Workato 的 AI 研究实验室专注于帮助客户利用智能体 AI 能力扩展生产自动化,这些系统可以推理、执行并协调跨业务的工作。目前,Workato 服务 超过 12,000 家全球企业客户,例如 Broadcom(博通)、Intuit(财务软件领域的 SaaS 巨头)、Box 等公司。
在 Workato 的业务规模下,每月需处理 1 万亿次自动化工作流,LLM 推理效率是硬性要求:每毫秒延迟和每个浪费的 GPU 周期直接影响成本、吞吐量和可靠性。为了使智能体(AI Agent)工作负载达到生产就绪状态,团队需要一个为生产规模设计的推理栈------提供可预测的性能和规模化下的单位经济效益,而不仅仅是原始算力。
DigitalOcean 与 Workato 的 AI 研究实验室团队合作,在其智能推理云上设计和调优这个部署,使用 NVIDIA Dynamo 搭配 vLLM 运行在 DigitalOcean Kubernetes 托管服务(DOKS) 上。为了支持 100K Token 上下文长度而不降低性能,Workato 选择了 NVIDIA H200 GPU 云服务器,因为它的显存有 141GB HBM3e。
工作负载的内存占用约为 125 GB(包括模型权重、键值缓存和激活缓冲区),因此单个 NVIDIA H200 GPU 能够容纳整个 footprint。然而,团队在每个节点使用 8 路张量并行来最大化持续吞吐量和并发负载下的延迟稳定性。
DigitalOcean 针对 Workato 的需求帮助他们最终实现了:
- 在所有测试配置中实现最高的每秒查询数
- **每 GPU 吞吐量提升 67%, 端到端延迟降低 79%,首 Token 时间降低 77%**(与相同硬件上的不同配置相比)
- 使用 NVIDIA H200 GPU vs NVIDIA A100 GPU 达到相同性能,硬件成本降低 33%
- **模型成本降低 67%**,同时使用的 GPU 数量减少一半
关键在于引入键值(KV)感知路由,以减少冗余并在推理栈中最大化性能和成本的价值。
本文,我们将详细拆解 DigitalOcean 是如何帮助 Workato 的 AI 研究实验室团队实现这些优化成果的。如果你的团队也在追求同样的目标,欢迎联系卓普云(aidroplet.com)进一步了解 DigitalOcean 云平台的各项 AI 相关产品与云服务。
LLM 如何处理请求以及为什么规模化后成本变高
在讨论架构决策之前,值得先理解驱动推理成本 mechanics 以及为什么这是一个 Workato 需要解决的复杂问题。每个 LLM 推理请求都经过两个阶段:
- Prefill 是模型处理整个输入提示词并为它读取的每个 Token 构建内部内存(称为键值/KV 状态)的阶段。这个阶段是计算密集型的,与输入序列长度呈二次方复杂度(O(n²))。对于长上下文工作负载(例如 10K-100K Token 提示词),prefill 可能占据总推理成本的大部分。主要原因是模型需要为提示词中的每个 Token 计算与其他所有 Token 的自注意力分数。例如,如果提示词是 1000 个 Token,模型大约执行 1000 × 1000 次注意力运算。如果提示词是 100,000 个 Token(与 Workato 的工作负载相同),这些运算会激增到 100 亿次。100K Token 的 prefill 需要每秒大量浮点运算(FLOPs),可能需要 GPU 满负荷运行数秒,导致每 GPU 吞吐量降低,直接增加成本。
- Decode 是模型使用缓存的 KV 状态逐个生成 Token、预测下一个 Token 的阶段。这个阶段受限于显存带宽;decode 阶段的性能直接影响 Token 流式输出的延迟。
存在真实的工作负载共享公共输入前缀,其中很大一部分相同的文本块在多个请求中重复使用。在企业 SaaS 应用(如 Workato 的 AI 研究实验室)中,推理请求之间通常存在高度的 Prefix 共享。当 GPU 执行 prefill 操作时,它会构建内存中的上下文(KV 缓存),这对于长提示词工作负载来说构建成本很高。
现在,如果后续查询都被路由到不同的 GPU,每个 GPU 都需要重建 KV 缓存,导致消耗冗余的 FLOPs,而这些 FLOPs 本可以用于服务其他查询。
KV 感知路由如何解决这个问题
KV 感知路由是一种利用前缀共性并将它们路由到同一 GPU 的技术。这有助于使 GPU 能够利用预热的 KV 缓存(通常通过 RadixCache)完全跳过计算密集的 prefill 阶段。
这有助于大幅降低用户的首 Token 延迟(TTFT),并通过回收本会花在冗余 prefill 计算上的 GPU FLOPs 来显著提升集群的总吞吐量。
NVIDIA Dynamo + DOKS:KV 感知路由的编排大脑
NVIDIA Dynamo 是一个开源的、低延迟的、模块化推理框架,设计用于在各个推理引擎之上运行。它与引擎无关,可以编排 vLLM(这就是我们在这里使用的)、TensorRT-LLM 和 SGLang 等后端。Dynamo 不是为了让单个 GPU 更快而设计的,而是为了防止集群做冗余工作并让正确的 GPU 保持在正确的推理阶段忙碌。在 Workato 的场景中,我们使用 Dynamo 的 KV 感知路由能力。 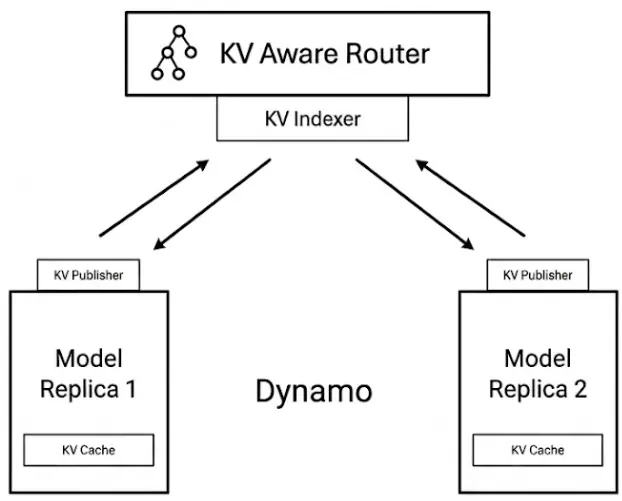
NVIDIA Dynamo 通过引入复杂的编排层改变了标准 LLM 基础设施,其能力远远超过普通多节点设置。Dynamo 的核心是一个全局调度器,全面了解集群中的每个 GPU,超越了只能看到自己本地资源的 worker 的局限性。这种全局视角由集群级 KV 缓存管理器管理,该管理器精心跟踪哪些 Token 驻留在特定的 worker 上,识别哪些块是"热"的或可以驱逐的,并确定重用、卸载或重新计算各种缓存段的最佳时机。
这个架构的定义特性是 KV 感知路由器,它用 LLM 感知的请求路由取代了传统的、"盲目的"轮询分配。路由器不是将所有 worker 视为平等的,而是使用复杂的成本函数根据现有缓存重叠和系统指标之间的关键权衡对候选 worker 进行评分。具体来说,它平衡了最小化 prefill 成本的需求(改善首 Token 时间 TTFT)与有效 decode 性能的要求,如 Token 间延迟(ITL)和每输出 Token 时间(TPOT)。通过整合对全局缓存状态的实时感知,Dynamo 确保路由决策是全局最优的,从而实现无缝的 KV 缓存卸载和跨不同请求的最大化重用。
然而,部署像 NVIDIA Dynamo 这样的集群感知推理栈会引入真正的运营复杂性。你不再是在负载均衡器后面运行几个 vLLM 服务器,而是在运行一个分布式系统,包含路由前端、检测过的 worker 后端、KV 缓存管理器,以及它们之间的实时协调。要做到这一点,既需要正确的框架,也需要支持它的平台。虽然 NVIDIA Dynamo 提供了逻辑,但 DOKS 提供了使 KV 感知路由成为可能的执行环境。DOKS 不仅仅是"运行"pod;其原生服务发现机制和智能调度允许 Dynamo 前端充当集群范围的调度器。这确保传入的请求被即时路由到相关 KV 缓存已经存在的特定 GPU 节点,从而消除冗余计算并从完整推理栈中获取最大价值,具体包括:
- 路由前端和 worker 后端的独立副本管理意味着团队可以在调优配置时分别扩展每一层。
- Kubernetes 原生的服务发现机制让路由器前端干净地找到并路由到 worker pod,无需自定义网络工作。
- 运营简单性:DOKS 完全抽象掉控制平面,因此 Workato 的工程师可以专注于推理优化,而不是 Kubernetes 编排。
推理栈架构
我们使用 nvidia/Llama-3.3-70B-Instruct-FP8 作为模型,在各种 DOKS 集群上进行了评估:
- 1 节点,8 个 NVIDIA H200 GPU
- 2 节点,16 个 GPU
- 4 节点,32 个 GPU
我们还针对 NVIDIA Dynamo + vLLM(选择它是因为其广泛的特性覆盖和干净的集成界面)在两种配置下比较了每种拓扑:一种没有 KV 感知路由,另一种启用了 KV 感知路由。这将为 Workato 提供真正的性能-成本权衡空间地图,而不仅仅是单个数据点。
2 节点部署的完整集群架构如下:
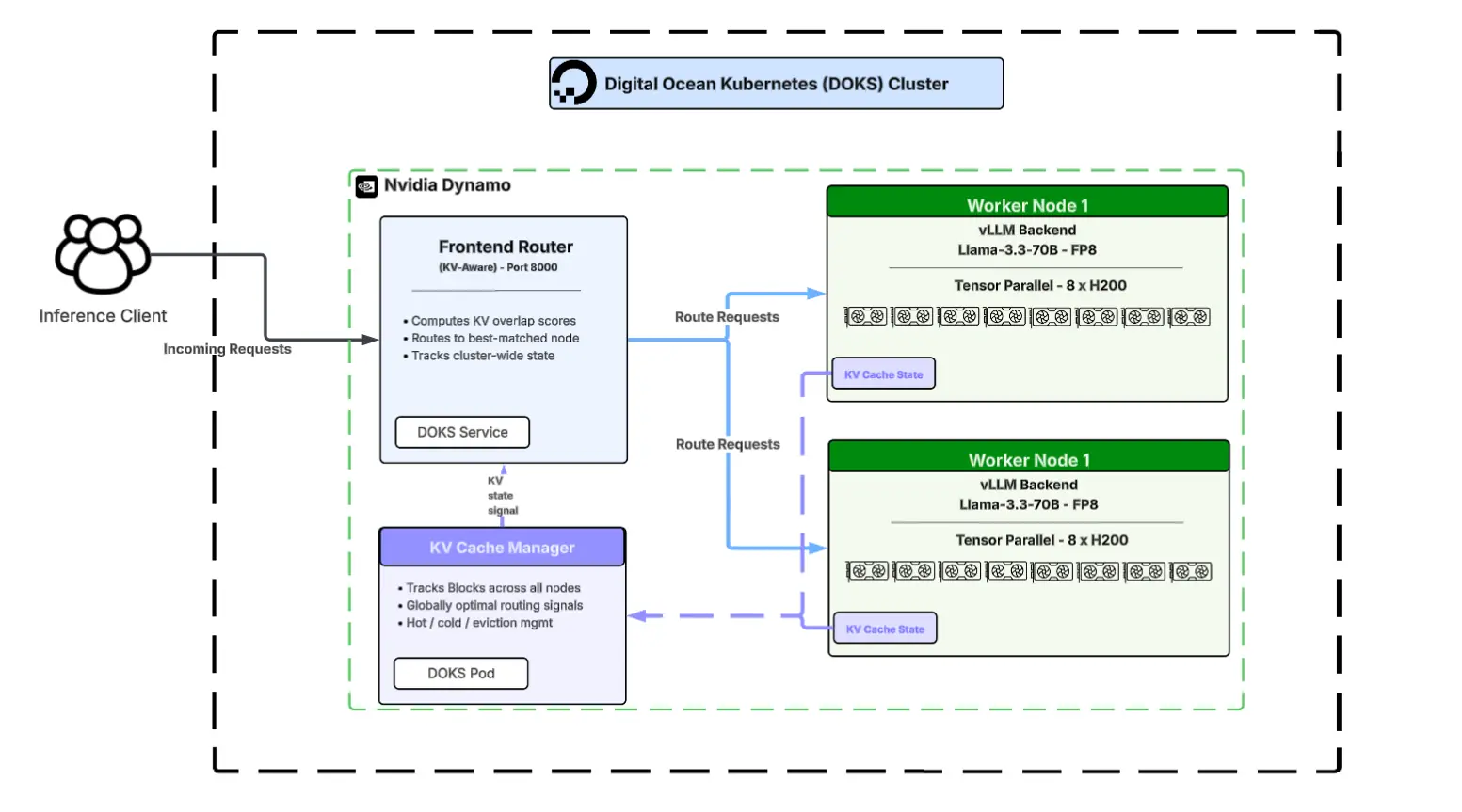
NVIDIA Dynamo 的前端路由器是位于 GPU worker pod 前方的轻量级 DOKS 服务。Worker 是配备 Dynamo 代理的完整 vLLM 实例,持续将 KV 缓存状态发布回路由器和缓存管理器。KV 缓存管理器是一个独立的 Pod,维护全局视图,跟踪哪些节点上的缓存是"热"的,发出驱逐信号,并向路由器的评分函数提供新鲜状态。将路由器、worker 和缓存管理器分离为独立的 DOKS 工作负载,使 Workato 能够独立调优每一层,并使架构能够随着工作负载需求的增长水平扩展。
两种测试配置
配置 1:无 KV 感知路由
此配置使用相同的模型、相同的 GPU,但启用了 vLLM 自己的优化:前缀缓存、块状 Prefill、FP8 权重和 KV 缓存。这不包含 KV 感知集群路由------每个节点做出智能的本地决策,但没有跨集群的全局缓存状态视图。
css
vllm serve nvidia/Llama-3.3-70B-Instruct-FP8 \
--tensor-parallel-size 8 \
--enable-prefix-caching \
--enable-chunked-prefill \
--quantization fp8 \
--kv-cache-dtype fp8 \
--trust-remote-code当此配置在 100K Token prefill 负载下运行时会发生什么?当两个提示词共享很长的公共前缀但落在不同的 worker 上时,两个节点都会冗余地重新计算相同的 prefill,因为双方都不知道对方已经完成的工作。在这种情况下,缓存局部性完全是偶然的------也就是说,一个请求是否受益于预热的 KV 缓存纯粹取决于运气,而不是战略性放置。这种缺乏协调导致严重负载不均衡的出现;一些 worker 被长 prefill 拖累,而其他 worker 处理 decode 重度流量,导致它们的处理队列发散。最终,在更高并发下尾延迟会激增,因为单个不幸的路由决策可能会将特定 worker 固定在多个重型 prefill 上,而其他可用资源却闲置。
配置 2:KV 感知路由
这是架构从根本上发生改变的地方,在我们测试的两种配置中,这是明显的赢家。总的来说,NVIDIA Dynamo 部署利用集群感知路由,将系统分为 1)前端(路由器 + 调度器),2)Worker 集合(配备 Dynamo 的 vLLM 实例)
Dynamo 前端(启用 KV 路由器)
css
python3 -m dynamo.frontend --http-port 8000 --router-mode kvNVIDIA Dynamo 前端主动计算与可用 worker 的 KV 重叠分数,并应用专门的路由成本函数来决定 prefill 和 decode 阶段应该精确在哪里执行。通过跟踪集群范围的负载和当前全局缓存状态,系统确保每个请求都以最大效率处理。在这种设置下,前端完全启用 KV 路由运行,以验证这些架构改进。
Worker(部署为 GPU 节点上的 DOKS pod):
每个 worker 都是通过 NVIDIA Dynamo 的包装器启动的 vLLM 实例。集成暴露了:
- KV 缓存事件:创建、重用或驱逐了哪些块
- 指标:队列深度、decode 负载、内存压力
配方:Dynamo + vLLM Worker
css
python3 -m dynamo.vllm \
--model nvidia/Llama-3.3-70B-Instruct-FP8 \
--tensor-parallel-size 8 \
--enable-prefix-caching \
--enable-chunked-prefill \
--quantization fp8 \
--kv-cache-dtype fp8 \
--trust-remote-code \
--enable-log-requests核心概念:KV 感知路由
对于每个传入请求和每个 worker,NVIDIA Dynamo 估计一个成本:
ini
cost = overlap_score_weight * prefill_blocks + decode_blocks其中:
- prefill_blocks:需要计算多少新 KV(缓存未命中成本)
- decode_blocks:worker 在 decode 端的繁忙程度
- overlap_score_weight:权衡 TTFT 与 decode 延迟
这将路由从盲目的负载均衡器 转变为状态感知的调度器。
调优
到目前为止,我们讨论了 NVIDIA Dynamo + vLLM 之所以有效的原因:KV 感知路由、分离的 prefill/decode 和集群级调度。但在实践中,除非正确转动正确的旋钮,否则这些都没有意义。
我们将使用 Workato 的结果来分解这一点,并关注三个关键指标:
- **TTFT(首 Token 时间)**:请求到达后第一个 Token 产生的速度。
- **TPOT / ITL(每输出 Token 时间 / Token 间延迟)**:后续 Token 生成的速度。
- **吞吐量(QPS / 每 GPU 每秒 Token 数)**:系统可以处理的持续工作。
TTFT:Prefill 成本与 KV 重用
首 Token 时间(TTFT)由 prefill 工作主导,即模型处理提示词构建 KV 状态的时间。这里的调优旋钮是:
--enable-prefix-caching:为共享前缀重用 KV 块。--enable-chunked-prefill:将 prefill 分割成可管理的块以避免 GPU 停滞。--kv-cache-dtype fp8:减少显存占用和压力,改善缓存驻留能力。
为什么 NVIDIA Dynamo 表现出色:Dynamo 将请求路由到大多数 KV 前缀已经缓存的 worker,避免冗余 prefill。即使在 高并发(32 个提示词)下,TTFT 优势也很明显。
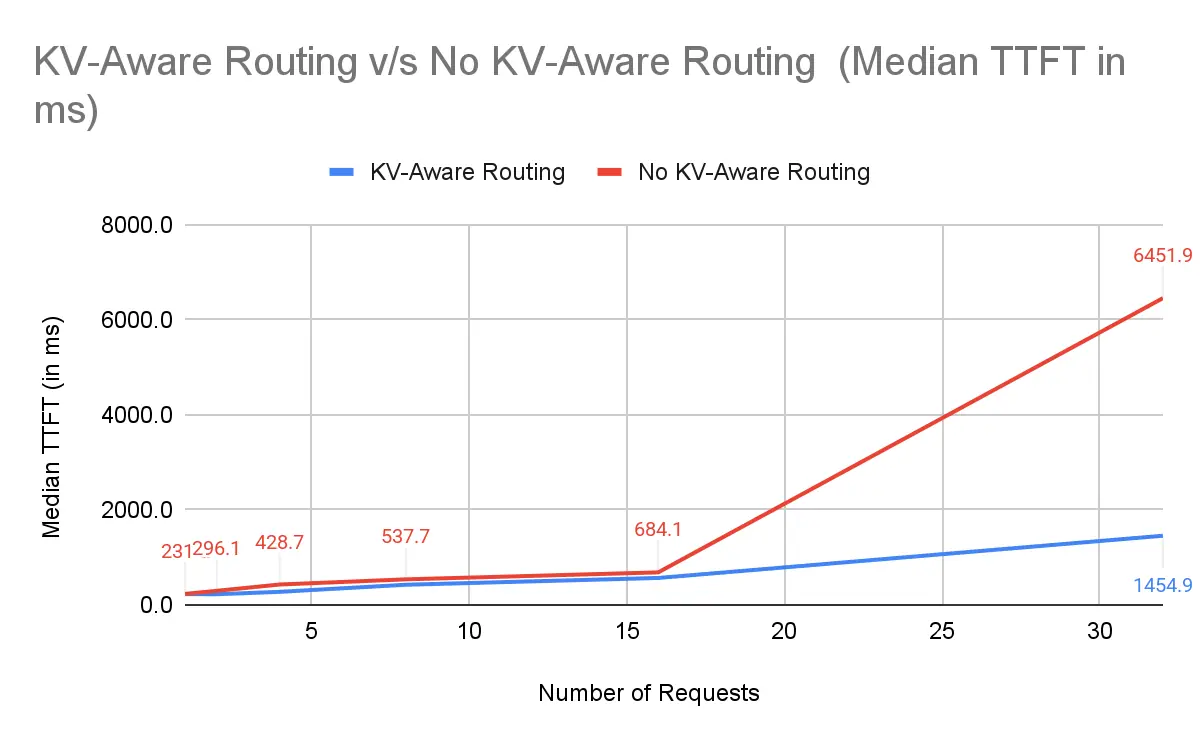
中位 TTFT(ms)(2 节点,16-32 个请求):
| 请求数 | NVIDIA Dynamo KV 感知路由 | 无 KV 感知路由 | 提升幅度 |
|---|---|---|---|
| 16 | 566.7 | 684.1 | +17.2% |
| 32 | 1454.9 | 6451.9 | +77.5% |
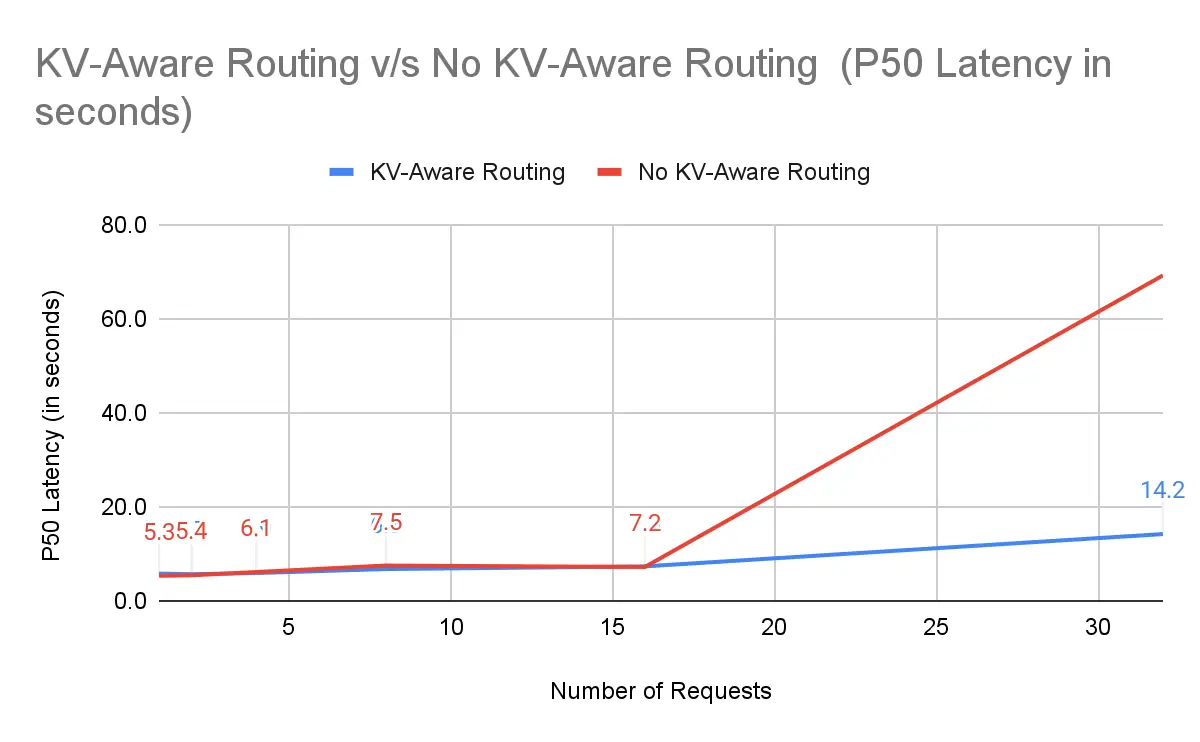
P50 延迟(s)(2 节点,16-32 个请求):
| 请求数 | NVIDIA Dynamo KV 感知路由 | 无 KV 感知路由 | 提升幅度 |
|---|---|---|---|
| 16 | 7.3 | 7.2 | -1.4% |
| 32 | 14.2 | 69.2 | +79.5% |
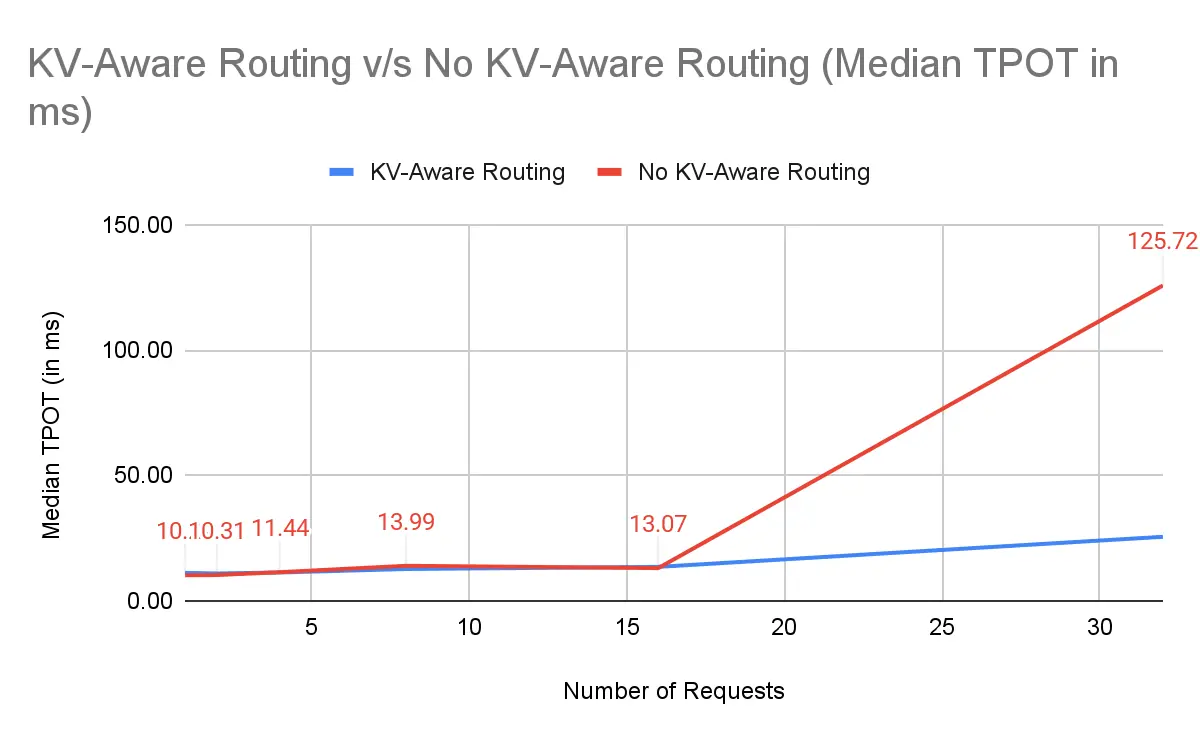
TPOT / ITL:Decode 负载均衡
TPOT 和 ITL 取决于 GPU 在 decode 期间的繁忙程度。块状 prefill 防止单个重型请求阻塞 decode 管道。NVIDIA Dynamo 进一步跨 worker 平衡 decode 负载,即使在突发情况下也能保持 TPOT 稳定。
数据快照(2 节点,16-32 个请求):
| 请求数 | NVIDIA Dynamo KV 感知路由 | 无 KV 感知路由 | 提升幅度 |
|---|---|---|---|
| 16 | 13.57 | 13.07 | -3.8% |
| 32 | 25.55 | 125.72 | +79.97% |
没有前缀感知路由,朴素的 vLLM 在高并发下崩溃,因为一些 worker 收到"prefill 重"的请求而其他则空闲,导致 TPOT 和尾延迟膨胀。
Dynamo 的优点:
- KV 重用:避免重新计算大型 prefill 段
- 路由:将请求发送到具有热 KV 缓存的 worker
- 调度:平衡 decode 负载,防止热点 GPU 拥塞
QPS 和 Token 吞吐量:GPU 利用率
在 SLA 下每 GPU 的吞吐量(Token/秒/GPU):
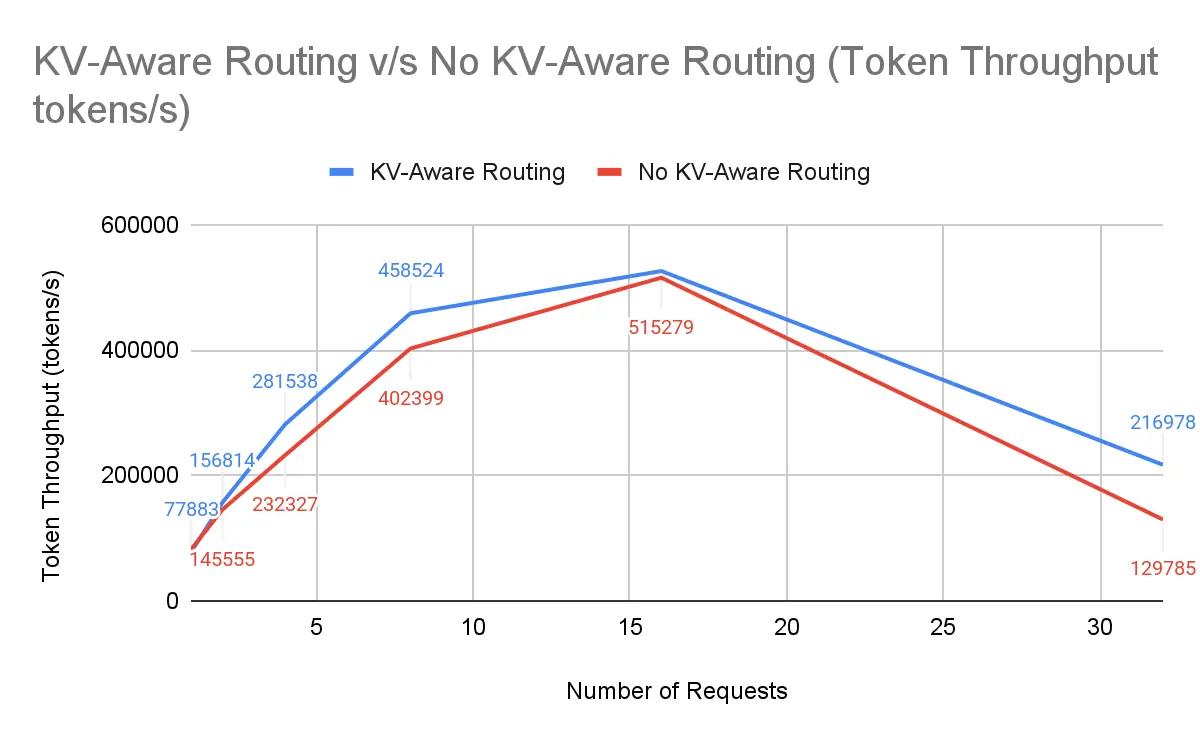
数据快照(2 节点,16-32 个请求):
| 请求数 | NVIDIA Dynamo KV 感知路由 | 无 KV 感知路由 | 提升幅度 |
|---|---|---|---|
| 16 | 525,898 | 515,279 | +2.06% |
| 32 | 216,978 | 129,785 | +67.19% |
通过 KV 感知路由,我们实现了每 GPU 13,561 Token/秒,而没有 KV 感知路由时是 8,111 Token/秒,**在相同硬件上提升了 67%**。这一改进从根本上改变了容量需求。对于固定的 SLA 和 Token 吞吐量目标,GPU 数量与每 GPU 吞吐量成反比。1.67 倍的吞吐量增益意味着每个 GPU 现在执行 1.67 个基准 GPU 的工作,将所需容量减少到原始占用的大约 60%,或者相同工作负载减少 40% 的 GPU。实际上,以前需要 10 个 GPU 的部署现在大约可以用 6 个 GPU 维持相同的负载。
更少的 GPU 意味着更少的节点、更低的每小时消耗和更少的扩展开销。每 GPU 更高的吞吐量不仅仅让系统更快:它减少了服务相同负载所需的 GPU 数量,将性能提升转化为可衡量的成本节约。
最后总结一下
Workato 在 DigitalOcean 智能推理云上的结果表明,规模化下的推理性能更多地取决于系统如何围绕模型架构,而不是模型本身。
对于长上下文、高并发工作负载,冗余的 prefill 计算和不均衡的 decode 负载迅速成为主要的成本和延迟驱动因素。仅仅增加 GPU 数量无法解决这些低效问题。协调路由和缓存感知调度可以做到。
通过在 DOKS 上部署 NVIDIA Dynamo + vLLM 并启用 KV 感知路由,Workato 消除了冗余的 prefill 工作,改善了 worker 之间的负载均衡,并在并发下稳定了延迟。在相同硬件上,这转化为每 GPU 每秒 Token 数提升 67%,负载下端到端延迟降低高达 79%,TTFT 降低 77%------从而降低每个 Token 的成本,并减少满足 SLA 所需的 GPU 数量。
关键结论是架构层面的:推理效率主要是一个系统问题。当路由、缓存管理、GPU 拓扑和 Kubernetes 编排协调一致时,收益会叠加。
最后,如果你希望测试体验 DigitalOcean GPU 云服务器以及 AI 推理云产品,欢迎联系 DigitalOcean 中国区独家战略合作伙伴卓普云。另外,DigitalOcean 即将在 2026 年初上线 NVIDIA B300 GPU 服务器,现在可预约测试,预约渠道 :卓普云官网 aidroplet.com。