什么是多路转接?
举个例子,普通人钓鱼都是坐在那什么都不做干等着鱼上钩,有一个富豪,拉了一车鱼竿,哪个上钩了去哪里捞鱼,这个富豪就是多路转接的IO,与基础IO的区别就是,他可以同时等很多文件,IO效率高。
一、select
IO=等+拷贝
select负责一件事情,就是等,它可以一次等待多个fd。
一旦多个fd有任意一个或多个fd的事情就绪了,select就会通知上层,告诉调用方哪些fd已经可以IO了!
结论:select是通过等待多个fd的一种就绪时间通知机制
什么叫做可读?什么叫做可写?
底层有数据,读事件就绪。
底层有空间,写事件就绪。
最开始的fd:接收和发送缓冲区都是空的,所以对于fd一般默认读事件不就绪,写事件默认就绪。
1.select函数
cpp
#include <sys/select.h>
int select(int nfds, fd_set *readfds, fd_set *writefds,
fd_set *exceptfds, struct timeval *timeout);2.参数
timeval:
cpp
struct timeval {
time_t tv_sec; /* 秒*/
suseconds_t tv_usec; /* 微秒 */
};fd_set:内核提供给用户的数据结构,一次可以运行向fd_set里边添加多个fd,位图结构实现
①nfds:你要检测的最大文件描述符+1,比如你要检测4、6、7、9,那么nfd就是9+1=10;
②timeout:struct timeval是一种表示时间的结构体,如果等待时间超过设置的时间,select立即返回,等待文件描述符超时,如果设置为NULL,就没有时间限制,也就是阻塞等待,如果设置为0,那就是只检查一次有哪些fd就绪,不等待直接返回,本质是非阻塞轮询。timeout是一个输入输出型参数,输入为设置的时长,返回为剩余时间;
③返回值:
大于零: 是几就表示几个fd就绪;
等于零: 超时了;
小于零: 报错;
④readfds:输入输出型参数
输入:比特位的位置,代表fd编号,比特位的内容,表示是否关心,置1就关心,简单说就是用户告诉内核,你要啊帮我关心哪些fd上的读事件;
输出:内核告诉用户,你让我关心的哪些fd上边的读事件已经就绪了,比特位的位置表示fd编号,比特位的内容表示是否就绪;
⑤writefds:写事件,规则与readfds相同;
⑥exceptfds:异常事件,规则同上。
细节①位图是输入输出型的,所以将来这个位图一定会被频繁变更
②位图有多少个比特位,就决定了select最多能关心多少个fd,fd_set是一个系统提供的数据类型:fd_set大小固定,所以select能同时等待的fd有上限,测试可知上限为1024(不同版本可能有不同)
cpp#include <sys/select.h> #include <iostream> int main() { fd_set fset; std::cout << sizeof(fd_set) * 8 <<std::endl; }③如果把fd添加到readfds集合中,表示该fd,只关心读事件,如果想要同时关心读写:就将对应的文件描述符同时添加到readfds和writefds中,同理关心异常继续添加就行了。

3.接口
cpp
void FD_CLR(int fd, fd_set *set);
int FD_ISSET(int fd, fd_set *set);
void FD_SET(int fd, fd_set *set);
void FD_ZERO(fd_set *set);①FD_CLR:从set中将指定的fd移除;
②FD_ISSET:判断一个fd是否在对应的set集里;
③FD_SET:把fd添加到set集里;
④FD_ZERO:清空set集。
4.SelectServer
篇幅问题,我将SelectServer单独写入了一篇文章,链接如下:
5.select的特点
①可监控的文件描述符个数取决于sizeof(fd_set)的值,每个bit表示一个文件描述符,导致服务器支持的最大文件描述符是有上限的,我的服务器是1024个,太少了;
②将fd加入select监控集的同时,还要使用一个数据结构array保存放到select监控集中的fd,一是用于在select返回后,array作为源数据和fd_set进行FD_ISSET判断,二是select返回后会把以前加入的但并无事件发生的fd清空,则每次开始select前都要重新从array取得fd逐一加入,扫描array的同时取得fd最大值maxfd,用于select的第一个参数;
③每次调用select,都需要手动设置fd集合,从接口使用角度来说也非常不便;
④每次调用select,都需要吧fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大;
⑤每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多的时候很大。
二、poll
poll的作用是什么?
poll只负责等,一次可以等待多个fd,事件就绪就可以对上层进行事件通知。
1.poll函数
cpp
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);2.参数
①fds
调用的时候,fd和events有效:用户告诉内核,你要帮我关心fd上边的events事件
poll成功返回的时候,fd和revents有效:内核告诉用户,你要让我关心的fd上边的events事件已经就绪了。
cppstruct pollfd { int fd; /* file descriptor */ short events; /* requested events */ short revents; /* returned events */ };fd:
- 要监控的文件描述符,比如
0(标准输入)、socket()返回的套接字描述符。- 若
fd = -1,内核会忽略这个结构体的events,且revents会被置为 0。events(常用取值):
表格
取值 含义 POLLIN 数据可读(包括普通数据 / EOF) POLLOUT 数据可写 POLLERR 发生错误(无需手动设置,内核自动检测) POLLHUP 挂起(比如对方关闭连接) revents :调用
poll()后,内核会根据实际事件填充这个字段,你需要通过判断它的值来确定发生了什么事件(比如revents & POLLIN为真,表示该 fd 可读)。
②nfds
nfds_t nfds
- 表示
fds数组中有效元素的个数(即你要监视的文件描述符总数)。nfds_t是一个无符号整数类型(通常是unsigned int),目的是告诉内核要遍历多少个pollfd结构体。- 示例:如果
fds数组有 3 个要监视的元素,nfds就传 3。
③timeout
表示
poll()函数的超时时间(单位:毫秒),控制函数的阻塞行为:表格
取值 行为 > 0 阻塞指定毫秒数,超时后返回 0 = 0 非阻塞模式,立即返回(不管是否有事件) < 0 无限阻塞,直到有至少一个文件描述符触发事件
3.注意
①poll输入输出参数分离了,所以不用在poll之前进行参数重置了;
②poll等待的fd个数没有上限。
4.pollserver
为了条理更加清晰,pollserver部分我单独写了一篇文章,链接如下:
5.poll的优缺点
优点
①不同于select使用了三个位图来表示fdset的方式,poll使用一个pollfd的指针实现;
②pollfd结构包含了要监视的event和发生的event,不再使用select"参数-值"传递的方式,因此接口使用比select更方便;
③poll并没有最大数量限制。
缺点
①和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符;
②同时连接大量客户端在一时刻可能只有少量的出于就绪状态,因此随着监视的描述符数量的增长,其效率也会线性下降。
特点
每次调用poll都需要吧大量的pollfd结构从用户态拷贝到内核态。
三、epoll
epoll核心定位:基于对多个fd等待的就绪事件通知机制,通过等来达到通知的目的(同select,poll)
什么是epoll?
因为poll在处理用户量过多的时候,效率会降低,epoll是为了处理大量句柄二改进的poll。
虽然epoll是poll的升级版,但是epoll的实现原理与接口和poll差别非常大。
为什么需要epoll?
用「老师点名」的比喻理解:
- select/poll:老师每次上课都要拿着「全班名单」(所有文件描述符)挨个喊名字,不管学生有没有到(不管 fd 是否就绪),哪怕只有 1 个学生到了,也要遍历全班。缺点:① 遍历所有 fd,fd 越多越慢;② 每次调用都要重新传递 fd 列表(用户态→内核态拷贝);③ 最大支持 fd 数有限(如 select 默认 1024)。
- epoll:老师提前让学生「签到登记」(把关注的 fd 注册到 epoll 实例),学生到了主动举手(fd 就绪时内核标记),老师只需要看「举手的学生」(就绪 fd 列表)。优点:① 只处理就绪 fd,无轮询开销;② fd 只需注册一次(无需重复拷贝);③ 支持海量 fd(仅受系统内存限制)。
1.epoll接口
epoll不同于select和poll使用一个接口实现,epoll提供了三个接口来帮助我们完成想要完成的工作。
①epoll_create
cpp#include <sys/epoll.h> int epoll_create(int size);功能:创建epoll模型
参数:目前版本已忽略,但必须大于零
返回值:失败返回-1,成功返回文件描述符,用来操作epoll。
②epoll_ctl
cpp#include <sys/epoll.h> int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);功能:向指定epoll文件描述符中新增特定文件描述符的特定事件。
参数:
a.epfd:epoll句柄,epoll_create的返回值,用来控制epoll
b.op:代表你想做什么操作,如下图三个选项,增删改
c.fd:你所要监管的文件描述符
d.event:用户告诉内核,你要帮我关心哪一个fd上边的event事件
cpptypedef union epoll_data { void *ptr; int fd; uint32_t u32; uint64_t u64; } epoll_data_t; struct epoll_event { uint32_t events; /* Epoll events */ epoll_data_t data; /* User data variable */ };events可以是以下⼏个宏的集合:
• EPOLLIN : 表⽰对应的⽂件描述符可以读 (包括对端SOCKET正常关闭);
• EPOLLOUT : 表⽰对应的⽂件描述符可以写;
• EPOLLPRI : 表⽰对应的⽂件描述符有紧急的数据可读 (这⾥应该表⽰有带外数据到来);
• EPOLLERR : 表⽰对应的⽂件描述符发⽣错误;
• EPOLLHUP : 表⽰对应的⽂件描述符被挂断;
• EPOLLET : 将EPOLL设为边缘触发(Edge Triggered)模式, 这是相对于⽔平触发(Level Triggered)来说的.
• EPOLLONESHOT:只监听⼀次事件, 当监听完这次事件之后, 如果还需要继续监听这个socket的话, 需要再次把这个socket加⼊到EPOLL红⿊树⾥.
可以通过按位或设置进event中
返回值:成功0被返回,失败-1被返回
③epoll_wait
cpp#include <sys/epoll.h> int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);参数:
epfd:同epoll_ctl
events:内核通知用户,你让我关心的哪些fd门的哪些事件已经就绪了
maxevents:events长度
timeout:同poll

2.epoll原理
epll底层是由一个红黑树、一个就绪队列和回调组成。
红黑树本质是告诉内核,你要帮我关心哪个fd的哪一个事件;
就绪队列本质是内核告诉用户,哪一个文件描述符上的哪一个事件已经就绪了;
在网络协议栈中,存在一种回调机制:在底层,特定的fd上有数据就绪,会自动进行回调,激活红黑树中的节点,激活到就绪队列中。
注意:节点激活到就绪队列,不是将节点移动,而是一个节点即属于红黑树,又属于就绪队列,激活本质就是进行指针操作。
内核态核心结构(epoll 高效的关键)
epoll 在内核中维护了 3 个核心数据结构,这是它高效的本质:
- 红黑树(RB-Tree):存储所有「被监控的 fd」及对应的事件(由 epoll_ctl 维护)。作用:快速增删改 fd(红黑树的增删改查时间复杂度 O (logn)),解决了 select/poll 每次传递 fd 列表的问题。
- 就绪链表(Ready List):存储「已就绪的 fd」(内核主动把就绪 fd 加入此链表)。作用:epoll_wait 只需遍历此链表,无需轮询所有 fd,这是 epoll 最核心的优化。
- 回调机制(Callback):内核为每个被监控的 fd 绑定一个回调函数。作用:当 fd 就绪(如收到数据)时,内核自动触发回调,把该 fd 加入「就绪链表」,无需主动轮询。
在epoll模型中,三个接口分别负责的哪些工作呢?
①epoll_create:创建两种结构(红黑树、就绪队列),注册一种机制(回调机制);
②epoll_ctl:修改维护(增删改)红黑树;
③epoll_wait:只关心就绪队列,监测是否有fd就绪
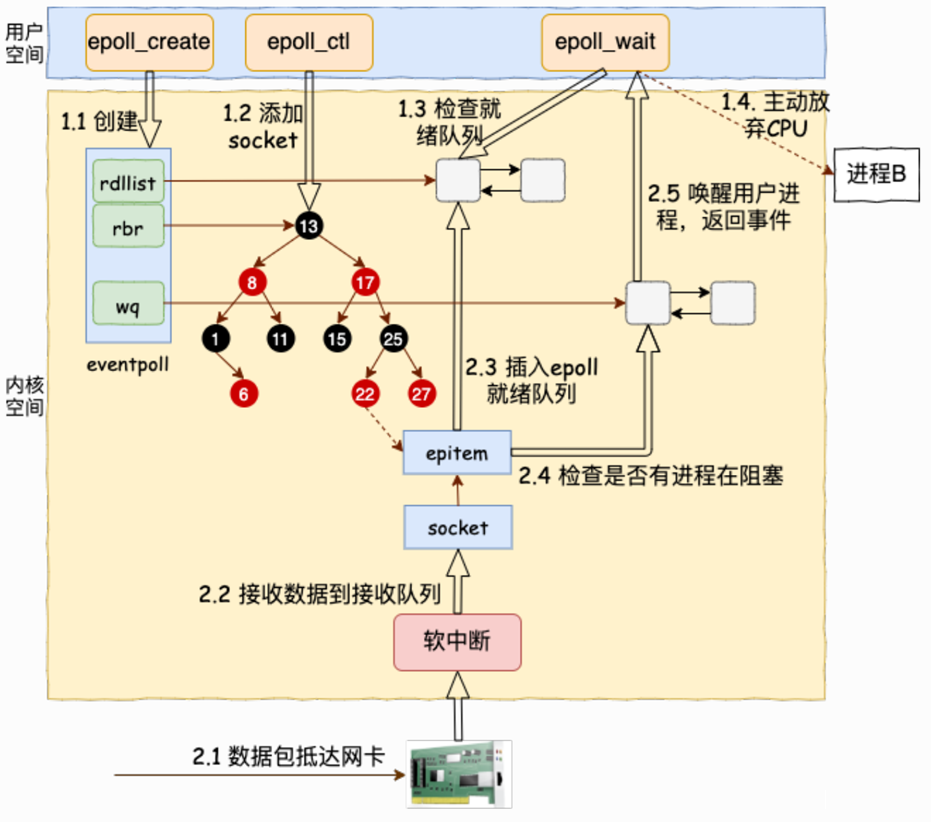
如何看待就绪队列?
当有数据到来的时候,epoll_wait将新到来的结点添加到就绪队列中,然后按顺序读取就绪队列中的数据,所以就绪队列本质就是一个生产者消费者模型。
3.epoll的优点
①接⼝使⽤⽅便: 虽然拆分成了三个函数, 但是反⽽使⽤起来更⽅便⾼效. 不需要每次循环都设置关注的⽂件描述符, 也做到了输⼊输出参数分离开
②数据拷⻉轻量: 只在合适的时候调⽤ EPOLL_CTL_ADD 将⽂件描述符结构拷⻉到内核中, 这个操作并不频繁(⽽select/poll都是每次循环都要进⾏拷⻉)
③事件回调机制: 避免使⽤遍历, ⽽是使⽤回调函数的⽅式, 将就绪的⽂件描述符结构加⼊到就绪队列中, epoll_wait 返回直接访问就绪队列就知道哪些⽂件描述符就绪. 这个操作时间复杂度O(1).即使⽂件描述符数⽬很多, 效率也不会受到影响.
④没有数量限制: ⽂件描述符数⽬⽆上限.
四、Epoll的两种模式
epoll作为多路转接的最优解,存在两种模式,它们分别是LT模式和ET模式。
如何理解LT模式和ET模式?
一句话记住
水平触发 LT :只要条件满足,就一直通知
边缘触发 ET :只有条件变化时,才通知一次
用 "门铃 + 有人敲门" 类比
假设:缓冲区有数据 = 门口有人
- 水平触发 LT(select/poll 默认)
有人站在门口 → 门铃一直响
你去读了一部分,但还有人没走 → 门铃继续响
直到没人了,门铃才停
特点:
容错高,读不完下次还会提醒
简单、不容易丢事件
但频繁触发,效率一般
- 边缘触发 ET(epoll 常用)
从没人 → 有人 → 门铃只响一次
你只读了一半,剩下的数据还在 → 门铃不响了
除非再次 "没人→有人",才再响一次
特点:
只通知一次
必须一次性读完所有数据,否则会卡住
效率极高,是高性能网络编程标配
1.LT模式
水平触发Level Triggered,epoll的默认处理方式。
如果有事件就绪,但是没有来得及处理,EPOLL模型会一直通知我们,这就是LT模式。
LT模式实现的EpollServer如下,供大家参考
2.ET模式
简单来说,ET和LT的本质区别就是在recv的时候,LT模式如果数据没有读完的话就会一直通知你去读,而ET模式只通知一次。
那ET模式通知一次,怎么保证你的数据全部读完了呢?
在边缘触发(ET)模式下,要保证数据全部读完,核心思路是:循环读取,直到内核返回「暂时无数据」的信号。
核心原理
ET 模式下,内核只会在「数据从无到有」时通知你一次。要读完所有数据,必须:
- 将文件描述符(fd)设置为非阻塞模式(关键!否则读不到数据时会阻塞);
- 循环调用
read()/recv(),直到返回EAGAIN或EWOULDBLOCK(这两个宏等价,代表「当前无数据可读」);- 处理过程中要捕获其他错误(如连接断开)。
为什么使用ET模式要设置为非阻塞?
先看反例:如果不设置非阻塞会怎样?
假设 fd 是阻塞模式 ,你在 ET 模式下循环调用
read():
- 内核通知你「有数据」→ 你第一次
read()读到了一部分数据;- 你继续循环调用
read()→ 此时内核缓冲区已经空了;- 因为是阻塞模式 ,
read()会一直卡住(阻塞),等待新数据到来;- 但 ET 模式下,内核只有「数据从无到有」时才会通知一次 ------ 新数据来的时候,你的程序还卡在之前的
read()里,根本收不到新通知;- 最终结果:程序卡死,无法处理其他连接 / 事件,完全失去响应。
简单说:阻塞模式下,
read()会在「数据读完后」无限等待,而不是返回「数据已读完」的信号。
正向解释:非阻塞的核心作用
设置非阻塞(
O_NONBLOCK)后,read()会变成「非阻塞读」,行为完全不同:
- 有数据时 → 正常读取,返回读到的字节数;
- 无数据时 → 不会阻塞 ,而是立刻返回
-1,并把errno设为EAGAIN/EWOULDBLOCK(这是「当前无数据可读」的明确信号);- 你拿到这个信号,就知道「数据已经读完了」,可以安全退出循环,去处理其他事件。
把
read()比作「去厨房拿水」:
- 阻塞模式:打开水龙头,没水就一直站在那等(卡死),直到来水才走;
- 非阻塞模式:打开水龙头,没水就立刻回头告诉主人「没水了」(返回 EAGAIN),主人就知道「水已经接完了」,可以去做别的事。
ET 模式下,你需要的是「没水了就告诉我」,而不是「没水就一直等」------ 这就是非阻塞的核心价值。
LT和ET谁更高效?
①ET通知效率更高,有效通知数量最多;
②ET尽快读完所有数据,可以给对方更新一个更大的win窗口,提供对方滑动窗口大小,提高网络发送的报文并发度。
注意:ET循环读取,可以使接收缓冲区的可用空间更大,给发送端一个更大的win窗口,提高TCP的传输效率。
为什么要使用ET?
①ET本身通知效率高;
②ET强制程序员使用非阻塞+循环读取,强制性的提高效率,使用LT不一定使用非阻塞+循环读取。
在接收缓冲区中存在一个低水位线,低于低水位线不会立即通知上层读取(因为频繁通知上层读取需要成本),如果接收缓冲区的数据低于低水位线,但是客户端想要服务端尽快处理它,那么客户端就会在TCP报文中添加一个标志位(PSH紧急指针),服务端就会立即将数据传输到上层使其就绪,着也是ET的处理方式。
Reactor模式
一、Reactor 模式是什么?(通俗比喻)
想象你是一家餐厅的大堂经理(Reactor 核心),餐厅有多个餐桌(客户端连接):
传统方式(BIO):经理亲自服务一个餐桌,直到客人吃完(一个连接处理完),才能服务下一个,效率极低;
Reactor 方式(IO 多路复用):经理只负责「监听」所有餐桌的需求(比如点餐、加菜),一旦某个餐桌有需求,就把这个需求分配给对应的服务员(工作线程)处理,自己继续监听其他餐桌。
核心总结:Reactor 模式是基于 IO 多路复用(epoll/select/poll),将「监听 IO 事件」和「处理 IO 事件」分离,实现单线程监听、多线程处理的高并发模型。
二、Reactor 模式核心组件(4 个)
表格
组件 作用(对应餐厅例子) 技术实现(Linux) Reactor 监听 IO 事件,分发事件 epoll + 主线程 Acceptor 监听新连接事件(如客户端发起连接) accept () + 新连接处理 Handler 处理具体的 IO 事件(读 / 写) 读写回调函数 Event Loop 循环监听事件、分发事件(核心循环) while 循环 + epoll_wait 代码展示
