AI编辑器开源主模型搭配本地模型辅助对标GPT5.2/GPT5.4/Claude4.6(前端开发专属)
前言
本文是从一个前端从业者角度,整合现有资源进行聚合互补,达到对标一线模型的优化方案。仅代表个人看法。
背景(核心痛点)
在前端开发、项目重构及技术方案设计的全流程中,AI模型的选型直接决定开发效率、代码规范度及复杂项目的落地质量;当前主流AI编辑器内置的国际一线编程模型,存在使用成本偏高的问题,导致长期使用会给个人开发者及中小型团队带来不小的成本压力。
与此同时,如何利用现有开源模型资源,实现"低成本、高质量"的前端开发,已成为绝大多数程序员日常工作中亟待解决的核心诉求。
原因分析
- 一线模型成本太高:国际一线AI编程模型(如GPT系列、Claude系列)多采用订阅制或按Token计费模式,长期使用成本居高不下
- 项目安全隐私风险:一些AI编辑器使用需要开启工具,部分模型存在外网依赖、隐私泄露风险,项目安全得不到保障
- 开源模型侧重不同:前端开发全流程(需求解析、代码生成、重构优化、方案设计、测试用例等)对模型的专业性、适配性要求较高,若选择能力不足的模型,会增加开发投入、降低交付效率,进一步提升开发成本。
归因分析
如何使用低成本的模型,进行安全、高质量项目开发,成为前端职业工作者需要时常思考的问题?
- 模型互补方案缺少
国际一线模型较贵,而国内开源模型在不同能力方面有所侧重。单一模型无法解决前端的整体开发问题,模型选择错误会导致开发成本直线上升。并且AI编程工具基本上只内置单模型开发模式,加剧这种情况的发生 - 工具交互体验不足
一个好的编程工具,应当是:编程过程支持拖拉拽文档/图片;控制台一键添加对话;模型修改错误支持回退历史对话节点,不需要严重依赖Ctrl + Z 或者 Git。依行业较火的Cursor为例,模型修改内容错误,且进行多轮对话后,会退某个对话节点内容很麻烦。 - 项目安全隐私忽视
企业的项目属于公司数字资产,并非开源项目。使用过程中会上传大量代码到外网存在很大安全风险,尤其项目内配置各种密钥/账密等情况下。因速度而牺牲项目安全,是前端管理者更需要考量的事情
解决方案
- 打通不同源主副模型互补
依托AI编辑器内置的开源主模型,搭配不同厂商的本地27B/35B级辅助模型,采用"开源主模型+本地辅助模型"打通互补的方案。多维度形成模型能力互补,从而无需依赖高成本国际一线模型,即可实现对标国际一级AI编程模型的使用效果。兼顾低成本与高实用性,同时实现本地私有化部署,保障代码隐私安全。 - 前端规范化打造和监督
打造前端开发规范标准和监督制度,企业数字安全和隐私化法律法规普及,以及成员能力/认知培养。这些不在本文内容,需要管理者去考量
版本介绍
-
AI编辑器:TRAE CN 版本 3.3.50(内置VSCode 版本: 1.107.1)
-
硬件参数:Mac M5 Pro 48G(内存/显存共享)
-
模型工具:LM Studio 版本 0.4.12+1 (0.4.12+1)
-
MCP版本:lmstudio-mcp-server 版本 1.0.1
Trae CN 打通本地AI模型详见我另一个博客内容
https://blog.csdn.net/weixin_44461275/article/details/160262926?spm=1011.2415.3001.5331
模型介绍
本文针对TRAE CN内置6款开源主模型,搭配3款本地辅助模型,形成18组组合,以GPT-5.2(4星)为基准,对标GPT-5.4/GPT-5.3-Code(5星满星)。
从前端日常开发、技术方案设计、复杂项目重构三个核心场景打分,明确各组优势劣势,为前端开发者提供精准选型参考。
一、基准说明与模型参数
1. 评分基准
- 满分:★★★★★(5星),对标GPT-5.4/GPT-5.3-Code(当前前端编程模型天花板)
- 基准线:GPT-5.2 = ★★★★(4星),代表前端开发中"优秀可用"的标准水平
- 评分逻辑:贴合前端实际开发场景(TS/组件/架构/重构),客观反映大众使用体验,不夸大模型能力
2. 模型参数说明(主模型)
所有主模型均为TRAE CN内置开源模型,参数规模直接影响模型推理能力与资源占用,具体如下:
| 主模型 | 参数规模 | 特点 |
|---|---|---|
| GLM-5.1 | 约65B | (参数规模最大,工程化能力顶级) |
| DeepSeek-V3.1-Terminus | 约67B | 全局架构与重构能力突出 |
| Doubao-Seed-2.0-Code | 约32B | 前端专项优化,中文理解优秀 |
| Qwen3.6-plus | 约32B | 前端生成体验佳,长上下文能力强 |
| GLM-5 | 约60B | 成熟稳定,适配多数常规场景 |
| MiniMax-M2.7 | 约32B | 轻量流畅,适合简单场景 |
3. 辅助模型(本地部署)
| 辅助模型 | 参数规模 | 特点 | 下载全名安装 |
|---|---|---|---|
| samuelcardillo 35B-Claude | 35B | Claude 4.6 Opus蒸馏版,代码严谨,推理能力强 | lms get samuelcardillo/Qwen3.5-35B-A3B-Claude-4.6-Opus-Reasoning-Distilled-GGUF |
| Qwen3.6-35B-A3B | 35B | 官方MoE模型,生成速度快,前端适配好 | lms get Qwen3.6-35B-A3B |
| Jackrong 27B-v2 | 27B | Claude蒸馏版,轻量稳定,少幻觉,内存友好 | lms get Jackrong/Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2-GGUF |
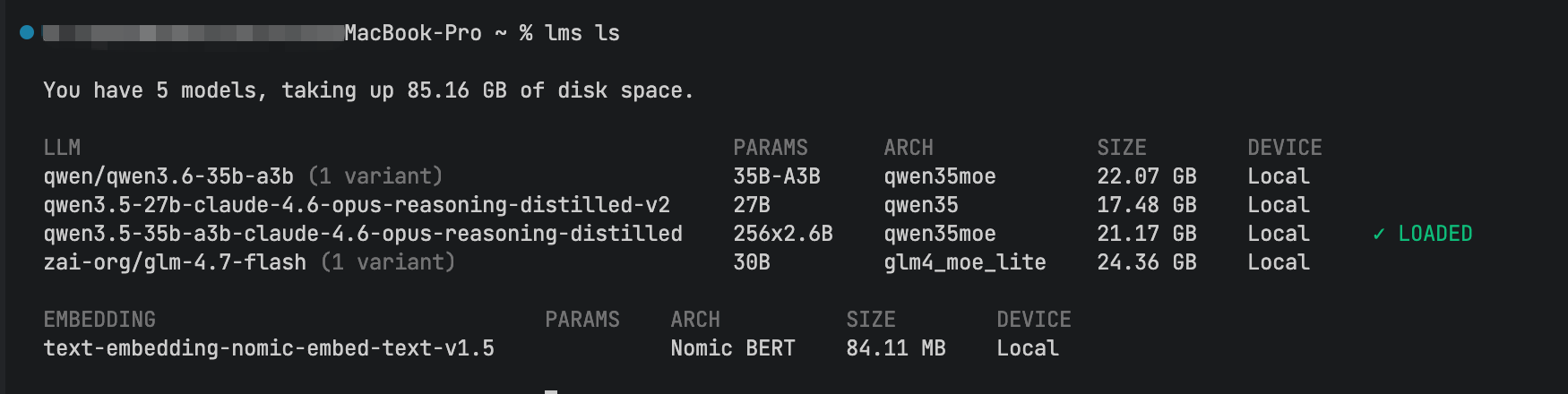
关键注意点
- Qwen3.6-plus(主模型)+ Qwen3.6-35B-A3B(辅助模型) 为同系组合,会出现代码问题补偿分析能力明显下降,方案深度与重构稳定性缩水,选型时需重点规避。
- Qwen3.5-27B-Claude-4.6-Opus-Reasoning-Distilled-v2是v2版本,注意不要下载v1版本
二、18组模型组合全对比表(前端专属)
说明:表格中"同系补偿下降"均指Qwen主辅同系组合,其余组合无此问题;星级越高,越接近GPT-5.4水平。
| 序号 | 主模型(参数规模) | 辅助模型 | 前端日常开发 | 技术方案设计 | 复杂项目重构 | 组合优势 | 组合劣势 |
|---|---|---|---|---|---|---|---|
| 1 | GLM-5.1 (约65B) | samuelcardillo 35B-Claude | ★★★★★ | ★★★★★ | ★★★★★ | 工程化、架构能力顶级,TS严谨,长上下文稳定,综合最接近GPT5.4 | 本地显存占用偏高,极端场景偶有过度设计 |
| 2 | GLM-5.1 (约65B) | Qwen3.6-35B-A3B | ★★★★☆ | ★★★★ | ★★★★ | 生成速度快,前端补全顺滑,整体强于GPT5.2 | 同系轻微补偿下降,复杂重构细节易丢失 |
| 3 | GLM-5.1 (约65B) | Jackrong 27B-v2 | ★★★★ | ★★★★ | ★★★★ | 极稳、少幻觉,内存友好,长期开发体验舒适 | 大项目上限略低于35B-Claude组合 |
| 4 | DeepSeek-V3.1-Terminus (约67B) | samuelcardillo 35B-Claude | ★★★★ | ★★★★★ | ★★★★★ | 全局架构、仓库级重构能力最强,代码逻辑严谨 | 中文前端细节略逊GLM,本地偶有轻微逻辑跳变 |
| 5 | DeepSeek-V3.1-Terminus (约67B) | Qwen3.6-35B-A3B | ★★★★ | ★★★★ | ★★★★ | MoE互补,长代码梳理强,速度与质量均衡 | 同系轻微补偿下降,边界Case严谨度略降 |
| 6 | DeepSeek-V3.1-Terminus (约67B) | Jackrong 27B-v2 | ★★★★ | ★★★★ | ★★★☆ | 稳定不卡顿,资源占用低,适合日常业务迭代 | 超大型项目重构上限一般 |
| 7 | Doubao-Seed-2.0-Code (约32B) | samuelcardillo 35B-Claude | ★★★★ | ★★★★ | ★★★★ | 中文理解强,前端代码规范,调试友好 | 通用架构推理略弱于GLM/DeepSeek |
| 8 | Doubao-Seed-2.0-Code (约32B) | Qwen3.6-35B-A3B | ★★★☆ | ★★★☆ | ★★★ | 轻量高效,适合快速页面/组件开发 | 同系补偿下降,架构深度不足,大重构易断层 |
| 9 | Doubao-Seed-2.0-Code (约32B) | Jackrong 27B-v2 | ★★★ | ★★★ | ★★★ | 稳定轻量,日常CRUD与简单修复很顺手 | 复杂方案与大型重构能力偏弱 |
| 10 | Qwen3.6-plus (约32B) | samuelcardillo 35B-Claude | ★★★★★ | ★★★★ | ★★★★ | 前端生成体验最强,长上下文优秀,补齐架构短板 | 架构深度不如GLM/DeepSeek,长会话略易发散 |
| 11 | Qwen3.6-plus (约32B) | Qwen3.6-35B-A3B | ★★★★ | ★★★☆ | ★★★☆ | 同系速度极快,前端写码流畅 | 明显补偿下降:方案浅显,复杂重构逻辑易混乱 |
| 12 | Qwen3.6-plus (约32B) | Jackrong 27B-v2 | ★★★★ | ★★★☆ | ★★★★ | 前端强、长文本稳,平衡速度与质量 | 系统性架构设计能力一般 |
| 13 | MiniMax-M2.7 (约32B) | samuelcardillo 35B-Claude | ★★★☆ | ★★★ | ★★★ | 对话流畅,中文友好,辅助补全可用 | 整体能力中等,不适合重度工程与大型重构 |
| 14 | MiniMax-M2.7 (约32B) | Qwen3.6-35B-A3B | ★★★ | ★★★ | ★★★ | 速度快,适合简单业务与原型 | 代码严谨度一般,重构能力弱 |
| 15 | MiniMax-M2.7 (约32B) | Jackrong 27B-v2 | ★★★ | ★★☆ | ★★☆ | 最轻量、不占资源,适合小需求快修 | 架构与重构能力明显不足,略弱于GPT5.2 |
| 16 | GLM-5 (约60B) | samuelcardillo 35B-Claude | ★★★★ | ★★★★ | ★★★★ | 成熟稳定,生态适配好,可靠性高 | 长程推理与极限上限略弱于GLM-5.1 |
| 17 | GLM-5 (约60B) | Qwen3.6-35B-A3B | ★★★☆ | ★★★☆ | ★★★ | 通用能力强,适合中后台简单业务 | 同系补偿下降,复杂架构思考不足 |
| 18 | GLM-5 (约60B) | Jackrong 27B-v2 | ★★★ | ★★★ | ★★★ | 轻量稳定,日常开发够用 | 复杂重构偏弱,整体略低于GPT5.2水平 |
三、梯队划分(精准匹配前端开发场景)
按模型组合能力分为三梯队,结合前端开发需求(日常开发/方案设计/重构),方便快速选型:
第一梯队(接近GPT5.4,4.5★+,全能首选)
适合:大型复杂项目、架构设计、仓库级重构、高标准前端开发
-
GLM-5.1 + samuelcardillo 35B-Claude(综合最强,无明显短板)
-
DeepSeek-V3.1-Terminus + samuelcardillo 35B-Claude(重构天花板,大型项目首选)
-
Qwen3.6-plus + samuelcardillo 35B-Claude(前端写码体验最佳,Vibe Coding首选)
第二梯队(≥ GPT5.2,4★,常规可用)
适合:中型项目、常规业务开发、普通重构、中后台开发
-
GLM-5.1 + Qwen3.6-35B-A3B / Jackrong 27B-v2
-
DeepSeek-V3.1-Terminus + Qwen3.6-35B-A3B / Jackrong 27B-v2
-
Doubao-Seed-2.0-Code + samuelcardillo 35B-Claude
-
Qwen3.6-plus + Jackrong 27B-v2
-
GLM-5 + samuelcardillo 35B-Claude
第三梯队(≈ / < GPT5.2,3.0★~3.5★,轻量备用)
适合:小型项目、简单CRUD、快速原型、临时调试(不适合复杂场景)
-
Doubao-Seed-2.0-Code + Qwen3.6-35B-A3B / Jackrong 27B-v2
-
Qwen3.6-plus + Qwen3.6-35B-A3B(同系拉胯,谨慎使用)
-
MiniMax-M2.7 全系组合(MiniMax+3款辅助模型)
-
GLM-5 + Qwen3.6-35B-A3B / Jackrong 27B-v2
四、前端开发者选型指南(直接照做)
1. 优先选择(推荐度从高到低)
-
综合全能型:GLM-5.1 + samuelcardillo 35B-Claude → 覆盖所有前端场景,最接近GPT5.4
-
重构专项型:DeepSeek-V3.1-Terminus + samuelcardillo 35B-Claude → 大型项目重构、架构升级首选
-
前端高效型:Qwen3.6-plus + samuelcardillo 35B-Claude → 写组件、页面、TS代码效率最高
-
轻量稳定型:GLM-5.1 + Jackrong 27B-v2 → 内存友好,长期开发不卡顿
2. 规避组合(重点提醒)
-
❌ Qwen3.6-plus + Qwen3.6-35B-A3B:同系补偿下降明显,复杂重构易出问题,仅适合极速原型开发
-
❌ MiniMax-M2.7 全系组合:不适合大型项目与复杂重构,仅作为日常中小项目使用,备用
3. 资源适配建议
-
高配置设备(显存≥48G):优先第一梯队组合,发挥模型最大能力
-
中配置设备(显存32-48G):优先第二梯队组合,平衡性能与资源占用
-
低配置设备(显存<32G):优先第三梯队轻量组合(如MiniMax+Jackrong 27B-v2)
五、总结
前端开发中,模型组合的核心是"主模型控全局(架构/方案),辅助模型补细节(代码/调试/审查/补充)"。
本次18组组合中:
- GLM-5.1与DeepSeek搭配samuelcardillo 35B-Claude的组合,是最接近GPT5.4水平的选择,能满足大型项目、复杂重构的高标准需求;
- Qwen3.6-plus搭配Claude辅助,是前端日常开发的效率王者;
- 而Qwen同系组合与MiniMax全系组合,仅适合轻量简单场景。
选型时需结合自身设备配置、项目规模,避开同系组合的短板,才能最大化发挥模型组合的价值,提升前端开发效率与代码质量。
文档补充
Trae CN 打通本地AI模型详见我另一个博客:
https://blog.csdn.net/weixin_44461275/article/details/160262926