导读 introduction
Agent 能写代码、能调工具,但它不了解你团队的规范、流程和质量标准,每次对话都从零教起,既低效又不稳定。Skill 机制正是为解决这个问题而生:把你的经验和流程结构化地交给 Agent,让它像拿到工作手册一样自主执行。本文从设计原理、编写方法到评测迭代,梳理 Skill 的实践路径,帮助开发者打造高效易用的Agent Skill。
01 Skill 是什么,为什么需要它
1.1 Agent 的先天缺陷
大模型很聪明,但它有一个根本问题:没有你的私域知识和专属能力。
你团队的代码规范是什么?做 Code Review 要看哪几个维度?创建一份 PPTX 应该遵循什么品牌样式?这些东西不在训练数据里,每次对话都重新教一遍既低效又不稳定。
更现实的问题是,即使你通过 MCP 给了 Agent 工具调用能力,能读 GitHub、能查 Sentry、能操作 Linear,它依然不知道该按什么流程、什么顺序、什么标准去使用这些工具。而 Skill 就可以提供这些信息,帮助Agent更好地执行任务。
1.2 从 MCP 到 Skill:能力扩展的演进
Agent 能力扩展的路径,经历了几个关键节点:
MCP(Model Context Protocol) 解决了"连接"问题。2024 年 11 月 Anthropic 开源 MCP,让 Agent 能够标准化地调用外部工具和数据源。这是基础设施层面的突破,Agent 终于能"伸手"触达外部世界了。
AGENTS.md 是社区自发的探索。随着 Cursor、Claude Code 等 AI 编码助手的普及,开发者很快意识到一个问题:这些 Agent 能写代码,但不了解项目的技术栈选择、代码风格约定、架构决策背景。于是社区开始在仓库根目录放置 AGENTS.md,用自然语言把项目的上下文和规范写给 Agent 看。
Skill 则是 Anthropic 在 2025 年 10 月正式推出的标准化方案。它把 AGENTS.md 的理念系统化,不仅仅是一个 Markdown 文件,而是一个结构化的文件夹,包含指令、脚本、参考文档和资源文件,形成完整的知识包。随后,Cursor、Windsurf 等产品也纷纷推出类似机制,Skill 正在成为 Agent 能力扩展的主流范式。
1.3 Skill 的核心设计:渐进式披露
Skill 最精妙的设计在于它的三级渐进式披露(Progressive Disclosure)机制,不会一次性把内容全塞给模型,而是分层按需加载:
第一级:YAML frontmatter 中的 description 字段。 本质上是一段结构化的自然语言声明,包含三层信息:这个 Skill 干什么用 ("分析 Figma 设计稿并生成开发交付文档")、核心能力是什么 ("设计规范提取、组件文档生成、标注导出")、什么时候触发("当用户上传 .fig 文件或要求'设计转代码交付'时")。它始终存在于 Agent 的系统提示词中,作用类似索引,当用户输入到来时,Agent 拿请求和所有 Skill 的 description 做匹配,命中了才加载对应 Skill 的完整内容。这个设计意味着你可以同时挂载几十个 Skill,而激活判断的成本只是几十行短文本的比对,不需要把所有 Skill 的完整指令都塞进上下文。
第二级: SKILL.md 正文。 当 Agent 判断某个 Skill 与当前任务相关时,才会读取 SKILL.md 的完整内容。这里包含核心指令、工作流程和关键示例。
第三级: references/ 和 scripts/ 。 references/ 目录下的详细文档、scripts/ 下的可执行脚本,这些只在 Agent 执行过程中确实需要时才会去查阅或调用。
为什么要这么设计?它解决了两个实际问题:
- Token 效率:不把所有知识一股脑塞进上下文,避免信息过载。
- 注意力聚焦:模型的注意力机制在上下文越长时衰减越明显,渐进式披露让模型在每个阶段只关注最相关的信息。
1.4 怎么组织和安装 Skill
当 Skill 越写越多,散落在各处很快就会失控。推荐一开始就用Git仓库统一管理。
objectivec
team-skills/
├── code-review/
│ └── SKILL.md
├── react-state-management/
│ ├── SKILL.md
│ └── references/
├── sprint-planning/
│ ├── SKILL.md
│ └── scripts/
└── ...好处很直接:版本有记录,团队能协作,跨仓库安装迅速。
安装到具体的 Agent 平台时,各家的路径约定不同,但社区已经有了统一的解决方案,Vercel 开源的 skills CLI 工具,一条命令兼容多平台:
csharp
# 从 GitHub 安装,自动识别当前环境并放到正确的位置
npx skills add https://github.com/your-team/skills/tree/main/code-review
# 支持 Claude Code、Cursor、Windsurf 等主流 Agent 平台
# 无需关心各平台的路径差异当然,你也可以手动放置安装。因平台和场景而异路径约定不同,以Claude Code为例:
Claude Code:
bash
# 项目级(只在当前项目生效)
.claude/skills/code-review/SKILL.md
# 全局级(所有项目生效)
~/.claude/skills/code-review/SKILL.md社区实践一瞥
Skill 的生态正在快速成长。Anthropic 官方提供了一批高质量 Skill, 在anthropics/skills 仓库,尤其是 pdf、skill-creator、frontend-design 这几个,它们很好地展示了渐进式披露和脚本自动化的最佳实践。这些 Skill 本身就是很好的学习范本。
社区层面,Asana、Atlassian、Figma、Sentry、Zapier 等厂商已经为自己的 MCP Server 配套了 Skill。独立开发者也在持续贡献,从前端设计到代码审查,从数据分析到项目管理,可用的 Skill 库正在不断扩大。
02 如何编写一个 Skill
2.1 基本格式
一个 Skill 在文件系统中是一个文件夹,最小结构只需要一个文件:
bash
your-skill-name/
├── SKILL.md # 必须,入口文件
├── scripts/ # 可选,可执行脚本
├── references/ # 可选,参考文档
└── assets/ # 可选,模板、图标等资源命名规则简单但严格:
- 文件夹名用 kebab-case :
my-cool-skill是正确的,而My Cool Skill以及my_cool_skill等都是无效的。 - 入口文件必须精确命名为
SKILL.md,大小写敏感,skill.md或SKILL.MD都不行 - 不要在Skill文件夹内放README.md(所有文档放在SKILL.md或 references/ 中)
SKILL.md 的结构分两部分:YAML Frontmatter 和 Markdown 正文。
yaml
---
name: my-skill-name
description: 做什么。在用户说"XXX"时使用。核心能力包括 A、B、C。
---
# My Skill Name
## Instructions
具体的指令内容...Frontmatter 用 --- 包裹,其中 name 和 description 是必填字段。正文用标准 Markdown 编写,包含 Agent 执行任务时需要遵循的具体指令。
2.2 工作原理
理解 Skill 的工作原理,有助于写出更有效的 Skill。核心流程是这样的:
阶段一:常驻索引。 你安装的所有 Skill 的 description 字段会被注入到 Agent 的系统提示词中。Agent 在每次对话开始时就"知道"自己拥有哪些 Skill,但不知道具体内容。
阶段二:激活读取。 当用户的请求与某个 Skill 的 description 匹配时,Agent 会使用内置工具(如 view 或 read 命令)读取该 Skill 的 SKILL.md 完整内容。这一步对应 messages[] 中的一个工具调用。
阶段三:执行与深入。 Agent 根据 SKILL.md 中的指令开始执行任务。如果指令中引用了 references/ 下的文档或 scripts/ 下的脚本,Agent 会在需要时再去读取或执行它们。
用 API 的 messages[] 视角来看,一个典型的 Skill 调用大约是这样的
css
用户消息 → Agent 识别需要 Skill → [工具调用: 读取 SKILL.md]
→ Agent 获得指令 → [工具调用: 执行任务步骤] → 返回结果这意味着 Skill 的激活本身会消耗 1-2 步工具调用。所以 description 写得准不准,直接影响 Token 消耗和响应速度,误触发意味着浪费,漏触发意味着能力缺失。
03 编写优质的 Skill
一个 Skill 能不能用和好不好用,差距巨大。这个差距主要体现在两个地方:Description 决定"什么时候用",Body 决定"用起来效果如何"。
3.1 Description:激活的精准度
Description 是整个 Skill 体系中最关键的一行文字。它决定了 Agent 在什么场景下会加载你的 Skill,写得不好,要么该用的时候不触发(under-triggering),要么不该用的时候乱触发(over-triggering)。
三大要素: 一个好的 Description 需要同时回答三个问题
- 能做什么:这个 Skill 的核心价值是什么
- 核心能力:具体包含哪些能力
- 激活条件:用户说什么话、做什么操作时应该触发
正面案例:
makefile
# 清晰、具体、包含触发短语
description: >
分析 Figma 设计稿并生成开发交付文档。当用户上传 .fig 文件、
要求"设计规范"、"组件文档"或"设计转代码交付"时使用。
makefile
# 明确的服务边界和触发词
description: >
管理 Linear 项目工作流,包括迭代规划、任务创建和状态跟踪。
当用户提到"迭代"、"Linear 任务"、"项目规划"或要求
"创建工单"时使用。反面案例:
makefile
# 太模糊,几乎什么都能匹配
description: Helps with projects.
# 缺少触发条件,Agent 不知道什么时候该用
description: Creates sophisticated multi-page documentation systems.
# 过于技术化,没有用户视角的触发词
description: Implements the Project entity model with hierarchical relationships.防止过度触发的技巧: 如果你的 Skill 经常在不相关的场景被加载,可以在 Description 中加入"负向触发"说明:
kotlin
description: >
CSV 文件的高级数据分析,包括统计建模、回归分析、聚类。
不要用于简单的数据浏览(那个用 data-viz skill)。3.2 Body:执行的效果
Description 写好了只是让 Skill 在对的时间出现,Body 的质量才决定最终效果。根据使用场景,Body 通常呈现两种形态:
形态一:知识文档型
适用于需要 Agent 掌握特定领域知识或遵循特定标准的场景。
核心要素:
- 领域知识:把你的专业判断和决策逻辑写成 Agent 可以理解的规则
- 质量检查清单:明确定义"什么算做好了",让 Agent 在交付前自查
- Few-Shot 示例:给出 2-3 个输入输出的范例,比抽象描述有效得多
markdown
## Code Review Standards
### Critical Checks (must pass)
1. No hardcoded credentials or API keys
2. All user inputs sanitized
3. Error boundaries on async operations
### Quality Checks (should pass)
1. Functions under 50 lines
2. Meaningful variable names (no single letters except loop counters)
3. Comments explain "why", not "what"
### Example Review
**Input:** A React component with inline styles and no error handling
**Expected output:**
- Flag: inline styles → suggest CSS modules or Tailwind
- Flag: missing error boundary → provide template
- Pass: component size reasonable
- Suggestion: extract magic numbers to constants形态二:工作流型
适用于多步骤、有固定流程的任务。
核心要素:
- 步骤清晰:每一步做什么、调用什么工具、预期输出是什么
- 步骤间校验:上一步的输出满足条件才进入下一步,而不是盲目往下走
- 可循环迭代:对质量不达标的输出能回到前面的步骤重做
shell
## Sprint Planning WorkflowStep 1: Gather Context
`Fetch current project status from Linear. Validation: Confirm at least 1 active project returned.
Step 2: Analyze Velocity
Calculate team velocity from last 3 sprints. Validation: Velocity data covers at least 2 complete sprints.
Step 3: Draft Plan
Create task breakdown with estimates. Validation: Total story points ≤ average velocity × 0.85 (buffer).
Step 4: Review & Adjust
Present plan to user. If user requests changes: → Return to Step 3 with modified constraints.
Step 5: Execute`
Create tasks in Linear with labels and assignments. Validation: All tasks created successfully, no API errors.
3.3 进阶技巧:分层与自动化
多层渐进: SKILL.md 只放核心指令和工作流主干。详细的 API 文档、完整的示例库、边缘场景的处理方案,都放到 references/ 目录下,在正文中用明确的路径引用:
diff
Before writing API queries, consult references/api-patterns.md for:
- Rate limiting guidance
- Pagination patterns
- Error codes and handling这样既保证 Agent 知道有这些资源可用,又不会在每次激活时都加载全部内容。
脚本自动化: 凡是可以用代码确定性完成的事情,就不要让模型用自然语言"理解"着去做。模型理解自然语言有概率性,但代码执行是确定性的。
官方的 PDF、DOCX、PPTX 等 Skill 大量使用了这个模式,核心的文档生成逻辑封装在 Python 脚本中,SKILL.md 只负责告诉 Agent 什么时候调用哪个脚本、传什么参数。
04 基于评测迭代
写完 Skill 不是终点。Skill 本质上是给概率性系统写的指令,"我觉得写得挺好"和"它确实在各种场景下都表现稳定"之间,往往隔着好几轮迭代的距离。评测不是锦上添花,而是 Skill 开发流程中不可省略的一环。
4.1 核心理念:像对待 Prompt 一样对待 Skill
Skill 的 Description 是系统提示词的一部分,Body 是任务执行时的指令集。这使得 Skill 开发和 Prompt 开发面临相似的挑战,而 Prompt 开发有一个被反复验证的基本事实:你无法靠直觉判断一段指令的好坏,只能靠在真实场景中反复测试来验证。
这引出三个关键原则:
原则一:分层评测。 Description 和 Body 解决的是完全不同的问题,前者决定"什么时候用",后者决定"用起来效果如何"。它们的评测方法、评测标准和迭代策略完全不同,必须分开处理。
原则二:对照实验。 "好不好"是相对概念。一个 Skill 的输出质量,只有和某个基线对比才有意义。这个基线可以是没有 Skill 时的裸跑效果,也可以是上一个版本的 Skill。没有对照组,改进就无从衡量。
原则三:人类参与。 自动化评分能覆盖格式、结构、字段完整性这类客观检查,但 Skill 真正的价值,比如审美判断、业务适配度、专业深度,只有人能评估。评测流程的设计必须让人的判断能高效地注入迭代循环。
4.2 评测 Description:触发的精准度
Description 评测要回答一个简单的问题:Agent 在该用这个 Skill 的时候用了吗?在不该用的时候没用吧?
理解触发机制
在动手测之前,先理解两个关于触发的事实:
事实一:Agent 只在觉得自己搞不定时才找 Skill。 简单的一步操作(比如"读一下这个文件"),即使 Description 完美匹配也可能不触发,因为 Agent 判断自己直接就能完成。这意味着你的测试用例必须足够复杂,不然你测的不是 Description 好不好,而是任务够不够难。
事实二:Agent 天生偏向欠触发(under-triggering)。 Description 要写得主动一点,把边界往外推。比如不只写"分析 Figma 设计稿并生成交付文档",而是追加"当用户提到设计规范、UI 组件文档、设计转代码交付,甚至只是上传了 .fig 文件但没明说要干嘛时,都应该使用"。
还有一个常见错误:把"什么时候该用这个 Skill"的信息写在 Body 里。Body 是触发之后才加载的,写了也没有任何帮助。所有触发相关的信息,必须且只能写在 Description 中。
构建评测集
准备 16-20 条测试 query,分两组:
- 应触发组(8-10 条) :覆盖不同的表述方式,正式的、口语的、没有明确提到 Skill 名称但显然需要它的
- 不应触发组(8-10 条) :重点选近似场景,而非明显无关的请求
arduino
[
{
"query": "我们团队要移除 less-loader,把 .less 文件全部转成 PostCSS 方案。项目比较大有 200 多个 LESS 文件,有复杂的 mixin 嵌套,用哪种方式风险更低?",
"should_trigger": true
},
{
"query": "项目已经在用 PostCSS 了,现在想加 postcss-px-to-viewport 做移动端适配,postcss.config.js 不知道怎么写。",
"should_trigger": false
}
]构建评测集时最容易踩的坑:
- 测试 query 太干净。 "请帮我做代码审查"这种教科书式的指令在真实场景中几乎不存在。真人会带上文件路径、个人上下文、前因后果,甚至拼写错误和口语缩写。你的测试 query 越像真人说的话,评测结果越有参考价值。
- 反例太容易。 "写一个斐波那契函数"作为 CSS 迁移 Skill 的反例毫无价值。最有意义的反例是那些共享了关键词但实际需要别的工具 ,或者触及了 Skill 的领域但处于一个不该触发的上下文中的 query。这些边界 case 才能真正检验 Description 的区分度。
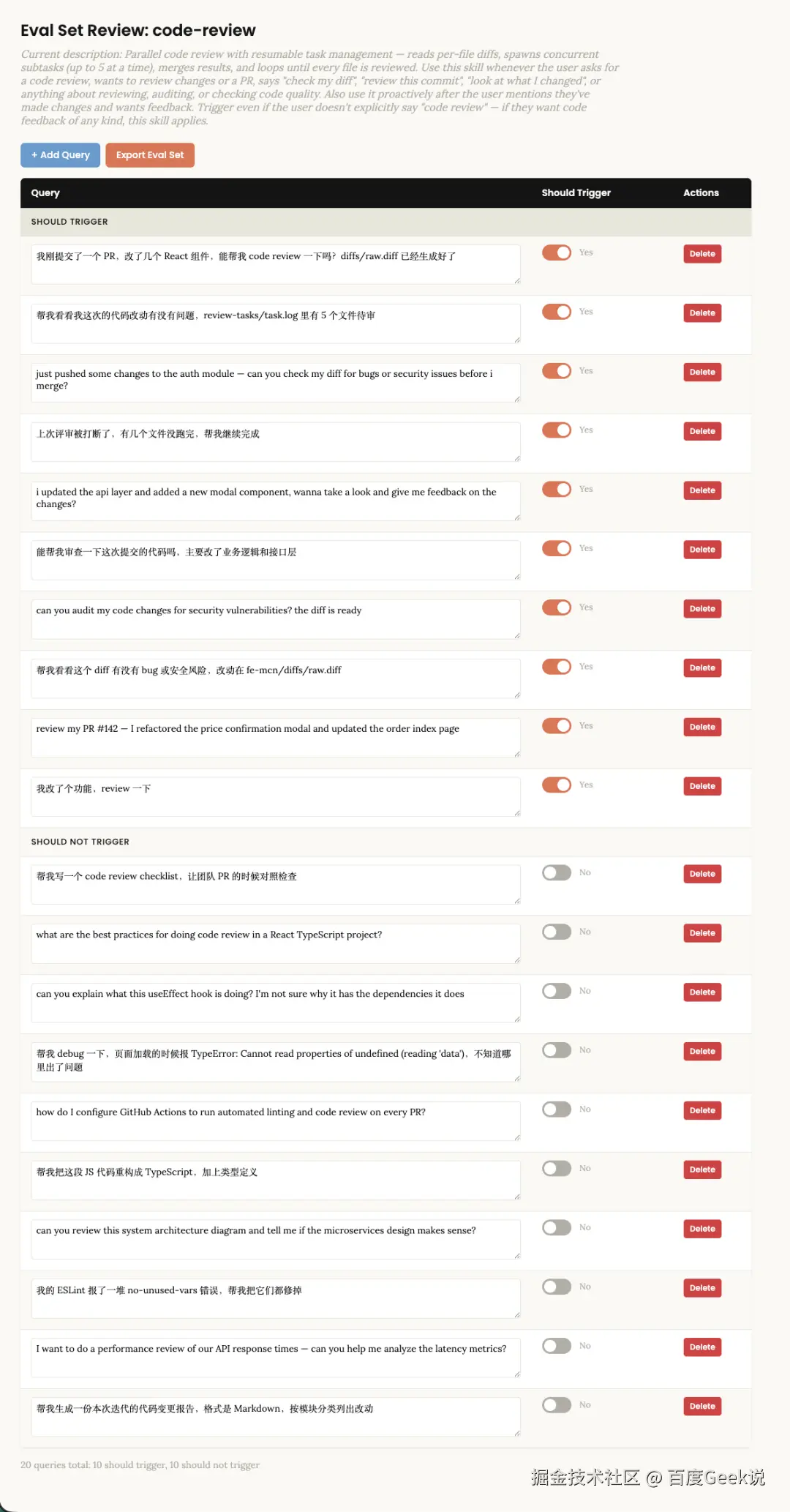 △ code-review skill的触发测试 △ code-review skill的触发测试 |
 △ less-to-postcss skill的触发测试 △ less-to-postcss skill的触发测试 |
|---|
执行评测
逐条把测试 query 发给 Agent,观察它是否加载了对应的 Skill。记录结果,计算两个指标:
- 召回率:应触发组中实际触发的比例(衡量"该用的时候用了没")
- 精确率:不应触发组中正确未触发的比例(衡量"不该用的时候克制住了没")
💡 一个快速调试技巧:直接问 Agent "你什么时候会使用 skill-name 这个 Skill?",它会把 Description 复述回来,你可以据此判断它的理解是否与你的意图一致。
迭代改进
根据失败 case 分析原因,调整 Description:
- 漏触发居多:补充更多触发关键词和场景描述,把边界推得更宽
- 误触发居多:增加负向说明("不要用于..."),收窄适用范围
- 两者都有:Description 可能定位模糊,需要重新理清这个 Skill 的核心边界
每次修改后,用完整评测集重跑,对比前后得分。注意不要只盯着失败的 case 做针对性修补。Description 最终要面对的是无穷多种真实 query,过拟合到几条测试用例没有意义。
4.3 评测 Body:输出质量
Body 的评测比 Description 复杂得多,因为"好不好"不是布尔值,而是一个多维度的质量判断。核心方法是有 Skill 和无 Skill 的对照实验。
Step 1:设计测试用例
准备 2-5 个代表性的测试任务。好的测试用例有几个特征:
- 覆盖 Skill 的核心能力,不要只测边缘功能
- 有明确的可判断的输出,而不是开放性的问答
- 复杂度接近真实使用场景,太简单的任务区分不出有无 Skill 的差异
每个测试用例准备好输入材料(需要审查的代码、需要分析的数据、需要处理的文档等)。
Step 2:对照实验
对每个测试用例,分别跑两次:
- 实验组:正常加载 Skill,执行任务
- 对照组:不加载 Skill(或加载旧版本 Skill),执行相同任务
关键要求:用相同的 Agent、相同的输入、相同的系统环境。唯一的变量是 Skill 的有无或版本差异。
把输出保存在结构化的目录中,方便后续对比:
javascript
eval-workspace/
├── iteration-1/
│ ├── test-case-auth-module/
│ │ ├── with-skill/
│ │ └── baseline/
│ ├── test-case-api-refactor/
│ │ ├── with-skill/
│ │ └── baseline/
│ └── ...Step 3:定义评判标准
在看结果之前(避免结果影响标准),先想清楚"什么算好"。评判标准分两类:
可程序化验证的客观标准,用脚本直接检测:
- 输出文件格式是否合法(JSON schema 校验、文件是否可打开)
- 必要字段是否存在
- 是否满足特定的结构要求
需要人判断的主观标准,形成检查清单:
- "每个问题是否附带了具体的修改建议,而非仅描述问题"
- "是否有将正确代码误标为问题的情况"
- "输出的优先级排序是否合理"
对于写作风格、设计审美这类高度主观的 Skill,不需要勉强定义细粒度标准,直接看输出、做整体判断,反而更有效。
Step 4:评分和对比
逐个翻看每个测试用例的两组输出,记录:
- 客观检查项的通过情况:跑脚本,统计通过率
- 主观判断和具体反馈:哪里好、哪里差、哪里出乎意料。反馈要写具体。"输出不够好"没有行动指引,"安全维度的审查遗漏了 SQL 注入风险,建议在 Skill 中增加 OWASP Top 10 检查清单"才能指导改进
- 效率数据:如果可获取,记录 token 消耗和响应时间,避免质量提升以不可接受的效率代价为前提
最终形成一个清晰的判断:Skill 版本在哪些维度上比基线好、在哪些维度上持平、在哪些维度上退步了。
Step 5:分析和改进
基于评分结果和具体反馈,修改 Skill。这一步是整个迭代中最需要判断力的环节,几个关键原则:
从反馈中提炼通用规律,别过拟合到具体用例。 Skill 最终要在无数不同的真实任务上运行,你现在只是用几个测试用例来快速迭代。如果某个改动解决了测试用例 B 的问题但让测试用例 A 退步了,大概率你在做过于针对性的调整。好的改动应该是普适的。
保持指令精简。 如果能获取到 Agent 的执行过程(而不只是最终输出),仔细看看它在做什么。如果 Agent 花了大量步骤在做无用功,找到 Skill 中导致这些无用功的指令,砍掉试试。冗余的指令不只是浪费 token,还会分散模型的注意力,降低真正重要的指令的执行质量。
解释 why 而不是堆 MUST。 如果你发现自己在写 ALWAYS 或 NEVER 这种全大写的硬约束,先停下来想想,能不能换成解释"为什么这件事重要"。模型理解了原因之后,执行的灵活性和准确度通常都比死记硬背的规则好。硬约束应该留给那些真正不可违反的底线,而不是泛滥在每一条指令里。
关注重复劳动。 如果你在多个测试用例的输出中发现 Agent 都独立编写了类似的辅助脚本或做了类似的预处理工作,这说明这个步骤应该被提炼到 Skill 的 scripts/ 目录下直接复用,而不是每次让 Agent 从头造轮子。
常见问题和改进方向参考:

 △ body的评测结果 - 有无skill对比 △ body的评测结果 - 有无skill对比 |
 △ body的评测结果 - 经过迭代对检出问题细节优化 △ body的评测结果 - 经过迭代对检出问题细节优化 |
|---|
4.4 循环迭代
把上面的步骤连成闭环,每一轮迭代的流程是:
- 跑对照实验:在新的目录下同时跑所有测试用例的实验组和对照组
- 评分:客观指标跑脚本,主观维度人工判断
- 分析反馈:哪里好了、哪里退步了、哪里还不够
- 改 Skill :基于反馈修改 SKILL.md 或脚本,遵循上述改进原则
- 重跑:用完整评测集验证改动效果
对照组的选择取决于你要回答的问题。如果是新建 Skill,对照组就是没有 Skill 的裸跑,你要证明 Skill 的存在有价值。如果是改进已有 Skill,对照组可以是旧版本,你要证明改动带来了正向提升。
终止条件:反馈趋于空白(没什么要改了)、你已经没有更多手段继续改进、或者你对输出质量满意了。不需要追求完美,Skill 和代码一样,可以持续迭代,在实际使用中收集到新的失败 case 时随时回来改进。
4.5 案例:Skill 迭代的实际路径
案例一:Skill-Creator 的三次进化
Anthropic 官方的 Skill-Creator 本身就经历了迭代式演进:
- 第一版(创建) :帮用户从自然语言描述生成 SKILL.md,输出格式正确的 Frontmatter 和基本指令结构。核心价值是降低上手门槛。
- 第二版(创建 + 优化) :增加了分析与改进的能力,将自身能力边界进行了拓展,可以承接几乎所有与Skill相关的工作,因此其
description也变得更为激进。用户指出Skill执行时的问题和现象后,可以自主改进Skill内容并给出建议。 - 第三版(自动评测优化) :基于完整的评测改进循环理论进行构建,不仅仅为生成、改进内容工作负责,也为Skill的最终运行效果负责。这一版可以基于需求生成评测用例、创建评分机制、运行评测、评价汇总、循环改进,完成Skill编写的同时给出效果结论。
案例二:Code-Review Skill 的质量提升
一个更贴近业务的例子,代码审查 Skill 的迭代过程:
- 第一版(简单 Prompt) :一段直白的 Markdown 指令,列出审查维度和注意事项,以及项目隐式需要注意的的点。效果还行,但输出质量波动大,有时遗漏重要问题,有时对细枝末节过度关注,如果
git diff的文件信息过多上下文会超出导致失败。 - 第二版(多 Agent 组合架构) :引入 SubAgent 模式,每个 Subtask Agent 只持有一个文件的diff + 源码,不会被其他文件干扰。单 Agent 串行审查时,随文件数增加上下文污染越来越严重;并发子Agent 则始终保持干净的注意力窗口。把一次 Code Review 拆解为多个阶段,总览分析(掌握全局)、分维度审查(安全、性能、可维护性分别深入)、使用子agent交叉验证(排除误报)、去重合并(消除冗余)、最终报告(按优先级排序输出)。每个阶段有明确的输入输出契约和质量检查点。依赖文件系统,有明确的"任务是否全部完成"的可检查标准,即使因为网络超时中断,也可以恢复继续处理任务,单个子任务失败不影响其他任务的完成,失败的任务重新跑而无需跑整个PR。
两个版本在相同的 20 个 PR 上跑评测,用 Grader Agent 评估输出质量、覆盖率和误报率,第二版在三项指标上均有明显提升。

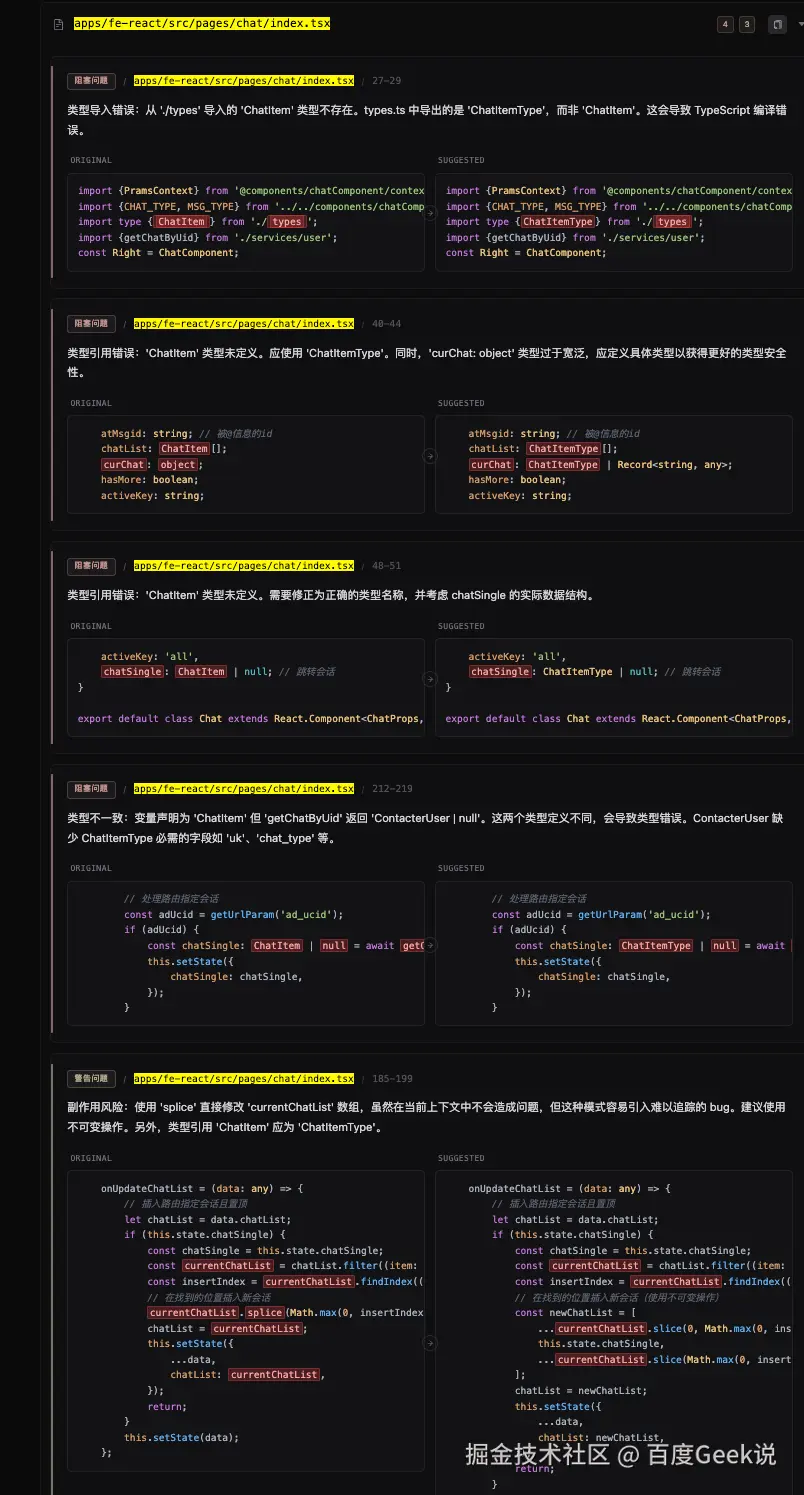 △ 旧架构的检出效果 △ 旧架构的检出效果 |
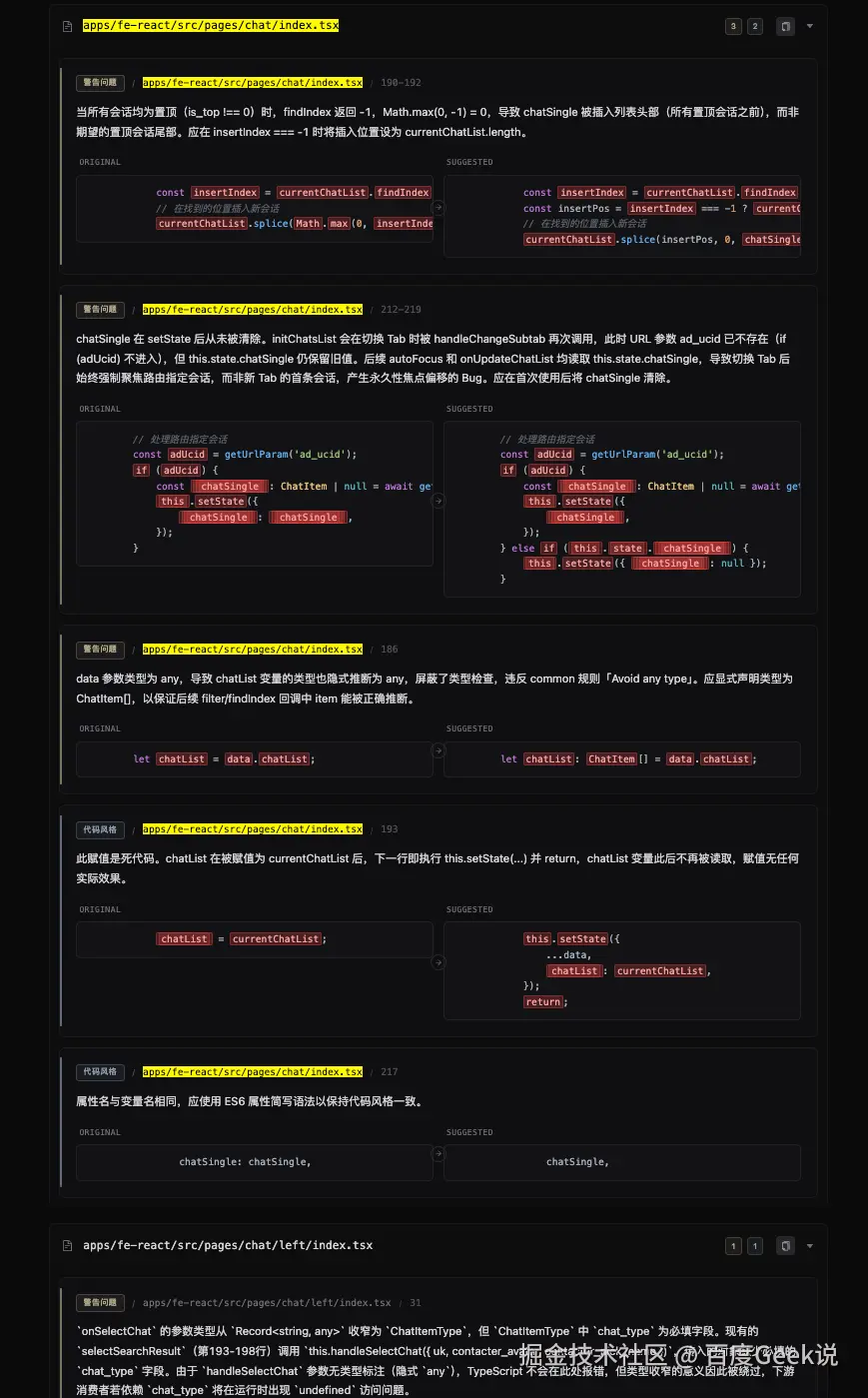 △ 新架构的实现效果,更关注逻辑实现和减少误判 △ 新架构的实现效果,更关注逻辑实现和减少误判 |
|---|
05 总结
Skill 正在统一 Agent 能力扩展的途径。 从 MCP 提供工具连接,到 AGENTS.md 的社区探索,再到 Skill 的标准化方案,Agent "学习新技能"的方式正在收敛。渐进式披露的设计不仅节省 Token,更重要的是提升了模型的注意力分配效率。以自然语言为载体的知识表达,比硬编码的逻辑更灵活,也更 Agentic。
广泛的社区 Skill 可以直接提升生成效果。 Anthropic 官方的文档生成 Skill(PDF、DOCX、PPTX)、前端设计 Skill,以及社区贡献的各类工作流 Skill,都可以拿来即用。在你动手定制之前,先看看现有 Skill 能否满足需求。
定制化 Skill 是让 Agent 在你的场景中真正好用的关键投入。 通用的 Agent 能力就像一个聪明但不了解你业务的新人,Skill 就是你给他的工作手册。Description 的精准度决定了它出现在正确的场景,Body 的质量决定了它在场景中的表现。这两者都有明确的设计原则和可遵循的技巧。
评测是 Agentic 工程必不可少的环节。 不只是工具开发、系统开发需要评测,Skill 开发同样需要。拍脑袋觉得"差不多了"和用数据验证"确实好了"之间,往往隔着好几轮迭代的距离。基于评测的循环优化,评测、分析、改进、重新评测,是通往高质量 Skill 的可靠路径。
回过头看,Skill 做的事情并不复杂:把你本来每次都要重新交代的经验、流程和标准,整理一次存下来,之后 Agent 自己就知道该怎么做了。省掉重复劳动,换来稳定可预期的输出。