferenceService 中作为 storageUri 使用。
示例 2-11. 添加 model-registry:// schema 支持的 ClusterStorageContainer
yaml
apiVersion: serving.kserve.io/v1alpha1
kind: ClusterStorageContainer
metadata:
name: model-registry-storage
spec:
container:
name: storage-initializer
image: kubeflow/model-registry-storage-initializer
supportedUriFormats:
- prefix: model-registry:// 用于执行 initializer 逻辑的 OCI 镜像引用。
注册 model-registry 这个 URL schema,使其可在 InferenceService 中使用。
Kubernetes 会在模型运行时启动之前,把 storage initializer 作为 init-container 运行;它的唯一职责,就是让模型数据对 serving runtime 可用。
INIT CONTAINERS 与 SIDECARS
Init container 和 sidecar 是 Kubernetes 中增强 Pod 行为的两种强大模式。Init container 会最先运行,执行一次性的初始化任务,比如把主容器所需的数据填充到共享卷中。
而 sidecar 则与主容器并行运行,通常提供辅助能力,例如日志、数据处理或容器间数据共享。
这两种模式结合起来,使 Pod 的设计具备了很高的灵活性和模块化程度。关于更多内容,可以参考 Kubernetes Patterns 中对 init container 和 sidecar 模式的介绍。
表 2-2 展示了 KServe 开箱即用支持的 storage initializer。
表 2-2. KServe storage initializer
| Schema | 描述 | 示例 |
|---|---|---|
| gs | 从 Google Cloud Storage 下载 | gs://kfserving-examples/models/sklearn/1.0/model |
| s3 | 从 S3 bucket 下载 | s3://kserve-examples/mnist |
| https | 通过 HTTP 下载模型数据 | https://huggingface.co/meta-llama/Llama-3.2-3B |
| hdfs, webhdfs | 从 Hadoop Distributed File System 访问文件 | hdfs://path/to/model |
| pvc | 从给定 PVC 引用的 PersistentVolume 中复制模型数据 | pvc://${PVC_NAME}/export |
| oci | 拉取包含模型数据的 OCI 镜像,并通过 modelcar 直接访问;见"Modelcars" | oci://quay.io/rhuss/kserving-example-sklearn:1.0 |
| model-registry | 访问在 Kubeflow Registry 中注册的模型;详见"Kubeflow Model Registry" | model-registry://iris/v1 |
| hf | 直接从 Hugging Face Hub 下载 | hf://meta-llama/Llama-2-7b-chat-hf |
在 Kubernetes 中,一个常见模式是使用专门的节点本地卷在容器之间共享数据。表 2-2 中的大多数 storage initializer,都会把模型数据下载到节点本地目录中,然后由 LLM 运行时共享挂载,以便直接访问这些数据。
为此,Kubernetes 提供了 emptyDir 卷类型。Kubernetes 会把它初始化为空目录,并允许同一 Pod 内所有容器挂载它,包括先运行的 init container 和后运行的应用容器。模型服务运行时随后会挂载这个卷,以访问准备好的数据。有关这一技术的更多细节和变体,可以参考 Kubernetes Patterns 中的 immutable configuration 模式。
虽然 emptyDir 提供的是节点本地存储,但它要求每一个 Pod 实例都各自复制一份模型数据。如果多个副本都在提供同一个模型服务,那么使用由共享分布式文件系统支持的 PersistentVolume,会是更节省存储的一种方式。
使用 PersistentVolume 的共享存储
当你运行多个 InferenceService 副本时,每个副本都需要访问同一份模型数据。我们前面看到的方法,要么是从远程存储下载新的副本,要么是把模型打包进 OCI 镜像(见"用于存储模型数据的 OCI 镜像")。PersistentVolume(PV)提供了第三种思路:只保留一份共享模型数据,并让多个 Pod 同时访问。
PV 通过 NFS 或 Ceph 这类分布式文件系统实现高效共享模型。你不需要在每个节点或每个 Pod 上都维护一份拷贝,而是只存储一次,然后在所有副本之间统一挂载。这种方式带来三个主要优势:
第一,在运行几十个副本时可以显著节省存储成本;
第二,它实现了职责分离------数据科学家在外部管理模型,而 Kubernetes 只负责消费这些模型;
第三,通过中心化存储位置,使模型更新更简单。
示例 2-12 展示了一个用于模型存储的基本 PV 和 PersistentVolumeClaim(PVC)配置。
该 PV 指定了 ReadOnlyMany 访问模式,允许多个 Pod 以只读方式同时挂载它。
persistentVolumeReclaimPolicy 决定了 PVC 被删除时会发生什么:Retain 会保留数据(防止模型被误删),而 Delete 则会删除 PV 及其底层存储。
示例 2-12. 用于模型存储的 PersistentVolume 和 PersistentVolumeClaim
yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: llama-3-8b-pv
spec:
capacity:
storage: 20Gi
accessModes:
- ReadOnlyMany
persistentVolumeReclaimPolicy: Retain
nfs:
server: nfs-server.example.com
path: /exports/models/llama-3-8b
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: llama-3-8b-pvc
namespace: default
spec:
accessModes:
- ReadOnlyMany
resources:
requests:
storage: 20GiPV 的总存储容量。
允许多个 Pod 同时以只读方式挂载。
当 PVC 被删除时保留数据(防止误删模型)。
这里用 NFS 作为示例;你所在集群支持的其他分布式文件系统(例如 Ceph、AWS EFS、Azure Files 或 Google Cloud Filestore)也可以用类似方式配置。
PVC 所请求的访问模式必须与 PV 兼容。
模型服务类工作负载通常只需要对模型权重和配置文件进行只读访问。推理引擎在服务过程中会读取模型参数,但不会修改它们。因此,这种只读特性使 ReadOnlyMany 成为模型存储 PV 的理想访问模式。
只读访问的配置发生在两个层面。
在 PV 层面,ReadOnlyMany 允许多个 Pod 同时挂载该卷用于读取。
在 Pod 层面,在 volumeMount 规范中设置 readOnly: true 又进一步强化了这一约束,并带来额外收益。
只读挂载有两个性能优势。
第一,由于操作系统知道数据不会变化,因此可以更激进地进行文件系统缓存。
第二,不会出现多个副本并发访问时的锁竞争,也就避免了读写挂载场景中可能产生的协调开销。
KServe(见"KServe")通过 pvc:// 这个 storage URI schema 支持 PV,从而能直接与 PersistentVolumeClaim 集成。示例 2-13 展示了如何在 InferenceService 中使用示例 2-12 的 PV 和 PVC。
示例 2-13. 在 InferenceService 中使用 PersistentVolumeClaim 作为模型数据来源
yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: llama-pvc
spec:
predictor:
model:
modelFormat:
name: pytorch
storageUri: pvc://llama-3-8b-pvc/ 通过名称引用 PVC。KServe 会把这个 PVC 直接挂载到模型容器中的 /mnt/models。
与从 s3:// 或 gs:// 这类远程来源下载数据的 storage initializer 不同,pvc:// 的工作方式完全不同。KServe 会创建一个基于 PVC 的卷(名为 kserve-pvc-source),并将 PVC 直接挂载到模型容器中的 /mnt/models。这里没有复制步骤:运行时会直接从挂载的 PVC 上读取模型文件。
storage initializer 依然会运行,但对于 PVC URI 来说,它本质上几乎不执行任何动作,因为数据访问已经由卷挂载本身完成了。
这种直接挂载的方式,是 PV 与其他存储方式之间的根本区别。
S3 或 Google Cloud Storage 之类的 initializer 会先把数据下载并复制到 emptyDir 卷中;而 PV 则彻底消除了这个复制步骤。模型容器通过网络文件系统访问这些文件,就像访问本地文件一样,尽管网络延迟会影响读取性能。
节点本地存储与网络后端存储在访问性能上存在显著差异。
本地访问方式------例如 init-container 复制、modelcar(见"Modelcars")以及 OCI volume(见"OCI Image Volume Mounts")------通过直接的节点本地 I/O,提供最快的推理性能。
通过 PV 的网络访问则会在每次读操作上引入额外延迟,性能取决于网络带宽与后端存储能力。这里的根本权衡,是存储效率与访问速度之间的取舍。
并发访问的可扩展性取决于多种因素:后端存储性能、模型大小、推理吞吐需求,以及可用网络带宽。对于典型的 GPU 推理部署(10--20 个副本),PV 通常是可行的,因为 GPU 成本本身就自然限制了规模。
基于 CPU 的推理可能会扩展得更高,而这时存储后端性能就会成为瓶颈。需要警惕的信号包括:存储后端磁盘压力增大、I/O wait 时间上升,以及响应延迟不稳定。潜在瓶颈则可能来自网络饱和、NFS 服务器负载上限以及并发读竞争。
Kubernetes 生态已经明确认识到"太多 Pod 共享同一个 PVC"是一个真实问题类别,尽管并没有一个统一的硬阈值。像 Ceph 或 AWS EFS、Azure Files 这类高性能云存储服务,能承受的并发负载通常比基础 NFS 更高。对于高规模部署或高吞吐推理需求,你可以考虑接下来会讲到的节点本地方案,例如"用于存储模型数据的 OCI 镜像"中介绍的 OCI volume。
PV 的启动速度通常很快,因为挂载只需要建立网络挂载,而不需要复制数据。
但在 scale-to-zero 场景中,每次 Pod 重启都需要重新通过网络挂载,且无法从 Pod 重启之间的本地缓存中获益。
在"经验总结"一节中,我们会把 PV 与其他模型数据访问方式进行对比,帮助你根据自身需求选择合适方案。
除了 PersistentVolume 之外,OCI 镜像也为传输和存储模型数据提供了另一种思路。接下来的几节将讨论如何把模型打包为 OCI 镜像,并让 LLM 运行时高效访问这些镜像中的数据。
用于存储模型数据的 OCI 镜像
2013 年,Docker 发明了一种巧妙的分层格式,用来存储容器蓝图。它最初、也是至今仍然最常见的用途,是在内核之外存储构成 Linux 操作系统的二进制文件和系统文件。
这种格式是分层的,因此用户可以创建可复用的基础镜像,再在此之上构建不同的专用镜像,例如包含容器中应用程序的镜像。多个容器在运行时如果引用了相同层,就可以共享这些层。
除了镜像的只读层之外,Docker 还使用联合文件系统(union filesystem),在镜像层栈的顶部加上一层可读写层,这样不同的容器实例就仍然可以共享相同的底层操作系统文件。
这种模式的一个关键好处,是只读层可以单独缓存,因此 OCI 镜像的使用效率非常高:只有发生变化的层才需要被重新分发。
这里我们不会深入展开底层格式细节,因为当我们用这类层来承载模型数据时,许多技术细节并不重要。当前最关键的是理解两点:
第一,层是可以共享的;
第二,OCI 镜像是按层级结构构建起来的,也就是层层堆叠。
这种"堆叠"方式与模型组合技术非常契合,例如在基础模型之上叠加 Low-Rank Adaptation(LoRA)适配器进行微调。关于 LoRA,我们会在"Low-Rank Adaptation"中进一步讨论。
这些以基础镜像形式存储的基础模型,在集群节点上运行时可以被共享,因此对于运行多个专用微调模型来说,会非常高效。
图 2-8 展示了这类镜像是如何组合的。最终,所有层都会被打包进一个 tar 归档文件,并存储在 OCI Registry 中。
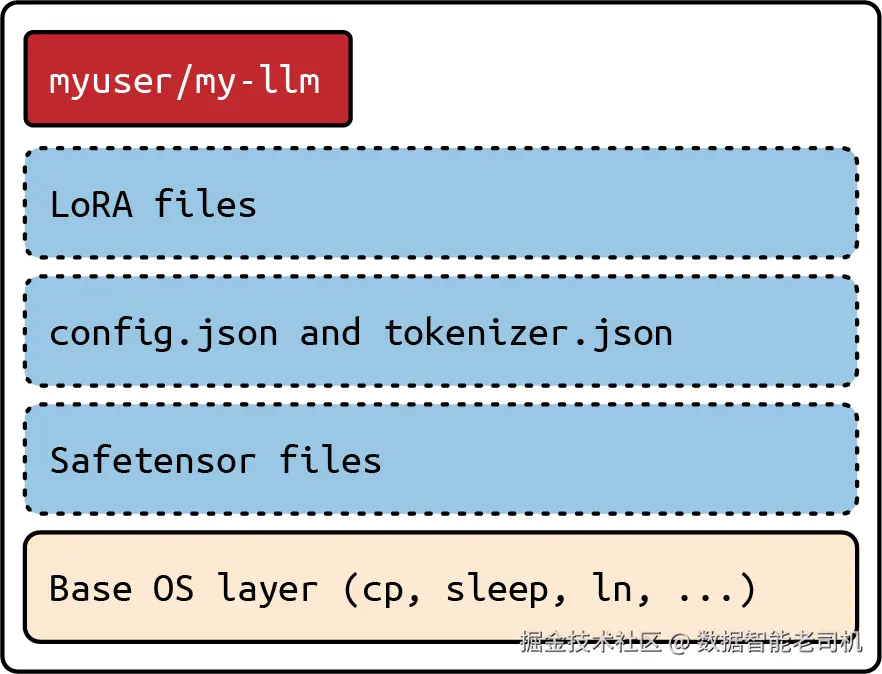
图 2-8. OCI 镜像由多个文件系统层构成
Docker 的成功最终推动了 OCI 镜像规范的标准化。随着时间推移,围绕 OCI 镜像出现了一整套支持工具生态,从托管 OCI 镜像的 registry,到 skopeo、oras 这类用于检查和管理 OCI 镜像的 CLI 工具。把 LLM 放进 OCI 镜像中,实际上就是借力这一整套成熟生态,并自动受益于其中已经积累的大量工作成果。
在"手动将模型部署到 Kubernetes"一节中,我们已经看到如何用原生 Kubernetes Deployment 来部署一个 LLM 模型。示例 1-9 展示的是从 Hugging Face Hub 在线下载模型数据,但我们也可以直接从 OCI 容器镜像中初始化模型数据。
示例 2-14 展示了一个类似的 Deployment,不过这次我们引入了一个 emptyDir 卷,用于共享模型数据。
示例 2-14. 通过 init-container 将模型数据复制到 emptyDir 卷的 Deployment
yaml
kind: Deployment
apiVersion: apps/v1
metadata:
name: vllm
spec:
replicas: 1
template:
spec:
initContainers:
- name: copy-model-data
image: quay.io/rhuss/qwen2.5-0.5b-instruct:latest
command:
- "sh"
- "-c"
- "cp -a /models/. /mnt/models"
volumeMounts:
- name: models
mountPath: /mnt/models
containers:
- name: vllm
image: vllm/vllm-openai:latest
args:
- "--served-model-name",
- "Qwen/Qwen2.5-0.5B-Instruct",
- "--model",
"/mnt/models"
volumeMounts:
- name: models
mountPath: /mnt/models
volumes:
- name: models
emptyDir: {}这个 OCI 镜像中保存了 Qwen 2.5 的模型数据,位于 /models 目录(见示例 2-9)。
把镜像目录 /models 中的数据复制到挂载在 /mnt/models、由 emptyDir 支撑的目录中。根据模型大小不同,这一步可能需要不少时间。
把 emptyDir 卷挂载到 init-container 的 /mnt/models。
运行 vLLM,使其访问存放在 /mnt/models 中的模型。
把共享目录挂载到应用容器的 /mnt/models,从而访问 init-container 复制过来的数据。
声明一个空的节点本地目录卷 emptyDir。
示例 2-14 展示的是一种典型的模型数据初始化方式:不论数据来自 S3 bucket,还是来自 OCI 镜像,最终都会以类似方式进入已部署模型。KServe 在表 2-2 中列出的 storage initializer,本质上也是采用这种 init-container 方式,把模型数据从各种来源复制进来。
但除了下载数据之外,这种方式每次启动运行时 Pod 时都会执行昂贵的数据复制步骤,尤其在模型体量达到 GB 级甚至更大时,代价会很高。
接下来的几节将展示,如何避免对这些 GB 级数据做重复复制,转而直接访问 OCI 模型数据镜像中包含的数据。
CNCF MODELPACK 规范
CNCF ModelPack 规范是一个 CNCF Sandbox 项目,它扩展了 OCI 镜像规范,用于打包和分发 AI 模型。它的目标是在 OCI 标准之上扩展出对 AI 模型制品的支持,包括模型权重、元数据和配置。其目的在于统一模型存储和管理方式,提升不同运行时环境之间的兼容性。
通过利用 OCI 的可扩展架构,这一规范希望简化模型部署与共享。它与后文"Modelcars"和"OCI Image Volume Mounts"中介绍的 OCI 镜像卷挂载能力形成互补。定义新的 annotation 类型也是该规范的一部分。
该规范于 2025 年 5 月被接纳进入 CNCF Sandbox,反映出社区浓厚兴趣与产业界的强力支持。如果它取得成功,将推动云原生环境中 AI 工作负载的运维方式走向更统一的路径。
Modelcars
正如我们在示例 2-14 中看到的那样,从 OCI 镜像中访问模型其实并不难。然而,把所有模型数据都复制到一个中间存储中,这种做法也存在一些明显缺点。
如果能在不复制的前提下直接访问 OCI 镜像中的模型数据,那么初始化速度将显著提升,同时还能减少节点空间占用。镜像只需要下载一次,就可以被多个 Pod 同时使用。
而且,对于那些可以利用 OCI 镜像分层特性的 LLM 模型(例如基于基础模型再加 LoRA 微调的模型),所需总存储空间也会下降。基础模型的镜像层可以在多个专用模型之间共享,从而显著减少所需磁盘空间。
很长一段时间里,Kubernetes 都缺少对这一用例的原生支持。虽然相关需求在 GitHub issue 831 中早在 10 多年前就被提出,但多年间一直没有真正推进实现。
不过,随着 LLM 的兴起,以及人们希望用 OCI 镜像来承载模型数据,这种情况发生了变化。从 Kubernetes 1.35 开始,你已经可以在 Pod 规范中直接使用 image volume mounts。不过,这项能力从实验阶段走向稳定,可能还需要一段时间。
我们后面会详细讨论 OCI image volume mounts,但 KServe 已经用一种技巧在旧版本 Kubernetes 上实现了类似效果。如果你已经可以使用 OCI volume mounts,那么你甚至可以直接跳到"OCI Image Volume Mounts"一节,因为 modelcars 可以看作是当前可用、但临时性的过渡方案。
OCI image volumes 最终会覆盖 modelcars 的全部能力,而且它是一种更干净、更标准化的技术。只要条件允许,你都应优先使用 OCI image volumes;只有在暂时不可用时,才退而使用 modelcars。
示例 2-15 展示了如何在 KServe 中配置 modelcars。为了便于说明,例子使用的是一个更简单的 scikit-learn 模型。不同于示例 2-14 中原生 Kubernetes Deployment 的写法,KServe 的 InferenceService 资源会自动处理 modelcar 的设置。
这里的 oci:// URL 格式是 KServe 特有的语法,用于引用包含模型数据的 OCI 镜像,引用的镜像中的模型数据会被直接访问,而不会预先复制到某个卷中。对于大数据集场景,modelcars 能显著加快模型运行时的启动速度。
示例 2-15. 使用 OCI 镜像中模型数据的 InferenceService
yaml
apiVersion: serving.kserve.io/v1beta1
kind: InferenceService
metadata:
name: "sklearn-iris-oci"
spec:
predictor:
model:
modelFormat:
name: sklearn
# OCI Registry and repository of the image holding the model data
storageUri: "oci://rhuss/kserving-example-sklearn:1.0"NOTE
本节后半部分会深入到 modelcars 的技术架构与实现细节。因为细节程度要高于本书大部分其他内容,如果你更关注结果,可以直接跳到"OCI Image Volume Mounts"。
不过,我们认为这项技术背后的模式在其他处理大规模数据的场景中也非常有借鉴意义,因此仍然保留在这里,既作为技术趣味,也作为学习材料。
Kubernetes 的 Pod 规范支持一个不太为人所知的属性:shareProcessNamespace。
默认情况下,Kubernetes 启动的同一个 Pod 内部的不同容器,是彼此不可见的。在容器内执行 ps aux,通常只能看到该容器自己启动的进程。这样做对隔离容器很有好处。
而把 shareProcessNamespace 设为 true 后,容器就能够"看到"其他容器中的进程。你还可以通过 /proc 文件系统访问其他容器的文件系统。
示例 2-16 展示了这种跨容器文件系统访问如何进行测试。
示例 2-16. 访问另一个容器的根文件系统
bash
$ cat spns.yaml
apiVersion: v1
kind: Pod
metadata:
name: spns
spec:
containers:
- image: docker.io/httpd
name: httpd
- image: docker.io/busybox
name: busybox
command: ["sleep", "infinity"]
shareProcessNamespace: false
$ kubectl apply -f spns.yaml
# Jump into the busybox container
$ kubectl exec -it spns -c busybox -- sh
$$ ps
PID USER TIME COMMAND
1 root 0:00 sleep infinity
7 root 0:00 sh
14 root 0:00 ps aux
$$ ls -d /proc [0-9]*
/proc/1 /proc/7
# Root filesystem of PID 1
$$ ls /proc/1/root/
bin dev etc home lib lib64
proc root run sys tmp usr var
# Jump out of the container again
$$ exit
# Change `shareProcessNamespace` from false to true
$ sed 's/false/true/' spns.yml | kubectl apply --force -f -
# Jump into busybox container like before
$ kubectl exec -it spns -c busybox -- sh\
$$ ps
PID USER TIME COMMAND
1 root 0:00 /pause
7 root 0:00 httpd -DFOREGROUND
15 www-data 0:00 httpd -DFOREGROUND
16 www-data 0:00 httpd -DFOREGROUND
17 www-data 0:00 httpd -DFOREGROUND
99 root 0:00 sleep infinity
126 root 0:00 sh
132 root 0:00 ps
# Show data from the other container
$$ head -3 /proc/7/root/usr/local/apache2/conf/httpd.conf
#
# This is the main Apache HTTP server configuration file. It contains the
# configuration directives that give the server its instructions.一个简单的 Pod,包含两个容器:一个 Apache HTTP server 和一个永远 sleep 的 busybox,用于保持容器存活。这里没有启用进程命名空间共享。
只能看到当前容器进程命名空间中的进程。启用了进程命名空间隔离时,容器指定的命令会拥有 PID 1。
PID 1 的根文件系统(也就是 ls / 的结果)。
启用进程命名空间共享后,也能看到其他容器的 PID。
通过 proc 文件系统,可以从 busybox 容器中访问 httpd 容器特有的文件。
NOTE
只有在 Unix 权限允许的情况下,你才能访问其他进程的文件系统。理想情况下,Pod 内所有容器中的进程使用相同的 UID,这样跨容器访问文件系统通常不会有问题。
不过,具体集群配置还可能受到 SELinux 等额外机制影响,即便容器使用相同 UID,甚至 UID 0,也未必一定能访问另一个容器的文件系统。
这种跨容器共享文件系统的技术,对 Kubernetes 来说是通用的,可以用于任何已部署工作负载,而不管你的运行时是自己部署的,还是通过某个附加平台部署的。
虽然并不一定非要理解底层原理,但 KServe 是如何实现"直接挂载镜像"的,确实很有启发性。这个技巧本身并不依赖 KServe,在其他需要访问存储于 OCI 镜像中的大规模数据集的场景里,同样适用。
图 2-9 展示了 KServe 中 modelcar 的组件与结构。
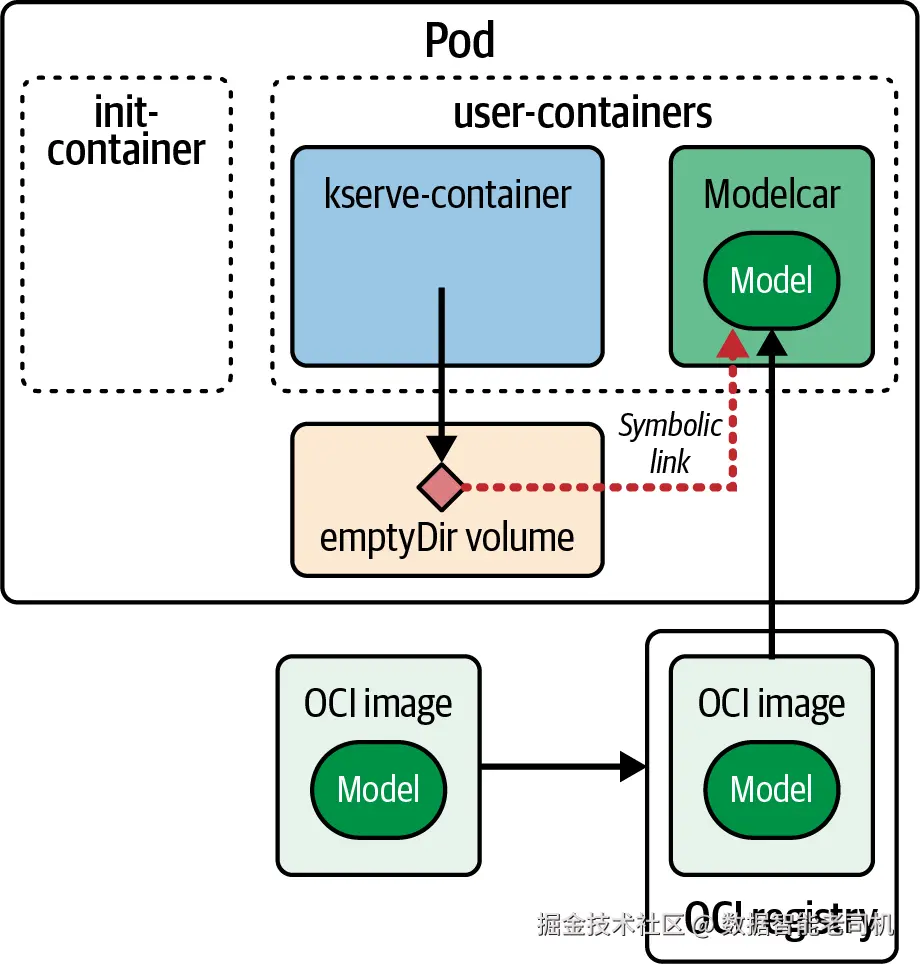
图 2-9. Modelcar 组件
serving runtime 和 modelcar 容器会并行启动。在启动过程中,modelcar 会从自己的文件系统创建一个符号链接,指向一个对两个容器都可见的共享 emptyDir 卷。随后,modelcar 会进入无限睡眠,以保持容器存活。
这个链接操作是 modelcar 启动命令的一部分,几乎不消耗资源------维持空闲状态通常不到 10 MB 内存。
需要强调的是,这里没有复制任何数据;只是创建了一个符号链接,让 serving runtime 容器能够在固定位置(例如 /mnt/models)找到模型数据。
示例 2-17 展示了创建 InferenceService 后生成的 Pod 定义。这里的关键点在于:通过创建链接,并把共享 emptyDir 卷挂载进去,使运行时能够跟随这个符号链接访问另一个容器中的文件系统。
示例 2-17. 使用 /proc 符号链接访问模型数据的 modelcar sidecar Pod
yaml
apiVersion: v1
kind: Pod
metadata:
name: sklearn-iris-oci-predictor-00001-deployment-7fd9c7fc67-dzdsz
namespace: default
spec:
shareProcessNamespace: true
containers:
- name: kserve-container
image: kserve/sklearnserver
args:
- --model_name=sklearn-iris-oci
- --model_dir=/mnt/models
volumeMounts:
- mountPath: /mnt
name: kserve-provision-location
- name: modelcar
image: rhuss/kserving-example-sklearn:1.0
args:
- sh
- -c
- ln -s /proc/$$$$/root/models /mnt/models && sleep infinity
volumeMounts:
- mountPath: /mnt
name: kserve-provision-location
volumes:
- name: kserve-provision-location
emptyDir: {}执行模型的 serving runtime。
把共享本地目录挂载到 /mnt,从而通过 /mnt/models 访问模型。
保存模型数据的 modelcar 镜像。
创建一个符号链接 /mnt/models,指向 modelcar 自身根文件系统中的模型目录;该目录通过 proc 文件系统暴露出来。在 YAML 中,$$$$ 最终会被替换成 $$,这是 shell 中表示当前 shell 进程 ID 的特殊变量。链接创建后,modelcar 会无限睡眠以保持容器存活。
声明共享的 emptyDir 卷,该卷会被 serving runtime 和 modelcar 同时引用。
虽然 modelcar 技术在优化 LLM 初始化方面非常有价值,但它也有一些明显缺点:
启动顺序
serving runtime 通常默认认为自己启动时模型数据已经存在。但在 modelcar 模式下,modelcar 容器与 runtime 容器是并行启动的。这可能导致 runtime 启动时,模型尚未准备好。
尽管 modelcar 容器本身启动很快,但如果 modelcar 镜像还需要先从 OCI Registry 拉取,那么启动时间会显著变慢。这个问题可以通过 Kubernetes sidecar 支持来缓解------自 Kubernetes 1.28 起,这是一项可选特性,它能确保 runtime 只有在 modelcar 初始化完成后才启动。
如果当前环境没有启用 sidecar 特性,也可以通过在 init-container 中预拉取 modelcar 镜像来降低竞争条件的风险,从而保证真正启动 modelcar sidecar 时,其 OCI 镜像已经存在于集群节点上。
安全性
启用 shareProcessNamespace 意味着 Pod 中定义的所有容器,其进程命名空间和文件系统都可能被相互访问。尤其在还有其他 sidecar 的情况下,这一点必须格外小心。
一个典型例子是 Istio 服务网格,它通过 sidecar 提供功能。Istio sidecar 默认假定自己是完全隔离的,因此不会额外隐藏诸如其上游 Istio daemon 的访问配置等敏感信息。正如某些安全报告展示的那样,如果本地 Istio 配置没有进一步加密,就很容易被利用。
因此,在使用 Istio 或 Knative 这类会自动注入 sidecar 的工具和平台时,理解这一后果至关重要。
启动时间不一致
根据模型 OCI 镜像是否已经被加载到 Kubernetes 节点的 OCI 运行时中,实际 serving runtime 的启动时间可能截然不同:快的时候几乎立刻启动,慢的时候则要等上几分钟,直到一个潜在很大的模型镜像从 registry 下载完成。
为了让启动时间更可预测,尤其是在 scale-to-zero 场景下,可以使用镜像预取等优化技术。
多架构支持
Modelcar 需要有一个活跃进程来维持 sidecar 存活,而这个进程本身是 CPU 架构相关的。因此,如果你想在多架构环境中使用 modelcar 镜像,就必须为每种 CPU 架构各自构建一个 modelcar 副本。
这些镜像里包含的是相同的机器学习模型,因此会造成资源浪费。
不过,BuildKit、umoci 或 skopeo 这类工具可以通过创建带 manifest list 的多架构镜像来缓解这一重复------它们会在不同平台之间共享那些与架构无关的层(例如模型数据层),只复制与架构相关的可执行层。这种做法利用了 OCI 的 content-addressable storage 机制,在推送到 registry 时自动去重共享层。
所有这些缺点,都可以被真正的 OCI image volume mounts 解决。幸运的是,Kubernetes 1.35 已经以 beta 特性的形式提供了 OCI image sources for volumes。虽然它距离普遍可用还需要一些时间,但在此之前,modelcars 是一个非常好的过渡技术,而且未来升级到 OCI image volume mounts 的路径也很平滑。
OCI Image Volume Mounts
从 Kubernetes 1.31 开始,Pod 可以直接把 OCI 容器镜像挂载为卷,而不需要先复制模型数据。
这一特性为访问存储在 OCI 镜像中的大型模型制品提供了高效方法,同时减少了初始化时间和存储开销。
与 modelcar 方案(见"Modelcars")相比,直接 image mount 的优势在于:它不再需要符号链接,也不需要共享进程命名空间。相反,模型数据可以直接作为挂载卷从镜像层中读取,并受益于底层 OCI 镜像层缓存。
示例 2-18 展示了如何使用 OCI image volume mount,让 vLLM 直接服务模型。
示例 2-18. 通过本地挂载的 LLM 使用 vLLM 提供服务的 Pod
yaml
apiVersion: v1
kind: Pod
metadata:
name: llm-server
spec:
containers:
- name: main
image: vllm/vllm-openai:latest
args:
- "--served-model-name"
- "meta-llama/Meta-Llama-3-8B"
- "--model"
- "/mnt/models"
volumeMounts:
- name: model-volume
mountPath: /mnt/models
subPath: models
volumes:
- name: model-volume
image:
reference: quay.io/meta-llama/meta-llama-3.2-8b
pullPolicy: IfNotPresent 这里使用的运行时镜像是 vLLM,用于提供模型服务。
把挂载后的模型绝对路径作为启动参数传给 vLLM。
把 OCI 镜像的内容挂载到 /mnt/models。
subPath 字段表示只挂载镜像中的特定子目录,而不是整个镜像根目录。这里使用 models 作为子路径,与典型的 modelcar 镜像结构保持一致,从而具备向前兼容性。
image: 表示这是一个用于挂载的 OCI image 类型卷。镜像拉取遵循标准语义:如果没有显式指定 pullPolicy,且 tag 是 latest,就总是拉取;否则,只有当节点上不存在该镜像时才会拉取。
也可以显式指定拉取策略。
Image volume 支持 subPath 和 subPathExpr,允许你只挂载 OCI 镜像中的某个子目录,而不是整个镜像根目录。
subPath 对于与 modelcars 的前向兼容尤其重要。只要你把模型数据放在 OCI 镜像中的 /models 子目录,并通过 subPath: models 来挂载,那么同一份镜像就能同时兼容 modelcar 方案和原生 OCI image volume。
这样一来,你就可以在无需重建模型镜像的前提下,从 modelcars 平滑迁移到原生 image volume。
不过,到 2026 年初为止,这项 image volume mount 特性仍存在一些限制:
容器运行时支持方面:CRI-O v1.33+ 提供完整支持;containerd 需要 v2.2.0+ 才能支持 beta 功能(v2.1.0+ 仅支持基础能力)。
Feature gate 必须显式开启(默认仍然关闭)。
该特性不支持可写层;卷仍然是只读的。
只支持目录挂载;不能直接挂载单个文件。
社区正在积极解决这些限制,未来计划加入签名校验、压缩层和读写支持等能力。随着能力成熟,这项特性最终将成为 Kubernetes 上服务 LLM 的首选方式,并逐步替代 modelcar 方案。在此之前,modelcars 仍然是直接访问 OCI 镜像中模型数据的一种可靠方案。
经验总结
本章我们探讨了如何在 Kubernetes 中打包、存储和访问模型数据,从存储格式一直讲到部署策略。
模型数据访问策略本质上涉及存储效率、访问性能和运维复杂度之间的权衡。表 2-3 总结了各方案的关键特征。
表 2-3. 模型数据访问策略对比
| 方案 | 存储效率 | 访问速度 | 启动时间 | 最适合 | 局限 |
|---|---|---|---|---|---|
| Init Container Copy | 低 | 快 | 慢 | 每节点单副本、对延迟敏感的推理 | 浪费节点存储、初始 Pod 创建慢、重复复制 |
| PersistentVolume | 最高 | 中等 | 快 | 多副本、中等规模、外部模型管理 | 依赖网络、基础设施开销大、扩展到数百副本时困难 |
| Modelcar | 高 | 快 | 中等 | 多模型共享基础层、存储高效 | 需要 OCI 打包、需要进程命名空间共享、有安全考量 |
| OCI Volume Mount | 高 | 快 | 中等 | 多模型、原生 Kubernetes 集成 | Beta 特性(K8s 1.35+)、运行时支持有限 |
Init container copying 通过节点本地 I/O 提供了最快的推理性能,因此非常适合对延迟敏感的工作负载。
但这种方案在运行多个副本时会浪费存储,因为每个节点都要维护自己的模型副本。
当你是单副本或低并发场景,并且可以接受较慢启动来换取最高推理性能时,这种策略是合适的。
PersistentVolume 通过只存一份模型并在所有副本之间共享,提供了最高的存储效率。
这种效率的代价,是每次读取模型文件都要承受网络延迟。
PV 在几十个副本规模时通常表现良好,但扩展到上百副本时,容易因后端饱和和网络争用而出现问题。
当存储成本比峰值推理性能更重要,或者模型由数据科学家通过外部分布式文件系统管理时,PV 是合理选择。
基于 OCI 镜像的方案(modelcars 与 volume mounts)提供了一种折中:一方面通过层共享获得较高存储效率,另一方面又具备快速的本地访问能力。
作为标准化格式,OCI 还天然支持跨 registry 的模型分发与发现。
Modelcars 现在就可用,但需要共享进程命名空间,并带来一定安全考量。
OCI volume mounts 则作为原生 Kubernetes 特性,集成更加干净,但到 Kubernetes 1.33 仍处于实验性阶段。
当你运行多个共享同一基础模型的微调模型时,这两种方式尤其有优势,因为通用层可以在所有实例之间共享。
对于复杂环境,可以考虑混合策略。
例如,开发环境中可以用 PersistentVolume,以便更容易更新模型;而生产环境则使用 OCI volume,以获得更好的性能和可靠性。
不同级别的模型也可以采用不同方式:高频访问的模型用 OCI 镜像以追求速度,而不那么关键的模型则共享 PersistentVolume,以节省成本。
随着 OCI volume mounts 逐渐成熟并获得广泛运行时支持,它很可能会成为大多数部署场景中的首选方案。
至此,第一部分结束。
你现在已经具备了在 Kubernetes 上部署 LLM 的基础:包括 serving runtime、生命周期控制器,以及管理模型数据的策略。
下一部分将在这个基础上继续展开,讨论在生产环境中运行推理工作负载所需的能力,包括 GPU 管理、扩缩容和可观测性。