文章目录
- 一、定义
- [二、 为什么以及时间线](#二、 为什么以及时间线)
-
- [2.1 起源追溯](#2.1 起源追溯)
- [2.2 ReAct框架的诞生](#2.2 ReAct框架的诞生)
- [2.3 自动化工具学习](#2.3 自动化工具学习)
- [2.4 标准化的API](#2.4 标准化的API)
- [2.5 多样化的探索](#2.5 多样化的探索)
- [2.6 多智能体协作](#2.6 多智能体协作)
- [2.7 生态成熟期](#2.7 生态成熟期)
- 三、工具调用流程
- 四、工具调用评估
- 五、实践中提升工具调用效果
- 六、信息来源
一、定义
大模型**工具调用(Function Call / Tool Use)**是一种让语言模型能够主动调用外部API、函数或工具来完成其自身无法执行任务的技术机制,通过"推理-行动-观察"(ReAct)的循环模式,将大模型的文本理解能力与外部世界的执行能力无缝连接。
二、 为什么以及时间线
2.1 起源追溯
工具调用核心驱动力来自三个现实需求:大模型推理能力有限,需要外部知识 补充;大模型无法直接访问实时信息 ;大模型缺乏执行实际操作 的能力。
当GPT-3展现出惊人的zero-shot能力时,研究者们开始思考:如果模型不仅能理解问题,还能主动去获取答案,会发生什么?
PS:要主要到,LLM本身并没有真的在"执行"工具,只是产出调用工具的格式化输出,后面流程中还会提到。
2.2 ReAct框架的诞生
2022年10月,Princeton大学的Shunyu Yao等人发表了《ReAct: Synergizing Reasoning and Acting in Language Models》论文。这篇论文成为工具调用领域的奠基之作。
ReAct 的核心创新在于将"推理"(Reasoning)和"行动"(Acting)有机结合。它创造了一个三元组结构:Thought-Action-Observation。模型先思考需要做什么,然后执行一个行动,观察结果后再继续思考。
在HotpotQA任务上,ReAct显著提升了性能。更重要的是,它证明了工具调用可以减少幻觉。当模型需要事实性信息时,它可以通过调用Wikipedia API来获取,而不是依赖可能错误的训练数据。
ReAct范式确立了一个新的交互模式:模型不再是被动的回答者,而是主动的信息获取者和问题解决者。这个范式至今仍然是工具调用的核心框架。
此时注意依靠的是设计精致的prompt。
2.3 自动化工具学习
2023年2月,Meta AI的Timo Schick等人发表了《Toolformer: Language Models Can Teach Themselves to Use Tools》论文。这篇论文解决了一个关键问题:如何让模型自动学会使用工具,而不需要大量的人工标注?
Toolformer的方法很巧妙。它使用LLM生成文本中潜在的API调用位置和参数(通过in-context prompt),执行这些API调用,然后基于结果是否降低困惑度来决定是否保留。最后用筛选后的数据微调模型。
这个方法的创新点在于自监督学习。模型自己教自己何时使用工具、如何使用工具。支持的计算器、问答系统、搜索引擎、翻译器、日历、地图等6类工具,都是通过这种方式学会的。
Toolformer证明了工具使用不需要人类专家精心设计提示词或标注数据。模型可以通过与环境的交互,自主发现和掌握工具的使用方法。这个思想对后续的研究产生了深远影响。
2.4 标准化的API
2023年6月,OpenAI在gpt-3.5-turbo-0613和gpt-4-0613中正式推出了函数调用功能。这是工具调用走向工业标准的关键一步。
OpenAI引入了functions和function_call参数,模型能够输出符合JSON Schema的结构化参数。它能够自动检测何时需要调用函数,支持多函数并发调用。最关键的是,它提供了可靠的JSON输出。
在模型训练阶段,就使用大量的数据教会模型什么时候该调用模型,应该如何生成调用参数。开发者使用时,不再需要复杂的提示词工程,只需要在tools参数中传入可用的工具schema,模型就能学会如何使用。这个设计成为后续很多产品模仿的对象,包括Anthropic的Tool Use、Mistral的Function Calling等。
2.5 多样化的探索
2023年下半年,工具调用领域呈现出多样化的探索趋势。
Gorilla是UC Berkeley发布的一个专门用于API调用的模型。它在API调用准确率上超越了当时的GPT-4,重点解决了API文档理解和参数映射问题。这个工作证明了,专门的模型在特定任务上可以超越通用大模型。
Chameleon提出了"插件即模型"的概念,支持动态工具选择和组合。它将工具视为模型的可插拔组件,根据任务需求动态加载和卸载。
ToolLLM系统性研究了工具学习的数据和方法,构建了工具评测基准ToolBench。这个基准包含1646个真实API工具,涵盖了49个类别,为工具调用的评估提供了重要参考。
这些工作从不同角度推动了工具调用技术的发展:有的追求更高的准确率,有的探索更灵活的架构,有的建立评估标准。
2.6 多智能体协作
2023年底,工具调用的研究开始向多智能体协作方向发展。
CAMEL框架提出了多智能体协作模式,通过角色分工实现复杂任务分解。一个智能体负责规划,另一个负责执行,第三个负责评估。这种分工协作模式可以完成单个智能体难以处理的复杂任务。
AutoGPT虽然稳定性有限,但它引发了广泛关注。它展示了AI如何自主规划、执行、反思、修正,形成一个完整的任务执行循环。虽然早期的实现还很粗糙,但它预示了未来的可能性。
多智能体协作意味着工具调用不再是单打独斗,而是多个智能体通过协调合作,完成更加复杂的任务。这是从"工具调用"向"智能体编排"的重要转变。
2.7 生态成熟期
2024年,工具调用技术进入了生态成熟期。
标准化方面,OpenAI不断完善函数调用功能,Anthropic推出了标准化的工具调用接口,Google DeepMind在Gemini中集成了工具使用能力。虽然各家API设计略有差异,但核心思想已经趋于一致。
工具生态爆发,各种专业工具API涌现:代码解释器、数据分析、图像处理、数据库查询、文件操作等等。开发者可以像搭积木一样,将这些工具组合起来,构建复杂的AI应用。
开源工具调用框架出现,LangChain成为最流行的选择,它提供了统一的抽象层,支持多种大模型的工具调用。此外还有Semantic Kernel、AutoGen、Guidance等框架,各有特色。
技术优化方面,多工具协同调用、工具调用的高效检索、安全性增强、自我反思和纠错能力等都在持续改进。
三、工具调用流程
LLM并没有真的亲自运行工具 ,只是决策使用哪个/哪些工具,然后输出结构化的工具调用方式。本地根据大模型的输出进行真正的工具调用,然后将得到的工具结果返回给大模型,继续进行回答(可能LLM判断需要再次进行工具调用,或者根据工具调用的结果得到整合后的回答)。
所以对LLM的优化,重点在于让模型判断什么时候该调用什么工具,输出的格式是什么样子
流程图
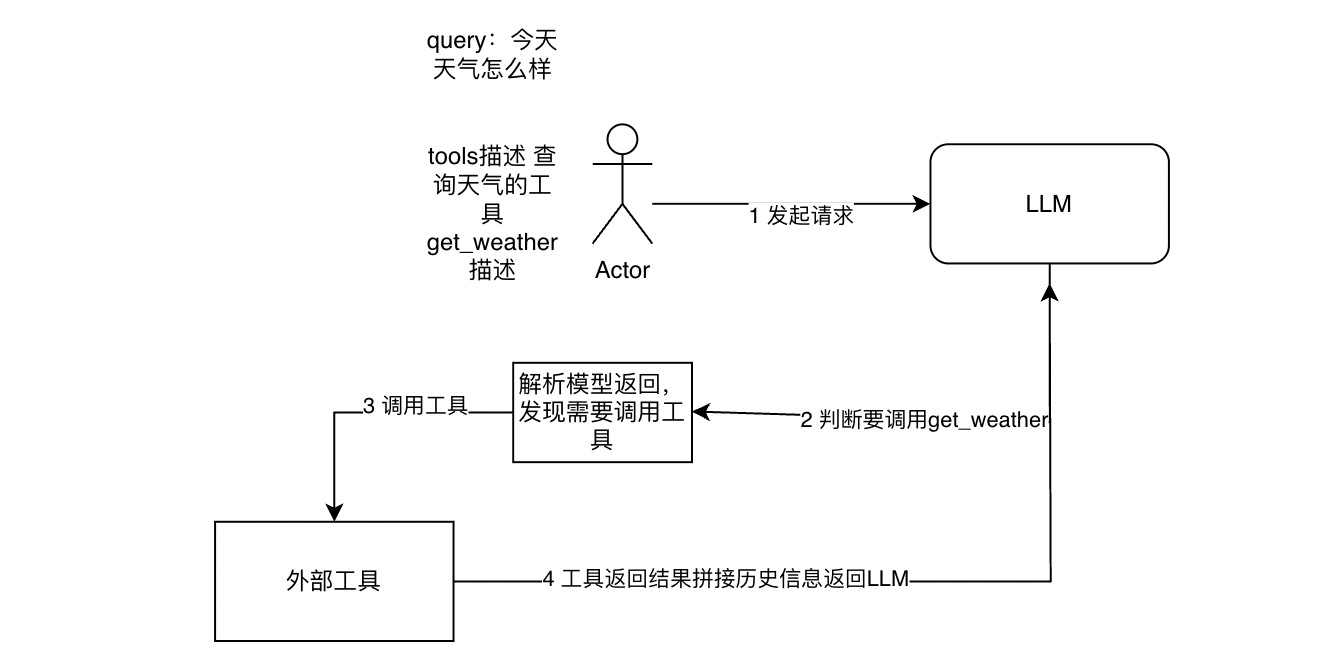
四、工具调用评估
评估工具调用大概有这么几个思路:
- 端到端效果,with tool use的最终效果是否比没有添加工具好
- 手动标记工具应该使用情况,和实际调用情况进行比较
- 利用更好的模型进行整体评估
- 其他指标,如工具调用轮次(过多往往意味着有问题)、工具选择准确性等(正确的路有到合适领域的工具)
五、实践中提升工具调用效果
工具描述的质量对结果影响非常非常大
应当清楚描述工具的作用、使用边界,可以增加可以做什么不可以做什么的使用说明,when to use limitations等说明
-
工具数量 超过15个,大量占用token而且效果会下降 https://tianpan.co/zh/blog/2026-04-09-tool-selection-problem-agent-tool-routing-at-scale
-
静态选择。通过向量比较相似度,选择topK 工具子集合提供给模型
-
混合检索。 向量相似度+关键词,对于一些专业领域,关键词反而效果更好
-
分层路由。先用分类器(或者小的LLM)决定选择哪个类别的工具,再在子类别中进行筛选
-
随着对话的进行,新的context可能需要筛选新的工具类别
-
多个子智能体调用工具,可以将智能体和工具说明一起转为embedding比较
六、信息来源
-
ReAct: Synergizing Reasoning and Acting in Language Models (2022) - arXiv:2210.03629 - https://arxiv.org/abs/2210.03629
-
Toolformer: Language Models Can Teach Themselves to Use Tools (2023) - arXiv:2302.04761 - https://arxiv.org/abs/2302.04761
-
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models (2022) - https://arxiv.org/abs/2201.11903
-
ToolBench: Open Large-Scale Tool Learning (2023) - arXiv:2307.16789 - https://arxiv.org/abs/2307.16789
-
ToRA: Tool-Integrated Reasoning Agent (2023) - arXiv:2309.17452 - https://arxiv.org/abs/2309.17452
-
Gorilla: Large Language Model Connected with Massive APIs (2023) - arXiv:2305.15334 - https://arxiv.org/abs/2305.15334
-
Chameleon: Plug-and-Play Compositional Reasoning (2023) - arXiv:2304.09842 - https://arxiv.org/abs/2304.09842
-
OpenAI Function Calling - https://platform.openai.com/docs/guides/function-calling
-
Anthropic Tool Use - https://docs.anthropic.com/en/docs/build-with-claude/tool-use
-
Google Gemini Function Calling - https://ai.google.dev/gemini-api/docs/function-calling
-
Llama Documentation - https://llama.meta.com/docs/
-
Mistral Documentation - https://docs.mistral.ai/
-
https://tianpan.co/zh/blog/2026-04-09-tool-selection-problem-agent-tool-routing-at-scale
-
LangChain - https://github.com/langchain-ai/langchain
-
Semantic Kernel - https://github.com/microsoft/semantic-kernel
-
AutoGen - https://github.com/microsoft/autogen
-
Guidance - https://github.com/microsoft/guidance
-
AgentVerse - https://github.com/OpenBMB/AgentVerse