一、前言
在日常编程刷题、程序开发的过程中,排序是我们最高频使用的基础算法之一。我们经常会直接调用语言库自带的排序函数快速实现数据排序,但绝大多数人都只知其用、不知其理。看似简单的排序操作,背后蕴含着循环迭代、分治递归、贪心、分组增量、堆结构、桶分配等多种核心算法思想。八大经典排序算法是数据结构的重中之重,也是面试、算法学习的核心考点。
本文将系统性梳理八大排序算法的整体分类、核心原理与执行思路,帮助大家建立完整的排序算法知识体系,清晰区分不同排序的特性与适用场景。
二、八大排序算法分类
为了方便理解和记忆,我们从实现难度、算法稳定性两个维度,对八大排序算法进行统一分类,搭建整体知识框架。
1. 按实现难度分类
基础简单排序(双重循环实现,逻辑直观)
-
直接插入排序、冒泡排序、选择排序、基数排序
-
特点:代码简洁、逻辑易懂,适合小规模数据排序,时间复杂度普遍为 O(n²)
进阶高效排序(高级算法思想,性能更优)
-
希尔排序、归并排序、堆排序、快速排序
-
特点:基于分组、分治、堆结构实现,突破简单排序的性能瓶颈,平均时间复杂度为 O(nlogn),是工业级常用排序
2. 按算法稳定性分类
稳定性定义:排序后,原有相等元素的相对位置不发生改变,即为稳定排序,反之则为不稳定排序。多关键字排序场景下,稳定性至关重要。
稳定排序(4种)
直接插入排序、冒泡排序、归并排序、基数排序
不稳定排序(4种)
希尔排序、选择排序、堆排序、快速排序
三、八大排序思路讲解
1. 直接插入排序
直接插入排序的原理和我们整理扑克牌很像。它将数组分为有序区和无序区,默认第一个元素为有序区,后续逐个取出无序区元素,向前遍历比对,插入到有序区的正确位置。该算法在数据接近有序时效率极高,最好时间复杂度可达 O(n),且是稳定排序,整体适合小规模、基本有序的数据。
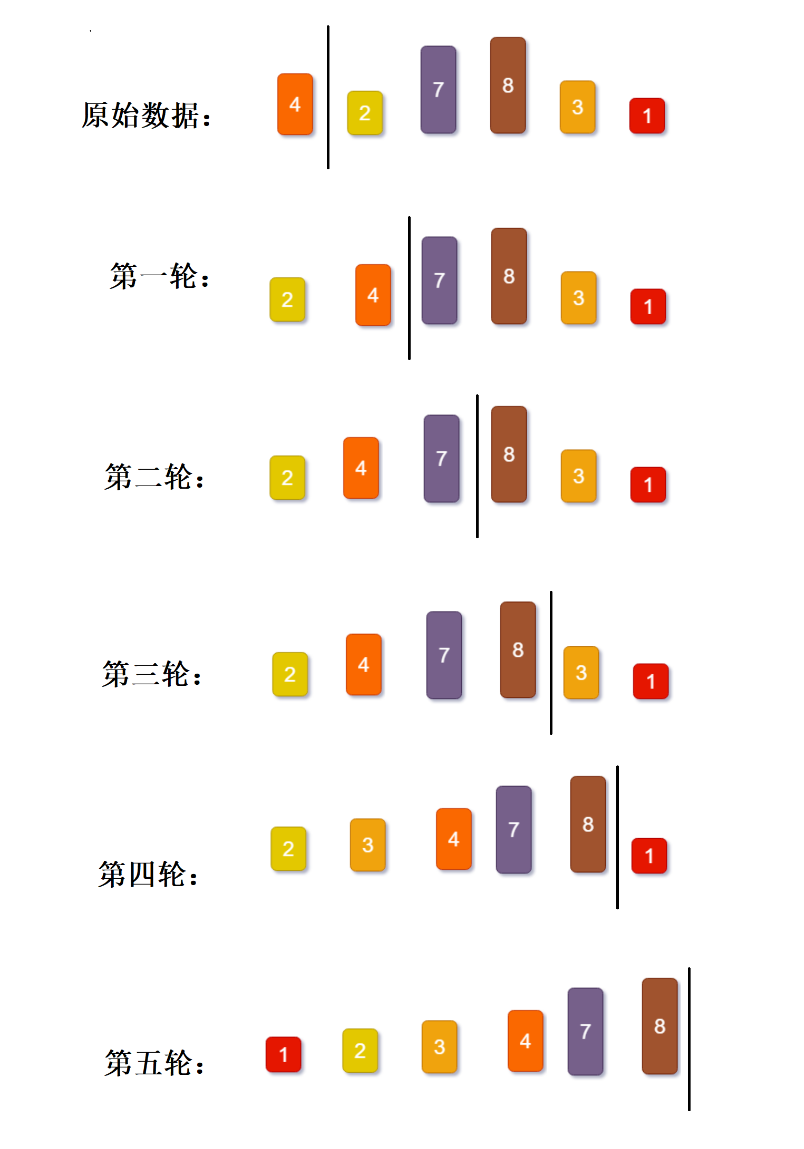
2. 希尔排序
希尔排序是直接插入排序的优化版本。它引入增量 gap 对数组分组,先对每组数据做插入排序,再不断缩小增量,直到增量为 1 完成全局插入排序。通过先局部有序、再整体有序的方式,大幅提升乱序数据的排序效率。但分组交换会打乱相等元素的相对位置,因此属于不稳定排序。
原始数据: 67 45 87 49 13 24 78 91 34 28 79 2149 32 66
第一轮:按照增量5进行分组(分成5组)
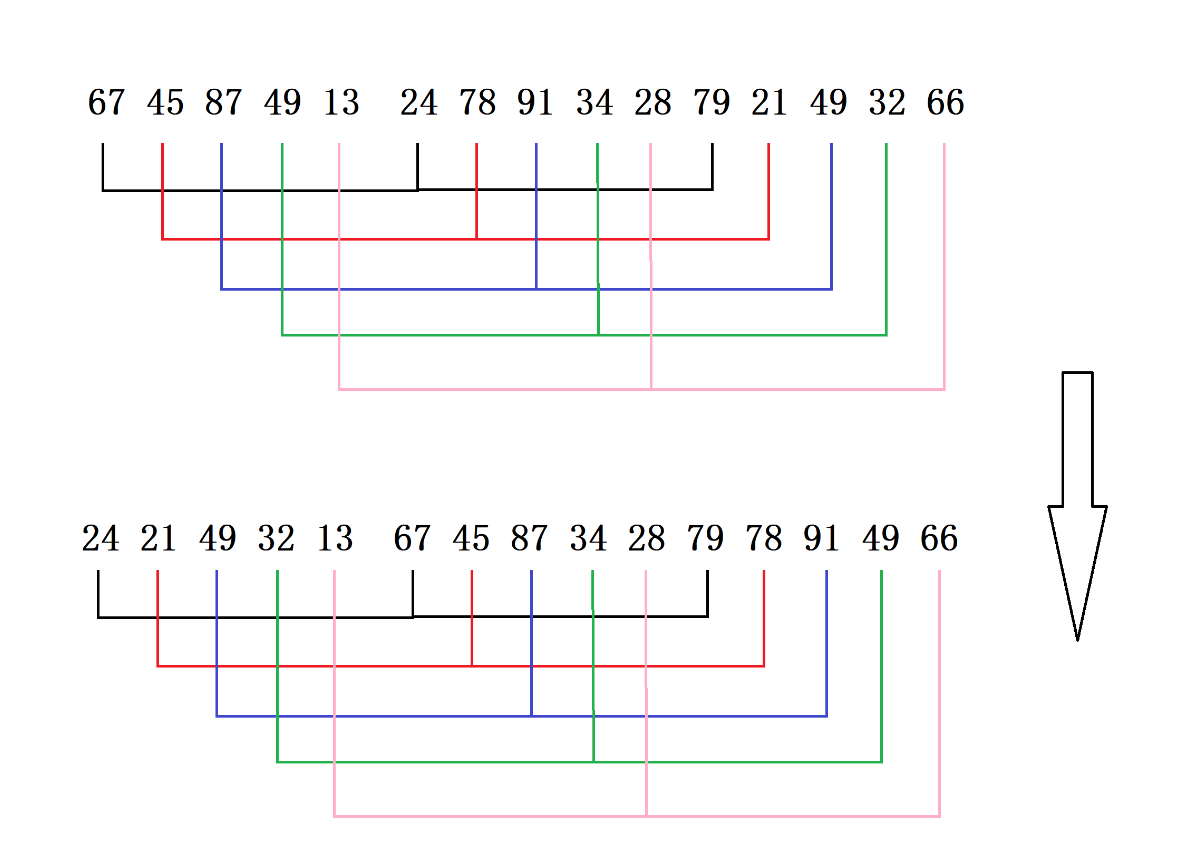
第二轮:再按增量3进行处理(分成3个组)
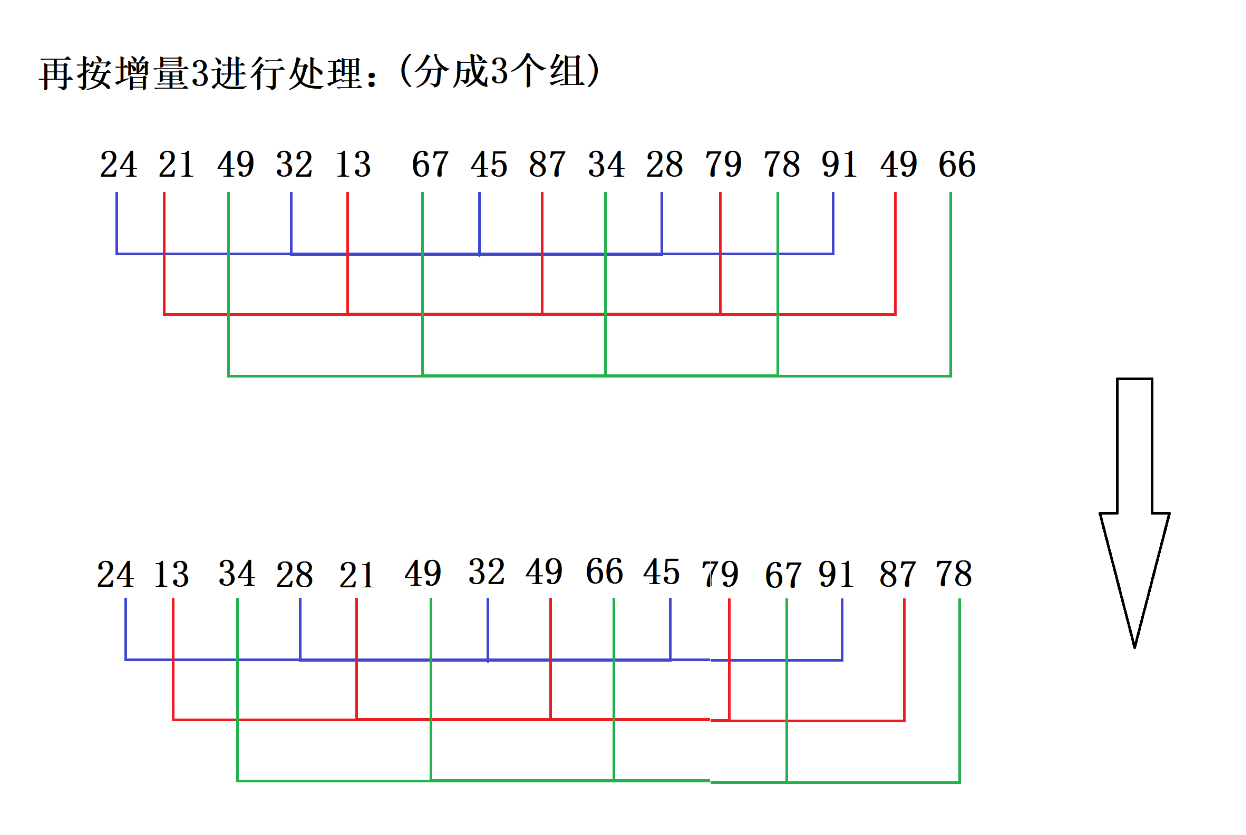
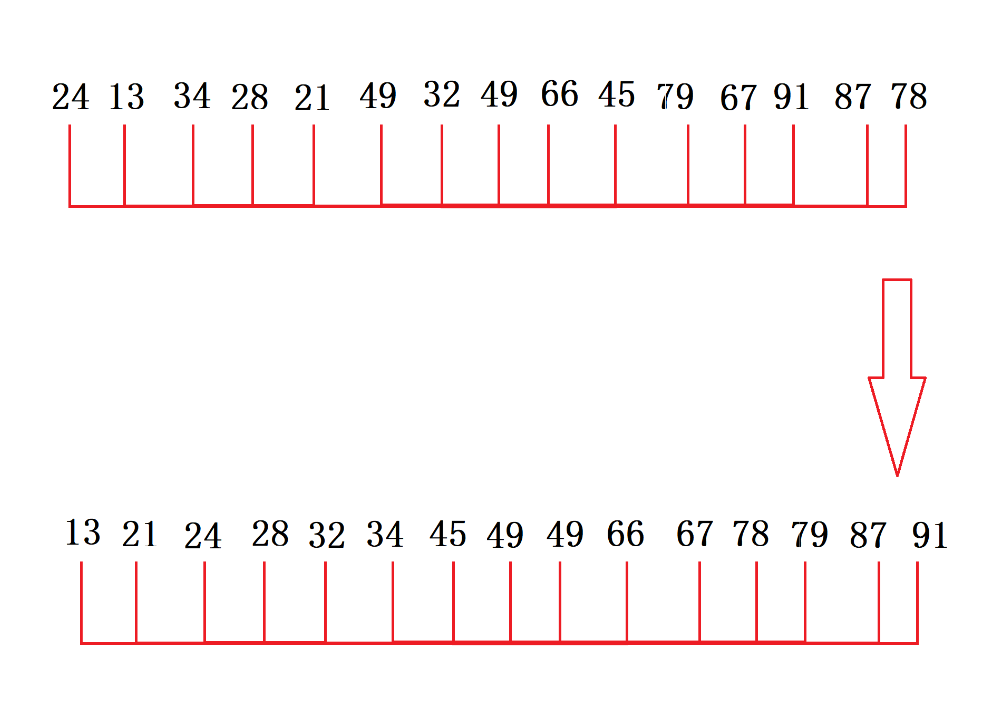
第三轮:按增量1进行处理(把所有的数据分成一个红)
3. 选择排序
选择排序的核心是每一轮遍历无序区间,筛选出最小值,与无序区间首位元素交换,逐步扩充有序区间。无论数据是否有序,都需要完整遍历,时间复杂度稳定 O(n²)。它的优势是交换次数少,但因为会跨位置交换元素,会破坏相等元素的原有顺序,属于不稳定排序。
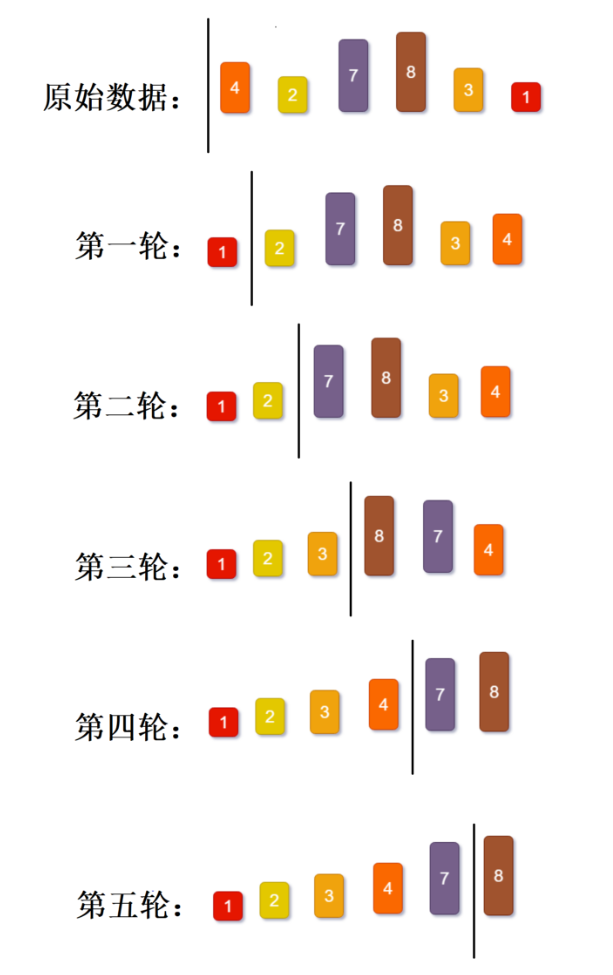
4. 冒泡排序
冒泡排序通过相邻元素两两对比交换,每一轮都会将当前最大值冒泡到无序区末尾。我在代码中做了优化,新增标记位,若某一轮遍历无任何交换,说明数组已有序,可直接提前终止。算法逻辑简单、实现直观、排序稳定,适合小规模数据,大数据量下效率较低。

5. 快速排序
快速排序是工程中最常用的高效排序,基于分治思想 实现。先选取基准值,通过分区操作将数组划分为小于、大于基准值的两个区间,再递归处理左右子区间。它平均时间复杂度为 O(nlogn ),性能优异,但极端情况下会退化到 O(n²),且属于不稳定排序。同时可以用栈实现非递归版本,规避递归深度过大导致的栈溢出问题。
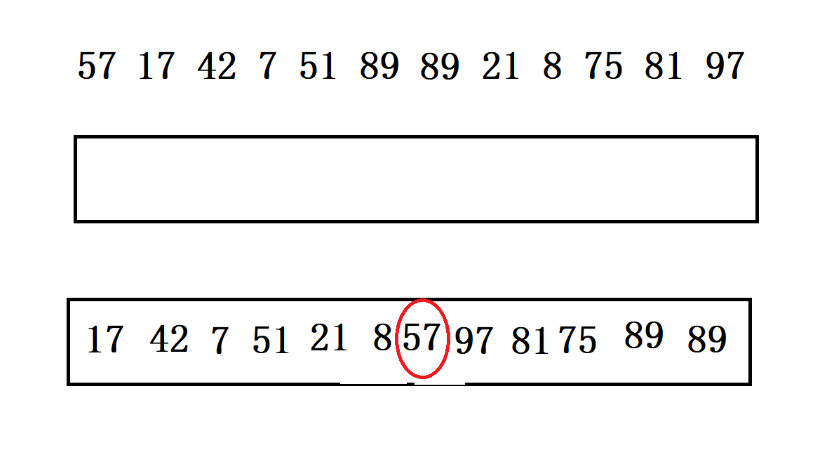
**原始数据:**57 17 42 7 51 89 89 21 8 75 81 97
第一种划分方法:需要额外的辅助空间
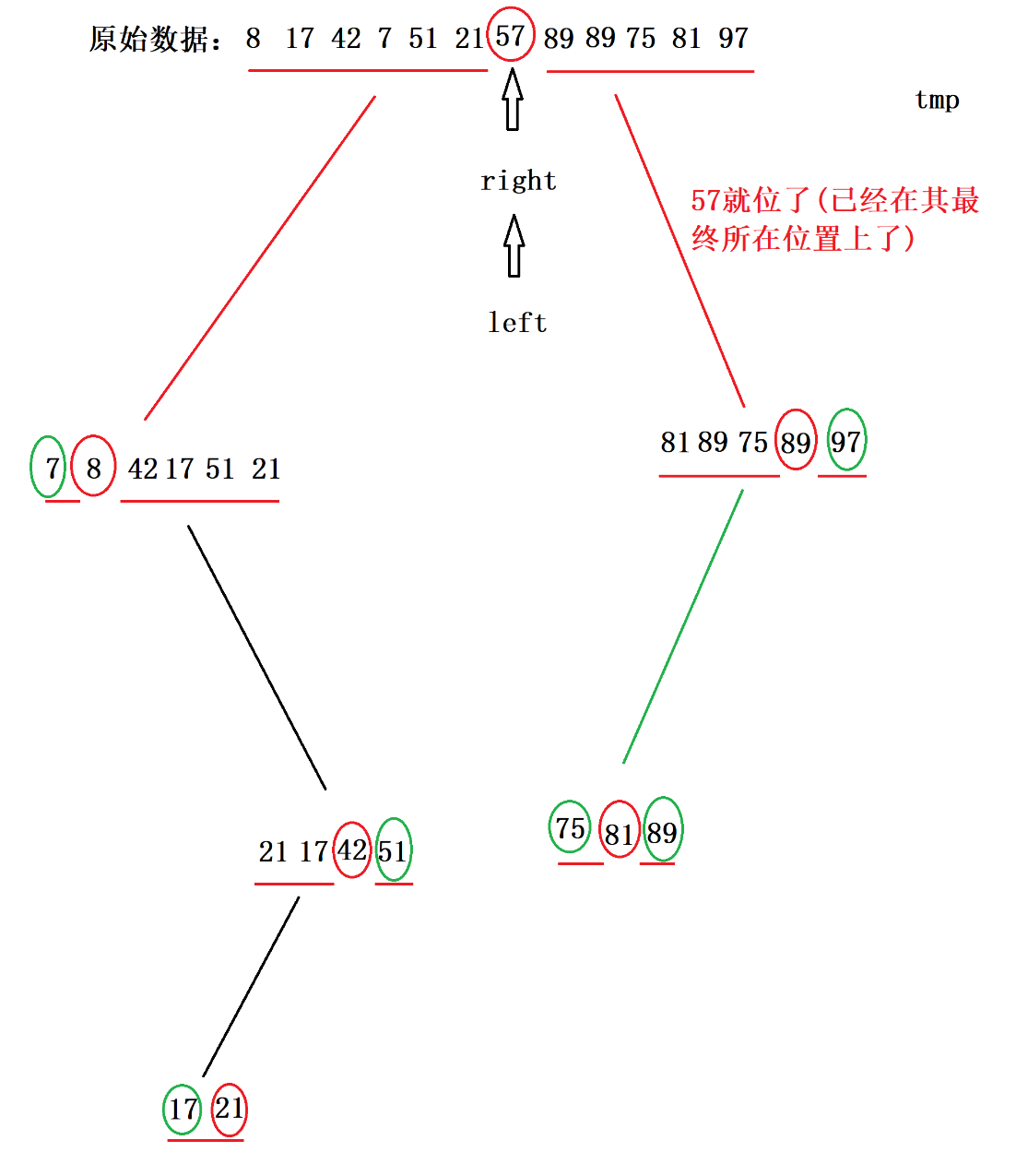
第二种划分方法:挖空法

两个指针向中间逼近,直到没有相遇则进行循环
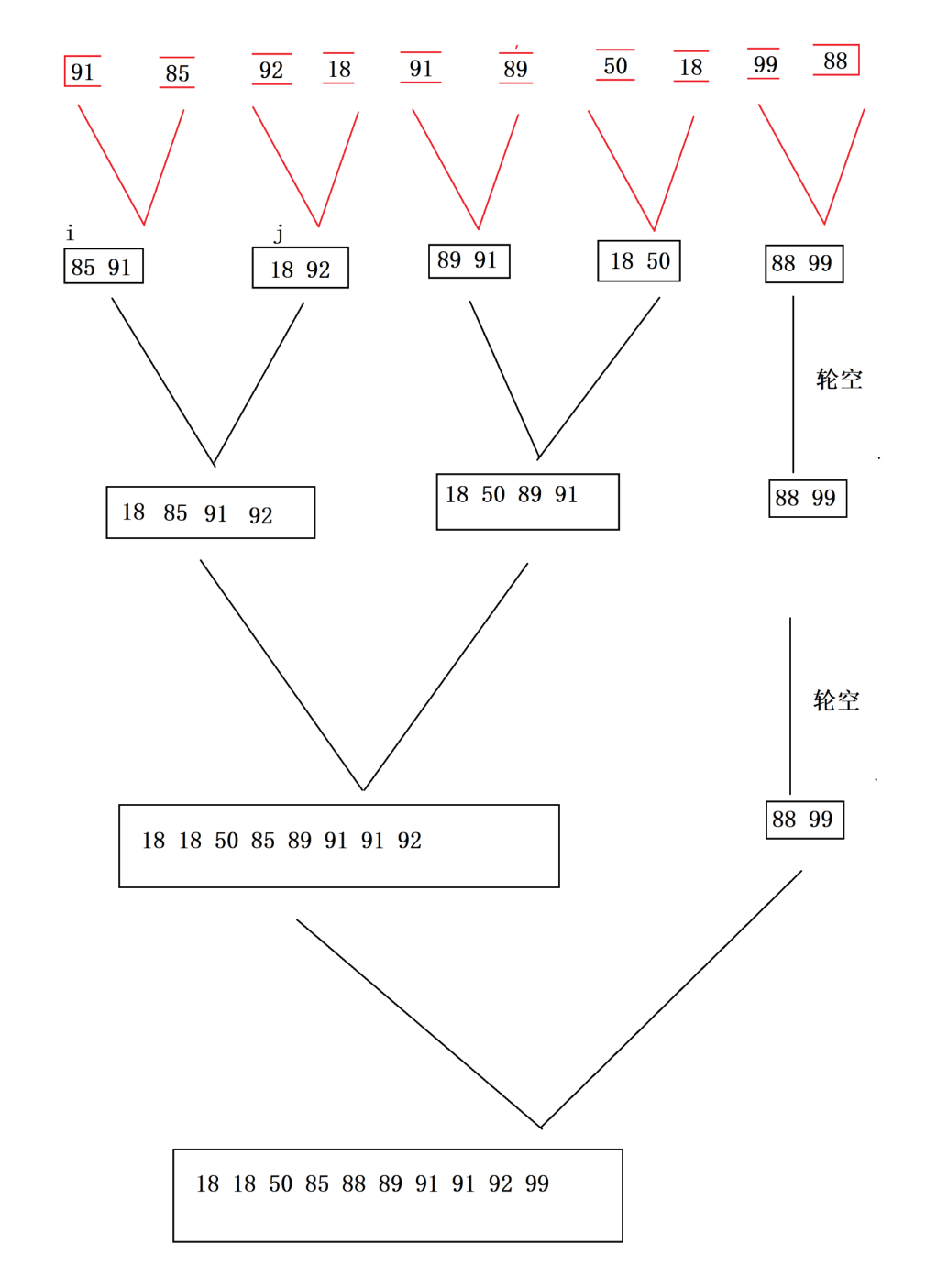
6. 归并排序
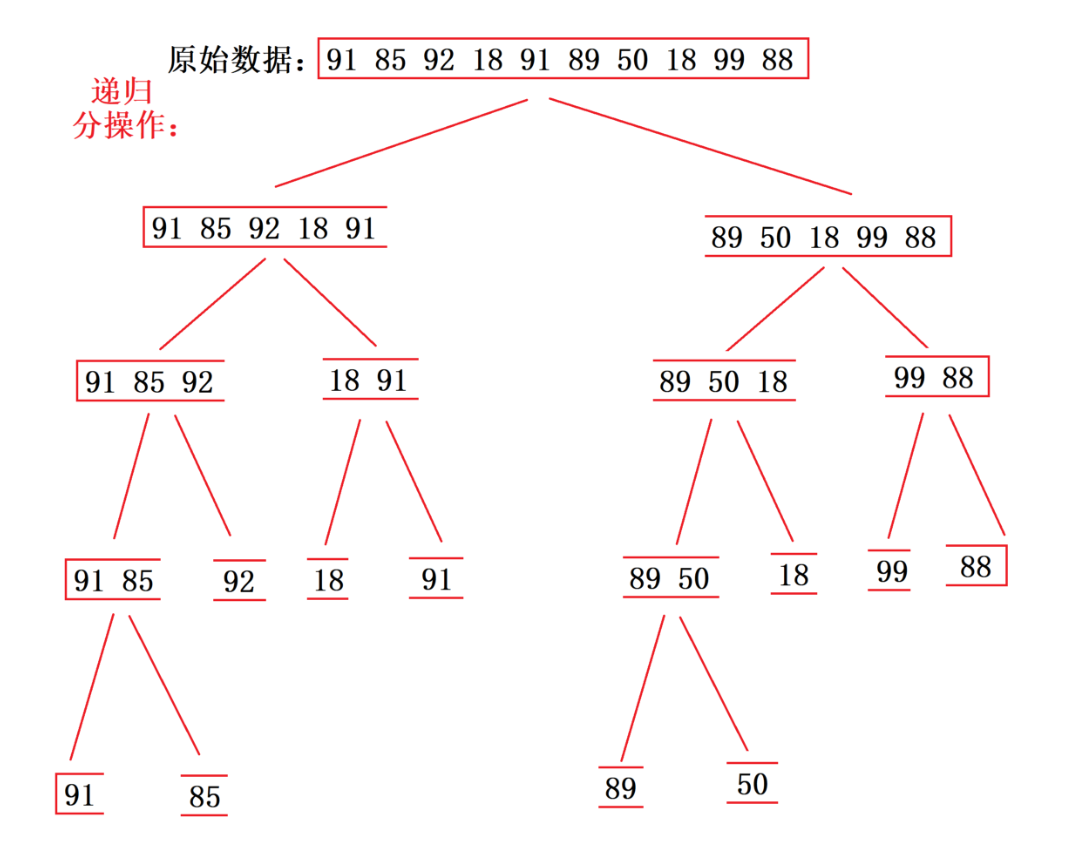
归并排序同样采用分治思想,分为拆分与合并两个阶段。先递归将数组二分拆分,直至每个子区间仅有一个元素,再逐层合并两个有序子序列,最终得到完整有序数组。它的时间复杂度恒定 O(nlogn),排序绝对稳定,唯一缺点是需要额外的辅助空间存储数据。
递归分操作
递归合操作
7. 堆排序
堆排序基于大顶堆结构实现。首先将数组构建为大顶堆 ,此时堆顶为全局最大值;再将堆顶与末尾元素交换,截断末尾有序元素,重新调整堆结构,循环迭代完成排序。该算法属于原地排序、无额外空间开销、效率高,但调整堆的过程会打乱相等元素顺序,属于不稳定排序。
**原始数据:**18 95 71 29 70 41 92 70 91 27
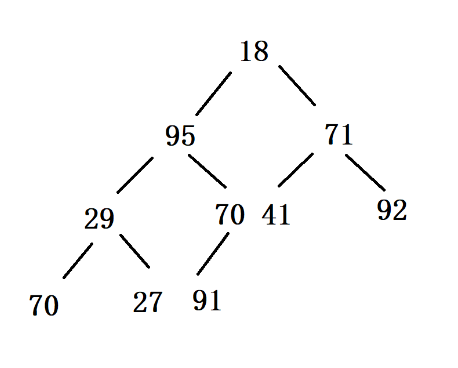
**第一步:**将原始数据构建的完全二叉树调整成大顶堆(第一次的调整,要由内而外调整),具体调整策略为从最后一个非叶子节点作为根节点的子树开始调整,从左向右,从下向上。
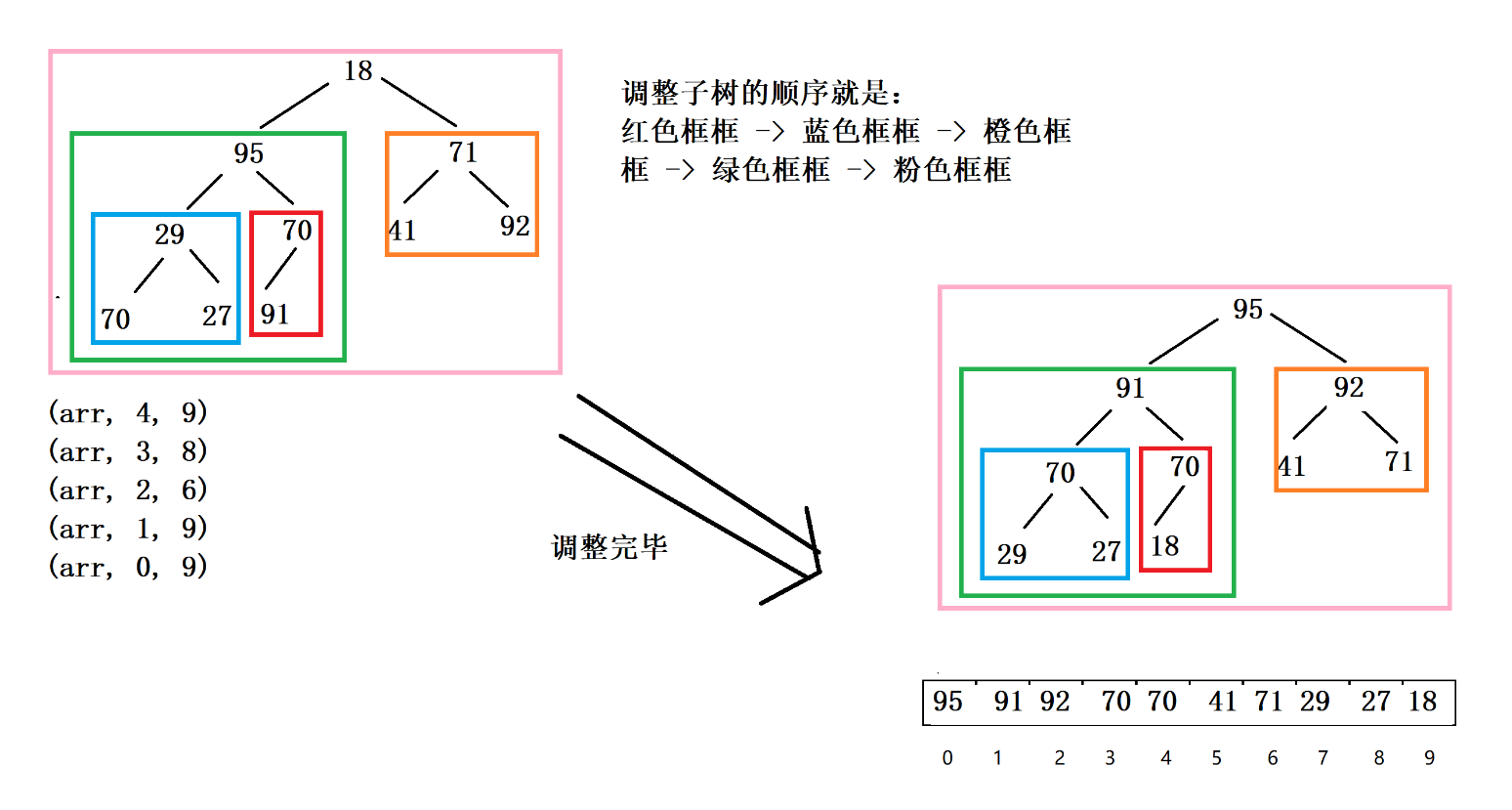
**第二步:**头尾交换,把大顶堆的根节点(最大值)和最后一个节点讲行交互,此时最大值就有序了,所以将尾结点断开链接。
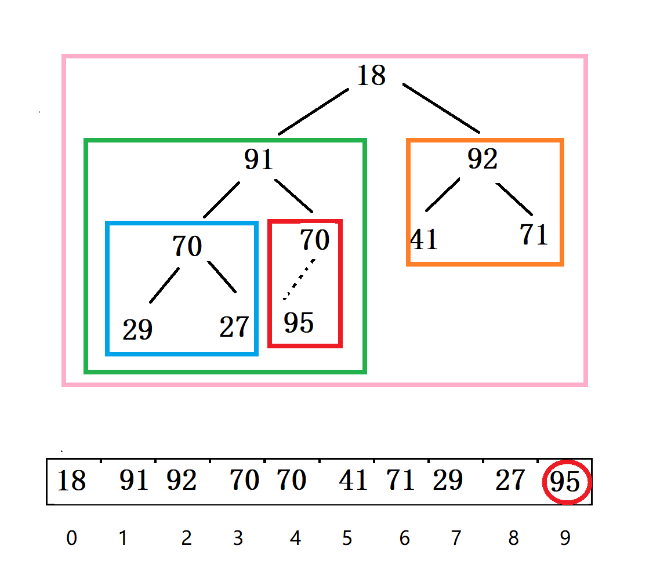
**第三步:**重新调整为大顶堆(注意,此时只需要调整最外层框框)
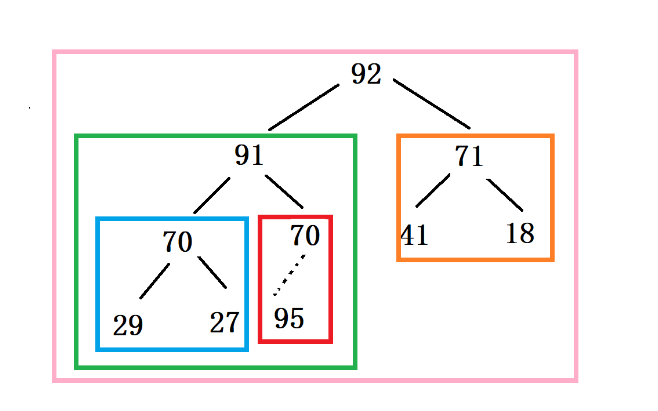
**第四步:**反复执行二,三这两步,直到树中只剩下一个节点为止。
8. 基数排序
基数排序是一种非比较型排序算法,依托队列桶实现。按照数字的位数优先级,从低位到高位依次遍历,将元素分配到对应编号的队列桶中,逐位排序、逐层收集。仅适用于整数类型数据,排序稳定、效率高,数据位数越少,整体排序速度越快。
**原始数据:**15 79 812 894 561 58 92 95 81 624 98 6
第一趟:按**"个位"**排序
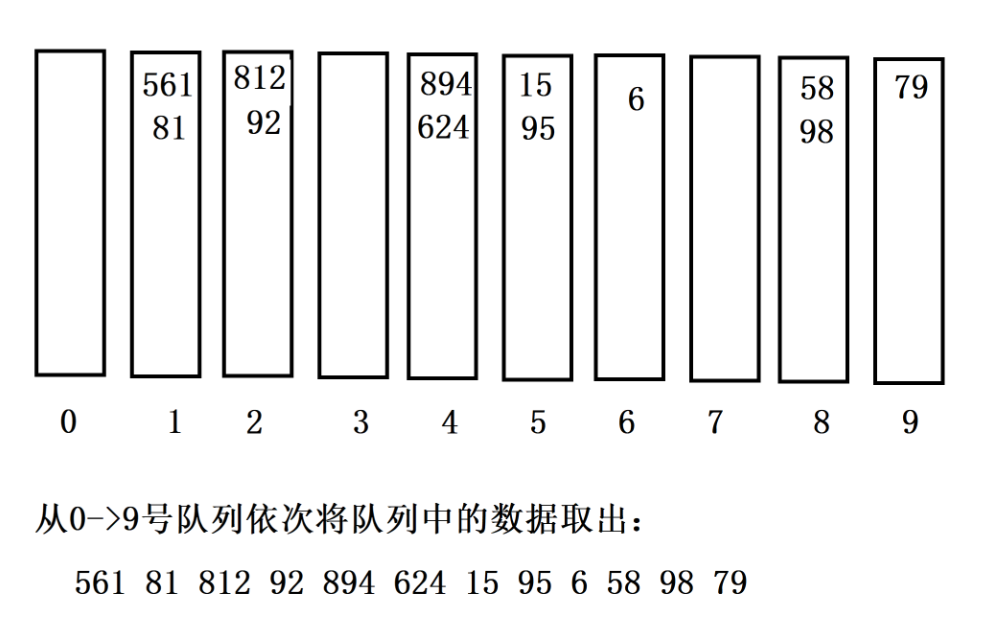
现在只看个位,数据已经完全有序
第二趟:在个位有序的数据基础上,再以**"十位"**进行处理
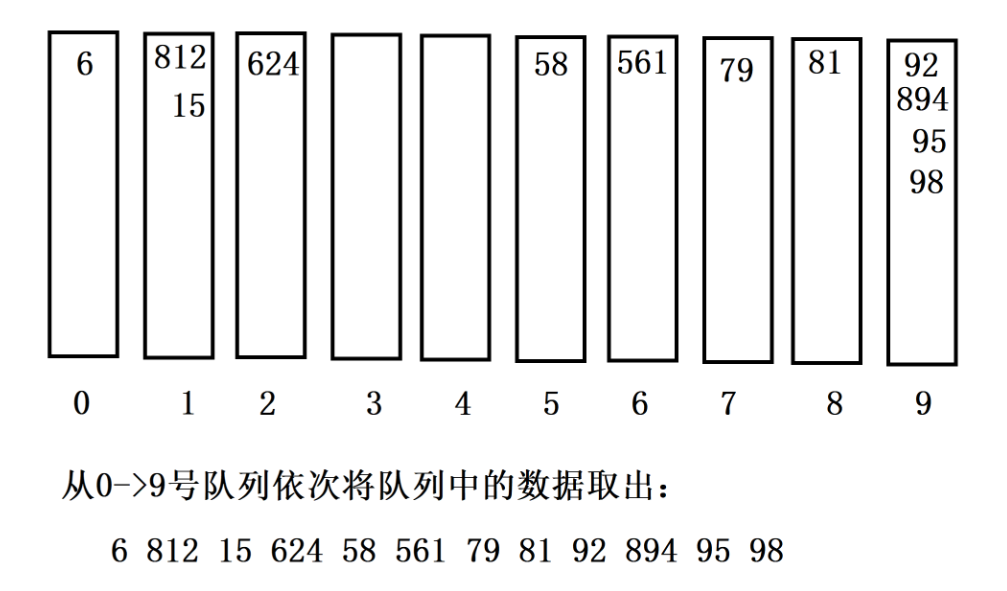
现在只看个位与十位,数据是完全有序的
第三趟:在个位与十位有序的数据基础上,再以**"百位"** 进行处理
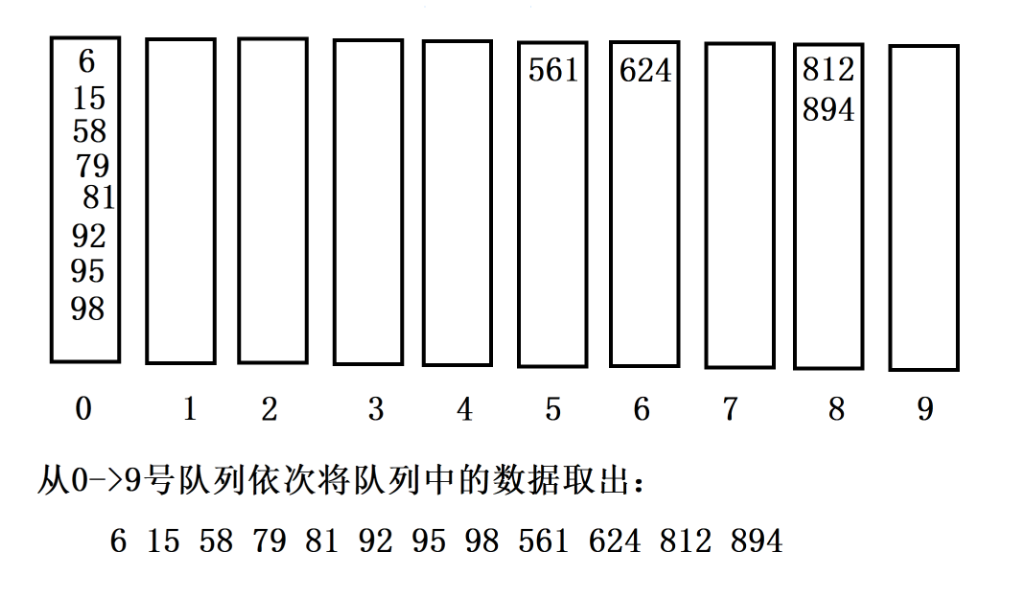
四、八大排序代码实现
1. 直接插入排序
代码思路
- 把数组分为有序区 (默认第一个元素)和无序区
- 从无序区第一个元素开始,保存到临时变量
- 向前遍历有序区,比临时变量大的元素向后挪动
- 找到合适位置,把临时变量插入进去
- 重复直到整个数组有序
C++ 代码实现
cpp
// 直接插入排序:稳定,O(n²)
void Insert_Sort(int arr[], int len) {
// 从第2个元素开始遍历(i从1开始)
for (int i = 1; i < len; i++) {
int tmp = arr[i]; // 保存当前要插入的元素
int j = i - 1; // j指向有序区最后一个元素
// 向前遍历有序区,比tmp大的元素后移
for (; j >= 0 && arr[j] > tmp; j--) {
arr[j + 1] = arr[j];
}
arr[j + 1] = tmp; // 插入到正确位置
}
}2. 希尔排序
代码思路
- 定义递减分组增量 gap(如 5、3、1)
- 按 gap 把数组分成多个小组
- 每个小组内部做直接插入排序
- 逐步缩小 gap,重复分组排序
- 当 gap=1 时,整体做一次插入排序完成
C++ 代码实现
cpp
// 希尔排序单次分组插入
void Shell(int arr[], int len, int gap) {
// 从gap位置开始遍历,组内插入排序
for (int i = gap; i < len; i++) {
int tmp = arr[i];
int j = i - gap;
// 同组元素向前比较移动
for (; j >= 0 && arr[j] > tmp; j -= gap) {
arr[j + gap] = arr[j];
}
arr[j + gap] = tmp;
}
}
// 希尔排序:不稳定,O(n¹·³)
void Shell_Sort(int arr[], int len) {
// 递减增量序列
int gap[] = { 5,3,1 };
int gap_size = sizeof(gap) / sizeof(gap[0]);
// 按不同gap分组排序
for (int i = 0; i < gap_size; i++) {
Shell(arr, len, gap[i]);
}
}3. 选择排序
代码思路
- 遍历数组,每一轮确定一个最小值
- 记录最小值下标
- 把最小值和无序区第一个元素交换
- 缩小无序区范围
- 重复直到全部有序
C++ 代码实现
cpp
// 选择排序:不稳定,O(n²)
void Select_Sort(int arr[], int len) {
// 共需要 len-1 轮
for (int i = 0; i < len - 1; i++) {
int min_index = i; // 记录最小值下标
// 找到未排序区间最小值下标
for (int j = i + 1; j < len; j++) {
if (arr[j] < arr[min_index]) {
min_index = j;
}
}
// 交换到有序区末尾
if (i != min_index) {
int tmp = arr[i];
arr[i] = arr[min_index];
arr[min_index] = tmp;
}
}
}4. 冒泡排序
代码思路
- 相邻元素两两比较
- 前大后小就交换,最大值逐步 "冒" 到末尾
- 每轮结束后,无序区减少一个元素
- 加入标记位优化:无交换则说明已有序,直接退出
- 重复直到有序
C++ 代码实现
cpp
// 冒泡排序(优化版):稳定,O(n²)
void Bubble_Sort(int arr[], int len) {
for (int i = 0; i < len - 1; i++) {
bool flag = true; // 标记本轮是否交换
// 每轮比较到无序区末尾
for (int j = 0; j + 1 < len - i; j++) {
if (arr[j] > arr[j + 1]) {
// 交换
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false; // 发生交换
}
}
if (flag) break; // 无交换,提前结束
}
}5. 快速排序
代码思路
- 选一个基准值,把数组分成 "小左大右" 两部分
- 左右指针交替扫描,交换不符合条件的元素
- 基准值归位,返回下标
- 递归处理左区间和右区间
- 递归结束则数组有序
C++ 代码实现
cpp
// 快排分区函数:小左大右,返回基准下标
int Partition(int arr[], int left, int right) {
int pivot = arr[left]; // 选最左为基准
while (left < right) {
// 右向左找小于基准
while (left < right && arr[right] >= pivot)
right--;
arr[left] = arr[right];
// 左向右找大于基准
while (left < right && arr[left] <= pivot)
left++;
arr[right] = arr[left];
}
arr[left] = pivot; // 基准归位
return left; // 返回基准下标
}
// 快排递归函数
void Quick(int arr[], int left, int right) {
if (left >= right) return;
int par = Partition(arr, left, right);
Quick(arr, left, par - 1); // 递归左区间
Quick(arr, par + 1, right); // 递归右区间
}
// 快速排序:不稳定,O(nlogn)
void Quick_Sort(int arr[], int len) {
Quick(arr, 0, len - 1);
}6. 归并排序
代码思路
- 把数组递归二分,直到每个区间只有一个元素
- 准备辅助数组,合并两个有序区间
- 双指针遍历两个有序段,小的先放入辅助数组
- 把剩余元素依次放入
- 把辅助数组内容拷贝回原数组
C++ 代码实现
cpp
// 合并两个有序区间
void Merge(int arr[], int brr[], int left, int mid, int right) {
int i = left, j = mid + 1; // i左区间起点,j右区间起点
int k = left; // 辅助数组下标
// 双指针合并
while (i <= mid && j <= right) {
if (arr[i] <= arr[j])
brr[k++] = arr[i++];
else
brr[k++] = arr[j++];
}
// 处理剩余元素
while (i <= mid) brr[k++] = arr[i++];
while (j <= right) brr[k++] = arr[j++];
// 拷贝回原数组
for (int m = left; m <= right; m++)
arr[m] = brr[m];
}
// 递归拆分
void Divide(int arr[], int brr[], int left, int right) {
if (right <= left) return;
int mid = (left + right) / 2;
Divide(arr, brr, left, mid); // 拆分左边
Divide(arr, brr, mid + 1, right); // 拆分右边
Merge(arr, brr, left, mid, right);// 合并有序段
}
// 归并排序:稳定,O(nlogn)
void Merge_Sort(int arr[], int len) {
int* brr = (int*)malloc(len * sizeof(int)); // 辅助数组
Divide(arr, brr, 0, len - 1);
free(brr);
}7. 堆排序
代码思路
- 从最后一个非叶子节点开始,自下而上建大顶堆
- 堆顶(最大值)与数组末尾交换
- 排除末尾有序元素,重新调整堆
- 重复交换 + 调整,直到全部有序
C++ 代码实现
cpp
// 堆调整:维护大顶堆
void Heap_Adjust(int arr[], int start, int end) {
int tmp = arr[start]; // 保存堆顶
// i指向左孩子
for (int i = start * 2 + 1; i <= end; i = start * 2 + 1) {
// 取左右孩子较大值
if (i + 1 <= end && arr[i + 1] > arr[i])
i++;
// 孩子大于父节点则上移
if (arr[i] > tmp) {
arr[start] = arr[i];
start = i;
} else {
break;
}
}
arr[start] = tmp; // 节点归位
}
// 堆排序:不稳定,O(nlogn)
void Heap_Sort(int arr[], int len) {
// 建堆:从最后一个非叶子节点开始
for (int i = (len - 2) / 2; i >= 0; i--) {
Heap_Adjust(arr, i, len - 1);
}
// 交换堆顶+调整堆
for (int i = 0; i < len - 1; i++) {
// 最大值交换到末尾
int tmp = arr[0];
arr[0] = arr[len - 1 - i];
arr[len - 1 - i] = tmp;
// 调整剩余元素为大顶堆
Heap_Adjust(arr, 0, len - 1 - i - 1);
}
}8. 基数排序
代码思路
- 找出数组最大值,确定最大位数
- 从个位开始,依次按每一位排序
- 按当前位数字,把元素放入 0~9 队列
- 按队列顺序回收元素,完成本位排序
- 处理到最高位,整体有序
C++ 代码实现
cpp
// 获取最大值的位数
int Get_MaxNum_Figure(int arr[], int len) {
int max = arr[0];
for (int i = 0; i < len; i++)
if (arr[i] > max) max = arr[i];
int count = 0;
while (max > 0) {
max /= 10;
count++;
}
return count;
}
// 获取数字第index位
int Get_Num_digit(int num, int index) {
for (int i = 0; i < index; i++) num /= 10;
return num % 10;
}
// 按某一位进行分配+收集
void Radix(int arr[], int len, int index) {
queue<int> qu[10]; // 0~9号队列
// 分配:按位入队
for (int i = 0; i < len; i++) {
int w = Get_Num_digit(arr[i], index);
qu[w].push(arr[i]);
}
// 收集:依次出队
int j = 0;
for (int i = 0; i < 10; i++) {
while (!qu[i].empty()) {
arr[j++] = qu[i].front();
qu[i].pop();
}
}
}
// 基数排序:稳定,非比较排序
void Radix_Sort(int arr[], int len) {
int index = Get_MaxNum_Figure(arr, len);
// 从低位到高位依次排序
for (int i = 0; i < index; i++)
Radix(arr, len, i);
}五、八大排序对比表
| 排序算法 | 平均时间复杂度 | 最好时间复杂度 | 最坏时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|---|---|
| 直接插入排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 希尔排序 | O(n¹·³) | O(n) | O(n²) | O(1) | 不稳定 |
| 选择排序 | O(n²) | O(n²) | O(n²) | O(1) | 不稳定 |
| 冒泡排序 | O(n²) | O(n) | O(n²) | O(1) | 稳定 |
| 快速排序 | O(nlogn) | O(nlogn) | O(n²) | O(logn) | 不稳定 |
| 归并排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(n) | 稳定 |
| 堆排序 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 不稳定 |
| 基数排序 | O(d*n) | O(d*n) | O(d*n) | O(n) | 稳定 |
**注:**d 代表数据最大位数,n 代表数据元素个数
六、回顾与总结
在排序算法的选择上,总结了三个关键点:第一,小规模数据 适合用插入排序和优化后的冒泡排序,实现简单效率高;大规模数据 优先考虑快排、归并和堆排序,时间复杂度都是O(nlogn )。第二,需要稳定排序 时选择归并、基数排序或优化后的冒泡排序;内存受限时使用堆排序或希尔排序。第三,对纯整数数据,基数排序的效率最高。
每种排序算法都有其最适合的应用场景,比如快排适合通用数据,基数排序适合整数排序,归并排序适合需要稳定性的场景。关键在于理解不同算法的特性,根据具体需求选择最合适的实现。