这篇论文为什么值得读?
695 GFLOPs vs 2 GFLOPs。
同一个裂缝分割任务,精度更高,计算量只有别人的 0.3%。
如果你做过工业视觉部署,你知道这意味着什么------一个原本只能跑在 A100 上的模型,现在有可能塞进路边的巡检设备里。
但效率只是结果,真正值得关注的是背后的思路:
1. "先理解再设计"比"先堆叠再调参"高明得多。 之前的混合架构把 CNN、Transformer、Mamba 当积木拼。MixerCSeg 先深入分析 Mamba 的隐式注意力机制,发现 Δt 天然地将通道分为全局和局部两类,然后顺势而为地把它们交给最合适的处理路径。
2. 极致效率打开了边缘部署的可能性。 2.05 GFLOPs、2.54M 参数、1190 MiB 显存------这个量级可以塞进嵌入式设备。对路面巡检车、桥梁监测无人机来说,这不是"学术上的改进",而是"能不能用"的分界线。
3. "深度=1 最优"值得更多任务借鉴。 在"更深=更好"的惯性思维下,MixerCSeg 用数据证明:对依赖细粒度边缘特征的任务,单层足矣,更深只会帮倒忙。
这篇论文叫 《MixerCSeg: An Efficient Mixer Architecture for Crack Segmentation via Decoupled Mamba Attention》 ,来自山东大学齐鲁交通学院和杜兰大学的联合团队,已被 CVPR 2026 接收,代码已开源(github.com/spiderforest/MixerCSeg)。
为什么裂缝分割这么难?
路面裂缝分割是基础设施健康监测的关键技术。但裂缝可能细如发丝,也可能交叉成网,加上低对比度和不均匀纹理,精确的像素级分割一直是老大难。
当前的深度学习方案围绕三种架构展开,但各有硬伤:
- CNN(DeepCrack、SDDNet):局部纹理提取快,但感受野有限,看不到长距离的像素依赖
- Transformer(CrackFormer、DTrCNet):能建模全局依赖,但计算复杂度二次方增长,推理慢
- Mamba(SCSegamba、CrackMamba):线性复杂度的全局建模,但单次前向对全局上下文的利用不够充分
有人尝试过混合架构------比如 MambaVision、RestorMixer------但它们只是把不同模块简单堆在一起,串行或并行。相当于三个专家坐在一起开会,各说各话。
MixerCSeg 的思路完全不同:不是从外部"拼装"三种架构,而是从 Mamba 内部"拆解"出混合表示的能力。
核心发现:Mamba 里藏着两套注意力
这是整篇论文最有洞察力的部分。
在 Mamba 的状态空间模型中,有一个关键参数 Δt,控制着每个 token 的信息传播范围:
- Δt → 0 :当前 token 被丢弃,历史信息被保留 → 信息只在局部流动
- Δt > 0 :当前 token 与衰减后的历史叠加 → 信息在全局传播
论文通过可视化 VMamba 的通道级注意力热力图证实了这一点:不同通道的 Δt 值天然地分成两类------一些通道的感受野覆盖全图(全局通道),另一些只关注邻域区域(局部通道)。

翻译成人话:Mamba 自己已经在做"全局+局部"的混合表示了,只是把这两种能力混在一起,没有被单独优化过。
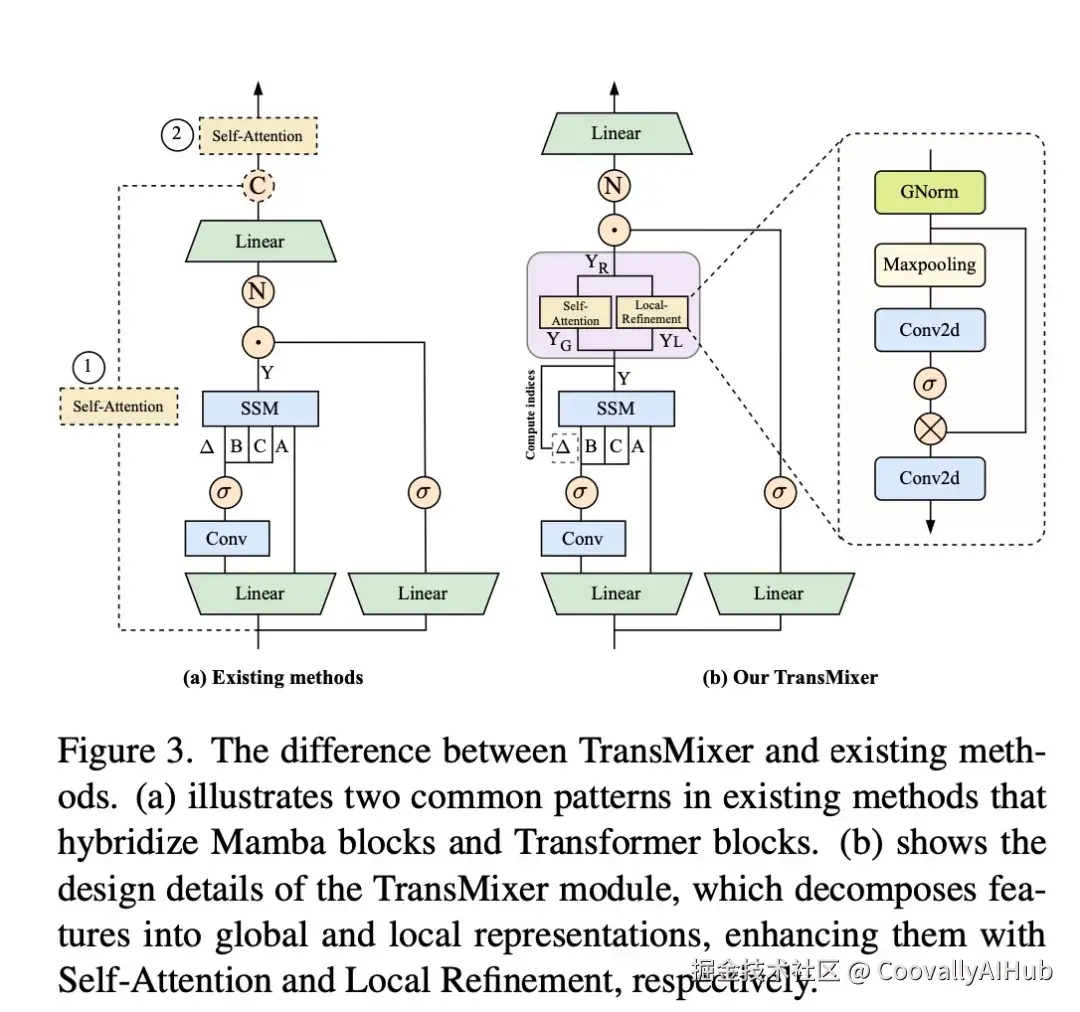
TransMixer 做的事情,就是把这种隐式分工变成显式设计------全局通道交给 Self-Attention 进一步增强长距离依赖,局部通道交给 CNN 精炼细粒度纹理。
不是"把三个专家凑在一起",而是"在一个专家体内发现了三种能力,然后各自强化"。
方法:三个模块,一条流水线

模块一:TransMixer------解耦式混合编码器
整个流程分四步:
Step 1:输入序列经过 Mamba(Linear → Conv1D → SSM)得到输出 Y。Mamba 中每个 token 对输出的贡献可量化为注意力权重 α_i,j,由 Δt 决定信息流通范围。
Step 2:对 Δt 沿通道维度排序,取 top 50% 通道(γ=0.5)为"全局 token",剩余 50% 为"局部 token"。
Step 3:分路增强------
- 全局 token → Self-Attention → 增强长距离依赖
- 局部 token → GroupNorm → MaxPool → Conv1×1 → Sigmoid 逐元素加权 → 精炼局部细节
Step 4:合并回原始通道顺序,输出特征图。
模块二:DEGConv------方向引导边缘门控卷积
裂缝沿多个方向延伸和分支,普通卷积对这种不规则边缘的感知力不够。DEGConv 的做法:
- 把特征图切成小块(cell 8×8)
- 每个小块用 Sobel 算子计算梯度 → arctan(dy/dx) 得到方向角 → 统计 180 个方向区间的方向直方图 → 经 Conv1×1 → Conv3×3 生成方向嵌入向量 ε
- 用方向嵌入增强后的特征做门控 EdgeConv(内部用 1×k 和 k×1 条形卷积提取双方向特征)------方向对的地方权重高,方向不对的被抑制
关键:这个模块只增加 0.08 GFLOPs 和 0.14M参数。几乎零成本引入了几何先验。
模块三:SRF------空间精炼多级融合
用最高分辨率的特征图生成一张空间注意力图,用它来引导低分辨率特征的上采样融合。
替换 SegFormer 解码器后,计算量降低 89.3%,显存下降 67.2%,精度反而还有提升。
四张表看懂效果
实验在单张 NVIDIA A100 上完成,输入尺寸 512×512,训练 50 epoch(batch=1, AdamW, lr=5e-4),覆盖 DeepCrack(537 张)、CamCrack789(789 张)、CrackMap(120 张)、Crack500(3368 张)四个数据集。
表 1:精度------四个数据集全部 SOTA
| 方法 | DeepCrack mIoU | CamCrack789 mIoU | CrackMap mIoU | Crack500 mIoU |
|---|---|---|---|---|
| U-Net | 0.8987 | 0.8372 | 0.7983 | 0.7105 |
| SCSegamba | 0.9022 | 0.8268 | 0.8094 | 0.7778 |
| RestorMixer | 0.9008 | 0.8356 | 0.7887 | 0.7425 |
| MambaVision | 0.8991 | 0.8146 | 0.7737 | 0.7015 |
| MixerCSeg | 0.9151 | 0.8409 | 0.8123 | 0.7824 |
DeepCrack 上 mIoU 达到 91.51%,比次优 SCSegamba 高出 1.29 个百分点。四个数据集全面领先,没有短板。

表 2:效率------碾压级优势
| 方法 | FLOPs (G) | 参数量 (M) | 显存 (MiB) |
|---|---|---|---|
| RINDNet | 695.77 | 59.39 | 5392 |
| MambaVision | 642.86 | 13.57 | 5222 |
| U-Net | 204.38 | 28.99 | 4394 |
| RestorMixer | 98.71 | 3.19 | 10384 |
| SCSegamba | 18.16 | 2.80 | 2206 |
| MixerCSeg | 2.05 | 2.54 | 1190 |
核心数据:
- 计算量 2.05 GFLOPs ,比 SCSegamba 少 88.7%,比 RINDNet 少 99.7%
- 显存仅 1190 MiB ,比 RestorMixer(10384 MiB)少 88.5%
- 精度最高的同时,计算资源消耗全面最低
表 3:消融------每个模块都在干活
| TransMixer | DEGConv | SRF | FLOPs(G) | DeepCrack mIoU |
|---|---|---|---|---|
| 17.74 | 0.8826 | |||
| ✔ | 19.10 | 0.9016 | ||
| ✔ | ✔ | 19.18 | 0.9097 | |
| ✔ | ✔ | ✔ | 2.05 | 0.9151 |
TransMixer 是主力(+1.9%),DEGConv 低成本增益(+0.81%,仅 +0.08G),SRF 替换解码器后精度再涨 0.54% 的同时把计算量从 19G 直接砍到 2G。
表 4:深度=1 最优------最反直觉的发现
| 网络深度 | FLOPs(G) | 参数量(M) | DeepCrack mIoU |
|---|---|---|---|
| 1 | 2.05 | 2.54 | 0.9151 |
| 2 | 3.51 | 4.76 | 0.9141 |
| 4 | 6.42 | 9.20 | 0.9126 |
| 6 | 9.33 | 13.63 | 0.9073 |
单层 TransMixer 即为最优。 深度从 1 增到 6,计算量涨了 355%,参数涨了 437%,精度反而掉了 0.78%。
论文的解释是:对裂缝这种高度依赖局部细粒度特征的任务,更深的网络会导致边缘过度平滑和优化困难。
写在最后
混合架构不是新概念,但大多数工作只是在做"1+1+1"的堆叠。
MixerCSeg 的贡献在于它回答了一个更深层的问题:Mamba 内部到底在做什么? 答案是------它已经在隐式地做全局+局部的混合表示,只是没有人把这两种能力拆开、放大、各自优化过。
当你理解了这一点,CNN+Transformer+Mamba 的协同就不再是三个模块的拼装,而是一个模型内部能力的自然延伸。
2 GFLOPs,四大基准全 SOTA。有时候,真正的效率来自于对模型本身的深入理解,而不是更多的参数。
不过,从我们的角度看,这篇工作也留下了几个值得继续探索的方向:
- Crack500 上的领先幅度有限(mIoU +0.46%)。Crack500 以宽裂缝、低曲率为主,与细密裂缝的分割需求差异较大,MixerCSeg 的优势在这类场景中没有完全释放。
- 方向嵌入依赖 Sobel 先验。当前的方向感知基于手工设计的梯度算子,面对极端光照或严重遮挡时,可学习的方向预测可能更鲁棒。
- 缺少实际推理帧率(FPS)报告。论文给出了 FLOPs 和显存,但对于工程部署来说,实际推理速度才是最终指标。2.05 GFLOPs 的理论计算量能否转化为边缘设备上的实时推理,还需要实测验证。
论文信息
- 标题:MixerCSeg: An Efficient Mixer Architecture for Crack Segmentation via Decoupled Mamba Attention
- 作者:Zilong Zhao, Zhengming Ding, Pei Niu, Wenhao Sun, Feng Guo
- 机构:山东大学齐鲁交通学院、杜兰大学计算机科学系
- 会议:CVPR 2026
- arXiv:2603.01361v1
- 代码:github.com/spiderforest/MixerCSeg